
בדף הזה מוצגות דרכים לעיבוד נתונים טבלאיים באמצעות AutoML. כדי להבין את ההבדלים העיקריים בין AutoML לבין אימון מותאם אישית, אפשר לעיין במאמר בחירת שיטת אימון.
תרחישים לדוגמה לשימוש בנתונים טבלאיים
נניח שאתם עובדים במחלקת השיווק של קמעונאי דיגיטלי. אתם והצוות שלכם יוצרים תוכנית אימייל בהתאמה אישית שמבוססת על פרסונות של לקוחות. יצרתם את דמויות הקונים, והאימיילים השיווקיים מוכנים לשליחה. עכשיו אתם צריכים ליצור מערכת שמסווגת את הלקוחות לכל דמות קונה על סמך העדפות הקניות וההתנהגות שלהם בהוצאות, גם אם הם לקוחות חדשים. כדי למקסם את מעורבות הלקוח, כדאי גם לחזות את הרגלי ההוצאות שלהם כדי לבצע אופטימיזציה של מועדי שליחת האימיילים.
בתור קמעונאים דיגיטליים, יש לכם נתונים על הלקוחות ועל הרכישות שהם ביצעו. אבל מה לגבי לקוחות חדשים? בגישות מסורתיות אפשר לחשב את הערכים האלה עבור לקוחות קיימים עם היסטוריית רכישות ארוכה, אבל הגישות האלה לא מתאימות ללקוחות עם מעט נתונים היסטוריים. מה אם הייתם יכולים ליצור מערכת שתנבא את הערכים האלה ותגדיל את המהירות שבה אתם מציעים תוכניות שיווק בהתאמה אישית לכל הלקוחות שלכם?
למזלנו, למידת מכונה ו-Vertex AI יכולים לפתור את הבעיות האלה.
במדריך הזה מוסבר איך Vertex AI פועל במערכי נתונים ובמודלים של AutoML, ומוצגים סוגי הבעיות ש-Vertex AI נועד לפתור.
איך Vertex AI עובד?
Vertex AI משתמשת בלמידת מכונה מפוקחת כדי להשיג את התוצאה הרצויה. הפרטים הספציפיים של האלגוריתם ושיטות האימון משתנים בהתאם לסוג הנתונים ולתרחיש לדוגמה. הרבה קטגוריות משנה שונות של למידת מכונה פותרות בעיות שונות ועובדות במסגרת אילוצים שונים.
מאמנים מודל למידת מכונה עם נתונים לדוגמה. Vertex AI
משתמש בנתונים טבלאיים (מובְנים) כדי לאמן מודל של למידת מכונה, במטרה להסיק מסקנות לגבי נתונים חדשים. עמודה אחת ממערך הנתונים, שנקראת היעד, היא מה שהמודל ילמד לחזות. מספר מסוים של עמודות הנתונים האחרות
הן נתוני קלט (שנקראים תכונות) שהמודל ילמד מהם דפוסים. אתם יכולים להשתמש באותן תכונות קלט כדי ליצור כמה סוגים של מודלים, רק על ידי שינוי של עמודת היעד ואפשרויות ההדרכה. בדוגמה של שיווק באימייל, המשמעות היא שאפשר ליצור מודלים עם אותן תכונות קלט אבל עם מסקנות שונות לגבי היעד. מודל אחד יכול לחזות את פרסונת הלקוח (יעד קטגורי), מודל אחר יכול לחזות את ההוצאה החודשית שלו (יעד מספרי), ומודל נוסף יכול לחזות את הביקוש היומי למוצרים שלכם בשלושת החודשים הבאים (סדרה של יעדים מספריים).
תהליך העבודה ב-Vertex AI
ב-Vertex AI נעשה שימוש בתהליך עבודה סטנדרטי של למידת מכונה:
- איסוף הנתונים: קובעים אילו נתונים נדרשים לאימון ולבדיקה של המודל, בהתאם לתוצאה שרוצים להשיג.
- הכנת הנתונים: מוודאים שהפורמט של הנתונים תקין ושהם מסומנים בצורה נכונה.
- אימון: הגדרת פרמטרים ובניית המודל.
- הערכה: בודקים את מדדי המודל.
