
Creazione di AI di produzione su Cloud TPU con JAX
Lo stack AI JAX estende il core numerico JAX con una raccolta di librerie componibili supportate da Google, trasformandolo in una piattaforma open source end-to-end solida per il machine learning su larga scala. Pertanto, lo stack AI JAX è costituito da un ecosistema completo e solido che copre l'intero ciclo di vita del machine learning:
Fondazione su scala industriale: lo stack JAX AI è progettato per una scalabilità massiccia, sfruttando ML Pathways per orchestrare l'addestramento su decine di migliaia di chip e Orbax per il checkpointing asincrono resiliente e ad alto throughput, consentendo l'addestramento di modelli all'avanguardia di livello di produzione.
Kit di strumenti completo e pronto per la produzione:lo stack JAX AI fornisce un insieme completo di librerie per l'intero processo di sviluppo: Flax per la creazione flessibile di modelli, Optax per strategie di ottimizzazione componibili e Grain per le pipeline di dati deterministiche essenziali per esecuzioni riproducibili su larga scala.
Prestazioni di picco specializzate:per ottenere il massimo utilizzo dell'hardware, lo stack AI JAX offre librerie specializzate, tra cui Tokamax per kernel personalizzati all'avanguardia, Qwix per la quantizzazione non invasiva che aumenta la velocità di addestramento e inferenza e XProf per la profilazione approfondita delle prestazioni integrata nell'hardware.
Percorso completo per la produzione:lo stack AI JAX offre una transizione fluida dalla ricerca al deployment. Sono inclusi MaxText come riferimento scalabile per l'addestramento di modelli di base, Tunix per l'apprendimento per rinforzo (RL) e l'allineamento all'avanguardia e una soluzione di inferenza unificata con l'integrazione di vLLM TPU e il runtime di pubblicazione JAX.
La filosofia dello stack JAX AI è quella di componenti a basso accoppiamento, ognuno dei quali fa bene una cosa. Anziché essere un framework ML monolitico, JAX è di portata limitata e si concentra su operazioni efficienti su array e trasformazioni di programmi. L'ecosistema si basa su questo framework principale per fornire un'ampia gamma di funzionalità, relative sia all'addestramento dei modelli ML sia ad altri tipi di workload come il computing scientifico.
Questo sistema di componenti a basso accoppiamento ti consente di selezionare e combinare le librerie nel modo migliore per soddisfare i tuoi requisiti. Dal punto di vista dell'ingegneria del software, questa architettura consente anche di aggiornare in modo iterativo le funzionalità che tradizionalmente sarebbero considerate componenti del framework di base (ad esempio, pipeline di dati e checkpoint) senza il rischio di destabilizzare il framework di base o di rimanere bloccati nei cicli di rilascio. Poiché la maggior parte delle funzionalità viene implementata nelle librerie anziché nelle modifiche a un framework monolitico, la libreria numerica principale è più duratura e adattabile ai cambiamenti futuri nel panorama tecnologico.
Le sezioni seguenti forniscono una panoramica tecnica dello stack AI JAX, delle sue funzionalità chiave, delle decisioni di progettazione che le hanno ispirate e di come si combinano per creare una piattaforma duratura per i moderni carichi di lavoro ML.
JAX AI Stack e altri componenti dell'ecosistema
| Componente | Funzione / Descrizione |
|---|---|
| Componenti e core di JAX AI Stack1 | |
| JAX | Calcolo di array e trasformazione di programmi orientati all'acceleratore (JIT, grad, vmap, pmap). |
| Lino | Libreria di creazione di reti neurali flessibile per la creazione e la modifica intuitive dei modelli. |
| Optax | Una libreria di trasformazioni di elaborazione e ottimizzazione del gradiente componibili. |
| Orbax | Libreria di checkpointing distribuito "any-scale" per la resilienza dell'addestramento su larga scala. |
| Grano | Una libreria di pipeline di dati di input scalabile, deterministica e controllabile. |
| JAX AI stack - Infrastructure | |
| XLA | Compilatore open source di machine learning per TPU, CPU e GPU. |
| Pathways | Runtime distribuito per l'orchestrazione del calcolo su decine di migliaia di chip. |
| JAX AI stack - Adv. Sviluppo | |
| Pallas | Un'estensione JAX per scrivere kernel personalizzati di basso livello e ad alte prestazioni implementati in Python. |
| Tokamax | Una libreria selezionata di kernel personalizzati ad alte prestazioni e all'avanguardia (ad esempio, Attention). |
| Qwix | Una libreria completa e non intrusiva per la quantizzazione (PTQ, QAT, QLoRA). |
| JAX AI stack - Application | |
| MaxText / MaxDiffusion | Framework di riferimento scalabili e di punta per l'addestramento di modelli di base (ad esempio LLM e Diffusion). |
| Tunix | Un framework per l'allineamento e il post-addestramento all'avanguardia (RLHF, DPO). |
| vLLM | Una soluzione di inferenza LLM ad alte prestazioni che utilizza l'integrazione integrata del framework vLLM. |
| XProf | Un profiler integrato nell'hardware per l'analisi delle prestazioni a livello di sistema. |
1 Incluso nel pacchetto Python jax-ai-stack.
Figura 1: i componenti dello stack e dell'ecosistema JAX AI
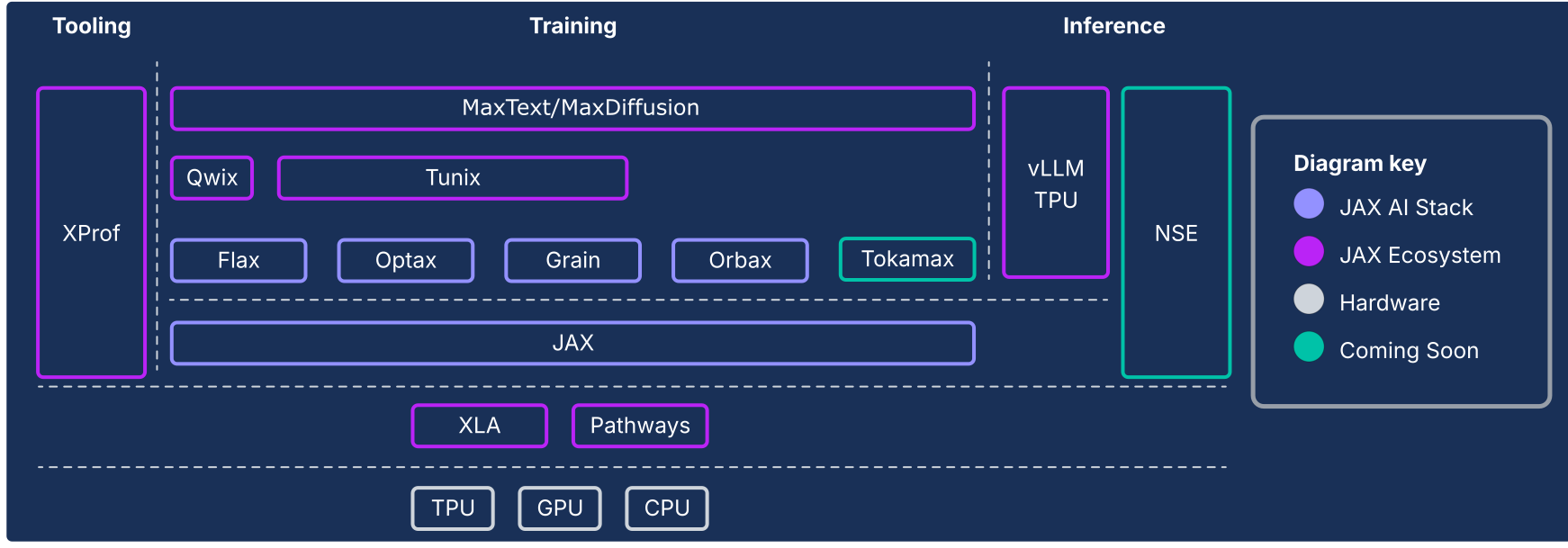
L'imperativo architettonico: prestazioni oltre i framework
Man mano che le architetture dei modelli convergono, ad esempio sui transformer multimodali Mixture-of-Experts (MoE), la ricerca delle massime prestazioni sta portando all'emergere dei Megakernel. Un Megakernel è effettivamente l'intera passata in avanti (o una parte consistente) di un modello specifico, codificato manualmente utilizzando un'API di livello inferiore come l'SDK CUDA sulle GPU NVIDIA. Questo approccio consente di ottenere il massimo utilizzo dell'hardware sovrapponendo in modo aggressivo calcolo, memoria e comunicazione. Recenti lavori della community di ricerca hanno dimostrato che questo approccio può produrre aumenti significativi del throughput, in alcuni casi superiori al 22%, per l'inferenza sulle GPU. Questa tendenza non è limitata all'inferenza; le prove suggeriscono che alcuni sforzi di addestramento su larga scala hanno comportato il controllo hardware di basso livello per ottenere notevoli miglioramenti dell'efficienza.
