
このドキュメントでは、さまざまなニーズに合わせて Vertex AI に Ray クラスタを設定する手順について説明します。たとえば、イメージをビルドするには、カスタム イメージをご覧ください。一部の企業では、プライベート ネットワーキングを使用しています。このドキュメントでは、Ray on Vertex AI の Private Service Connect インターフェースについても説明します。別のユースケースとして、リモート ファイルをローカル ファイルのようにアクセスする方法があります(Ray on Vertex AI ネットワーク ファイル システムをご覧ください)。
概要
ここでは、次のトピックについて説明します。
- Vertex AI に Ray クラスタを作成する
- Ray クラスタのライフサイクルを管理する
- カスタム イメージを作成する
- プライベート接続とパブリック接続(VPC)を設定する
- Ray on Vertex AI に Private Service Connect インターフェースを使用する
- Ray on Vertex AI ネットワーク ファイル システム(NFS)を設定する
- VPC-SC と VPC ピアリングを使用して Ray ダッシュボードとインタラクティブ シェルを設定する
Ray クラスタを作成する
Ray クラスタを作成するには、 Google Cloud コンソールまたは Vertex AI SDK for Python を使用します。クラスタには最大 2,000 個のノードを配置できます。1 つのワーカープール内のノード数の上限は 1,000 です。ワーカープールの数に上限はありませんが、1 ノードあたり 1,000 ワーカープールのように、ワーカープールの数が多くなると、クラスタのパフォーマンスに影響する可能性があります。
始める前に、Ray on Vertex AI の概要を読み、前提条件となるすべてのツールを設定してください。
Vertex AI の Ray クラスタを作成してから起動するまでに 10~20 分ほどかかる場合があります。
コンソール
OSS Ray のベスト プラクティスの推奨事項に従い、ヘッドノードでワークロードを実行しないように、Ray ヘッドノードで論理 CPU 数を 0 に設定します。
Google Cloud コンソールで、[Vertex AI での Ray] ページに移動します。
[クラスタを作成] をクリックして [クラスタの作成] パネルを開きます。
[クラスタの作成] パネルの各ステップで、デフォルトのクラスタ情報を確認または置き換えます。[続行] をクリックして、各手順を完了します。
[名前とリージョン] で名前を指定し、クラスタのリージョンを選択します。
[コンピューティング設定] で、マシンタイプ、アクセラレータ タイプと数、ディスクタイプとサイズ、レプリカ数など、Vertex AI のヘッドノードの Ray クラスタの構成を指定します。必要に応じて、カスタム イメージ URI を追加してカスタム コンテナ イメージを指定し、デフォルトのコンテナ イメージでは提供されていない Python の依存関係を追加します。カスタム イメージをご覧ください。
[詳細オプション] で、次の操作を行います。
- 独自の暗号鍵を指定します。
- カスタム サービス アカウントを指定します。
- トレーニング中にワークロードのリソース統計情報をモニタリングする必要がない場合は、指標の収集を無効にします。
(省略可)クラスタのプライベート エンドポイントをデプロイする場合は、Private Service Connect を使用する方法をおすすめします。詳細については、Ray on Vertex AI 用の Private Service Connect インターフェースをご覧ください。
[作成] をクリックします。
Ray on Vertex AI SDK
OSS Ray のベスト プラクティスの推奨事項に従い、ヘッドノードでワークロードを実行しないように、Ray ヘッドノードで論理 CPU 数を 0 に設定します。
インタラクティブな Python 環境から、次のコマンドを使用して Vertex AI に Ray クラスタを作成します。
import ray import vertex_ray from google.cloud import aiplatform from vertex_ray import Resources from vertex_ray.util.resources import NfsMount # Define a default CPU cluster, machine_type is n1-standard-16, 1 head node and 1 worker node head_node_type = Resources() worker_node_types = [Resources()] # Or define a GPU cluster. head_node_type = Resources( machine_type="n1-standard-16", node_count=1, custom_image="us-docker.pkg.dev/my-project/ray-custom.2-9.py310:latest", # Optional. When not specified, a prebuilt image is used. ) worker_node_types = [Resources( machine_type="n1-standard-16", node_count=2, # Must be >= 1 accelerator_type="NVIDIA_TESLA_T4", accelerator_count=1, custom_image="us-docker.pkg.dev/my-project/ray-custom.2-9.py310:latest", # When not specified, a