
このドキュメントでは、Agent Development Kit(ADK)フレームワークで構築された AI エージェントを構成して、マルチモーダル プロンプトとレスポンスを収集して保存する方法について説明します。また、保存されたマルチモーダル メディアを表示、分析、評価する方法についても説明します。
[Trace エクスプローラ] ページを使用すると、個々のプロンプトやレスポンスの表示や、会話全体の表示ができます。メディアをレンダリング形式または未加工形式で表示するオプションがあります。詳細については、マルチモーダル プロンプトとレスポンスを表示するをご覧ください。
BigQuery サービスを使用してマルチモーダル データを分析します。たとえば、
AI.GENERATEなどの関数を使用して会話を要約できます。詳細については、BigQuery を使用してプロンプトとレスポンスのデータを分析するをご覧ください。Vertex AI SDK を使用して会話を評価します。たとえば、Google Colaboratory を使用して感情分析を行うことができます。詳細については、Colaboratory でプロンプトとレスポンスのデータに対する評価を実行するをご覧ください。
収集できるメディアの種類
収集できるメディアの種類は次のとおりです。
- 音声。
- ドキュメント。
- イメージ。
- 書式なしテキストとマークダウン形式のテキスト。
- 動画。
プロンプトとレスポンスには、インライン コンテンツとリンクを含めることができます。リンクによって、公開リソースや Cloud Storage バケットに移動できます。
プロンプトとレスポンスの保存場所
エージェント アプリケーションがプロンプトやレスポンスを作成または受信すると、ADK は OpenTelemetry 計測を呼び出します。この計測では、OpenTelemetry GenAI セマンティック規約のバージョン 1.37.0 に準じて、プロンプトとレスポンス、およびそれらに含まれる可能性のあるマルチモーダル データがフォーマットされます。これより新しいバージョンもサポートされています。
次に、OpenTelemetry 計測では次の処理が行われます。
プロンプトとレスポンス データ用のオブジェクト識別子が作成され、そのデータが Cloud Storage バケットに書き込まれます。Cloud Storage バケット内のエントリは JSON Lines 形式で保存されます。
ログデータとトレースデータが Google Cloud プロジェクトに送信されます。Logging サービスと Trace サービスでは、このデータが取得され、保存されます。OpenTelemetry のセマンティック規約により、ログエントリまたはトレーススパンに付加される属性とフィールドの多くが決定されます。
OpenTelemetry 計測で Cloud Storage バケット オブジェクトが作成されると、これらのオブジェクトへの参照を含むログエントリも書き込まれます。次の例は、オブジェクト参照を含むログエントリの一部を示しています。
{ ... "labels": { "gen_ai.system": "vertex_ai", "event.name": "gen_ai.client.inference.operation.details", "gen_ai.output.messages_ref": "gs://my-bucket/eso9aP7NA_GX2PgPkrOi-Qg_output.jsonl", "gen_ai.system.instructions_ref": "gs://my-bucket/eso9aP7NA_GX2PgPkrOi-Qg_system_instructions.jsonl", "gen_ai.input.messages_ref": "gs://my-bucket/eso9aP7NA_GX2PgPkrOi-Qg_input.jsonl" }, "logName": "projects/my-project/logs/gen_ai.client.inference.operation.details", "trace": "projects/my-project/traces/963761020fc7713e4590cad89ad03229", "spanId": "1234512345123451", ... }ログエントリの例では、次の点に注意してください。
- ラベル
