
Ray は、AI および Python アプリケーションをスケーリングするためのオープンソース フレームワークです。Ray は、機械学習(ML)ワークフローの分散コンピューティングと並列処理を実現するためのインフラストラクチャを提供します。

すでに Ray を使用している場合は、同じオープンソースの Ray コードを使用して、最小限の変更でプログラムを作成し、Vertex AI でアプリケーションを開発できます。これにより、ML ワークフローの一部として、他の Google Cloudサービス(Vertex AI Prediction や BigQuery など)、との Vertex AI のインテグレーションを使用できます。
すでに Vertex AI を使用していて、コンピューティング リソースをより簡単に管理する必要がある場合は、Ray コードを使用してトレーニングをスケールできます。
Ray on Vertex AI を使用するためのワークフロー
Colab Enterprise と Vertex AI SDK for Python を使用して Ray クラスタに接続します。
| ステップ | 説明 |
|---|---|
| 1. Ray on Vertex AI を設定する | Google プロジェクトを設定し、Ray Client の機能を含むバージョンの Vertex AI SDK for Python をインストールして、VPC ピアリング ネットワークを設定(オプション)します。 |
| 2. Vertex AI に Ray クラスタを作成する | Vertex AI に Ray クラスタを作成します。Vertex AI の管理者ロールが必要です。 |
| 3. Vertex AI で Ray アプリケーションを開発する | Vertex AI の Ray クラスタに接続してアプリケーションを開発します。Vertex AI のユーザーロールが必要です。 |
| 4. (省略可)BigQuery で Ray on Vertex AI を使用する | BigQuery を使用してデータの読み取り、書き込み、変換を行います。 |
| 5. (省略可)Vertex AI にモデルをデプロイして推論を取得する | Vertex AI オンライン エンドポイントにモデルをデプロイして、推論を取得します。 |
| 6. Vertex AI で Ray クラスタをモニタリングする | 生成されたログは Cloud Logging でモニタリングし、指標は Cloud Monitoring でモニタリングします。 |
| 7. Vertex AI の Ray クラスタを削除する | 不要な課金を避けるため、Vertex AI の Ray クラスタを削除します。 |
概要
Ray クラスタは、重要な ML ワークロードやピークシーズンに十分な容量を確保するために組み込まれています。ジョブの完了後にトレーニング サービスがリソースを解放するカスタムジョブとは異なり、Ray クラスタは削除されるまで使用できます。
注: 次のシナリオでは、長時間実行の Ray クラスタを使用します。
- 同じ Ray ジョブを複数回送信する場合は、同じ長時間実行 Ray クラスタでジョブを実行することで、データと画像のキャッシュのメリットを活用できます。
- 実際の処理時間がジョブの起動時間よりも短い、短期的な Ray ジョブを多数実行する場合は、長時間実行クラスタを使用すると効果的です。
Vertex AI の Ray クラスタは、パブリック接続またはプライベート接続で設定できます。次の図では、Ray on Vertex AI のアーキテクチャとワークフローを示します。詳細については、パブリック接続またはプライベート接続をご覧ください。
パブリック接続を使用したアーキテクチャ
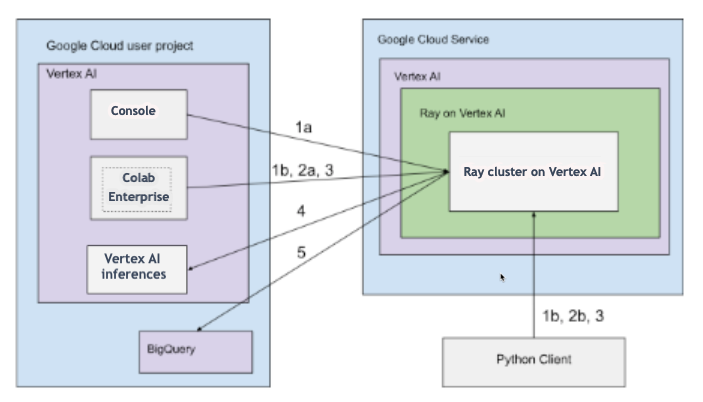
次のオプションを使用して、Vertex AI に Ray クラスタを作成します。
a. Google Cloud コンソールを使用して Vertex AI に Ray クラスタを作成します。
b. Vertex AI SDK for Python を使用して Vertex AI に Ray クラスタを作成します。
次のオプションを使用して、Vertex AI の Ray クラスタに接続し、インタラクティブな開発を行います。
a. Google Cloud コンソールで Colab Enterprise を使用して、シームレスに接続します。
b. 公共のインターネットにアクセスできる Python 環境を使用します。
Vertex AI の Ray クラスタでアプリケーションを開発し、モデルをトレーニングします。
