
Créer une IA de production sur des Cloud TPU avec JAX
La pile d'IA JAX étend le cœur numérique JAX avec une collection de bibliothèques composables soutenues par Google, ce qui en fait une plate-forme Open Source de bout en bout robuste pour le machine learning à des échelles extrêmes. À ce titre, la pile d'IA JAX se compose d'un écosystème complet et robuste qui couvre l'ensemble du cycle de vie du ML :
Fondation à l'échelle industrielle : la pile d'IA JAX est conçue pour une mise à l'échelle massive, en s'appuyant sur ML Pathways pour orchestrer l'entraînement sur des dizaines de milliers de puces et sur Orbax pour un checkpointing asynchrone résilient et à haut débit, ce qui permet un entraînement de qualité production de modèles de pointe.
Boîte à outils complète et prête pour la production : la pile d'IA JAX fournit un ensemble complet de bibliothèques pour l'ensemble du processus de développement : Flax pour la création de modèles flexibles, Optax pour les stratégies d'optimisation composables et Grain pour les pipelines de données déterministes essentiels aux exécutions reproductibles à grande échelle.
Performances de pointe et spécialisées : pour maximiser l'utilisation du matériel, la pile d'IA JAX propose des bibliothèques spécialisées, y compris Tokamax pour les noyaux personnalisés de pointe, Qwix pour la quantification non intrusive qui améliore la vitesse d'entraînement et d'inférence, et XProf pour le profilage des performances approfondi et intégré au matériel.
Chemin complet vers la production : la pile d'IA JAX permet une transition fluide de la recherche au déploiement. Cela inclut MaxText comme référence évolutive pour l'entraînement des modèles de fondation, Tunix pour l'apprentissage par renforcement (RL) et l'alignement de pointe, ainsi qu'une solution d'inférence unifiée avec l'intégration vLLM TPU et l'environnement d'exécution JAX pour le service.
La philosophie de la pile d'IA JAX repose sur des composants faiblement couplés, chacun d'eux étant spécialisé dans une tâche. Plutôt que d'être un framework de ML monolithique, JAX est lui-même de portée limitée et se concentre sur les opérations de tableaux et les transformations de programmes efficaces. L'écosystème est basé sur ce framework principal pour fournir un large éventail de fonctionnalités, liées à l'entraînement des modèles de ML et à d'autres types de charges de travail telles que le calcul scientifique.
Ce système de composants faiblement couplés vous permet de sélectionner et de combiner des bibliothèques de la manière la plus adaptée à vos besoins. Du point de vue de l'ingénierie logicielle, cette architecture vous permet également de mettre à jour de manière itérative les fonctionnalités qui seraient traditionnellement considérées comme des composants de framework de base (par exemple, les pipelines de données et la création de points de contrôle), sans risquer de déstabiliser le framework de base ni d'être pris dans les cycles de publication. Étant donné que la plupart des fonctionnalités sont implémentées dans des bibliothèques plutôt que dans des modifications apportées à un framework monolithique, cela rend la bibliothèque de nombres de base plus durable et adaptable aux futurs changements du paysage technologique.
Les sections suivantes présentent un aperçu technique de la pile d'IA JAX, de ses principales fonctionnalités, des décisions de conception qui les sous-tendent et de la manière dont elles se combinent pour créer une plate-forme durable pour les charges de travail de ML modernes.
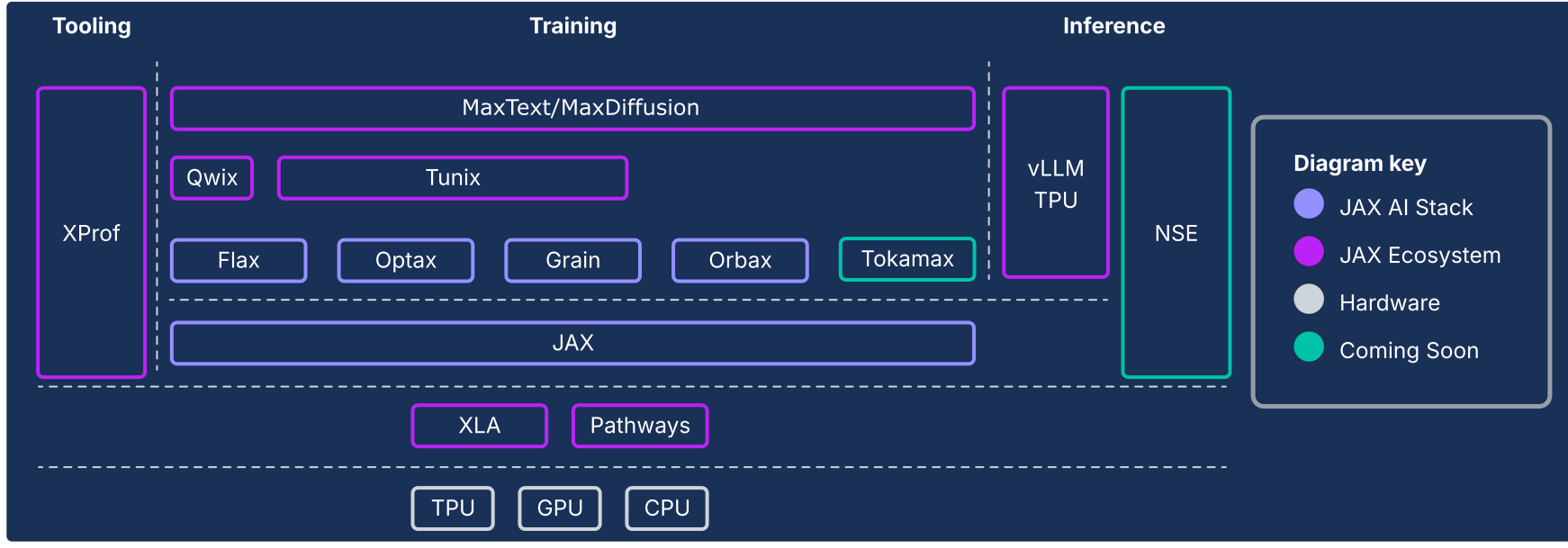
Pile JAX AI et autres composants de l'écosystème
| Composant | Fonction / Description |
|---|---|
| Composants et cœur de la pile JAX AI1 | |
| JAX | Calcul de tableaux et transformation de programmes orientés accélérateur (JIT, grad, vmap, pmap). |
| Flax | Bibliothèque flexible de création de réseaux neuronaux pour une création et une modification intuitives des modèles. |
| Optax | Bibliothèque de transformations composables pour le traitement et l'optimisation des gradients. |
| Orbax | Bibliothèque de point de contrôle distribuée "toute échelle" pour la résilience de l'entraînement à l'échelle héroïque. |
| Grain | Bibliothèque de pipeline de données d'entrée évolutive, déterministe et vérifiable. |
| Pile d'IA JAX : infrastructure | |
| XLA | Compilateur de machine learning Open Source pour les TPU, les processeurs et les GPU. |
| Pathways | Runtime distribué pour orchestrer le calcul sur des dizaines de milliers de puces. |
| Pile JAX AI : avancé Développement | |
| Pallas | Extension JAX permettant d'écrire des noyaux personnalisés de bas niveau et hautes performances implémentés en Python. |
| Tokamax | Une bibliothèque organisée de noyaux personnalisés hautes performances et de pointe (par exemple, Attention). |
| Qwix | Une bibliothèque complète et non intrusive pour la quantification (PTQ, QAT, QLoRA). |
| Pile JAX AI : application | |
| MaxText / MaxDiffusion | Frameworks de référence phares et évolutifs pour l'entraînement des modèles de fondation (par exemple, LLM et diffusion). |
| Tunix | Framework pour l'entraînement et l'alignement post-entraînement de pointe (RLHF, DPO). |
| vLLM | Solution d'inférence LLM hautes performances utilisant l'intégration intégrée du framework vLLM. |
| XProf | Profileur intégré au matériel pour une analyse des performances à l'échelle du système. |
