
פיתוח AI לשימוש בסביבת ייצור ב-Cloud TPU באמצעות JAX
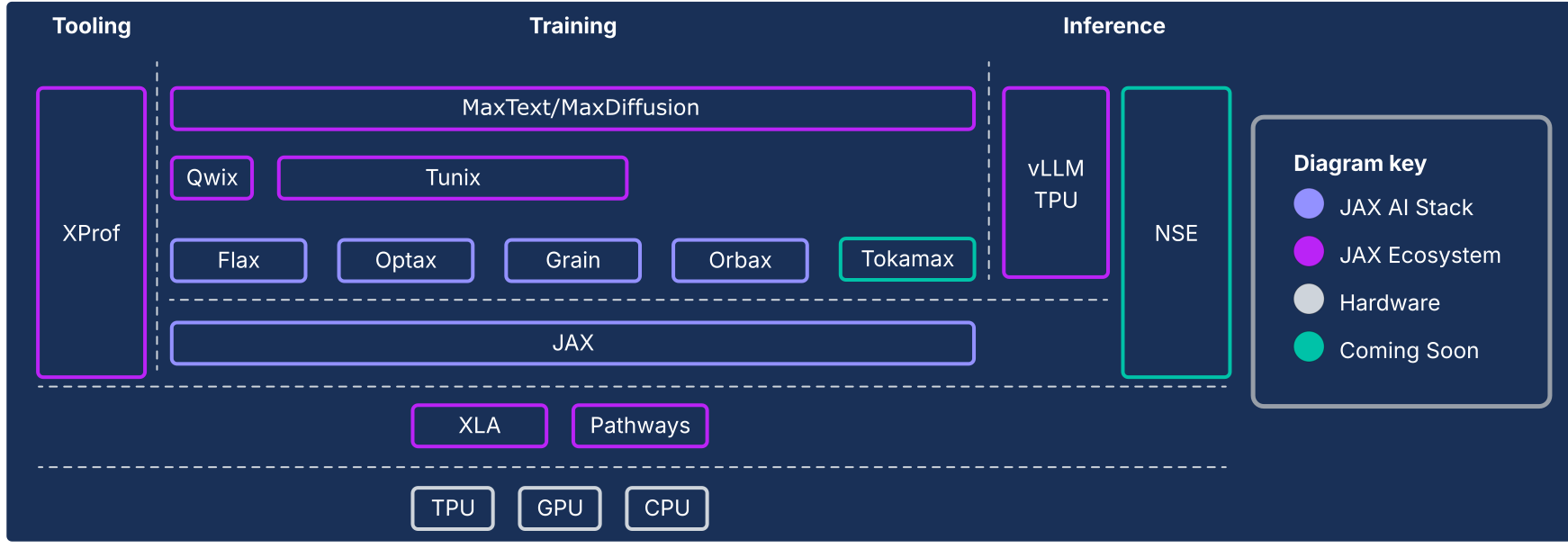
חבילת ה-AI של JAX מרחיבה את ליבת המספרים של JAX עם אוסף של ספריות מודולריות שנתמכות על ידי Google, והופכת אותה לפלטפורמה חזקה מקצה לקצה בקוד פתוח ללמידת מכונה בהיקפים גדולים במיוחד. לכן, חבילת ה-AI של JAX כוללת מערכת אקולוגית מקיפה וחזקה שמטפלת בכל מחזור החיים של למידת מכונה:
בסיס בקנה מידה תעשייתי: ארכיטקטורת מחסנית ה-AI של JAX מיועדת לקנה מידה עצום, תוך מינוף ML Pathways לתיאום אימון בעשרות אלפי שבבים ו-Orbax ליצירת נקודות ביקורת אסינכרוניות עמידות עם תפוקה גבוהה, שמאפשרות אימון ברמת ייצור של מודלים מתקדמים.
ערכת כלים מלאה ומוכנה לייצור: סטאק ה-AI של JAX מספק קבוצה מקיפה של ספריות לכל תהליך הפיתוח: Flax ליצירת מודלים גמישים, Optax לאסטרטגיות אופטימיזציה שניתנות להרכבה ו-Grain לצינורות נתונים דטרמיניסטיים שחיוניים להפעלות בקנה מידה גדול שניתנות לשחזור.
ביצועים מיטביים ומיוחדים: כדי להשיג ניצול מקסימלי של החומרה, מחסנית ה-AI של JAX מציעה ספריות מיוחדות, כולל Tokamax לליבות מותאמות אישית מתקדמות, Qwix לכמויות לא פולשניות שמשפרות את מהירות האימון וההסקה, ו-XProf ליצירת פרופילים מפורטים של ביצועים שמשולבים בחומרה.
נתיב מלא לסביבת הייצור: מחסנית ה-AI של JAX מאפשרת מעבר חלק ממחקר לפריסה. הם כוללים את MaxText כהפניה ניתנת להרחבה לאימון מודלי בסיס, את Tunix ללמידת חיזוק (RL) ויישור מתקדמים, ופתרון היקש מאוחד עם שילוב של vLLM TPU וזמן הריצה של JAX.
הפילוסופיה של חבילת ה-AI של JAX היא של רכיבים בצימוד חלש, שכל אחד מהם עושה דבר אחד בצורה טובה. במקום להיות מסגרת ML מונוליטית, JAX עצמה היא בעלת היקף מצומצם ומתמקדת בפעולות יעילות של מערכים ובהמרות של תוכניות. המערכת האקולוגית מבוססת על המסגרת המרכזית הזו כדי לספק מגוון רחב של פונקציות שקשורות להדרכה של מודלים של למידת מכונה (ML) ולסוגים אחרים של עומסי עבודה, כמו מחשוב מדעי.
המערכת הזו של רכיבים בצימוד חלש מאפשרת לכם לבחור ולשלב ספריות בצורה הכי טובה כדי להתאים לדרישות שלכם. מבחינת הנדסת תוכנה, הארכיטקטורה הזו מאפשרת גם לעדכן פונקציונליות שנחשבת באופן מסורתי לרכיבי מסגרת ליבה (לדוגמה, צינורות נתונים ונקודות ביקורת) באופן איטרטיבי, בלי להסתכן בערעור היציבות של מסגרת הליבה או להיתקע במחזורי הפצה. מכיוון שרוב הפונקציונליות מיושמת בספריות ולא בשינויים במסגרת מונוליטית, ספריית הליבה של המספרים עמידה יותר וניתנת להתאמה לשינויים עתידיים בסביבה הטכנולוגית.
בקטעים הבאים מופיעה סקירה טכנית של חבילת JAX AI, התכונות העיקריות שלה, ההחלטות העיצוביות שמאחוריהן והאופן שבו הן משולבות כדי ליצור פלטפורמה עמידה לעומסי עבודה מודרניים של ML.
ה-JAX AI stack ורכיבים אחרים במערכת האקולוגית
| רכיב | פונקציה / תיאור |
|---|---|
| הליבה והרכיבים של JAX AI stack1 | |
| JAX | חישוב מערכים והמרת תוכניות שמתבצעים באמצעות מאיץ (JIT, grad, vmap, pmap). |
| Flax | ספרייה גמישה ליצירת רשתות נוירונים, ליצירה ולשינוי אינטואיטיביים של מודלים. |
| Optax | ספרייה של טרנספורמציות להרכבה לעיבוד ולאופטימיזציה של גרדיאנטים. |
| Orbax | ספרייה מבוזרת של נקודות ביקורת (checkpointing) בכל קנה מידה, לאימון עמיד בקנה מידה גדול. |
| Grain | ספרייה של פייפליינים של נתוני קלט שניתנים להרחבה, דטרמיניסטיים וניתנים להגדרה של נקודות עצירה. |
| JAX AI stack - Infrastructure | |
| XLA | קומפיילר ללמידת מכונה בקוד פתוח ל-TPU, ל-CPU ול-GPU. |
| Pathways | זמן ריצה מבוזר לתיאום חישובים בעשרות אלפי שבבים. |
| JAX AI stack - Adv. פיתוח | |
| Pallas | תוסף JAX לכתיבת ליבות מותאמות אישית ברמה נמוכה עם ביצועים ברמה גבוהה, שמיושמות ב-Python. |
| Tokamax | ספרייה שנבחרה בקפידה של ליבות מותאמות אישית מתקדמות עם ביצועים גבוהים (לדוגמה, Attention). |
| Qwix | ספרייה מקיפה ולא פולשנית לכמויות (PTQ, QAT, QLoRA). |
| JAX AI stack - Application | |
| MaxText / MaxDiffusion | Frameworks לדוגמה, ניתנים להרחבה, לאימון מודלים בסיסיים (לדוגמה, LLM ו-Diffusion). |
| Tunix | מסגרת לשיטות מתקדמות לאימון ולאישור (RLHF, DPO). |
| vLLM | פתרון להסקת מסקנות מ-LLM עם ביצועים גבוהים, שמשתמש בשילוב מובנה של מסגרת vLLM. |
| XProf | כלי ליצירת פרופיל מעמיק שמשולב בחומרה לצורך ניתוח ביצועים ברמת המערכת. |
1 כלול בחבילת Python jax-ai-stack.