prebuilt image is used. )] # Optional. Create cluster with Network File System (NFS) setup. nfs_mount = NfsMount( server="10.10.10.10", path="nfs_path", mount_point="nfs_mount_point", ) aiplatform.init() # Initialize Vertex AI to retrieve projects for downstream operations. # Create the Ray cluster on Vertex AI CLUSTER_RESOURCE_NAME = vertex_ray.create_ray_cluster( head_node_type=head_node_type, network=NETWORK, #Optional worker_node_types=worker_node_types, python_version="3.10", # Optional ray_version="2.47", # Optional cluster_name=CLUSTER_NAME, # Optional service_account=SERVICE_ACCOUNT, # Optional enable_metrics_collection=True, # Optional. Enable metrics collection for monitoring. labels=LABELS, # Optional. nfs_mounts=[nfs_mount], # Optional. )
ここで
CLUSTER_NAME: Vertex AI の Ray クラスタの名前。プロジェクト全体で一意にする必要があります。
NETWORK:(省略可)VPC ネットワークの完全な名前(
projects/PROJECT_ID/global/networks/VPC_NAME形式)。クラスタのパブリック エンドポイントではなくプライベート エンドポイントを設定するには、Ray on Vertex AI で使用する VPC ネットワークを指定します。詳細については、プライベート接続とパブリック接続をご覧ください。VPC_NAME: 省略可。VM が動作する VPC。
PROJECT_ID: 実際の Google Cloud プロジェクト ID。プロジェクト ID は、 Google Cloud コンソールの [ようこそ] ページで確認できます。
SERVICE_ACCOUNT: 省略可。クラスタで Ray アプリケーションを実行するサービス アカウント。必要なロールを付与します。
LABELS: 省略可。Ray クラスタの編成に使用されるユーザー定義のメタデータを含むラベル。ラベルのキーと値は 64 文字(Unicode コードポイント)以下にする必要があります。使用できるのは小文字、数字、アンダースコア、ダッシュのみです。国際文字も使用できます。ラベルの詳細と例については https://goo.gl/xmQnxf をご覧ください。
ステータスが RUNNING に変わるまで、次の出力が表示されます。
[Ray on Vertex AI]: Cluster State = State.PROVISIONING Waiting for cluster provisioning; attempt 1; sleeping for 0:02:30 seconds ... [Ray on Vertex AI]: Cluster State = State.RUNNING
次の点にご注意ください。
最初のノードはヘッドノードです。
TPU マシンタイプはサポートされていません。
ライフサイクル管理
Vertex AI の Ray クラスタのライフサイクルでは、各アクションが状態に関連付けられます。次の表に、各状態の課金ステータスと管理オプションの概要を示します。各状態の定義については、リファレンス ドキュメントをご覧ください。
| アクション | 状態 | 課金対象か | 削除アクションは可能か | キャンセル アクションは可能か |
|---|---|---|---|---|
| ユーザーがクラスタを作成 | PROVISIONING | いいえ | いいえ | いいえ |
| ユーザーが手動でスケールアップまたはスケールダウン | UPDATING | はい、リアルタイムのサイズに基づきます | はい | いいえ |
| クラスタが実行される | RUNNING | はい | はい | 該当なし。削除可能 |
| クラスタが自動的にスケールアップまたはスケールダウン | UPDATING | はい、リアルタイムのサイズに基づきます | はい | いいえ |
| ユーザーがクラスタを削除 | STOPPING | いいえ | いいえ | 該当なし。すでに停止 |
| クラスタがエラー状態になる | エラー | いいえ | はい | 該当なし。削除可能です |
| 該当なし | STATE_UNSPECIFIED | いいえ | はい | 該当なし |
カスタム イメージ(省略可)
ビルド済みイメージは、ほとんどのユースケースに対応しています。イメージをビルドする場合は、Ray on Vertex AI のビルド済みイメージをベースイメージとして使用します。ベースイメージからイメージを作成する方法については、Docker のドキュメントをご覧ください。
これらのベースイメージには、Python、Ubuntu、Ray のインストールが含まれています。また、次のような依存関係も含まれます。
- python-json-logger
- google-cloud-resource-manager
- ca-certificates-java
- libatlas-base-dev
- liblapack-dev
- g++、libio-all-perl
- libyaml-0-2.