1 Inclus dans le package Python jax-ai-stack.
Figure 1 : Composants de la pile et de l'écosystème JAX AI
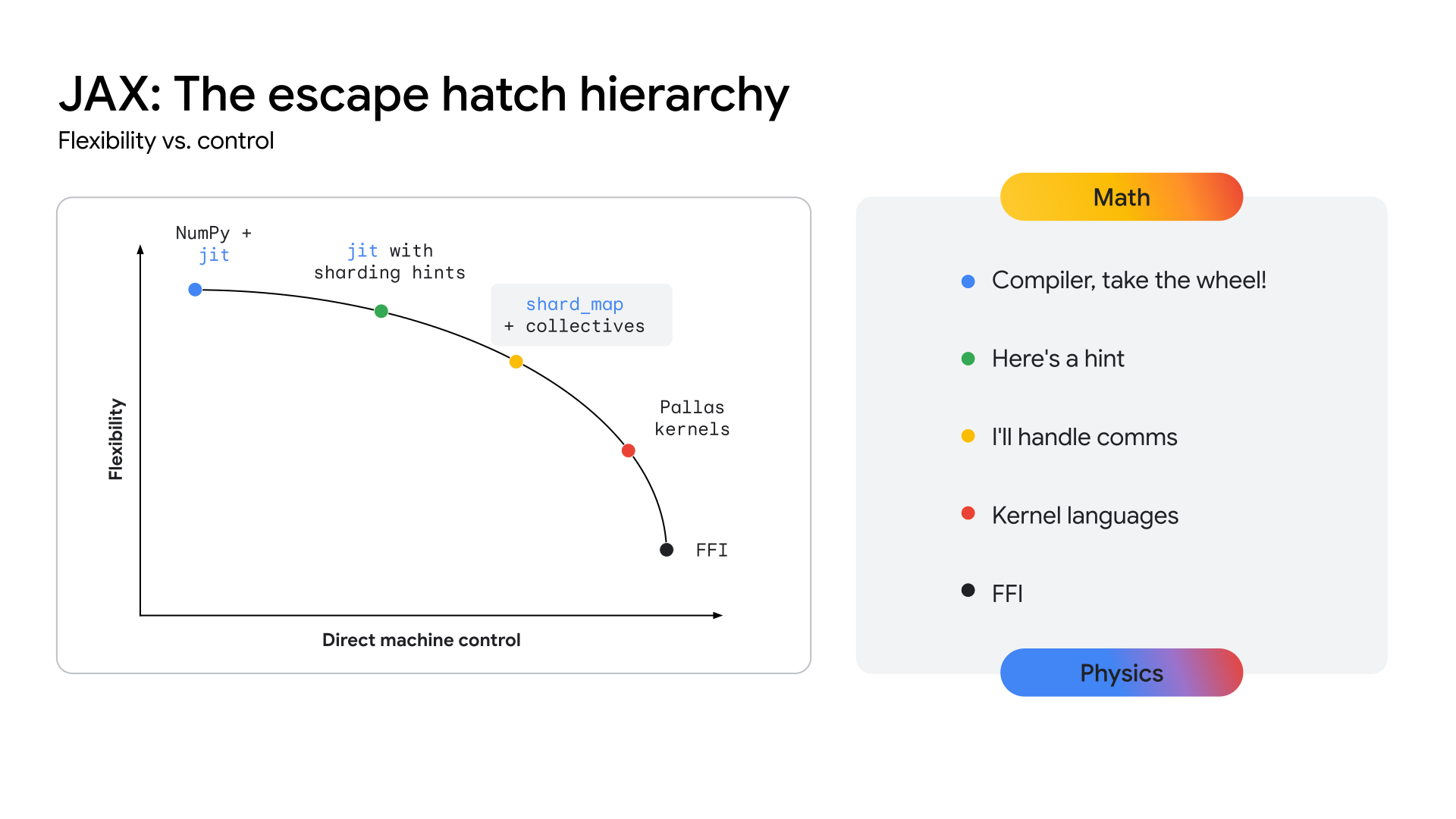
L'impératif architectural : des performances au-delà des frameworks
Alors que les architectures de modèles convergent (par exemple, sur les Transformers multimodaux Mixture-of-Experts (MoE)), la recherche de performances maximales conduit à l'émergence des Megakernels. Un mégakernel correspond à l'intégralité (ou une grande partie) de la passe avant d'un modèle spécifique, codée manuellement à l'aide d'une API de niveau inférieur comme le SDK CUDA sur les GPU NVIDIA. Cette approche permet d'utiliser au maximum le matériel en chevauchant de manière agressive le calcul, la mémoire et la communication. Des travaux récents de la communauté de recherche ont démontré que cette approche peut générer des gains de débit importants (plus de 22 % dans certains cas) pour l'inférence sur les GPU. Cette tendance ne se limite pas à l'inférence. Des éléments suggèrent que certains efforts d'entraînement à grande échelle ont impliqué un contrôle matériel de bas niveau pour obtenir des gains d'efficacité importants.
Si cette tendance s'accélère, tous les frameworks de haut niveau tels qu'ils existent aujourd'hui risquent de devenir moins pertinents, car l'accès de bas niveau au matériel est ce qui compte en fin de compte pour les performances sur les architectures matures et stables. Cela représente un défi pour toutes les piles ML modernes : comment fournir un contrôle matériel de niveau expert sans sacrifier la productivité et la flexibilité d'un framework de haut niveau ?
Pour que les TPU offrent une voie claire vers ce niveau de performances, l'écosystème doit exposer une couche d'API plus proche du matériel, permettant le développement de ces kernels hautement spécialisés. La pile JAX est conçue pour résoudre ce problème en offrant un continuum d'abstraction (voir la figure 2), des optimisations automatisées de haut niveau du compilateur XLA au contrôle manuel et précis de la bibliothèque de création de noyaux Pallas.
Figure 2 : Continuum d'abstraction JAX
Pile JAX AI de base
La pile d'IA JAX de base se compose de cinq bibliothèques clés qui fournissent les bases du développement de modèles :
JAX : une base pour la transformation de programmes composables et hautes performances
JAX est une bibliothèque Python pour le calcul de tableaux et la transformation de programmes orientés accélérateur. Elle est conçue pour le calcul numérique hautes performances et le machine learning à grande échelle. Avec son modèle de programmation fonctionnelle et son API de type NumPy, JAX fournit une base solide pour les bibliothèques de niveau supérieur.
Grâce à sa conception axée sur le compilateur, JAX favorise intrinsèquement l'évolutivité en tirant parti de XLA (voir la section XLA) pour une analyse, une optimisation et un ciblage matériel agressifs et complets. L'accent mis par JAX sur la programmation fonctionnelle (par exemple, les fonctions pures) rend ses transformations de programme de base plus faciles à gérer et, surtout, composables.
Ces transformations de base peuvent être combinées pour obtenir des performances élevées et une mise à l'échelle des charges de travail en fonction de la taille du modèle, de la taille du cluster et des types de matériel :
- jit : compilation à la volée des fonctions Python en exécutables XLA optimisés et fusionnés.
- grad : différenciation automatique, compatible avec les modes forward et reverse, ainsi qu'avec les dérivées d'ordre supérieur.
- vmap : vectorisation automatique, permettant le traitement par lot et le parallélisme des données sans modifier la logique de la fonction.
- pmap / shard_map : parallélisation automatique sur plusieurs appareils (par exemple, les cœurs de TPU), qui constitue la base de l'entraînement distribué.
L'intégration fluide avec le modèle GSPMD (General-purpose SPMD) de XLA permet à JAX de paralléliser automatiquement les calculs sur de grands pods TPU avec un minimum de modifications de code. Dans la plupart des cas, la mise à l'échelle ne nécessite que des annotations de sharding de haut niveau.
Flax : création flexible de réseaux de neurones
Flax simplifie la création, le débogage et l'analyse des réseaux de neurones dans JAX en fournissant une approche intuitive et orientée objet pour la création de modèles. Bien que l'API fonctionnelle de JAX soit puissante, elle offre une abstraction basée sur les couches plus familière aux développeurs habitués aux frameworks tels que PyTorch, sans aucune perte de performances.
Cette conception simplifie la modification ou la combinaison des composants du modèle entraîné.
Les techniques telles que LoRA et la quantification nécessitent des définitions de modèle manipulables, que l'API NNX de Flax fournit via une interface Pythonique. NNX encapsule l'état du modèle, réduit la charge cognitive de l'utilisateur et permet la traversée et la modification programmatiques de la hiérarchie du modèle.
Points forts :
- API orientée objet intuitive : simplifie la construction de modèles et permet des cas d'utilisation avancés tels que le remplacement de sous-modules et l'initialisation partielle.
- Cohérence avec Core JAX : Flax fournit des transformations liftées entièrement compatibles avec le paradigme fonctionnel de JAX, offrant toutes les performances de JAX avec une convivialité améliorée pour les développeurs.
Optax : stratégies composables de traitement et d'optimisation des gradients
Optax est une bibliothèque de traitement et d'optimisation des gradients pour JAX. Il est conçu pour fournir aux créateurs de modèles des blocs de construction qui peuvent être recombinés de manière personnalisée afin d'entraîner des modèles de deep learning, entre autres applications. Elle s'appuie sur les capacités de la bibliothèque JAX principale pour fournir une bibliothèque de fonctions de perte et d'optimiseur hautes performances et bien testée, ainsi que des techniques associées qui peuvent être utilisées pour entraîner des modèles de ML.
