
סקירה והצגה חזותית של נתונים ב-BigQuery מתוך JupyterLab
בדף הזה מפורטות כמה דוגמאות לאופן שבו אפשר לחקור ולהציג נתונים שמאוחסנים ב-BigQuery מתוך ממשק JupyterLab של מופע מסמכי ה-notebooks המנוהלים של Vertex AI Workbench.
פתיחת JupyterLab
נכנסים לדף Managed notebooks במסוף Google Cloud .
לצד השם של מכונת המחברות המנוהלות, לוחצים על Open JupyterLab.
מופע המחברת המנוהלת ייפתח ב-JupyterLab.
קריאת נתונים מ-BigQuery
בקטעים הבאים תקראו נתונים מ-BigQuery, שבהם תשתמשו בהמשך כדי ליצור תרשימים. השלבים האלה זהים לאלה שבמאמר שליחת שאילתות לנתונים ב-BigQuery מתוך JupyterLab, כך שאם כבר השלמתם אותם, אתם יכולים לדלג אל קבלת סיכום של נתונים בטבלה ב-BigQuery.
שאילתות על נתונים באמצעות פקודת הקסם %%bigquery
בקטע הזה, תכתבו SQL ישירות בתאי מחברת ותקראו נתונים מ-BigQuery לתוך מחברת Python.
פקודות Magic שמשתמשות בתו אחוז אחד או שניים (% או %%) מאפשרות לכם להשתמש בתחביר מינימלי כדי ליצור אינטראקציה עם BigQuery בתוך המחברת. ספריית הלקוח של BigQuery ל-Python מותקנת באופן אוטומטי במופע של מחברות מנוהלות. מאחורי הקלעים, פקודת ה-magic %%bigquery משתמשת בספריית הלקוח של BigQuery ל-Python כדי להריץ את השאילתה שצוינה, להמיר את התוצאות ל-DataFrame של pandas, לשמור את התוצאות במשתנה (אופציונלי) ואז להציג את התוצאות.
הערה: החל מגרסה 1.26.0 של חבילת google-cloud-bigquery Python, נעשה שימוש ב-BigQuery Storage API כברירת מחדל להורדת תוצאות מפקודות ה-magic של %%bigquery.
כדי לפתוח קובץ notebook, בוחרים באפשרות קובץ > חדש > Notebook (מחברת).
בתיבת הדו-שיח Select Kernel, בוחרים באפשרות Python (Local) ולוחצים על Select.
קובץ ה-IPYNB החדש ייפתח.
כדי לקבל את מספר האזורים לפי מדינה במערך הנתונים
international_top_termsמזינים את ההצהרה הבאה:%%bigquery SELECT country_code, country_name, COUNT(DISTINCT region_code) AS num_regions FROM `bigquery-public-data.google_trends.international_top_terms` WHERE refresh_date = DATE_SUB(CURRENT_DATE, INTERVAL 1 DAY) GROUP BY country_code, country_name ORDER BY num_regions DESC;
לוחצים על הרצת התא.
הפלט אמור להיראות כך:
Query complete after 0.07s: 100%|██████████| 4/4 [00:00<00:00, 1440.60query/s] Downloading: 100%|██████████| 41/41 [00:02<00:00, 20.21rows/s] country_code country_name num_regions 0 TR Turkey 81 1 TH Thailand 77 2 VN Vietnam 63 3 JP Japan 47 4 RO Romania 42 5 NG Nigeria 37 6 IN India 36 7 ID Indonesia 34 8 CO Colombia 33 9 MX Mexico 32 10 BR Brazil 27 11 EG Egypt 27 12 UA Ukraine 27 13 CH Switzerland 26 14 AR Argentina 24 15 FR France 22 16 SE Sweden 21 17 HU Hungary 20 18 IT Italy 20 19 PT Portugal 20 20 NO Norway 19 21 FI Finland 18 22 NZ New Zealand 17 23 PH Philippines 17 ...