- פריסה וחיזוי: הפיכת המודל לזמין לשימוש.
לפני שמתחילים לאסוף את הנתונים, כדאי לחשוב על הבעיה שרוצים לפתור. ההגדרות האלה משפיעות על דרישות הנתונים.
תהליך הכנת נתונים
הערכת תרחיש השימוש
מתחילים עם הבעיה: מה התוצאה שרוצים להשיג?
איזה סוג נתונים יש בעמודת היעד? כמה נתונים יש לכם גישה אליהם? בהתאם לתשובות שלכם, Vertex AI יוצר את המודל הדרוש כדי לפתור את תרחיש השימוש שלכם:
- מודלים של סיווג בינארי חוזים תוצאה בינארית (אחת משתי קטגוריות). משתמשים בסוג המודל הזה לשאלות שהתשובה עליהן היא כן או לא. לדוגמה, יכול להיות שתרצו ליצור מודל סיווג בינארי כדי לחזות אם לקוח ירכוש מינוי. באופן כללי, בעיה של סיווג בינארי דורשת פחות נתונים מאשר סוגים אחרים של מודלים.
- מודלים של סיווג רב-מחלקתי חוזים מחלקה אחת מתוך שלוש מחלקות נפרדות או יותר. משתמשים בסוג המודל הזה לסיווג. לדוגמה, אם אתם קמעונאים, יכול להיות שתרצו לבנות מודל סיווג רב-מחלקתי כדי לפלח לקוחות לפי פרסונות שונות.
- מודלים של רגרסיה חוזים ערך רציף. לדוגמה, אם אתם קמעונאים, יכול להיות שתרצו ליצור מודל רגרסיה כדי לחזות כמה לקוח יוציא בחודש הבא.
- מודלים של חיזוי חוזים רצף של ערכים. לדוגמה, קמעונאים יכולים להשתמש בתחזיות כדי לחזות את הביקוש היומי למוצרים שלהם ב-3 החודשים הבאים, וכך להתכונן מראש ולדאוג למלאי מתאים.
חיזוי נתונים טבלאיים שונה מסיווג ומנסיגה בשני היבטים מרכזיים:
בסיווג וברגרסיה, הערך החזוי של היעד תלוי רק בערכים של עמודות התכונות באותה שורה. בתחזיות, הערכים החזויים תלויים גם בערכי ההקשר של היעד ושל התכונות.
בבעיות של רגרסיה וסיווג, הפלט הוא ערך אחד. בבעיות של תחזיות, הפלט הוא רצף של ערכים.
איסוף הנתונים
אחרי שמגדירים את תרחיש השימוש, אוספים את הנתונים שמאפשרים ליצור את המודל הרצוי.
 אחרי שמגדירים את תרחיש השימוש, צריך לאסוף נתונים כדי לאמן את המודל.
השגת נתונים והכנתם הם שלבים חשובים מאוד בבניית מודל של למידת מכונה.
סוג הבעיות שתוכלו לפתור תלוי בנתונים שזמינים לכם. כמה נתונים זמינים לך? האם הנתונים רלוונטיים לשאלות שאתם מנסים לענות עליהן? כשמלקטים את הנתונים, חשוב לזכור את הנקודות העיקריות הבאות.
אחרי שמגדירים את תרחיש השימוש, צריך לאסוף נתונים כדי לאמן את המודל.
השגת נתונים והכנתם הם שלבים חשובים מאוד בבניית מודל של למידת מכונה.
סוג הבעיות שתוכלו לפתור תלוי בנתונים שזמינים לכם. כמה נתונים זמינים לך? האם הנתונים רלוונטיים לשאלות שאתם מנסים לענות עליהן? כשמלקטים את הנתונים, חשוב לזכור את הנקודות העיקריות הבאות.
בחירת ישויות רלוונטיות
תכונה היא מאפיין קלט שמשמש לאימון המודל. התכונות הן האופן שבו המודל מזהה דפוסים כדי להסיק מסקנות, ולכן הן צריכות להיות רלוונטיות לבעיה. לדוגמה, כדי ליצור מודל שמנבא אם עסקה בכרטיס אשראי היא שמקורו בתרמית או לא, צריך ליצור מערך נתונים שמכיל פרטי עסקה כמו הקונים, בית העסק, הסכום, התאריך והשעה והפריטים שנרכשו. תכונות מועילות אחרות יכולות להיות מידע היסטורי על הקונה והמוכר, ועל התדירות שבה הפריט שנרכש היה מעורב בהונאה. אילו תכונות נוספות עשויות להיות רלוונטיות?