Se questa tendenza accelera, tutti i framework di alto livello come esistono oggi rischiano di diventare meno pertinenti, poiché l'accesso di basso livello all'hardware è ciò che conta in definitiva per le prestazioni su architetture mature e stabili. Ciò rappresenta una sfida per tutti gli stack ML moderni: come fornire un controllo hardware a livello di esperto senza sacrificare la produttività e la flessibilità di un framework di alto livello.
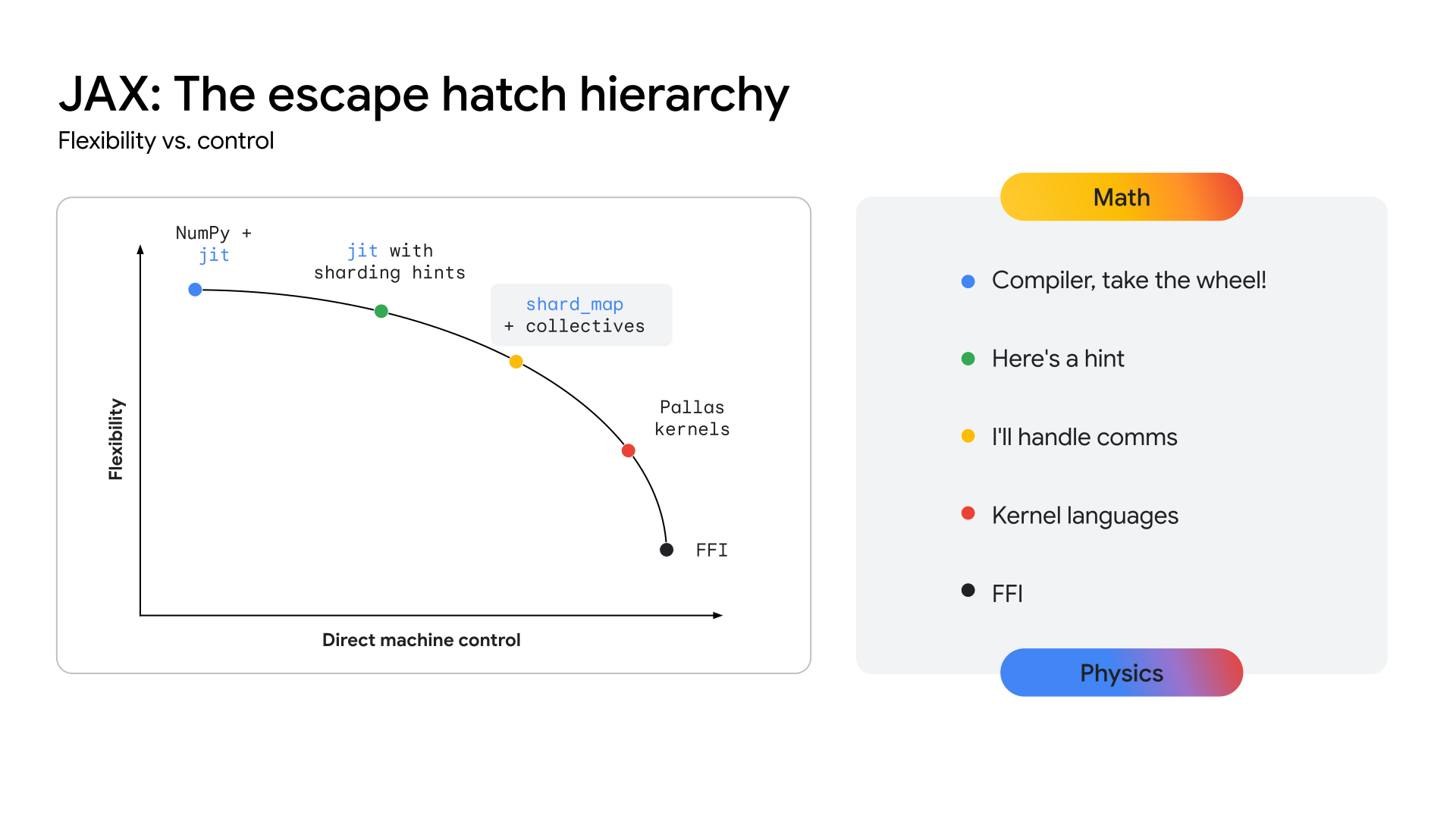
Affinché le TPU forniscano un percorso chiaro verso questo livello di prestazioni, l'ecosistema deve esporre un livello API più vicino all'hardware, consentendo lo sviluppo di questi kernel altamente specializzati. Lo stack JAX è progettato per risolvere questo problema offrendo un continuum di astrazione (vedi Figura 2), dalle ottimizzazioni automatizzate di alto livello del compilatore XLA al controllo manuale e granulare della libreria di creazione del kernel Pallas.
Figura 2: il continuum di astrazione di JAX
Lo stack AI JAX principale
Lo stack JAX AI di base è costituito da cinque librerie chiave che forniscono le basi per lo sviluppo di modelli:
JAX: una base per la trasformazione di programmi componibili ad alte prestazioni
JAX è una libreria Python per il calcolo di array e la trasformazione di programmi orientati agli acceleratori, progettata per il calcolo numerico ad alte prestazioni e il machine learning su larga scala. Con il suo modello di programmazione funzionale e l'API simile a NumPy, JAX fornisce una base solida per le librerie di livello superiore.
Grazie al suo design basato sul compilatore, JAX promuove intrinsecamente la scalabilità sfruttando XLA (vedi la sezione XLA) per analisi, ottimizzazione e targeting hardware aggressivi dell'intero programma. L'enfasi di JAX sulla programmazione funzionale (ad esempio, funzioni pure) rende le sue trasformazioni di programma principali più trattabili e, soprattutto, componibili.
Queste trasformazioni di base possono essere combinate per ottenere prestazioni elevate e scalabilità dei workload in base alle dimensioni del modello, alle dimensioni del cluster e ai tipi di hardware:
- jit: compilazione just-in-time delle funzioni Python in eseguibili XLA ottimizzati e fusi.
- grad: differenziazione automatica, che supporta la modalità diretta e inversa, nonché derivate di ordine superiore.
- vmap: vettorizzazione automatica, che consente il batching e il parallelismo dei dati senza modificare la logica della funzione.
- pmap / shard_map: parallelizzazione automatica su più dispositivi (ad esempio, core TPU), che costituisce la base per l'addestramento distribuito.
L'integrazione perfetta con il modello GSPMD (General-purpose SPMD) di XLA consente a JAX di parallelizzare automaticamente i calcoli su pod TPU di grandi dimensioni con modifiche minime al codice. Nella maggior parte dei casi, lo scaling richiede solo annotazioni di sharding di alto livello.
Flax: Flexible neural network authoring
Flax semplifica la creazione, il debug e l'analisi delle reti neurali in JAX fornendo un approccio intuitivo e orientato agli oggetti alla creazione di modelli. Sebbene l'API funzionale di JAX sia potente, offre un'astrazione basata su livelli più familiare per gli sviluppatori abituati a framework come PyTorch, senza alcuna penalità in termini di prestazioni.
Questo design semplifica la modifica o la combinazione dei componenti del modello addestrato.
Tecniche come LoRA e la quantizzazione richiedono definizioni di modelli manipolabili, che l'API NNX di Flax fornisce tramite un'interfaccia Pythonic. NNX incapsula
lo stato del modello, riducendo il carico cognitivo dell'utente e consentendo l'attraversamento
e la modifica programmatica della gerarchia del modello.
Punti di forza principali:
- API intuitiva orientata agli oggetti: semplifica la costruzione del modello e consente casi d'uso avanzati come la sostituzione di sottomoduli e l'inizializzazione parziale.
- Coerenza con Core JAX: Flax fornisce trasformazioni sollevate completamente compatibili con il paradigma funzionale di JAX, offrendo le prestazioni complete di JAX con una maggiore facilità d'uso per gli sviluppatori.
Optax: Strategie di elaborazione e ottimizzazione del gradiente componibili
Optax è una libreria di elaborazione e ottimizzazione dei gradienti per JAX. È progettata per fornire ai creatori di modelli componenti di base che possono essere ricombinati in modi personalizzati per addestrare modelli di deep learning, tra le altre applicazioni. Si basa sulle funzionalità della libreria JAX di base per fornire una libreria di funzioni di perdita e ottimizzatore e tecniche associate ben testate e ad alte prestazioni che possono essere utilizzate per addestrare modelli ML.
Motivazione
Il calcolo e la minimizzazione delle perdite sono alla base di ciò che consente l'addestramento dei modelli ML. Grazie al supporto della differenziazione automatica, la libreria JAX di base fornisce le funzionalità numeriche per addestrare i modelli, ma non implementazioni standard di ottimizzatori (ad esempio RMSProp o Adam) o perdite (ad esempio CrossEntropy o MSE). Anche se potresti implementare queste funzioni (e alcuni sviluppatori esperti sceglieranno di farlo), un bug nell'implementazione di un ottimizzatore introdurrebbe problemi di qualità del modello difficili da diagnosticare. Anziché chiedere all'utente di implementare questi elementi critici, Optax fornisce implementazioni di questi algoritmi testate per correttezza e prestazioni.