"event.name": "gen_ai.client.inference.operation.details"は、ログエントリに Cloud Storage オブジェクトへの参照が含まれていることを示します。 - キーに
gen_aiが含まれるラベルは、それぞれ Cloud Storage バケット内のオブジェクトを参照しています。 - オブジェクト参照が含まれるログエントリはすべて、
projects/my-project/logs/gen_ai.client.inference.operation.detailsという名前の同じログに書き込まれます。
オブジェクト参照が含まれるログエントリを表示する方法については、このドキュメントのプロンプトとレスポンスを参照するすべてのログエントリを検索するをご覧ください。
- ラベル
マルチモーダル プロンプトとレスポンスを収集する
ADK では OpenTelemetry が自動的に呼び出され、プロンプトとレスポンスが保存されてログデータとトレースデータが Google Cloud プロジェクトに送信されます。アプリケーションを変更する必要はありません。ただし、 Google Cloud プロジェクトと ADK を構成する必要があります。
アプリケーションからマルチモーダル プロンプトとレスポンスを収集して表示する手順は次のとおりです。
プロジェクトを構成します。
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Vertex AI, Cloud Storage, Telemetry, Cloud Logging, and Cloud Trace APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. Cloud Storage バケットがあることを確認します。必要に応じて、Cloud Storage バケットを作成します。
次のことをおすすめします。
Cloud Storage バケットは、アプリケーションのログデータを保存するログバケットと同じロケーションに作成します。この構成により、BigQuery クエリの効率が向上します。
Cloud Storage バケットのストレージ クラスが外部テーブルをサポートしていることを確認します。この機能を使用すると、BigQuery でプロンプトとレスポンスのクエリを実行できます。新しい Cloud Storage バケットにデフォルト設定を使用しない場合は、バケットを作成する前に、Cloud Storage 外部テーブルを作成するを確認してください。
Cloud Storage バケットの保持期間を、ログエントリを保存するログバケットの保持期間と一致するように設定します。ログデータのデフォルトの保持期間は 30 日です。Cloud Storage バケットの保持期間を設定する方法については、バケットロックをご覧ください。
アプリケーションが使用するサービス アカウントに、Cloud Storage バケットに対する
storage.objects.create権限を付与します。この権限により、アプリケーションは Cloud Storage バケットにオブジェクトを書き込むことができます。これらのオブジェクトには、エージェント アプリケーションが作成または受信するプロンプトとレスポンスが保存されます。詳細については、バケットでの IAM ポリシーの設定と管理をご覧ください。
-
ADK の構成
次の依存関係をインストールしてアップグレードします。
google-adk>=1.16.0opentelemetry-instrumentation-google-genai>=0.4b0fsspec[gcs]
ADK 呼び出しを更新して
otel_to_cloudフラグをオンにします。ADK 用 CLI を使用している場合は、次のコマンドを実行します。
adk web --otel_to_cloud [other options]それ以外の場合は、FastAPI アプリの作成時にフラグを渡します。
get_fast_api_app(..., otel_to_cloud=True)
次の環境変数を設定します。
Cloud Storage オブジェクトを JSON Lines としてフォーマットするように OpenTelemetry に指示します。
