
כדי לאחזר נתוני תכונות לאימון המודל, משתמשים בשליפת נתונים ב-batch. אם אתם צריכים לייצא ערכי תכונות לצורך ארכיון או ניתוח אד-הוק, אתם יכולים לייצא ערכי תכונות.
אחזור ערכי תכונות לאימון המודל
כדי לאמן מודל, צריך מערך נתונים לאימון שמכיל דוגמאות של משימת החיזוי. הדוגמאות האלה מורכבות ממופעים שכוללים את התכונות והתוויות שלהם. המופע הוא הדבר שרוצים ליצור לגביו תחזית. לדוגמה, נניח שהמופע הוא בית, ואתם רוצים לקבוע את שווי השוק שלו. התכונות האלה יכולות לכלול את המיקום, הגיל והמחיר הממוצע של בתים סמוכים שנמכרו לאחרונה. תווית היא תשובה למשימת החיזוי, למשל: הבית נמכר בסופו של דבר ב-100,000$.
מכיוון שכל תווית היא תצפית בנקודת זמן ספציפית, צריך לאחזר ערכי תכונות שתואמים לנקודת הזמן שבה התצפית בוצעה – לדוגמה, המחירים של בתים סמוכים כשבית מסוים נמכר. הערכים של התכונות משתנים עם הזמן, ככל שנאספים יותר נתונים לגבי התוויות והתכונות. ב-Vertex AI Feature Store (גרסה קודמת) אפשר לבצע חיפוש של נתונים בזמן מסוים, כדי לאחזר את ערכי התכונות בנקודת זמן מסוימת.
דוגמה לחיפוש בנקודת זמן
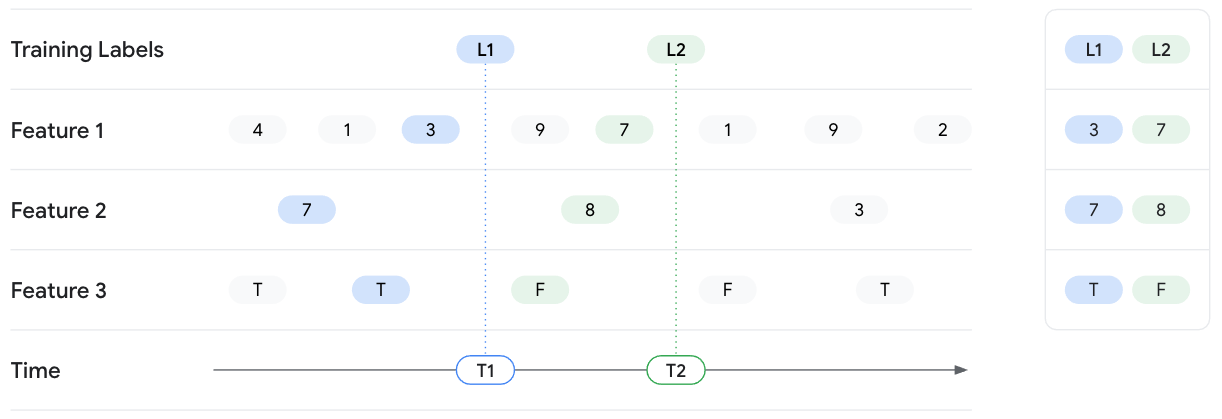
בדוגמה הבאה, המערכת מאחזרת ערכי תכונות עבור שני מקרים של אימון עם תוויות L1 ו-L2. שתי התוויות נצפו במיקומים T1 ו-T2, בהתאמה. תארו לעצמכם שאתם מקפיאים את מצב ערכי התכונות בחותמות הזמן האלה. לכן, בחיפוש לפי נקודת זמן ב-T1, Vertex AI Feature Store (Legacy) מחזיר את ערכי התכונות האחרונים עד לזמן T1 עבור Feature 1, Feature 2 ו-Feature 3, ולא חושף ערכים אחרי T1. ככל שהזמן עובר, ערכי התכונות משתנים וגם התווית משתנה. לכן, בנקודת הזמן T2, Feature Store מחזיר ערכי תכונות שונים.