איור 1: מחסנית ה-AI של JAX ורכיבי המערכת האקולוגית
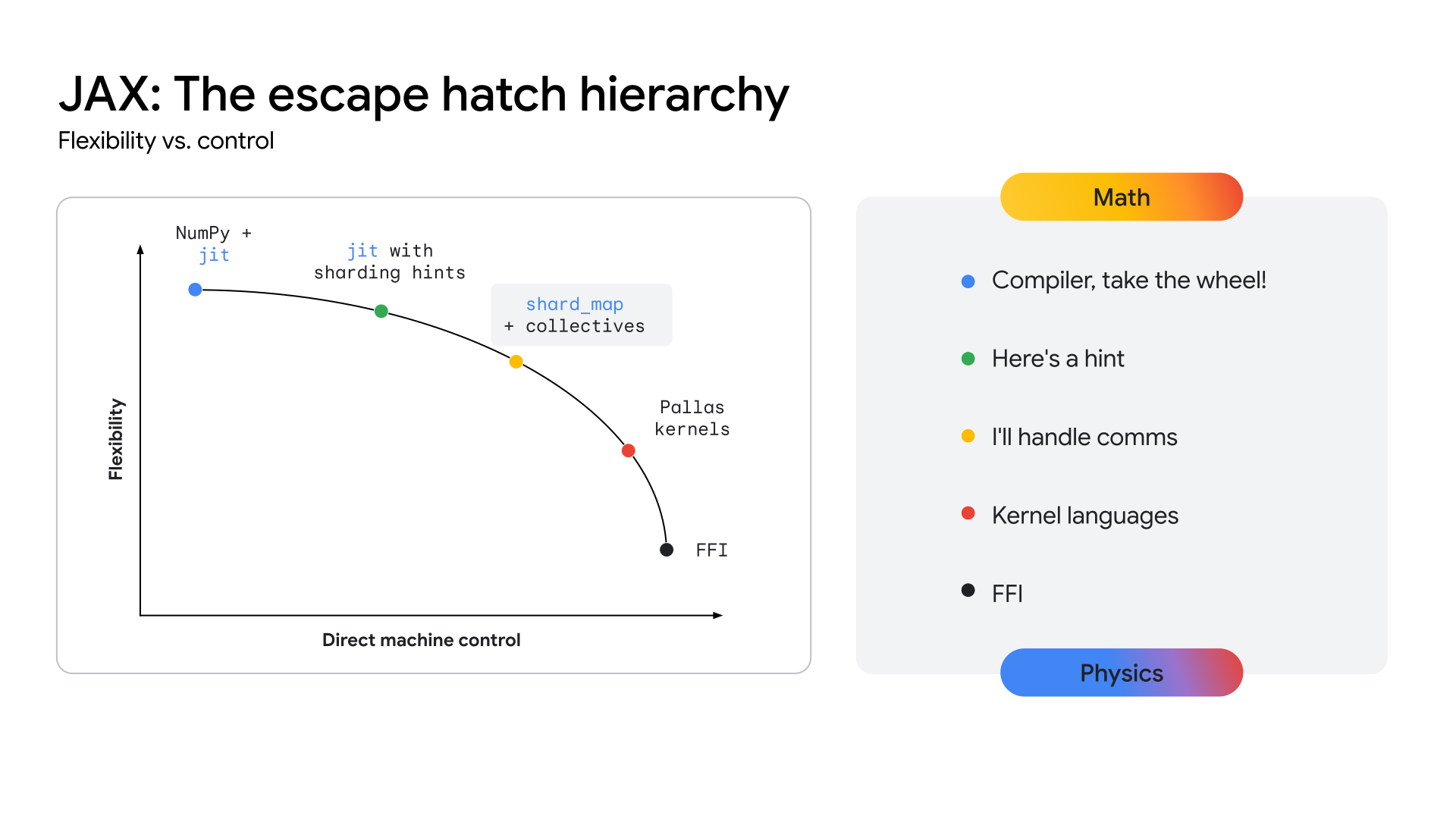
הדרישה הארכיטקטונית: ביצועים מעבר למסגרות
ככל שהארכיטקטורות של המודלים מתכנסות – למשל, ב-Transformers של MoE (תערובת של מומחים) מולטי-מודאליים – השאיפה לביצועים אופטימליים מובילה להופעה של Megakernels. מגה-קרנל הוא למעשה כל ההעברה קדימה (או חלק גדול ממנה) של מודל ספציפי אחד, שקודד ידנית באמצעות API ברמה נמוכה יותר, כמו CUDA SDK במעבדי GPU של NVIDIA. הגישה הזו מאפשרת ניצול מקסימלי של החומרה על ידי חפיפה אגרסיבית של חישובים, זיכרון ותקשורת. מחקרים שנעשו לאחרונה בקהילת המחקר הראו שהגישה הזו יכולה להניב שיפורים משמעותיים בנפח הנתונים, מעל 22% במקרים מסוימים, עבור הסקה ב-GPU. המגמה הזו לא מוגבלת להסקת מסקנות. יש ראיות לכך שחלק מהמאמצים של אימון בקנה מידה גדול כללו שליטה בחומרה ברמה נמוכה כדי להשיג שיפורים משמעותיים ביעילות.
אם המגמה הזו תימשך, כל המסגרות ברמה גבוהה כפי שהן קיימות היום עלולות להפוך לפחות רלוונטיות, כי גישה ברמה נמוכה לחומרה היא מה שחשוב בסופו של דבר לביצועים בארכיטקטורות יציבות ובשלות. זו בעיה בכל מחסניות ה-ML המודרניות: איך לספק שליטה בחומרה ברמת מומחה בלי לפגוע בפרודוקטיביות ובגמישות של מסגרת ברמה גבוהה.
כדי ש-TPU יספקו נתיב ברור לרמת הביצועים הזו, המערכת האקולוגית צריכה לחשוף שכבת API שקרובה יותר לחומרה, כדי לאפשר פיתוח של ליבות מיוחדות מאוד כאלה. מערך הכלים JAX נועד לפתור את הבעיה הזו באמצעות רצף של הפשטות (ראו איור 2), החל מהאופטימיזציות האוטומטיות ברמה גבוהה של מהדר XLA ועד לשליטה ידנית בגרעין של ספריית Pallas.
איור 2: רצף ההפשטה של JAX
הליבה של JAX AI Stack
הליבה של חבילת JAX AI Stack מורכבת מחמש ספריות מרכזיות שמהוות את הבסיס לפיתוח מודלים:
JAX: בסיס לטרנספורמציה של תוכניות עם ביצועים גבוהים
JAX היא ספריית Python לחישוב מערכים ולשינוי תוכניות שמתמקדת במאיצים, ומיועדת לחישובים מספריים עתירי ביצועים וללמידת מכונה בהיקפים גדולים. עם מודל התכנות הפונקציונלי וממשק ה-API שדומה ל-NumPy, JAX מספקת בסיס מוצק לספריות ברמה גבוהה יותר.
העיצוב של JAX מבוסס על קומפילציה, ולכן הוא תומך בסקלביליות באמצעות XLA (ראו את הקטע בנושא XLA) לניתוח, לאופטימיזציה ולטירגוט חומרה אגרסיביים של תוכניות שלמות. הדגש של JAX על תכנות פונקציונלי (לדוגמה, פונקציות טהורות) מאפשר לבצע את השינויים העיקריים בתוכנה בצורה נוחה יותר, וחשוב מכך, בצורה מודולרית.
אפשר לשלב בין השינויים המרכזיים האלה כדי להשיג ביצועים גבוהים ולהתאים את עומסי העבודה לגודל המודל, לגודל האשכול ולסוגי החומרה:
- jit: קומפילציה בזמן ריצה של פונקציות Python לקובצי הפעלה אופטימליים של XLA.
- grad: דיפרנציאציה אוטומטית, תמיכה במצב קדימה ובמצב הפוך, וגם נגזרות מסדר גבוה יותר.
- vmap: וקטוריזציה אוטומטית, שמאפשרת חלוקה לקבוצות ועיבוד מקבילי של נתונים בצורה חלקה בלי לשנות את הלוגיקה של הפונקציה.
- pmap / shard_map: מקביליות אוטומטית בכמה מכשירים (לדוגמה, ליבות TPU), שמהווה את הבסיס לאימון מבוזר.
השילוב החלק עם מודל GSPMD (General-purpose SPMD) של XLA מאפשר ל-JAX לבצע אוטומטית חישובים מקבילים ב-TPU Pods גדולים עם שינויים מינימליים בקוד. ברוב המקרים, כדי להגדיל או להקטין את PAT צריך רק להוסיף הערות גבוהות ברמת ה-sharding.
Flax: כתיבה גמישה של רשתות נוירונים
Flax מפשטת את היצירה, הניפוי והניתוח של רשתות נוירונים ב-JAX, באמצעות גישה אינטואיטיבית מבוססת-אובייקטים לבניית מודלים. ממשק ה-API הפונקציונלי של JAX הוא עוצמתי, אבל הוא מציע הפשטה מוכרת יותר שמבוססת על שכבות למפתחים שמורגלים למסגרות כמו PyTorch, בלי לפגוע בביצועים.
העיצוב הזה מאפשר לשנות או לשלב בקלות רכיבים של מודל שאומן.
טכניקות כמו LoRA וקוונטיזציה דורשות הגדרות מודל שניתן לתפעל, ו-API NNX של Flax מספק אותן באמצעות ממשק Pythonic. NNX מכיל את מצב המודל, מפחית את העומס הקוגניטיבי על המשתמשים ומאפשר מעבר פרוגרמטי בין רמות בהיררכיית המודל ושינוי שלהן.
נקודות חוזק עיקריות:
- ממשק API אינטואיטיבי מבוסס-אובייקטים: מפשט את בניית המודלים ומאפשר תרחישי שימוש מתקדמים כמו החלפת מודול משנה ואתחול חלקי.
- תואם ל-Core JAX: Flax מספק טרנספורמציות מורמות שתואמות באופן מלא לפרדיגמה הפונקציונלית של JAX, ומציע את הביצועים המלאים של JAX עם שיפורים שנועדו להקל על המפתחים.
Optax: אסטרטגיות אופטימיזציה ועיבוד של גרדיאנטים שאפשר להרכיב
Optax היא ספרייה לעיבוד ולאופטימיזציה של גרדיאנטים ב-JAX. הספרייה נועדה לספק ליוצרי מודלים אבני בניין שאפשר לשלב מחדש בדרכים מותאמות אישית כדי לאמן מודלים של למידה עמוקה, בין היתר. היא מבוססת על היכולות של ספריית הליבה JAX כדי לספק ספרייה של פונקציות הפסד ואופטימיזציה, וטכניקות קשורות שנבדקו היטב ובעלות ביצועים גבוהים, שאפשר להשתמש בהן כדי לאמן מודלים של למידת מכונה.
למה בחרנו לעשות זאת?
החישוב והמזעור של ההפסדים הם הליבה של מה שמאפשר את האימון של מודלים של למידת מכונה. ספריית הליבה של JAX תומכת בבידול אוטומטי ומספקת את היכולות המספריות לאימון מודלים, אבל היא לא מספקת הטמעות סטנדרטיות של אופטימיזציה פופולרית (לדוגמה, RMSProp או Adam) או הפסדים (לדוגמה, CrossEntropy או MSE). אפשר להטמיע את הפונקציות האלה (ומפתחים מתקדמים בוחרים לעשות זאת), אבל באג בהטמעה של אופטימיזציה יוביל לבעיות באיכות המודל שקשה לאבחן. במקום שהמשתמש יטמיע רכיבים קריטיים כאלה, Optax מספקת הטמעות של האלגוריתמים האלה שנבדקו מבחינת דיוק וביצועים.