נחזור לתרחיש לדוגמה מהמבוא בנושא שיווק באימייל בענף הקמעונאות. ריכזנו כמה עמודות של מאפיינים שאולי תצטרכו:
- רשימת פריטים שנרכשו (כולל מותגים, קטגוריות, מחירים והנחות)
- מספר הפריטים שנרכשו (ביום האחרון, בשבוע האחרון, בחודש האחרון, בשנה האחרונה)
- סכום הכסף שהוצא (ביום האחרון, בשבוע האחרון, בחודש האחרון, בשנה האחרונה)
- לכל פריט, המספר הכולל שנמכר בכל יום
- לכל פריט, סך המלאי בכל יום
- אם אתם מריצים מבצע ליום מסוים
- פרופיל דמוגרפי ידוע של הקונה
הכללת מספיק נתונים
 באופן כללי, ככל שיש לכם יותר דוגמאות לאימון, כך התוצאה טובה יותר. כמות נתוני הדוגמה הנדרשת משתנה בהתאם למורכבות הבעיה שאתם מנסים לפתור. לא תצטרכו כמות גדולה של נתונים כדי לקבל מודל סיווג בינארי מדויק, בהשוואה למודל רב-סיווגי, כי קל יותר לחזות סיווג אחד מתוך שניים מאשר מתוך הרבה.
באופן כללי, ככל שיש לכם יותר דוגמאות לאימון, כך התוצאה טובה יותר. כמות נתוני הדוגמה הנדרשת משתנה בהתאם למורכבות הבעיה שאתם מנסים לפתור. לא תצטרכו כמות גדולה של נתונים כדי לקבל מודל סיווג בינארי מדויק, בהשוואה למודל רב-סיווגי, כי קל יותר לחזות סיווג אחד מתוך שניים מאשר מתוך הרבה.
אין נוסחה מושלמת, אבל יש מינימום מומלץ של נתוני דוגמה:
- בעיית סיווג: 50 שורות כפול מספר התכונות
- בעיה בתחזיות:
- 5,000 שורות כפול מספר התכונות
- 10 ערכים ייחודיים בעמודת המזהה של סדרת הזמן כפול מספר התכונות
- בעיית רגרסיה: 200 כפול מספר התכונות
תיעוד הווריאציה
מערך הנתונים צריך לשקף את המגוון של תחום הבעיה. ככל שהמודל נחשף ליותר דוגמאות מגוונות במהלך האימון, כך הוא יכול להכליל בקלות רבה יותר דוגמאות חדשות או פחות נפוצות. תארו לעצמכם שמודל קמעונאי אומן רק באמצעות נתוני רכישה מהחורף. האם המודל יוכל לחזות בהצלחה את ההעדפות או את התנהגויות הרכישה של בגדי קיץ?
הכנת הנתונים
 אחרי שמזהים את הנתונים הזמינים, צריך לוודא שהם מוכנים לאימון.
אם הנתונים מוטים או מכילים ערכים חסרים או שגויים, זה משפיע על איכות המודל. לפני שמתחילים לאמן את המודל, כדאי לשקול את הנקודות הבאות.
מידע נוסף
אחרי שמזהים את הנתונים הזמינים, צריך לוודא שהם מוכנים לאימון.
אם הנתונים מוטים או מכילים ערכים חסרים או שגויים, זה משפיע על איכות המודל. לפני שמתחילים לאמן את המודל, כדאי לשקול את הנקודות הבאות.