OTEL_INSTRUMENTATION_GENAI_UPLOAD_FORMAT='jsonl'このコンテンツをトレーススパンに埋め込むのではなく、プロンプトとレスポンスのデータをアップロードするように OpenTelemetry に指示します。アップロードされたオブジェクトへの参照がログエントリに含まれます。
OTEL_INSTRUMENTATION_GENAI_COMPLETION_HOOK='upload'生成 AI の最新のセマンティック規約を使用するように OpenTelemetry に指示します。
OTEL_SEMCONV_STABILITY_OPT_IN='gen_ai_latest_experimental'オブジェクトのパスを指定します。
OTEL_INSTRUMENTATION_GENAI_UPLOAD_BASE_PATH='gs://STORAGE_BUCKET/PATH'上記の式で、STORAGE_BUCKET は Cloud Storage バケットの名前を指しています。PATH は、オブジェクトが保存されるパスを指しています。
マルチモーダル プロンプトとレスポンスを表示する
スパンに表示するプロンプトとレスポンスを特定するために、Cloud Trace からログデータの読み取りと Cloud Storage バケットに保存されているデータの読み取りを行うクエリが発行されます。データが返されるかどうかは、クエリ対象のリソースに対する Identity and Access Management(IAM)ロールによって決まります。エラー メッセージが表示されることもあります。たとえば、Cloud Storage バケットからデータを読み取る権限がない場合、そのデータにアクセスしようとすると、権限拒否エラーが発生します。
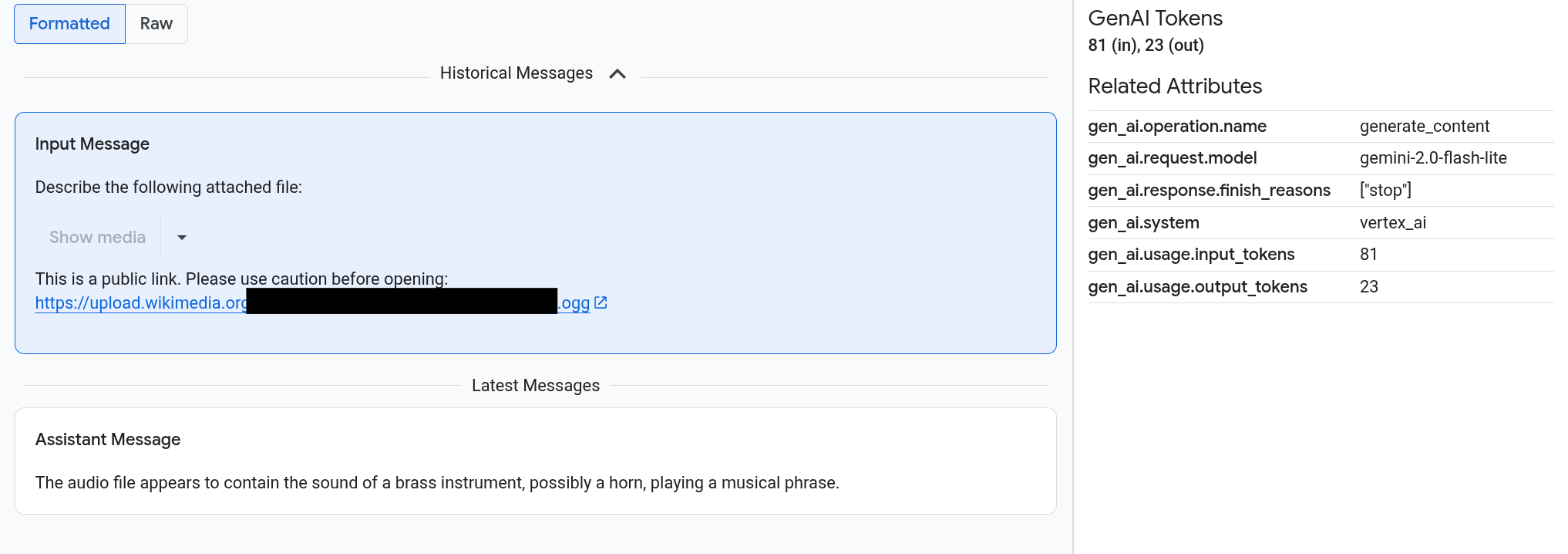
プロンプトとレスポンスはチャットのような形式で表示され、画像などのメディアを自動的にレンダリングするか、ソース形式で表示するかを選択できます。同様に、会話履歴全体を表示することも、スパンに関連付けられたプロンプトとレスポンスのみを表示することもできます。
たとえば、次の例は、プロンプトとレスポンスがどのように表示され、OpenTelemetry: 属性がどのように要約されるかを示しています。
始める前に
マルチモーダル プロンプトとレスポンスの表示に必要な権限を取得するには、プロジェクトに対する次の IAM ロールを付与するように管理者に依頼してください。
-
Cloud トレース ユーザー(
roles/cloudtrace.user) - ログ閲覧者(
roles/logging.viewer) -
ストレージ オブジェクト閲覧者(
roles/storage.objectViewer)
ロールの付与については、プロジェクト、フォルダ、組織へのアクセス権の管理をご覧ください。
必要な権限は、カスタムロールや他の事前定義ロールから取得することもできます。
マルチモーダル プロンプトとレスポンスを含むスパンを検索する
マルチモーダル プロンプトとレスポンスを含むスパンを検索するには、次の操作を行います。
-
Google Cloud コンソールで、[Trace エクスプローラ] ページに移動します。
このページは、検索バーを使用して見つけることもできます。
[スパンフィルタ] ペインで、[スパン名] セクションに移動して、
generate_contentを選択します。または、フィルタ
gen_ai.operation.name: generate_contentを追加します。スパンのリストからスパンを選択します。
スパンの [詳細] ページが開きます。このページには、トレースのコンテキスト内のスパンが表示されます。スパン名に [入力 / 出力] というラベルのボタン
 がある場合は、生成 AI イベントを利用できます。次のセクションのマルチモーダル プロンプトとレスポンスを調べるでは、データの表示方法と可視化オプションについて説明します。
がある場合は、生成 AI イベントを利用できます。次のセクションのマルチモーダル プロンプトとレスポンスを調べるでは、データの表示方法と可視化オプションについて説明します。
マルチモーダル プロンプトとレスポンスを調べる
[入力 / 出力] タブには 2 つのセクションがあります。一方のセクションにはプロンプトとレスポンスが表示され、もう一方のセクションには OpenTelemetry: 属性が表示されます。このタブは、Trace に送信されたスパンが OpenTelemetry GenAI セマンティック規約(バージョン 1.37.0 以降)に準拠している場合にのみ表示されます。これにより、名前が gen_ai で始まるメッセージが生成されます。
