
Garantir a confiabilidade e a qualidade da configuração de alta disponibilidade do Patroni é crucial para manter as operações contínuas do banco de dados do AlloyDB Omni e minimizar o tempo de inatividade. Esta página oferece um guia abrangente para testar seu cluster do Patroni, abordando vários cenários de falha, consistência de replicação e mecanismos de failover.
Testar a configuração do Patroni
Conecte-se a qualquer uma das suas instâncias do patroni (
alloydb-patroni1,alloydb-patroni2oualloydb-patroni3) e navegue até a pasta do patroni do AlloyDB Omni.cd /alloydb/
Inspecione os registros do Patroni.
sudo journalctl -u patroni
As últimas entradas precisam refletir informações sobre o nó Patroni. Você vai ver algo parecido com isto.
May 16 15:10:29 alloydb-patroni1 patroni[1234]: 2024-06-12 15:10:29,020 INFO: no action. I am (patroni1), the leader with the lock May 16 15:10:39 alloydb-patroni1 patroni[1234]: 2024-06-12 15:10:39,010 INFO: no action. I am (patroni1), the leader with the lock May 16 15:10:49 alloydb-patroni1 patroni[1234]: 2024-06-12 15:10:49,007 INFO: no action. I am (patroni1), the leader with the lock
Conecte-se a qualquer instância do Linux com conectividade de rede à sua instância principal do Patroni,
alloydb-patroni1, e receba informações sobre a instância. Talvez seja necessário instalar a ferramentajqexecutandosudo dnf install jq.curl -s http://alloydb-patroni1:8008/patroni | jq .
Algo semelhante ao seguinte vai aparecer:
{ "state": "running", "postmaster_start_time": "2024-05-16 14:12:30.031673+00:00", "role": "master", "server_version": 150005, "xlog": { "location": 83886408 }, "timeline": 1, "replication": [ { "usename": "alloydbreplica", "application_name": "patroni2", "client_addr": "10.172.0.40", "state": "streaming", "sync_state": "async", "sync_priority": 0 }, { "usename": "alloydbreplica", "application_name": "patroni3", "client_addr": "10.172.0.41", "state": "streaming", "sync_state": "async", "sync_priority": 0 } ], "dcs_last_seen": 1715870011, "database_system_identifier": "7369600155531440151", "patroni": { "version": "3.3.0", "scope": "my-patroni-cluster", "name": "patroni1" } }
Chamar o endpoint de API HTTP do Patroni em um nó do Patroni expõe vários detalhes sobre o estado e a configuração dessa instância específica do PostgreSQL gerenciada pelo Patroni, incluindo informações sobre o estado do cluster, linha do tempo, informações do WAL e verificações de integridade que indicam se os nós e o cluster estão funcionando corretamente.
Testar a configuração do HAProxy
Em uma máquina com um navegador e conectividade de rede com o nó do HAProxy, acesse o seguinte endereço:
http://haproxy:7000. Como alternativa, use o endereço IP externo da instância do HAProxy em vez do nome do host.Você vai ver algo parecido com a captura de tela abaixo.