מידע נוסף
מניעת דליפת נתונים ו-training-serving skew
זליגת נתונים מתרחשת כשמשתמשים בתכונות קלט במהלך האימון ש "מזליגות" מידע על היעד שמנסים לחזות, שלא זמין כשהמודל מופעל בפועל. אפשר לזהות את זה כשכוללים כמאפיין קלט מאפיין שיש לו קורלציה גבוהה עם עמודת היעד. לדוגמה, אם אתם בונים מודל לחיזוי אם לקוח יירשם למינוי בחודש הבא, ואחד ממאפייני הקלט הוא תשלום עתידי על מינוי מאותו לקוח. הדבר עלול להוביל לביצועים טובים של המודל במהלך הבדיקות, אבל לא כשהוא מופעל בסביבת ייצור, כי פרטי התשלום של המינוי העתידי לא זמינים בזמן הצגת המודל.
הטיה בין אימון להצגה היא מצב שבו תכונות הקלט שמשמשות בזמן האימון שונות מאלה שמועברות למודל בזמן ההצגה, וכתוצאה מכך איכות המודל בסביבת הייצור נמוכה. לדוגמה, בניית מודל לחיזוי טמפרטורות לפי שעה, אבל אימון המודל עם נתונים שמכילים רק טמפרטורות שבועיות. דוגמה נוספת: תמיד מספקים את הציונים של התלמיד בנתוני האימון כשמנסים לחזות נשירה של תלמידים, אבל לא מספקים את המידע הזה בזמן ההצגה.
חשוב להבין את נתוני האימון כדי למנוע דליפת נתונים ו-training-serving skew:
- לפני שמשתמשים בנתונים, חשוב להבין מה המשמעות שלהם ולקבוע אם כדאי להשתמש בהם כמאפיין
- בודקים את המתאם בכרטיסייה Train (אימון). צריך לסמן מתאמים גבוהים לבדיקה.
- הטיה בין אימון להצגה: מוודאים שאתם מספקים למודל רק תכונות קלט שזמינות בדיוק באותו פורמט בזמן ההצגה.
ניקוי נתונים חסרים, חלקיים ולא עקביים
בנתונים לדוגמה, בדרך כלל יש ערכים חסרים ולא מדויקים. לפני שמשתמשים בנתונים לאימון, כדאי להקדיש זמן לבדיקה ולשיפור איכות הנתונים, אם אפשר. ככל שיש יותר ערכים חסרים, כך הנתונים פחות שימושיים לאימון של מודל למידת מכונה.
- בודקים אם חסרים ערכים בנתונים ומתקנים אותם אם אפשר, או משאירים את הערך ריק אם העמודה מוגדרת כעמודה שיכולה להכיל ערך null. Vertex AI יכול לטפל בערכים חסרים, אבל סביר יותר שתקבלו תוצאות אופטימליות אם כל הערכים יהיו זמינים.
- לצורך חיזוי, צריך לוודא שהמרווח בין שורות האימון עקבי. Vertex AI יכול להשלים ערכים חסרים, אבל סביר יותר שתקבלו תוצאות אופטימליות אם כל השורות יהיו זמינות.
- מנקים את הנתונים על ידי תיקון או מחיקה של שגיאות או רעשי רקע בנתונים. מוודאים שהנתונים עקביים: בודקים את האיות, הקיצורים והפורמט.
ניתוח הנתונים אחרי הייבוא
אחרי הייבוא של מערך הנתונים, תוכלו לראות סקירה כללית שלו ב-Vertex AI. בודקים את קבוצת הנתונים המיובאת כדי לוודא שלכל עמודה הוגדר סוג המשתנה הנכון. Vertex AI יזהה באופן אוטומטי את סוג המשתנה על סמך הערכים בעמודות, אבל מומלץ לבדוק כל אחד מהם. כדאי גם לבדוק את מאפיין המציין אם ערך יכול להיות ריק (nullability) של כל עמודה, שקובעת אם בעמודה יכולים להיות ערכים חסרים או ערכי null.
דגם הרכבת
אחרי שמייבאים את מערך הנתונים, השלב הבא הוא לאמן מודל. Vertex AI ייצור מודל מהימן של למידת מכונה עם הגדרות ברירת המחדל של האימון, אבל יכול להיות שתרצו לשנות חלק מהפרמטרים בהתאם לתרחיש השימוש שלכם.
כדאי לבחור כמה שיותר עמודות של תכונות לאימון, אבל חשוב לבדוק כל אחת מהן כדי לוודא שהיא מתאימה לאימון. חשוב לזכור את הנקודות הבאות כשבוחרים תכונות:
- לא כדאי לבחור עמודות של תכונות שייצרו רעשי רקע, כמו עמודות של מזהים שהוקצו באופן אקראי עם ערך ייחודי לכל שורה.