Il campo della teoria dell'ottimizzazione si trova nel regno della ricerca, ma il suo ruolo centrale nell'addestramento lo rende anche una parte indispensabile dell'addestramento dei modelli ML di produzione. Una libreria che svolge questo ruolo deve essere sufficientemente flessibile per adattarsi a iterazioni di ricerca rapide, ma anche sufficientemente solida e performante per essere affidabile per l'addestramento del modello di produzione. Inoltre, dovrebbe fornire implementazioni ben testate di algoritmi all'avanguardia che corrispondono alle equazioni standard. La libreria Optax, grazie alla sua architettura modulare componibile e all'enfasi sul codice corretto e leggibile, è progettata per raggiungere questo obiettivo.
Design
Optax è progettato per migliorare la velocità della ricerca e la transizione dalla ricerca alla produzione fornendo implementazioni leggibili, ben testate ed efficienti degli algoritmi di base. Optax ha utilizzi che vanno oltre il contesto del deep learning, ma in questo contesto può essere considerato una raccolta di funzioni di perdita, algoritmi di ottimizzazione e trasformazioni del gradiente ben noti implementati in modo puramente funzionale in linea con la filosofia di JAX. La raccolta di funzioni di perdita e ottimizzatori ben noti consente agli utenti di iniziare con facilità e sicurezza.
L'approccio modulare adottato da Optax consente di concatenare più ottimizzatori insieme, seguiti da altre trasformazioni comuni (ad esempio, il troncamento del gradiente) e di raggrupparli utilizzando tecniche comuni come MultiStep o Lookahead per ottenere strategie di ottimizzazione efficaci con poche righe di codice. L'interfaccia flessibile ti consente di studiare nuovi algoritmi di ottimizzazione e di utilizzare potenti tecniche di ottimizzazione di secondo ordine come shampoo o muon.
# Optax implementation of a RMSProp optimizer with a custom learning rate
# schedule, gradient clipping and gradient accumulation.
optimizer = optax.chain(
optax.clip_by_global_norm(GRADIENT_CLIP_VALUE),
optax.rmsprop(learning_rate=optax.cosine_decay_schedule(init_value=lr,decay_steps=decay)),
optax.apply_every(k=ACCUMULATION_STEPS)
)
# The same thing, in PyTorch
optimizer = optim.RMSprop(model_params, lr=LEARNING_RATE)
scheduler = optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=TOTAL_STEPS)
for i, (inputs, targets) in enumerate(data_loader):
# ... Training loop body ...
if (i + 1) % ACCUMULATION_STEPS == 0:
torch.nn.utils.clip_grad_norm_(model.parameters(), GRADIENT_CLIP_VALUE)
optimizer.step()
scheduler.step()
optimizer.zero_grad()
Lo snippet di codice precedente mostra come configurare un ottimizzatore con un tasso di apprendimento personalizzato, il troncamento del gradiente e l'accumulo del gradiente.
Punti di forza principali
- Libreria solida: fornisce una libreria completa di perdite, ottimizzatori e algoritmi con particolare attenzione alla correttezza e alla leggibilità.
- Trasformazioni modulari concatenabili:questa API flessibile ti consente di creare strategie di ottimizzazione potenti e complesse in modo dichiarativo, senza modificare il ciclo di addestramento.
- Funzionale e scalabile:le implementazioni funzionali pure si integrano perfettamente con i meccanismi di parallelizzazione di JAX (ad esempio pmap), consentendoti di utilizzare lo stesso codice per scalare da un singolo host a cluster di grandi dimensioni.
Orbax / TensorStore: checkpointing distribuito su larga scala
Orbax è una libreria di checkpoint per JAX progettata per qualsiasi scala, dal singolo dispositivo all'addestramento distribuito su larga scala. Il suo obiettivo è unificare le implementazioni frammentate del checkpointing e fornire funzionalità di rendimento critiche, come il checkpointing asincrono e multilivello, a un pubblico più ampio. Orbax consente la resilienza necessaria per i job di addestramento di grandi dimensioni e fornisce un formato flessibile per la pubblicazione dei checkpoint.
A differenza dei sistemi di checkpoint e ripristino generalizzati che acquisiscono uno snapshot dell'intero stato del sistema, il checkpoint ML con Orbax salva in modo selettivo solo le informazioni essenziali per riprendere l'addestramento dei pesi del modello, lo stato dell'ottimizzatore e lo stato del caricatore di dati. Questo approccio mirato riduce al minimo i tempi di inattività dell'acceleratore. Orbax lo fa sovrapponendo le operazioni di I/O al calcolo, una funzionalità fondamentale per i workload di grandi dimensioni. Il tempo di inattività degli acceleratori temporali viene ridotto alla durata del trasferimento dei dati dal dispositivo host, che può essere ulteriormente sovrapposto al passaggio di addestramento successivo, rendendo il checkpointing quasi senza costi dal punto di vista delle prestazioni.
Al suo interno, Orbax utilizza TensorStore per la lettura e la scrittura efficienti e parallele dei dati degli array. L'API Orbax astrae questa complessità, offrendo un'interfaccia intuitiva per la gestione di PyTrees, che sono la rappresentazione standard dei modelli in JAX.
Punti di forza principali:
- Adozione diffusa: Con milioni di download mensili, Orbax funge da mezzo comune per la condivisione di artefatti di ML.
- Semplifica le complessità: Orbax astrae le complessità del checkpointing distribuito, inclusi il salvataggio asincrono, l'atomicità e i dettagli del file system.
- Flessibile: oltre a offrire API per casi d'uso comuni, Orbax ti consente di personalizzare il flusso di lavoro per gestire requisiti specializzati.
- Prestazioni elevate e scalabilità: funzionalità come il checkpointing asincrono, un formato di archiviazione efficiente (OCDBT) e strategie di caricamento intelligente dei dati garantiscono che Orbax possa essere scalato per eseguire addestramenti che coinvolgono decine di migliaia di nodi.
Grain: pipeline di dati di input deterministiche e scalabili
Grain è una libreria Python per leggere ed elaborare i dati per l'addestramento e la valutazione dei modelli JAX. È flessibile, veloce e deterministico e supporta funzionalità avanzate come il checkpointing, essenziali per l'addestramento riuscito di workload di grandi dimensioni. Supporta i formati di dati e i backend di archiviazione più comuni e fornisce anche un'API flessibile per estendere il supporto a formati e backend specifici dell'utente che non sono supportati in modo nativo. Sebbene Grain sia progettato principalmente per funzionare con JAX, è indipendente dal framework, non richiede l'esecuzione di JAX e può essere utilizzato anche con altri framework.
Motivazione
Le pipeline di dati costituiscono una parte fondamentale dell'infrastruttura di addestramento. Devono essere flessibili in modo che le trasformazioni comuni possano essere espresse in modo efficiente e sufficientemente performanti da mantenere gli acceleratori occupati in ogni momento. Inoltre, devono essere in grado di supportare più formati di archiviazione e backend. A causa dei tempi di esecuzione più lunghi, l'addestramento di modelli di grandi dimensioni su larga scala pone ulteriori requisiti alla pipeline di dati oltre a quelli richiesti dai normali carichi di lavoro di addestramento, principalmente incentrati su determinismo e riproducibilità2. La libreria Grain è progettata con un'architettura flessibile che soddisfa queste esigenze.
2Nella sezione 5.1 del documento su PaLM, gli autori osservano picchi di perdita molto elevati nonostante il ritaglio del gradiente sia attivato. La soluzione è stata rimuovere i batch di dati problematici e riavviare l'addestramento da un checkpoint precedente al picco di perdita. Ciò è possibile solo con una configurazione di addestramento completamente deterministica e riproducibile.
Design
Al livello più alto, esistono due modi per strutturare una pipeline di input: come cluster separato di data worker o collocando i data worker sugli host che gestiscono gli acceleratori. Grain sceglie la seconda opzione per diversi motivi.
Gli acceleratori vengono combinati con host potenti che in genere rimangono inattivi durante i passaggi di addestramento, il che li rende una scelta naturale per eseguire la pipeline di dati di input. Questa implementazione offre ulteriori vantaggi: semplifica la visualizzazione dello sharding dei dati fornendo una visualizzazione coerente dello sharding tra input e calcolo. Si potrebbe sostenere che l'inserimento del data worker sull'host dell'acceleratore rischia di saturare la CPU dell'host, ma ciò non impedisce di scaricare le trasformazioni ad alta intensità di calcolo su un altro cluster utilizzando le RPC3.