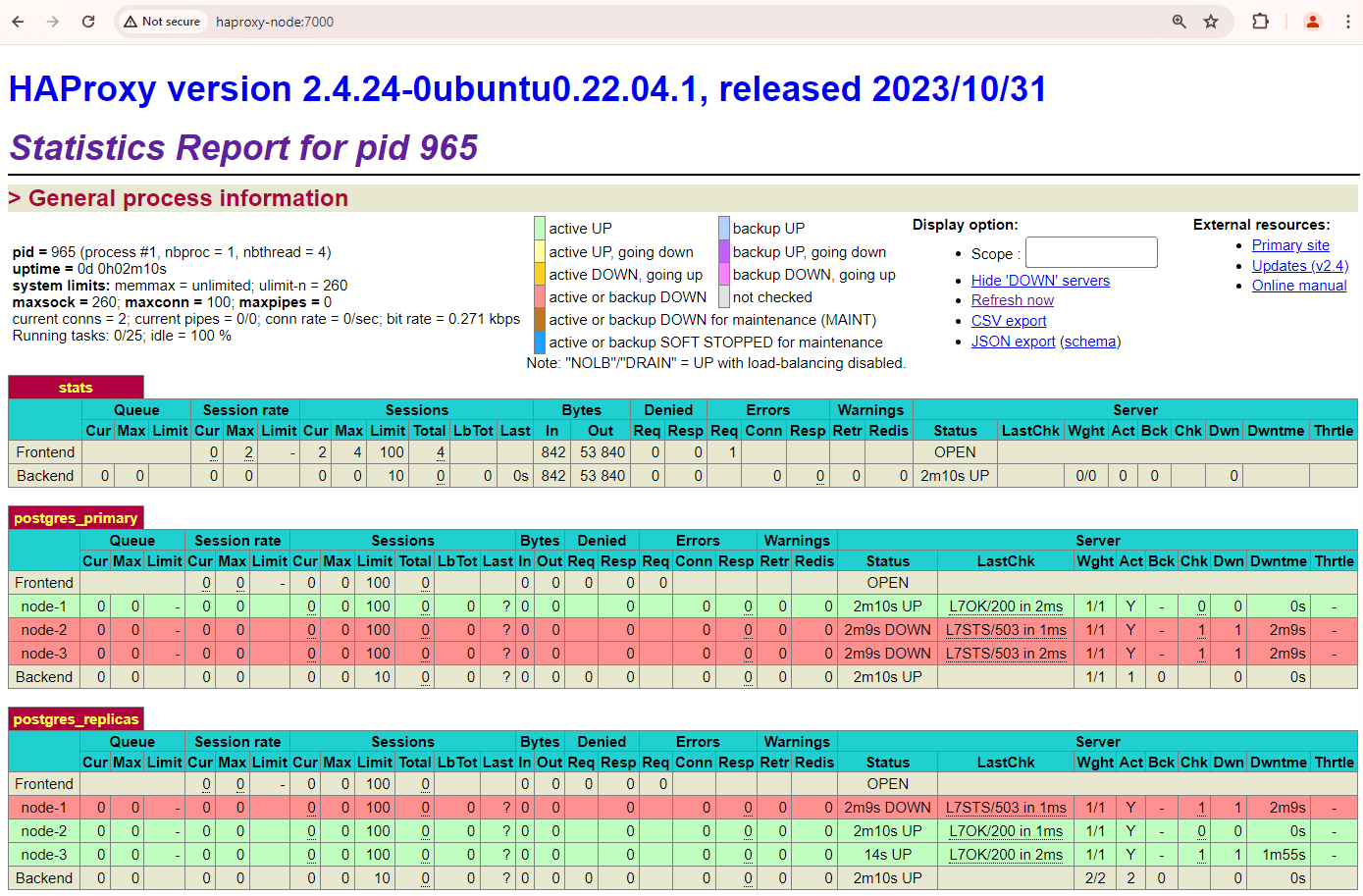
Figura 1. Página de status do HAProxy mostrando o status de integridade e a latência dos nós do Patroni.
No painel do HAProxy, é possível conferir o status de integridade e a latência do nó principal do Patroni,
patroni1, e das duas réplicas,patroni2epatroni3.É possível executar consultas para verificar as estatísticas de replicação no cluster. Em um cliente como o pgAdmin, conecte-se ao servidor de banco de dados principal pelo HAProxy e execute a seguinte consulta.
SELECT pid, usename, application_name, client_addr, state, sync_state FROM pg_stat_replication;Você vai ver algo parecido com o diagrama a seguir, mostrando que
patroni2epatroni3estão fazendo streaming depatroni1.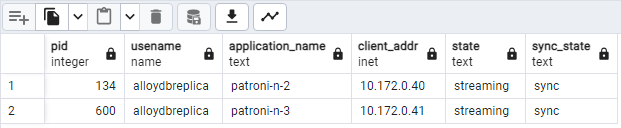
Figura 2.Saída de pg_stat_replication mostrando o estado de replicação dos nós do Patroni.