Motivation
Le calcul et la minimisation des pertes sont au cœur de ce qui permet l'entraînement des modèles de ML. Grâce à sa prise en charge de la différenciation automatique, la bibliothèque JAX principale fournit les capacités numériques nécessaires à l'entraînement des modèles, mais elle ne fournit pas d'implémentations standards des optimiseurs populaires (par exemple, RMSProp ou Adam) ni des pertes (par exemple, CrossEntropy ou MSE). Bien que vous puissiez implémenter ces fonctions (et certains développeurs avancés choisiront de le faire), un bug dans l'implémentation d'un optimiseur entraînerait des problèmes de qualité du modèle difficiles à diagnostiquer. Au lieu de demander à l'utilisateur d'implémenter ces éléments critiques, Optax fournit des implémentations de ces algorithmes qui sont testées pour leur exactitude et leurs performances.
Le domaine de la théorie de l'optimisation relève entièrement de la recherche. Toutefois, son rôle central dans l'entraînement en fait également une partie indispensable de l'entraînement des modèles de ML de production. Une bibliothèque qui remplit ce rôle doit être suffisamment flexible pour s'adapter aux itérations de recherche rapides, mais aussi suffisamment robuste et performante pour être fiable pour l'entraînement des modèles de production. Il doit également fournir des implémentations bien testées d'algorithmes de pointe qui correspondent aux équations standards. La bibliothèque Optax, grâce à son architecture modulaire et composable, et à l'accent mis sur un code correct et lisible, est conçue pour atteindre cet objectif.
Conception
Optax est conçu pour accélérer la recherche et la transition de la recherche à la production en fournissant des implémentations lisibles, bien testées et efficaces des algorithmes de base. Optax a des utilisations au-delà du contexte du deep learning, mais dans ce contexte, il peut être considéré comme une collection de fonctions de perte, d'algorithmes d'optimisation et de transformations de gradient bien connus, implémentés de manière purement fonctionnelle conformément à la philosophie JAX. La collection de fonctions de perte et d'optimiseurs connus permet aux utilisateurs de se lancer facilement et en toute confiance.
L'approche modulaire adoptée par Optax vous permet d'enchaîner plusieurs optimiseurs, suivis d'autres transformations courantes (par exemple, le clipping de gradient) et de les encapsuler à l'aide de techniques courantes telles que MultiStep ou Lookahead pour obtenir des stratégies d'optimisation puissantes avec quelques lignes de code. L'interface flexible vous permet de rechercher de nouveaux algorithmes d'optimisation et d'utiliser de puissantes techniques d'optimisation du second ordre comme Shampoo ou Muon.
# Optax implementation of a RMSProp optimizer with a custom learning rate
# schedule, gradient clipping and gradient accumulation.
optimizer = optax.chain(
optax.clip_by_global_norm(GRADIENT_CLIP_VALUE),
optax.rmsprop(learning_rate=optax.cosine_decay_schedule(init_value=lr,decay_steps=decay)),
optax.apply_every(k=ACCUMULATION_STEPS)
)
# The same thing, in PyTorch
optimizer = optim.RMSprop(model_params, lr=LEARNING_RATE)
scheduler = optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=TOTAL_STEPS)
for i, (inputs, targets) in enumerate(data_loader):
# ... Training loop body ...
if (i + 1) % ACCUMULATION_STEPS == 0:
torch.nn.utils.clip_grad_norm_(model.parameters(), GRADIENT_CLIP_VALUE)
optimizer.step()
scheduler.step()
optimizer.zero_grad()
L'extrait de code précédent montre comment configurer un optimiseur avec un taux d'apprentissage personnalisé, un écrêtement du gradient et une accumulation du gradient.
Points forts
- Bibliothèque robuste : fournit une bibliothèque complète de pertes, d'optimiseurs et d'algorithmes en mettant l'accent sur l'exactitude et la lisibilité.
- Transformations modulaires et chaînables : cette API flexible vous permet de créer des stratégies d'optimisation puissantes et complexes de manière déclarative, sans modifier la boucle d'entraînement.
- Fonctionnel et évolutif : les implémentations fonctionnelles pures s'intègrent parfaitement aux mécanismes de parallélisation de JAX (par exemple, pmap), ce qui vous permet d'utiliser le même code pour passer d'un seul hôte à de grands clusters.
Orbax / TensorStore : point de contrôle distribué à grande échelle
Orbax est une bibliothèque de points de contrôle pour JAX conçue pour toutes les échelles, de l'entraînement sur un seul appareil à l'entraînement distribué à grande échelle. Il vise à unifier les implémentations fragmentées de la création de points de contrôle et à fournir des fonctionnalités de performances critiques, telles que la création de points de contrôle asynchrone et à plusieurs niveaux, à un public plus large. Orbax permet la résilience requise pour les tâches d'entraînement massives et fournit un format flexible pour la publication de points de contrôle.
Contrairement aux systèmes de point de contrôle et de restauration généralisés qui prennent un instantané de l'état du système entier, le point de contrôle ML avec Orbax ne conserve sélectivement que les informations essentielles pour reprendre l'entraînement : les pondérations du modèle, l'état de l'optimiseur et l'état du chargeur de données. Cette approche ciblée minimise les temps d'arrêt de l'accélérateur. Orbax y parvient en chevauchant les opérations d'E/S avec le calcul, une fonctionnalité essentielle pour les charges de travail volumineuses. Le temps d'inactivité des accélérateurs temporels est réduit à la durée du transfert de données vers l'appareil hôte, qui peut être encore chevauché avec l'étape d'entraînement suivante, ce qui rend la création de points de contrôle presque sans frais du point de vue des performances.
Orbax utilise TensorStore pour lire et écrire des données de tableaux de manière efficace et parallèle. L'API Orbax résume cette complexité en offrant une interface conviviale pour la gestion des PyTrees, qui sont la représentation standard des modèles dans JAX.
Points forts :
- Adoption généralisée : avec des millions de téléchargements mensuels, Orbax sert de support commun pour le partage d'artefacts de ML.
- Simplifie les complexités : Orbax élimine les complexités du checkpointing distribué, y compris l'enregistrement asynchrone, l'atomicité et les détails du système de fichiers.
- Flexibilité : Orbax propose des API pour les cas d'utilisation courants, mais vous permet également de personnaliser votre workflow pour répondre à des exigences spécifiques.
- Performant et évolutif : des fonctionnalités telles que la création de points de contrôle asynchrones, un format de stockage efficace (OCDBT) et des stratégies de chargement de données intelligentes garantissent qu'Orbax s'adapte aux entraînements impliquant des dizaines de milliers de nœuds.
Grain : pipelines de données d'entrée déterministes et évolutifs
Grain est une bibliothèque Python permettant de lire et de traiter des données pour entraîner et évaluer des modèles JAX. Il est flexible, rapide et déterministe, et prend en charge des fonctionnalités avancées telles que la création de points de contrôle, qui sont essentielles pour entraîner correctement de grandes charges de travail. Il est compatible avec les formats de données et les backends de stockage courants. Il fournit également une API flexible permettant d'étendre la compatibilité aux formats et backends spécifiques aux utilisateurs qui ne sont pas compatibles en mode natif. Bien que Grain soit principalement conçu pour fonctionner avec JAX, il est indépendant du framework, ne nécessite pas l'exécution de JAX et peut également être utilisé avec d'autres frameworks.
Motivation
Les pipelines de données constituent un élément essentiel de l'infrastructure d'entraînement. Ils doivent être suffisamment flexibles pour que les transformations courantes puissent être exprimées efficacement, et suffisamment performants pour que les accélérateurs soient occupés à tout moment. Ils doivent également pouvoir s'adapter à plusieurs formats de stockage et backends. En raison de leurs temps de traitement plus longs, l'entraînement de grands modèles à grande échelle impose des exigences supplémentaires au pipeline de données, au-delà de celles requises par les charges de travail d'entraînement régulières. Ces exigences sont principalement axées sur le déterminisme et la reproductibilité2. La bibliothèque Grain est conçue avec une architecture flexible qui répond à ces besoins.
2 Dans la section 5.1 de l'article sur PaLM, les auteurs indiquent avoir observé de très fortes hausses de perte malgré l'activation de la limitation du gradient. La solution consistait à supprimer les lots de données incriminés et à redémarrer l'entraînement à partir d'un point de contrôle avant le pic de perte. Cela n'est possible qu'avec une configuration d'entraînement entièrement déterministe et reproductible.
Conception
Au plus haut niveau, il existe deux façons de structurer un pipeline d'entrée : en tant que cluster distinct de nœuds de calcul de données ou en colocalisant les nœuds de calcul de données sur les hôtes qui pilotent les accélérateurs. Grain choisit cette dernière option pour diverses raisons.
Les accélérateurs sont combinés à des hôtes puissants qui sont généralement inactifs pendant les étapes d'entraînement, ce qui en fait un choix naturel pour exécuter le pipeline de données d'entrée. Cette implémentation présente d'autres avantages. Elle simplifie votre vue du partitionnement des données en fournissant une vue cohérente du partitionnement entre l'entrée et le calcul. On pourrait soutenir que le fait de placer le nœud de calcul de données sur l'hôte de l'accélérateur risque de saturer le processeur de l'hôte. Toutefois, cela n'empêche pas de décharger les transformations gourmandes en calcul sur un autre cluster à l'aide de RPC3.