תחום תורת האופטימיזציה נמצא בתחום המחקר, אבל התפקיד המרכזי שלו באימון הופך אותו לחלק חיוני באימון מודלים של למידת מכונה. ספרייה שממלאת את התפקיד הזה צריכה להיות גמישה מספיק כדי להתאים לאיטרציות מהירות של מחקר, וגם חזקה ויעילה מספיק כדי שאפשר יהיה להסתמך עליה לאימון מודלים לייצור. הספרייה צריכה גם לספק יישומים שנבדקו היטב של אלגוריתמים מתקדמים שתואמים למשוואות הסטנדרטיות. הספרייה Optax, באמצעות הארכיטקטורה המודולרית שלה שניתנת להרכבה והדגש על קוד נכון וקריא, נועדה להשיג את המטרה הזו.
עיצוב
Optax נועד לשפר את מהירות המחקר ואת המעבר ממחקר לייצור, על ידי מתן יישומים קריאים, שנבדקו היטב ויעילים של אלגוריתמים מרכזיים. ל-Optax יש שימושים מעבר להקשר של למידה עמוקה, אבל בהקשר הזה אפשר לראות בה אוסף של פונקציות הפסד ידועות, אלגוריתמים לאופטימיזציה וטרנספורמציות של גרדיאנטים שמיושמים בצורה פונקציונלית טהורה בהתאם לפילוסופיה של JAX. אוסף של פונקציות הפסד ואופטימיזציות מוכרות מאפשר למשתמשים להתחיל לעבוד בקלות ובביטחון.
הגישה המודולרית של Optax מאפשרת לשרשר כמה אופטימיזציות יחד, ואחריהן טרנספורמציות נפוצות אחרות (לדוגמה, חיתוך שיפועים) ולעטוף אותן באמצעות טכניקות נפוצות כמו MultiStep או Lookahead, כדי להשיג אסטרטגיות אופטימיזציה יעילות בכמה שורות קוד. הממשק הגמיש מאפשר לכם לחקור אלגוריתמים חדשים לאופטימיזציה, ולהשתמש בטכניקות אופטימיזציה מתקדמות כמו שמפו או מיואון.
# Optax implementation of a RMSProp optimizer with a custom learning rate
# schedule, gradient clipping and gradient accumulation.
optimizer = optax.chain(
optax.clip_by_global_norm(GRADIENT_CLIP_VALUE),
optax.rmsprop(learning_rate=optax.cosine_decay_schedule(init_value=lr,decay_steps=decay)),
optax.apply_every(k=ACCUMULATION_STEPS)
)
# The same thing, in PyTorch
optimizer = optim.RMSprop(model_params, lr=LEARNING_RATE)
scheduler = optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=TOTAL_STEPS)
for i, (inputs, targets) in enumerate(data_loader):
# ... Training loop body ...
if (i + 1) % ACCUMULATION_STEPS == 0:
torch.nn.utils.clip_grad_norm_(model.parameters(), GRADIENT_CLIP_VALUE)
optimizer.step()
scheduler.step()
optimizer.zero_grad()
בקטע הקוד הקודם מוצג איך מגדירים אופטימיזציה עם קצב למידה מותאם אישית, חיתוך שיפוע וצבירת שיפוע.
חוזקות עיקריות
- ספרייה חזקה: ספרייה מקיפה של פונקציות הפסד, אופטימיזטורים ואלגוריתמים, עם דגש על נכונות וקריאות.
- שינויים מודולריים שניתנים לשרשור: ה-API הגמיש הזה מאפשר לכם ליצור אסטרטגיות אופטימיזציה מורכבות וחזקות באופן הצהרתי, בלי לשנות את לולאת האימון.
- פונקציונליות ומדרגיות: ההטמעות הפונקציונליות הטהורות משתלבות בצורה חלקה עם מנגנוני הטעינה במקביל של JAX (לדוגמה, pmap), ומאפשרות להשתמש באותו קוד כדי להרחיב את הפתרון ממארח יחיד לאשכולות גדולים.
Orbax / TensorStore – שמירת נקודות ביקורת מבוזרות בקנה מידה גדול
Orbax היא ספרייה ליצירת נקודות ביקורת (checkpointing) עבור JAX, שנועדה לכל קנה מידה, החל ממכשיר יחיד ועד לאימון מבוזר בקנה מידה גדול. המטרה היא לאחד יישומי checkpointing מפוצלים ולספק לקהל רחב יותר תכונות ביצועים קריטיות, כמו checkpointing אסינכרוני ורב-שכבתי. Orbax מאפשר את הגמישות שנדרשת להרצת אימונים מסיביים, ומספק פורמט גמיש לפרסום נקודות ביקורת.
בניגוד למערכות כלליות של נקודות ביקורת ושחזור שמצלמות את מצב המערכת כולו, בנקודות ביקורת של ML עם Orbax נשמר באופן סלקטיבי רק המידע שחיוני להמשך ההדרכה של משקלי המודל, מצב האופטימיזציה ומצב טוען הנתונים. הגישה הממוקדת הזו מצמצמת את זמן ההשבתה של המאיץ. Orbax עושה את זה על ידי חפיפה בין פעולות קלט/פלט לחישובים, תכונה חשובה לעומסי עבודה גדולים. זמן ההמתנה של מאיצי הזמן מצטמצם למשך העברת הנתונים מהמכשיר למארח, ויכול להיות חפיפה עם שלב האימון הבא. כך, יצירת נקודות ביקורת כמעט לא משפיעה על הביצועים.
בבסיס, Orbax משתמש ב-TensorStore לקריאה וכתיבה יעילות ומקבילות של נתוני מערך. Orbax API מפשט את המורכבות הזו ומציע ממשק ידידותי למשתמש לטיפול ב-PyTrees, שהם הייצוג הסטנדרטי של מודלים ב-JAX.
נקודות חוזק עיקריות:
- אימוץ נרחב: עם מיליוני הורדות מדי חודש, Orbax משמש ככלי נפוץ לשיתוף של ארטיפקטים של למידת מכונה.
- מפשט מורכבויות: Orbax מסתיר את המורכבויות של שמירת נקודות ביקורת מבוזרות, כולל שמירה אסינכרונית, אטומיות ופרטים של מערכת הקבצים.
- גמיש: Orbax מציע ממשקי API לתרחישי שימוש נפוצים, אבל מאפשר לכם גם להתאים אישית את תהליך העבודה כדי לטפל בדרישות מיוחדות.
- ביצועים טובים וניתנות להרחבה: תכונות כמו יצירת נקודות ביקורת אסינכרוניות, פורמט אחסון יעיל (OCDBT) ואסטרטגיות חכמות לטעינת נתונים מבטיחות ש-Orbax יתאים לאימונים שכוללים עשרות אלפי צמתים.
Grain: צינורות עיבוד נתונים דטרמיניסטיים וניתנים להתאמה
Grain היא ספריית Python לקריאה ולעיבוד של נתונים לצורך אימון והערכה של מודלים של JAX. הוא גמיש, מהיר ודטרמיניסטי, ותומך בתכונות מתקדמות כמו checkpointing, שחיוניות לאימון מוצלח של עומסי עבודה גדולים. הוא תומך בפורמטים פופולריים של נתונים ובמערכות אחסון עורפיות, ומספק גם API גמיש להרחבת התמיכה בפורמטים ובמערכות עורפיות ספציפיים למשתמש שלא נתמכים באופן מובנה. Grain מיועדת בעיקר לעבודה עם JAX, אבל היא לא תלויה ב-framework, לא נדרשת JAX להפעלה ואפשר להשתמש בה גם עם framework אחרים.
למה בחרנו לעשות זאת?
צינורות נתונים הם חלק קריטי בתשתית האימון – הם צריכים להיות גמישים כדי שאפשר יהיה לבצע טרנספורמציות נפוצות ביעילות, וגם להיות יעילים מספיק כדי שהמאיצים יהיו עסוקים כל הזמן. הם גם צריכים לתמוך בפורמטים שונים של אחסון ובקצה העורפי. בגלל משכי הזמן הארוכים יותר של השלבים, אימון מודלים גדולים בקנה מידה גדול מחייב דרישות נוספות בפייפליין, מעבר לדרישות של עומסי עבודה רגילים של אימון. הדרישות האלה מתמקדות בעיקר בדטרמיניזם ובשחזור2. ספריית Grain מבוססת על ארכיטקטורה גמישה שנותנת מענה לצרכים האלה.
2בקטע 5.1 של מאמר PaLM, המחברים מציינים שהם הבחינו בעליות חדות מאוד בהפסד למרות שהם הפעילו חיתוך של הגרדיאנט. הפתרון היה להסיר את אצוות הנתונים הבעייתיות ולהפעיל מחדש את האימון מנקודת ביקורת לפני העלייה החדה באובדן. אפשר לעשות את זה רק אם ההגדרה של האימון היא דטרמיניסטית לחלוטין וניתנת לשחזור.
עיצוב
ברמה הגבוהה ביותר, יש שתי דרכים לבנות צינור להזנת נתונים: כאוסף נפרד של עובדי נתונים, או על ידי מיקום משותף של עובדי הנתונים במארחים שמפעילים את המאיצים. Grain בוחרת באפשרות השנייה מסיבות שונות.
האצת הביצועים משולבת עם מארחים חזקים שבדרך כלל לא פעילים במהלך שלבי האימון, ולכן היא בחירה טבעית להפעלת פייפליין של נתוני הקלט. יש יתרונות נוספים להטמעה הזו – היא מפשטת את התצוגה של חלוקת הנתונים על ידי מתן תצוגה עקבית של החלוקה על פני הקלט והחישוב. אפשר לטעון שאם מציבים את עובד הנתונים במארח המאיץ, יש סיכון לשימוש יתר במעבד של המארח. עם זאת, אפשר להעביר את העומס של טרנספורמציות עתירות חישוב לאשכול אחר באמצעות RPC3.
בצד ה-API, עם הטמעה טהורה של Python שתומכת במספר תהליכים וב-API גמיש, Grain מאפשרת לכם להטמיע טרנספורמציות נתונים מורכבות באופן שרירותי על ידי הרכבת שלבי צינורות על סמך פרדיגמות טרנספורמציה מובנות היטב.
