
כדי להשתמש בהסברים מבוססי-דוגמאות, צריך להגדיר הסברים על ידי ציון explanationSpec כשמייבאים או מעלים את משאב Model אל מאגר המודלים.
לאחר מכן, כשמבקשים הסברים אונליין, אפשר לשנות חלק מערכי ההגדרה האלה על ידי ציון ExplanationSpecOverride בבקשה. אי אפשר לבקש הסברים על קבוצות של תמונות, כי אין תמיכה באפשרות הזו.
בדף הזה מוסבר איך להגדיר ולעדכן את האפשרויות האלה.
הגדרת הסברים כשמייבאים או מעלים את המודל
לפני שמתחילים, חשוב לוודא שיש לכם:
מיקום ב-Cloud Storage שמכיל את ארטיפקטים של המודל. המודל צריך להיות מודל של רשת עצבית עמוקה (DNN) שבו מציינים את השם של שכבה או חתימה, שהפלט שלה יכול לשמש כמרחב לטנטי, או שאפשר לספק מודל שמפיק הטמעות (ייצוג של מרחב לטנטי) באופן ישיר. המרחב הסמוי הזה כולל את הייצוגים לדוגמה שמשמשים ליצירת הסברים.
מיקום ב-Cloud Storage שמכיל את המופעים שיש לאנדקס לחיפוש של השכן הקרוב ביותר המשוער. מידע נוסף זמין במאמר בנושא דרישות לנתוני קלט.
המסוף
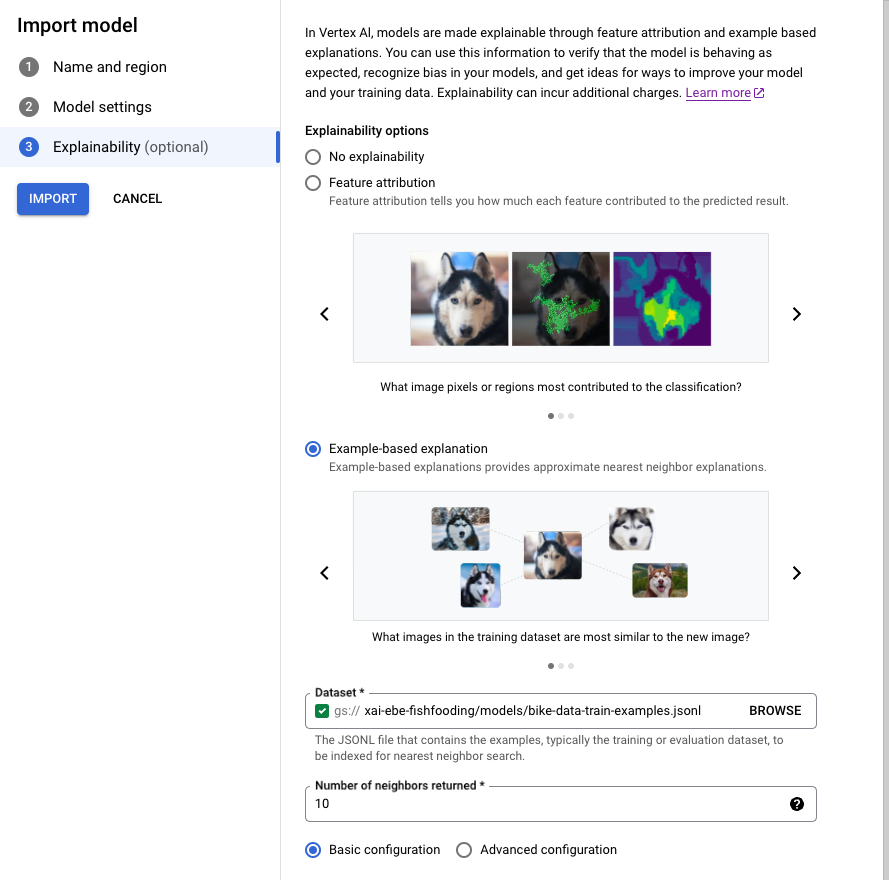
פועלים לפי המדריך בנושא ייבוא מודל באמצעות מסוף Google Cloud .