Du côté de l'API, avec une implémentation Python pure qui prend en charge plusieurs processus et une API flexible, Grain vous permet d'implémenter des transformations de données arbitrairement complexes en composant des étapes de pipeline en fonction de paradigmes de transformation bien compris.
D'emblée, Grain est compatible avec les formats de données à accès aléatoire efficaces tels que ArrayRecord et Bagz, ainsi qu'avec d'autres formats de données courants tels que Parquet et TFDS. Grain permet de lire les données à partir de systèmes de fichiers locaux et de Cloud Storage par défaut. En plus de prendre en charge les formats et les backends de stockage populaires, une abstraction propre de la couche de stockage vous permet d'ajouter la prise en charge de vos sources de données existantes ou de les encapsuler pour les rendre compatibles avec la bibliothèque Grain.
3 C'est ainsi que les pipelines de données multimodales doivent fonctionner : les tokenizers d'images et audio, par exemple, sont eux-mêmes des modèles qui s'exécutent dans leurs propres clusters sur leurs propres accélérateurs. Les pipelines d'entrée effectuent des appels RPC pour convertir les exemples de données en flux de jetons.
Points forts
- Alimentation déterministe des données : la colocation du nœud de calcul des données avec l'accélérateur et son couplage avec un brassage global stable et des itérateurs vérifiables permettent de vérifier l'état du modèle et du pipeline de données ensemble dans un instantané cohérent à l'aide d'Orbax, ce qui améliore le déterminisme du processus d'entraînement.
- API flexibles pour des transformations de données puissantes : une API transformations flexible et purement Python vous permet d'effectuer des transformations de données étendues dans le pipeline de traitement des entrées.
- Prise en charge extensible de plusieurs formats et backends : une API sources de données extensible est compatible avec les formats et les backends de stockage courants, et vous permet d'ajouter la prise en charge de nouveaux formats et backends.
- Interface de débogage puissante : les outils de visualisation des pipelines de données et un mode débogage vous permettent d'inspecter, de déboguer et d'optimiser les performances de vos pipelines de données.
Pile d'IA JAX étendue
Au-delà de la pile principale, un riche écosystème de bibliothèques spécialisées fournit l'infrastructure, les outils avancés et les solutions de couche application nécessaires au développement de ML de bout en bout.
Infrastructure de base : compilateurs et environnements d'exécution
XLA : le moteur indépendant du matériel et axé sur le compilateur
Motivation
XLA (Accelerated Linear Algebra) est le compilateur spécifique à un domaine de Google, qui est bien intégré à JAX et compatible avec les appareils TPU, CPU et GPU. XLA a été conçu pour être un générateur de code indépendant du matériel, ciblant les TPU, les GPU et les CPU.
La conception "compiler-first" du compilateur XLA est un choix architectural fondamental qui crée un avantage durable dans un paysage de recherche en évolution rapide. En revanche, l'approche axée sur le noyau qui prévaut dans d'autres écosystèmes repose sur des bibliothèques optimisées manuellement pour les performances. Bien que cette approche soit très efficace pour les architectures de modèles stables et bien établies, elle crée un goulot d'étranglement pour l'innovation. Lorsque de nouvelles recherches introduisent des architectures inédites, l'écosystème doit attendre que de nouveaux noyaux soient écrits et optimisés. Cependant, notre conception axée sur le compilateur peut souvent être généralisée à de nouveaux modèles, ce qui permet de bénéficier d'un chemin de haute performance pour la recherche de pointe dès le premier jour.
Conception
XLA fonctionne en compilant à la volée les graphiques de calcul que JAX génère lors de son processus de traçage (par exemple, lorsqu'une fonction est décorée avec @jax.jit).
Cette compilation suit un pipeline en plusieurs étapes :
- Graphique de calcul JAX
- Optimiseur de haut niveau (HLO)
- Optimiseur de bas niveau (LLO)
- Code matériel
- Du graphique JAX à HLO : le graphique de calcul JAX est converti en représentation HLO de XLA. À ce niveau élevé, des optimisations puissantes et indépendantes du matériel, telles que la fusion d'opérateurs et la gestion efficace de la mémoire, sont appliquées. Le dialecte StableHLO sert d'interface durable et versionnée pour cette étape.
- De HLO à LLO : après les optimisations de haut niveau, les backends spécifiques au matériel prennent le relais, en abaissant la représentation HLO en LLO orienté machine.
- Du LLO au code matériel : le LLO est enfin compilé en code machine très efficace. Pour les TPU, ce code est regroupé sous forme de paquets Very Long Instruction Word (VLIW) qui sont envoyés directement au matériel.
Pour la mise à l'échelle, la conception de XLA est axée sur le parallélisme. Il utilise des algorithmes pour exploiter au maximum les unités de multiplication matricielle (MXU) d'une puce. Entre les puces, XLA utilise SPMD (Single Program Multiple Data), une technique de parallélisation basée sur le compilateur qui utilise un seul programme sur tous les appareils. Ce modèle puissant est exposé via les API JAX, ce qui vous permet de gérer le parallélisme des données, des modèles ou des pipelines avec des annotations de partitionnement de haut niveau.
Pour les modèles de parallélisme plus complexes, le MPMD (Multiple Program Multiple Data) est également possible. Des bibliothèques comme PartIR:MPMD permettent aux utilisateurs de JAX de fournir également des annotations MPMD.
Points forts
- Compilation : la compilation juste-à-temps du graphique de calcul permet d'optimiser la disposition de la mémoire, l'allocation de mémoire tampon et la gestion de la mémoire. Les alternatives, telles que les méthodologies basées sur le noyau, font peser cette charge sur le développeur. Dans la plupart des cas, XLA peut atteindre d'excellentes performances sans compromettre la vélocité des développeurs.
- Parallélisme : XLA implémente plusieurs formes de parallélisme avec SPMD, qui sont exposées au niveau JAX. Cela vous permet d'exprimer des stratégies de partitionnement, ce qui permet d'expérimenter et de mettre à l'échelle des modèles sur des milliers de puces.
Pathways : un environnement d'exécution unifié pour le calcul distribué à grande échelle
Pathways propose des abstractions pour l'entraînement et l'inférence distribués avec tolérance aux pannes et récupération intégrées, ce qui permet aux chercheurs en ML de coder comme s'ils utilisaient une seule machine puissante.
Motivation
Pour pouvoir entraîner et déployer des modèles volumineux, il faut des centaines, voire des milliers de puces. Ces puces sont réparties sur de nombreux racks et machines hôtes. Un job d'entraînement est un programme synchrone à grande échelle qui nécessite que toutes ces puces et leurs hôtes respectifs fonctionnent de concert sur des calculs XLA qui ont été parallélisés (fragmentés). Dans le cas des grands modèles linguistiques, qui peuvent nécessiter plus de dizaines de milliers de puces, ce service doit être capable de s'étendre sur plusieurs pods dans une structure de centre de données, en plus d'utiliser des structures d'interconnexion entre puces (ICI) et sur puce (OCI) dans un pod.
Conception
ML Pathways est le système que nous utilisons pour coordonner les calculs distribués sur les hôtes et les puces TPU. Il est conçu pour l'évolutivité et l'efficacité sur des centaines de milliers d'accélérateurs. Pour l'entraînement à grande échelle, il fournit un client Python unique pour plusieurs jobs de pod, l'intégration Megascale XLA, un service de compilation et Python à distance. Il est également compatible avec le parallélisme et la tolérance à la préemption multislices, ce qui permet une récupération automatique en cas de préemption des ressources.
Pathways intègre des collectifs inter-hôtes optimisés qui permettent aux graphiques de calcul XLA de s'étendre au-delà d'un seul pod TPU. Il étend la compatibilité de XLA avec le parallélisme des données, des modèles et des pipelines pour fonctionner au-delà des limites des tranches TPU à l'aide du réseau de centre de données (DCN) en intégrant un environnement d'exécution distribué qui gère la communication DCN avec les primitives de communication XLA.
Points forts
L'architecture à contrôleur unique, intégrée à JAX, est une abstraction clé. Il permet aux chercheurs d'explorer diverses stratégies de sharding et de parallélisme pour l'entraînement et le déploiement, tout en s'adaptant facilement à des dizaines de milliers de puces.
Développement avancé : performances, données et efficacité
Pallas : écrire des noyaux personnalisés hautes performances dans JAX
Bien que JAX soit axé sur le compilateur, il existe des situations où vous pouvez souhaiter un contrôle précis du matériel pour obtenir des performances maximales. Pallas est une extension de JAX qui permet d'écrire des noyaux personnalisés pour les GPU et les TPU. Il vise à fournir un contrôle précis sur le code généré, combiné à l'ergonomie de haut niveau du traçage JAX et de l'API jax.numpy.
