
הסקת מסקנות באצווה היא בקשה לא סנכרונית להסקת מסקנות ישירות ממשאב המודל, בלי צורך בפריסת המודל לנקודת קצה.
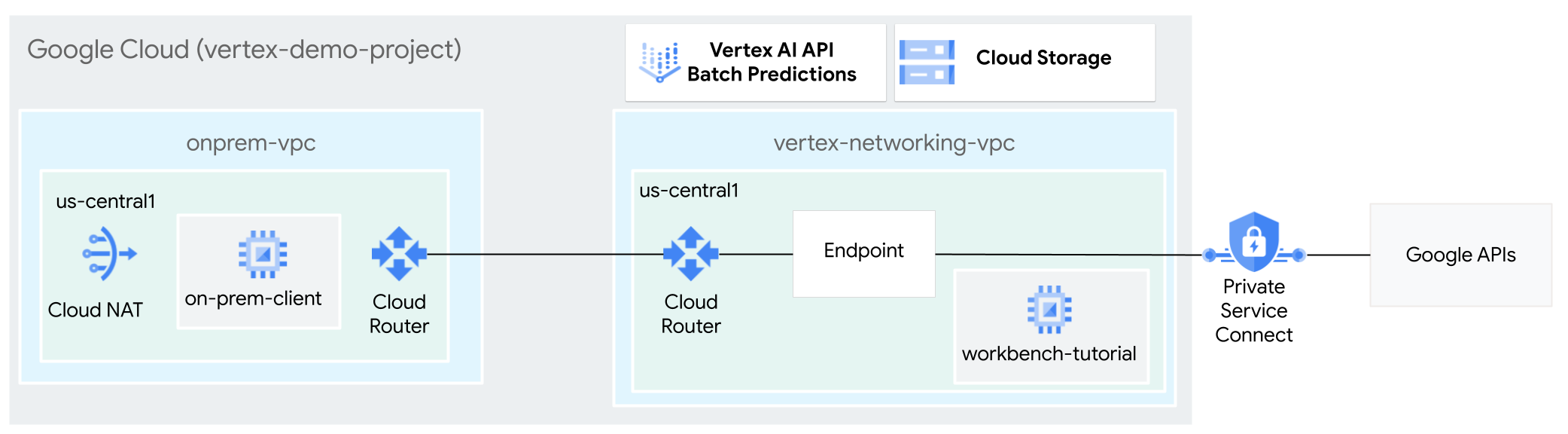
במדריך הזה משתמשים ב-HA VPN (רשת VPN בזמינות גבוהה) כדי לשלוח בקשות להסקת מסקנות (inference) באצווה למודל מאומן באופן פרטי, בין שתי רשתות ענן וירטואלי פרטי (VPC) שיכולות לשמש כבסיס לקישוריות פרטית בין כמה עננים ובין רשתות מקומיות.
המדריך הזה מיועד לאדמינים של רשתות ארגוניות, למדעני נתונים ולחוקרים שמכירים את Vertex AI, את הענן הווירטואלי הפרטי (VPC), את Google Cloud המסוף ואת Cloud Shell. היכרות עם Vertex AI Workbench מועילה אבל לא חובה.
מטרות
- יוצרים שתי רשתות VPC, כמו שמוצג בתרשים הקודם:
- אחד (
vertex-networking-vpc) הוא לגישה ל-Google APIs להסקת מסקנות באצווה. - האפשרות השנייה (
onprem-vpc) מייצגת רשת מקומית.
- אחד (
- פריסת שערי HA VPN, מנהרות Cloud VPN ו-Cloud Routers כדי לחבר בין
vertex-networking-vpcל-onprem-vpc. - יוצרים מודל היסק (inference) של Vertex AI באצווה ומעלים אותו לקטגוריה של Cloud Storage.
- יוצרים נקודת קצה (endpoint) של Private Service Connect (PSC) כדי להעביר בקשות פרטיות אל Vertex AI batch inference API בארכיטקטורת REST.
- מגדירים את מצב הפרסום המותאם אישית של Cloud Router ב-
vertex-networking-vpcכדי לפרסם מסלולים לנקודת הקצה של Private Service Connect אלonprem-vpc. - יוצרים מכונה וירטואלית ב-Compute Engine ב-
onprem-vpcכדי לייצג אפליקציית לקוח (on-prem-client) ששולחת בקשות להסקת מסקנות באצווה באופן פרטי דרך HA VPN.
עלויות
במסמך הזה משתמשים ברכיבים הבאים של Google Cloud, והשימוש בהם כרוך בתשלום:
כדי להעריך את ההוצאות בהתאם לתחזית השימוש שלכם, אתם יכולים להיעזר במחשבון העלויות.
כשמסיימים את המשימות שמתוארות במסמך הזה אפשר למחוק את המשאבים שיצרתם כדי להימנע מחיובים נוספים. מידע נוסף זמין בקטע הסרת המשאבים.
לפני שמתחילים
-
In the Google Cloud console, go to the project selector page.
-
Select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
- פותחים את Cloud Shell כדי להריץ את הפקודות שמפורטות במדריך הזה. Cloud Shell היא סביבת מעטפת אינטראקטיבית של Google Cloud שמאפשרת לכם לנהל את הפרויקטים והמשאבים שלכם מדפדפן האינטרנט.
- ב-Cloud Shell, מגדירים את הפרויקט הנוכחי למזהה הפרויקט Google Cloud ומאחסנים את אותו מזהה פרויקט במשתנה המעטפת
projectid: projectid="PROJECT_ID" gcloud config set project ${projectid} - אם אתם לא הבעלים של הפרויקט, אתם צריכים לבקש מבעלי הפרויקט להקצות לכם את התפקיד Project IAM Admin (אדמין IAM של הפרויקט) (roles/resourcemanager.projectIamAdmin). כדי להקצות תפקידי IAM בשלב הבא, צריך להיות לכם התפקיד הזה.
-
Make sure that you have the following role or roles on the project: roles/compute.instanceAdmin.v1, roles/compute.networkAdmin, roles/compute.securityAdmin, roles/dns.admin, roles/iap.tunnelResourceAccessor, roles/notebooks.admin, roles/iam.serviceAccountAdmin, roles/iam.serviceAccountUser, roles/servicedirectory.editor, roles/serviceusage.serviceUsageAdmin, roles/storage.admin, roles/aiplatform.admin, roles/aiplatform.user, roles/resourcemanager.projectIamAdmin
Check for the roles
-
In the Google Cloud console, go to the IAM page.
Go to IAM - Select the project.
-
In the Principal column, find all rows that identify you or a group that you're included in. To learn which groups you're included in, contact your administrator.
- For all rows that specify or include you, check the Role column to see whether the list of roles includes the required roles.
Grant the roles
-
In the Google Cloud console, go to the IAM page.
כניסה לדף IAM - בוחרים את הפרויקט.
- לוחצים על Grant access.
-
בשדה New principals, מזינים את מזהה המשתמש. בדרך כלל מזהה המשתמש הוא כתובת האימייל של חשבון Google.
- לוחצים על בחירת תפקיד ומחפשים את התפקיד.
- כדי לתת עוד תפקידים, לוחצים על Add another role ומוסיפים את כולם.
- לוחצים על Save.