Per quanto riguarda l'API, con un'implementazione Python pura che supporta più processi e un'API flessibile, Grain ti consente di implementare trasformazioni dei dati complesse in modo arbitrario componendo insieme le fasi della pipeline in base a paradigmi di trasformazione ben noti.
Grain supporta formati di dati ad accesso casuale efficienti come
ArrayRecord e Bagz, oltre ad altri formati di dati popolari come Parquet
e TFDS. Grain supporta la lettura dai file system locali e da Cloud Storage per impostazione predefinita. Oltre a supportare i backend e i formati di archiviazione più diffusi, un'astrazione pulita al livello di archiviazione ti consente di aggiungere il supporto o eseguire il wrapping delle origini dati esistenti per renderle compatibili con la libreria Grain.
3 È così che devono funzionare le pipeline di dati multimodali: i tokenizer di immagini e audio, ad esempio, sono modelli che vengono eseguiti nei propri cluster sui propri acceleratori e le pipeline di input effettuano chiamate RPC per convertire gli esempi di dati in flussi di token.
Punti di forza principali
- Inserimento deterministico dei dati: la collocazione del worker dei dati con l'acceleratore e l'accoppiamento con un rimescolamento globale stabile e iteratori con checkpoint consentono di creare checkpoint dello stato del modello e della pipeline di dati insieme in uno snapshot coerente utilizzando Orbax, migliorando il determinismo del processo di addestramento.
- API flessibili per abilitare trasformazioni dei dati efficaci:un'API di trasformazioni flessibile e pura in Python consente di eseguire trasformazioni dei dati estese all'interno della pipeline di elaborazione dell'input.
- Supporto estensibile per più formati e backend:un'API origini dati estensibile supporta i formati e i backend di archiviazione più comuni e consente di aggiungere il supporto per nuovi formati e backend.
- Potente interfaccia di debug:gli strumenti di visualizzazione della pipeline di dati e una modalità di debug ti consentono di esaminare, eseguire il debug e ottimizzare le prestazioni delle pipeline di dati.
Lo stack AI JAX esteso
Oltre allo stack principale, un ricco ecosistema di librerie specializzate fornisce l'infrastruttura, gli strumenti avanzati e le soluzioni a livello di applicazione necessari per lo sviluppo ML end-to-end.
Infrastruttura di base: compilatori e runtime
XLA: il motore indipendente dall'hardware e incentrato sul compilatore
Motivazione
XLA o Accelerated Linear Algebra è il compilatore specifico per il dominio di Google, che è ben integrato in JAX e supporta dispositivi hardware TPU, CPU e GPU. XLA è stato progettato per essere un generatore di codice indipendente dall'hardware che ha come target TPU, GPU e CPU.
La progettazione del compilatore XLA è una scelta architettonica fondamentale che crea un vantaggio duraturo in un panorama di ricerca in rapida evoluzione. Al contrario, l'approccio prevalente incentrato sul kernel in altri ecosistemi si basa su librerie ottimizzate manualmente per le prestazioni. Sebbene questo approccio sia molto efficace per architetture di modelli stabili e consolidate, crea un collo di bottiglia per l'innovazione. Quando nuove ricerche introducono nuove architetture, l'ecosistema deve attendere che vengano scritti e ottimizzati nuovi kernel. Il nostro design incentrato sul compilatore, tuttavia, può spesso essere generalizzato a nuovi pattern, fornendo un percorso ad alte prestazioni per la ricerca all'avanguardia fin dal primo giorno.
Design
XLA funziona compilando Just-In-Time (JIT) i grafici di calcolo che JAX genera durante il processo di tracciamento (ad esempio, quando una funzione è decorata con @jax.jit).
Questa compilazione segue una pipeline in più fasi:
- Grafico di calcolo JAX
- Ottimizzatore di alto livello (HLO)
- Ottimizzatore di basso livello (LLO)
- Codice hardware
- Da JAX Graph a HLO: il grafico di calcolo JAX viene convertito nella rappresentazione HLO di XLA. A questo livello elevato, vengono applicate ottimizzazioni potenti e indipendenti dall'hardware, come la fusione degli operatori e la gestione efficiente della memoria. Il dialetto StableHLO funge da interfaccia durevole e con controllo delle versioni per questa fase.
- Da HLO a LLO: dopo le ottimizzazioni di alto livello, i backend specifici dell'hardware prendono il sopravvento, abbassando la rappresentazione HLO in un LLO orientato alla macchina.
- Da LLO a codice hardware: l'LLO viene finalmente compilato in codice macchina altamente efficiente. Per le TPU, questo codice viene raggruppato come pacchetti Very Long Instruction Word (VLIW) che vengono inviati direttamente all'hardware.
Per lo scaling, la progettazione di XLA si basa sul parallelismo. Utilizza algoritmi per utilizzare al massimo le unità di moltiplicazione della matrice (MXU) su un chip. Tra i chip, XLA utilizza SPMD (Single Program Multiple Data), una tecnica di parallelizzazione basata sul compilatore che utilizza un singolo programma su tutti i dispositivi. Questo potente modello è esposto tramite le API JAX, che ti consentono di gestire il parallelismo di dati, modelli o pipeline con annotazioni di sharding di alto livello.
Per pattern di parallelismo più complessi, è possibile anche Multiple Program Multiple Data (MPMD) e librerie come PartIR:MPMD consentono agli utenti JAX di fornire anche annotazioni MPMD.
Punti di forza principali
- Compilazione: la compilazione just-in-time del grafico di calcolo consente ottimizzazioni del layout di memoria, dell'allocazione dei buffer e della gestione della memoria. Alternative come le metodologie basate sul kernel trasferiscono questo onere allo sviluppatore. Nella maggior parte dei casi, XLA può ottenere prestazioni eccellenti senza compromettere la velocità degli sviluppatori.
- Parallelismo:XLA implementa diverse forme di parallelismo con SPMD e questo viene esposto a livello JAX. In questo modo puoi esprimere strategie di sharding, consentendo la sperimentazione e la scalabilità dei modelli su migliaia di chip.
Pathways: un runtime unificato per il calcolo distribuito su larga scala
Pathways offre astrazioni per l'addestramento e l'inferenza distribuiti con tolleranza agli errori e ripristino integrati, consentendo ai ricercatori ML di scrivere codice come se utilizzassero una singola macchina potente.
Motivazione
Per poter addestrare ed eseguire il deployment di modelli di grandi dimensioni, sono necessari da centinaia a migliaia di chip. Questi chip sono distribuiti su numerosi rack e macchine host. Un job di addestramento è un programma sincrono su larga scala che richiede tutti questi chip e i rispettivi host per funzionare in tandem sui calcoli XLA che sono stati parallelizzati (suddivisi). Nel caso di modelli linguistici di grandi dimensioni, che potrebbero aver bisogno di più di decine di migliaia di chip, questo servizio deve essere in grado di estendersi su più pod in una struttura di data center, oltre a utilizzare le strutture di interconnessione interchip (ICI) e on-chip (OCI) all'interno di un pod.
Design
ML Pathways è il sistema che utilizziamo per coordinare i calcoli distribuiti su host e chip TPU. È progettato per la scalabilità e l'efficienza su centinaia di migliaia di acceleratori. Per l'addestramento su larga scala, fornisce un unico client Python per più job Pod, integrazione di Megascale XLA, servizio di compilazione e Python remoto. Supporta anche il parallelismo e la tolleranza di preemptive tra slice, consentendo il recupero automatico dalle preemptive delle risorse.
Pathways incorpora collettivi cross-host ottimizzati che consentono ai grafici di calcolo XLA di estendersi oltre un singolo pod TPU. Estende il supporto di XLA per il parallelismo di dati, modelli e pipeline in modo che funzioni oltre i limiti delle sezioni TPU utilizzando la rete di data center (DCN) mediante l'integrazione di un runtime distribuito che gestisce la comunicazione DCN con le primitive di comunicazione XLA.
Punti di forza principali
L'architettura a controller singolo, integrata con JAX, è un'astrazione chiave. Consente ai ricercatori di esplorare varie strategie di sharding e parallelismo per l'addestramento e il deployment, scalando facilmente a decine di migliaia di chip.
Sviluppo avanzato: prestazioni, dati ed efficienza
Pallas: Writing high performance custom kernels in JAX
Sebbene JAX sia incentrato sul compilatore, in alcune situazioni potresti voler controllare
l'hardware in modo granulare per ottenere le massime prestazioni. Pallas è un'estensione di JAX che consente di scrivere kernel personalizzati per GPU e TPU. Il suo obiettivo è fornire un controllo preciso sul codice generato, combinato con l'ergonomia di alto livello del tracing JAX e dell'API jax.numpy.