Pallas expose un modèle de parallélisme basé sur une grille, dans lequel une fonction de noyau définie par l'utilisateur est lancée sur une grille multidimensionnelle de groupes de travail parallèles. Il permet une gestion explicite de la hiérarchie de mémoire en vous permettant de définir la manière dont les Tensors sont segmentés et transférés entre une mémoire plus lente et plus grande (par exemple, HBM) et une mémoire sur puce plus rapide et plus petite (par exemple, VMEM sur TPU, mémoire partagée sur GPU), en utilisant des cartes d'index pour associer les emplacements de grille à des blocs de données spécifiques. Pallas peut réduire la même définition de noyau pour s'exécuter efficacement sur les TPU de Google et sur divers GPU en compilant les noyaux dans une représentation intermédiaire adaptée à l'architecture cible : Mosaic pour les TPU ou en utilisant des technologies telles que Triton pour les GPU. Avec Pallas, vous pouvez écrire des noyaux à hautes performances qui spécialisent des blocs tels que l'attention pour obtenir les meilleures performances de modèle sur le matériel cible sans avoir à vous appuyer sur des kits d'outils spécifiques au fournisseur.
Tokamax : une bibliothèque organisée de kernels de pointe
Si Pallas est un outil pour la création de noyaux, Tokamax est une bibliothèque de noyaux d'accélérateur personnalisés de pointe qui sont compatibles avec les TPU et les GPU. Tokamax s'appuie sur JAX et Pallas, et vous permet d'exploiter tout le potentiel de votre matériel. Il fournit également des outils pour créer et régler automatiquement des kernels personnalisés.
Motivation
JAX, qui trouve ses racines dans XLA, est un framework axé sur le compilateur. Toutefois, il existe un ensemble limité de cas où vous devrez peut-être prendre le contrôle direct du matériel pour atteindre des performances maximales4. Les kernels personnalisés sont essentiels pour obtenir les meilleures performances des ressources d'accélérateur de ML coûteuses telles que les TPU et les GPU. Bien qu'elles soient largement utilisées pour permettre l'exécution performante d'opérateurs clés tels que l'attention, leur implémentation nécessite une compréhension approfondie du modèle et de l'architecture matérielle cible. Tokamax fournit une source faisant autorité de kernels sélectionnés, bien testés et hautes performances, ainsi qu'une infrastructure partagée robuste pour leur développement, leur maintenance et la gestion de leur cycle de vie. Une telle bibliothèque peut également servir d'implémentation de référence sur laquelle vous pouvez vous appuyer et que vous pouvez personnaliser selon vos besoins. Cela vous permet de vous concentrer sur la modélisation sans vous soucier de l'infrastructure.
4 Il s'agit d'un paradigme bien établi qui a déjà été utilisé dans le monde des processeurs, où le code compilé constitue la majeure partie du programme, les développeurs utilisant des intrinsèques ou de l'assembly en ligne pour optimiser les sections critiques en termes de performances.
Conception
Pour n'importe quel noyau, Tokamax fournit une API commune qui peut être soutenue par plusieurs implémentations. Par exemple, les noyaux TPU peuvent être implémentés soit par réduction XLA standard, soit explicitement avec Pallas/Mosaic-TPU. Les noyaux de GPU peuvent être implémentés par l'abaissement XLA standard, avec Mosaic-GPU ou Triton. Par défaut, l'API Tokamax choisit l'implémentation la plus connue pour une configuration donnée, déterminée par les résultats mis en cache des exécutions périodiques d'autotuning et de benchmarking. Toutefois, vous pouvez choisir des implémentations spécifiques si nécessaire. De nouvelles implémentations pourront être ajoutées au fil du temps pour mieux exploiter des fonctionnalités spécifiques dans les nouvelles générations de matériel et améliorer encore les performances.
Au-delà des kernels eux-mêmes, l'infrastructure sous-jacente qui vous permet d'écrire des kernels personnalisés est un élément clé de la bibliothèque Tokamax. Par exemple, l'infrastructure d'optimisation automatique vous permet de définir un ensemble de paramètres configurables (par exemple, les tailles de blocs) sur lesquels Tokamax peut effectuer un balayage exhaustif afin de déterminer et de mettre en cache les meilleurs paramètres optimisés. Les régressions nocturnes vous protègent contre les problèmes de performances et numériques inattendus causés par des modifications apportées à l'infrastructure du compilateur sous-jacente ou à d'autres dépendances.
Points forts
- Expérience développeur fluide : une bibliothèque unifiée et organisée fournit des implémentations connues et performantes des noyaux clés, avec des expressions claires des générations de matériel compatibles et des performances attendues, à la fois de manière programmatique et dans la documentation. Cela permet de minimiser la fragmentation et le churn.
- Flexibilité et gestion du cycle de vie : vous pouvez choisir différentes implémentations, et même les modifier au fil du temps si nécessaire. Par exemple, si le compilateur XLA améliore la prise en charge de certaines opérations qui ne nécessitent plus de noyaux personnalisés, il existe un chemin de dépréciation et de migration.
- Extensibilité : vous pouvez implémenter vos propres kernels tout en tirant parti d'une infrastructure partagée bien prise en charge, ce qui vous permet de vous concentrer sur les fonctionnalités et les optimisations à valeur ajoutée. Les implémentations standards clairement rédigées servent de point de départ aux utilisateurs pour apprendre et développer.
Qwix : quantification complète et non intrusive
Qwix est une bibliothèque de quantification complète pour la pile d'IA JAX. Elle est compatible avec les LLM et d'autres types de modèles à toutes les étapes, y compris l'entraînement (Quantization Aware Training (QAT), Quantization Technique (QT), Quantized Low-Rank Adaptation (QLoRA)) et l'inférence Post Training Quantization (PTQ), ciblant à la fois les runtimes XLA et sur l'appareil.
Motivation
Les bibliothèques de quantification existantes, en particulier dans l'écosystème PyTorch, ont souvent des objectifs limités (par exemple, uniquement PTQ ou uniquement QLoRA). Ce paysage fragmenté vous oblige à changer d'outil, ce qui nuit à l'utilisation cohérente du code et à la correspondance numérique précise entre l'entraînement et l'inférence. De plus, de nombreuses solutions nécessitent des modifications importantes du modèle, ce qui couple étroitement la logique du modèle à la logique de quantification.
Conception
La philosophie de conception de Qwix met l'accent sur une solution complète et, surtout, sur une intégration de modèle non intrusive. Son architecture hiérarchique et extensible repose sur des API fonctionnelles réutilisables.
Cette intégration non intrusive est obtenue grâce à un mécanisme d'interception méticuleusement conçu qui redirige les fonctions JAX vers leurs homologues quantifiés. Cela vous permet d'intégrer vos modèles sans aucune modification, en dissociant complètement le code de quantification des définitions de modèle.
L'exemple suivant montre comment appliquer la quantification w4a4 (poids de 4 bits, activation de 4 bits) aux couches MLP d'un LLM et la quantification w8 (poids de 8 bits) à l'intégrateur. Pour modifier la recette de quantification, il vous suffit de mettre à jour la liste des règles.
fp_model = ModelWithoutQuantization(...)
rules = [
qwix.QuantizationRule(
module_path=r'embedder',
weight_qtype='int8',
),
qwix.QuantizationRule(
module_path=r'layers_\d+/mlp',
weight_qtype='int4',
act_qtype='int4',
tile_size=128,
weight_calibration_method='rms,7',
),
]
quantized_model = qwix.quantize_model(fp_model, qwix.PtqProvider(rules))
Points forts
- Solution complète : Qwix est largement applicable à de nombreux scénarios de quantification, ce qui garantit une utilisation cohérente du code entre l'entraînement et l'inférence.
- Intégration de modèles non intrusifs : comme le montre l'exemple, vous pouvez intégrer des modèles avec une seule ligne de code. Vous pouvez ainsi utiliser des hyperparamètres sur de nombreux schémas de quantification pour trouver le meilleur compromis entre qualité et performances.
- Fédération avec d'autres bibliothèques : Qwix s'intègre parfaitement à la pile d'IA JAX. Par exemple, Tokamax s'adapte automatiquement pour utiliser des versions quantifiées des noyaux, sans code utilisateur supplémentaire, lorsque le modèle est quantifié avec Qwix.
- Adapté à la recherche : les API de base et l'architecture extensible de Qwix permettent aux chercheurs d'explorer de nouveaux algorithmes et de faciliter les comparaisons simples grâce à des outils d'évaluation et de benchmarking intégrés.
La couche application : entraînement et alignement
Entraînement de modèles de fondation : MaxText et MaxDiffusion
MaxText et MaxDiffusion sont les principaux frameworks d'entraînement de LLM et de modèles de diffusion de Google, respectivement. Ces dépôts contiennent une sélection d'implémentations hautement optimisées de modèles Open Source populaires. Elles ont une double utilité : elles servent à la fois de base de code pour l'entraînement de modèles prêts à l'emploi et de référence sur laquelle les créateurs de modèles de fondation peuvent s'appuyer.
