
Informações gerais do Cloud TPU de várias frações
O Cloud TPU de várias frações é uma tecnologia de escalonamento de desempenho full stack que permite que um job de treinamento use várias frações de TPU em uma única fração ou em frações em vários pods com paralelismo de dados padrão. Com os chips da TPU v4, isso significa que os jobs de treinamento podem usar mais de 4.096 chips em uma única execução. Pode ser mais útil em termos de desempenho usar uma única fração para jobs de treinamento que exigem menos de 4.096 chips. No entanto, é mais fácil que várias frações menores estejam disponíveis. Quando você usa a modalidade de várias frações com frações menores, o tempo de inicialização é mais rápido.
Quando implantados em configurações de várias frações, os chips de TPU em cada fração se comunicam por interconexão entre chips (ICI). Para se comunicarem entre as frações, eles transferem dados para CPUs (hosts), que transmitem esses dados pela rede do data center (DCN). Para mais informações sobre o escalonamento com várias frações, consulte Como escalonar o treinamento de IA para até dezenas de milhares de chips do Cloud TPU usando várias frações.
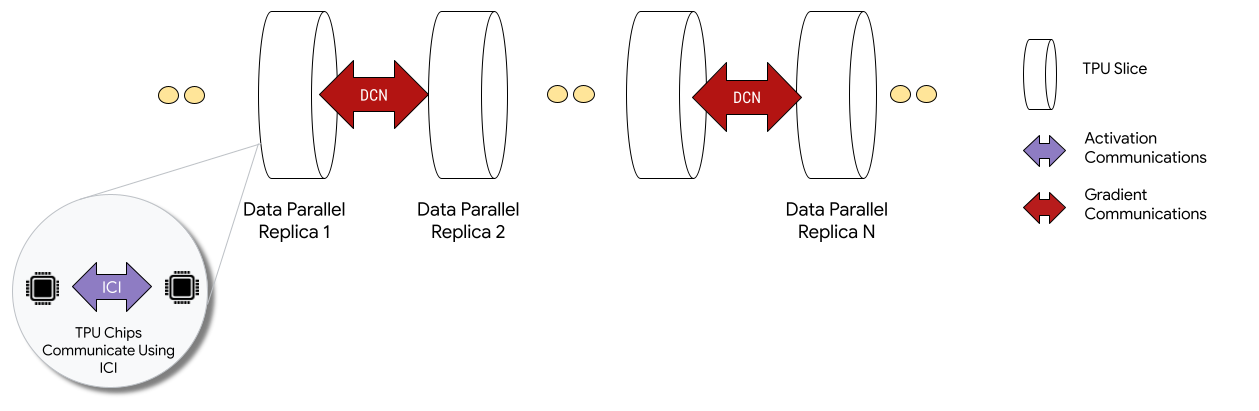
Os desenvolvedores não precisam escrever códigos para implementar a comunicação entre frações na DCN. O compilador XLA gera esse código para você e sobrepõe a comunicação com cálculos para maximizar o desempenho.
Conceitos
- Tipo de acelerador
- O formato de cada fração de TPU
que compõe um ambiente de várias frações. Todas as frações em uma
solicitação de várias frações têm o mesmo tipo de acelerador. Um tipo de acelerador
é um tipo de TPU (v4 ou mais recente) seguido pelo número de TensorCores.
Por exemplo,
v5litepod-128especifica uma TPU v5e com 128 TensorCores. - Reparo automático
- Quando uma fração passa por um evento de manutenção, uma preempção ou uma falha de hardware, o Cloud TPU cria outra fração. Se não houver recursos suficientes para criar uma fração, a criação não será concluída até que o hardware fique disponível. Depois que a nova fração é criada, todas as outras no ambiente de várias frações são reiniciadas para que o treinamento possa continuar. Com um script de inicialização configurado corretamente, o script de treinamento pode ser reiniciado automaticamente sem intervenção do usuário, sendo carregado e retomado com base no último checkpoint.
- Rede do data center (DCN)
- Uma rede de maior latência e menor capacidade de processamento (em comparação com a ICI) que conecta frações de TPU em uma configuração de várias frações.
- Programação em grupo
- Quando todas as frações de TPU são provisionadas em conjunto, você garante o provisionamento de todas ou nenhuma das frações.
- Interconexão entre chips (ICI)
- Links internos de alta velocidade e baixa latência que conectam TPUs em um Pod de TPU.
- Várias frações
- Duas ou mais frações de chip de TPU que podem se comunicar por DCN.
- Nó
- No contexto do ambiente de várias frações, nó se refere a uma única fração de TPU. Cada fração de TPU em um ambiente de várias frações recebe um ID de nó.
- Script de inicialização
- Um script de inicialização do Compute Engine padrão que é executado sempre que uma VM é iniciada ou reinicializada. No caso dos ambientes de várias frações, ele é especificado na solicitação de criação de QR. Para mais informações sobre scripts de inicialização do Cloud TPU, consulte Gerenciar recursos de TPU.
- Tensor
- Uma estrutura de dados usada para representar dados multidimensionais em um modelo de machine learning.
- Tipos de capacidade do Cloud TPU
As TPUs podem ser criadas com diferentes tipos de capacidade. Para saber mais, consulte Opções de uso em Como funcionam os preços das TPUs. Confira abaixo um resumo sobre os tipos de capacidade:
Reserva: para consumir uma reserva, é necessário ter um contrato de reserva com o Google. Use a flag
--reservedao criar seus recursos.Spot: tem como escopo cotas preemptivas e usa VMs spot. Seus recursos podem ser interrompidos e liberados para solicitações de um job de prioridade mais alta. Use a flag
--spotao criar seus recursos.On demand: tem como escopo cotas on demand, que não precisam de uma reserva e não são interrompidas. A solicitação de TPU será colocada em uma fila de cotas on demand oferecida pelo Cloud TPU, mas a disponibilidade dos recursos não é garantida. Essa é a seleção padrão, e não é necessário usar flags.
Introdução
Configure o ambiente do Cloud TPU.
-
In the Google Cloud console, activate Cloud Shell.