Pallas espone un modello di parallelismo basato su griglia in cui una funzione kernel definita dall'utente viene avviata in una griglia multidimensionale di gruppi di lavoro paralleli. Consente la gestione esplicita della gerarchia di memoria consentendoti di definire in che modo i tensori vengono suddivisi in blocchi e trasferiti tra la memoria più lenta e più grande (ad esempio, HBM) e la memoria on-chip più veloce e più piccola (ad esempio, VMEM su TPU, memoria condivisa su GPU), utilizzando le mappe degli indici per associare le posizioni della griglia a blocchi di dati specifici. Pallas può ridurre la stessa definizione del kernel per l'esecuzione efficiente sia sulle TPU di Google che su varie GPU compilando i kernel in una rappresentazione intermedia adatta all'architettura di destinazione: Mosaic per le TPU o utilizzando tecnologie come Triton per le GPU. Con Pallas, puoi scrivere kernel ad alte prestazioni che specializzano blocchi come l'attenzione per ottenere le migliori prestazioni del modello sull'hardware di destinazione senza dover fare affidamento su toolkit specifici del fornitore.
Tokamax: una raccolta curata di kernel all'avanguardia
Se Pallas è uno strumento per la creazione di kernel, Tokamax è una libreria di kernel di acceleratori personalizzati all'avanguardia che supportano sia TPU che GPU. Tokamax si basa su JAX e Pallas e ti consente di utilizzare tutta la potenza dell'hardware. Fornisce inoltre strumenti per creare e ottimizzare automaticamente i kernel personalizzati.
Motivazione
JAX, che ha le sue radici in XLA, è un framework basato sul compilatore. Tuttavia, esiste un insieme ristretto di casi in cui potrebbe essere necessario assumere il controllo diretto dell'hardware per ottenere le massime prestazioni4. I kernel personalizzati sono fondamentali per ottenere le migliori prestazioni da risorse di accelerazione ML costose come TPU e GPU. Sebbene siano ampiamente utilizzati per consentire l'esecuzione efficiente di operatori chiave come Attention, la loro implementazione richiede una profonda comprensione sia del modello che dell'architettura hardware di destinazione. Tokamax fornisce un'unica fonte autorevole di kernel curati, ben testati e ad alte prestazioni, in combinazione con un'infrastruttura condivisa solida per il loro sviluppo, manutenzione e gestione del ciclo di vita. Una libreria di questo tipo può anche fungere da implementazione di riferimento su cui basarsi e da personalizzare in base alle necessità. In questo modo puoi concentrarti sui tuoi sforzi di modellazione senza doverti preoccupare dell'infrastruttura.
4Si tratta di un paradigma consolidato e ha precedenti nel mondo delle CPU, dove il codice compilato costituisce la maggior parte del programma e gli sviluppatori utilizzano istruzioni intrinseche o assembly inline per ottimizzare le sezioni critiche per le prestazioni.
Design
Per ogni kernel, Tokamax fornisce un'API comune che può essere supportata da più implementazioni. Ad esempio, i kernel TPU possono essere implementati tramite l'abbassamento XLA standard o in modo esplicito con Pallas/Mosaic-TPU. I kernel GPU possono essere implementati mediante la riduzione XLA standard, con Mosaic-GPU o Triton. Per impostazione predefinita, l'API Tokamax sceglie l'implementazione più nota per una determinata configurazione, determinata dai risultati memorizzati nella cache di esecuzioni periodiche di autotuning e benchmarking, anche se puoi scegliere implementazioni specifiche, se necessario. Nel tempo potrebbero essere aggiunte nuove implementazioni per sfruttare meglio funzionalità specifiche nelle nuove generazioni di hardware e ottenere prestazioni ancora migliori.
Un componente chiave della libreria Tokamax, oltre ai kernel stessi, è l'infrastruttura di supporto che ti consente di scrivere kernel personalizzati. Ad esempio, l'infrastruttura di ottimizzazione automatica ti consente di definire un insieme di parametri configurabili (ad esempio, le dimensioni dei riquadri) su cui Tokamax può eseguire una scansione esaustiva per determinare e memorizzare nella cache le migliori impostazioni ottimizzate possibili. Le regressioni notturne ti proteggono da problemi imprevisti di prestazioni e numerici causati da modifiche all'infrastruttura del compilatore sottostante o ad altre dipendenze.
Punti di forza principali
- Esperienza sviluppatore senza interruzioni: una libreria unificata e curata fornisce implementazioni note, valide e ad alte prestazioni dei kernel chiave, con espressioni chiare delle generazioni di hardware supportate e delle prestazioni previste, sia a livello programmatico che nella documentazione. In questo modo si riducono al minimo la frammentazione e l'abbandono.
- Flessibilità e gestione del ciclo di vita:puoi scegliere implementazioni diverse, anche modificandole nel tempo, se opportuno. Ad esempio, se il compilatore XLA migliora il supporto di determinate operazioni non richiede più kernel personalizzati, esiste un percorso di ritiro e migrazione.
- Estensibilità:puoi implementare i tuoi kernel sfruttando un'infrastruttura condivisa ben supportata, il che ti consente di concentrarti su funzionalità e ottimizzazioni a valore aggiunto. Le implementazioni standard chiaramente create servono come punto di partenza per gli utenti da cui imparare ed estendere.
Qwix: quantizzazione non intrusiva e completa
Qwix è una libreria di quantizzazione completa per lo stack JAX AI, che supporta sia gli LLM sia altri tipi di modelli in tutte le fasi, tra cui l'addestramento (Quantization Aware Training (QAT), Quantization Technique (QT), Quantized Low-Rank Adaptation (QLoRA)) e l'inferenza Post Training Quantization (PTQ), con targeting sia per XLA sia per i runtime on-device.
Motivazione
Le librerie di quantizzazione esistenti, in particolare nell'ecosistema PyTorch, spesso hanno scopi limitati (ad esempio, solo PTQ o solo QLoRA). Questo panorama frammentato ti costringe a cambiare strumento, impedendo l'utilizzo coerente del codice e la corrispondenza numerica precisa tra addestramento e inferenza. Inoltre, molte soluzioni richiedono modifiche sostanziali al modello, accoppiando strettamente la logica del modello alla logica di quantizzazione.
Design
La filosofia di progettazione di Qwix enfatizza una soluzione completa e, soprattutto, un'integrazione del modello non intrusiva. È progettato con un design gerarchico ed estensibile basato su API funzionali riutilizzabili.
Questa integrazione non invasiva viene ottenuta tramite un meccanismo di intercettazione progettato meticolosamente che reindirizza le funzioni JAX alle loro controparti quantizzate. Ciò ti consente di integrare i tuoi modelli senza modifiche, separando completamente il codice di quantizzazione dalle definizioni dei modelli.
L'esempio seguente mostra l'applicazione della quantizzazione w4a4 (un peso a 4 bit, un'attivazione a 4 bit) ai livelli MLP di un LLM e della quantizzazione w8 (un peso a 8 bit) all'incorporatore. Per modificare la ricetta di quantizzazione, devi solo
aggiornare l'elenco delle regole.
fp_model = ModelWithoutQuantization(...)
rules = [
qwix.QuantizationRule(
module_path=r'embedder',
weight_qtype='int8',
),
qwix.QuantizationRule(
module_path=r'layers_\d+/mlp',
weight_qtype='int4',
act_qtype='int4',
tile_size=128,
weight_calibration_method='rms,7',
),
]
quantized_model = qwix.quantize_model(fp_model, qwix.PtqProvider(rules))
Punti di forza principali
- Soluzione completa: Qwix è ampiamente applicabile a numerosi scenari di quantizzazione, garantendo un utilizzo coerente del codice tra l'addestramento e l'inferenza.
- Integrazione non invasiva del modello: come mostra l'esempio, puoi integrare i modelli con una sola riga di codice. In questo modo, puoi utilizzare gli iperparametri in molti schemi di quantizzazione per trovare il miglior compromesso tra qualità e prestazioni.
- Federato con altre librerie: Qwix si integra perfettamente con lo stack AI JAX. Ad esempio, Tokamax si adatta automaticamente per utilizzare versioni quantizzate dei kernel, senza codice utente aggiuntivo, quando il modello viene quantizzato con Qwix.
- Adatto alla ricerca: le API di base e l'architettura estensibile di Qwix consentono ai ricercatori di esplorare nuovi algoritmi e facilitano i confronti diretti con strumenti di benchmark e valutazione integrati.
Livello di applicazione: addestramento e allineamento
Addestramento di modelli di base: MaxText e MaxDiffusion
MaxText e MaxDiffusion sono i framework di addestramento di modelli LLM e di diffusione di punta di Google, rispettivamente. Questi repository contengono una selezione di implementazioni altamente ottimizzate di modelli open-weights popolari. Hanno un duplice scopo: fungono sia da codebase di addestramento del modello pronto all'uso sia da riferimento che i creatori di foundation model possono utilizzare come base.
Motivazione
In tutto il settore si registra un rapido aumento dell'interesse per l'addestramento dei modelli di AI generativa. La popolarità dei modelli aperti ha accelerato questa tendenza, fornendo architetture collaudate. L'addestramento e l'adattamento di questi modelli richiedono prestazioni elevate, efficienza, scalabilità a un numero elevato di chip e codice chiaro e comprensibile. MaxText e MaxDiffusion sono soluzioni complete che possono essere utilizzate su TPU o GPU e sono progettate per soddisfare queste esigenze.