בכרטיסייה Explainability, בוחרים באפשרות Example-based explanation וממלאים את השדות.
למידע על כל שדה, אפשר לעיין בטיפים ב Google Cloud מסוף
(שמוצגים בהמשך) וגם במסמכי העזר של Example ושל ExplanationMetadata.
CLI של gcloud
- כותבים את הטקסט הבא
ExplanationMetadataלקובץ JSON בסביבה המקומית. שם הקובץ לא משנה, אבל בדוגמה הזו נקרא לקובץexplanation-metadata.json:
{
"inputs": {
"my_input": {
"inputTensorName": "INPUT_TENSOR_NAME",
"encoding": "IDENTITY",
},
"id": {
"inputTensorName": "id",
"encoding": "IDENTITY"
}
},
"outputs": {
"embedding": {
"outputTensorName": "OUTPUT_TENSOR_NAME"
}
}
}
- (אופציונלי) אם מציינים את
NearestNeighborSearchConfigהמלא, כותבים את הטקסט הבא לקובץ JSON בסביבה המקומית. שם הקובץ לא משנה, אבל בדוגמה הזו, שם הקובץ הואsearch_config.json:
{
"contentsDeltaUri": "",
"config": {
"dimensions": 50,
"approximateNeighborsCount": 10,
"distanceMeasureType": "SQUARED_L2_DISTANCE",
"featureNormType": "NONE",
"algorithmConfig": {
"treeAhConfig": {
"leafNodeEmbeddingCount": 1000,
"fractionLeafNodesToSearch": 1.0
}
}
}
}
- מריצים את הפקודה הבאה כדי להעלות את
Model.
אם אתם משתמשים בהגדרת חיפוש Preset, צריך להסיר את הדגל --explanation-nearest-neighbor-search-config-file. אם מציינים NearestNeighborSearchConfig, צריך להסיר את הדגלים --explanation-modality ו---explanation-query.
הדגשנו את הדגלים שהכי רלוונטיים להסברים שמבוססים על דוגמאות.
gcloud ai models upload \
--region=LOCATION \
--display-name=MODEL_NAME \
--container-image-uri=IMAGE_URI \
--artifact-uri=MODEL_ARTIFACT_URI \
--explanation-method=examples \
--uris=[URI, ...] \
--explanation-neighbor-count=NEIGHBOR_COUNT \
--explanation-metadata-file=explanation-metadata.json \
--explanation-modality=IMAGE|TEXT|TABULAR \
--explanation-query=PRECISE|FAST \
--explanation-nearest-neighbor-search-config-file=search_config.json
מידע נוסף זמין במאמר בנושא gcloud ai models upload.
-
פעולת ההעלאה מחזירה
OPERATION_IDשאפשר להשתמש בו כדי לבדוק מתי הפעולה מסתיימת. אפשר לבדוק את סטטוס הפעולה עד שהתגובה כוללת את"done": true. כדי לבדוק את הסטטוס, משתמשים בפקודה gcloud ai operations describe. לדוגמה:gcloud ai operations describe <operation-id>לא תוכלו לבקש הסברים עד שהפעולה תושלם. בהתאם לגודל מערך הנתונים ולארכיטקטורת המודל, בניית האינדקס שמשמש להרצת שאילתות על דוגמאות יכולה להימשך כמה שעות.
REST
לפני שמשתמשים בנתוני הבקשה, צריך להחליף את הנתונים הבאים:
- PROJECT
- LOCATION
מידע על ערכי ה-placeholder האחרים זמין במאמרים Model, explanationSpec וExamples.
מידע נוסף על העלאת מודלים זמין במאמרים upload וייבוא מודלים.
גוף הבקשה בפורמט JSON שמופיע בהמשך מציין הגדרת חיפוש Preset. אפשרות אחרת היא לציין אתNearestNeighborSearchConfig המלא.