At the bottom of the Google Cloud console, a Cloud Shell session starts and displays a command-line prompt. Cloud Shell is a shell environment with the Google Cloud CLI already installed and with values already set for your current project. It can take a few seconds for the session to initialize.
ici_data_parallelismici_fsdp_parallelismici_tensor_parallelismConfigure o ambiente:
$ gcloud auth login $ export QR_ID=your-queued-resource-id $ export TPU_NAME=your-tpu-name $ export PROJECT=your-project-name $ export ZONE=us-central1-a $ export NETWORK_NAME=your-network-name $ export SUBNETWORK_NAME=your-subnetwork-name $ export RUNTIME_VERSION=v2-alpha-tpuv5-lite $ export ACCELERATOR_TYPE=v5litepod-16 $ export EXAMPLE_TAG_1=your-tag-1 $ export EXAMPLE_TAG_2=your-tag-2 $ export SLICE_COUNT=4 $ export STARTUP_SCRIPT='#!/bin/bash\n'
Descrições de variáveis
Entrada Descrição QR_ID O ID atribuído pelo usuário do recurso em fila. TPU_NAME O nome atribuído pelo usuário da TPU. PROJETO Nome do projeto doGoogle Cloud . ZONE Especifica a zona em que os recursos serão criados. NETWORK_NAME Nome das redes VPC. SUBNETWORK_NAME Nome da sub-rede em redes VPC. RUNTIME_VERSION A versão do software do Cloud TPU. ACCELERATOR_TYPE v4-16 EXAMPLE_TAG_1, EXAMPLE_TAG_2 … As tags são usadas para identificar origens ou destinos válidos em firewalls de rede. SLICE_COUNT Número de frações. Limite máximo de 256 frações. STARTUP_SCRIPT Se você especificar um script de inicialização, ele será executado quando a fração de TPU for provisionada ou reiniciada. Crie chaves SSH para a
gcloud. Recomendamos deixar uma senha em branco. Para isso, pressione Enter duas vezes depois de executar o comando a seguir. Se você receber uma mensagem informando que o arquivogoogle_compute_enginejá existe, substitua a versão atual.$ ssh-keygen -f ~/.ssh/google_compute_engine
Provisione as TPUs:
gcloud
$ gcloud compute tpus queued-resources \ create ${QR_ID} \ --accelerator-type=${ACCELERATOR_TYPE} \ --runtime-version=${RUNTIME_VERSION} \ --node-id=${TPU_NAME} \ --zone=${ZONE} \ [--reserved |--spot]
A CLI do Google Cloud não aceita todas as opções de criação de QR, como tags. Para mais informações, consulte Criar QRs.
Console
No console do Google Cloud , acesse a página TPUs:
Clique em Criar TPU.
No campo Nome, insira um nome para a TPU.
Na caixa Zona, selecione a zona em que você quer criar a TPU.
Na caixa Tipo de TPU, selecione um tipo de acelerador. O tipo de acelerador especifica a versão e o tamanho do Cloud TPU que você quer criar. Para mais informações sobre os tipos de acelerador aceitos em cada versão de TPU, consulte Versões de TPU.
Na caixa Versão do software de TPU, selecione uma versão. Ao criar uma VM do Cloud TPU, a versão do software de TPU especifica a versão do ambiente de execução da TPU que será instalada. Para mais informações, consulte Versões do software de TPU.
Clique no botão Ativar enfileiramento.
No campo Nome do recurso em fila, digite um nome para a solicitação de recurso em fila.
Clique em Criar para criar a solicitação de recurso em fila.
Você deve aguardar até que o recurso em fila esteja no estado
ACTIVE, o que significa que os nós de trabalho estão no estadoREADY. O provisionamento do recursos em fila pode levar de um a cinco minutos para ser concluído, dependendo do tamanho do recurso. É possível verificar o status de uma solicitação de recurso em fila usando a gcloud CLI ou o console do Google Cloud :gcloud
$ gcloud compute tpus queued-resources \ list --filter=${QR_ID} --zone=${ZONE}
Console
No console do Google Cloud , acesse a página TPUs:
Clique na guia Recursos em fila.
Clique no nome da solicitação de recurso em fila.
Conecte-se à VM de TPU usando SSH:
$ gcloud compute tpus tpu-vm ssh ${TPU_NAME} --zone=${ZONE}
Clone o MaxText (que inclui
shardings.py) na VM de TPU:$ git clone https://github.com/AI-Hypercomputer/maxtext && cd maxtext
Instale o Python 3.10:
$ sudo apt-get update $ sudo apt install python3.10 $ sudo apt install python3.10-venv
Crie e ative um ambiente virtual:
$ python3 -m venv your-venv-name $ source your-venv-name/bin/activate
No diretório do repositório do MaxText, execute o script de configuração para instalar o JAX e outras dependências na fração de TPU. O script de configuração leva alguns minutos para ser executado.
$ bash setup.sh
Execute o comando a seguir para executar
shardings.pyna fração de TPU.$ python3 -m pedagogical_examples.shardings \ --ici_fsdp_parallelism 4 \ --batch_size 131072 \ --embedding_dimension 2048
Você pode conferir os resultados nos registros. As TPUs devem atingir cerca de 260 TFLOP por segundo ou uma impressionante utilização de FLOP de mais de 90%. Neste caso, selecionamos aproximadamente o lote máximo que cabe na memória de alta largura de banda (HBM) da TPU.
Você pode explorar outras estratégias de fragmentação na ICI. Por exemplo, tente a seguinte combinação:
$ python3 -m pedagogical_examples.shardings \ --ici_tensor_parallelism 4 \ --batch_size 131072 \ --embedding_dimension 2048
Exclua o recurso em fila e a fração de TPU quando terminar. Execute essas etapas de limpeza no ambiente em que você configurou a fração. Primeiro, execute
exitpara sair da sessão SSH. A exclusão leva de dois a cinco minutos para ser concluída. Se você estiver usando a gcloud CLI, execute o comando em segundo plano com a flag opcional--async.gcloud
$ gcloud compute tpus queued-resources \ delete ${QR_ID} --force (--async)
Console
No console do Google Cloud , acesse a página TPUs:
Clique na guia Recursos em fila.
Marque a caixa de seleção ao lado da solicitação de recurso em fila.
Clique em Excluir.