Motivation
L'intérêt pour l'entraînement des modèles d'IA générative croît rapidement dans le secteur. La popularité des modèles ouverts a accéléré cette tendance en fournissant des architectures éprouvées. L'entraînement et l'adaptation de ces modèles nécessitent des performances élevées, de l'efficacité, une évolutivité pour un grand nombre de puces et un code clair et compréhensible. MaxText et MaxDiffusion sont des solutions complètes qui peuvent être utilisées sur des TPU ou des GPU et qui sont conçues pour répondre à ces besoins.
Conception
MaxText et MaxDiffusion sont des bases de code de modèles de base conçues pour être lisibles et performantes. Ils sont structurés avec des composants réutilisables et bien testés : des définitions de modèles qui utilisent des kernels personnalisés (comme Tokamax) pour des performances maximales, un harnais d'entraînement pour l'orchestration et la surveillance, et un système de configuration puissant qui vous permet de contrôler des détails tels que le partitionnement et la quantification (à l'aide de Qwix) grâce à une interface intuitive. Des fonctionnalités de fiabilité avancées, comme le checkpointing multicouche, sont intégrées pour garantir un bon débit soutenu.
MaxText et MaxDiffusion utilisent les meilleures bibliothèques JAX (Qwix, Tunix, Orbax et Optax) pour fournir des fonctionnalités de base. Ces bibliothèques fournissent une infrastructure robuste et évolutive, ce qui réduit les frais généraux de développement et vous permet de vous concentrer sur la tâche de modélisation. Pour l'inférence, le code du modèle est partagé pour permettre une mise en service efficace et évolutive.
Points forts
- Performances dès la conception : avec une infrastructure d'entraînement configurée pour un "bon débit" (débit utile) élevé et des implémentations de modèles optimisées pour une utilisation élevée des FLOPS (opérations en virgule flottante par seconde) du modèle, MaxText et MaxDiffusion offrent des performances élevées à grande échelle dès le départ.
- Conçus pour l'évolutivité : en tirant parti de la puissance de la pile d'IA JAX (en particulier Pathways), ces frameworks vous permettent de passer facilement de dizaines à des dizaines de milliers de puces.
- Base solide pour les créateurs de modèles de fondation : les implémentations lisibles et de haute qualité servent de point de départ solide aux développeurs, qui peuvent les utiliser comme solution de bout en bout ou comme implémentation de référence pour leurs propres personnalisations.
Post-entraînement et alignement : le framework Tunix
Tunix propose des algorithmes d'apprentissage par renforcement (RL) open source de pointe, ainsi qu'un framework et une infrastructure robustes, offrant aux développeurs un moyen simple d'expérimenter des techniques de post-entraînement de LLM, y compris le fine-tuning supervisé (SFT) et l'alignement à l'aide de JAX et de TPU.
Motivation
L'entraînement post-apprentissage est une étape essentielle pour exploiter tout le potentiel des LLM. L'étape d'apprentissage par renforcement est particulièrement cruciale pour développer les capacités d'alignement et de raisonnement. Le développement Open Source dans ce domaine est presque exclusivement basé sur PyTorch et les GPU, ce qui laisse un vide fondamental pour les solutions JAX et TPU. Tunix (Tune-in-JAX) est une bibliothèque hautes performances native à JAX conçue pour combler cette lacune.
Conception
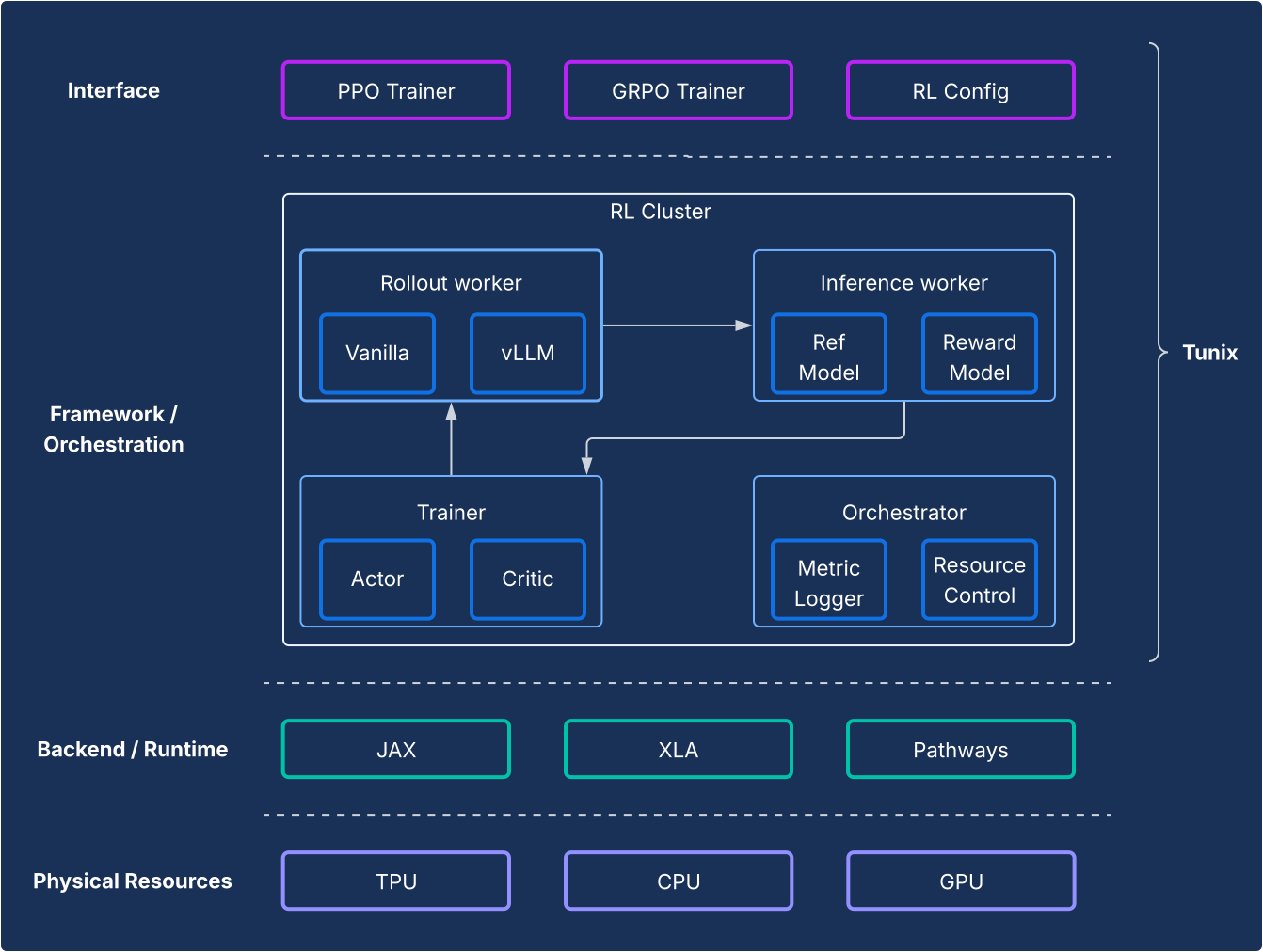
Du point de vue du framework, Tunix permet une configuration de pointe qui sépare clairement les algorithmes de RL de l'infrastructure. Il offre une API légère de type client qui masque la complexité de l'infrastructure RL, ce qui vous permet de développer de nouveaux algorithmes. Tunix fournit des solutions prêtes à l'emploi pour les algorithmes populaires, y compris l'optimisation de la stratégie proximale (PPO), l'optimisation directe des préférences (DPO) et d'autres.
Au niveau de l'infrastructure, Tunix est intégré à Pathways, ce qui permet une architecture à contrôleur unique qui rend l'entraînement RL multinœud accessible. Du côté de l'entraînement, Tunix est compatible en mode natif avec l'entraînement efficace des paramètres (par exemple, LoRA) et utilise le partitionnement JAX et XLA (General and Scalable Parallelization for ML Computation Graph (GSPMD)) pour générer un graphique de calcul performant. Il est compatible avec les modèles Open Source populaires comme Gemma et Llama.
Points forts
- Simplicité : elle fournit une API de haut niveau de type client qui élimine la complexité de l'infrastructure distribuée sous-jacente.
- Efficacité des développeurs : Tunix accélère le cycle de vie de la R&D grâce à des algorithmes et des "recettes" intégrés, ce qui vous permet d'obtenir un modèle fonctionnel et d'itérer rapidement.
- Performances et évolutivité : Tunix permet de créer une infrastructure d'entraînement très efficace et évolutive horizontalement en utilisant Pathways comme contrôleur unique sur le backend.
La couche application : production et inférence
Le chemin de la recherche à la production a toujours été un défi pour l'adoption de JAX. La pile d'IA JAX fournit désormais une histoire de production mature à deux volets qui offre à la fois la compatibilité de l'écosystème et les performances JAX.