- חשוב להבין את כל עמודה של מאפיין ואת הערכים שלה.
- אם יוצרים כמה מודלים ממערך נתונים אחד, צריך להסיר עמודות יעד שלא קשורות לבעיית ההסקה הנוכחית.
- נזכיר את עקרונות ההוגנות: האם אתם מאמנים את המודל באמצעות תכונה שעלולה להוביל לקבלת החלטות מוטה או לא הוגנת לגבי קבוצות מוחלשות?
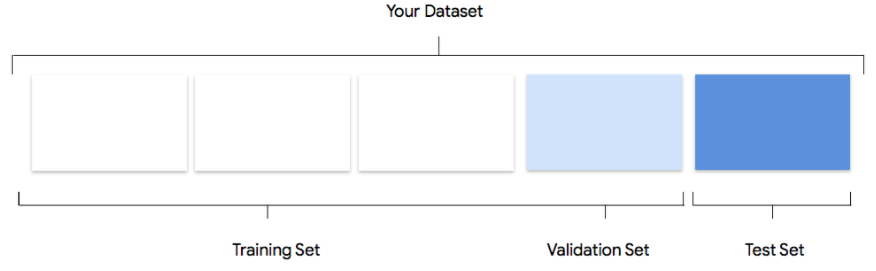
איך Vertex AI משתמש במערך הנתונים שלכם
מערך הנתונים יפוצל למערכי אימון, אימות ובדיקה. הפיצול שמוגדר כברירת מחדל ב-Vertex AI תלוי בסוג המודל שאתם מאמנים. אפשר גם לציין את הפיצולים (פיצולים ידניים) אם יש צורך. מידע נוסף זמין במאמר מידע על פיצול נתונים במודלים של AutoML.
קבוצת נתונים לאימון
 רוב הנתונים צריכים להיות בקבוצת נתונים לאימון. אלה הנתונים שהמודל 'רואה' במהלך האימון: הם משמשים ללימוד הפרמטרים של המודל, כלומר המשקלים של הקשרים בין הצמתים של הרשת הנוירונית.
רוב הנתונים צריכים להיות בקבוצת נתונים לאימון. אלה הנתונים שהמודל 'רואה' במהלך האימון: הם משמשים ללימוד הפרמטרים של המודל, כלומר המשקלים של הקשרים בין הצמתים של הרשת הנוירונית.
קבוצת נתונים לתיקוף
 קבוצת הנתונים לתיקוף, שנקראת לפעמים גם קבוצת הפיתוח, משמשת גם במהלך תהליך האימון.
אחרי שמסגרת הלמידה של המודל משלבת נתוני אימון במהלך כל איטרציה של תהליך האימון, היא משתמשת בביצועים של המודל בקבוצת נתונים לתיקוף כדי לכוונן את ההיפרפרמטרים של המודל, שהם משתנים שמציינים את המבנה של המודל. אם ניסיתם להשתמש בקבוצת הנתונים לאימון כדי לכוונן את ההיפר-פרמטרים, סביר מאוד שהמודל יתמקד יתר על המידה בנתוני האימון שלכם, ויתקשה להכליל דוגמאות שלא תואמות לו בדיוק.
שימוש במערך נתונים חדש יחסית כדי לשפר ולחדד את מבנה המודל, יאפשר למודל להכליל טוב יותר.
קבוצת הנתונים לתיקוף, שנקראת לפעמים גם קבוצת הפיתוח, משמשת גם במהלך תהליך האימון.
אחרי שמסגרת הלמידה של המודל משלבת נתוני אימון במהלך כל איטרציה של תהליך האימון, היא משתמשת בביצועים של המודל בקבוצת נתונים לתיקוף כדי לכוונן את ההיפרפרמטרים של המודל, שהם משתנים שמציינים את המבנה של המודל. אם ניסיתם להשתמש בקבוצת הנתונים לאימון כדי לכוונן את ההיפר-פרמטרים, סביר מאוד שהמודל יתמקד יתר על המידה בנתוני האימון שלכם, ויתקשה להכליל דוגמאות שלא תואמות לו בדיוק.
