

本節說明 Gemini Enterprise Agent Platform 服務,協助您透過機器學習 (ML) 工作流程實作機器學習運作 (MLOps)。
模型部署完成後,必須跟上環境中不斷變化的資料,才能發揮最佳效能並與時俱進。MLOps 是一組實務做法,可提升機器學習系統的穩定性和可靠性。
Gemini Enterprise Agent Platform MLOps 工具可協助 AI 團隊協作,並透過預測模型監控、快訊、診斷和可執行的說明,改善模型。所有工具都是模組化設計,因此您可以視需要整合到現有系統中。
如要進一步瞭解 MLOps,請參閱機器學習的持續推送軟體更新與自動化管線,以及機器學習運作從業人員指南。
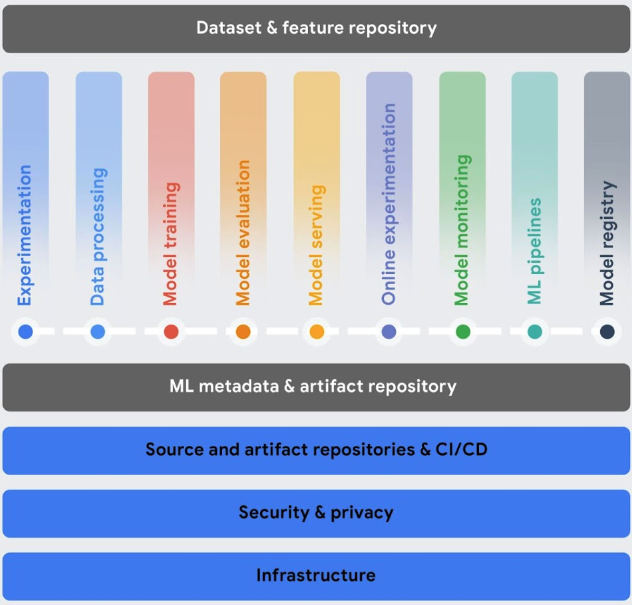
協調工作流程:手動訓練及提供模型服務可能相當耗時且容易出錯,尤其在您需要多次重複執行這些程序時更是如此。
- Gemini Enterprise 代理平台 Pipelines 可協助您自動執行、監控及管理機器學習工作流程。
管理及擴充訓練作業:有效管理訓練的運算資源是 MLOps 的核心挑戰,尤其是從實驗擴充到正式環境時。Vertex AI 訓練 提供彈性且全代管的服務,以及適合整個機器學習生命週期的運算選項,可解決上述問題。
如要進行實驗和處理變數工作負載,自訂訓練會使用預設的無伺服器平台,視需求佈建資源,提供最大的彈性。
對於大規模、可預測的工作負載,Gemini Enterprise Agent Platform 訓練叢集的預留叢集可提供持續的專屬環境,確保資源可用性、提供穩定效能,並協助高使用率團隊最佳化成本。
追蹤機器學習系統中使用的中繼資料:在資料科學中,追蹤機器學習工作流程中使用的參數、構件和指標非常重要,尤其是在重複執行工作流程多次時。
- Vertex ML Metadata可讓您記錄機器學習系統中使用的中繼資料、參數和構件。然後查詢該中繼資料,以利分析、偵錯及稽核 ML 系統或其產生的構件效能。
找出最適合特定用途的模型:嘗試新的訓練演算法時,您需要知道哪個訓練模型的效果最好。
Vertex AI Experiments 可讓您追蹤及分析不同的模型架構、超參數和訓練環境,找出最適合您用途的模型。
Vertex AI TensorBoard 可協助您追蹤、比較及以視覺化方式呈現機器學習實驗,藉此評估模型成效。
管理模型版本:將模型新增至中央存放區,有助於追蹤模型版本。
- Gemini Enterprise Agent Platform Model Registry 會顯示模型總覽,方便您更妥善地整理、追蹤及訓練新版本。在 Model Registry 中,您可以評估模型、將模型部署至端點、建立批次推論,以及查看特定模型和模型版本的詳細資料。
管理特徵:在多個團隊重複使用機器學習特徵時,您需要快速有效率地分享及提供特徵。
- Vertex AI 特徵儲存庫是可供整理、儲存和提供機器學習特徵的集中存放區。使用中央特徵儲存庫,機構就能大規模重複使用機器學習特徵,並加快開發及部署新機器學習應用程式的速度。
監控模型品質:在正式環境中部署模型時,模型的推論輸入資料最好與訓練資料相似,才能發揮最佳成效。如果輸入資料與模型訓練資料不同,就算模型本身沒有變動,效能也可能會降低。
- Gemini Enterprise Agent Platform Model Monitoring 會監控模型,偵測訓練/應用偏差和推論偏移,並在傳入的推論資料與訓練基準的偏差過大時傳送快訊。您可以根據快訊和特徵分布情形,評估是否需要重新訓練模型。
擴充 AI 和 Python 應用程式:Ray 是開放原始碼架構,可擴充 AI 和 Python 應用程式。Ray 提供基礎架構,可為機器學習 (ML) 工作流程執行分散式運算和平行處理。
- Ray on Agent Platform 的設計宗旨是讓您使用相同的開放原始碼 Ray 程式碼,在 Gemini Enterprise Agent Platform 上編寫程式及開發應用程式,且只需進行少量變更。然後,您可以使用 Gemini Enterprise Agent Platform 與其他 Google Cloud 服務 (例如 Vertex AI Inference 和 BigQuery) 的整合功能,做為機器學習 (ML) 工作流程的一部分。