ה-method של ה-HTTP וכתובת ה-URL:
POST https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT/locations/LOCATION/models:upload
תוכן בקשת JSON:
{
"model": {
"displayName": "my-model",
"artifactUri": "gs://your-model-artifact-folder",
"containerSpec": {
"imageUri": "us-docker.pkg.dev/vertex-ai/prediction/tf2-cpu.2-11:latest",
},
"explanationSpec": {
"parameters": {
"examples": {
"gcsSource": {
"uris": ["gs://your-examples-folder"]
},
"neighborCount": 10,
"presets": {
"modality": "image"
}
}
},
"metadata": {
"outputs": {
"embedding": {
"output_tensor_name": "embedding"
}
},
"inputs": {
"my_fancy_input": {
"input_tensor_name": "input_tensor_name",
"encoding": "identity",
"modality": "image"
},
"id": {
"input_tensor_name": "id",
"encoding": "identity"
}
}
}
}
}
}
כדי לשלוח את הבקשה צריך להרחיב אחת מהאפשרויות הבאות:
אתם אמורים לקבל תגובת JSON שדומה לזו:
{
"name": "projects/PROJECT_NUMBER/locations/LOCATION/models/MODEL_ID/operations/OPERATION_ID",
"metadata": {
"@type": "type.googleapis.com/google.cloud.aiplatform.v1.UploadModelOperationMetadata",
"genericMetadata": {
"createTime": "2022-01-08T01:21:10.147035Z",
"updateTime": "2022-01-08T01:21:10.147035Z"
}
}
}
פעולת ההעלאה מחזירה OPERATION_ID שאפשר להשתמש בו כדי לבדוק מתי הפעולה מסתיימת. אפשר לבדוק את סטטוס הפעולה עד שהתגובה כוללת את "done": true. כדי לבדוק את הסטטוס, משתמשים בפקודה gcloud ai operations describe. לדוגמה:
gcloud ai operations describe <operation-id>
לא תוכלו לבקש הסברים עד שהפעולה תושלם. בהתאם לגודל מערך הנתונים ולארכיטקטורת המודל, בניית האינדקס שמשמש להרצת שאילתות על דוגמאות יכולה להימשך כמה שעות.
Python
אפשר לעיין בקטע העלאת המודל במחברת ההסברים שמבוססים על דוגמאות לסיווג תמונות.
NearestNeighborSearchConfig
גוף בקשת ה-JSON הבא מדגים איך לציין את NearestNeighborSearchConfig המלא (במקום הגדרות קבועות מראש) בבקשת upload.
{
"model": {
"displayName": displayname,
"artifactUri": model_path_to_deploy,
"containerSpec": {
"imageUri": DEPLOY_IMAGE,
},
"explanationSpec": {
"parameters": {
"examples": {
"gcsSource": {
"uris": [DATASET_PATH]
},
"neighborCount": 5,
"nearest_neighbor_search_config": {
"contentsDeltaUri": "",
"config": {
"dimensions": dimensions,
"approximateNeighborsCount": 10,
"distanceMeasureType": "SQUARED_L2_DISTANCE",
"featureNormType": "NONE",
"algorithmConfig": {
"treeAhConfig": {
"leafNodeEmbeddingCount": 1000,
"fractionLeafNodesToSearch": 1.0
}
}
}
}
}
},
"metadata": { ... }
}
}
}
בטבלאות האלה מפורטים השדות של NearestNeighborSearchConfig.
| שדות | |
|---|---|
dimensions |
חובה. מספר המאפיינים של וקטורי הקלט. המאפיין הזה משמש רק להטמעות צפופות. |
approximateNeighborsCount |
חובה אם משתמשים באלגוריתם tree-AH. מספר השכנים שיימצאו באמצעות חיפוש משוער לפני שיתבצע מיון מחדש מדויק. סידור מחדש מדויק הוא הליך שבו התוצאות שמוחזרות על ידי אלגוריתם חיפוש משוער מסודרות מחדש באמצעות חישוב מרחק יקר יותר. |
ShardSize |
ShardSize
הגודל של כל רסיס. כשאינדקס גדול, הוא מחולק לרסיסים על סמך גודל הרסיס שצוין. במהלך ההצגה, כל רסיס מוצג בצומת נפרד ומתרחב באופן עצמאי. |
distanceMeasureType |
מדד המרחק שמשמש לחיפוש השכן הקרוב ביותר. |
featureNormType |
סוג הנרמול שיבוצע בכל וקטור. |
algorithmConfig |
oneOf:
ההגדרה של האלגוריתמים שבהם נעשה שימוש בחיפוש וקטורי לחיפוש יעיל. המאפיין הזה משמש רק להטמעות צפופות.