任意の環境(Colab Enterprise または Python ノートブック)で Vertex AI SDK for Python を使用します。
任意の環境を使用して Python スクリプトを作成します。
Vertex AI SDK for Python、Ray Job CLI、または Ray Job Submission API を使用して、Vertex AI の Ray クラスタに Ray ジョブを送信します。
ライブ推論のために、トレーニング済みモデルをオンライン Vertex AI エンドポイントにデプロイします。
BigQuery を使用してデータを管理します。
VPC を使用したアーキテクチャ
次の図は、 Google Cloud プロジェクトと VPC ネットワーク(オプション)を設定した後の Ray on Vertex AI のアーキテクチャとワークフローを示しています。
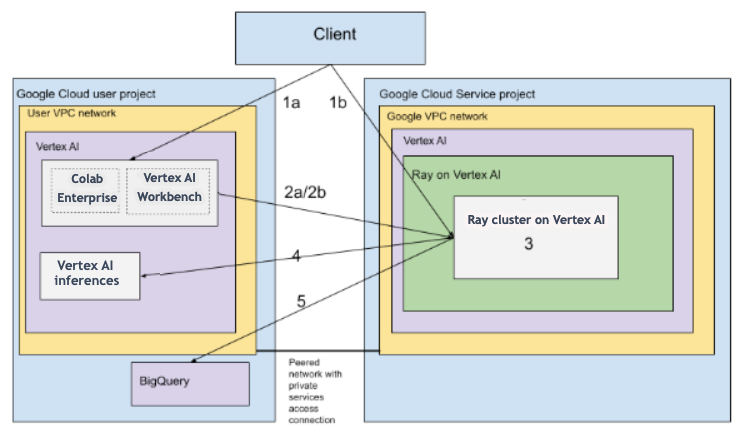
(a)Google プロジェクトと(b)VPC ネットワークを設定します。
次のオプションを使用して、Vertex AI に Ray クラスタを作成します。
a. Google Cloud コンソールを使用して Vertex AI に Ray クラスタを作成します。
b. Vertex AI SDK for Python を使用して Vertex AI に Ray クラスタを作成します。
次の方法を使用して、VPC ピアリング ネットワーク経由で Vertex AI の Ray クラスタに接続します。
Google Cloud コンソールで Colab Enterprise を使用する。
Vertex AI Workbench ノートブックを使用する。
Vertex AI の Ray クラスタでアプリケーションを開発し、次のオプションを使用してモデルをトレーニングします。
任意の環境(Colab Enterprise または Vertex AI Workbench ノートブック)で Vertex AI SDK for Python を使用します。
任意の環境を使用して Python スクリプトを作成します。Vertex AI SDK for Python、Ray Job CLI、または Ray ダッシュボードを使用して、Vertex AI の Ray クラスタに Ray ジョブを送信します。
推論のために、トレーニング済みモデルをオンライン Vertex AI エンドポイントにデプロイします。
BigQuery を使用してデータを管理します。
用語
用語の完全なリストについては、予測 AI の Vertex AI 用語集をご覧ください。
-
自動スケーリング
- 自動スケーリングは、Ray クラスタのワーカープールなどのコンピューティング リソースが、ワークロードの需要に基づいてノード数を自動的に増減し、リソース使用率と費用を最適化する機能です。詳細については、Vertex AI で Ray クラスタをスケーリングする: 自動スケーリングをご覧ください。
-
バッチ推論
- バッチ推論は、推論リクエストのグループを受け取り、結果を 1 つのファイルに出力します。詳細については、Vertex AI での推論の取得の概要をご覧ください。
-
BigQuery
- BigQuery は、Google Cloud が提供するフルマネージド型でサーバーレスの、スケーラビリティに優れた企業向けデータ ウェアハウスです。SQL クエリを使用して大規模なデータセットを非常に高速で分析できるように設計されています。BigQuery を使用すると、ユーザーはインフラストラクチャを管理することなく、強力なビジネス インテリジェンスと分析を実現できます。詳細については、データ ウェアハウスから自律型データと AI Platform へをご覧ください。
-
Cloud Logging
- Cloud Logging は、Google Cloud が提供するフルマネージド型のリアルタイム ロギング サービスです。このサービスを使用すると、すべての Google Cloud リソース、オンプレミス アプリケーション、カスタムソースからログを収集、保存、分析、モニタリングできます。Cloud Logging はログ管理を一元化するため、アプリケーションとインフラストラクチャの動作と健全性のトラブルシューティング、監査、把握が容易になります。詳細については、Cloud Logging の概要をご覧ください。
-
Colab Enterprise