Testar o failover automático
Nesta seção, no cluster de três nós, simulamos uma interrupção no nó principal interrompendo o contêiner Patroni anexado em execução. É possível parar o serviço Patroni no primário para simular uma interrupção ou aplicar algumas regras de firewall para interromper a comunicação com esse nó.
Na instância principal do Patroni, navegue até a pasta do AlloyDB Omni Patroni.
cd /alloydb/
Interrompa o contêiner.
sudo systemctl stop patroni
O resultado será semelhante a este: Isso deve validar que o contêiner e a rede foram interrompidos.
patroni.service - Runner for Patroni Loaded: loaded (/etc/systemd/system/patroni.service; enabled; vendor preset: disabled) Active: inactive (dead) since ...
Atualize o painel do HAProxy e veja como o failover acontece.
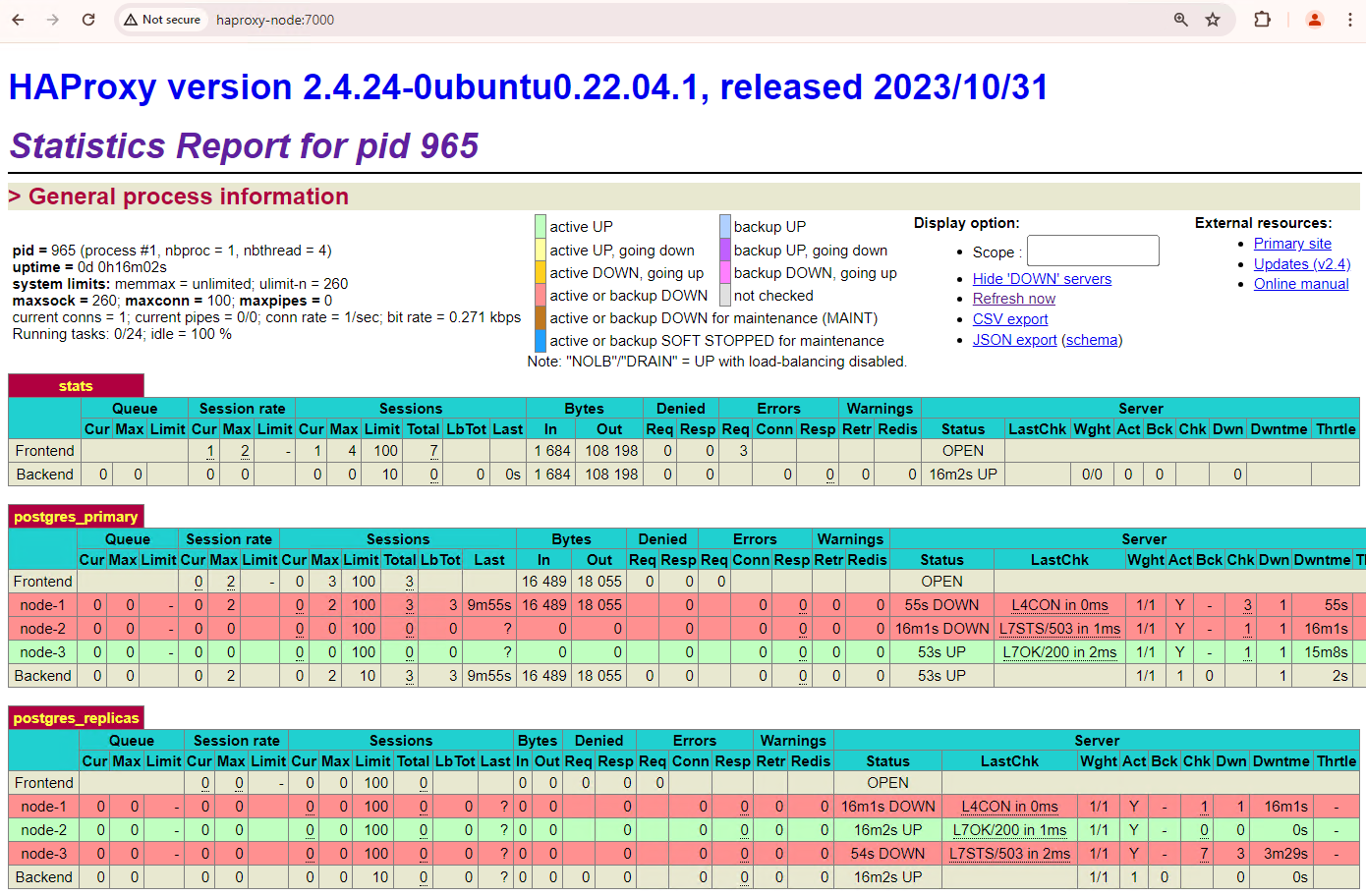
Figura 3. Painel do HAProxy mostrando o failover do nó principal para o nó em espera.