|
DistanceMeasureType
| טיפוסים בני מנייה (enum) | |
|---|---|
SQUARED_L2_DISTANCE |
מרחק אוקלידי (L2) |
L1_DISTANCE |
מרחק מנהטן (L1) |
DOT_PRODUCT_DISTANCE |
ערך ברירת המחדל. מוגדר כערך שלילי של המכפלה הסקלרית. שימו לב: אינדקס דליל תומך רק במרחק של מכפלה סקלרית. |
COSINE_DISTANCE |
מרחק קוסינוס. מומלץ מאוד להשתמש ב-DOT_PRODUCT_DISTANCE + UNIT_L2_NORM במקום במרחק COSINE. האלגוריתמים שלנו עברו אופטימיזציה לחישוב המרחק DOT_PRODUCT, וכשמשלבים אותו עם UNIT_L2_NORM, הוא מספק את אותו דירוג ואת אותה שקילות מתמטית כמו המרחק COSINE. |
FeatureNormType
| טיפוסים בני מנייה (enum) | |
|---|---|
UNIT_L2_NORM |
סוג הנורמליזציה של יחידה L2. |
NONE |
ערך ברירת המחדל. לא צוין סוג נורמליזציה. |
TreeAhConfig
אלה השדות שצריך לבחור עבור האלגוריתם tree-AH (עץ רדוד + גיבוב אסימטרי).
| שדות | |
|---|---|
fractionLeafNodesToSearch |
double |
| ברירת המחדל של החלק היחסי של צמתי עלים שאפשר לחפש בכל שאילתה. הערך חייב להיות בטווח 0.0 עד 1.0, לא כולל. ערך ברירת המחדל הוא 0.05 אם לא הוגדר. | |
leafNodeEmbeddingCount |
int32 |
| מספר ההטמעות בכל צומת עלה. ערך ברירת המחדל הוא 1,000 אם לא הוגדר ערך. | |
leafNodesToSearchPercent |
int32 |
הוצא משימוש, צריך להשתמש ב-fractionLeafNodesToSearch.אחוז ברירת המחדל של צמתי עלים שאפשר לחפש בכל שאילתה. הערך חייב להיות בטווח 1-100, כולל. ערך ברירת המחדל הוא 10 (כלומר 10%) אם לא הוגדר ערך. |
|
BruteForceConfig
האפשרות הזו מטמיעה את החיפוש הליניארי הרגיל במסד הנתונים עבור כל שאילתה. אין שדות להגדרה לחיפוש בכוח. כדי לבחור את האלגוריתם הזה, מעבירים אובייקט ריק ל-BruteForceConfig אל algorithmConfig.
הדרישות לגבי נתוני הקלט
מעלים את מערך הנתונים למיקום ב-Cloud Storage. מוודאים שהקבצים בפורמט JSON Lines.
הקבצים צריכים להיות בפורמט JSON Lines. הדוגמה הבאה היא מתוך מחברת ההסברים מבוססי-הדוגמאות של סיווג תמונות:
{"id": "0", "bytes_inputs": {"b64": "..."}}
{"id": "1", "bytes_inputs": {"b64": "..."}}
{"id": "2", "bytes_inputs": {"b64": "..."}}
עדכון האינדקס או ההגדרה
ב-Vertex AI אפשר לעדכן את אינדקס השכן הקרוב ביותר של מודל או את התצורה של Example. השיטה הזו שימושית אם רוצים לעדכן את המודל בלי ליצור מחדש את האינדקס של מערך הנתונים שלו. לדוגמה, אם האינדקס של המודל מכיל 1,000 מקרים, ואתם רוצים להוסיף עוד 500 מקרים, אתם יכולים להפעיל את UpdateExplanationDataset כדי להוסיף לאינדקס בלי לעבד מחדש את 1,000 המקרים המקוריים.