Enable the DNS, Artifact Registry, IAM, Compute Engine, Notebooks, and Vertex AI APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
יצירת רשתות VPC
בקטע הזה יוצרים שתי רשתות VPC: אחת לגישה ל-Google APIs להסקת מסקנות באצווה, והשנייה לסימולציה של רשת מקומית. בכל אחת משתי רשתות ה-VPC, יוצרים Cloud Router ושער Cloud NAT. שער Cloud NAT מספק קישוריות יוצאת למכונות וירטואליות (VM) של Compute Engine ללא כתובות IP חיצוניות.
יוצרים את רשת ה-VPC
vertex-networking-vpc:gcloud compute networks create vertex-networking-vpc \ --subnet-mode customברשת
vertex-networking-vpc, יוצרים תת-רשת בשםworkbench-subnetעם טווח IPv4 ראשי של10.0.1.0/28:gcloud compute networks subnets create workbench-subnet \ --range=10.0.1.0/28 \ --network=vertex-networking-vpc \ --region=us-central1 \ --enable-private-ip-google-accessיוצרים את רשת ה-VPC כדי לדמות את הרשת המקומית (
onprem-vpc):gcloud compute networks create onprem-vpc \ --subnet-mode customברשת
onprem-vpc, יוצרים רשת משנה בשםonprem-vpc-subnet1עם טווח IPv4 ראשי של172.16.10.0/29:gcloud compute networks subnets create onprem-vpc-subnet1 \ --network onprem-vpc \ --range 172.16.10.0/29 \ --region us-central1
איך מוודאים שהגדרות רשתות ה-VPC נכונות
במסוף Google Cloud , עוברים לכרטיסייה Networks in current project בדף VPC networks.
ברשימת רשתות ה-VPC, מוודאים ששתי הרשתות נוצרו:
vertex-networking-vpcו-onprem-vpc.לוחצים על הכרטיסייה Subnets in current project (רשתות משנה בפרויקט הנוכחי).
ברשימת תת-הרשתות של ה-VPC, מוודאים שתת-הרשתות
workbench-subnetו-onprem-vpc-subnet1נוצרו.
הגדרת קישוריות היברידית
בקטע הזה יוצרים שני שערי HA VPN שמחוברים זה לזה. אחד נמצא ברשת ה-VPC vertex-networking-vpc. השני נמצא ברשת onprem-vpc VPC. כל שער מכיל Cloud Router וצמד מנהרות VPN.
יצירת שערי HA VPN
יוצרים ב-Cloud Shell שער HA VPN לרשת
vertex-networking-vpcVPC:gcloud compute vpn-gateways create vertex-networking-vpn-gw1 \ --network vertex-networking-vpc \ --region us-central1יוצרים את שער HA VPN לרשת ה-VPC:
onprem-vpcgcloud compute vpn-gateways create onprem-vpn-gw1 \ --network onprem-vpc \ --region us-central1במסוף Google Cloud , עוברים לכרטיסייה Cloud VPN Gateways בדף VPN.
מוודאים ששני השערים (
vertex-networking-vpn-gw1ו-onprem-vpn-gw1) נוצרו ושלכל שער יש שתי כתובות IP של ממשקים.
יצירה של Cloud Routers ושערי Cloud NAT
בכל אחת משתי רשתות ה-VPC, יוצרים שני נתבי Cloud Router: אחד כללי ואחד אזורי. בכל אחד מ-Cloud Routers האזוריים, יוצרים שער Cloud NAT. שערי Cloud NAT מספקים קישוריות יוצאת למכונות וירטואליות (VM) של Compute Engine שאין להן כתובות IP חיצוניות.
יוצרים ב-Cloud Shell Cloud Router לרשת ה-VPC
vertex-networking-vpc:gcloud compute routers create vertex-networking-vpc-router1 \ --region us-central1\ --network vertex-networking-vpc \ --asn 65001יוצרים Cloud Router לרשת ה-VPC
onprem-vpc:gcloud compute routers create onprem-vpc-router1 \ --region us-central1\ --network onprem-vpc\ --asn 65002יוצרים Cloud Router אזורי לרשת ה-VPC
vertex-networking-vpc:gcloud compute routers create cloud-router-us-central1-vertex-nat \ --network vertex-networking-vpc \ --region us-central1מגדירים שער Cloud NAT ב-Cloud Router האזורי:
gcloud compute routers nats create cloud-nat-us-central1 \ --router=cloud-router-us-central1-vertex-nat \ --auto-allocate-nat-external-ips \ --nat-all-subnet-ip-ranges \ --region us-central1יוצרים Cloud Router אזורי לרשת ה-VPC
onprem-vpc:gcloud compute routers create cloud-router-us-central1-onprem-nat \ --network onprem-vpc \ --region us-central1מגדירים שער Cloud NAT ב-Cloud Router האזורי:
gcloud compute routers nats create cloud-nat-us-central1-on-prem \ --router=cloud-router-us-central1-onprem-nat \ --auto-allocate-nat-external-ips \ --nat-all-subnet-ip-ranges \ --region us-central1נכנסים לדף Cloud Routers במסוף Google Cloud .
ברשימה Cloud Routers, מוודאים שהנתבים הבאים נוצרו:
cloud-router-us-central1-onprem-natcloud-router-us-central1-vertex-natonprem-vpc-router1vertex-networking-vpc-router1
יכול להיות שתצטרכו לרענן את הכרטיסייה בדפדפן של Google Cloud המסוף כדי לראות את הערכים החדשים.
ברשימת נתבי Cloud, לוחצים על
cloud-router-us-central1-vertex-nat.בדף פרטי הנתב, מוודאים ששער Cloud NAT נוצר.
cloud-nat-us-central1לוחצים על החץ חזרה כדי לחזור לדף Cloud Routers.
ברשימת הנתבים, לוחצים על
cloud-router-us-central1-onprem-nat.בדף פרטי הנתב, מוודאים שנוצר שער
cloud-nat-us-central1-on-premCloud NAT.
יצירת מנהרות VPN
ב-Cloud Shell, ברשת
vertex-networking-vpc, יוצרים מנהרת VPN בשםvertex-networking-vpc-tunnel0:gcloud compute vpn-tunnels create vertex-networking-vpc-tunnel0 \ --peer-gcp-gateway onprem-vpn-gw1 \ --region us-central1 \ --ike-version 2 \ --shared-secret [ZzTLxKL8fmRykwNDfCvEFIjmlYLhMucH] \ --router vertex-networking-vpc-router1 \ --vpn-gateway vertex-networking-vpn-gw1 \ --interface 0ברשת
vertex-networking-vpc, יוצרים מנהרת VPN בשםvertex-networking-vpc-tunnel1:gcloud compute vpn-tunnels create vertex-networking-vpc-tunnel1 \ --peer-gcp-gateway onprem-vpn-gw1 \ --region us-central1 \ --ike-version 2 \ --shared-secret [bcyPaboPl8fSkXRmvONGJzWTrc6tRqY5] \ --router vertex-networking-vpc-router1 \ --vpn-gateway vertex-networking-vpn-gw1 \ --interface 1ברשת
onprem-vpc, יוצרים מנהרת VPN בשםonprem-vpc-tunnel0:gcloud compute vpn-tunnels create onprem-vpc-tunnel0 \ --peer-gcp-gateway vertex-networking-vpn-gw1 \ --region us-central1\ --ike-version 2 \ --shared-secret [ZzTLxKL8fmRykwNDfCvEFIjmlYLhMucH] \ --router onprem-vpc-router1 \ --vpn-gateway onprem-vpn-gw1 \ --interface 0ברשת
onprem-vpc, יוצרים מנהרת VPN בשםonprem-vpc-tunnel1:gcloud compute vpn-tunnels create onprem-vpc-tunnel1 \ --peer-gcp-gateway vertex-networking-vpn-gw1 \ --region us-central1\ --ike-version 2 \ --shared-secret [bcyPaboPl8fSkXRmvONGJzWTrc6tRqY5] \ --router onprem-vpc-router1 \ --vpn-gateway onprem-vpn-gw1 \ --interface 1נכנסים לדף VPN במסוף Google Cloud .