[入力 / 出力] タブには、チャットのような形式でメッセージが表示されます。タブのオプションを使用して、表示するメッセージとその形式を制御します。
- 会話全体を表示するには、[過去のメッセージ] ペインを開きます。
- 選択したスパンのプロンプトとレスポンスのみを表示するには、[最近のメッセージ] ペインを使用します。
画像、動画、その他のメディアを表示するには、[書式設定済み] を選択します。
メディアが常に表示されるわけではありません。プロンプトやレスポンスに一般公開されている画像、ドキュメント、動画へのリンクが含まれている場合は、ユーザーを保護するためにメディアを表示するかどうか確認する必要があります。同様に、プロンプトやレスポンスに Cloud Storage バケットに保存されているメディアが含まれており、そのメディアが非常に大きい場合は、メディアを表示するかどうか確認する必要があります。
画像や動画などの一部のメディアには、付属メニューが表示されます。このメニューを使用して、画像をローカル ドライブにダウンロードするといった操作を行うことができます。メニュー オプションはメディアタイプによって異なります。
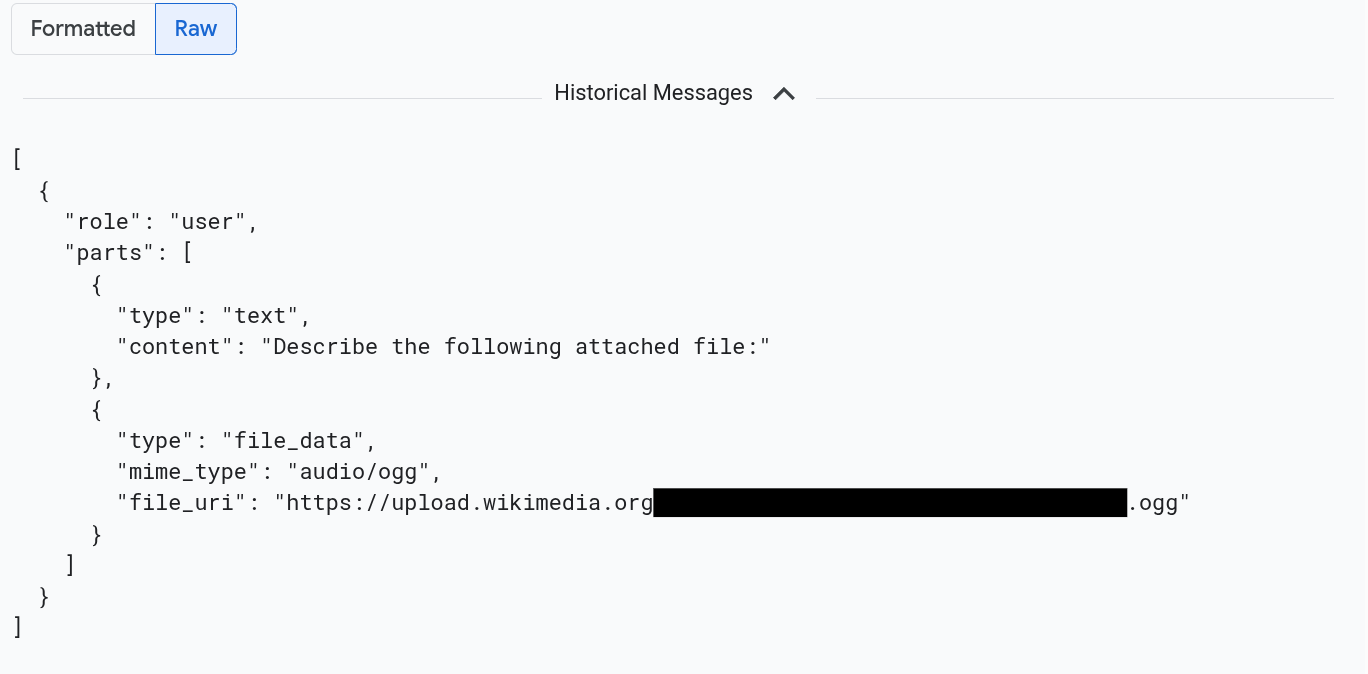
メッセージを JSON 形式で表示するには、[Raw] を選択します。この選択を行うと、画像などのメディアはレンダリングされません。
たとえば、次の画像は、会話が未加工形式でどのように表示されるかを示しています。
プロンプトとレスポンスを参照するすべてのログエントリを検索する
マルチモーダル プロンプトとレスポンスへのオブジェクト参照が含まれるログエントリを一覧表示するには、次の操作を行います。
-
Google Cloud コンソールで、[ログ エクスプローラ] ページに移動します。
検索バーを使用してこのページを検索する場合は、小見出しが [Logging] の結果を選択します。
プロジェクト選択ツールで、 Google Cloud プロジェクトを選択します。
ツールバーで [すべてのログ名] を開き、フィルタに
gen_aiを入力して、gen_ai.client.inference.operation.details という名前のログを選択します。前の手順では、次のクエリがログ エクスプローラに追加されます。
logName="projects/PROJECT_ID/logs/gen_ai.client.inference.operation.details"必要に応じて、ステートメントをコピーしてログ エクスプローラの [クエリ] ペインに貼り付けることができます。ただし、ステートメントをコピーする前に、PROJECT_ID をプロジェクト ID に置き換えてください。
ラベル値でログデータをフィルタすることもできます。たとえば、次のフィルタを追加すると、指定したラベルを含むログエントリのみが表示されます。
labels."event.name"="gen_ai.client.inference.operation.details"ログエントリで参照されているプロンプトとレスポンスを表示するには、ログエントリで
 [トレースの詳細を表示] をクリックします。
[トレースの詳細を表示] をクリックします。[入力 / 出力] タブのオプションを使用する方法については、このドキュメントのマルチモーダル プロンプトとレスポンスを調べるのセクションをご覧ください。
BigQuery を使用してプロンプトとレスポンスのデータを分析する
Cloud Storage バケットに保存されているプロンプトとレスポンスは、BigQuery を使用して分析できます。この分析を行う前に、次の手順を行います。
- 必要な API を有効にして、必要な IAM ロールが付与されていることを確認します。
- ログバケットにリンクされたデータセットを作成します。
- BigQuery に Cloud Storage バケットからの読み取り権限を付与します。
- 外部テーブルを作成します。
外部テーブルを作成したら、ログバケット内のデータを外部テーブルと結合し、結合されたデータに対して分析を行います。このセクションでは、テーブルを結合して特定のフィールドを抽出する方法について説明します。また、BigQuery ML 関数を使用して結合テーブルを分析する方法についても説明します。