- dcn_data_parallelism
- dcn_fsdp_parallelism
- dcn_tensor_parallelism
Clone o MaxText na máquina executora:
$ git clone https://github.com/AI-Hypercomputer/maxtext
Acesse o diretório do repositório.
$ cd maxtext
Crie chaves SSH para
gcloud. Recomendamos deixar uma senha em branco. Para isso, pressione Enter duas vezes depois de executar o comando a seguir. Se aparecer uma mensagem informando que o arquivogoogle_compute_enginejá existe, selecione a opção para não manter a versão atual.$ ssh-keygen -f ~/.ssh/google_compute_engine
Adicione uma variável de ambiente para definir a contagem de frações de TPU como
2.$ export SLICE_COUNT=2
Crie um ambiente de várias frações usando o comando
queued-resources createou o console do Google Cloud .gcloud
O comando a seguir mostra como criar uma TPU v5e de várias frações. Para usar uma versão de TPU diferente, especifique um
accelerator-typee umruntime-versiondiferentes.$ gcloud compute tpus queued-resources \ create ${QR_ID} \ --accelerator-type=${ACCELERATOR_TYPE} \ --runtime-version=${RUNTIME_VERSION} \ --node-count=${SLICE_COUNT} \ --node-prefix=${TPU_NAME} \ --zone=${ZONE} \ [--reserved|--spot]
Console
No console do Google Cloud , acesse a página TPUs:
Clique em Criar TPU.
No campo Nome, insira um nome para a TPU.
Na caixa Zona, selecione a zona em que você quer criar a TPU.
Na caixa Tipo de TPU, selecione um tipo de acelerador. O tipo de acelerador especifica a versão e o tamanho do Cloud TPU que você quer criar. O ambiente de várias frações só é aceito no Cloud TPU v4 e em versões mais recentes. Para mais informações sobre as versões de TPU, consulte Versões de TPU.
Na caixa Versão do software de TPU, selecione uma versão. Ao criar uma VM do Cloud TPU, a versão do software de TPU especifica a versão do ambiente de execução da TPU a ser instalada nas VMs. Para mais informações, consulte Versões do software de TPU.
Clique no botão Ativar enfileiramento.
No campo Nome do recurso em fila, digite um nome para a solicitação de recurso em fila.
Clique na caixa de seleção Usar TPU com várias frações.
No campo Contagem de frações, insira o número de frações que você quer criar.
Clique em Criar para criar a solicitação de recurso em fila.
O provisionamento do recurso em fila pode levar até cinco minutos para ser concluído, dependendo do tamanho do recurso. Aguarde até que o recurso em fila esteja no estado
ACTIVE. É possível verificar o status de uma solicitação de recurso em fila usando a gcloud CLI ou o console do Google Cloud :gcloud
$ gcloud compute tpus queued-resources list \ --filter=${QR_ID} --zone=${ZONE} --project=${PROJECT}
Isso vai gerar uma saída como esta:
NAME ZONE NODE_COUNT ACCELERATOR_TYPE STATE ... que-res-id us-central2-b 4 v5litepod-16 ACTIVE ...
Console
No console do Google Cloud , acesse a página TPUs:
Clique na guia Recursos em fila.
Clique no nome da solicitação de recurso em fila.
Entre em contato com seu representante da conta do Google Cloud se o status da QR ficar no estado
WAITING_FOR_RESOURCESouPROVISIONINGpor mais de 15 minutos.Instale as dependências.
$ python3 multihost_runner.py \ --TPU_PREFIX=${TPU_NAME} \ --ZONE=${ZONE} \ --COMMAND="bash setup.sh"
Execute
shardings.pyem cada worker usandomultihost_runner.py.$ python3 multihost_runner.py \ --TPU_PREFIX=${TPU_NAME} \ --ZONE=${ZONE} \ --COMMAND="python3 -m pedagogical_examples.shardings \ --dcn_data_parallelism ${SLICE_COUNT} \ --ici_fsdp_parallelism 16 \ --batch_size 131072 \ --embedding_dimension 2048"
Você vai notar cerca de 230 TFLOPs por segundo de desempenho nos arquivos de registro.
Para saber como configurar o paralelismo, consulte Fragmentação de várias frações usando o paralelismo da DCN e
shardings.py.Limpe as TPUs e o recurso em fila quando terminar. A exclusão leva de dois a cinco minutos para ser concluída. Se você estiver usando a gcloud CLI, execute o comando em segundo plano com a flag opcional
--async.- Use jax.experimental.mesh_utils.create_hybrid_device_mesh em vez de jax.experimental.mesh_utils.create_device_mesh when creating your mesh.
- Usar o script do executor de experimentos,
multihost_runner.py. - Usar o script do executor de produção,
multihost_job.py. - Usar uma abordagem manual.
Crie uma solicitação de recurso em fila usando este comando:
$ gcloud compute tpus queued-resources \ create ${QR_ID} \ --project=${PROJECT} \ --zone=${ZONE} \ --node-count=${SLICE_COUNT} \ --accelerator-type=${ACCELERATOR_TYPE} \ --runtime-version=${RUNTIME_VERSION} \ --network=${NETWORK_NAME} \ --subnetwork=${SUBNETWORK_NAME} \ --tags=${EXAMPLE_TAG_1},${EXAMPLE_TAG_2} \ --metadata=startup-script="${STARTUP_SCRIPT}" \ [--reserved|--spot]
Crie um arquivo
queued-resource-req.jsone copie o JSON a seguir nele.{ "guaranteed": { "reserved": true }, "tpu": { "node_spec": [ { "parent": "projects/your-project-number/locations/your-zone", "node": { "accelerator_type": "accelerator-type", "runtime_version": "tpu-vm-runtime-version", "network_config": { "network": "your-network-name", "subnetwork": "your-subnetwork-name", "enable_external_ips": true }, "tags" : ["example-tag-1"] "metadata": { "startup-script": "your-startup-script" } }, "multi_node_params": { "node_count": slice-count, "node_id_prefix": "your-queued-resource-id" } } ] } }
Substitua os seguintes valores:
- your-project-number: o número do projeto do Google Cloud .
- your-zone: a zona em que você quer criar o recurso em fila.
- accelerator-type: a versão e o tamanho de uma única fração. O ambiente de várias frações só é aceito no Cloud TPU v4 e em versões mais recentes.