נתוני קלט לשליפת נתונים ב-batch
כחלק מבקשת שליפת נתונים ב-batch, נדרשים הפרטים הבאים:
- רשימה של תכונות קיימות שאפשר לקבל את הערכים שלהן.
- רשימת מקרים לקריאה שמכילה מידע על כל דוגמה לאימון.
הוא מציג רשימה של תצפיות בנקודת זמן מסוימת. יכול להיות שזה קובץ CSV או טבלה ב-BigQuery. הרשימה צריכה לכלול את הפרטים הבאים:
- חותמות זמן: השעות שבהן התוויות נצפו או נמדדו. חותמות הזמן נדרשות כדי ש-Vertex AI Feature Store (גרסה קודמת) יוכל לבצע חיפוש של נתונים בנקודת זמן מסוימת.
- מזהי ישויות: מזהה אחד או יותר של הישויות שתואמות לתווית.
- ה-URI והפורמט של היעד שאליו ייכתב הפלט. בפלט, Vertex AI Feature Store (Legacy) מאחד למעשה את הטבלה מרשימת מופעי הקריאה ואת ערכי התכונות ממאגר הפיצ'רים. מציינים אחד מהפורמטים והמיקומים הבאים לפלט:
- טבלה ב-BigQuery במערך נתונים אזורי או במספר אזורים.
- קובץ CSV בקטגוריה אזורית או רב-אזורית של Cloud Storage. אבל אם ערכי התכונות כוללים מערכים, צריך לבחור פורמט אחר.
- קובץ Tfrecord בקטגוריה של Cloud Storage.
דרישות אזוריות
גם מופעי הקריאה וגם היעד צריכים להיות באותו אזור או באותו מיקום רב-אזורי כמו מאגר התכונות. לדוגמה, מאגר פיצ'רים ב-us-central1 יכול לקרוא נתונים מקטגוריות של Cloud Storage או ממערכי נתונים ב-BigQuery שנמצאים ב-us-central1 או במיקום במספר אזורים בארה"ב, או להעביר אליהם נתונים. לדוגמה, אי אפשר להשתמש בנתונים מ-us-east1. בנוסף, אין תמיכה בקריאה או בהצגה של נתונים באמצעות קטגוריות בשני אזורים.
רשימת מכונות לקריאה
ברשימת המופעים לקריאה מציינים את הישויות ואת חותמות הזמן של ערכי התכונות שרוצים לאחזר. קובץ ה-CSV או טבלת BigQuery חייבים להכיל את העמודות הבאות, בכל סדר. צריך להוסיף כותרת לכל עמודה.
- חובה לכלול עמודה של חותמות זמן, ששם הכותרת שלה הוא
timestampוהערכים בעמודה הם חותמות זמן בפורמט RFC 3339. - חובה לכלול עמודה אחת או יותר של סוגי ישויות, כאשר הכותרת היא מזהה סוג הישות והערכים בעמודה הם מזהי הישויות.
- אופציונלי: אפשר לכלול ערכים להעברה (עמודות נוספות), שמועברים כמו שהם לפלט. האפשרות הזו שימושית אם יש לכם נתונים שלא נמצאים ב-Vertex AI Feature Store (גרסה קודמת), אבל אתם רוצים לכלול את הנתונים האלה בפלט.
דוגמה (CSV)
נניח שיש מאגר פיצ'רים שמכיל את סוגי הישויות users ו-movies יחד עם הפיצ'רים שלהן. לדוגמה, התכונות של users יכולות לכלול את age ו-gender, והתכונות של movies יכולות לכלול את ratings ו-genre.