כדי לעדכן את מערך הנתונים של ההסברים:
Python
def update_explanation_dataset(model_id, new_examples):
response = clients["model"].update_explanation_dataset(model=model_id, examples=new_examples)
update_dataset_response = response.result()
return update_dataset_response
PRESET_CONFIG = {
"modality": "TEXT",
"query": "FAST"
}
NEW_DATASET_FILE_PATH = "new_dataset_path"
NUM_NEIGHBORS_TO_RETURN = 10
EXAMPLES = aiplatform.Examples(presets=PRESET_CONFIG,
gcs_source=aiplatform.types.io.GcsSource(uris=[NEW_DATASET_FILE_PATH]),
neighbor_count=NUM_NEIGHBORS_TO_RETURN)
MODEL_ID = 'model_id'
update_dataset_response = update_explanation_dataset(MODEL_ID, EXAMPLES)
הערות שימוש:
הקמפיין
model_idלא ישתנה אחרי הפעולהUpdateExplanationDataset.הפעולה
UpdateExplanationDatasetמשפיעה רק על המשאבModel, ולא מעדכנתDeployedModels משויכים. המשמעות היא שהאינדקס שלdeployedModelמכיל את מערך הנתונים בזמן הפריסה. כדי לעדכן את האינדקס שלdeployedModel, צריך לפרוס מחדש את המודל המעודכן לנקודת קצה.
שינוי ההגדרה כשמקבלים הסברים אונליין
כשמבקשים הסבר, אפשר לעקוף חלק מהפרמטרים תוך כדי הפעולה על ידי ציון השדה ExplanationSpecOverride.
בהתאם לאפליקציה, יכול להיות שתרצו להגביל את סוג ההסברים שמוחזרים. לדוגמה, כדי להבטיח מגוון של הסברים, משתמש יכול לציין פרמטר של צפיפות שמכתיב שאף סוג יחיד של דוגמאות לא יוצג בהסברים בצורה מוגזמת. לדוגמה, אם משתמש מנסה להבין למה ציפור סומנה כמטוס על ידי המודל, יכול להיות שהוא לא יתעניין בראיית יותר מדי דוגמאות של ציפורים כהסברים כדי לחקור טוב יותר את הסיבה הבסיסית.
בטבלה הבאה מפורטים הפרמטרים שאפשר לשנות בבקשה להסבר שמבוסס על דוגמה:
| שם הנכס | ערך הנכס | תיאור |
|---|---|---|
| neighborCount | int32 |
מספר הדוגמאות שיוחזרו כהסבר |
| crowdingCount | int32 |
המספר המקסימלי של דוגמאות שיוחזרו עם אותו תג צפיפות |
| אישור | String Array |
התגים שמותר להשתמש בהם בהסברים |
| דחייה | String Array |
התגים שאסור להשתמש בהם בהסברים |
במאמר סינון בחיפוש וקטורי מפורטים הפרמטרים האלה.
דוגמה לתוכן בקשת JSON עם שינויים:
{
"instances":[
{
"id": data[0]["id"],
"bytes_inputs": {"b64": bytes},
"restricts": "",
"crowding_tag": ""
}
],
"explanation_spec_override": {
"examples_override": {
"neighbor_count": 5,
"crowding_count": 2,
"restrictions": [
{
"namespace_name": "label",
"allow": ["Papilloma", "Rift_Valley", "TBE", "Influenza", "Ebol"]
}
]
}
}
}
המאמרים הבאים
דוגמה לתשובה לבקשה של explain שמבוססת על דוגמאות:
[
{
"neighbors":[
{
"neighborId":"311",
"neighborDistance":383.8
},
{
"neighborId":"286",
"neighborDistance":431.4
}
],
"input":"0"
},
{
"neighbors":[
{
"neighborId":"223",
"neighborDistance":471.6
},
{
"neighborId":"55",
"neighborDistance":392.7
}
],
"input":"1"
}
]
תמחור
אפשר לעיין בקטע בנושא הסברים מבוססי-דוגמאות בדף התמחור.