

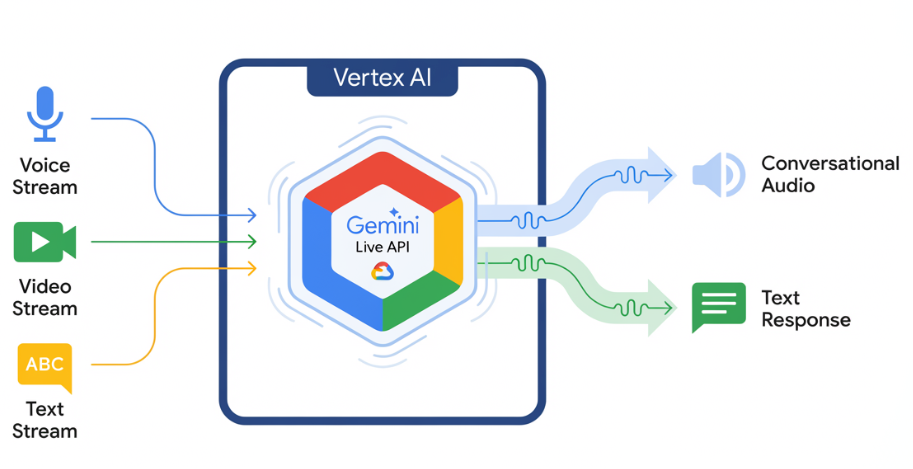
Gemini Live API 可與 Gemini 進行低延遲的即時語音和視訊互動,並處理連續的音訊、視訊或文字串流,提供即時且類似人類的口語回覆,為使用者打造自然的對話體驗。
在 Agent Platform Studio 中試用 Gemini Live API
應用實例
Gemini Live API 可用於建構即時語音和視訊代理程式,適用於各種產業,包括:
- 電子商務和零售:提供個人化建議的購物助理,以及解決顧客問題的支援服務專員。
- 遊戲:互動式非玩家角色 (NPC)、遊戲內說明助理,以及遊戲內容的即時翻譯。
- 新一代介面:在機器人、智慧眼鏡和車輛中,提供支援語音和視訊的體驗。
- 醫療保健:為病患提供支援和教育資訊的健康夥伴。
- 金融服務:提供財富管理和投資建議的 AI 顧問。
- 教育:AI 導師和學習夥伴,提供個人化指導和意見回饋。
主要功能與特色
Gemini Live API 提供全方位功能,可建構強大的語音和視訊代理程式:
- 高品質音質: Gemini Live API 支援多種語言,可提供自然逼真的語音。
- 支援多種語言: 支援 24 種語言。
- 插話: 使用者隨時可以打斷模型,進行回應式互動。
- 情感對話: 根據使用者輸入內容的措辭調整回覆風格和語氣。
- 使用工具: 整合函式呼叫和 Google 搜尋等工具,進行動態互動。
- 音訊轉錄稿: 提供使用者輸入內容和模型輸出內容的文字轉錄稿。
- 主動式語音 (預覽版): 可控制模型回覆的時間和情境。
技術規格
下表列出 Gemini Live API 的技術規格:
| 類別 | 詳細資料 |
|---|---|
| 輸入模態 | 音訊 (原始 16 位元 PCM 音訊,16 kHz,小端序)、圖片/影片 (JPEG 1FPS)、文字 |
| 輸出模態 | 音訊 (原始 16 位元 PCM 音訊,24 kHz,小端序)、文字 |
| 通訊協定 | 具狀態的 WebSocket 連線 (WSS) |
支援的模型
下列模型支援 Gemini Live API。請根據互動需求選取適當模型。
| 模型 ID | 可用性 | 用途 | 主要功能與特色 |
|---|---|---|---|
gemini-live-2.5-flash-native-audio |
正式發布版 | 建議做法:低延遲語音代理。支援流暢切換語言和情緒基調。 |
|
gemini-live-2.5-flash-preview-native-audio-09-2025 |
公開預先發布版 | 即時語音代理可節省成本。 |
|
開始使用
選取與開發環境相符的指南:
與合作夥伴整合
如果您想與部分合作夥伴整合,這些平台已透過 WebRTC 協定整合 Gemini Live API,簡化即時音訊和視訊應用程式的開發作業。