בתא הבא (מתחת לפלט מהתא הקודם), מזינים את הפקודה הבאה כדי להריץ את אותה שאילתה, אבל הפעם שומרים את התוצאות ב-DataFrame חדש של pandas בשם
regions_by_country. מזינים את השם הזה באמצעות ארגומנט עם פקודת הקסם%%bigquery.%%bigquery regions_by_country SELECT country_code, country_name, COUNT(DISTINCT region_code) AS num_regions FROM `bigquery-public-data.google_trends.international_top_terms` WHERE refresh_date = DATE_SUB(CURRENT_DATE, INTERVAL 1 DAY) GROUP BY country_code, country_name ORDER BY num_regions DESC;
הערה: מידע נוסף על הארגומנטים הזמינים לפקודה
%%bigqueryזמין במאמרי העזרה בנושא פקודות קסם בספריית הלקוח.לוחצים על הרצת התא.
בתא הבא, מזינים את הפקודה הבאה כדי לראות את השורות הראשונות של תוצאות השאילתה שקראתם:
regions_by_country.head()לוחצים על הרצת התא.
ה-DataFrame של pandas,
regions_by_country, מוכן לשרטוט.
שאילתת נתונים באמצעות ספריית הלקוח של BigQuery ישירות
>
קבלת סיכום של נתונים בטבלה ב-BigQuery
בקטע הזה תשתמשו בקיצור דרך במחברת כדי לקבל סיכום של נתונים סטטיסטיים והדמיות לכל השדות בטבלה ב-BigQuery. זו יכולה להיות דרך מהירה ליצור פרופיל של הנתונים לפני שממשיכים לבחון אותם.
ספריית הלקוח של BigQuery מספקת פקודה מיוחדת, %bigquery_stats, שאפשר להפעיל עם שם טבלה ספציפי כדי לקבל סקירה כללית של הטבלה ונתונים סטטיסטיים מפורטים על כל אחת מהעמודות בטבלה.
בתא הבא, מזינים את הקוד הבא כדי להריץ את הניתוח הזה בטבלה