始める前に
このセクションに記載されている IAM ロールは、ログバケットのアップグレードや外部テーブルの作成などのアクションを実行するために必要です。ただし、構成が完了すると、クエリの実行に必要な権限が少なくなります。
-
Enable the BigQuery and BigQuery Connection APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
BigQuery でマルチモーダル プロンプトとレスポンスを表示できるようにシステムを構成するために必要な権限を取得するには、プロジェクトに対する次の IAM ロールを付与するよう管理者に依頼します。
-
ログ構成書き込み(
roles/logging.configWriter) - ストレージ管理者(
roles/storage.admin) -
BigQuery Connection 管理者(
roles/bigquery.connectionAdmin) -
BigQuery データ閲覧者(
roles/bigquery.dataViewer) -
BigQuery Studio ユーザー(
roles/bigquery.studioUser)
ロールの付与については、プロジェクト、フォルダ、組織へのアクセス権の管理をご覧ください。
-
ログ構成書き込み(
ログバケットにリンクされたデータセットを作成する
ログデータを保存するログバケットがログ分析用にアップグレードされているかどうかを確認するには、次のコマンドを実行します。
gcloud logging buckets describe LOG_BUCKET_ID --location=LOCATIONコマンドを実行する前に、次のように置き換えます。
- LOG_BUCKET_ID: ログバケットの ID。
- LOCATION:ログバケットのロケーション。
ログ分析用にログバケットがアップグレードされると、
describeコマンドの結果に次のステートメントが含まれます。analyticsEnabled: trueログバケットがアップグレードされていない場合は、次のコマンドを実行します。
gcloud logging buckets update LOG_BUCKET_ID --location=LOCATION --enable-analytics --asyncアップグレードが完了するまでに数分かかることがあります。
describeコマンドでlifecycleStateがACTIVEと報告されたら、アップグレードは完了です。ログバケットにリンクされたデータセットを作成するには、次のコマンドを実行します。
gcloud logging links create LINKED_DATASET_NAME --bucket=LOG_BUCKET_ID --location=LOCATIONコマンドを実行する前に、次のように置き換えます。
- LOG_BUCKET_ID: ログバケットの ID。
- LOCATION:ログバケットのロケーション。
- LINKED_DATASET_NAME: 作成するリンクされたデータセットの名前。
リンクされたデータセットを使用すると、BigQuery はログバケットに保存されているログデータを読み取ることができます。詳細については、リンクされた BigQuery データセットをクエリするをご覧ください。
リンクが存在することを確認するには、次のコマンドを実行します。
gcloud logging links list --bucket=LOG_BUCKET_ID --location=LOCATION成功すると、前のコマンドに対するレスポンスに次の行が含まれます。
LINK_ID: LINKED_DATASET_NAME
BigQuery に Cloud Storage バケットからの読み取り権限を付与する
BigQuery 接続を作成するには、次のコマンドを実行します。
bq mk --connection --location=CONNECTION_LOCATION --project_id=PROJECT_ID \ --connection_type=CLOUD_RESOURCE CONNECTION_IDコマンドを実行する前に、次のように置き換えます。
- PROJECT_ID: プロジェクトの ID。
- CONNECTION_ID: 作成する接続の ID。