Design
MaxText e MaxDiffusion sono codebase di modelli di base progettate con leggibilità e prestazioni in mente. Sono strutturati con componenti riutilizzabili e ben testati: definizioni di modelli che utilizzano kernel personalizzati (come Tokamax) per ottenere le massime prestazioni, un harness di addestramento per l'orchestrazione e il monitoraggio e un potente sistema di configurazione che consente di controllare dettagli come lo sharding e la quantizzazione (utilizzando Qwix) tramite un'interfaccia intuitiva. Sono incorporate funzionalità di affidabilità avanzate, come il checkpointing multilivello, per garantire un buonput sostenuto.
MaxText e MaxDiffusion utilizzano le migliori librerie JAX, Qwix, Tunix, Orbax e Optax, per fornire funzionalità di base. Queste librerie forniscono un'infrastruttura solida e scalabile, riducendo l'overhead di sviluppo e consentendoti di concentrarti sull'attività di modellazione. Per l'inferenza, il codice del modello viene condiviso per consentire una distribuzione efficiente e scalabile.
Punti di forza principali
- Prestazioni per progettazione:con un'infrastruttura di addestramento configurata per un'elevata "goodput" (throughput utile) e implementazioni di modelli ottimizzate per un'elevata MFU (Model Flops Utilization), MaxText e MaxDiffusion offrono prestazioni elevate su larga scala pronte all'uso.
- Progettati per la scalabilità:sfruttando la potenza dello stack AI JAX (in particolare Pathways), questi framework consentono di scalare senza problemi da decine di chip a decine di migliaia di chip.
- Base solida per i creatori di modelli di base:le implementazioni leggibili e di alta qualità fungono da solido punto di partenza per gli sviluppatori, che possono utilizzarle come soluzione end-to-end o come implementazione di riferimento per le proprie personalizzazioni.
Post-training e allineamento: il framework Tunix
Tunix offre algoritmi di apprendimento per rinforzo (RL) open source all'avanguardia, insieme a un framework e un'infrastruttura robusti, fornendo agli sviluppatori un percorso semplificato per sperimentare le tecniche di post-addestramento degli LLM, tra cui il fine-tuning supervisionato (SFT) e l'allineamento utilizzando JAX e TPU.
Motivazione
Il post-training è un passaggio fondamentale per sbloccare il vero potenziale degli LLM. La fase di reinforcement learning (RL) è particolarmente cruciale per sviluppare l'allineamento e le capacità di ragionamento. Lo sviluppo open source in questo settore si è basato quasi esclusivamente su PyTorch e GPU, lasciando una lacuna fondamentale per le soluzioni JAX e TPU. Tunix (Tune-in-JAX) è una libreria ad alte prestazioni nativa di JAX progettata per colmare questa lacuna.
Design
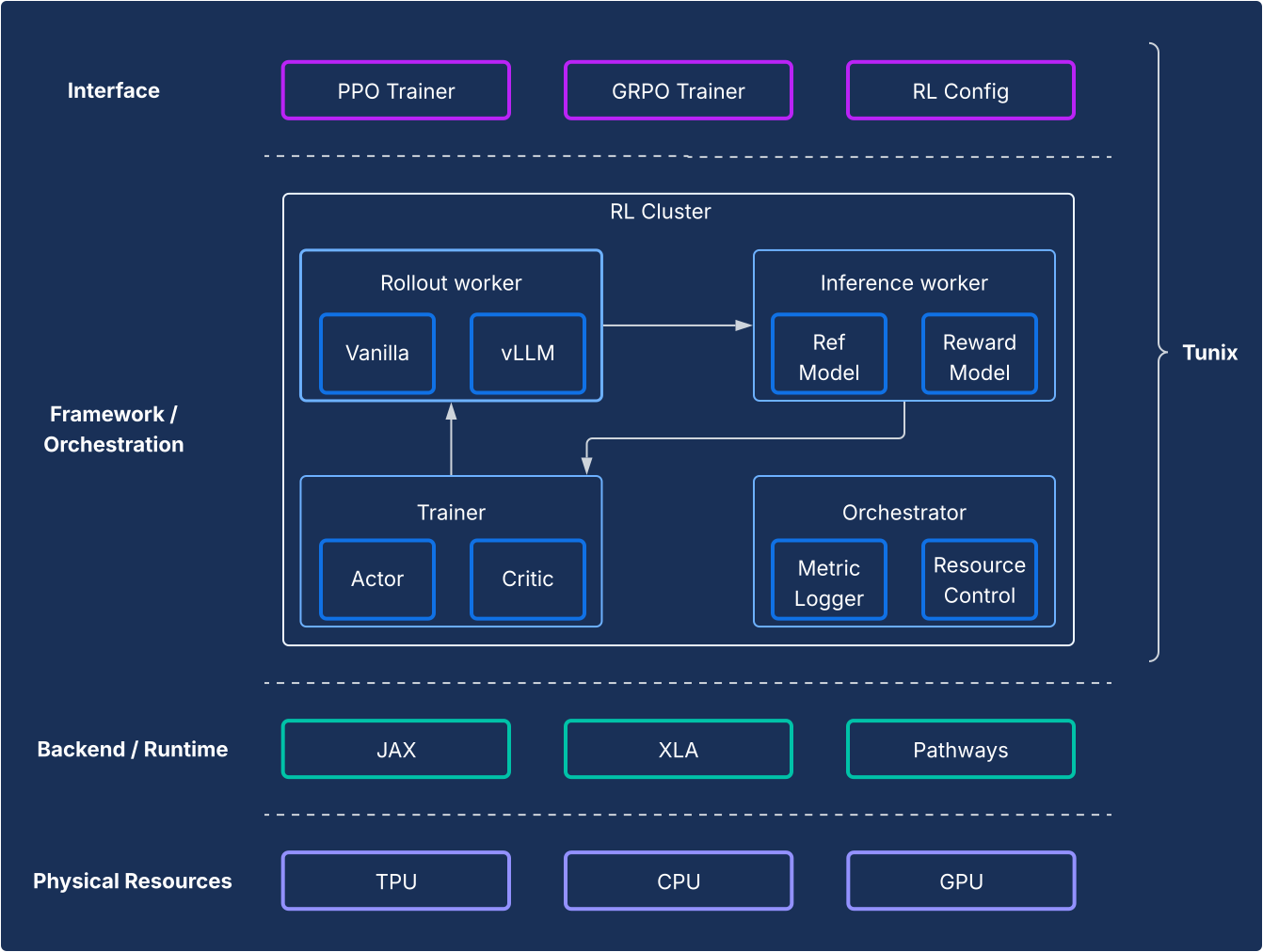
Dal punto di vista del framework, Tunix consente una configurazione all'avanguardia che separa chiaramente gli algoritmi RL dall'infrastruttura. Offre un'API leggera simile a un client che nasconde la complessità dell'infrastruttura RL, consentendoti di sviluppare nuovi algoritmi. Tunix fornisce soluzioni pronte all'uso per algoritmi popolari, tra cui Proximal Policy Optimization (PPO), Direct Preference Optimization (DPO) e altri.
Per quanto riguarda l'infrastruttura, Tunix è integrato con Pathways, consentendo un'architettura a controller singolo che rende accessibile l'addestramento RL multi-nodo. Per quanto riguarda l'addestramento, Tunix supporta in modo nativo l'addestramento efficiente dei parametri (ad esempio LoRA) e sfrutta lo sharding JAX e XLA (parallelizzazione generale e scalabile per il grafico di calcolo ML (GSPMD)) per generare un grafico di calcolo performante. Supporta modelli open source popolari come Gemma e Llama out of the box.
Punti di forza principali
- Semplicità:fornisce un'API di alto livello simile a un client che astrae le complessità dell'infrastruttura distribuita sottostante.
- Efficienza degli sviluppatori:Tunix accelera il ciclo di vita della ricerca e sviluppo con algoritmi e "ricette" integrati, fornendoti un modello funzionante e consentendoti di eseguire iterazioni rapidamente.
- Prestazioni e scalabilità: Tunix consente un'infrastruttura di addestramento orizzontalmente scalabile e altamente efficiente sfruttando Pathways come unico controller nel backend.
Livello di applicazione: produzione e inferenza
Una sfida storica per l'adozione di JAX è stata il percorso dalla ricerca alla produzione. Lo stack AI JAX ora fornisce una storia di produzione matura e duplice che offre sia la compatibilità dell'ecosistema sia le prestazioni di JAX.
Inferenza LLM ad alte prestazioni: la soluzione vLLM
vLLM-TPU è lo stack di inferenza ad alte prestazioni di Google progettato per eseguire in modo efficiente modelli linguistici di grandi dimensioni (LLM) PyTorch e JAX su Cloud TPU. Ciò è possibile grazie all'integrazione nativa del popolare framework open source vLLM con l'ecosistema JAX e TPU di Google.
