
אתם יכולים לנסות את הטכנולוגיה המתקדמת של Vector Search באמצעות ההדגמה האינטראקטיבית של Vector Search. ההדגמה מבוססת על מערכי נתונים מהעולם האמיתי, ומספקת דוגמה מציאותית שתעזור לכם להבין איך חיפוש וקטורי עובד, ללמוד על חיפוש סמנטי וחיפוש היברידי ולראות איך דירוג מחדש פועל. פשוט שולחים תיאור קצר של בעל חיים, צמח, מוצר מסחר אלקטרוני או פריט אחר, ונותנים לחיפוש וקטורי לעשות את השאר.
רוצה לנסות?
כדאי להתנסות באפשרויות השונות בהדגמה כדי להבין את היסודות של טכנולוגיית החיפוש הווקטורי ולהתחיל להשתמש בחיפוש וקטורי.
כדי להריץ:
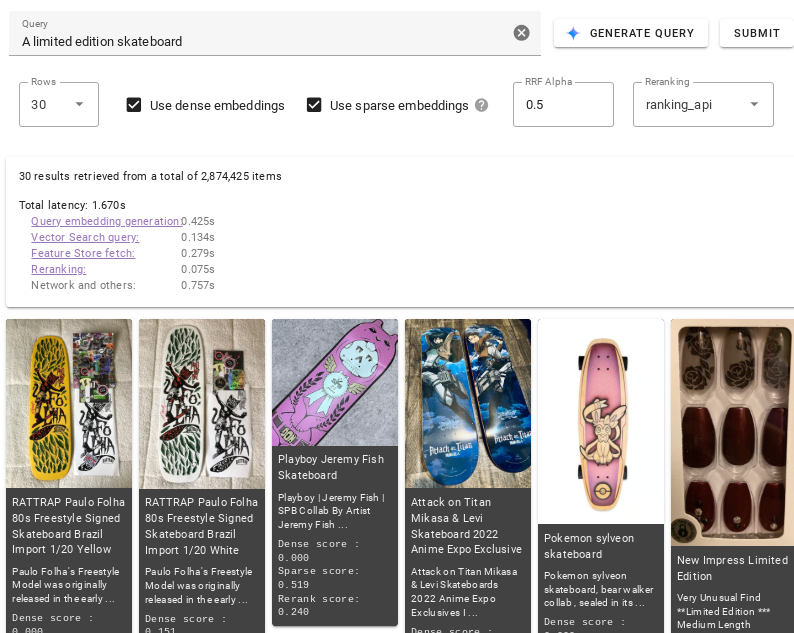
בשדה הטקסט שאילתה, מתארים את הפריטים שרוצים לשאול עליהם (לדוגמה,
vintage 1970s pinball machine). לחלופין, לוחצים על יצירת שאילתה כדי ליצור תיאור באופן אוטומטי.לוחצים על שליחה.
מידע נוסף על הפעולות שאפשר לבצע בהדגמה זמין במאמר ממשק משתמש.
ממשק משתמש
בקטע הזה מוסבר על ההגדרות בממשק המשתמש שבעזרתן אפשר לשלוט בתוצאות שמוחזרות מחיפוש וקטורי ובדירוג שלהן.
קבוצת הנתונים
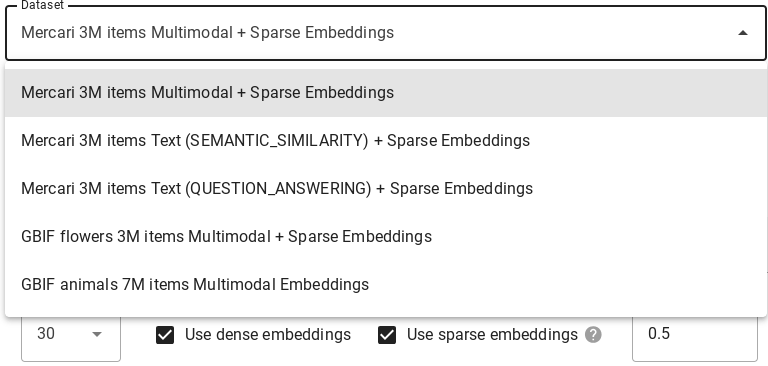
בתפריט הנפתח Dataset בוחרים את מערך הנתונים שבו רוצים להריץ את השאילתה בחיפוש הווקטורי. פרטים נוספים על כל אחד מהם זמינים במאמר בנושא מערכי נתונים.
שאילתה
בשדה Query, מוסיפים תיאור או מילת מפתח אחת או יותר כדי לציין אילו פריטים רוצים שחיפוש וקטורי ימצא. אפשרות אחרת היא ללחוץ על יצירת שאילתה כדי ליצור תיאור באופן אוטומטי.