שימוש במערך נתונים חדש יחסית כדי לשפר ולחדד את מבנה המודל, יאפשר למודל להכליל טוב יותר.
קבוצת נתונים לבדיקה
 קבוצת הנתונים לבדיקה לא מעורבת בתהליך האימון בכלל. אחרי שמודל סיים את האימון שלו, מערכת Vertex AI משתמשת בקבוצת הנתונים לבדיקה כאתגר חדש לגמרי עבור המודל.
הביצועים של המודל שלכם בקבוצת נתונים לבדיקה אמורים לתת לכם מושג טוב לגבי הביצועים של המודל שלכם בנתונים מהעולם האמיתי.
קבוצת הנתונים לבדיקה לא מעורבת בתהליך האימון בכלל. אחרי שמודל סיים את האימון שלו, מערכת Vertex AI משתמשת בקבוצת הנתונים לבדיקה כאתגר חדש לגמרי עבור המודל.
הביצועים של המודל שלכם בקבוצת נתונים לבדיקה אמורים לתת לכם מושג טוב לגבי הביצועים של המודל שלכם בנתונים מהעולם האמיתי.
הערכה, בדיקה ופריסה של המודל
הערכת המודל
 אחרי אימון המודל, תקבלו סיכום של הביצועים שלו. מדדי הערכת המודל מבוססים על הביצועים של המודל בהשוואה לפלח של מערך הנתונים (מערך הנתונים של הבדיקה). יש כמה מדדים ומושגים חשובים שכדאי להביא בחשבון כשקובעים אם המודל מוכן לשימוש עם נתונים אמיתיים.
אחרי אימון המודל, תקבלו סיכום של הביצועים שלו. מדדי הערכת המודל מבוססים על הביצועים של המודל בהשוואה לפלח של מערך הנתונים (מערך הנתונים של הבדיקה). יש כמה מדדים ומושגים חשובים שכדאי להביא בחשבון כשקובעים אם המודל מוכן לשימוש עם נתונים אמיתיים.
מדדי סיווג
סף הציון
נניח שיש מודל למידת מכונה שמנבא אם לקוח יקנה מעיל בשנה הבאה. מה רמת הוודאות שנדרשת מהמודל כדי לחזות שלקוח מסוים יקנה מעיל? במודלים של סיווג, לכל מסקנה מוקצה ציון מהימנות – הערכה מספרית של מידת הוודאות של המודל לגבי נכונות הסיווג שחזה. סף הניקוד הוא המספר שקובע מתי ניקוד מסוים מומר להחלטה חיובית או שלילית. כלומר, זהו הערך שבו המודל אומר "כן, רמת הביטחון הזו גבוהה מספיק כדי להסיק שהלקוח הזה ירכוש מעיל בשנה הקרובה".
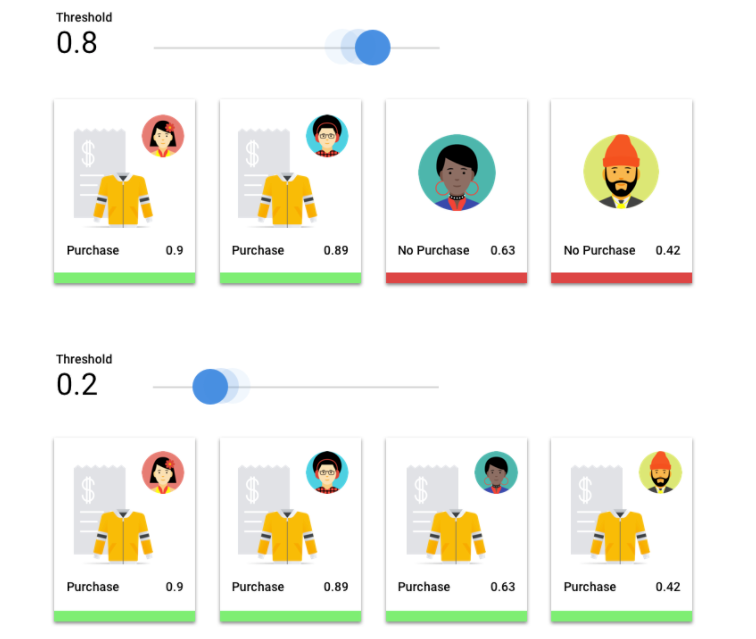
אם ערך הסף של הציון נמוך, קיים סיכון שהמודל יבצע סיווג שגוי. לכן, ערך הסף של הניקוד צריך להתבסס על תרחיש שימוש נתון.