- tpu-vm-runtime-version: a versão do ambiente de execução da VM de TPU que você quer usar.
- your-network-name (opcional): uma rede para anexar o recurso em fila.
- your-subnetwork-name (opcional): uma sub-rede para anexar o recurso em fila.
- example-tag-1 (opcional): uma string de tag arbitrária.
- your-startup-script: um script de inicialização que será executado quando o recurso em fila for alocado.
- slice-count: o número de frações de TPU no ambiente de várias frações.
- your-queued-resource-id: o ID fornecido pelo usuário para o recurso em fila.
Para mais informações, consulte a documentação da API REST Queued Resource com todas as opções disponíveis.
Para usar a capacidade de spot, substitua:
"guaranteed": { "reserved": true }por"spot": {}Remova a linha para usar a capacidade on demand padrão.
Envie a solicitação de criação de recurso em fila com o payload JSON:
$ curl -X POST -H "Authorization: Bearer $(gcloud auth print-access-token)" \ -H "Content-Type: application/json" \ -d @queuedresourcereq.json \ https://tpu.googleapis.com/v2alpha1/projects/your-project-id/locations/your-zone/queuedResources\?queued_resource_id\=your-queued-resource-id
Substitua os seguintes valores:
- your-project-id: o ID do projeto do Google Cloud .
- your-zone: a zona em que você quer criar o recurso em fila.
- your-queued-resource-id: o ID fornecido pelo usuário para o recurso em fila.
No console do Google Cloud , acesse a página TPUs:
Clique em Criar TPU.
No campo Nome, insira um nome para a TPU.
Na caixa Zona, selecione a zona em que você quer criar a TPU.
Na caixa Tipo de TPU, selecione um tipo de acelerador. O tipo de acelerador especifica a versão e o tamanho do Cloud TPU que você quer criar. O ambiente de várias frações só é aceito no Cloud TPU v4 e em versões mais recentes. Para mais informações sobre os tipos de acelerador aceitos em cada versão de TPU, consulte Versões de TPU.
Na caixa Versão do software de TPU, selecione uma versão. Ao criar uma VM do Cloud TPU, a versão do software de TPU especifica a versão do ambiente de execução da TPU que será instalada. Para mais informações, consulte Versões do software de TPU.
Clique no botão Ativar enfileiramento.
No campo Nome do recurso em fila, digite um nome para a solicitação de recurso em fila.
Clique na caixa de seleção Usar TPU com várias frações.
No campo Contagem de frações, insira o número de frações que você quer criar.
Clique em Criar para criar a solicitação de recurso em fila.
No console do Google Cloud , acesse a página TPUs:
Clique na guia Recursos em fila.
Clique no nome da solicitação de recurso em fila.
No console do Google Cloud , acesse a página TPUs:
Clique na guia Recursos em fila.
No console do Google Cloud , acesse a página TPUs:
Clique na guia Recursos em fila.
Marque a caixa de seleção ao lado da solicitação de recurso em fila.
Clique em Excluir.
- B é o tamanho do lote em tokens.
- P é o número de parâmetros.
- Ele gera uma bolha no pipeline, porque os chips ficam inativos aguardando dados.
- Ele exige microlotes, o que diminui o tamanho efetivo do lote, a intensidade aritmética e, por fim, a utilização de FLOP do modelo.
Para usar várias frações, os recursos de TPU precisam ser gerenciados como recursos em fila.
Exemplo introdutório
Este tutorial usa códigos do repositório do GitHub do MaxText. O MaxText é um LLM básico de alto desempenho amplamente testado, com escalonamento arbitrário e código aberto escrito em Python e Jax. O MaxText foi projetado para ser treinado com eficiência no Cloud TPU.
O código em shardings.py
foi criado para ajudar você a testar diferentes
opções de paralelismo. Por exemplo, paralelismo de dados, paralelismo de dados totalmente fragmentados (FSDP)
e paralelismo de tensores. Esse código pode ser usado em
ambientes de fração única ou de várias frações.
Paralelismo de ICI
ICI consiste na interconexão de alta velocidade
entre as TPUs em uma única fração. A fragmentação de ICI corresponde à fragmentação em uma fração. O shardings.py
fornece três parâmetros de paralelismo de ICI:
Os valores especificados para esses parâmetros determinam o número de fragmentos para cada método de paralelismo.
Essas entradas precisam ser restritas para que
ici_data_parallelism * ici_fsdp_parallelism * ici_tensor_parallelism seja igual ao
número de chips na fração.
A tabela abaixo mostra exemplos de entradas do usuário para o paralelismo de ICI nos quatro chips disponíveis na v4-8:
| ici_data_parallelism | ici_fsdp_parallelism | ici_tensor_parallelism | |
| FSDP de quatro vias | 1 | 4 | 1 |
| Paralelismo de tensor de quatro vias | 1 | 1 | 4 |
| FSDP bidirecional + Paralelismo de tensor bidirecional | 1 | 2 | 2 |
Observe que ici_data_parallelism deve ser mantido como 1 na maioria dos casos porque a rede de ICI é rápida
o suficiente para quase sempre optar por FSDP em vez de paralelismo de dados.
Este exemplo presume que você já sabe executar códigos em uma única fração de TPU,
como em Executar um cálculo em uma VM do Cloud TPU usando o JAX.
Aqui, mostramos como executar shardings.py em uma única fração.
Fragmentação de várias frações usando o paralelismo da DCN
O script shardings.py usa três parâmetros que especificam o paralelismo da DCN,
correspondente ao número de fragmentos de cada tipo de paralelismo de dados:
Os valores desses parâmetros precisam ser restritos para que
dcn_data_parallelism * dcn_fsdp_parallelism * dcn_tensor_parallelism seja igual
ao número de frações.
Como exemplo para duas frações, use --dcn_data_parallelism = 2.
| dcn_data_parallelism | dcn_fsdp_parallelism | dcn_tensor_parallelism | N° de frações | |
| Paralelismo de dados bidirecional | 2 | 1 | 1 | 2 |
dcn_tensor_parallelism precisa sempre ser definido como 1 porque a DCN não é adequada
para esse tipo de fragmentação. Para cargas de trabalho típicas de LLM
em chips da v4, dcn_fsdp_parallelism também precisa ser definido como 1 e, portanto, dcn_data_parallelism precisa
ser definido como o número de frações,
mas isso depende do aplicativo.