- CONNECTION_LOCATION: 接続のロケーション。
コマンドが正常に完了すると、次のようなメッセージが表示されます。
Connection 151560119848.CONNECTION_LOCATION.CONNECTION_ID successfully created接続を確認します。
bq show --connection PROJECT_ID.CONNECTION_LOCATION.CONNECTION_IDこのコマンドのレスポンスには、接続 ID とサービス アカウントが一覧表示されます。
{"serviceAccountId": "bqcx-151560119848-s1pd@gcp-sa-bigquery-condel.iam.gserviceaccount.com"}BigQuery 接続のサービス アカウントに、Cloud Storage バケットに保存されているデータを読み取ることができる IAM ロールを付与します。
gcloud storage buckets add-iam-policy-binding gs://STORAGE_BUCKET \ --member=serviceAccount:SERVICE_ACCT_EMAIL \ --role=roles/storage.objectViewerコマンドを実行する前に、次のように置き換えます。
- STORAGE_BUCKET: Cloud Storage バケットの名前。
- SERVICE_ACCT_EMAIL: サービス アカウントのメールアドレス。
外部 BigLake テーブルを作成する
BigQuery を使用して BigQuery に保存されていないデータをクエリするには、外部テーブルを作成します。Cloud Storage バケットにプロンプトとレスポンスが保存されるため、BigLake 外部テーブルを作成します。
-
Google Cloud コンソールで、[BigQuery] ページに移動します。
このページは、検索バーを使用して見つけることもできます。
クエリエディタで次のステートメントを入力します。
CREATE OR REPLACE EXTERNAL TABLE `PROJECT_ID.EXT_TABLE_DATASET_NAME.EXT_TABLE_NAME` ( -- Schema matching the JSON structure in a Cloud Storage bucket. parts ARRAY< STRUCT< type STRING, content STRING, -- multimodal attachments mime_type STRING, uri STRING, data BYTES, -- tool calls id STRING, name STRING, arguments JSON, response JSON > >, role STRING, `index` INT64, ) WITH CONNECTION `PROJECT_ID.CONNECTION_LOCATION.CONNECTION_ID` OPTIONS ( format = 'NEWLINE_DELIMITED_JSON', uris = ['gs://STORAGE_BUCKET/PATH/*'], ignore_unknown_values = TRUE );コマンドを実行する前に、次のように置き換えます。
- PROJECT_ID: プロジェクトの ID。
- EXT_TABLE_DATASET_NAME: 作成するデータセットの名前。
- EXT_TABLE_NAME: 作成する外部 BigLake テーブルの名前。
- CONNECTION_LOCATION: CONNECTION_ID のロケーション。
- CONNECTION_ID: 接続の ID。
- STORAGE_BUCKET: Cloud Storage バケットの名前。
- PATH: プロンプトとレスポンスのパス。
OTEL_INSTRUMENTATION_GENAI_UPLOAD_BASE_PATH環境変数でパスを指定します。
[実行] をクリックします。
外部テーブルの詳細については、以下をご覧ください。
外部テーブルをログデータと結合する