תוצאות של הסקה
אחרי שמחילים את ערך הסף של הניקוד, ההסקות שהמודל מבצע ישתייכו לאחת מארבע קטגוריות. כדי להבין את הקטגוריות האלה, נחזור לדוגמה של מודל סיווג בינארי של מעילים. בדוגמה הזו, הסיווג החיובי (מה שהמודל מנסה לחזות) הוא שהלקוח ירכוש מעיל בשנה הקרובה.
- חיובי אמיתי: המודל חוזה נכון את המחלקה החיובית. המודל חזה בצורה נכונה שלקוח רכש מעיל.
- תוצאה חיובית שגויה: המודל חוזה באופן שגוי את המחלקה החיובית. המודל חזה שלקוח רכש מעיל, אבל הוא לא רכש.
- שלילי אמיתי: המודל חוזה נכון את המחלקה השלילית. המודל חזה בצורה נכונה שלקוח לא רכש מעיל.
- שלילי שגוי: המודל חוזה באופן שגוי מחלקה שלילית. המודל חזה שלקוח לא רכש מעיל, אבל הוא כן רכש.

דיוק וזיכרון
מדדי הדיוק וההחזרה עוזרים להבין באיזו מידה המודל מצליח ללכוד מידע ומה הוא משמיט. מידע נוסף על דיוק ועל היקף החיפוש
- דיוק הוא החלק היחסי של ההסקות החיוביות שהיו נכונות. מתוך כל ההסקות לגבי רכישה של לקוח, איזה חלק היו רכישות בפועל?
- היזכרות היא החלק היחסי של השורות עם התווית הזו שהמודל חזה בצורה נכונה. מתוך כל הרכישות של הלקוחות שאפשר היה לזהות, כמה אחוזים זוהו?
בהתאם לתרחיש השימוש, יכול להיות שתצטרכו לבצע אופטימיזציה לדיוק או לריקול.
מדדים אחרים של סיווג
- AUC PR: השטח מתחת לעקומת הדיוק וההחזרה (PR). הערך הזה נע בין אפס לאחד, כאשר ערך גבוה יותר מציין מודל באיכות גבוהה יותר.
- AUC ROC: השטח מתחת לעקומת מאפייני ההפעלה של המקלט (ROC). הערך נע בין אפס לאחד, וככל שהערך גבוה יותר, המודל איכותי יותר.
- דיוק: החלק היחסי של מסקנות הסיווג שהופקו על ידי המודל שהיו נכונות.
- הפסד לוגריתמי: האנטרופיה הצולבת בין ההסקות של המודל לבין ערכי היעד. הטווח נע בין אפס לאינסוף, כאשר ערך נמוך יותר מציין מודל באיכות גבוהה יותר.
- ציון F1: הממוצע ההרמוני של הדיוק וההחזרה. המדד F1 שימושי אם אתם מחפשים איזון בין דיוק לבין היזכרות, ויש התפלגות לא אחידה של מחלקות.
מדדים של תחזיות ורגרסיות
אחרי בניית המודל, Vertex AI מספק מגוון של מדדים סטנדרטיים לבדיקה. אין תשובה מושלמת לשאלה איך להעריך את המודל. כדאי להשתמש במדדי הערכה בהקשר של סוג הבעיה ושל המטרה שלכם. ברשימה הבאה מפורטים כמה מדדים ש-Vertex AI יכול לספק.
שגיאה ממוצעת מוחלטת (MAE)
MAE הוא ההפרש המוחלט הממוצע בין ערכי היעד לבין הערכים החזויים. המדד הזה מודד את הגודל הממוצע של השגיאות – ההפרש בין ערך יעד לבין ערך חזוי – בקבוצה של מסקנות. בנוסף, מכיוון שהיא משתמשת בערכים מוחלטים, MAE לא מתייחסת לכיוון הקשר ולא מציינת ביצועים נמוכים או גבוהים מדי. כשמעריכים את MAE, ערך קטן יותר מצביע על מודל באיכות גבוהה יותר (0 מייצג מודל חיזוי מושלם).