בדוגמה הזו, אתם רוצים לאסוף נתוני אימון על העדפות של משתמשים לגבי סרטים. אתם מאחזרים את ערכי התכונות של שתי ישויות המשתמשים alice ו-bob, יחד עם תכונות מהסרטים שהם צפו בהם. ממערך נתונים נפרד, אתם יודעים שalice צפה בmovie_01 וסימן לייק. bob צפה בתוכן movie_02 ולא אהב אותו. לכן, רשימת מכונות לקריאה יכולה להיראות כמו בדוגמה הבאה:
users,movies,timestamp,liked "alice","movie_01",2021-04-15T08:28:14Z,true "bob","movie_02",2021-04-15T08:28:14Z,false
Vertex AI Feature Store (Legacy) מאחזר ערכי תכונות עבור הישויות שמופיעות ברשימה, בזמן שצוין או לפניו. אתם מציינים את התכונות הספציפיות שרוצים לקבל כחלק מבקשת שליפת נתונים ב-batch, ולא ברשימת מופעי הקריאה.
בדוגמה הזו יש גם עמודה בשם liked, שמציינת אם משתמש אהב סרט. העמודה הזו לא נכללת במאגר התכונות, אבל עדיין אפשר להעביר את הערכים האלה לפלט של שליפת נתונים ב-batch. בפלט, הערכים האלה של העברת נתונים מצורפים לערכים ממאגר פיצ'רים.
ערכי Null
אם ערך של מאפיין הוא null בחותמת זמן מסוימת, Feature Store של Vertex AI (גרסה קודמת) מחזיר את הערך הקודם של המאפיין שהוא לא null. אם אין ערכים קודמים, Vertex AI Feature Store (Legacy) מחזיר null.
הצגת ערכי תכונות בכמות גדולה
אפשר להשתמש בתכונה 'שליפת נתונים ב-batch' ממאגר פיצ'רים כדי לקבל נתונים, כפי שנקבע על ידי קובץ רשימת מופעי הקריאה.
אם רוצים להקטין את עלויות השימוש בנפח אחסון נדרש אופליין על ידי קריאת נתוני אימון עדכניים והחרגת נתונים ישנים, צריך לציין שעת התחלה. במאמר איך מציינים שעת התחלה כדי לייעל את עלויות האחסון במצב אופליין במהלך שליפת נתונים ב-batch וייצוא של נתונים באצווה מוסבר איך לציין שעת התחלה כדי להפחית את עלויות השימוש בנפח אחסון נדרש במצב אופליין.
ממשק משתמש באינטרנט
אפשר לנסות שיטה אחרת. אי אפשר להציג תכונות בקבוצות דרך מסוףGoogle Cloud .
REST
כדי להציג ערכי תכונות באצווה, שולחים בקשת POST באמצעות השיטה featurestores.batchReadFeatureValues.
בדוגמה הבאה מוצגת טבלה ב-BigQuery שמכילה ערכי מאפיינים עבור סוגי הישויות users ו-movies. הערה:
יכול להיות שלכל יעד פלט יש דרישות מוקדמות שצריך לעמוד בהן לפני ששולחים בקשה. לדוגמה, אם מציינים שם טבלה בשדה bigqueryDestination, צריך שיהיה קיים מערך נתונים. הדרישות האלה מתועדות בהפניית ה-API.
לפני שמשתמשים בנתוני הבקשה, צריך להחליף את הנתונים הבאים:
- LOCATION_ID: האזור שבו נוצר מאגר הפיצ'רים. לדוגמה,
us-central1. - PROJECT_ID: מזהה הפרויקט.
- FEATURESTORE_ID: מזהה של מאגר התכונות.
- DATASET_NAME: השם של מערך הנתונים ביעד ב-BigQuery.
- TABLE_NAME: השם של טבלת היעד ב-BigQuery.
- STORAGE_LOCATION: URI של Cloud Storage לקובץ ה-CSV של מופעי הקריאה.