ברשימת מנהרות ה-VPN, מוודאים שנוצרו ארבע מנהרות VPN.
יצירת סשנים של BGP
Cloud Router משתמש בפרוטוקול Border Gateway Protocol (BGP) כדי להחליף מסלולים בין רשת ה-VPC (במקרה הזה, vertex-networking-vpc) לבין הרשת המקומית (שמיוצגת על ידי onprem-vpc). ב-Cloud Router, מגדירים ממשק ורשת שכנה של BGP לנתב המקומי.
הממשק והגדרת עמית BGP יוצרים יחד סשן BGP.
בקטע הזה יוצרים שני סשנים של BGP ל-vertex-networking-vpc ושני סשנים ל-onprem-vpc.
אחרי שתגדירו את הממשקים ואת עמיתי ה-BGP בין הנתבים, הם יתחילו להחליף מסלולים באופן אוטומטי.
יצירת סשנים של BGP עבור vertex-networking-vpc
ב-Cloud Shell, ברשת
vertex-networking-vpc, יוצרים ממשק BGP ל-vertex-networking-vpc-tunnel0:gcloud compute routers add-interface vertex-networking-vpc-router1 \ --interface-name if-tunnel0-to-onprem \ --ip-address 169.254.0.1 \ --mask-length 30 \ --vpn-tunnel vertex-networking-vpc-tunnel0 \ --region us-central1ברשת
vertex-networking-vpc, יוצרים קישור בין רשתות שכנות באמצעות BGP למנהרהbgp-onprem-tunnel0:gcloud compute routers add-bgp-peer vertex-networking-vpc-router1 \ --peer-name bgp-onprem-tunnel0 \ --interface if-tunnel0-to-onprem \ --peer-ip-address 169.254.0.2 \ --peer-asn 65002 \ --region us-central1ברשת
vertex-networking-vpc, יוצרים ממשק BGP ל-vertex-networking-vpc-tunnel1:gcloud compute routers add-interface vertex-networking-vpc-router1 \ --interface-name if-tunnel1-to-onprem \ --ip-address 169.254.1.1 \ --mask-length 30 \ --vpn-tunnel vertex-networking-vpc-tunnel1 \ --region us-central1ברשת
vertex-networking-vpc, יוצרים קישור בין רשתות שכנות באמצעות BGP למנהרהbgp-onprem-tunnel1:gcloud compute routers add-bgp-peer vertex-networking-vpc-router1 \ --peer-name bgp-onprem-tunnel1 \ --interface if-tunnel1-to-onprem \ --peer-ip-address 169.254.1.2 \ --peer-asn 65002 \ --region us-central1
יצירת סשנים של BGP עבור onprem-vpc
ברשת
onprem-vpc, יוצרים ממשק BGP ל-onprem-vpc-tunnel0:gcloud compute routers add-interface onprem-vpc-router1 \ --interface-name if-tunnel0-to-vertex-networking-vpc \ --ip-address 169.254.0.2 \ --mask-length 30 \ --vpn-tunnel onprem-vpc-tunnel0 \ --region us-central1ברשת
onprem-vpc, יוצרים קישור בין רשתות שכנות באמצעות BGP למנהרהbgp-vertex-networking-vpc-tunnel0:gcloud compute routers add-bgp-peer onprem-vpc-router1 \ --peer-name bgp-vertex-networking-vpc-tunnel0 \ --interface if-tunnel0-to-vertex-networking-vpc \ --peer-ip-address 169.254.0.1 \ --peer-asn 65001 \ --region us-central1ברשת
onprem-vpc, יוצרים ממשק BGP ל-onprem-vpc-tunnel1:gcloud compute routers add-interface onprem-vpc-router1 \ --interface-name if-tunnel1-to-vertex-networking-vpc \ --ip-address 169.254.1.2 \ --mask-length 30 \ --vpn-tunnel onprem-vpc-tunnel1 \ --region us-central1ברשת
onprem-vpc, יוצרים קישור בין רשתות שכנות באמצעות BGP למנהרהbgp-vertex-networking-vpc-tunnel1:gcloud compute routers add-bgp-peer onprem-vpc-router1 \ --peer-name bgp-vertex-networking-vpc-tunnel1 \ --interface if-tunnel1-to-vertex-networking-vpc \ --peer-ip-address 169.254.1.1 \ --peer-asn 65001 \ --region us-central1
אימות של יצירת סשן BGP
נכנסים לדף VPN במסוף Google Cloud .
ברשימת מנהרות ה-VPN, מוודאים שהערך בעמודה BGP session status עבור כל אחת מהמנהרות השתנה מ-Configure BGP session ל-BGP established. יכול להיות שתצטרכו לרענן את כרטיסיית הדפדפן של Google Cloud המסוף כדי לראות את הערכים החדשים.
אימות של המסלולים שנלמדו vertex-networking-vpc
נכנסים לדף VPC networks במסוף Google Cloud .
ברשימת רשתות ה-VPC, לוחצים על
vertex-networking-vpc.לוחצים על הכרטיסייה מסלולים.
בוחרים באפשרות us-central1 (Iowa) ברשימה Region ולוחצים על View.
בעמודה Destination IP range (טווח כתובות ה-IP של היעד), מוודאים שטווח כתובות ה-IP של רשת המשנה (
172.16.10.0/29) מופיע פעמיים.onprem-vpc-subnet1
אימות של המסלולים שנלמדו onprem-vpc
לוחצים על החץ לחזרה כדי לחזור לדף רשתות VPC.
ברשימת רשתות ה-VPC, לוחצים על
onprem-vpc.לוחצים על הכרטיסייה מסלולים.
בוחרים באפשרות us-central1 (Iowa) ברשימה Region ולוחצים על View.
בעמודה Destination IP range מוודאים שטווח כתובות ה-IP של רשת המשנה (
10.0.1.0/28) מופיע פעמיים.workbench-subnet
יצירת נקודת קצה לצרכן ב-Private Service Connect
ב-Cloud Shell, שומרים כתובת IP של נקודת קצה (endpoint) של צרכן שתשמש לגישה אל Google APIs:
gcloud compute addresses create psc-googleapi-ip \ --global \ --purpose=PRIVATE_SERVICE_CONNECT \ --addresses=192.168.0.1 \ --network=vertex-networking-vpcיוצרים כלל העברה כדי לחבר את נקודת הקצה לממשקי API ולשירותים של Google.
gcloud compute forwarding-rules create pscvertex \ --global \ --network=vertex-networking-vpc\ --address=psc-googleapi-ip \ --target-google-apis-bundle=all-apis
יצירת מסלולים מותאמים אישית לפרסום עבור vertex-networking-vpc
בקטע הזה, מגדירים את מצב הפרסום המותאם אישית של Cloud Router לAdvertise custom IP ranges (פרסום של טווחי כתובות IP בהתאמה אישית) עבור vertex-networking-vpc-router1 (Cloud Router עבור vertex-networking-vpc) כדי לפרסם את כתובת ה-IP של נקודת הקצה של PSC ברשת onprem-vpc.