כברירת מחדל, Grain תומך בפורמטים של נתונים עם גישה אקראית יעילה, כמו ArrayRecord ו-Bagz, וגם בפורמטים פופולריים אחרים של נתונים, כמו Parquet ו-TFDS. Grain כולל תמיכה בקריאה ממערכות קבצים מקומיות וגם בקריאה מ-Cloud Storage כברירת מחדל. בנוסף לתמיכה בפורמטים פופולריים של אחסון ובקצה העורפי, הפשטה נקייה של שכבת האחסון מאפשרת לכם להוסיף תמיכה במקורות הנתונים הקיימים שלכם או לעטוף אותם כדי שיהיו תואמים לספריית Grain.
3כך צריכים לפעול צינורות להעברת נתונים מולטי-מודאליים – לדוגמה, טוקנייזרים של תמונות ואודיו הם מודלים בעצמם שפועלים באשכולות משלהם במאיצים משלהם, וצינורות הקלט יבצעו קריאות RPC כדי להמיר דוגמאות של נתונים לזרמים של טוקנים.
חוזקות עיקריות
- הזנת נתונים דטרמיניסטית: מיקום משותף של עובד הנתונים עם המאיץ ושילובו עם ערבוב גלובלי יציב ואיטרטורים שאפשר ליצור להם נקודות ביקורת מאפשרים ליצור נקודת ביקורת למצב המודל ולמצב פייפליין הנתונים יחד בתמונת מצב עקבית באמצעות Orbax, וכך לשפר את הדטרמיניזם של תהליך האימון.
- ממשקי API גמישים שמאפשרים לבצע טרנספורמציות עוצמתיות של נתונים: ממשק API גמיש של טרנספורמציות ב-Python מאפשר לבצע טרנספורמציות נרחבות של נתונים בצינור לעיבוד נתוני הקלט.
- תמיכה ניתנת להרחבה במספר פורמטים ובקצה העורפי: ממשק API למקורות נתונים ניתן להרחבה ותומך בפורמטים ובקצה העורפי של אחסון פופולריים, ומאפשר להוסיף תמיכה בפורמטים ובקצה העורפי חדשים.
- ממשק ניפוי באגים מתקדם: כלי ויזואליזציה של פייפליינים ומצב ניפוי באגים מאפשרים לכם לבצע בדיקה עצמית, לנפות באגים ולשפר את הביצועים של הפייפליינים.
הסטאק המורחב של JAX AI
בנוסף לסט הכלים הבסיסי, יש מערכת אקולוגית עשירה של ספריות ייעודיות שמספקות את התשתית, את הכלים המתקדמים ואת הפתרונות בשכבת האפליקציה שנדרשים לפיתוח ML מקצה לקצה.
תשתית בסיסית: קומפיילרים וסביבות זמן ריצה
XLA: מנוע עצמאי לחומרה, שמתמקד בקומפיילר
למה בחרנו לעשות זאת?
XLA או Accelerated Linear Algebra הוא קומפיילר ספציפי לדומיין של Google, שמשולב היטב ב-JAX ותומך במכשירי חומרה של TPU, CPU ו-GPU. XLA תוכנן להיות כלי ליצירת קוד בלתי תלוי בחומרה שמטרגט TPUs, GPUs ו-CPUs.
העיצוב של מהדר XLA, שבו המהדר הוא במקום הראשון, הוא בחירה ארכיטקטונית בסיסית שיוצרת יתרון מתמשך בסביבת מחקר שמתפתחת במהירות. לעומת זאת, הגישה הנפוצה במערכות אקולוגיות אחרות מתמקדת בליבת המערכת ומסתמכת על ספריות שעברו אופטימיזציה ידנית כדי לשפר את הביצועים. השיטה הזו יעילה מאוד לארכיטקטורות של מודלים יציבים ומבוססים, אבל היא יוצרת צוואר בקבוק לחדשנות. כשמחקר חדש מציג ארכיטקטורות חדשות, המערכת האקולוגית צריכה לחכות עד שייכתבו ויעברו אופטימיזציה ליבות חדשות. עם זאת, העיצוב שלנו מתמקד בקומפיילר, ולכן הוא יכול לעיתים קרובות להכליל דפוסים חדשים, ולספק דרך לביצועים גבוהים למחקרים מתקדמים כבר מהיום הראשון.
עיצוב
ה-XLA פועל באמצעות הידור JIT של גרפי החישוב ש-JAX יוצר במהלך תהליך המעקב שלו (לדוגמה, כשפונקציה מעוטרת ב-@jax.jit).
הקומפילציה הזו מתבצעת באמצעות צינור (pipeline) רב-שלבי:
- JAX Computation Graph
- כלי אופטימיזציה ברמה גבוהה (HLO)
- כלי אופטימיזציה ברמה נמוכה (LLO)
- קוד חומרה
- מ-JAX Graph ל-HLO: תרשים החישוב של JAX מומר לייצוג HLO של XLA. ברמה הגבוהה הזו, מוחלים אופטימיזציות חזקות שלא תלויות בחומרה, כמו מיזוג אופרטורים וניהול יעיל של הזיכרון. דיאלקט StableHLO משמש בשלב הזה כממשק עמיד עם גרסאות.
- מ-HLO ל-LLO: אחרי אופטימיזציות ברמה גבוהה, מערכות קצה ספציפיות לחומרה משתלטות על התהליך, ומורידות את הייצוג של HLO ל-LLO שמתאים למכונה.
- מ-LLO לקוד חומרה: קוד ה-LLO עובר הידור לשפת מכונה יעילה במיוחד. ב-TPU, הקוד הזה נארז כחבילות של מילים ארוכות מאוד של הוראות (VLIW) שנשלחות ישירות לחומרה.
העיצוב של XLA מבוסס על מקביליות, כדי לאפשר הרחבה. הוא משתמש באלגוריתמים כדי להפיק את המרב מיחידות הכפל של המטריצות (MXU) שבשבב. בין שבבים, XLA משתמש ב-SPMD (Single Program Multiple Data), טכניקת מקביליות מבוססת-קומפיילר שמשתמשת בתוכנית אחת בכל המכשירים. המודל המתקדם הזה נחשף דרך ממשקי JAX API, ומאפשר לכם לנהל נתונים, מודלים או מקביליות של צינורות (pipeline) באמצעות הערות שונות ברמה גבוהה.
לדפוסי מקביליות מורכבים יותר, אפשר להשתמש גם ב-Multiple Program Multiple Data (MPMD). ספריות כמו PartIR:MPMD מאפשרות למשתמשי JAX לספק גם הערות MPMD.
חוזקות עיקריות
- קומפילציה: קומפילציה בזמן אמת של גרף החישוב מאפשרת אופטימיזציות של פריסת הזיכרון, הקצאת מאגרים וניהול הזיכרון. חלופות כמו מתודולוגיות שמבוססות על ליבת המערכת מטילות את הנטל הזה על המפתח. ברוב המקרים, XLA יכול להשיג ביצועים מצוינים בלי לפגוע במהירות הפיתוח.
- מקביליות: XLA מטמיע כמה סוגים של מקביליות עם SPMD, והמקביליות הזו נחשפת ברמת JAX. כך אפשר להגדיר אסטרטגיות של חלוקה לשברים, ולבצע ניסויים והתאמות של מודלים לאלפי שבבים.
Pathways: סביבת ריצה מאוחדת לחישוב מבוזר בקנה מידה עצום
Pathways מציעה הפשטות לאימון מבוזר ולהיקש עם עמידות מובנית לכשלים ושחזור, ומאפשרת לחוקרי למידת מכונה לכתוב קוד כאילו הם משתמשים במכונה אחת ועוצמתית.
למה בחרנו לעשות זאת?
כדי לאמן ולפרוס מודלים גדולים, צריך מאות עד אלפי שבבים. הצ'יפים האלה מפוזרים על פני מתלים ומכונות מארחות רבים. משימת אימון היא תוכנית סינכרונית בקנה מידה גדול שדורשת שכל הצ'יפים האלה והמארחים שלהם יעבדו במקביל על חישובי XLA שעברו חלוקה (sharding). במקרה של מודלים גדולים של שפה, שעשויים לדרוש יותר מעשרות אלפי שבבים, השירות הזה צריך להיות מסוגל לפרוס מספר רב של תאי Pod ברשת של מרכז נתונים, בנוסף לשימוש ברשתות של חיבורים בין שבבים (ICI) וחיבורים בתוך שבב (OCI) בתוך תא Pod.
עיצוב
ML Pathways היא המערכת שבה אנחנו משתמשים כדי לתאם חישובים מבוזרים בין מארחים ושבבי TPU. הוא מיועד למדרגיות וליעילות במאות אלפי מאיצים. לאימון בהיקף גדול, הוא מספק לקוח Python יחיד למשימות מרובות של Pod, שילוב של Megascale XLA, שירות קומפילציה ו-Python מרוחק. הוא גם תומך במקביליות בין פרוסות ובסבילות להפסקה זמנית, ומאפשר שחזור אוטומטי מהפסקות זמניות של משאבים.
Pathways משלב קולקטיבים אופטימליים בין מארחים שמאפשרים לגרפים של חישובי XLA להתרחב מעבר ל-TPU Pod יחיד. הוא מרחיב את התמיכה של XLA במקביליות של נתונים, מודלים וצינורות, כדי לאפשר עבודה על פני גבולות של TPU slice באמצעות רשת מרכז הנתונים (DCN), על ידי שילוב של זמן ריצה מבוזר שמנהל את התקשורת של DCN עם פרימיטיבים של תקשורת XLA.
חוזקות עיקריות
ארכיטקטורת הבקרה היחידה, שמשולבת עם JAX, היא הפשטה מרכזית. הוא מאפשר לחוקרים לבחון אסטרטגיות שונות של חלוקה למקטעים (sharding) והקבלה (parallelism) לצורך אימון ופריסה, תוך התאמה לשימוש בעשרות אלפי שבבים בקלות.
פיתוח מתקדם: ביצועים, נתונים ויעילות
Pallas: כתיבת ליבות מותאמות אישית עם ביצועים גבוהים ב-JAX
JAX היא קודם כל קומפיילר, אבל יש מצבים שבהם כדאי לשלוט בחומרה בצורה מדויקת כדי להשיג ביצועים מקסימליים. Pallas היא תוסף ל-JAX שמאפשר לכתוב ליבות מותאמות אישית למעבדי GPU ול-TPU. היא נועדה לספק שליטה מדויקת בקוד שנוצר, בשילוב עם הארגונומיה ברמה גבוהה של מעקב JAX ו-jax.numpy API.