- Colab Enterprise は、コラボレーション指向のマネージド Jupyter ノートブック環境です。Google Colab の広く利用されているユーザー エクスペリエンスを Google Cloud に提供し、エンタープライズ レベルのセキュリティ機能とコンプライアンス機能を提供します。Colab Enterprise は、ノートブック主導型で構成は不要です。コンピューティング リソースは Vertex AI によって管理され、BigQuery などの他の Google Cloud サービスと統合されています。詳細については、Colab Enterprise の概要をご覧ください。
-
カスタム コンテナ イメージ
- カスタム コンテナ イメージは、ユーザーのアプリケーション コード、そのランタイム、ライブラリ、依存関係、環境構成を含む自己完結型の実行可能パッケージです。Google Cloud、特に Vertex AI のコンテキストでは、ユーザーは ML トレーニング コードまたはサービング アプリケーションを正確な依存関係とともにパッケージ化できます。これにより、再現性が確保され、ユーザーは標準環境で提供されていない特定のソフトウェア バージョンや独自の構成を使用して、マネージド サービスでワークロードを実行できます。詳細については、推論用のカスタム コンテナの要件をご覧ください。
-
エンドポイント
- 推論を行うためにトレーニング済みモデルをデプロイできるリソース。詳細については、エンドポイント タイプを選択するをご覧ください。
-
Identity and Access Management(IAM)権限
- Identity and Access Management(IAM)権限は、どの Google Cloud リソースに対して、どのユーザーがどのような操作を実行できるかを定義する、特定のきめ細かい機能です。権限はロールを通じてプリンシパル(ユーザー、グループ、サービス アカウントなど)に割り当てられ、Google Cloud プロジェクトまたは組織内のサービスとデータへのアクセスを正確に制御できます。詳しくは、IAM によるアクセス制御をご覧ください。
-
推論
- Vertex AI プラットフォームの文脈では、推論とは、データポイントを ML モデルに入力して、単一の数値スコアなどの出力を計算するプロセスを指します。このプロセスは、「ML モデルの運用」または「本番環境への ML モデルのデプロイ」とも呼ばれます。モデルを使用して新しいデータの推論を行うことができるという点で、推論は、ML ワークフローの重要なステップです。Vertex AI では、バッチ推論やオンライン推論など、さまざまな方法で推論を実行できます。バッチ推論では、推論リクエストのグループを実行して、結果を 1 つのファイルに出力します。一方、オンライン推論では、個々のデータポイントに対してリアルタイムの推論を行えます。
-
ネットワーク ファイル システム(NFS)
- ユーザーがネットワーク経由でファイルにアクセスし、ファイルをローカル ファイル ディレクトリにあるかのように扱えるクライアント / サーバー システム。詳細については、ネットワーク ファイル システム共有をマウントするをご覧ください。
-
オンライン推論
- 個々のインスタンスの推論を同期的に取得します。詳細については、オンライン推論をご覧ください。
-
永続リソース
- 明示的に削除されるまで割り当てられて使用可能な状態が維持される Vertex AI コンピューティング リソースのタイプ(Ray クラスタなど)。反復型の開発に役立ち、ジョブ間の起動オーバーヘッドを削減します。詳細については、永続リソース情報を取得するをご覧ください。
-
パイプライン
- ML パイプラインは移植可能でスケーラブルなコンテナベースの ML ワークフローです。 詳細については、Vertex AI Pipelines の概要をご覧ください。
-
ビルド済みコンテナ
- 一般的な ML フレームワークと依存関係がプリインストールされた Vertex AI 提供のコンテナ イメージ。トレーニング ジョブと推論ジョブの設定が簡素化されます。詳細については、サーバーレス トレーニング用の事前にビルドされたコンテナをご覧ください。
-
Private Service Connect(PSC)
- Private Service Connect は、Compute Engine のお客様がネットワーク内のプライベート IP を別の VPC ネットワークまたは Google API にマッピングできるテクノロジーです。詳細については、Private Service Connect をご覧ください。
-
Vertex AI の Ray クラスタ