נכנסים לדף Cloud Routers במסוף Google Cloud .
ברשימת Cloud Router, לוחצים על
vertex-networking-vpc-router1.בדף פרטי הנתב, לוחצים על עריכה.
בקטע מסלולים שפורסמו, בשורה מסלולים, בוחרים באפשרות יצירת מסלולים בהתאמה אישית.
מסמנים את תיבת הסימון פרסום כל רשתות המשנה שגלויות ל-Cloud Router כדי להמשיך לפרסם את רשתות המשנה שזמינות ל-Cloud Router. הפעלת האפשרות הזו מדמה את ההתנהגות של Cloud Router במצב ברירת המחדל של פרסום.
לוחצים על הוספת נתיב בהתאמה אישית.
בשדה מקור, בוחרים באפשרות טווח כתובות IP בהתאמה אישית.
בשדה טווח כתובות IP, מזינים את כתובת ה-IP הבאה:
192.168.0.1בקטע תיאור, מזינים את הטקסט הבא:
Custom route to advertise Private Service Connect endpoint IP addressלוחצים על סיום ואז על שמירה.
אימות שלמערכת onprem-vpc יש מידע על המסלולים שמפורסמים
נכנסים לדף Routes במסוף Google Cloud .
בכרטיסייה Effective routes (מסלולים אפקטיביים), מבצעים את הפעולות הבאות:
- בשדה רשת, בוחרים באפשרות
onprem-vpc. - בשדה אזור, בוחרים באפשרות
us-central1 (Iowa). - לוחצים על תצוגה.
ברשימת המסלולים, מוודאים שיש רשומות שהשמות שלהן מתחילים ב-
onprem-vpc-router1-bgp-vertex-networking-vpc-tunnel0וב-onprem-vpc-router1-bgp-vfertex-networking-vpc-tunnel1, ושבשתי הרשומות האלה טווח כתובות ה-IP של היעד הוא192.168.0.1.אם הרשומות האלה לא מופיעות מיד, צריך לחכות כמה דקות ואז לרענן את כרטיסיית הדפדפן של מסוף Google Cloud .
- בשדה רשת, בוחרים באפשרות
יצירת מכונה וירטואלית ב-onprem-vpc שמשתמשת בחשבון שירות שמנוהל על ידי משתמש
בקטע הזה יוצרים מכונת VM שמדמה אפליקציית לקוח מקומית ששולחת בקשות להסקת מסקנות באצווה. בהתאם לשיטות המומלצות של Compute Engine ו-IAM, המכונה הווירטואלית הזו משתמשת בחשבון שירות שמנוהל על ידי המשתמש במקום בחשבון השירות שמוגדר כברירת מחדל של Compute Engine.
יצירת חשבון שירות שמנוהל על ידי משתמש
ב-Cloud Shell, מריצים את הפקודות הבאות ומחליפים את PROJECT_ID במזהה הפרויקט:
projectid=PROJECT_ID gcloud config set project ${projectid}יוצרים חשבון שירות בשם
onprem-user-managed-sa:gcloud iam service-accounts create onprem-user-managed-sa \ --display-name="onprem-user-managed-sa-onprem-client"מקצים לחשבון השירות את התפקיד משתמש ב-Vertex AI (
roles/aiplatform.user):gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:onprem-user-managed-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/aiplatform.user"מקצים לחשבון השירות את התפקיד צפייה באובייקט אחסון (
storage.objectViewer):gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:onprem-user-managed-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/storage.objectViewer"
יצירת מופע של מכונה וירטואלית on-prem-client
למופע של המכונה הווירטואלית שאתם יוצרים אין כתובת IP חיצונית, ואי אפשר לגשת אליו ישירות דרך האינטרנט. כדי להפעיל גישת אדמין למכונה הווירטואלית, משתמשים בהעברת TCP של שרת proxy לאימות זהויות (IAP).
ב-Cloud Shell, יוצרים את המכונה הווירטואלית
on-prem-client:gcloud compute instances create on-prem-client \ --zone=us-central1-a \ --image-family=debian-11 \ --image-project=debian-cloud \ --subnet=onprem-vpc-subnet1 \ --scopes=https://www.googleapis.com/auth/cloud-platform \ --no-address \ --shielded-secure-boot \ --service-account=onprem-user-managed-sa@$projectid.iam.gserviceaccount.com \ --metadata startup-script="#! /bin/bash sudo apt-get update sudo apt-get install tcpdump dnsutils -y"יוצרים כלל חומת אש שמאפשר ל-IAP להתחבר למכונת ה-VM:
gcloud compute firewall-rules create ssh-iap-on-prem-vpc \ --network onprem-vpc \ --allow tcp:22 \ --source-ranges=35.235.240.0/20
אימות הגישה הציבורית ל-Vertex AI API
בקטע הזה משתמשים בכלי dig כדי לבצע חיפוש DNS ממופע של מכונה וירטואלית on-prem-client אל Vertex AI API (us-central1-aiplatform.googleapis.com). הפלט של dig מראה שהגישה שמוגדרת כברירת מחדל משתמשת רק בכתובות IP וירטואליות ציבוריות כדי לגשת אל Vertex AI API.
בקטע הבא נסביר איך מגדירים גישה פרטית ל-Vertex AI API.
ב-Cloud Shell, מתחברים למכונת ה-VM מספר
on-prem-clientבאמצעות IAP:gcloud compute ssh on-prem-client \ --zone=us-central1-a \ --tunnel-through-iapבמכונת ה-VM
on-prem-client, מריצים את הפקודהdig:dig us-central1-aiplatform.googleapis.comאמור להופיע פלט
digשדומה לזה, שבו כתובות ה-IP בקטע התשובה הן כתובות IP ציבוריות:; <<>> DiG 9.16.44-Debian <<>> us-central1.aiplatfom.googleapis.com ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 42506 ;; flags: qr rd ra; QUERY: 1, ANSWER: 16, AUTHORITY: 0, ADDITIONAL: 1 ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags:; udp: 512 ;; QUESTION SECTION: ;us-central1.aiplatfom.googleapis.com. IN A ;; ANSWER SECTION: us-central1.aiplatfom.googleapis.com. 300 IN A 173.194.192.95 us-central1.aiplatfom.googleapis.com. 300 IN A 142.250.152.95 us-central1.aiplatfom.googleapis.com. 300 IN A 172.217.219.95 us-central1.aiplatfom.googleapis.com. 300 IN A 209.85.146.95 us-central1.aiplatfom.googleapis.com. 300 IN A 209.85.147.95 us-central1.aiplatfom.googleapis.com. 300 IN A 142.250.125.95 us-central1.aiplatfom.googleapis.com. 300 IN A 142.250.136.95 us-central1.aiplatfom.googleapis.com. 300 IN A 142.250.148.95 us-central1.aiplatfom.googleapis.com. 300 IN A 209.85.200.95 us-central1.aiplatfom.googleapis.com. 300 IN A 209.85.234.95 us-central1.aiplatfom.googleapis.com. 300 IN A 142.251.171.95 us-central1.aiplatfom.googleapis.com. 300 IN A 108.177.112.95 us-central1.aiplatfom.googleapis.com. 300 IN A 142.250.128.95 us-central1.aiplatfom.googleapis.com. 300 IN A 142.251.6.95 us-central1.aiplatfom.googleapis.com. 300 IN A 172.217.212.95 us-central1.aiplatfom.googleapis.com. 300 IN A 74.125.124.95 ;; Query time: 8 msec ;; SERVER: 169.254.169.254#53(169.254.169.254) ;; WHEN: Wed Sep 27 04:10:16 UTC 2023 ;; MSG SIZE rcvd: 321
הגדרה ואימות של גישה פרטית ל-Vertex AI API
בקטע הזה מוסבר איך להגדיר גישה פרטית ל-Vertex AI API, כך שכשתשלחו בקשות להסקת מסקנות באצווה, הן יופנו מחדש לנקודת הקצה של PSC. נקודת הקצה (endpoint) של PSC מעבירה את הבקשות הפרטיות האלה אל Vertex AI batch inference API בארכיטקטורת REST.