Motivazione
Il settore è in rapida evoluzione, con una crescente domanda di soluzioni di inferenza fluide, ad alte prestazioni e facili da usare. Gli sviluppatori spesso devono affrontare sfide significative dovute a strumenti complessi e incoerenti, prestazioni scadenti e compatibilità limitata dei modelli. Lo stack vLLM risolve questi problemi fornendo una piattaforma unificata, performante e intuitiva.
Design
Questa soluzione estende il framework vLLM, anziché reinventarlo. vLLM-TPU è un motore di erogazione LLM open source altamente ottimizzato, noto per il suo elevato throughput, ottenuto utilizzando funzionalità chiave come PagedAttention (che gestisce le cache KV come la memoria virtuale per ridurre al minimo la frammentazione) e Continuous Batching (che aggiunge dinamicamente le richieste al batch per migliorare l'utilizzo).
vLLM-TPU si basa su questa base e sviluppa i componenti principali per la gestione delle richieste, la pianificazione e la gestione della memoria. Introduce un backend basato su JAX che funge da ponte, traducendo il grafico computazionale e le operazioni di memoria di vLLM in codice eseguibile dalla TPU. Questo backend gestisce le interazioni con i dispositivi, l'esecuzione del modello JAX e le specifiche della gestione della cache KV sull'hardware TPU. Incorpora ottimizzazioni specifiche per le TPU, come meccanismi di attenzione efficienti (ad esempio, sfruttando i kernel JAX Pallas per l'attenzione a pagine irregolari) e la quantizzazione, il tutto personalizzato per l'architettura TPU.
Punti di forza principali
- Costo di onboarding/offboarding pari a zero per gli utenti:gli utenti possono adottare questa soluzione senza particolari difficoltà. Dal punto di vista dell'esperienza utente, l'elaborazione delle richieste di inferenza sulle TPU dovrebbe essere la stessa delle GPU. La CLI per avviare il server, accettare i prompt e restituire gli output sono tutti condivisi.
- Sfrutta appieno l'ecosistema:questo approccio utilizza e contribuisce all'interfaccia e all'esperienza utente del vLLM, garantendo compatibilità e facilità d'uso.
- Fungibilità tra TPU e GPU: la soluzione funziona in modo efficiente sia su TPU che su GPU, offrendoti flessibilità.
- Conveniente (miglior rapporto prestazioni/costo): ottimizza le prestazioni per fornire il miglior rapporto prestazioni/costo per i modelli più diffusi.
JAX serving: serializzazione Orbax e motore di pubblicazione Neptune
Per modelli diversi dai LLM o per gli utenti che desiderano una pipeline completamente nativa di JAX, la libreria di serializzazione Orbax e il sistema del motore di pubblicazione Neptune (NSE) forniscono una soluzione di pubblicazione end-to-end ad alte prestazioni.
Motivazione
Storicamente, i modelli JAX spesso si basavano su un percorso tortuoso verso la produzione, ad esempio venivano inclusi in grafici TensorFlow ed eseguiti il deployment utilizzando TensorFlow Serving. Questo approccio ha introdotto limitazioni e inefficienze significative, costringendo gli sviluppatori a interagire con un ecosistema separato e rallentando l'iterazione. Un sistema di pubblicazione nativo di JAX dedicato è fondamentale per la sostenibilità, la riduzione della complessità e le prestazioni ottimizzate.
Design
Questa soluzione è costituita da due componenti principali, come illustrato nel seguente diagramma.
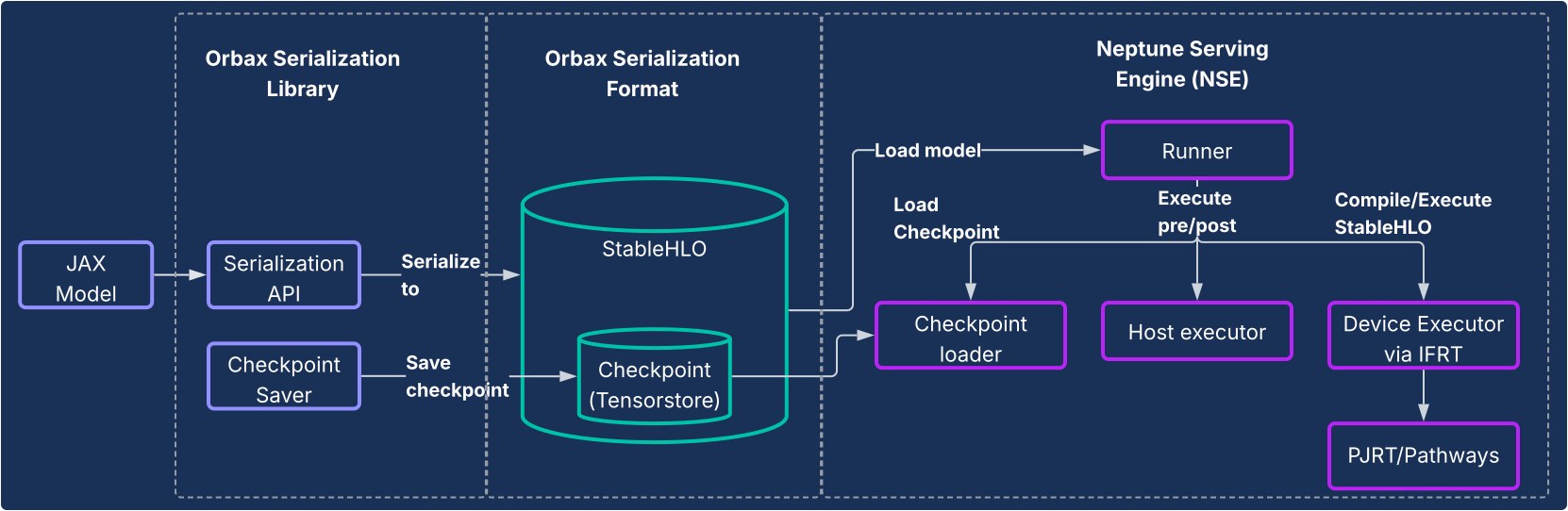
- Libreria di serializzazione Orbax:fornisce API facili da usare per serializzare i modelli JAX in un nuovo formato di serializzazione Orbax robusto. Questo formato è ottimizzato per l'implementazione in produzione. Rappresenta direttamente i calcoli del modello JAX utilizzando StableHLO, consentendo la rappresentazione nativa del grafico di calcolo. Sfrutta anche TensorStore per l'archiviazione dei pesi, consentendo un caricamento rapido dei checkpoint per la pubblicazione.
- Neptune Serving Engine (NSE): questo è il motore di gestione flessibile e ad alte prestazioni (in genere implementato come binario C++) progettato per eseguire in modo nativo i modelli JAX nel formato Orbax. NSE offre funzionalità essenziali per la produzione, come il caricamento rapido dei modelli, il servizio simultaneo ad alta velocità effettiva con batching integrato, il supporto di più versioni del modello e il servizio su uno o più host (utilizzando PJRT e Pathways). Utilizza il motore di pubblicazione
Neptune per:
- Modelli non LLM: è una soluzione per uso generico ideale per carichi di lavoro come sistemi di raccomandazione, modelli di diffusione e altri modelli di AI.
- LLM di piccole dimensioni e servizio "one-shot": è progettato per modelli non autoregressivi o modelli più piccoli che vengono pubblicati in modo "unary", in cui l'intero output viene generato in un unico passaggio senza la necessità di una gestione complessa dello stato, come una cache KV.
In breve, Neptune Serving Engine colma il divario per la pubblicazione dell'ampia gamma di modelli che non sono modelli linguistici autoregressivi di grandi dimensioni, fornendo una soluzione nativa per TPU ad alte prestazioni per l'ecosistema ML più ampio.
Punti di forza principali
- JAX Native Serving:la soluzione è creata in modo nativo per JAX, eliminando l'overhead tra framework nella serializzazione e nella pubblicazione dei modelli. Ciò garantisce un caricamento rapido dei modelli e un'esecuzione ottimizzata su CPU, GPU e TPU.
- Deployment di produzione semplice: i modelli serializzati forniscono un percorso di deployment ermetico che non è influenzato dalla deriva delle dipendenze di Python e consente controlli di integrità del modello in fase di runtime. Ciò fornisce un percorso semplice e intuitivo per la messa in produzione del modello JAX.
- Esperienza dello sviluppatore migliorata: eliminando la necessità di un wrapping del framework macchinoso, questa soluzione riduce significativamente le dipendenze e la complessità del sistema, accelerando l'iterazione per gli sviluppatori JAX.
Analisi e profilazione a livello di sistema
XProf: profilazione delle prestazioni integrata nell'hardware
XProf è uno strumento di profilazione e analisi delle prestazioni che fornisce una visibilità approfondita su vari aspetti dell'esecuzione del carico di lavoro ML, consentendoti di eseguire il debug e ottimizzare le prestazioni. È profondamente integrato negli ecosistemi JAX e TPU.