このセクションでは、BigQuery でマルチモーダル プロンプトを分析する方法について説明します。このソリューションは、外部 BigLake テーブルとログデータを結合することにより、Cloud Storage バケットからオブジェクトを取得します。この例では、入力メッセージの URI gen_ai.input.messages で結合しています。出力メッセージの URI(gen_ai.output.messages)またはシステム指示(gen_ai.system.instructions)で結合することもできます。
外部 BigLake テーブルをログデータと結合するには、次の操作を行います。
-
Google Cloud コンソールで、[BigQuery] ページに移動します。
このページは、検索バーを使用して見つけることもできます。
クエリエディタで次のクエリを入力します。このクエリは、Cloud Storage バケット エントリのパスでログデータと外部テーブルを結合します。
-- Query the linked dataset for completion logs. FROM-- Join completion log entries with the external table. |> JOIN `PROJECT_ID.EXT_TABLE_DATASET_NAME.EXT_TABLE_NAME` ON messages_ref_uri = _FILE_NAME |> RENAME `index` AS message_idx -- Flatten. |> CROSS JOIN UNNEST(parts) AS part WITH OFFSET AS part_idx -- Print fields. |> SELECT insert_id, labels, timestamp, trace, span_id, role, part.content, part.uri, part.mime_type, TO_HEX(MD5(part.data)) AS data_md5_hex, part.id AS tool_id, part.name AS tool_name, part.arguments AS tool_args, part.response AS tool_response, message_idx, part_idx, |> ORDER BY timestamp, message_idx, part_idx; |> LIMIT 10;PROJECT_ID.LINKED_DATASET_NAME._AllLogs|> WHERE log_name = 'projects/PROJECT_ID/logs/gen_ai.client.inference.operation.details' AND timestamp > TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 1 DAY) |> SELECT insert_id, timestamp, labels, trace, span_id, STRING(labels['gen_ai.input.messages_ref']) AS messages_ref_uriクエリを実行する前に、次のように置き換えます。
- PROJECT_ID: プロジェクトの ID。
- LINKED_DATASET_NAME: リンクされたデータセットの名前。
- EXT_TABLE_DATASET_NAME: 外部 BigLake テーブルのデータセットの名前。
- EXT_TABLE_NAME: 外部 BigLake テーブルの名前。
省略可: 前のクエリは、ログ名とタイムスタンプでフィルタします。特定のトレース ID でもフィルタする場合は、
WHERE句に次のステートメントを追加します。AND trace = 'projects/PROJECT_ID/traces/TRACE_ID'前の式で、TRACE_ID はトレース ID を含む 16 バイトの 16 進文字列に置き換えます。
BigQuery ML 関数を使用する
Cloud Storage バケットに保存されているプロンプトとレスポンスに対して、AI.GENERATE などの BigQuery ML 関数を使用できます。
たとえば、次のクエリは、完了ログエントリを外部テーブルと結合し、結合結果を平坦化してフィルタします。次に、プロンプトにより AI.GENERATE が実行され、エントリに画像が含まれているかどうかの分析と各エントリの要約の生成が行われます。
-- Query the linked dataset for completion logs.