מעדכנים את הקובץ /etc/hosts כך שיפנה לנקודת הקצה של PSC
בשלב הזה מוסיפים שורה לקובץ /etc/hosts שגורמת להפניה מחדש של בקשות שנשלחות לנקודת הקצה של השירות הציבורי (us-central1-aiplatform.googleapis.com) לנקודת הקצה של ה-PSC (192.168.0.1).
במכונה הווירטואלית
on-prem-client, משתמשים בכלי לעריכת טקסט כמוvimאוnanoכדי לפתוח את הקובץ/etc/hosts:sudo vim /etc/hostsמוסיפים את השורה הבאה לקובץ:
192.168.0.1 us-central1-aiplatform.googleapis.comהשורה הזו מקצה את כתובת ה-IP של נקודת הקצה (endpoint) של PSC (
192.168.0.1) לשם דומיין שמוגדר במלואו עבור Vertex AI Google API (us-central1-aiplatform.googleapis.com).הקובץ הערוך צריך להיראות כך:
127.0.0.1 localhost ::1 localhost ip6-localhost ip6-loopback ff02::1 ip6-allnodes ff02::2 ip6-allrouters 192.168.0.1 us-central1-aiplatform.googleapis.com # Added by you 172.16.10.6 on-prem-client.us-central1-a.c.vertex-genai-400103.internal on-prem-client # Added by Google 169.254.169.254 metadata.google.internal # Added by Googleשומרים את הקובץ באופן הבא:
- אם אתם משתמשים ב-
vim, לוחצים על המקשEsc, ואז מקלידים:wqכדי לשמור את הקובץ ולצאת. - אם אתם משתמשים ב-
nano, מקלידיםControl+Oומקישים עלEnterכדי לשמור את הקובץ, ואז מקלידיםControl+Xכדי לצאת.
- אם אתם משתמשים ב-
מבצעים פינג לנקודת הקצה של Vertex AI באופן הבא:
ping us-central1-aiplatform.googleapis.comהפלט הבא אמור להתקבל באמצעות הפקודה
ping. 192.168.0.1היא כתובת ה-IP של נקודת הקצה (endpoint) של PSC:PING us-central1-aiplatform.googleapis.com (192.168.0.1) 56(84) bytes of data.מקלידים
Control+Cכדי לצאת מ-ping.מקלידים
exitכדי לצאת מהמכונה הווירטואליתon-prem-client.
יוצרים חשבון שירות שמנוהל על ידי משתמש עבור Vertex AI Workbench ב-vertex-networking-vpc
בקטע הזה, כדי לשלוט בגישה למופע של Vertex AI Workbench, יוצרים חשבון שירות בניהול משתמשים ואז מקצים לחשבון השירות תפקידי IAM. כשיוצרים את המכונה, מציינים את חשבון השירות.
ב-Cloud Shell, מריצים את הפקודות הבאות ומחליפים את PROJECT_ID במזהה הפרויקט:
projectid=PROJECT_ID gcloud config set project ${projectid}יוצרים חשבון שירות בשם
workbench-sa:gcloud iam service-accounts create workbench-sa \ --display-name="workbench-sa"מקצים לחשבון השירות את התפקיד משתמש ב-Vertex AI (
roles/aiplatform.user) ב-IAM:gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:workbench-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/aiplatform.user"מקצים לחשבון השירות את תפקיד ה-IAM BigQuery User (
roles/bigquery.user):gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:workbench-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/bigquery.user"מקצים לחשבון השירות את התפקיד אדמין אחסון (
roles/storage.admin) ב-IAM:gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:workbench-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/storage.admin"מקצים לחשבון השירות את התפקיד Logs Viewer (
roles/logging.viewer) ב-IAM:gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:workbench-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/logging.viewer"
יצירת מכונה של Vertex AI Workbench
ב-Cloud Shell, יוצרים מכונת Vertex AI Workbench ומציינים את
workbench-saחשבון השירות:gcloud workbench instances create workbench-tutorial \ --vm-image-project=deeplearning-platform-release \ --vm-image-family=common-cpu-notebooks \ --machine-type=n1-standard-4 \ --location=us-central1-a \ --subnet-region=us-central1 \ --shielded-secure-boot=True \ --subnet=workbench-subnet \ --disable-public-ip \ --service-account-email=workbench-sa@$projectid.iam.gserviceaccount.comנכנסים לכרטיסייה Instances בדף Vertex AI Workbench במסוף Google Cloud .
לצד השם של מופע Vertex AI Workbench (
workbench-tutorial), לוחצים על Open JupyterLab.המכונה שלכם ב-Vertex AI Workbench תיפתח ב-JupyterLab.
בוחרים באפשרות קובץ > חדש > מחברת.
בתפריט Select Kernel (בחירת ליבה), בוחרים באפשרות Python 3 (Local) (פייתון 3 (מקומי)) ולוחצים על Select (בחירה).
כשפותחים את ה-Notebook החדש, יש תא קוד שמוגדר כברירת מחדל שאפשר להזין בו קוד. נראה כמו
[ ]:ואחריו שדה טקסט. בשדה הטקסט מדביקים את הקוד.כדי להתקין את Vertex AI SDK ל-Python, מדביקים את הקוד הבא בתא ולוחצים על Run the selected cells and advance (הפעלת התאים שנבחרו ומעבר לתא הבא):
!pip3 install --upgrade google-cloud-bigquery scikit-learn==1.2בשלב הזה ובכל אחד מהשלבים הבאים, מוסיפים תא קוד חדש (אם צריך) על ידי לחיצה על הוספת תא מתחת, מדביקים את הקוד בתא ואז לוחצים על הפעלת התאים שנבחרו ומעבר.
כדי להשתמש בחבילות החדשות שהותקנו בסביבת זמן הריצה הזו של Jupyter, צריך להפעיל מחדש את סביבת זמן הריצה:
# Restart kernel after installs so that your environment can access the new packages import IPython app = IPython.Application.instance() app.kernel.do_shutdown(True)מגדירים את משתני הסביבה הבאים במחברת JupyterLab, ומחליפים את PROJECT_ID במזהה הפרויקט.