Pallas חושף מודל מקביליות מבוסס-רשת שבו פונקציית ליבה שהוגדרה על ידי המשתמש מופעלת ברשת רב-ממדית של קבוצות עבודה מקבילות. הוא מאפשר ניהול מפורש של היררכיית הזיכרון על ידי הגדרה של אופן חלוקת הטנסורים והעברתם בין זיכרון גדול יותר ואיטי יותר (לדוגמה, HBM) לבין זיכרון קטן יותר ומהיר יותר על שבב (לדוגמה, VMEM ב-TPU, זיכרון משותף ב-GPU), באמצעות מפות אינדקס כדי לשייך מיקומי רשת לבלוקים ספציפיים של נתונים. Pallas יכולה להוריד את אותה הגדרת ליבה כדי להריץ אותה ביעילות גם במעבדי TPU של Google וגם במעבדי GPU שונים, על ידי קומפילציה של ליבות לייצוג ביניים שמתאים לארכיטקטורת היעד – Mosaic למעבדי TPU, או שימוש בטכנולוגיות כמו Triton למעבדי GPU. עם Pallas, אפשר לכתוב ליבות (kernels) עם ביצועים גבוהים שמתמחות בבלוקים כמו תשומת לב, כדי להשיג את הביצועים הכי טובים של המודל בחומרה הייעודית, בלי להסתמך על ערכות כלים ספציפיות לספקים.
Tokamax: ספרייה שנאספה בקפידה של ליבות מתקדמות
אם Pallas הוא כלי ליצירת ליבות, Tokamax הוא ספרייה של ליבות מותאמות אישית מתקדמות של מאיצים שתומכות ב-TPU וב-GPU. Tokamax מבוסס על JAX ו-Pallas ומאפשר לכם להשתמש בכל היכולות של החומרה שלכם. הוא גם מספק כלים לבנייה ולכוונון אוטומטי של ליבות מותאמות אישית.
למה בחרנו לעשות זאת?
JAX, שמבוסס על XLA, הוא framework שמתמקד בהידור. עם זאת, יש מקרים ספציפיים שבהם צריך לשלוט ישירות בחומרה כדי להשיג ביצועים מקסימליים4. ליבות בהתאמה אישית הן חיוניות כדי להפיק את הביצועים הטובים ביותר ממשאבי האצה יקרים של למידת מכונה, כמו TPU ו-GPU. הן נמצאות בשימוש נרחב כדי לאפשר ביצועים טובים של אופרטורים מרכזיים כמו Attention, אבל כדי להטמיע אותן צריך להבין לעומק את המודל ואת ארכיטקטורת החומרה של היעד. Tokamax מספק מקור מוסמך אחד של ליבות שנבדקו היטב, שנאספו ונבחרו בקפידה ושמניבות ביצועים גבוהים, בשילוב עם תשתית משותפת חזקה לפיתוח, לתחזוקה ולניהול מחזור החיים שלהן. ספרייה כזו יכולה לשמש גם כהטמעה לדוגמה, שאפשר להסתמך עליה ולבצע בה התאמות אישיות לפי הצורך. כך תוכלו להתמקד במאמצי המידול בלי לדאוג לגבי התשתית.
4 זוהי פרדיגמה מבוססת היטב, ויש לה תקדים בעולם המעבדים, שבו קוד שעבר קומפילציה מהווה את רוב התוכנית, ומפתחים משתמשים בפונקציות פנימיות (intrinsics) או בהוראות מכונה מוטמעות כדי לבצע אופטימיזציה של חלקים קריטיים לביצועים.
עיצוב
לכל ליבה נתונה, Tokamax מספקת API משותף שיכול להיות מגובה על ידי כמה הטמעות. לדוגמה, אפשר להטמיע ליבות TPU באמצעות XLA רגיל או באופן מפורש באמצעות Pallas/Mosaic-TPU. יכול להיות שגרעיני GPU ייושמו על ידי הפחתה סטנדרטית של XLA, עם Mosaic-GPU או Triton. כברירת מחדל, Tokamax API בוחר את ההטמעה המוכרת ביותר עבור הגדרה נתונה, על סמך תוצאות שמורות במטמון מריצות תקופתיות של כוונון אוטומטי והשוואה לשוק. עם זאת, אפשר לבחור הטמעות ספציפיות אם צריך. יכול להיות שנוסיף עם הזמן הטמעות חדשות כדי לנצל טוב יותר תכונות ספציפיות בדורות חדשים של חומרה, וכך לשפר עוד יותר את הביצועים.
רכיב מרכזי בספריית Tokamax, מעבר לליבות עצמן, הוא התשתית התומכת שמאפשרת לכתוב ליבות בהתאמה אישית. לדוגמה, התשתית של הכוונון האוטומטי מאפשרת להגדיר קבוצה של פרמטרים שניתנים להגדרה (למשל, גודלי משבצות) ש-Tokamax יכול לבצע בהם סריקה מקיפה, כדי לקבוע את ההגדרות המכווננות הטובות ביותר ולשמור אותן במטמון. הבדיקות הרגרסיביות הליליות מגנות עליכם מפני בעיות לא צפויות בביצועים ובנתונים המספריים שנגרמות כתוצאה משינויים בתשתית הבסיסית של הקומפיילר או בתלות אחרת.
חוזקות עיקריות
- חוויית מפתחים חלקה: ספרייה מאוחדת ומסודרת מספקת יישומים טובים וידועים של ליבות מפתח, עם ביצועים גבוהים, וכוללת תיאורים ברורים של דורות החומרה הנתמכים ושל הביצועים הצפויים, גם באופן פרוגרמטי וגם במסמכים. כך מצמצמים את הפיצול ואת נטישת המשתמשים.
- גמישות וניהול מחזור החיים: אתם יכולים לבחור הטמעות שונות, ואפילו לשנות אותן לאורך זמן אם זה מתאים. לדוגמה, אם קומפיילר XLA משפר את התמיכה בפעולות מסוימות שכבר לא דורשות ליבות מותאמות אישית, יש דרך להוציא משימוש ולבצע מיגרציה.
- יכולת הרחבה: אתם יכולים להטמיע ליבות משלכם, תוך שימוש בתשתית משותפת עם תמיכה טובה, וכך להתמקד ביכולות ובאופטימיזציות שמוסיפות ערך. הטמעות סטנדרטיות שנוצרו בצורה ברורה משמשות כנקודת התחלה למשתמשים ללמידה ולהרחבה.
Qwix: Non-intrusive, comprehensive quantization
Qwix היא ספריית קוונטיזציה מקיפה למערך ה-AI של JAX, שתומכת ב-LLM ובסוגים אחרים של מודלים בכל השלבים, כולל אימון (Quantization Aware Training (QAT), Quantization Technique (QT), Quantized Low-Rank Adaptation (QLoRA)) והסקת מסקנות (Post Training Quantization (PTQ)), ומיועדת לזמני ריצה של XLA ולזמני ריצה במכשיר.
למה בחרנו לעשות זאת?
ספריות קיימות של קוונטיזציה, במיוחד במערכת האקולוגית של PyTorch, משמשות לעיתים קרובות למטרות מוגבלות (לדוגמה, רק PTQ או רק QLoRA). הסביבה המפוצלת הזו מחייבת אתכם לעבור בין כלים, ומונעת שימוש עקבי בקוד והתאמה מספרית מדויקת בין שלבי האימון וההסקה. בנוסף, פתרונות רבים דורשים שינויים משמעותיים במודל, שיוצרים קשר הדוק בין הלוגיקה של המודל לבין הלוגיקה של הכימות.
עיצוב
פילוסופיית העיצוב של Qwix מדגישה פתרון מקיף, וחשוב מכך, שילוב לא פולשני של מודלים. הארכיטקטורה שלו מבוססת על עיצוב היררכי וניתן להרחבה, שנבנה על ממשקי API פונקציונליים לשימוש חוזר.
השילוב הלא פולשני הזה מתבצע באמצעות מנגנון יירוט שתוכנן בקפידה ומפנה פונקציות JAX למקבילות שלהן שעברו קוונטיזציה. כך אפשר לשלב את המודלים בלי לבצע שינויים, ולנתק לחלוטין את קוד הכימות מהגדרות המודל.
בדוגמה הבאה מוצגת קוונטיזציה של w4a4 (משקל של 4 ביט, הפעלה של 4 ביט) בשכבות MLP של LLM וקוונטיזציה של w8 (משקל של 8 ביט) בשכבת ההטמעה. כדי לשנות את המתכון של הכימות, צריך רק לעדכן את רשימת הכללים.
fp_model = ModelWithoutQuantization(...)
rules = [
qwix.QuantizationRule(
module_path=r'embedder',
weight_qtype='int8',
),
qwix.QuantizationRule(
module_path=r'layers_\d+/mlp',
weight_qtype='int4',
act_qtype='int4',
tile_size=128,
weight_calibration_method='rms,7',
),
]
quantized_model = qwix.quantize_model(fp_model, qwix.PtqProvider(rules))
חוזקות עיקריות
- פתרון מקיף: אפשר להשתמש ב-Qwix במגוון רחב של תרחישי קוונטיזציה, והוא מבטיח שימוש עקבי בקוד בין אימון למסקנה.
- שילוב מודלים לא פולשני: כמו שאפשר לראות בדוגמה, אפשר לשלב מודלים באמצעות שורת קוד אחת. כך תוכלו להשתמש בהיפרפרמטרים על פני הרבה סכימות קוונטיזציה כדי למצוא את האיזון הטוב ביותר בין איכות לבין ביצועים.
- פדרציה עם ספריות אחרות: Qwix משתלב בצורה חלקה עם חבילת ה-AI של JAX. לדוגמה, Tokamax מתאים את עצמו באופן אוטומטי לשימוש בגרסאות מכומתות של ליבות, בלי קוד משתמש נוסף, כשהמודל מכומת באמצעות Qwix.
- ידידותי למחקר: ממשקי ה-API הבסיסיים של Qwix והארכיטקטורה הניתנת להרחבה מאפשרים לחוקרים לבדוק אלגוריתמים חדשים ולבצע השוואות פשוטות באמצעות כלי השוואה והערכה משולבים.
שכבת האפליקציות: אימון והתאמה
אימון מודלים בסיסיים: MaxText ו-MaxDiffusion
MaxText ו-MaxDiffusion הם מסגרות הדגל של Google לאימון מודלים גדולים של שפה ומודלים של דיפוזיה, בהתאמה. המאגרים האלה מכילים מבחר של הטמעות שעברו אופטימיזציה גבוהה של מודלים פופולריים עם משקלים פתוחים. הם משמשים למטרה כפולה: הם פועלים כבסיס קוד מוכן לאימון מודלים, וגם כהפניה שיוצרי מודלים בסיסיים יכולים להשתמש בה כדי לבנות עליה.
