
Com a transcrição de voz, é possível converter seus dados de áudio de streaming em texto transcrito em tempo real. O Agent Assist faz sugestões com base em texto. Portanto, os dados de áudio precisam ser convertidos antes de serem usados. Também é possível usar áudio de streaming transcrito com o Customer Experience Insights para coletar dados em tempo real sobre conversas de agentes (por exemplo, Modelagem de temas).
Há duas maneiras de transcrever áudio de streaming para uso com o Agent Assist: usando o recurso SIPREC ou fazendo chamadas gRPC com dados de áudio como payload. Nesta página, descrevemos o processo de transcrição de dados de áudio streaming usando chamadas gRPC.
A transcrição de voz funciona usando o reconhecimento de fala de streaming do Speech-to-Text. A Speech-to-Text oferece vários modelos de reconhecimento, padrão e aprimorado. O Agent Assist não restringe os modelos que podem ser usados com a transcrição de voz, mas ela é compatível no nível GA apenas quando usada com o modelo de telefonia ou Chirp 3. Para ter a melhor qualidade de transcrição, recomendamos o modelo Chirp 3, sujeito à disponibilidade regional.
Pré-requisitos
- Crie um projeto em Google Cloud.
- Ative a API Dialogflow.
- Entre em contato com seu representante do Google para garantir que sua conta tenha acesso aos modelos avançados do Speech-to-Text.
Criar um perfil de conversa
Para criar um perfil de conversa, use o console do Agent Assist ou chame o método create diretamente no recurso ConversationProfile.
Para transcrição de voz, recomendamos que você configure
ConversationProfile.stt_config como o InputAudioConfig padrão ao enviar
dados de áudio em uma conversa.
![]()
Receber transcrições durante a conversa
Para receber transcrições durante a conversa, crie participantes e envie dados de áudio para cada um deles.
Criar participantes
Há três tipos de participante.
Consulte a documentação de referência para mais detalhes sobre os papéis. Chame o método create no
participant e especifique o role. Somente um participante END_USER ou HUMAN_AGENT pode chamar StreamingAnalyzeContent, que é necessário para receber uma transcrição.
Enviar dados de áudio e receber uma transcrição
É possível usar
StreamingAnalyzeContent
para enviar o áudio de um participante ao Google e receber a transcrição, com os
seguintes parâmetros:
A primeira solicitação no stream precisa ser
InputAudioConfig. Os campos configurados aqui substituem as configurações correspondentes emConversationProfile.stt_config. Não envie nenhuma entrada de áudio até a segunda solicitação.audioEncodingprecisa ser definido comoAUDIO_ENCODING_LINEAR_16ouAUDIO_ENCODING_MULAW.model: é o modelo do Speech-to-Text que você quer usar para transcrever o áudio. Defina esse campo comochirp_3. A variante não afeta a qualidade da transcrição. Portanto, você pode deixar Variante do modelo de fala sem especificação ou escolher Usar a melhor opção disponível.singleUtteranceprecisa ser definido comofalsepara garantir a melhor qualidade de transcrição. Não espereEND_OF_SINGLE_UTTERANCEsesingleUtteranceforfalse, mas você pode depender deisFinal==trueemStreamingAnalyzeContentResponse.recognition_resultpara fechar parcialmente o fluxo.- Parâmetros adicionais opcionais: os parâmetros a seguir são opcionais. Para ter acesso a esses parâmetros, entre em contato com seu representante do Google.
languageCode:language_codedo áudio. O valor padrão éen-US.alternativeLanguageCodes: esse recurso está disponível apenas para o modelo Chirp 3. Outros idiomas que podem ser detectados no áudio. O Agent Assist usa o campolanguage_codepara detectar automaticamente o idioma no início do áudio e o define como padrão em todas as conversas seguintes. O campoalternativeLanguageCodespermite especificar mais opções para o Agent Assist escolher.phraseSets: o nome do recursophraseSetda adaptação do modelo de conversão de voz em texto.- Para configurar a adaptação do modelo do Chirp 3, adicione frases inline separadas por novas linhas, sem vírgulas.
- Para usar a adaptação do modelo com outros modelos, como
telephonypara transcrição de voz, primeiro crie ophraseSetusando a API Speech-to-Text e especifique o nome do recurso aqui.
Depois de enviar a segunda solicitação com a carga útil de áudio, você vai começar a receber alguns
StreamingAnalyzeContentResponsesdo stream.- Você pode fechar parcialmente o stream (ou parar de enviar em algumas linguagens, como Python) quando vir
is_finaldefinido comotrueemStreamingAnalyzeContentResponse.recognition_result. - Depois que você fechar parcialmente o stream, o servidor vai enviar de volta a resposta com a transcrição final, além de possíveis sugestões do Dialogflow ou do Agent Assist.