# set project ID and location PROJECT_ID = "PROJECT_ID" REGION = "us-central1"יוצרים קטגוריה של Cloud Storage לאחסון זמני של משימת האימון:
BUCKET_NAME = f"{PROJECT_ID}-ml-staging" BUCKET_URI = f"gs://{BUCKET_NAME}" !gcloud storage buckets create {BUCKET_URI} --location={REGION} --project={PROJECT_ID}
הכנת נתוני האימון
בקטע הזה מכינים נתונים שישמשו לאימון של מודל הסקה.
במחברת JupyterLab, יוצרים לקוח BigQuery:
from google.cloud import bigquery bq_client = bigquery.Client(project=PROJECT_ID)שליפת נתונים ממערך הנתונים הציבורי
ml_datasetsשל BigQuery:DATA_SOURCE = "bigquery-public-data.ml_datasets.census_adult_income" # Define the SQL query to fetch the dataset query = f""" SELECT * FROM `{DATA_SOURCE}` LIMIT 20000 """ # Download the dataset to a dataframe df = bq_client.query(query).to_dataframe() df.head()משתמשים בספריית
sklearnכדי לפצל את הנתונים לצורך אימון ובדיקה:from sklearn.model_selection import train_test_split # Split the dataset X_train, X_test = train_test_split(df, test_size=0.3, random_state=43) # Print the shapes of train and test sets print(X_train.shape, X_test.shape)מייצאים את מסגרות הנתונים של האימון והבדיקה לקובצי CSV בקטגוריית האחסון הזמני:
X_train.to_csv(f"{BUCKET_URI}/train.csv",index=False, quoting=1, quotechar='"') X_test[[i for i in X_test.columns if i != "income_bracket"]].iloc[:20].to_csv(f"{BUCKET_URI}/test.csv",index=False,quoting=1, quotechar='"')
הכנת אפליקציית האימון
בקטע הזה מוסבר איך ליצור ולבנות את אפליקציית ההדרכה ב-Python ולשמור אותה בקטגוריית האחסון הזמני.
ב-notebook של JupyterLab, יוצרים תיקייה חדשה לקבצים של אפליקציית האימון:
!mkdir -p training_package/trainerעכשיו אמורה להופיע תיקייה בשם
training_packageבתפריט הניווט של JupyterLab.מגדירים את התכונות, היעד, התווית והשלבים לאימון המודל ולייצוא שלו לקובץ:
%%writefile training_package/trainer/task.py from sklearn.ensemble import RandomForestClassifier from sklearn.feature_selection import SelectKBest from sklearn.pipeline import FeatureUnion, Pipeline from sklearn.preprocessing import LabelBinarizer import pandas as pd import argparse import joblib import os TARGET = "income_bracket" # Define the feature columns that you use from the dataset COLUMNS = ( "age", "workclass", "functional_weight", "education", "education_num", "marital_status", "occupation", "relationship", "race", "sex", "capital_gain", "capital_loss", "hours_per_week", "native_country", ) # Categorical columns are columns that have string values and # need to be turned into a numerical value to be used for training CATEGORICAL_COLUMNS = ( "workclass", "education", "marital_status", "occupation", "relationship", "race", "sex", "native_country", ) # load the arguments parser = argparse.ArgumentParser() parser.add_argument('--training-dir', dest='training_dir', default=os.getenv('AIP_MODEL_DIR'), type=str,help='get the staging directory') args = parser.parse_args() # Load the training data X_train = pd.read_csv(os.path.join(args.training_dir,"train.csv")) # Remove the column we are trying to predict ('income-level') from our features list # Convert the Dataframe to a lists of lists train_features = X_train.drop(TARGET, axis=1).to_numpy().tolist() # Create our training labels list, convert the Dataframe to a lists of lists train_labels = X_train[TARGET].to_numpy().tolist() # Since the census data set has categorical features, we need to convert # them to numerical values. We'll use a list of pipelines to convert each # categorical column and then use FeatureUnion to combine them before calling # the RandomForestClassifier. categorical_pipelines = [] # Each categorical column needs to be extracted individually and converted to a numerical value. # To do this, each categorical column will use a pipeline that extracts one feature column via # SelectKBest(k=1) and a LabelBinarizer() to convert the categorical value to a numerical one. # A scores array (created below) will select and extract the feature column. The scores array is # created by iterating over the COLUMNS and checking if it is a CATEGORICAL_COLUMN. for i, col in enumerate(COLUMNS): if col in CATEGORICAL_COLUMNS: # Create a scores array to get the individual categorical column. # Example: # data = [39, 'State-gov', 77516, 'Bachelors', 13, 'Never-married', 'Adm-clerical', # 'Not-in-family', 'White', 'Male', 2174, 0, 40, 'United-States'] # scores = [0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0] # # Returns: [['Sate-gov']] scores = [] # Build the scores array for j in range(len(COLUMNS)): if i == j: # This column is the categorical column we want to extract. scores.append(1) # Set to 1 to select this column else: # Every other column should be ignored. scores.append(0) skb = SelectKBest(k=1) skb.scores_ = scores # Convert the categorical column to a numerical value lbn = LabelBinarizer() r = skb.transform(train_features) lbn.fit(r) # Create the pipeline to extract the categorical feature categorical_pipelines.append( ( "categorical-{}".format(i), Pipeline([("SKB-{}".format(i), skb), ("LBN-{}".format(i), lbn)]), ) ) # Create pipeline to extract the numerical features skb = SelectKBest(k=6) # From COLUMNS use the features that are numerical skb.scores_ = [1, 0, 1, 0, 1, 0, 0, 0, 0, 0, 1, 1, 1, 0] categorical_pipelines.append(("numerical", skb)) # Combine all the features using FeatureUnion preprocess = FeatureUnion(categorical_pipelines) # Create the classifier classifier = RandomForestClassifier() # Transform the features and fit them to the classifier classifier.fit(preprocess.transform(train_features), train_labels) # Create the overall model as a single pipeline pipeline = Pipeline([("union", preprocess), ("classifier", classifier)]) # Save the model pipeline joblib.dump(pipeline, os.path.join(args.training_dir,"model.joblib"))יוצרים קובץ
__init__.pyבכל תיקיית משנה כדי להפוך אותה לחבילה:!touch training_package/__init__.py !touch training_package/trainer/__init__.pyיוצרים סקריפט הגדרה של חבילת Python:
%%writefile training_package/setup.py from setuptools import find_packages from setuptools import setup setup( name='trainer', version='0.1', packages=find_packages(), include_package_data=True, description='Training application package for census income classification.' )משתמשים בפקודה
sdistכדי ליצור את הפצת המקור של אפליקציית האימון:!cd training_package && python setup.py sdist --formats=gztarמעתיקים את חבילת Python לקטגוריית האחסון הזמני:
!gcloud storage cp training_package/dist/trainer-0.1.tar.gz $BUCKET_URI/מוודאים שמאגר הנתונים הזמני מכיל שלושה קבצים:
!gcloud storage ls $BUCKET_URIהפלט צריך להיות:
gs://$BUCKET_NAME/test.csv gs://$BUCKET_NAME/train.csv gs://$BUCKET_NAME/trainer-0.1.tar.gz
אימון המודל
בקטע הזה, מאמנים את המודל על ידי יצירה והרצה של משימת אימון בהתאמה אישית.