- Vertex AI の Ray クラスタは、分散 ML と Python アプリケーションの実行に使用できるコンピューティング ノードのマネージド クラスタです。ML ワークフローの分散コンピューティングと並列処理を実行するためのインフラストラクチャを提供します。Ray クラスタは、重要な ML ワークロードやピークシーズンに十分な容量を確保するために Vertex AI に組み込まれています。ジョブが完了するとトレーニング サービスからリソースが解放されるカスタムジョブとは異なり、Ray クラスタは削除されるまで使用できます。詳細については、Ray on Vertex AI の概要をご覧ください。
-
Ray on Vertex AI(RoV)
- Ray on Vertex AI は、同じオープンソースの Ray コードを使用して、最小限の変更でプログラムを作成し、Vertex AI でアプリケーションを開発できるように設計されています。詳細については、Ray on Vertex AI の概要をご覧ください。
-
Ray on Vertex AI SDK for Python
- Ray on Vertex AI SDK for Python は、Ray Client、Ray BigQuery コネクタ、Vertex AI での Ray クラスタ管理、Vertex AI での推論の機能が含まれているバージョンの Vertex AI SDK for Python です。詳細については、Vertex AI SDK for Python の概要をご覧ください。
-
Ray on Vertex AI SDK for Python
- Ray on Vertex AI SDK for Python は、Ray Client、Ray BigQuery コネクタ、Vertex AI での Ray クラスタ管理、Vertex AI での推論の機能が含まれているバージョンの Vertex AI SDK for Python です。詳細については、Vertex AI SDK for Python の概要をご覧ください。
-
サービス アカウント
- サービス アカウントは、アプリケーションや仮想マシンが Google Cloud サービスに対して承認済みの API 呼び出しを行うために使用する特別な Google Cloud アカウントです。ユーザー アカウントとは異なり、個々のユーザーに関連付けられていませんが、コードの ID として機能し、ユーザーの認証情報を必要とせずにリソースへの安全なプログラムによるアクセスを可能にします。詳しくは、サービス アカウントの概要をご覧ください。
-
Vertex AI Workbench
- Vertex AI Workbench は、データ探索と分析からモデルの開発、トレーニング、デプロイまで、データ サイエンス ワークフロー全体をサポートする、Jupyter ノートブック ベースの統合開発環境です。Vertex AI Workbench は、BigQuery や Cloud Storage などの他の Google Cloud サービスとの統合が組み込まれた、マネージドでスケーラブルなインフラストラクチャを提供します。これにより、データ サイエンティストは基盤となるインフラストラクチャを管理することなく、ML タスクを効率的に実行できます。詳細については、Vertex AI Workbench の概要をご覧ください。
-
ワーカーノード
- ワーカーノードは、タスクや作業の実行を担当する、クラスタ内の個々のマシンまたはコンピューティング インスタンスを指します。Kubernetes クラスタや Ray クラスタなどのシステムでは、ノードがコンピューティングの基本単位です。詳細については、ハイ パフォーマンス コンピューティング(HPC)とはをご覧ください。
-
ワーカープール
- 分散タスクを実行する Ray クラスタのコンポーネント。ワーカープールは特定のマシンタイプで構成でき、自動スケーリングと手動スケーリングの両方をサポートします。詳細については、トレーニング クラスタの構造をご覧ください。
料金
Vertex AI での Ray の料金は次のように計算されます。
使用するコンピューティング リソースは、Vertex AI に Ray クラスタを作成するときに選択したマシン構成に基づいて課金されます。Vertex AI の Ray の料金については、料金ページをご覧ください。
Ray クラスタの場合、料金は RUNNING と UPDATING 状態のときにのみ発生します。他の状態では課金されません。課金される金額は、その時点での実際のクラスタサイズに基づきます。
Vertex AI で Ray クラスタを使用してタスクを実行する場合、ログが自動的に生成され、Cloud Logging の料金に基づいて課金されます。
オンライン推論用のエンドポイントにモデルをデプロイする場合は、Vertex AI の料金ページの予測と説明セクションをご覧ください。
Vertex AI の Ray と BigQuery を使用する場合は、BigQuery の料金をご覧ください。