למה בחרנו לעשות זאת?
יש עניין גובר בתעשייה בהכשרת מודלים של AI גנרטיבי. הפופולריות של מודלים פתוחים האיצה את המגמה הזו, וסיפקה ארכיטקטורות מוכחות. כדי לאמן את המודלים האלה ולהתאים אותם, נדרשים ביצועים גבוהים, יעילות, יכולת הרחבה למספרים גדולים של שבבים וקוד ברור ומובן. MaxText ו-MaxDiffusion הם פתרונות מקיפים שאפשר להשתמש בהם ב-TPU או ב-GPU, והם נועדו לתת מענה לצרכים האלה.
עיצוב
MaxText ו-MaxDiffusion הם בסיסי קוד של מודלים בסיסיים שנועדו להיות קריאים ולספק ביצועים טובים. הם בנויים מרכיבים שנבדקו היטב וניתנים לשימוש חוזר: הגדרות מודל שמשתמשות בקרנלים מותאמים אישית (כמו Tokamax) לביצועים מקסימליים, מערכת אימון לתיאום ולמעקב ומערכת תצורה עוצמתית שמאפשרת לכם לשלוט בפרטים כמו חלוקה (sharding) וכימות (quantization) (באמצעות Qwix) דרך ממשק אינטואיטיבי. תכונות מתקדמות של אמינות, כמו יצירת נקודות ביקורת רב-שכבתיות, משולבות כדי להבטיח קצב העברת נתונים טוב לאורך זמן.
MaxText ו-MaxDiffusion משתמשים בספריות JAX הכי טובות מסוגן – Qwix, Tunix, Orbax ו-Optax – כדי לספק יכולות ליבה. הספריות האלה מספקות תשתית חזקה וניתנת להרחבה, מצמצמות את התקורה של הפיתוח ומאפשרות לכם להתמקד במשימת המידול. לצורך הסקת מסקנות, קוד המודל משותף כדי לאפשר פרסום יעיל וניתן להרחבה.
חוזקות עיקריות
- ביצועים טובים כבר מההתחלה: עם תשתית אימון שהוגדרה ל'תפוקה טובה' (throughput שימושי) גבוהה ויישומים של מודלים שעברו אופטימיזציה לשימוש גבוה ב-MFU (Model Flops Utilization), MaxText ו-MaxDiffusion מספקים ביצועים גבוהים בהיקף רחב כבר מההתחלה.
- מיועד להרחבה: המסגרות האלה מבוססות על יכולות ה-AI של JAX (במיוחד Pathways), ומאפשרות לכם להרחיב את השימוש בצורה חלקה מעשרות שבבים לעשרות אלפי שבבים.
- בסיס איתן ליוצרי מודלים בסיסיים: ההטמעות האיכותיות והקריאות משמשות כנקודת התחלה טובה למפתחים, והם יכולים להשתמש בהן כפתרון מקצה לקצה או כהטמעה לדוגמה להתאמות אישיות משלהם.
פוסטים לאימון ולהתאמה: מסגרת Tunix
Tunix מציעה אלגוריתמים מתקדמים של למידת חיזוק (RL) בקוד פתוח, יחד עם מסגרת ותשתית חזקות, ומספקת למפתחים דרך יעילה להתנסות בטכניקות של מודלים גדולים של שפה (LLM) אחרי האימון, כולל כוונון עדין מפוקח (SFT) והתאמה באמצעות JAX ו-TPU.
למה בחרנו לעשות זאת?
השלב שאחרי האימון הוא שלב קריטי למיצוי היכולות האמיתיות של מודלים מסוג LLM. שלב הלמידה המחוזקת (RL) חשוב במיוחד לפיתוח יכולות של התאמה וחשיבה רציונלית. פיתוח קוד פתוח בתחום הזה התבסס כמעט באופן בלעדי על PyTorch ו-GPU, מה שהשאיר פער מהותי בפתרונות של JAX ו-TPU. Tunix (Tune-in-JAX) היא ספרייה מקורית של JAX עם ביצועים גבוהים, שנועדה לתת מענה לצורך הזה.
עיצוב
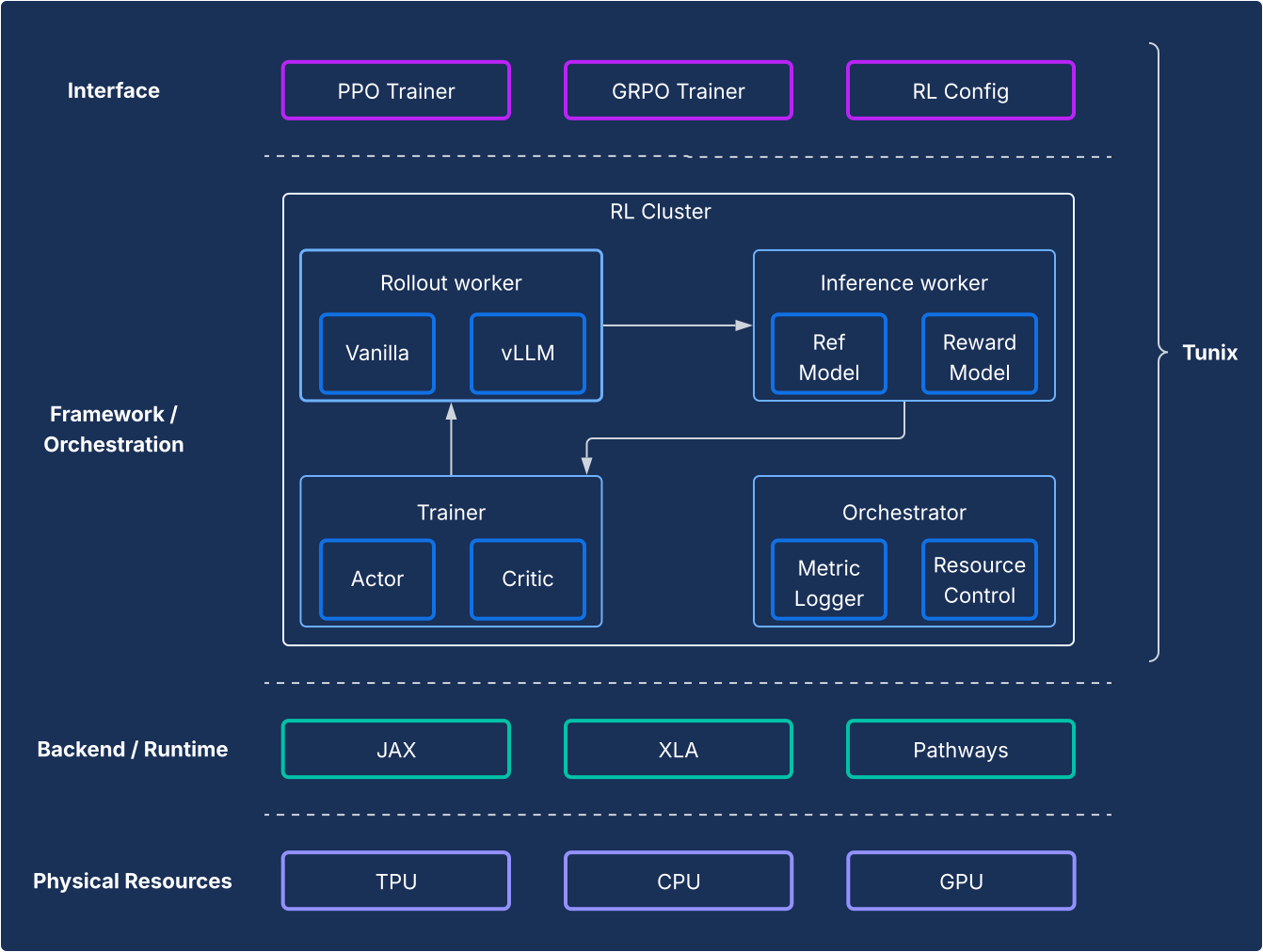
מנקודת מבט של מסגרת, Tunix מאפשרת הגדרה מתקדמת שמפרידה באופן ברור בין אלגוריתמים של RL לבין התשתית. הוא מציע API קל משקל שדומה ללקוח ומסתיר את המורכבות של תשתית ה-RL, וכך מאפשר לכם לפתח אלגוריתמים חדשים. Tunix מספק פתרונות מוכנים לשימוש לאלגוריתמים פופולריים, כולל Proximal Policy Optimization (PPO), Direct Preference Optimization (DPO) ואחרים.
בצד התשתית, Tunix משולב עם Pathways, מה שמאפשר ארכיטקטורה של בקר יחיד שנותנת גישה לאימון RL מרובה צמתים. בצד האימון, Tunix תומכת באופן מובנה באימון יעיל של פרמטרים (לדוגמה, LoRA) ומשתמשת ב-JAX sharding וב-XLA (מקביליות כללית וניתנת להרחבה לגרף חישוב של ML (GSPMD)) כדי ליצור גרף חישוב עם ביצועים טובים. היא תומכת במודלים פופולריים של קוד פתוח כמו Gemma ו-Llama.
חוזקות עיקריות
- פשטות: הוא מספק API ברמה גבוהה, כמו לקוח, שמפשט את המורכבויות של התשתית המבוזרת הבסיסית.
- יעילות הפיתוח: Tunix מאיץ את מחזור החיים של המחקר והפיתוח באמצעות אלגוריתמים ו'מתכונים' מובנים, ומספק מודל עובד שמאפשר לכם לבצע איטרציות במהירות.
- ביצועים וגמישות: Tunix מאפשרת תשתית אימון יעילה מאוד וגמישה, על ידי שימוש ב-Pathways כבקר יחיד בקצה העורפי.
שכבת האפליקציות: ייצור והיקש
אתגר היסטורי באימוץ JAX היה המעבר ממחקר לייצור. חבילת ה-AI של JAX מספקת עכשיו סיפור הפקה בוגר עם שני היבטים, שכולל גם תאימות למערכת האקולוגית וגם ביצועים של JAX.