ה-method של ה-HTTP וכתובת ה-URL:
POST https://LOCATION_ID-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION_ID/featurestores/FEATURESTORE_ID:batchReadFeatureValues
גוף בקשת JSON:
{
"destination": {
"bigqueryDestination": {
"outputUri": "bq://PROJECT_ID.DATASET_NAME.TABLE_NAME"
}
},
"csvReadInstances": {
"gcsSource": {
"uris": ["STORAGE_LOCATION"]
}
},
"entityTypeSpecs": [
{
"entityTypeId": "users",
"featureSelector": {
"idMatcher": {
"ids": ["age", "liked_genres"]
}
}
},
{
"entityTypeId": "movies",
"featureSelector": {
"idMatcher": {
"ids": ["title", "average_rating", "genres"]
}
}
}
],
"passThroughFields": [
{
"fieldName": "liked"
}
]
}
כדי לשלוח את הבקשה עליכם לבחור אחת מהאפשרויות הבאות:
curl
שומרים את גוף הבקשה בקובץ בשם request.json ומריצים את הפקודה הבאה:
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION_ID-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION_ID/featurestores/FEATURESTORE_ID:batchReadFeatureValues"
PowerShell
שומרים את גוף הבקשה בקובץ בשם request.json ומריצים את הפקודה הבאה:
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://LOCATION_ID-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION_ID/featurestores/FEATURESTORE_ID:batchReadFeatureValues" | Select-Object -Expand Content
הפלט שיוצג אמור להיות דומה לזה שמופיע כאן. אפשר להשתמש ב-OPERATION_ID בתגובה כדי לקבל את הסטטוס של הפעולה.
{
"name": "projects/PROJECT_NUMBER/locations/LOCATION_ID/featurestores/FEATURESTORE_ID/operations/OPERATION_ID",
"metadata": {
"@type": "type.googleapis.com/google.cloud.aiplatform.v1.BatchReadFeatureValuesOperationMetadata",
"genericMetadata": {
"createTime": "2021-03-02T00:03:41.558337Z",
"updateTime": "2021-03-02T00:03:41.558337Z"
}
}
}
Python
במאמר התקנת Vertex AI SDK ל-Python מוסבר איך להתקין או לעדכן את Vertex AI SDK ל-Python. מידע נוסף מופיע ב מאמרי העזרה של Python API.
שפות נוספות
אפשר להתקין את ספריות הלקוח הבאות של Vertex AI ולהשתמש בהן כדי לקרוא ל-Vertex AI API. ספריות לקוח ב-Cloud מספקות חוויית פיתוח אופטימלית באמצעות שימוש במוסכמות ובסגנונות הטבעיים של כל שפה נתמכת.
הצגת משימות שליפת נתונים ב-batch
משתמשים ב Google Cloud מסוף כדי להציג משימות של שליפת נתונים ב-batch בGoogle Cloud פרויקט.
ממשק משתמש באינטרנט
- בקטע Vertex AI במסוף Google Cloud , עוברים לדף Features.
- בוחרים אזור מהרשימה הנפתחת אזור.
- בסרגל הפעולות, לוחצים על הצגת משימות של שליפת נתונים ב-batch כדי לראות רשימה של משימות שליפת נתונים ב-batch לכל מאגרי הפיצ'רים.
- לוחצים על המזהה של משימת שליפת נתונים ב-batch כדי לראות את הפרטים שלה, כמו מקור מופע הקריאה שבו נעשה שימוש ויעד הפלט.
המאמרים הבאים
- איך מבצעים העלאה של ערכי מאפיינים בקבוצות
- כך מציגים תכונות באמצעות הצגה אונליין.
- צפייה במכסת המשימות בו-זמניות של אצווה ב-Vertex AI Feature Store (גרסה קודמת).
- פתרון בעיות נפוצות ב-Vertex AI Feature Store (גרסה קודמת).