Inférence LLM hautes performances : la solution vLLM
vLLM-TPU est la pile d'inférence hautes performances de Google conçue pour exécuter efficacement les grands modèles de langage (LLM) PyTorch et JAX sur les Cloud TPU. Pour ce faire, il intègre de manière native le framework vLLM Open Source populaire à l'écosystème JAX et TPU de Google.
Motivation
Le secteur évolue rapidement, avec une demande croissante pour des solutions d'inférence fluides, performantes et faciles à utiliser. Les développeurs sont souvent confrontés à des défis importants en raison d'outils complexes et incohérents, de performances médiocres et d'une compatibilité limitée des modèles. La pile vLLM résout ces problèmes en fournissant une plate-forme unifiée, performante et intuitive.
Conception
Cette solution étend le framework vLLM au lieu de le réinventer. vLLM-TPU est un moteur de diffusion LLM Open Source hautement optimisé, connu pour son débit élevé, obtenu grâce à des fonctionnalités clés telles que PagedAttention (qui gère les caches KV comme la mémoire virtuelle pour minimiser la fragmentation) et Continuous Batching (qui ajoute dynamiquement des requêtes au lot pour améliorer l'utilisation).
vLLM-TPU s'appuie sur cette base et développe des composants essentiels pour la gestion des requêtes, la planification et la gestion de la mémoire. Il introduit un backend basé sur JAX qui sert de pont, en traduisant le graphe de calcul et les opérations de mémoire de vLLM en code exécutable par TPU. Ce backend gère les interactions avec les appareils, l'exécution du modèle JAX et les spécificités de la gestion du cache KV sur le matériel TPU. Il intègre des optimisations spécifiques aux TPU, telles que des mécanismes d'attention efficaces (par exemple, en utilisant les noyaux JAX Pallas pour l'attention paginée irrégulière) et la quantification, le tout adapté à l'architecture TPU.
Points forts
- Aucun coût d'intégration/de désintégration pour les utilisateurs : les utilisateurs peuvent adopter cette solution sans difficulté. Du point de vue de l'expérience utilisateur, le traitement des requêtes d'inférence sur les TPU doit être identique à celui sur les GPU. L'interface de ligne de commande permettant de démarrer le serveur, d'accepter les invites et de renvoyer les résultats est partagée.
- Adoptez pleinement l'écosystème : cette approche utilise l'interface et l'expérience utilisateur de vLLM, et y contribue, en garantissant la compatibilité et la facilité d'utilisation.
- Fongibilité entre les TPU et les GPU : la solution fonctionne efficacement sur les TPU et les GPU, ce qui vous offre de la flexibilité.
- Rentabilité (meilleur rapport performances/coût) : optimise les performances pour fournir le meilleur rapport performances/coût pour les modèles populaires.
Diffusion JAX : sérialisation Orbax et moteur de diffusion Neptune
Pour les modèles autres que les LLM ou pour les utilisateurs qui souhaitent un pipeline entièrement natif à JAX, la bibliothèque de sérialisation Orbax et le système Neptune Serving Engine (NSE) fournissent une solution d'inférence de bout en bout et à hautes performances.
Motivation
Historiquement, les modèles JAX s'appuyaient souvent sur un chemin détourné vers la production, par exemple en étant encapsulés dans des graphiques TensorFlow et déployés à l'aide de TensorFlow Serving. Cette approche a introduit des limitations et des inefficacités importantes, obligeant les développeurs à interagir avec un écosystème distinct et ralentissant l'itération. Un système de diffusion JAX natif dédié est essentiel pour la durabilité, la réduction de la complexité et l'optimisation des performances.
Conception
Cette solution se compose de deux composants principaux, comme illustré dans le schéma suivant.
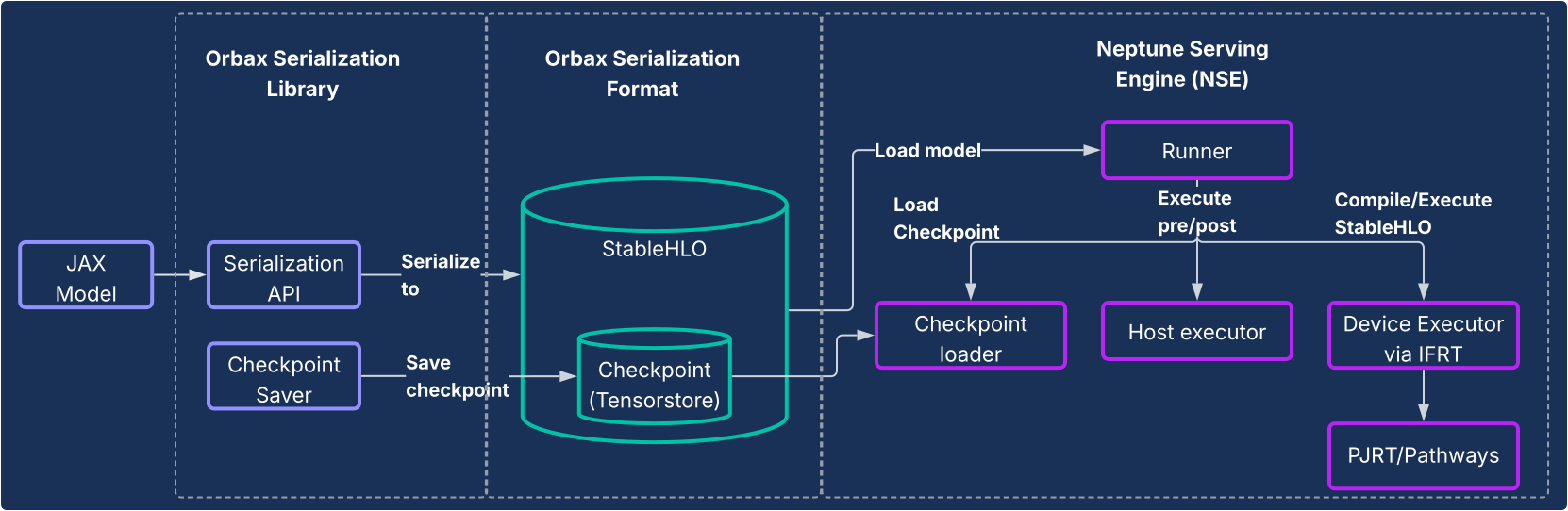
- Bibliothèque de sérialisation Orbax : fournit des API conviviales pour sérialiser les modèles JAX dans un nouveau format de sérialisation Orbax robuste. Ce format est optimisé pour le déploiement en production. Il représente directement les calculs du modèle JAX à l'aide de StableHLO, ce qui permet de représenter le graphique de calcul de manière native. Il utilise également TensorStore pour stocker les poids, ce qui permet de charger rapidement les points de contrôle pour le service.
- Neptune Serving Engine (NSE) : il s'agit du moteur d'inférence hautes performances et flexible associé (généralement déployé en tant que binaire C++) conçu pour exécuter nativement les modèles JAX au format Orbax. NSE offre des fonctionnalités essentielles à la production, telles que le chargement rapide de modèles, l'inférence simultanée à haut débit avec regroupement intégré, la prise en charge de plusieurs versions de modèles et l'inférence sur un ou plusieurs hôtes (à l'aide de PJRT et Pathways). Utilisez le moteur de diffusion Neptune pour :
- Modèles non LLM : il s'agit d'une solution à usage général idéale pour les charges de travail telles que les systèmes de recommandation, les modèles de diffusion et d'autres modèles d'IA.
- Petits LLM et service "one-shot" : il est conçu pour les modèles non autorégressifs ou les modèles plus petits qui sont servis de manière "unaire", où la sortie entière est générée en une seule passe sans avoir besoin d'une gestion d'état complexe comme un cache KV.
En bref, Neptune Serving Engine comble le vide pour la diffusion de la grande variété de modèles qui ne sont pas de grands modèles de langage autorégressifs, en fournissant une solution native TPU très performante pour l'écosystème ML plus large.
Points forts
- Mise en service native de JAX : la solution est conçue de manière native pour JAX, ce qui élimine les frais généraux inter-framework liés à la sérialisation et à la mise en service des modèles. Cela garantit un chargement rapide des modèles et une exécution optimisée sur les processeurs, les GPU et les TPU.
- Déploiement de production sans effort : les modèles sérialisés fournissent un chemin de déploiement hermétique qui n'est pas affecté par la dérive des dépendances Python et qui permet d'effectuer des vérifications de l'intégrité du modèle au moment de l'exécution. Cela permet de produire des modèles JAX de manière fluide et intuitive.
- Expérience de développement améliorée : en éliminant le besoin d'un enveloppement de framework complexe, cette solution réduit considérablement les dépendances et la complexité du système, ce qui accélère l'itération pour les développeurs JAX.