A instância
patroni3se tornou a nova principal, epatroni2é a única réplica restante. A primária anterior,patroni1, está inativa e as verificações de integridade falham.O Patroni realiza e gerencia o failover usando uma combinação de monitoramento, consenso e orquestração automatizada. Assim que o nó primário não renovar o contrato de locação dentro de um tempo limite especificado ou se ele informar uma falha, os outros nós do cluster reconhecerão essa condição pelo sistema de consenso. Os nós restantes se coordenam para selecionar a réplica mais adequada para promover como a nova principal. Depois que uma réplica candidata é selecionada, o Patroni promove esse nó a principal aplicando as mudanças necessárias, como atualizar a configuração do PostgreSQL e reproduzir todos os registros WAL pendentes. Em seguida, o novo nó principal atualiza o sistema de consenso com o status dele, e as outras réplicas se reconfiguram para seguir a nova instância principal, incluindo a troca da origem de replicação e, possivelmente, a atualização de novas transações. O HAProxy detecta o novo principal e redireciona as conexões do cliente de acordo, garantindo uma interrupção mínima.
Em um cliente como o pgAdmin, conecte-se ao servidor de banco de dados pelo HAProxy e verifique as estatísticas de replicação no cluster após o failover.
SELECT pid, usename, application_name, client_addr, state, sync_state FROM pg_stat_replication;Você vai ver algo parecido com o diagrama a seguir, mostrando que apenas
patroni2está transmitindo agora.
Figura 4: saída de pg_stat_replication mostrando o estado da replicação dos nós do Patroni após o failover.
Seu cluster de três nós pode sobreviver a mais uma interrupção. Se você parar o nó principal atual,
patroni3, outro failover vai ocorrer.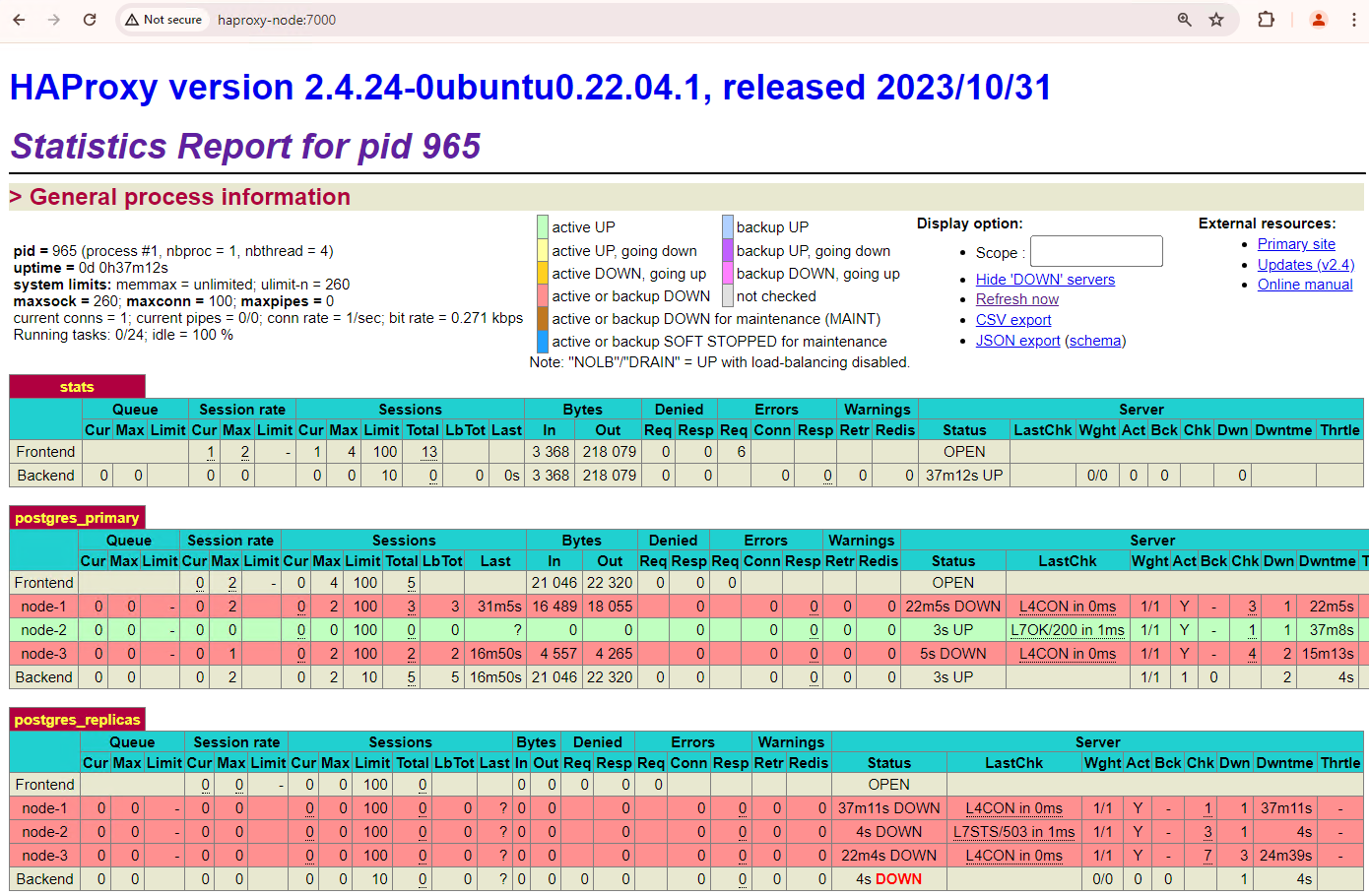
Figura 5. Painel do HAProxy mostrando o failover do nó principal,
patroni3, para o nó em espera,patroni2.
Considerações sobre substituição
O fallback é o processo de restabelecer o antigo nó de origem após um failover. O failback automático geralmente não é recomendado em um cluster de banco de dados de alta disponibilidade devido a várias questões críticas, como recuperação incompleta, risco de cenários de split-brain e atraso na replicação.
No cluster do Patroni, se você ativar os dois nós em que simulou uma interrupção, eles vão se juntar ao cluster como réplicas em espera.