Ao aumentar o número de frações (supondo que o tamanho da fração e o lote por fração sejam mantidos constantes), você aumenta a quantidade de paralelismo de dados.
Executar shardings.py em um ambiente de várias frações
É possível executar shardings.py em um ambiente de várias frações usando
multihost_runner.py ou executando shardings.py em cada VM de TPU. Neste caso, use
multihost_runner.py. As etapas a seguir são muito parecidas com aquelas de
Introdução: experimentos rápidos com várias frações
no repositório do MaxText. A diferença é que aqui você deve executar shardings.py em vez do
LLM mais complexo em train.py.
A ferramenta multihost_runner.py é otimizada para experimentos rápidos e reutiliza
repetidamente as mesmas TPUs. Como o script multihost_runner.py depende de conexões SSH de longa duração,
não o recomendamos para jobs de longa duração.
Se você quiser executar um job mais longo que leve horas ou dias,
recomendamos usar multihost_job.py.
Neste tutorial, usamos o termo executor para indicar a máquina em que você
executa o script multihost_runner.py. Usamos o termo workers para indicar
as VMs de TPU que compõem as frações. É possível executar multihost_runner.py em uma
máquina local ou em qualquer VM do Compute Engine no mesmo projeto das frações. Não é possível executar
multihost_runner.py em um worker.
O multihost_runner.py se conecta automaticamente por SSH aos workers de TPU.
Neste exemplo, você executa shardings.py em duas frações da v5e-16, com um total de
quatro VMs e 16 chips de TPU. É possível modificar o exemplo para execução em mais TPUs.
Configurar o ambiente
Como escalonar uma carga de trabalho para abranger várias frações
Antes de executar o modelo em um ambiente de várias frações, faça estas mudanças no código:
Essas devem ser as únicas mudanças de código necessárias ao migrar para o ambiente de várias frações. Para alcançar alto desempenho, a DCN precisa ser associada a eixos de paralelismo de dados, paralelismo de dados totalmente fragmentados ou paralelismo de pipeline. Saiba mais sobre desempenho e estratégias de fragmentação em Fragmentação com várias frações para desempenho máximo.
Para validar se o código pode acessar todos os dispositivos, confirme se
len(jax.devices()) é igual ao número de chips no ambiente
de várias frações. Por exemplo, ao usar quatro frações de v4-16,
você tem oito chips por fração * 4 frações. Portanto, len(jax.devices()) retorna 32.
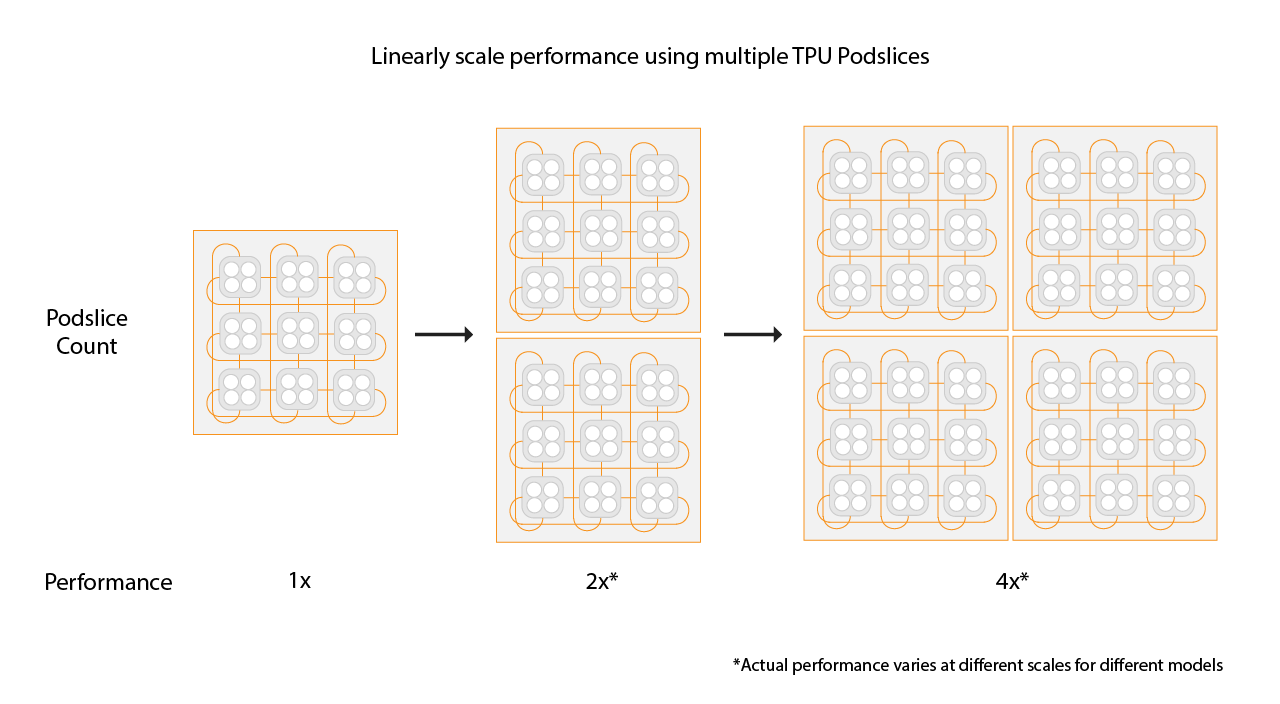
Como escolher tamanhos de fração para ambientes de várias frações
Para ter um aumento linear de velocidade, adicione novas frações do mesmo tamanho
da atual. Por exemplo, se você usar uma fração v4-512,
o ambiente de várias frações vai atingir cerca do dobro do desempenho porque vai adicionar uma
segunda fração v4-512 e dobrar o tamanho global do lote. Para mais informações, consulte
Fragmentação com várias frações para desempenho máximo.
Executar um job em várias frações
Há três abordagens diferentes para executar uma carga de trabalho personalizada em um ambiente de várias frações:
Script do executor de experimentos
O script multihost_runner.py
distribui o código para um ambiente de várias frações atual, executa o comando em cada host,
copia os registros de volta e monitora
o status de erro de cada comando. O script multihost_runner.py está no
README do MaxText.