Analyse et profilage à l'échelle du système
XProf : profilage des performances approfondi et intégré au matériel
XProf est un outil de profilage et d'analyse des performances qui offre une visibilité approfondie sur différents aspects de l'exécution des charges de travail de ML, ce qui vous permet de déboguer et d'optimiser les performances. Il est profondément intégré aux écosystèmes JAX et TPU.
Motivation
D'une part, les charges de travail de ML sont de plus en plus complexes. D'un autre côté, les capacités matérielles spécialisées ciblant ces charges de travail explosent. Il est essentiel de les faire correspondre efficacement pour garantir des performances et une efficacité optimales, compte tenu des coûts énormes de l'infrastructure de ML. Cela nécessite une visibilité approfondie sur la charge de travail et le matériel, présentée de manière rapidement exploitable. XProf excelle dans ce domaine.
Conception
XProf se compose de deux éléments principaux : la collecte et l'analyse.
- Collection : XProf capture des informations provenant de diverses sources : annotations dans votre code JAX, modèles de coûts pour les opérations dans le compilateur XLA et fonctionnalités de profilage matériel spécialement conçues dans le TPU. Cette collecte peut être déclenchée de manière programmatique ou à la demande, ce qui génère un artefact d'événement complet.
- Analyse : XProf post-traite les données collectées et crée une suite de visualisations puissantes, accessibles avec un navigateur.
Points forts
La véritable puissance de XProf réside dans son intégration profonde à la pile complète, qui offre une étendue et une profondeur d'analyse qui constituent un avantage tangible de l'écosystème JAX/TPU co-conçu.
- Conçu en collaboration avec le TPU : XProf exploite des fonctionnalités matérielles spécialement conçues pour collecter des profils de manière fluide, ce qui permet de réduire la surcharge de collecte à moins de 1 %. Cela permet au profilage de devenir une partie légère et itérative du développement.
- Étendue et profondeur de l'analyse : XProf fournit une analyse approfondie sur plusieurs axes. Voici les outils dont vous disposez :
- Lecteur de traces : vue chronologique des opérations exécutées sur différentes unités matérielles (par exemple, les TensorCores).
- Profil des opérations HLO : décompose le temps total passé en différentes catégories d'opérations.
- Visionneuse de mémoire : affiche les détails des allocations de mémoire par différentes opérations pendant la période profilée.
- Analyse Roofline : vous aide à déterminer si des opérations spécifiques sont liées au calcul ou à la mémoire, et à quelle distance elles se trouvent des capacités maximales du matériel.
- Graph Viewer : fournit une vue complète du graphique HLO exécuté par le matériel.
Perspective comparative : la pile JAX/TPU comme choix intéressant
Le paysage moderne du machine learning offre de nombreuses chaînes d'outils excellentes et matures. La pile d'IA JAX offre un ensemble d'avantages uniques et intéressants pour les développeurs axés sur le ML hautes performances à grande échelle, qui découlent directement de sa conception modulaire et de sa co-conception matérielle approfondie.
Si de nombreux frameworks offrent un large éventail de fonctionnalités, la pile JAX AI fournit des différenciateurs spécifiques et puissants dans les domaines clés du cycle de vie du développement :
- Une expérience de développement plus simple et plus puissante : le paradigme de transformation de gradient chaînable d'Optax permet des stratégies d'optimisation plus puissantes et plus flexibles qui sont déclarées une seule fois, plutôt que gérées de manière impérative dans la boucle d'entraînement. Au niveau du système, l'interface de contrôleur unique plus simple de Pathways élimine la complexité de l'entraînement multislices, ce qui constitue une simplification importante pour les chercheurs.
- Conçue pour une résilience à l'échelle héroïque : la pile JAX est conçue pour l'entraînement à très grande échelle. Orbax fournit des fonctionnalités de "résilience d'entraînement à l'échelle héroïque", comme le point de contrôle d'urgence et à plusieurs niveaux. Cela est complété par Grain, qui offre une prise en charge complète de la reproductibilité avec des shuffles globaux déterministes et des chargeurs de données vérifiables. La possibilité de créer des points de contrôle atomiques pour l'état du pipeline de données (Grain) avec l'état du modèle (Orbax) est une fonctionnalité essentielle pour garantir la reproductibilité des tâches de longue durée.
- Un écosystème complet de bout en bout : la pile fournit une solution cohérente de bout en bout. Les développeurs peuvent utiliser MaxText comme référence SOTA pour l'entraînement, Tunix pour l'alignement et suivre un double chemin clair vers la production avec vLLM-TPU (pour la compatibilité vLLM) et NSE (pour les performances JAX).
Bien que de nombreuses piles soient similaires d'un point de vue logiciel de haut niveau, le facteur décisif se résume souvent à Performances/TCO, où la conception conjointe de JAX et des TPU offre un avantage distinct. Cet avantage en termes de performances/TCO est le résultat direct de l'intégration verticale entre le logiciel et le matériel TPU. La capacité du compilateur XLA à fusionner des opérations spécifiquement pour l'architecture TPU, ou du profileur XProf à utiliser des hooks matériels pour un profilage avec une surcharge inférieure à 1 %, sont des avantages concrets de cette intégration poussée.
Pour les organisations qui adoptent cette pile, la nature complète de la pile JAX AI minimise le coût de la migration. Pour les clients qui utilisent des architectures de modèles ouverts populaires, le passage d'autres frameworks à MaxText consiste souvent à configurer des fichiers de configuration. De plus, la capacité de la pile à ingérer des formats de points de contrôle populaires tels que safetensors permet de migrer les points de contrôle existants sans avoir besoin d'un réentraînement coûteux.
Le tableau suivant met en correspondance les composants fournis par la pile JAX AI et leurs équivalents dans d'autres frameworks ou bibliothèques.
| Fonction | JAX | Alternatives/équivalents dans d'autres frameworks5 |
| Compilateur / Environnement d'exécution | XLA | Inducteur, enthousiaste |
| Entraînement MultiPod | Parcours de formation | Stratégies Torch Lightning, Ray Train, Monarch (nouveau). |
| Framework de base | JAX | PyTorch |
| Création de modèles | Modèles Flax et Max* | torch.nn.*,
NVidia TransformerEngine, HuggingFace Transformers
|
| Optimiseurs et pertes | Optax | torch.optim.*, torch.nn.*Loss |
| Chargeurs de données | Grain | Ray Data, chargeurs de données HuggingFace |
| Points de contrôle | Orbax | Points de contrôle distribués PyTorch, Points de contrôle NeMo |
| Quantification | Qwix | TorchAO, bitsandbytes |
| Création de kernels et implémentations connues | Pallas / Tokamax | Triton/Helion, Liger-kernel, TransformerEngine |
| Post-entraînement / réglage | Tunix | VERL, NeMoRL |
| Profilage | XProf | Profileur PyTorch, systèmes NSight, NSight Compute |
| Entraînement de modèle de fondation | MaxText, MaxDiffusion | NeMo-Megatron, DeepSpeed, TorchTitan |
| Inférence LLM | vLLM | SGLang |
| Inférence non LLM | NSE | Triton Inference Server, RayServe |
5 Certains équivalents ne sont pas toujours de vraies comparaisons, car d'autres frameworks tracent les limites de l'API différemment de JAX. La liste des équivalents n'est pas exhaustive et de nouvelles bibliothèques apparaissent fréquemment.
Conclusion : une plate-forme durable et prête pour la production pour l'avenir de l'IA
Les données fournies dans le tableau précédent illustrent une conclusion évidente : ces piles ont leurs propres forces et faiblesses dans un petit nombre de domaines, mais sont globalement très similaires du point de vue logiciel. Les deux piles fournissent des solutions clés en main pour le pré-entraînement, l'adaptation post-entraînement et le déploiement des modèles de base.
La pile d'IA JAX offre une solution attrayante et robuste pour entraîner et déployer des modèles de ML à n'importe quelle échelle. Il s'appuie sur une intégration verticale approfondie des logiciels et du matériel TPU pour offrir des performances et un coût total de possession de premier ordre.
En s'appuyant sur des systèmes internes éprouvés, la pile a évolué pour offrir une fiabilité et une évolutivité intrinsèques, permettant aux utilisateurs de développer et de déployer en toute confiance même les modèles les plus volumineux. Sa conception modulaire et composable, ancrée dans la philosophie de la pile d'IA JAX, offre aux utilisateurs une liberté et un contrôle inégalés, leur permettant d'adapter la pile à leurs besoins spécifiques sans les contraintes d'un framework monolithique.
Avec XLA et Pathways qui fournissent une base évolutive et tolérante aux pannes, JAX qui fournit une bibliothèque de calculs numériques performante et expressive, de puissantes bibliothèques de développement de base comme Flax, Optax, Grain et Orbax, des outils de performances avancés comme Pallas, Tokamax et Qwix, et une couche d'application et de production robuste dans MaxText, vLLM et NSE, la pile JAX AI fournit une base durable sur laquelle les utilisateurs peuvent s'appuyer et mettre rapidement en production des recherches de pointe.