top_termsשל ארה"ב:%bigquery_stats bigquery-public-data.google_trends.top_termsלוחצים על הרצת התא.
אחרי שהקמפיין פועל במשך זמן מה, מופיעה תמונה עם נתונים סטטיסטיים שונים על כל אחד מ-7 המשתנים בטבלה
top_terms. בתמונה הבאה אפשר לראות חלק מהפלט לדוגמה: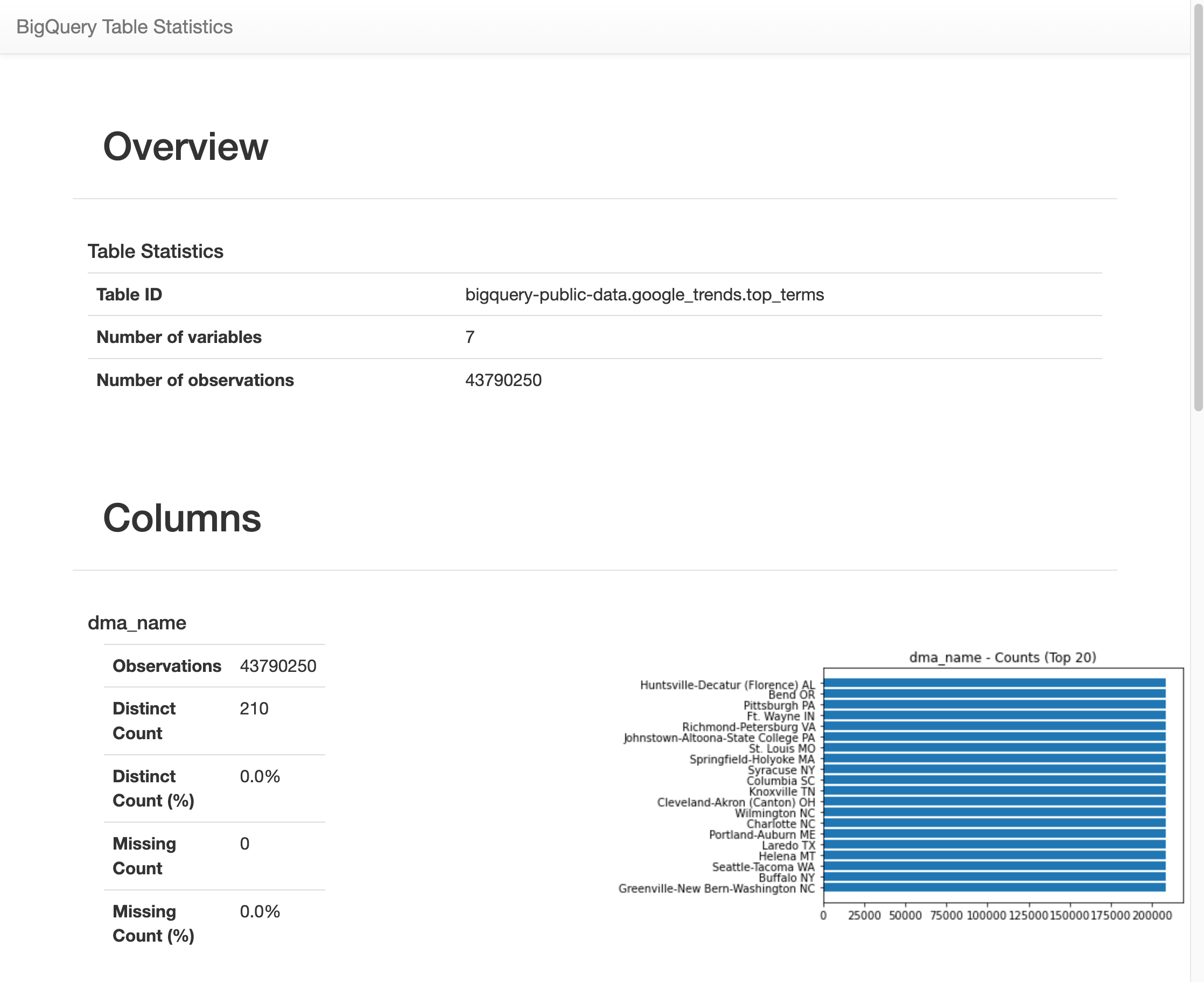
הדמיה של נתונים ב-BigQuery
בקטע הזה תשתמשו ביכולות של יצירת תרשימים כדי להמחיש את התוצאות של השאילתות שהפעלתם קודם במסמך ה-notebook של Jupyter.
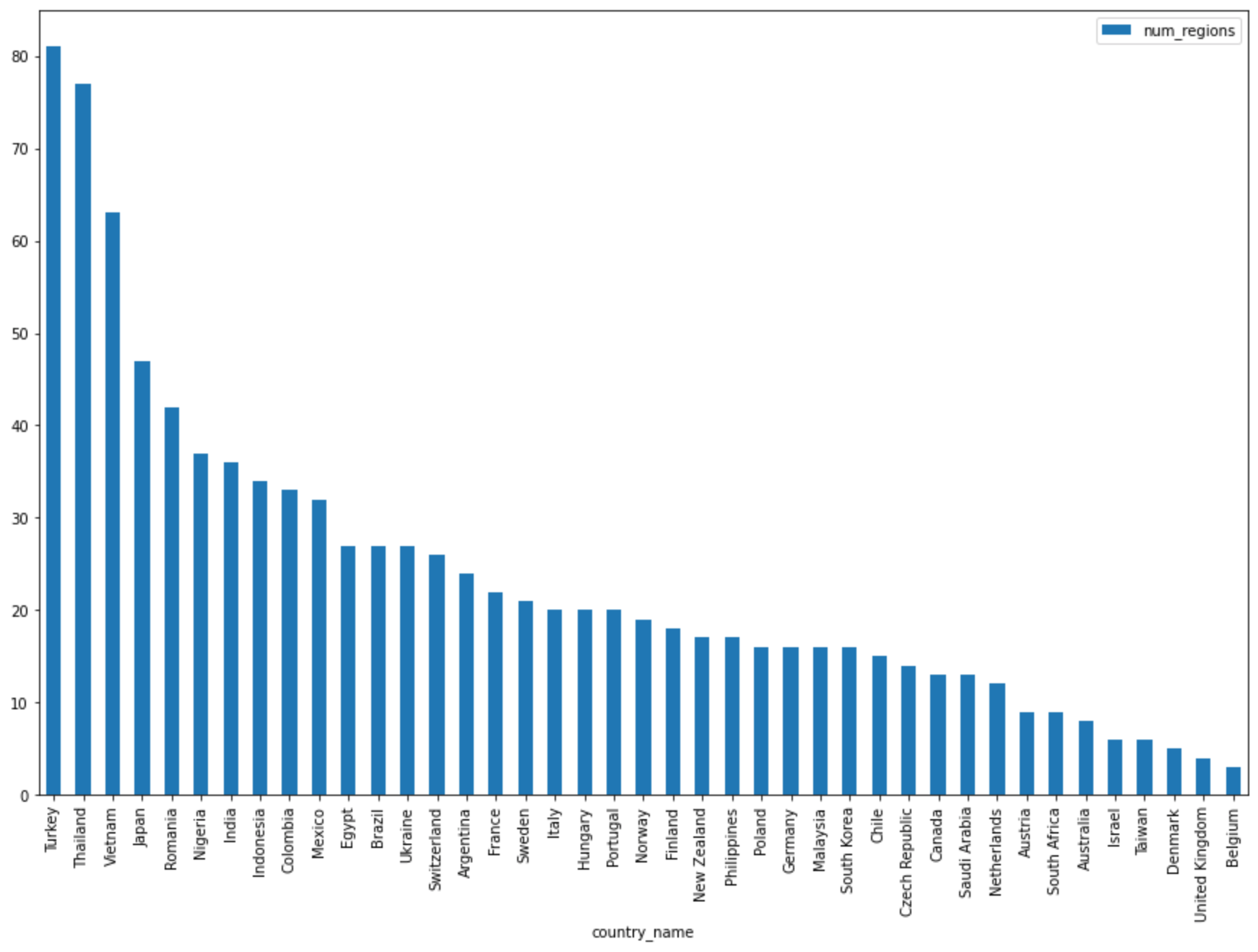
בתא הבא, מזינים את הקוד הבא כדי להשתמש בשיטה
DataFrame.plot()של pandas כדי ליצור תרשים עמודות שמציג את התוצאות של השאילתה שמחזירה את מספר האזורים לפי מדינה:regions_by_country.plot(kind="bar", x="country_name", y="num_regions", figsize=(15, 10))לוחצים על הרצת התא.