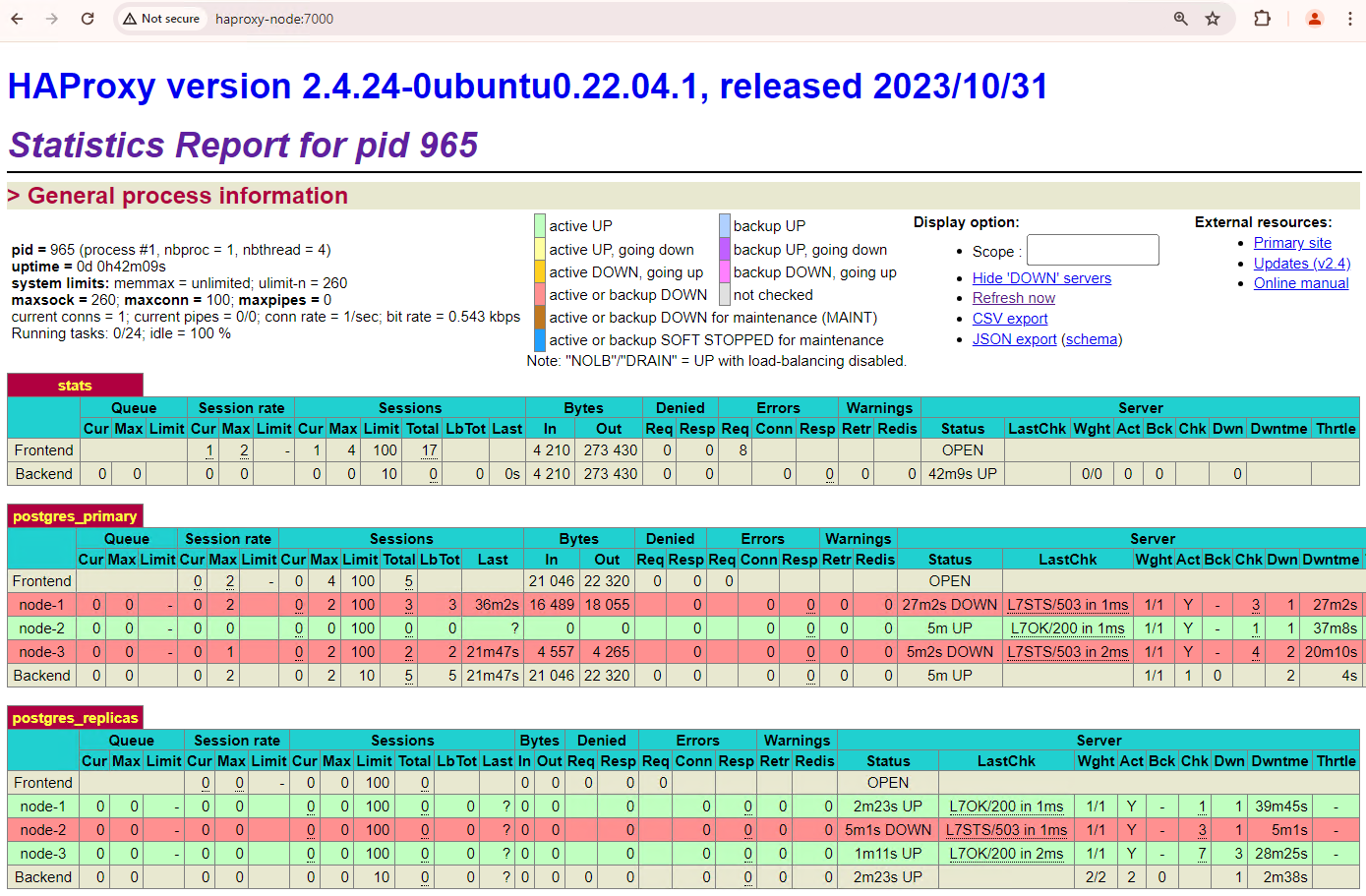
Figura 6. Painel do HAProxy mostrando a restauração de patroni1 e
patroni3 como nós em espera.
Agora, patroni1 e patroni3 estão replicando da instância principal atual patroni2.

Figura 7.Saída de pg_stat_replication mostrando o estado da replicação dos nós do Patroni após o fallback.
Se quiser fazer failback manual para a primária inicial, use a interface de linha de comando patronictl. Ao optar pelo fallback manual, você garante um processo de recuperação mais confiável, consistente e totalmente verificado, mantendo a integridade e a disponibilidade dos seus sistemas de banco de dados.