Como o multihost_runner.py mantém conexões SSH persistentes, ele só é adequado para
experimentos de tamanho modesto e duração relativamente curta. Você pode
adaptar as etapas do tutorial do multihost_runner.py
à sua carga de trabalho e à sua configuração de hardware.
Script do executor de produção
Para jobs de produção que precisam de resiliência contra falhas de hardware e outras interrupções,
é melhor fazer a integração diretamente
com a API Create Queued Resource. Use multihost_job.py como um exemplo
funcional que aciona a chamada da API Created Queued Resource com o script de inicialização
adequado para executar o treinamento e retomar a execução após uma preempção. O script multihost_job.py
está no
README do MaxText.
Como o multihost_job.py precisa provisionar recursos para cada execução, ele não
oferece um ciclo de iteração tão rápido quanto multihost_runner.py.
Abordagem manual
Recomendamos usar ou adaptar multihost_runner.py ou multihost_job.py para executar uma carga de trabalho personalizada na configuração de várias frações. No entanto, se você preferir provisionar e gerenciar o ambiente usando diretamente comandos de QR, consulte Gerenciar um ambiente de várias frações.
Gerenciar um ambiente de várias frações
Para provisionar e gerenciar manualmente QRs sem usar as ferramentas fornecidas no repositório do MaxText, confira as seções a seguir.
Criar recursos em fila
gcloud
Verifique se você tem a cota padrão on demand ou a cota respectiva antes de selecionar --reserved ou --spot. Para informações sobre tipos de cota,
consulte Política de cotas.
curl
A resposta será parecida com esta:
{ "name": "projects/<your-project-id>/locations/<your-zone>/operations/operation-<your-qr-guid>", "metadata": { "@type": "type.googleapis.com/google.cloud.common.OperationMetadata", "createTime": "2023-11-01T00:17:05.742546311Z", "target": "projects/<your-project-id>/locations/<your-zone>/queuedResources/<your-qa-id>", "verb": "create", "cancelRequested": false, "apiVersion": "v2alpha1" }, "done": false }
Para receber informações sobre a solicitação de recurso em fila, use o valor GUID
no final do valor da string para o atributo name.
Console
Recuperar o status de um recurso em fila
gcloud
$ gcloud compute tpus queued-resources describe ${QR_ID} --zone=${ZONE}
Para um recurso em fila no estado ACTIVE,
a saída será assim:
...
state:
state: ACTIVE
...
curl
$ curl -X GET -H "Authorization: Bearer $(gcloud auth print-access-token)" -H "Content-Type: application/json" https://tpu.googleapis.com/v2/projects/your-project-id/locations/your-zone/queuedResources/${YOUR_QR_ID}
Para um recurso em fila no estado ACTIVE,
a saída será assim:
{
"name": your-queued-res,
"tpu": {
"nodeSpec": [
{
... // node 1
},
{
... // node 2
},
...
]
},
...
"state": "ACTIVE"
}
Console
Depois que a TPU for provisionada, você também poderá conferir detalhes sobre a solicitação de recurso em fila. Para isso, acesse a página TPUs, encontre sua TPU e clique no nome da solicitação de recurso em fila correspondente.
Em um cenário raro, você pode notar o recurso em fila no estado FAILED
enquanto algumas frações estão ACTIVE. Se isso acontecer, exclua os recursos criados e
tente de novo em alguns minutos ou entre em contato com a ajuda doGoogle Cloud .
SSH e dependências de instalação
O artigo Executar códigos do JAX em frações de TPU
descreve como se conectar por SSH às VMs de TPU em uma única fração. Para se conectar por SSH a todas
as VMs de TPU no ambiente de várias frações e instalar as dependências,
use este comando gcloud:
$ gcloud compute tpus queued-resources ssh ${QR_ID} \ --zone=${ZONE} \ --node=all \ --worker=all \ --command="command-to-run" \ --batch-size=4
Esse comando gcloud envia o comando especificado para todos os workers e nós na
QR usando SSH. O comando é colocado em lotes de quatro
e enviado simultaneamente. O lote de comandos seguinte é enviado quando
a execução do atual é concluída. Se um dos comandos falhar, o processamento
será interrompido e nenhum outro lote será enviado. Para mais informações, consulte a
referência da API de recursos em fila.
Se o número de frações que você está usando exceder o limite de processamento paralelo do
computador local (também chamado de limite de lote), ocorrerá um impasse. Por exemplo,
imagine que o limite de lote na máquina local é 64. Se você tentar executar um
script de treinamento em mais de 64 frações (por exemplo, em 100), o comando SSH vai dividir as
frações em lotes. Ele vai executar o script de treinamento no
primeiro lote de 64 frações e aguardar a conclusão antes de executar o script
no lote restante de 36 frações. No entanto, o primeiro lote de 64 frações não
pode ser concluído até que as 36 frações restantes comecem a executar o script,
o que causa um impasse.
Para evitar esse cenário, execute o script de treinamento em segundo plano em
cada VM anexando um e comercial (&) ao comando de script especificado
com a flag --command. Quando você faz isso,
depois que o script de treinamento é iniciado no primeiro lote de frações,
o controle retorna imediatamente para o comando SSH. Assim, o comando SSH pode começar a executar o script de treinamento no
lote restante de 36 frações. Você vai precisar redirecionar os fluxos
stdout e stderr de maneira adequada ao executar os comandos em segundo plano. Para aumentar
o paralelismo na mesma QR, selecione frações específicas usando
o parâmetro --node.
Configuração de rede
Para garantir que as frações de TPU possam se comunicar entre si, siga as etapas abaixo.
Instale o JAX em cada uma das frações. Para mais informações, consulte
Executar códigos do JAX em frações de TPU. Verifique se len(jax.devices())
é igual ao número de chips
no ambiente de várias frações. Para fazer isso, execute o seguinte em cada fração:
$ python3 -c 'import jax; print(jax.devices())'
Se você executar esse código em quatro frações
da v4-16, haverá oito chips por fração e quatro frações.
Um total de 32 chips (dispositivos) será retornado por jax.devices().