プライベート接続とパブリック接続
デフォルトでは、Ray on Vertex AI は、Vertex AI の Ray クラスタで Ray クライアントを使用してインタラクティブな開発を行うための、安全なパブリック エンドポイントを作成します。開発や一時的なユースケースには、パブリック接続を使用します。このパブリック エンドポイントには、インターネット経由でアクセスできます。クラスタにアクセスできるのは、Ray クラスタのユーザー プロジェクトに対する Vertex AI ユーザーロール権限が付与されている承認済みユーザーのみです。
クラスタへのプライベート接続が必要な場合や、VPC Service Controls を使用している場合は、Vertex AI の Ray クラスタで VPC ピアリングがサポートされています。プライベート エンドポイントを使用するクラスタには、Vertex AI とピアリングされている VPC ネットワーク内のクライアントからのみアクセスできます。
Ray on Vertex AI の VPC ピアリングを使用してプライベート接続を設定するには、クラスタの作成時に VPC ネットワークを選択します。VPC ネットワークには、VPC ネットワークと Vertex AI の間に限定公開サービス接続が必要です。コンソールで Ray on Vertex AI を使用する場合は、クラスタを作成するときにプライベート サービス アクセス接続を設定できます。
Vertex AI の Ray クラスタで VPC Service Controls と VPC ピアリングを使用する場合は、Ray ダッシュボードとインタラクティブ シェルを使用するために追加の設定が必要になります。VPC-SC と VPC ピアリングを使用した Ray ダッシュボードとインタラクティブ シェルの手順に沿って、ユーザー プロジェクトで VPC-SC と VPC ピアリングを使用してインタラクティブ シェルの設定を構成します。
Vertex AI に Ray クラスタを作成したら、Vertex AI SDK for Python を使用してヘッドノードに接続できます。接続環境(Compute Engine VM や Vertex AI Workbench インスタンスなど)は、Vertex AI とピアリングされている VPC ネットワークに存在する必要があります。プライベート サービス接続の IP アドレスの数には上限があるため、IP アドレスが枯渇する可能性があります。そのため、長時間実行されるクラスタにはプライベート接続を使用することをおすすめします。
Ray on Vertex AI の Private Service Connect インターフェース
Private Service Connect インターフェースの下り(外向き)と Private Service Connect インターフェースの上り(内向き)は、Vertex AI の Ray クラスタでサポートされています。
Private Service Connect インターフェースの下り(外向き)接続を使用するには、次の操作を行います。VPC Service Controls が有効になっていない場合、Private Service Connect インターフェースの下り(外向き)があるクラスタは、Ray クライアントで上り(内向き)に安全なパブリック エンドポイントを使用します。
VPC Service Controls が有効になっている場合、Private Service Connect インターフェースの入力は、デフォルトで Private Service Connect インターフェースの出力とともに使用されます。Ray クライアントに接続するか、Private Service Connect インターフェースの入力があるクラスタのノートブックからジョブを送信するには、ノートブックがユーザー プロジェクトの VPC とサブネットワーク内にあることを確認してください。VPC Service Controls の設定方法の詳細については、Vertex AI を使用した VPC Service Controls をご覧ください。
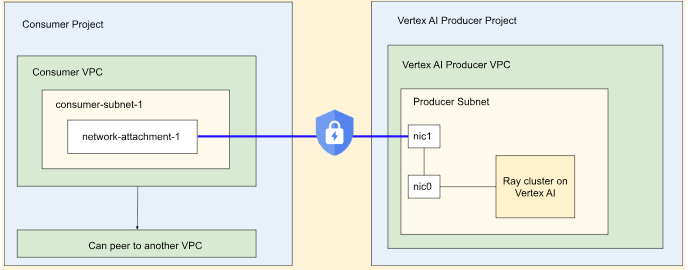
Private Service Connect インターフェースを有効にする
リソースの設定ガイドに沿って、Private Service Connect インターフェースを設定します。リソースを設定したら、Vertex AI の Ray クラスタで Private Service Connect インターフェースを有効にできます。
コンソール
クラスタの作成時に、[名前とリージョン] と [コンピューティング設定] を指定すると、[ネットワーキング] オプションが表示されます。
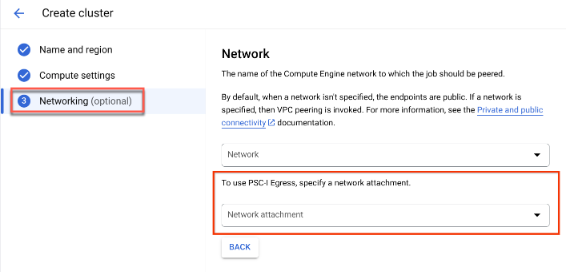
次のいずれかの方法でネットワーク アタッチメントを設定します。
- Private Service Connect のリソースを設定したときに指定した NETWORK_ATTACHMENT_NAME 名を使用します。
- プルダウンに表示される [ネットワーク アタッチメントを作成] ボタンをクリックして、新しいネットワーク アタッチメントを作成します。

[ネットワーク アタッチメントの作成] をクリックします。
表示されたサブタスクで、新しいネットワーク アタッチメントの名前、ネットワーク、サブネットワークを指定します。

[作成] をクリックします。
Ray on Vertex AI SDK
Ray on Vertex AI SDK は、Vertex AI SDK for Python の一部です。Vertex AI SDK for Python のインストールまたは更新の方法については、Vertex AI SDK for Python をインストールするをご覧ください。詳細については、Vertex AI SDK for Python API のリファレンス ドキュメントをご覧ください。
from google.cloud import aiplatform import vertex_ray # Initialization aiplatform.init() # Create a default cluster with network attachment configuration psc_config = vertex_ray.PscIConfig(network_attachment=NETWORK_ATTACHMENT_NAME) cluster_resource_name = vertex_ray.create_ray_cluster( psc_interface_config=psc_config, )