Motivazione
Da un lato, i carichi di lavoro ML stanno diventando sempre più complicati. D'altra parte, si verifica un'esplosione di funzionalità hardware specializzate che hanno come target questi carichi di lavoro. Abbinare in modo efficace i due elementi per garantire prestazioni ed efficienza ottimali è fondamentale, dati gli enormi costi dell'infrastruttura ML. Ciò richiede una visibilità approfondita sia del carico di lavoro che dell'hardware, presentata in modo rapido da consumare. XProf eccelle in questo.
Design
XProf è costituito da due componenti principali: raccolta e analisi.
- Raccolta:XProf acquisisce informazioni da varie fonti: annotazioni nel codice JAX, modelli di costi per le operazioni all'interno del compilatore XLA e funzionalità di profilazione hardware create appositamente all'interno della TPU. Questa raccolta può essere attivata in modo programmatico o on demand, generando un artefatto di eventi completo.
- Analisi:XProf post-elabora i dati raccolti e crea una suite di visualizzazioni efficaci, accessibili con un browser.
Punti di forza principali
La vera potenza di XProf deriva dalla sua profonda integrazione con l'intero stack, che offre un'ampiezza e una profondità di analisi che rappresentano un vantaggio tangibile dell'ecosistema JAX/TPU progettato congiuntamente.
- Progettato in collaborazione con la TPU: XProf sfrutta funzionalità hardware progettate appositamente per una raccolta dei profili senza interruzioni, consentendo un overhead di raccolta inferiore all'1%. In questo modo, la profilazione diventa una parte leggera e iterativa dello sviluppo.
- Ampiezza e profondità dell'analisi: XProf produce un'analisi approfondita su più assi. I suoi strumenti includono:
- Trace Viewer:una visualizzazione della sequenza temporale delle operazioni di esecuzione su diverse unità hardware (ad esempio, TensorCore).
- Profilo dell'operazione HLO: suddivide il tempo totale trascorso in diverse categorie di operazioni.
- Visualizzatore memoria:mostra in dettaglio le allocazioni di memoria per le diverse operazioni durante la finestra profilata.
- Analisi del profilo di prestazioni: ti aiuta a identificare se operazioni specifiche sono vincolate alla capacità di calcolo o alla memoria e quanto sono lontane dalle capacità di picco dell'hardware.
- Visualizzatore grafici:fornisce una visualizzazione del grafico HLO completo eseguito dall'hardware.
Una prospettiva comparativa: lo stack JAX/TPU come scelta convincente
Il panorama moderno del machine learning offre molte toolchain eccellenti e mature. Lo stack AI JAX offre una serie di vantaggi unici e convincenti per gli sviluppatori incentrati su ML ad alte prestazioni e su larga scala, derivanti direttamente dalla sua progettazione modulare e dalla profonda progettazione congiunta dell'hardware.
Sebbene molti framework offrano un'ampia gamma di funzionalità, lo stack AI JAX fornisce differenziatori specifici e potenti in aree chiave del ciclo di vita dello sviluppo:
- Un'esperienza per sviluppatori più semplice e potente: il paradigma di trasformazione del gradiente concatenabile di Optax consente strategie di ottimizzazione più potenti e flessibili che vengono dichiarate una sola volta, anziché gestite in modo imperativo nel ciclo di addestramento. A livello di sistema, l'interfaccia di controllo singola e più semplice di Pathways astrae la complessità dell'addestramento multislice, una semplificazione significativa per i ricercatori.
- Progettato per la resilienza su larga scala: lo stack JAX è progettato per l'addestramento su larga scala. Orbax offre funzionalità di "resilienza dell'addestramento su larga scala" come il checkpointing di emergenza e multilivello. Questo è completato da Grain, che offre il pieno supporto per la riproducibilità con rimescolamenti globali deterministici e caricatori di dati controllabili. La possibilità di eseguire il checkpoint in modo atomico dello stato della pipeline di dati (Grain) con lo stato del modello (Orbax) è una funzionalità fondamentale per garantire la riproducibilità nei job a lunga esecuzione.
- Un ecosistema completo end-to-end: lo stack fornisce una soluzione end-to-end coesa. Gli sviluppatori possono utilizzare MaxText come riferimento SOTA per l'addestramento, Tunix per l'allineamento e seguire un percorso di produzione chiaro e doppio con vLLM-TPU (per la compatibilità con vLLM) e NSE (per le prestazioni JAX).
Sebbene molti stack siano simili dal punto di vista del software di alto livello, il fattore decisivo spesso è Performance/TCO, dove la progettazione congiunta di JAX e TPU offre un vantaggio distinto. Questo vantaggio in termini di prestazioni/TCO è il risultato diretto dell'integrazione verticale tra software e hardware TPU. La capacità del compilatore XLA di unire le operazioni in modo specifico per l'architettura TPU o per il profiler XProf di utilizzare hook hardware per la profilazione con un overhead inferiore all'1% sono vantaggi tangibili di questa integrazione profonda.
Per le organizzazioni che adottano questo stack, la natura completa dello stack JAX AI riduce al minimo il costo della migrazione. Per i clienti che utilizzano architetture di modelli open source popolari, il passaggio da altri framework a MaxText spesso consiste nella configurazione dei file di configurazione. Inoltre, la capacità dello stack di importare formati di checkpoint popolari come safetensors consente di eseguire la migrazione dei checkpoint esistenti senza dover eseguire un costoso riaddestramento.
La tabella seguente fornisce un mapping dei componenti forniti dallo stack JAX AI e dei relativi equivalenti in altri framework o librerie.
| Funzione | JAX | Alternative/equivalenti in altri framework5 |
| Compilatore / runtime | XLA | Induttore, impaziente |
| Addestramento MultiPod | Pathways | Strategie di illuminazione della torcia, Ray Train, Monarch (novità). |
| Framework principale | JAX | PyTorch |
| Creazione di modelli | Modelli Flax, Max* | torch.nn.*,
NVidia TransformerEngine, HuggingFace Transformers
|
| Ottimizzatori e perdite | Optax | torch.optim.*, torch.nn.*Loss |
| Caricatori di dati | Grana | Ray Data, HuggingFace dataloaders |
| Checkpoint | Orbax | Checkpointing distribuito di PyTorch, Checkpointing di NeMo |
| Quantizzazione | Qwix | TorchAO, bitsandbytes |
| Creazione di kernel e implementazioni note | Pallas / Tokamax | Triton/Helion, Liger-kernel, TransformerEngine |
| Post-addestramento / ottimizzazione | Tunix | VERL, NeMoRL |
| Profilazione | XProf | Profiler PyTorch, NSight Systems, NSight Compute |
| Addestramento del modello di base | MaxText, MaxDiffusion | NeMo-Megatron, DeepSpeed, TorchTitan |
| Inferenza LLM | vLLM | SGLang |
| Inferenza non LLM | NSE | Triton Inference Server, RayServe |
5Alcuni degli equivalenti qui non sono sempre confronti veritieri perché altri framework tracciano i limiti delle API in modo diverso rispetto a JAX. L'elenco degli equivalenti non è esaustivo e vengono aggiunte nuove librerie di frequente.
Conclusione: una piattaforma durevole e pronta per la produzione per il futuro dell'AI
I dati forniti nella tabella precedente illustrano una conclusione evidente: questi stack hanno punti di forza e di debolezza in un numero ridotto di aree, ma nel complesso sono molto simili dal punto di vista del software. Entrambi gli stack forniscono soluzioni chiavi in mano per il pre-addestramento, l'adattamento post-addestramento e il deployment di modelli di base.
Lo stack JAX AI offre una soluzione convincente e solida per l'addestramento e il deployment di modelli ML su qualsiasi scala. Sfrutta l'integrazione verticale profonda tra software e hardware TPU per offrire prestazioni leader di classe e costi totali di proprietà.
Basandosi su sistemi interni collaudati, lo stack si è evoluto per fornire affidabilità e scalabilità intrinseche, consentendo agli utenti di sviluppare e implementare con sicurezza anche i modelli più grandi. Il suo design modulare e componibile, basato sulla filosofia dello stack AI JAX, offre agli utenti libertà e controllo senza precedenti, consentendo loro di personalizzare lo stack in base alle loro esigenze specifiche senza i vincoli di un framework monolitico.
Con XLA e Pathways che forniscono una base scalabile e tollerante agli errori, JAX che offre una libreria numerica performante ed espressiva, potenti librerie di sviluppo di base come Flax, Optax, Grain e Orbax, strumenti avanzati per le prestazioni come Pallas, Tokamax e Qwix e un livello di produzione e applicazione solido in MaxText, vLLM e NSE, lo stack JAX AI fornisce una base duratura su cui gli utenti possono basarsi e portare rapidamente la ricerca all'avanguardia in produzione.