במחברת JupyterLab, מריצים את הפקודה הבאה כדי ליצור משימת אימון בהתאמה אישית:
!gcloud ai custom-jobs create --display-name=income-classification-training-job \ --project=$PROJECT_ID \ --worker-pool-spec=replica-count=1,machine-type='e2-highmem-2',executor-image-uri='us-docker.pkg.dev/vertex-ai/training/sklearn-cpu.1-0:latest',python-module=trainer.task \ --python-package-uris=$BUCKET_URI/trainer-0.1.tar.gz \ --args="--training-dir","/gcs/$BUCKET_NAME" \ --region=$REGIONהפלט אמור להיראות כך: המספר הראשון בכל נתיב של משימה מותאמת אישית הוא מספר הפרויקט (PROJECT_NUMBER). המספר השני הוא מזהה המשימה המותאמת אישית (CUSTOM_JOB_ID). כדאי לרשום את המספרים האלה כדי להשתמש בהם בשלב הבא.
Using endpoint [https://us-central1-aiplatform.googleapis.com/] CustomJob [projects/721032480027/locations/us-central1/customJobs/1100328496195960832] is submitted successfully. Your job is still active. You may view the status of your job with the command $ gcloud ai custom-jobs describe projects/721032480027/locations/us-central1/customJobs/1100328496195960832 or continue streaming the logs with the command $ gcloud ai custom-jobs stream-logs projects/721032480027/locations/us-central1/customJobs/1100328496195960832מריצים את משימת האימון בהתאמה אישית ומציגים את ההתקדמות על ידי סטרימינג של יומנים מהמשימה בזמן שהיא פועלת:
!gcloud ai custom-jobs stream-logs projects/PROJECT_NUMBER/locations/us-central1/customJobs/CUSTOM_JOB_IDמחליפים את הערכים הבאים:
- PROJECT_NUMBER: מספר הפרויקט מהפלט של הפקודה הקודמת
- CUSTOM_JOB_ID: מזהה המשימה המותאם אישית מהפלט של הפקודה הקודמת
עכשיו מופעלת עבודת האימון המותאמת אישית. התהליך אורך כ-10 דקות.
כשהמשימה מסתיימת, אפשר לייבא את המודל ממאגר הנתונים הזמני אל מרשם המודלים של Vertex AI.
ייבוא המודל
משימת האימון המותאמת אישית מעלה את המודל המאומן לקטגוריית ה-staging. אחרי שהמשימה מסתיימת, אפשר לייבא את המודל מהמאגר אל מרשם המודלים של Vertex AI.
ב-notebook של JupyterLab, מייבאים את המודל על ידי הרצת הפקודה הבאה:
!gcloud ai models upload --container-image-uri="us-docker.pkg.dev/vertex-ai/prediction/sklearn-cpu.1-2:latest" \ --display-name=income-classifier-model \ --artifact-uri=$BUCKET_URI \ --project=$PROJECT_ID \ --region=$REGIONמציגים ברשימה את המודלים של Vertex AI בפרויקט באופן הבא:
!gcloud ai models list --region=us-central1הפלט אמור להיראות כך: אם מופיעים שני מודלים או יותר, המודל הראשון ברשימה הוא זה שיובא לאחרונה.
רושמים את הערך בעמודה MODEL_ID. הוא נדרש כדי ליצור את בקשת ההסקה באצווה.
Using endpoint [https://us-central1-aiplatform.googleapis.com/] MODEL_ID DISPLAY_NAME 1871528219660779520 income-classifier-modelאפשר גם להציג את רשימת המודלים בפרויקט באופן הבא:
במסוף Google Cloud , בקטע Vertex AI, עוברים לדף מרשם המודלים של Vertex AI.
מעבר לדף מרשם המודלים של Vertex AI
כדי לראות את מזהי המודלים ופרטים נוספים על מודל, לוחצים על שם המודל ואז על הכרטיסייה פרטי הגרסה.
קבלת מסקנות אצווה מהמודל
עכשיו אפשר לבקש מהמודל מסקנות אצווה. בקשות להסקת מסקנות באצווה מוגשות ממכונת ה-VM on-prem-client.
יצירת בקשת הסקה באצווה
בשלב הזה, משתמשים ב-ssh כדי להתחבר למכונה הווירטואלית on-prem-client.
במכונת ה-VM, יוצרים קובץ טקסט בשם request.json שמכיל את מטען הייעודי (payload) של בקשת curl לדוגמה ששולחים למודל כדי לקבל מסקנות אצווה.
ב-Cloud Shell, מריצים את הפקודות הבאות ומחליפים את PROJECT_ID במזהה הפרויקט:
projectid=PROJECT_ID gcloud config set project ${projectid}מתחברים למכונה הווירטואלית
on-prem-clientבאמצעותssh:gcloud compute ssh on-prem-client \ --project=$projectid \ --zone=us-central1-aבמכונה הווירטואלית
on-prem-client, משתמשים בכלי לעריכת טקסט כמוvimאוnanoכדי ליצור קובץ חדש בשםrequest.jsonשמכיל את הטקסט הבא:{ "displayName": "income-classification-batch-job", "model": "projects/PROJECT_ID/locations/us-central1/models/MODEL_ID", "inputConfig": { "instancesFormat": "csv", "gcsSource": { "uris": ["BUCKET_URI/test.csv"] } }, "outputConfig": { "predictionsFormat": "jsonl", "gcsDestination": { "outputUriPrefix": "BUCKET_URI" } }, "dedicatedResources": { "machineSpec": { "machineType": "n1-standard-4", "acceleratorCount": "0" }, "startingReplicaCount": 1, "maxReplicaCount": 2 } }מחליפים את הערכים הבאים:
- PROJECT_ID: מזהה הפרויקט
- MODEL_ID: מזהה המודל של המודל שלכם
- BUCKET_URI: ה-URI של קטגוריית האחסון שבה העליתם את המודל
מריצים את הפקודה הבאה כדי לשלוח את בקשת ההסקה של אצווה:
curl -X POST \ -H "Authorization: Bearer $(gcloud auth print-access-token)" \ -H "Content-Type: application/json; charset=utf-8" \ -d @request.json \ "https://us-central1-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/us-central1/batchPredictionJobs"מחליפים את PROJECT_ID במזהה הפרויקט.
אמורה להופיע השורה הבאה בתגובה:
"state": "JOB_STATE_PENDING"עכשיו העבודה שלכם להסקת מסקנות בקבוצות פועלת באופן אסינכרוני. התהליך נמשך כ-20 דקות.
במסוף Google Cloud , בקטע Vertex AI, עוברים לדף Batch predictions.
בזמן שפעולת ההסקה באצווה פועלת, הסטטוס שלה הוא
Running. כשההעברה מסתיימת, הסטטוס שלה משתנה ל-Finished.לוחצים על השם של משימת ההסקה באצווה (
income-classification-batch-job), ואז לוחצים על הקישור Export location בדף הפרטים כדי לראות את קובצי הפלט של משימת האצווה ב-Cloud Storage.לחלופין, אפשר ללחוץ על הסמל הצגת פלט התחזית ב-Cloud Storage (בין העמודה העדכון האחרון לבין התפריט פעולות).