התרשים אמור להיראות כך:
בתא הבא, מזינים את הקוד הבא כדי להשתמש בשיטה
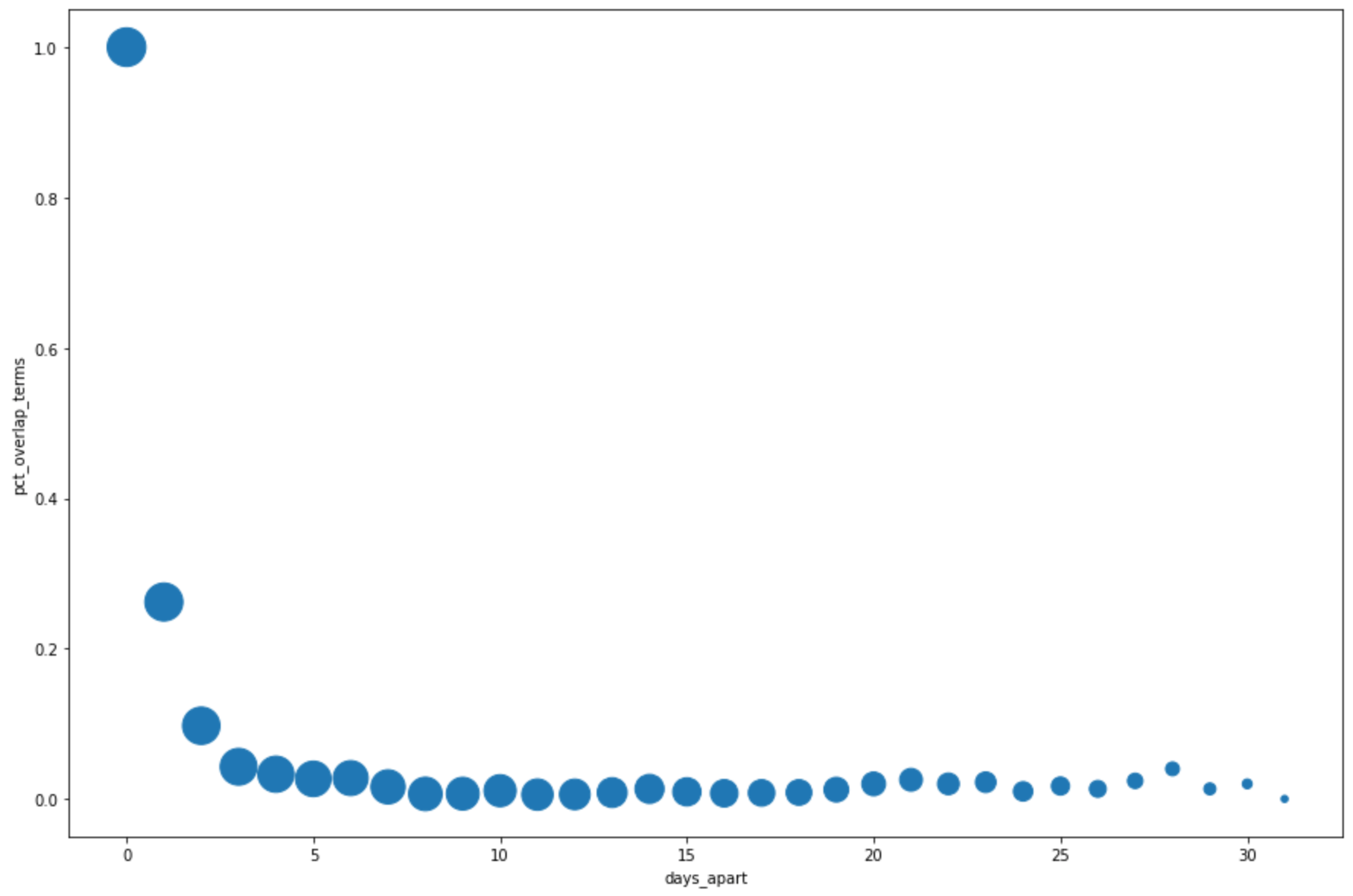
DataFrame.plot()של pandas כדי ליצור תרשים פיזור שממחיש את התוצאות מהשאילתה לגבי אחוז החפיפה במונחי החיפוש המובילים לפי מספר הימים בין החיפושים:pct_overlap_terms_by_days_apart.plot( kind="scatter", x="days_apart", y="pct_overlap_terms", s=len(pct_overlap_terms_by_days_apart["num_date_pairs"]) * 20, figsize=(15, 10) )לוחצים על הרצת התא.
התרשים אמור להיראות כך: הגודל של כל נקודה משקף את מספר זוגות התאריכים שההפרש ביניהם הוא מספר הימים הזה בנתונים. לדוגמה, יש יותר זוגות עם הפרש של יום אחד מאשר זוגות עם הפרש של 30 יום, כי מונחי החיפוש הנפוצים ביותר מוצגים מדי יום במשך כחודש.
מידע נוסף על ויזואליזציה של נתונים זמין במסמכי התיעוד של pandas.