הסקת מסקנות ממודל שפה גדול (LLM) עם ביצועים גבוהים: הפתרון vLLM
vLLM-TPU הוא מחסנית הסקת מסקנות של Google עם ביצועים גבוהים, שנועדה להפעיל ביעילות מודלים גדולים של שפה (LLM) של PyTorch ו-JAX ב-Cloud TPU. השילוב הזה מתבצע באופן מובנה של ה-framework הפופולרי vLLM בקוד פתוח עם המערכת האקולוגית של JAX ו-TPU של Google.
למה בחרנו לעשות זאת?
התחום מתפתח במהירות, ויש ביקוש הולך וגדל לפתרונות הסקה חלקים, עם ביצועים גבוהים ונוחים לשימוש. מפתחים נתקלים לעיתים קרובות באתגרים משמעותיים שנובעים מכלים מורכבים ולא עקביים, מביצועים לא מספיקים ומתאימות מוגבלת של מודלים. מערכת vLLM פותרת את הבעיות האלה באמצעות פלטפורמה מאוחדת, יעילה ואינטואיטיבית.
עיצוב
הפתרון הזה מרחיב את המסגרת vLLM, במקום להמציא אותה מחדש. vLLM-TPU הוא מנוע שרת LLM בקוד פתוח שעבר אופטימיזציה גבוהה, והוא ידוע בנפח התפוקה הגבוה שלו. הנפח הזה מושג באמצעות תכונות מרכזיות כמו PagedAttention (שמנהלת מטמוני KV כמו זיכרון וירטואלי כדי למזער את הפיצול) וContinuous Batching (שמוסיפה באופן דינמי בקשות לאצווה כדי לשפר את הניצול).
vLLM-TPU מתבסס על התשתית הזו ומפתח רכיבי ליבה לטיפול בבקשות, לתזמון ולניהול זיכרון. הוא כולל קצה עורפי מבוסס-JAX שפועל כגשר, ומתרגם את הגרף החישובי של vLLM ואת פעולות הזיכרון לקוד שניתן להרצה ב-TPU. הקצה העורפי הזה מטפל באינטראקציות עם המכשיר, בהרצת מודל JAX ובפרטים הספציפיים של ניהול מטמון ה-KV בחומרת TPU. הוא כולל אופטימיזציות ספציפיות ל-TPU, כמו מנגנוני תשומת לב יעילים (לדוגמה, שימוש בגרעיני JAX Pallas ל-Ragged Paged Attention) וקוונטיזציה, והכול מותאם לארכיטקטורת ה-TPU.
חוזקות עיקריות
- עלות אפסית להוספה או להסרה של משתמשים: המשתמשים יכולים להשתמש בפתרון הזה בלי בעיות משמעותיות. מבחינת חוויית המשתמש, עיבוד בקשות להסקת מסקנות ב-TPU צריך להיות זהה לעיבוד ב-GPU. ה-CLI כדי להפעיל את השרת, לקבל הנחיות ולהחזיר פלט, הכול משותף.
- שימוש מלא בסביבה העסקית: הגישה הזו משתמשת בממשק vLLM ובחוויית המשתמש שלו ותורמת להם, כדי להבטיח תאימות ונוחות שימוש.
- אפשרות להחלפה בין TPU ל-GPU: הפתרון פועל ביעילות גם ב-TPU וגם ב-GPU, ומאפשר לכם גמישות.
- יעילות מבחינת עלות (הביצועים הכי טובים ביחס לעלות): אופטימיזציה של הביצועים כדי לספק את יחס הביצועים לעלות הטוב ביותר עבור מודלים פופולריים.
הצגת מודלים ב-JAX: סריאליזציה של Orbax ומנוע להצגת מודלים של Neptune
למודלים שאינם LLM, או למשתמשים שרוצים צינור נתונים מקורי לחלוטין של JAX, ספריית הסריאליזציה Orbax ומערכת Neptune serving engine (NSE) מספקות פתרון הגשה מקצה לקצה עם ביצועים גבוהים.
למה בחרנו לעשות זאת?
בעבר, מודלים של JAX הסתמכו לעיתים קרובות על נתיב עקיף להעברה לסביבת הייצור, כמו עטיפה בתרשימים של TensorFlow ופריסה באמצעות TensorFlow Serving. הגישה הזו הציגה מגבלות משמעותיות וחוסר יעילות, ואילצה את המפתחים לעבוד עם מערכת אקולוגית נפרדת, מה שהאט את תהליך האיטרציה. מערכת ייעודית להצגת מודעות בפורמט JAX-native היא חיונית כדי להבטיח קיימות, להפחית את המורכבות ולשפר את הביצועים.
עיצוב
הפתרון הזה מורכב משני רכיבי ליבה, כפי שמוצג בדיאגרמה הבאה.
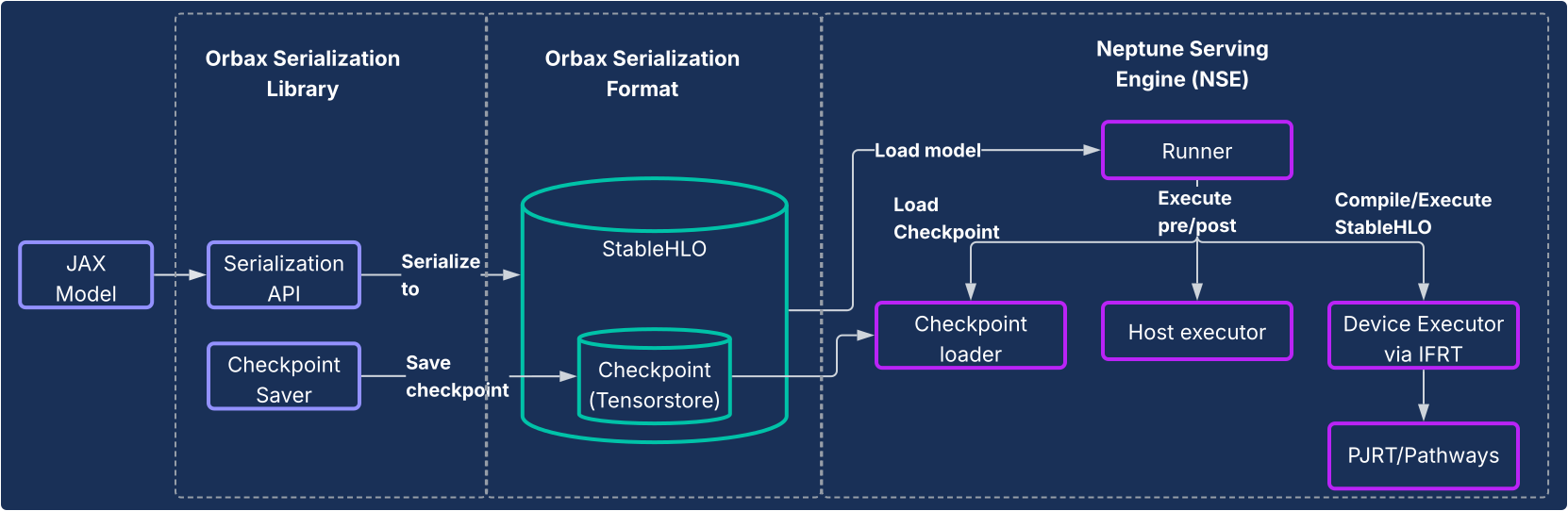
- ספריית הסריאליזציה של Orbax: מספקת ממשקי API ידידותיים למשתמש לסריאליזציה של מודלים של JAX לפורמט סריאליזציה חדש וחזק של Orbax. הפורמט הזה מותאם לפריסה בסביבת ייצור. הוא מייצג ישירות חישובים של מודל JAX באמצעות StableHLO, ומאפשר לייצג את גרף החישוב באופן מקורי. הוא גם משתמש ב-TensorStore לאחסון משקלים, וכך מאפשר טעינה מהירה של נקודות ביקורת לצורך הצגה.
- Neptune Serving Engine (NSE): מנוע ההצגה הנלווה הזה הוא בעל ביצועים גבוהים וגמישות (בדרך כלל הוא נפרס כקובץ בינארי של C++) והוא מיועד להפעיל מודלים של JAX בפורמט Orbax באופן מקורי. NSE מציע יכולות חיוניות לייצור, כמו טעינת מודלים מהירה, שירות מקביל עם תפוקה גבוהה עם חלוקה מובנית למנות, תמיכה בכמה גרסאות של מודלים ושירות של מארח יחיד ומארחים מרובים (באמצעות PJRT ו-Pathways). אפשר להשתמש ב-Neptune Serving Engine כדי:
- מודלים שאינם LLM: זהו פתרון למטרות כלליות שמתאים לעומסי עבודה כמו מערכות המלצה, מודלים של דיפוזיה ומודלים אחרים של AI.
- מודלים קטנים של LLM והצגה של תוצאות ב'פעם אחת': המודל הזה מיועד למודלים לא אוטומטיים או למודלים קטנים יותר שמוצגים ב'פעם אחת', שבהם הפלט כולו נוצר במעבר יחיד בלי הצורך בניהול מורכב של מצב כמו מטמון KV.
בקיצור, Neptune Serving Engine משלים את הפער במתן שירות למגוון רחב של מודלים שאינם מודלים גדולים של שפה אוטו-רגרסיבית, ומספק פתרון TPU מקורי עם ביצועים גבוהים למערכת האקולוגית הרחבה יותר של ML.
חוזקות עיקריות
- JAX Native Serving: הפתרון מובנה באופן מקורי עבור JAX, ולכן אין תקורה בין מסגרות בסריאליזציה של המודל ובביצוע משימות. כך נמנע עומס על המודל והביצועים שלו יהיו אופטימליים במעבדי CPU, מעבדי GPU ומעבדי TPU.
- פריסת Production קלה: מודלים שעברו סריאליזציה מספקים נתיב פריסה הרמטי שלא מושפע מסחף בתלות של Python ומאפשר בדיקות תקינות של המודל בזמן הריצה. כך אפשר להעביר מודלים של JAX לייצור בצורה חלקה ואינטואיטיבית.
- חוויית מפתחים משופרת: הפתרון הזה מבטל את הצורך בעטיפת מסגרות מסורבלות, וכך מצמצם באופן משמעותי את התלות ואת מורכבות המערכת, ומאפשר למפתחי JAX לבצע איטרציות מהר יותר.
ניתוח ופרופיל בכל המערכת
XProf: ניתוח מעמיק של פרופילי ביצועים עם שילוב חומרה
XProf הוא כלי ליצירת פרופילים ולניתוח ביצועים, שמספק תובנות מעמיקות לגבי היבטים שונים של ביצוע עומסי עבודה של ML, ומאפשר לכם לנפות באגים ולבצע אופטימיזציה של הביצועים. הוא משולב באופן מלא במערכות האקולוגיות של JAX ו-TPU.