שורש טעות ריבועית ממוצעת (RMSE)
ה-RMSE הוא השורש הריבועי של ההפרש הממוצע בריבוע בין ערכי היעד לבין הערכים החזויים. המדד RMSE רגיש יותר לערכים חריגים מהמדד MAE, ולכן אם אתם חוששים משגיאות גדולות, כדאי להשתמש במדד RMSE כדי להעריך את השגיאות. בדומה ל-MAE, ערך קטן יותר מציין מודל באיכות גבוהה יותר (0 מייצג מודל חיזוי מושלם).
שורש טעות ריבועית ממוצעת לוגריתמית (RMSLE)
RMSLE הוא RMSE בקנה מידה לוגריתמי. המדד RMSLE רגיש יותר לשגיאות יחסיות מאשר לשגיאות מוחלטות, וחשוב לו יותר שהביצועים לא יהיו נמוכים מדי מאשר שהם לא יהיו גבוהים מדי.
קוונטיל שנצפה (חיזוי בלבד)
עבור קוונטיל יעד נתון, הקוונטיל שנצפה מציג את השבר בפועל של הערכים שנצפו מתחת לערכי ההסקה של הקוונטיל שצוין. הערך observed quantile מראה עד כמה המודל קרוב או רחוק מהקוונטיל של היעד. הבדל קטן יותר בין שני הערכים מצביע על מודל באיכות גבוהה יותר.
הפסד פינבול משוקלל (לחיזוי בלבד)
מדד לאיכות המודל בקוונטיל יעד נתון. מספר נמוך יותר מציין מודל באיכות גבוהה יותר. אפשר להשוות את מדד הפסד הפינבול המותאם באחוזונים שונים כדי לקבוע את הדיוק היחסי של המודל בין האחוזונים השונים האלה.
בדיקת המודל
הדרך העיקרית לקבוע אם המודל מוכן לפריסה היא להעריך את מדדי המודל, אבל אפשר גם לבדוק אותו באמצעות נתונים חדשים. כדאי להעלות נתונים חדשים כדי לבדוק אם ההסקות של המודל תואמות לציפיות שלכם. על סמך מדדי ההערכה או הבדיקה עם נתונים חדשים, יכול להיות שתצטרכו להמשיך לשפר את הביצועים של המודל.
פריסת המודל
כשמרוצים מהביצועים של המודל, אפשר להשתמש בו. יכול להיות שהמשמעות היא שימוש בהיקף ייצור, או שאולי מדובר בבקשת הסקה חד-פעמית. בהתאם לתרחיש לדוגמה שלכם, תוכלו להשתמש במודל בדרכים שונות.
הסקת מסקנות באצווה
הסקת מסקנות באצווה שימושית כשרוצים לשלוח הרבה בקשות להסקת מסקנות בבת אחת. הסקת מסקנות באצווה היא אסינכרונית, כלומר המודל ימתין עד שיעבד את כל בקשות הסקת המסקנות לפני שיחזיר קובץ CSV או טבלת BigQuery עם ערכי הסקת המסקנות.
הסקת מסקנות אונליין
פורסים את המודל כדי שיהיה זמין לבקשות היקש באמצעות API בארכיטקטורת REST. הסקת מסקנות אונליין היא סינכרונית (בזמן אמת), כלומר היא תחזיר במהירות מסקנה, אבל היא מקבלת רק בקשת מסקנה אחת לכל קריאה ל-API. הסקת מסקנות אונליין שימושית אם המודל שלכם הוא חלק מאפליקציה וחלקים מהמערכת שלכם תלויים בהסקת מסקנות מהירה.
הסרת המשאבים
כדי להימנע מחיובים לא רצויים, מומלץ לבטל את הפריסה של המודל כשלא משתמשים בו.
אחרי שמסיימים להשתמש במודל, מומלץ למחוק את המשאבים שיצרתם כדי להימנע מחיובים לא רצויים בחשבון.