
En este documento se describe cómo puedes configurar un agente ReAct de LangGraph o un agente de IA generativa creado con el framework Agent Development Kit (ADK) para enviar peticiones y respuestas multimodales a tu proyecto de Google Cloud . También se describe cómo puedes ver, analizar y evaluar tu contenido multimedia multimodal almacenado:
Usa la página Explorador de trazas para ver peticiones o respuestas concretas, o bien una conversación completa. Puedes ver el contenido multimedia en formato renderizado o sin procesar. Para obtener más información, consulta Ver peticiones y respuestas multimodales.
Usa los servicios de BigQuery para analizar los datos multimodales. Por ejemplo, puedes usar una función como
AI.GENERATEpara resumir una conversación. Para obtener más información, consulta Analizar datos de peticiones y respuestas con BigQuery.Usa el SDK de Vertex AI para evaluar una conversación. Por ejemplo, puedes usar Google Colaboratory para realizar análisis de sentimiento. Para obtener más información, consulta Realizar evaluaciones en los datos de peticiones y respuestas con Colaboratory.
Tipos de contenido multimedia que puedes recoger
Puede recoger los siguientes tipos de contenido multimedia:
- Audio.
- Documentos.
- Imágenes.
- Texto sin formato y texto con formato Markdown.
- Vídeo.
Tus peticiones y respuestas pueden incluir contenido y enlaces insertados. Los enlaces pueden dirigir a recursos públicos o a segmentos de Cloud Storage.
Dónde se almacenan tus peticiones y respuestas
Cuando tu aplicación de agente crea o recibe peticiones o respuestas, el SDK que usa tu aplicación invoca la instrumentación de OpenTelemetry. Esta instrumentación da formato a las peticiones y respuestas, así como a los datos multimodales que puedan contener, de acuerdo con la versión 1.37.0 de las convenciones semánticas de GenAI de OpenTelemetry. También se admiten versiones posteriores.
A continuación, la instrumentación de OpenTelemetry hace lo siguiente:
Crea identificadores de objetos para las peticiones y los datos de respuesta y, a continuación, escribe esos datos en tu segmento de Cloud Storage. Las entradas de tu segmento de Cloud Storage se guardan en formato JSON Lines.
Envía datos de registro y de traza a tu Google Cloud proyecto, donde los servicios Logging y Trace ingieren y almacenan los datos. Las convenciones semánticas de OpenTelemetry determinan muchos de los atributos y campos asociados a tus entradas de registro o a tus intervalos de traza.
Cuando la instrumentación de OpenTelemetry crea objetos de segmento de Cloud Storage, también escribe una entrada de registro que contiene referencias a esos objetos. En el siguiente ejemplo se muestra parte de una entrada de registro que incluye referencias de objetos:
{ ... "labels": { "gen_ai.system": "vertex_ai", "event.name": "gen_ai.client.inference.operation.details", "gen_ai.output.messages_ref": "gs://my-bucket/eso9aP7NA_GX2PgPkrOi-Qg_output.jsonl", "gen_ai.system_instructions_ref": "gs://my-bucket/eso9aP7NA_GX2PgPkrOi-Qg_system_instructions.jsonl", "gen_ai.input.messages_ref": "gs://my-bucket/eso9aP7NA_GX2PgPkrOi-Qg_input.jsonl" }, "logName": "projects/my-project/logs/gen_ai.client.inference.operation.details", "trace": "projects/my-project/traces/963761020fc7713e4590cad89ad03229", "spanId": "1234512345123451", ... }En el ejemplo de entrada de registro, observe lo siguiente:
- La etiqueta
"event.name": "gen_ai.client.inference.operation.details"indica que la entrada de registro contiene referencias a objetos de Cloud Storage. - Las etiquetas cuyas claves incluyen
gen_aihacen referencia a un objeto de un segmento de Cloud Storage. - Todas las entradas de registro que contienen referencias de objetos se escriben en el mismo registro, llamado
projects/my-project/logs/gen_ai.client.inference.operation.details.
Para saber cómo mostrar las entradas de registro que contienen referencias a objetos, consulta la sección Buscar todas las entradas de registro que hacen referencia a peticiones y respuestas de este documento.
- La etiqueta
Recoger peticiones y respuestas multimodales
El SDK que usa tu aplicación invoca automáticamente OpenTelemetry para almacenar tus peticiones y respuestas, así como para enviar datos de registro y de seguimiento a tu proyecto de Google Cloud . No es necesario que modifiques tu aplicación. Sin embargo, debes configurar tu proyecto deGoogle Cloud y el SDK que estés usando.