Listar recursos em fila
gcloud
Use o comando queued-resources list para conferir o estado dos recursos em fila:
$ gcloud compute tpus queued-resources list --zone=${ZONE}
A resposta será assim:
NAME ZONE NODE_COUNT ACCELERATOR_TYPE STATE ... que-res-id us-central1-a 4 v5litepod-16 ACTIVE ...
Console
Iniciar um job em um ambiente provisionado
É possível executar cargas de trabalho manualmente. Para isso, conecte-se por SSH a todos os hosts em cada fração e execute o comando abaixo em todos eles.
$ gcloud compute tpus tpu-vm ssh ${TPU_NAME} \ --zone=${ZONE} \ --worker=all \ --command="command-to-run"
Redefinir QRs
A API ResetQueuedResource pode ser usada para
redefinir todas as VMs em uma QR ACTIVE. A redefinição forçada das VMs apaga a memória
das máquinas e as redefine para o estado inicial. Todos os dados armazenados localmente
vão permanecer intactos, e o script de inicialização será invocado após uma redefinição. A API ResetQueuedResource
pode ser útil para reiniciar todas as TPUs. Por exemplo,
quando o treinamento fica travado e redefinir todas as VMs é mais fácil do que fazer a depuração.
As redefinições de todas as VMs são feitas em paralelo, e uma operação ResetQueuedResource
leva de um a dois minutos para ser concluída. Para invocar a API, use o seguinte
comando:
$ gcloud compute tpus queued-resources reset ${QR_ID} --zone=${ZONE}
Como excluir recursos em fila
Para liberar recursos ao final da sessão de treinamento,
exclua o recurso em fila. A exclusão leva de dois a cinco minutos para ser concluída. Se você
estiver usando a gcloud CLI, execute o comando em segundo plano
com a flag opcional --async.
gcloud
$ gcloud compute tpus queued-resources \ delete ${QR_ID} --zone=${ZONE} --force [--async]
Console
Recuperação automática de falhas
Em caso de interrupção, o ambiente de várias frações oferece o reparo sem intervenção da fração afetada e a redefinição posterior de todas as frações. A fração afetada é substituída por uma nova, e as demais que estão íntegras são redefinidas. Se não houver capacidade disponível para alocar uma fração de substituição, o treinamento será interrompido.
Para retomar o treinamento automaticamente após uma interrupção, especifique um script de inicialização para verificar e carregar os últimos checkpoints salvos. O script de inicialização é executado automaticamente sempre que uma fração é realocada ou uma VM é redefinida. Você especifica um script de inicialização no payload JSON que é enviado à API de solicitação de criação de QR.
O script de inicialização a seguir (usado em Criar QRs) permite a recuperação automática de falhas e a retomada do treinamento com base em checkpoints armazenados em um bucket do Cloud Storage durante o treinamento do MaxText:
{
"tpu": {
"node_spec": [
{
...
"metadata": {
"startup-script": "#! /bin/bash \n pwd \n runuser -l user1 -c 'cd /home/user1/MaxText && python3 -m MaxText.train MaxText/configs/base.yml run_name=run_test_failure_recovery dcn_data_parallelism=4 ici_fsdp_parallelism=8 steps=10000 save_period=10 base_output_directory='gs://user1-us-central2'' EOF"
}
...
}
]
}
}
Clone o repositório do MaxText antes de testar essa opção.
Criação de perfil e depuração
A criação de perfil é igual em ambientes de fração única e de várias frações. Para mais informações, consulte Como criar perfis de programas JAX.
Como otimizar o treinamento
As seções a seguir descrevem como otimizar o treinamento com várias frações.
Fragmentação com várias frações para desempenho máximo
Para alcançar desempenho máximo em ambientes de várias frações, é necessário considerar como fazer a fragmentação em várias frações. Normalmente, há três opções: paralelismo de dados, paralelismo de dados totalmente fragmentados e paralelismo de pipeline. Não recomendamos a fragmentação de ativações nas dimensões do modelo, um processo que também é chamado de paralelismo de tensores, porque isso exige muita largura de banda entre frações. Você pode manter a mesma estratégia de fragmentação que funcionou para você no passado em uma fração.
Recomendamos começar com o paralelismo de dados puro. Usar o paralelismo de dados totalmente fragmentados é útil para liberar o uso da memória. A desvantagem é que a comunicação entre as frações usa a rede DCN e diminui a velocidade da carga de trabalho. Use o paralelismo de pipeline somente quando necessário com base no tamanho do lote (conforme analisado abaixo).
Quando usar o paralelismo de dados
O paralelismo de dados puro é adequado quando você tem uma carga de trabalho que está funcionando bem, mas quer melhorar o desempenho dela com o escalonamento para várias frações.
Para alcançar um escalonamento eficiente em várias frações, o tempo necessário para executar a operação all-reduce na DCN deve ser menor que o tempo necessário para executar a passagem reversa. A DCN é usada para a comunicação entre frações e, por isso, afeta a capacidade de processamento da carga de trabalho.
Cada chip da TPU v4 tem um desempenho máximo de 275 * 1012 FLOPS por segundo.
Há quatro chips por host de TPU, e cada host tem uma largura de banda de rede máxima de 50 Gbps.
Isso significa que a intensidade aritmética é 4 * 275 * 1012 FLOPS/50 Gbps = 22.000 FLOPS/bit.
O modelo vai usar de 32 a 64 bits de largura de banda da DCN para cada parâmetro por etapa. Se você usar duas frações, o modelo vai usar 32 bits de largura de banda da DCN. Se você usar mais de duas frações, o compilador vai realizar uma operação all-reduce aleatória e usar até 64 bits de largura de banda da DCN para cada parâmetro por etapa. A quantidade de FLOPS necessária para cada parâmetro varia de acordo com o modelo. Especificamente, para modelos de linguagem baseados em Transformer, o número de FLOPS necessários para uma passagem direta e uma reversa é aproximadamente 6 * B * P, em que:
O número de FLOPS por parâmetro é 6 * B, e o número de FLOPS por parâmetro
durante a passagem reversa é 4 * B.
Para garantir um escalonamento eficiente em várias frações, verifique se a intensidade
operacional excede a intensidade aritmética do hardware de TPU. Para calcular a
intensidade operacional, divida o número de FLOPS por parâmetro durante a passagem reversa
pela largura de banda da rede (em bits)
por parâmetro por etapa: Operational Intensity = FLOPSbackwards_pass / DCN bandwidth.