למה בחרנו לעשות זאת?
מצד אחד, עומסי העבודה של למידת מכונה הולכים ונעשים מורכבים יותר. מצד שני, יש התפוצצות של יכולות חומרה מיוחדות שמיועדות לעומסי העבודה האלה. התאמה יעילה בין השניים חיונית כדי להבטיח ביצועים ויעילות מקסימליים, בהתחשב בעלויות הגבוהות של תשתית למידת מכונה. כדי לעשות את זה, צריך לקבל תצוגה מפורטת של עומס העבודה ושל החומרה, בצורה שקל להבין. XProf מצטיין בכך.
עיצוב
XProf מורכב משני רכיבים עיקריים: איסוף וניתוח.
- איסוף: XProf אוסף מידע ממקורות שונים: הערות בקוד JAX, מודלים של עלויות לפעולות בקומפיילר XLA ותכונות פרופיל חומרה שנוצרו במיוחד ב-TPU. אפשר להפעיל את האוסף הזה באופן פרוגרמטי או לפי דרישה, וכך ליצור ארטיפקט מקיף של אירוע.
- ניתוח: XProf מעבד את הנתונים שנאספו ויוצר חבילה של תרשימים רבי עוצמה, שאפשר לגשת אליהם באמצעות דפדפן.
חוזקות עיקריות
העוצמה האמיתית של XProf נובעת מהשילוב העמוק שלה עם המערכת המלאה, ומספקת ניתוח רחב ומעמיק שהוא יתרון מוחשי של מערכת JAX/TPU שתוכננה במשותף.
- תכנון משותף עם TPU: XProf מנצל תכונות חומרה שתוכננו במיוחד לאיסוף חלק של פרופילים, ומאפשר תקורה של איסוף של פחות מ-1%. כך אפשר להשתמש בפרופילים כחלק קל ואיטרטיבי מהפיתוח.
- רוחב ועומק הניתוח: XProf מספק ניתוח מעמיק בכמה מישורים. הכלים שלו כוללים:
- Trace Viewer: תצוגת ציר זמן של פעולה שמתבצעת ביחידות חומרה שונות (לדוגמה, TensorCores).
- פרופיל פעולות HLO: פירוט של הזמן הכולל שהושקע בקטגוריות שונות של פעולות.
- Memory Viewer: פרטים על הקצאות זיכרון לפי פעולות שונות במהלך חלון הפרופיל.
- ניתוח Roofline: עוזר לכם לזהות אם פעולות ספציפיות מוגבלות על ידי המחשוב או הזיכרון, וכמה רחוקות הן מיכולות השיא של החומרה.
- Graph Viewer: כלי שמאפשר לראות את הגרף המלא של HLO שמופעל על ידי החומרה.
פרספקטיבה השוואתית: מחסנית JAX/TPU כאפשרות משכנעת
בנוף המודרני של למידת מכונה יש הרבה שרשראות כלים מצוינות ומוכחות. חבילת ה-AI של JAX מציגה יתרונות ייחודיים ומשמעותיים למפתחים שמתמקדים בלמידת מכונה (ML) בקנה מידה גדול ועם ביצועים גבוהים. היתרונות האלה נובעים ישירות מהעיצוב המודולרי שלה ומהתכנון המשותף המעמיק של החומרה.
יש הרבה מסגרות שמציעות מגוון רחב של תכונות, אבל JAX AI Stack מספקת הבדלים ספציפיים ומשמעותיים בתחומים מרכזיים של מחזור החיים של הפיתוח:
- חוויית פיתוח פשוטה ויעילה יותר: פרדיגמת השינוי של Optax מאפשרת ליצור אסטרטגיות אופטימיזציה יעילות וגמישות יותר, שמוצהרות פעם אחת במקום לנהל אותן באופן אימפרטיבי בלולאת האימון. ברמת המערכת, ממשק הבקרה היחיד הפשוט יותר של Pathways מפשט את המורכבות של אימון עם כמה פרוסות, וזהו יתרון משמעותי לחוקרים.
- מתוכנן לעמידות ברמת גיבור: מחסנית JAX מיועדת לאימון בקנה מידה קיצוני. Orbax מספק תכונות של 'עמידות לאימונים בקנה מידה גדול' כמו יצירת נקודות עצירה (checkpointing) במקרה חירום ובכמה רמות. בנוסף, Grain מציע תמיכה מלאה בשחזור עם ערבובים גלובליים דטרמיניסטיים וטועני נתונים שאפשר להגדיר להם נקודות עצירה. היכולת לבצע צ'קפוינט אטומי של מצב פייפליין הנתונים (Grain) עם מצב המודל (Orbax) היא יכולת קריטית להבטחת שחזוריות במשימות ארוכות טווח.
- מערכת אקולוגית מלאה מקצה לקצה: חבילת המוצרים מספקת פתרון מגובש מקצה לקצה. מפתחים יכולים להשתמש ב-MaxText כהפניה ל-SOTA לצורך אימון, ב-Tunix לצורך התאמה, ולפעול לפי נתיב ברור עם שני מסלולים להפקה באמצעות vLLM-TPU (לתאימות ל-vLLM) ו-NSE (לביצועים של JAX).
מבחינת תוכנה ברמה גבוהה, הרבה מחסניות דומות, אבל הגורם המכריע הוא לרוב ביצועים/עלות כוללת של בעלות, ופה העיצוב המשותף של JAX ו-TPU מספק יתרון מובהק. היתרון הזה בביצועים ובעלות הכוללת על הבעלות (TCO) הוא תוצאה ישירה של השילוב האנכי בין תוכנה לחומרה של TPU. היכולת של קומפיילר XLA למזג פעולות במיוחד לארכיטקטורת TPU, או של פרופיילר XProf להשתמש בווים של חומרה כדי ליצור פרופילים עם תקורה של פחות מ-1%, הן יתרונות מוחשיים של השילוב העמוק הזה.
לארגונים שמאמצים את הסטאק הזה, האופי המלא של סטאק ה-AI של JAX ממזער את עלות המיגרציה. ללקוחות שמשתמשים בארכיטקטורות פופולריות של מודלים פתוחים, המעבר ממסגרות אחרות ל-MaxText הוא לרוב עניין של הגדרת קובצי תצורה. בנוסף, היכולת של המערכת להטמיע פורמטים פופולריים של נקודות ביקורת כמו safetensors מאפשרת להעביר נקודות ביקורת קיימות בלי צורך באימון מחדש יקר.
בטבלה הבאה מוצג מיפוי של הרכיבים שסופקו על ידי חבילת ה-AI של JAX והרכיבים המקבילים שלהם בספריות או במסגרות אחרות.
| פונקציה | JAX | חלופות/מקבילות במסגרות אחרות5 |
| מהדר (Compiler) / זמן ריצה | XLA | Inductor, eager |
| אימון MultiPod | Pathways | Torch lightning strategies, Ray Train, Monarch (new). |
| Core framework | JAX | PyTorch |
| יצירת מודלים | דגמי Flax, Max* | torch.nn.*,
NVidia TransformerEngine, HuggingFace Transformers
|
| אופטימיזציה והפסדים | Optax | torch.optim.*, torch.nn.*Loss |
| כלי טעינת נתונים | גרעיניות | Ray Data, HuggingFace dataloaders |
| Checkpointing | Orbax | PyTorch distributed checkpointing, NeMo checkpointing |
| קוונטיזציה | Qwix | TorchAO, bitsandbytes |
| יצירת ליבות והטמעות מוכרות | Pallas / Tokamax | Triton/Helion, Liger-kernel, TransformerEngine |
| אחרי אימון או כוונון | Tunix | VERL, NeMoRL |
| יצירת פרופילים | XProf | PyTorch profiler, NSight systems, NSight Compute |
| אימון מודל בסיסי | MaxText, MaxDiffusion | NeMo-Megatron, DeepSpeed, TorchTitan |
| הסקת מסקנות של LLM | vLLM | SGLang |
| הסקת מסקנות שאינה LLM | NSE | Triton Inference Server, RayServe |
5חלק מההשוואות כאן לא תמיד מדויקות כי מסגרות אחרות מציירות גבולות API באופן שונה בהשוואה ל-JAX. רשימת המקבילים היא חלקית בלבד, וספריות חדשות מופיעות לעיתים קרובות.
מסקנה: פלטפורמה עמידה ומוכנה לייצור לעתיד ה-AI
הנתונים שמוצגים בטבלה הקודמת ממחישים מסקנה ברורה – לכל אחת מהחבילות האלה יש יתרונות וחסרונות משלה במספר קטן של תחומים, אבל באופן כללי הן דומות מאוד מבחינת התוכנה. שתי המערכות מספקות פתרונות מוכנים לאימון מוקדם, להתאמה אחרי האימון ולפריסה של מודלים בסיסיים.
חבילת ה-AI של JAX מציעה פתרון משכנע וחזק לאימון ולפריסה של מודלים של למידת מכונה בכל קנה מידה. הוא משתמש בשילוב אנכי עמוק בין תוכנה וחומרת TPU כדי לספק ביצועים מובילים בענף ועלות כוללת של בעלות.
הסטאק מבוסס על מערכות פנימיות שנבדקו בשטח, והוא התפתח כדי לספק מהימנות ומדרגיות מובנות. כך המשתמשים יכולים לפתח ולפרוס בביטחון גם את המודלים הגדולים ביותר. העיצוב המודולרי והקומפוזבילי, שמבוסס על הפילוסופיה של JAX AI Stack, מעניק למשתמשים חופש ושליטה חסרי תקדים, ומאפשר להם להתאים את החבילה לצרכים הספציפיים שלהם בלי המגבלות של מסגרת מונוליטית.
עם XLA ו-Pathways שמספקים בסיס ניתן להרחבה ועמיד בפני תקלות, JAX שמספק ספרייה נומרית יעילה ורחבה, ספריות פיתוח ליבה חזקות כמו Flax, Optax, Grain ו-Orbax, כלי ביצועים מתקדמים כמו Pallas, Tokamax ו-Qwix, ושכבת יישומים וייצור חזקה ב-MaxText, vLLM ו-NSE, חבילת ה-AI של JAX מספקת בסיס עמיד למשתמשים לבנייה ולהעברה מהירה של מחקר מתקדם לייצור.