ここで
- NETWORK_ATTACHMENT_NAME: ユーザー プロジェクトで Private Service Connect のリソースを設定するときに指定した名前。
Ray on Vertex AI ネットワーク ファイル システム(NFS)
リモート ファイルをクラスタで使用できるようにするには、ネットワーク ファイル システム(NFS)共有をマウントします。これにより、ジョブはローカル ファイルのようにリモート ファイルにアクセスできるようになり、高スループットと低レイテンシが実現します。
VPC の設定
VPC の設定には次の 2 つの方法があります。
NFS インスタンスを設定する
Filestore インスタンスの作成方法の詳細については、インスタンスを作成するをご覧ください。Private Service Connect インターフェースを使用する場合は、Filestore の作成時にプライベート サービス アクセス モードを選択する必要はありません。
ネットワーク ファイル システム(NFS)を使用する
ネットワーク ファイル システムを使用するには、ネットワークまたはネットワーク アタッチメント(推奨)を指定します。
コンソール
作成ページの [ネットワーキング] ステップで、ネットワークまたはネットワーク アタッチメントのいずれかを指定した後。これを行うには、[ネットワーク ファイル システム(NFS)] セクションの [NFS マウントを追加] をクリックし、NFS マウント(サーバー、パス、マウント ポイント)を指定します。
フィールド 説明 serverNFS サーバーの IP アドレス。これは VPC 内のプライベート アドレスである必要があります。 pathNFS 共有パス。 /で始まる絶対パスを指定する必要があります。mountPointローカル マウント ポイント。有効な UNIX ディレクトリ名を指定してください。たとえば、ローカル マウント ポイントが sourceDataの場合、トレーニング VM インスタンスからのパス/mnt/nfs/ sourceDataを指定します。詳細については、コンピューティング リソースを指定する場所をご覧ください。
サーバー、パス、マウント ポイントを指定します。

[作成] をクリックします。これにより、Ray クラスタが作成されます。
VPC-SC と VPC ピアリングを使用した Ray ダッシュボードとインタラクティブ シェル
-
peered-dns-domainsを構成します。{ VPC_NAME=NETWORK_NAME REGION=LOCATION gcloud services peered-dns-domains create training-cloud \ --network=$VPC_NAME \ --dns-suffix=$REGION.aiplatform-training.cloud.google.com. # Verify gcloud beta services peered-dns-domains list --network $VPC_NAME; }
-
NETWORK_NAME: ピアリングされたネットワークに変更します。
-
LOCATION: 目的のロケーション(例:
us-central1)。
-
-
DNS managed zoneを構成します。{ PROJECT_ID=PROJECT_ID ZONE_NAME=$PROJECT_ID-aiplatform-training-cloud-google-com DNS_NAME=aiplatform-training.cloud.google.com DESCRIPTION=aiplatform-training.cloud.google.com gcloud dns managed-zones create $ZONE_NAME \ --visibility=private \ --networks=https://www.googleapis.com/compute/v1/projects/$PROJECT_ID/global/networks/$VPC_NAME \ --dns-name=$DNS_NAME \ --description="Training $DESCRIPTION" }
-
PROJECT_ID: 実際のプロジェクト ID。これらの ID は、 Google Cloud コンソールの [ようこそ] ページで確認できます。
-
-
DNS トランザクションを記録します。
{ gcloud dns record-sets transaction start --zone=$ZONE_NAME gcloud dns record-sets transaction add \ --name=$DNS_NAME. \ --type=A 199.36.153.4 199.36.153.5 199.36.153.6 199.36.153.7 \ --zone=$ZONE_NAME \ --ttl=300 gcloud dns record-sets transaction add \ --name=*.$DNS_NAME. \ --type=CNAME $DNS_NAME. \ --zone=$ZONE_NAME \ --ttl=300 gcloud dns record-sets transaction execute --zone=$ZONE_NAME }
-
インタラクティブ シェル、VPC-SC、VPC ピアリングを有効にしてトレーニング ジョブを送信します。
責任の共有
Vertex AI でのワークロードの保護は共有責任です。Vertex AI はセキュリティの脆弱性に対処するためにインフラストラクチャ構成を定期的にアップグレードしますが、実行中のワークロードをプリエンプトしないように、既存の Ray on Vertex AI クラスタと永続リソースは自動的にアップグレードされません。そのため、次のようなタスクはユーザーの責任となります。
- 最新のインフラストラクチャ バージョンを使用するには、Ray on Vertex AI クラスタと永続リソースを定期的に削除して再作成します。Vertex AI では、クラスタと永続リソースを少なくとも 30 日に 1 回再作成することをおすすめします。
- 使用するカスタム イメージを適切に構成します。
詳しくは、責任の共有をご覧ください。