Portanto, para um modelo de linguagem baseado em Transformer, se você usar duas frações:
Operational intensity = 4 * B / 32.
Se você usar mais de duas frações: Operational intensity = 4 * B/64.
Isso sugere um tamanho mínimo de lote entre 176 mil e 352 mil para modelos de linguagem baseados em Transformer. Como a rede DCN pode descartar pacotes brevemente, é melhor manter uma margem de erro significativa, implantando o paralelismo de dados somente se o tamanho do lote por pod for de pelo menos 350 mil (dois pods) a 700 mil (muitos pods).
Para outras arquiteturas de modelo, é necessário estimar o tempo de execução da passagem reversa por fração (cronometrando com um criador de perfil ou contando FLOPS). Depois, compare esse valor com o tempo de execução esperado para a redução na DCN e você terá uma boa estimativa para saber se o paralelismo de dados funciona para você.
Quando usar o paralelismo de dados totalmente fragmentados (FSDP)
O paralelismo de dados totalmente fragmentados (FSDP) combina o paralelismo de dados (fragmentação dos dados entre nós) com a fragmentação dos pesos entre os nós. Para cada operação nas passagens reversa e direta, os pesos são coletados para que cada fração tenha os pesos necessários. Em vez de sincronizar os gradientes usando a operação all-reduce, eles são reduzidos e distribuídos pela operação reduce-scatter à medida que são produzidos. Dessa forma, cada fração recebe apenas os gradientes dos pesos pelos quais é responsável.
Assim como o paralelismo de dados, o FSDP exige o escalonamento do tamanho global do lote de maneira linear com o número de frações. O FSDP vai diminuir a pressão na memória à medida que você aumenta o número de frações. Isso acontece porque o número de pesos e o estado do otimizador por fração diminuem, mas ao custo do aumento do tráfego de rede e de maior possibilidade de bloqueio devido a uma operação de comunicação coletiva atrasada.
Na prática, o FSDP em frações é melhor se você aumentar o lote por fração, armazenando mais ativações para minimizar a rematerialização durante a passagem reversa ou aumentando o número de parâmetros na rede neural.
As operações all-gather e all-reduce no FSDP funcionam de maneira semelhante às do DP. Assim, é possível determinar se a carga de trabalho do FSDP é limitada pelo desempenho da DCN da forma descrita na seção anterior.
Quando usar o paralelismo de pipeline
O paralelismo de pipeline é relevante quando o objetivo é alto desempenho com outras estratégias de paralelismo que exigem um tamanho global de lote maior do que o tamanho máximo de lote que você prefere. O paralelismo de pipeline permite que as frações de um pipeline compartilhem um lote. No entanto, o paralelismo de pipeline tem duas grandes desvantagens:
Use o paralelismo de pipeline apenas se as outras estratégias exigirem um tamanho de lote global muito grande. Antes de testar o paralelismo de pipeline, faça um experimento para verificar empiricamente se a convergência por amostra diminui no tamanho de lote necessário para alcançar um FSDP de alto desempenho. O FSDP tende a alcançar uma utilização maior de FLOP do modelo, mas se a convergência por amostra diminuir à medida que o tamanho do lote aumenta, o paralelismo de pipeline ainda pode ser a melhor opção. A maioria das cargas de trabalho pode tolerar tamanhos de lote suficientemente grandes para não ser relevante usar o paralelismo de pipeline, mas sua carga de trabalho pode ser diferente.
Se o paralelismo de pipeline for necessário, recomendamos combiná-lo com o paralelismo de dados ou o FSDP. Assim, é possível minimizar a profundidade do pipeline e aumentar o tamanho do lote por pipeline até que a latência da DCN se torne menos importante para a capacidade de processamento. Por exemplo, se você tiver N frações, considere pipelines de profundidade 2 e réplicas N/2 de paralelismo de dados, depois pipelines de profundidade 4 e réplicas N/4 de paralelismo de dados. Siga esse padrão até que o lote por pipeline fique grande o suficiente para que as operações de comunicação coletiva da DCN possam ser ocultadas pela aritmética na passagem reversa. Isso vai minimizar a lentidão causada pelo paralelismo de pipeline e permitir que você faça o escalonamento para além do limite global de tamanho do lote.
Práticas recomendadas para várias frações
As seções a seguir descrevem as práticas recomendadas para o treinamento com várias frações.
Carregamento de dados
Durante o treinamento, lotes de um conjunto de dados são carregados repetidamente para alimentar o modelo. Ter um carregador de dados assíncrono e eficiente que fragmenta o lote em vários hosts é importante para evitar que as TPUs fiquem sem trabalho. O carregador de dados atual no MaxText faz com que cada host carregue um subconjunto igual dos exemplos. Essa solução é adequada para textos, mas exige uma refragmentação no modelo. Além disso, o MaxText ainda não oferece snapshots determinísticos, o que permitiria que o iterador de dados carregasse os mesmos dados antes e depois da preempção.
Como estabelecer checkpoints
A biblioteca de checkpoint Orbax fornece
primitivos para checkpoints de PyTrees do JAX no armazenamento local ou no armazenamento do Google Cloud .
Fornecemos uma integração de referência com checkpoint síncrono no MaxText
em checkpointing.py.
Configurações aceitas
As seções a seguir descrevem os formatos de fração, a orquestração, os frameworks e o paralelismo aceitos em ambientes de várias frações.
Formatos
Todas as frações precisam ter o mesmo formato (por exemplo, o mesmo AcceleratorType).
Formatos heterogêneos não são aceitos.
Orquestração
A orquestração está disponível no GKE. Para mais informações, consulte TPUs no GKE.
Frameworks
Os ambientes de várias frações aceitam apenas cargas de trabalho do JAX e do PyTorch.
Paralelismo
Recomendamos que os usuários testem o ambiente de várias frações com o paralelismo de dados. Para saber como implementar o paralelismo de pipeline com várias frações, entre em contato com seu representante da conta doGoogle Cloud .
Ajuda e feedback
Queremos saber sua opinião. Para compartilhar feedback ou pedir ajuda, entre em contato usando o formulário de ajuda ou feedback do Cloud TPU.