לוחצים על הקישור לקובץ
prediction.results-00000-of-00002אוprediction.results-00001-of-00002, ואז לוחצים על הקישור כתובת URL מאומתת כדי לפתוח את הקובץ.הפלט של משימת ההסקה באצווה אמור להיראות כמו בדוגמה הזו:
{"instance": ["27", " Private", "391468", " 11th", "7", " Divorced", " Craft-repair", " Own-child", " White", " Male", "0", "0", "40", " United-States"], "prediction": " <=50K"} {"instance": ["47", " Self-emp-not-inc", "192755", " HS-grad", "9", " Married-civ-spouse", " Machine-op-inspct", " Wife", " White", " Female", "0", "0", "20", " United-States"], "prediction": " <=50K"} {"instance": ["32", " Self-emp-not-inc", "84119", " HS-grad", "9", " Married-civ-spouse", " Craft-repair", " Husband", " White", " Male", "0", "0", "45", " United-States"], "prediction": " <=50K"} {"instance": ["32", " Private", "236543", " 12th", "8", " Divorced", " Protective-serv", " Own-child", " White", " Male", "0", "0", "54", " Mexico"], "prediction": " <=50K"} {"instance": ["60", " Private", "160625", " HS-grad", "9", " Married-civ-spouse", " Prof-specialty", " Husband", " White", " Male", "5013", "0", "40", " United-States"], "prediction": " <=50K"} {"instance": ["34", " Local-gov", "22641", " HS-grad", "9", " Never-married", " Protective-serv", " Not-in-family", " Amer-Indian-Eskimo", " Male", "0", "0", "40", " United-States"], "prediction": " <=50K"} {"instance": ["32", " Private", "178623", " HS-grad", "9", " Never-married", " Other-service", " Not-in-family", " Black", " Female", "0", "0", "40", " ?"], "prediction": " <=50K"} {"instance": ["28", " Private", "54243", " HS-grad", "9", " Divorced", " Transport-moving", " Not-in-family", " White", " Male", "0", "0", "60", " United-States"], "prediction": " <=50K"} {"instance": ["29", " Local-gov", "214385", " 11th", "7", " Divorced", " Other-service", " Unmarried", " Black", " Female", "0", "0", "20", " United-States"], "prediction": " <=50K"} {"instance": ["49", " Self-emp-inc", "213140", " HS-grad", "9", " Married-civ-spouse", " Exec-managerial", " Husband", " White", " Male", "0", "1902", "60", " United-States"], "prediction": " >50K"}
הסרת המשאבים
כדי להימנע מחיובים בחשבון Google Cloud על המשאבים שבהם השתמשתם במדריך הזה, אתם יכולים למחוק את הפרויקט שמכיל את המשאבים, או להשאיר את הפרויקט ולמחוק את המשאבים בנפרד.
אפשר למחוק את המשאבים הבודדים במסוף Google Cloud באופן הבא:
כדי למחוק את משימת ההסקה באצווה:
במסוף Google Cloud , בקטע Vertex AI, עוברים לדף Batch predictions.
לצד השם של משימת ההסקה באצווה (
income-classification-batch-job), לוחצים על התפריט פעולות ובוחרים באפשרות מחיקת משימת חיזוי באצווה.
כדי למחוק את המודל:
במסוף Google Cloud , בקטע Vertex AI, עוברים לדף מרשם המודלים.
לצד שם המודל (
income-classifier-model), לוחצים על תפריט הפעולות ובוחרים באפשרות מחיקת המודל.
כדי למחוק את המכונה של Vertex AI Workbench:
במסוף Google Cloud , בקטע Vertex AI, עוברים לכרטיסייה Instances בדף Workbench.
בוחרים את
workbench-tutorialהמופע של Vertex AI Workbench ולוחצים על מחיקה.
כדי למחוק את המכונה הווירטואלית של Compute Engine:
במסוף Google Cloud , נכנסים לדף Compute Engine.
בוחרים את
on-prem-clientמכונת ה-VM ולוחצים על מחיקה.
מוחקים את מנהרות ה-VPN באופן הבא:
נכנסים לדף VPN במסוף Google Cloud .
בדף VPN, לוחצים על הכרטיסייה Cloud VPN Tunnels (מנהרות Cloud VPN).
ברשימת מנהרות ה-VPN, בוחרים את ארבע מנהרות ה-VPN שיצרתם במדריך הזה ולוחצים על מחיקה.
כדי למחוק את שערי HA VPN:
בדף VPN, לוחצים על הכרטיסייה Cloud VPN Gateways.
ברשימת שערי ה-VPN, לוחצים על
onprem-vpn-gw1.בדף Cloud VPN gateway details (פרטי שער Cloud VPN), לוחצים על Delete VPN Gateway (מחיקת שער VPN).
לוחצים על החץ 'חזרה' אם צריך לחזור לרשימת שערים של VPN, ואז לוחצים על
vertex-networking-vpn-gw1.בדף Cloud VPN gateway details (פרטי שער Cloud VPN), לוחצים על Delete VPN Gateway (מחיקת שער VPN).
כדי למחוק את Cloud Routers:
עוברים לדף Cloud Routers.
ברשימת נתבי Cloud, בוחרים את ארבעת הנתבים שיצרתם במדריך הזה.
כדי למחוק את הנתבים, לוחצים על מחיקה .
פעולה זו תמחק גם את שני שערי Cloud NAT שמחוברים ל-Cloud Routers.
מוחקים את
pscvertexכלל העברת התנועה עבור רשת ה-VPC vertex-networking-vpcבאופן הבא:עוברים לכרטיסייה קצה קדמי בדף איזון עומסים.
ברשימת כללי ההעברה, לוחצים על
pscvertex.בדף פרטי כלל ההעברה, לוחצים על מחיקה.
כדי למחוק את רשתות ה-VPC:
עוברים לדף VPC networks.
ברשימת רשתות ה-VPC, לוחצים על
onprem-vpc.בדף VPC network details (פרטי רשת VPC), לוחצים על Delete VPC Network (מחיקת רשת VPC).
מחיקה של כל רשת מוחקת גם את רשתות המשנה, המסלולים וכללי חומת האש שלה.
ברשימת רשתות ה-VPC, לוחצים על
vertex-networking-vpc.בדף VPC network details (פרטי רשת VPC), לוחצים על Delete VPC Network (מחיקת רשת VPC).
כדי למחוק את קטגוריית האחסון:
פותחים את הדף Cloud Storage במסוף Google Cloud .
בוחרים את דלי האחסון ולוחצים על מחיקה.
מוחקים את חשבונות השירות
workbench-saו-onprem-user-managed-saבאופן הבא:עוברים לדף Service accounts.
בוחרים את חשבונות השירות
onprem-user-managed-saו-workbench-saולוחצים על מחיקה.
המאמרים הבאים
- מידע על אפשרויות של רשתות ארגוניות לגישה לנקודות קצה ולשירותים של Vertex AI
- איך Private Service Connect עובד ולמה הוא מציע יתרונות משמעותיים בביצועים.
- כך משתמשים ב-VPC Service Controls כדי ליצור גבולות גזרה מאובטחים כדי לאפשר או לחסום גישה ל-Vertex AI ול-Google APIs אחרים בנקודת הקצה של ההיקש אונליין.
- כאן מוסבר איך משתמשים באזור העברת DNS במקום לעדכן את הקובץ
/etc/hostsבסביבות ייצור ובסביבות גדולות, וגם למה כדאי לעשות את זה.