שינוי
יש כמה אפשרויות לשינוי התוצאות שמתקבלות מחיפוש וקטורי:

לוחצים על שורות ובוחרים את המספר המקסימלי של תוצאות החיפוש שרוצים שמנוע החיפוש הווקטורי יחזיר.
בוחרים באפשרות שימוש בהטמעות צפופות אם רוצים שחיפוש וקטורי יחזיר תוצאות דומות מבחינה סמנטית.
בוחרים באפשרות שימוש בהטמעות דלילות אם רוצים שחיפוש וקטורי יחזיר תוצאות על סמך תחביר הטקסט של השאילתה. לא כל מערכי הנתונים הזמינים תומכים במודלים של הטמעה דלילה.
אם רוצים שמנוע Vector Search ישתמש בחיפוש היברידי, צריך לבחור גם באפשרות Use dense embeddings (שימוש בהטמעות צפופות) וגם באפשרות Use sparse embeddings (שימוש בהטמעות דלילות). לא כל מערכי הנתונים תומכים במודל הזה. חיפוש היברידי משלב אלמנטים של הטמעות צפופות ודלילות, מה שיכול לשפר את האיכות של תוצאות החיפוש. מידע נוסף אפשר למצוא במאמר מידע על חיפוש היברידי.
בשדה RRF Alpha, מזינים ערך בין 0.0 ל-1.0 כדי לציין את ההשפעה של דירוג RRF.
כדי לשנות את דירוג תוצאות החיפוש, בוחרים באפשרות ranking_api מהתפריט הנפתח שינוי דירוג או באפשרות ללא כדי להשבית את שינוי הדירוג.
מדדים
אחרי הרצת שאילתה, מוצגים מדדי השהיה שמפרטים את הזמן שנדרש להשלמת שלבים שונים של החיפוש.

תהליך השאילתה
כשמערכת מעבדת שאילתה, קורים הדברים הבאים:
יצירת הטמעה של שאילתה: נוצרת הטמעה של טקסט השאילתה שצוין.
שאילתת חיפוש וקטורי: השאילתה מורצת עם אינדקס החיפוש הווקטורי.
שליפה מ-Vertex AI Feature Store: המערכת קוראת מאפיינים (לדוגמה, שם פריט, תיאור או כתובת URL של תמונה) מ-Vertex AI Feature Store באמצעות רשימת מזהי הפריטים שמוחזרת מ-Vector Search.
דירוג מחדש: הפריטים שאוחזרו ממוינים באמצעות ממשקי API לדירוג, שמשתמשים בטקסט השאילתה, בשם הפריט ובתיאור הפריט כדי לחשב את ציון הרלוונטיות.
הטמעות
מולטי-מודאלי: חיפוש סמנטי מולטי-מודאלי בתמונות של פריטים. פרטים נוספים זמינים במאמר מהו חיפוש מולטימודאלי: 'מודלים גדולים של שפה עם ראייה' משנים את העסקים.
טקסט (דמיון סמנטי): חיפוש סמנטי של טקסט בשמות ובתיאורים של פריטים על סמך דמיון סמנטי. מידע נוסף זמין במאמר Vertex AI Embeddings for Text: Grounding LLMs made easy.
טקסט (מענה על שאלות): חיפוש סמנטי של טקסט בשמות של פריטים ובתיאורים שלהם, עם שיפור באיכות החיפוש לפי סוג המשימה QUESTION_ANSWERING. האפשרות הזו מתאימה לאפליקציות מסוג שאלות ותשובות. מידע על הטמעות של סוגי משימות זמין במאמר שיפור תרחיש השימוש ב-AI גנרטיבי באמצעות הטמעות של Vertex AI וסוגי משימות.
דליל (חיפוש היברידי): חיפוש מילות מפתח (מבוסס-טוקנים) בשמות ובתיאורים של פריטים, שנוצרו באמצעות אלגוריתם TF-IDF. מידע נוסף זמין במאמר מידע על חיפוש היברידי.
מערכי נתונים
ההדגמה האינטראקטיבית כוללת כמה מערכי נתונים שאפשר להריץ עליהם שאילתות. ההבדלים בין מערכי הנתונים הם במודל ההטמעה, בתמיכה בהטמעות דלילות, במאפייני ההטמעה ובמספר הפריטים המאוחסנים.
| קבוצת הנתונים | מודל הטמעה | מודל הטמעה דלילה | הטמעת מאפיינים | מספר הפריטים |
|---|---|---|---|---|
| Mercari Multimodal + Sparse embeddings | הטמעה מולטי-מודאלית | TF-IDF (שם הפריט והתיאור) |
1408 | כ-3 מיליון |
| Mercari Text (semantic similarity) + Sparse embeddings | text-embedding-005 (סוג המשימה: SEMANTIC_SIMILARITY) |
TF-IDF (שם הפריט והתיאור) |
768 | כ-3 מיליון |
| Mercari Text (question answering) + Sparse embeddings | text-embedding-005 (סוג המשימה: QUESTION_ANSWERING) |
TF-IDF (שם הפריט והתיאור) |
768 | כ-3 מיליון |
| GBIF Flowers Multimodal + Sparse embeddings | הטמעה מולטי-מודאלית | TF-IDF (שם הפריט והתיאור) |
1408 | ~3.3 מיליון |
| הטמעות מולטי-מודאליות של בעלי חיים מ-GBIF | הטמעה מולטי-מודאלית | לא רלוונטי | 1408 | כ-7 מיליון |
השלבים הבאים
אחרי שצפיתם בהדגמה, אתם מוכנים ללמוד לעומק איך להשתמש בחיפוש וקטורי.
מדריך למתחילים: שימוש במערך נתונים לדוגמה כדי ליצור ולפרוס אינדקס ב-30 דקות או פחות.
לפני שמתחילים: כדאי להבין מה צריך לעשות כדי להכין הטמעות ולקבוע את סוג נקודת הקצה שבה רוצים לפרוס את האינדקס.