FROM PROJECT_ID.LINKED_DATASET_NAME._AllLogs
|> WHERE
log_name = 'projects/PROJECT_ID/logs/gen_ai.client.inference.operation.details'
AND timestamp > TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 1 DAY)
|> SELECT
insert_id,
timestamp,
labels,
trace,
span_id,
STRING(labels['gen_ai.input.messages_ref']) AS messages_ref_uri
-- Join completion log entries with the external table.
|> JOIN `PROJECT_ID.EXT_TABLE_DATASET_NAME.EXT_TABLE_NAME`
ON messages_ref_uri = _FILE_NAME
|> RENAME `index` AS message_idx
-- Flatten.
|> CROSS JOIN UNNEST(parts) AS part WITH OFFSET AS part_idx
|> WHERE part.uri IS NOT NULL AND part.uri LIKE 'gs://%'
|> LIMIT 10
-- Use natural language to search for images, and then summarize the entry.
|> EXTEND
AI.GENERATE(
(
'Describe the attachment in one sentence and whether the image contains a diagram.',
OBJ.FETCH_METADATA(OBJ.MAKE_REF(part.uri, 'CONNECTION_LOCATION.CONNECTION_ID'))),
connection_id => 'CONNECTION_LOCATION.CONNECTION_ID',
endpoint => 'gemini-2.5-flash-lite',
output_schema => 'description STRING, is_match BOOLEAN') AS gemini_summary
|> SELECT insert_id, trace, span_id, timestamp, part_idx, part.uri, part.mime_type, gemini_summary
|> WHERE gemini_summary.is_match = TRUE
|> ORDER BY timestamp DESC
クエリを実行する前に、次のように置き換えます。
- PROJECT_ID: プロジェクトの ID。
- LINKED_DATASET_NAME: リンクされたデータセットの名前。
- EXT_TABLE_DATASET_NAME: 外部 BigLake テーブルのデータセットの名前。
- EXT_TABLE_NAME: 外部 BigLake テーブルの名前。
- CONNECTION_LOCATION: CONNECTION_ID のロケーション。
- CONNECTION_ID: 接続の ID。
Colaboratory でプロンプトとレスポンスのデータに対する評価を実行する
Vertex AI SDK for Python を使用して、プロンプトとレスポンスを評価できます。
Google Colaboratory ノートブックを使用して評価を実行するには、次の操作を行います。
サンプル ノートブックを表示するには、
evaluating_observability_datasets.ipynbをクリックします。GitHub が開き、ノートブックの使用手順が表示されます。
[Colab で開く] を選択します。
Colaboratory が開き、
evaluating_observability_datasets.ipynbファイルが表示されます。ツールバーで [ドライブにコピー] をクリックします。
Colaboratory によりノートブックのコピーが作成されてドライブに保存され、そのコピーが開きます。
コピーで、[Google Cloud プロジェクト情報を設定する] というセクションに移動し、 Google Cloud プロジェクト ID と Vertex AI でサポートされているロケーションを入力します。たとえば、ロケーションを
"us-central1"に設定できます。[Google Observability Gen AI データセットに読み込む] というセクションに移動し、次のソースの値を入力します。
- INPUT_SOURCE
- OUTPUT_SOURCE
- SYSTEM_SOURCE
これらのフィールドの値は、ログエントリに付加されている
gen_aiラベルを使用して確認できます。たとえば、INPUT_SOURCE の値は次のようになります。'gs://STORAGE_BUCKET/PATH/REFERENCE_inputs.jsonl'上記の式で、フィールドの意味は次のとおりです。
- STORAGE_BUCKET: Cloud Storage バケットの名前。
- PATH: プロンプトとレスポンスのパス。
- REFERENCE: Cloud Storage バケット内のデータの識別子。
これらのソースの値を検索する方法については、プロンプトとレスポンスを参照するすべてのログエントリを検索するをご覧ください。
ツールバーで [すべてを実行] をクリックします。