- Você pode fechar parcialmente o stream (ou parar de enviar em algumas linguagens, como Python) quando vir
Você encontra a transcrição final nos seguintes locais:
StreamingAnalyzeContentResponse.message.content.- Se você ativar as notificações do Pub/Sub, também poderá ver a transcrição no Pub/Sub.
Inicie um novo stream depois que o anterior for fechado.
- Reenvio de áudio: os dados de áudio gerados após o último
speech_end_offsetda resposta comis_final=truepara o novo horário de início do stream precisam ser reenviados paraStreamingAnalyzeContentpara garantir a melhor qualidade de transcrição.
- Reenvio de áudio: os dados de áudio gerados após o último
Confira o diagrama que ilustra como o stream funciona.
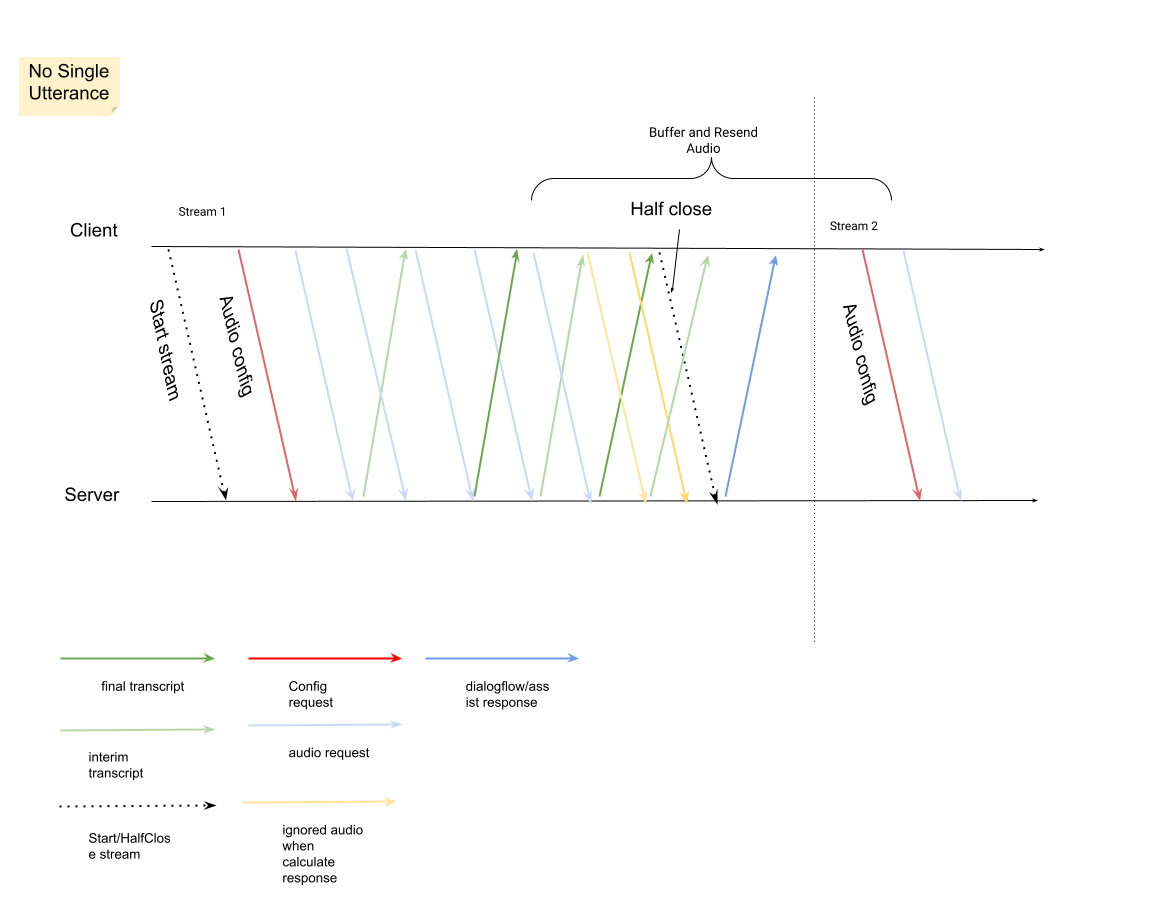
Exemplo de código de solicitação de reconhecimento de streaming
O exemplo de código a seguir ilustra como enviar uma solicitação de transcrição de streaming.
Python
Para autenticar no Agent Assist, configure o Application Default Credentials. Para mais informações, consulte Configurar a autenticação para um ambiente de desenvolvimento local.
Siga estas etapas para ver os arquivos Python de conversation_management e participant_management.
Acesse o repositório do GitHub para documentos do Python.
Clique em Acessar arquivo e digite o nome do arquivo:
conversation_managementouparticipant_management.Pressione Enter.
Práticas recomendadas
O tempo de envio da mensagem é quando uma expressão começa. Use o horário de envio da mensagem para determinar a ordem em que a central de atendimento mostra ou analisa as mensagens de voz.