Para recoger y ver tus peticiones y respuestas multimodales de una aplicación, haz lo siguiente:
Configura tu proyecto:
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Vertex AI, Cloud Storage, Telemetry, Cloud Logging, and Cloud Trace APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. Asegúrate de tener un segmento de Cloud Storage. Si es necesario, crea un segmento de Cloud Storage.
Te recomendamos que hagas lo siguiente:
Crea el segmento de Cloud Storage en la misma ubicación que el segmento de registro que almacena los datos de registro de tu aplicación. Esta configuración hace que las consultas de BigQuery sean más eficientes.
Asegúrate de que la clase de almacenamiento de tu segmento de Cloud Storage sea compatible con las tablas externas. Esta función te permite consultar tus peticiones y respuestas con BigQuery. Si no tienes previsto usar la configuración predeterminada de un nuevo segmento de Cloud Storage, antes de crear el segmento, consulta el artículo Crear tablas externas de Cloud Storage.
Define el periodo de retención de tu segmento de Cloud Storage para que coincida con el periodo de retención del segmento de registro que almacena tus entradas de registro. El periodo de conservación predeterminado de los datos de registro es de 30 días. Para saber cómo definir el periodo de conservación de tu segmento de Cloud Storage, consulta Bucket Lock.
Concede a la cuenta de servicio que usa tu aplicación el permiso
storage.objects.createen tu segmento de Cloud Storage. Este permiso permite que tu aplicación escriba objetos en tu segmento de Cloud Storage. Estos objetos almacenan las peticiones y las respuestas que crea o recibe tu aplicación basada en agentes. Para obtener más información, consulta Definir y gestionar políticas de IAM en los contenedores.
-
Configura el SDK:
Instala y actualiza las siguientes dependencias:
ADK
google-adk>=1.16.0opentelemetry-instrumentation-google-genai>=0.4b0fsspec[gcs]
LangGraph
opentelemetry-instrumentation-vertexai==2.2b0(o versiones posteriores)opentelemetry-instrumentation-google-genai>=0.4b0fsspec[gcs]
Si usas ADK, actualiza la invocación de tu aplicación para activar la marca
otel_to_cloud:Si usas la CLI de ADK, ejecuta el siguiente comando:
adk web --otel_to_cloud [other options]De lo contrario, pasa el indicador al crear la aplicación FastAPI:
get_fast_api_app(..., otel_to_cloud=True)
Define las siguientes variables de entorno:
Indica a OpenTelemetry que dé formato a los objetos de Cloud Storage como líneas JSON.
OTEL_INSTRUMENTATION_GENAI_UPLOAD_FORMAT='jsonl'Indica a OpenTelemetry que suba los datos de las peticiones y las respuestas en lugar de insertar este contenido en los intervalos de traza. Las referencias a los objetos subidos se incluyen en una entrada de registro.
OTEL_INSTRUMENTATION_GENAI_COMPLETION_HOOK='upload'Indica a OpenTelemetry que use las convenciones semánticas más recientes para la IA generativa.
OTEL_SEMCONV_STABILITY_OPT_IN='gen_ai_latest_experimental'Especifica la ruta de los objetos:
OTEL_INSTRUMENTATION_GENAI_UPLOAD_BASE_PATH='gs://STORAGE_BUCKET/PATH'En la expresión anterior, STORAGE_BUCKET hace referencia al nombre del segmento de Cloud Storage. PATH hace referencia a la ruta en la que se almacenan los objetos.
En el caso de los agentes ReAct de LangGraph, indica a OpenTelemetry que capture automáticamente los datos de registro:
OTEL_PYTHON_LOGGING_AUTO_INSTRUMENTATION_ENABLED='true'
Ver peticiones y respuestas multimodales
Para determinar las peticiones y respuestas que se deben mostrar en un intervalo, Cloud Trace envía consultas para leer datos de registro y datos almacenados en un segmento de Cloud Storage. Los roles de gestión de identidades y accesos (IAM) que tengas en los recursos consultados determinan si se devuelven datos. En algunos casos, es posible que veas un mensaje de error. Por ejemplo, si no tienes permiso para leer datos de un segmento de Cloud Storage, los intentos de acceder a esos datos generarán un error de permiso denegado.
Las peticiones y las respuestas se muestran en un formato similar al de un chat, y puedes elegir si quieres que los elementos multimedia, como las imágenes, se rendericen automáticamente o se muestren en formato de origen. Del mismo modo, puedes ver todo el historial de la conversación o solo las peticiones y respuestas asociadas a un intervalo.
Por ejemplo, en el siguiente ejemplo se muestra cómo aparecen las peticiones y las respuestas, y cómo se resumen los atributos de OpenTelemetry:
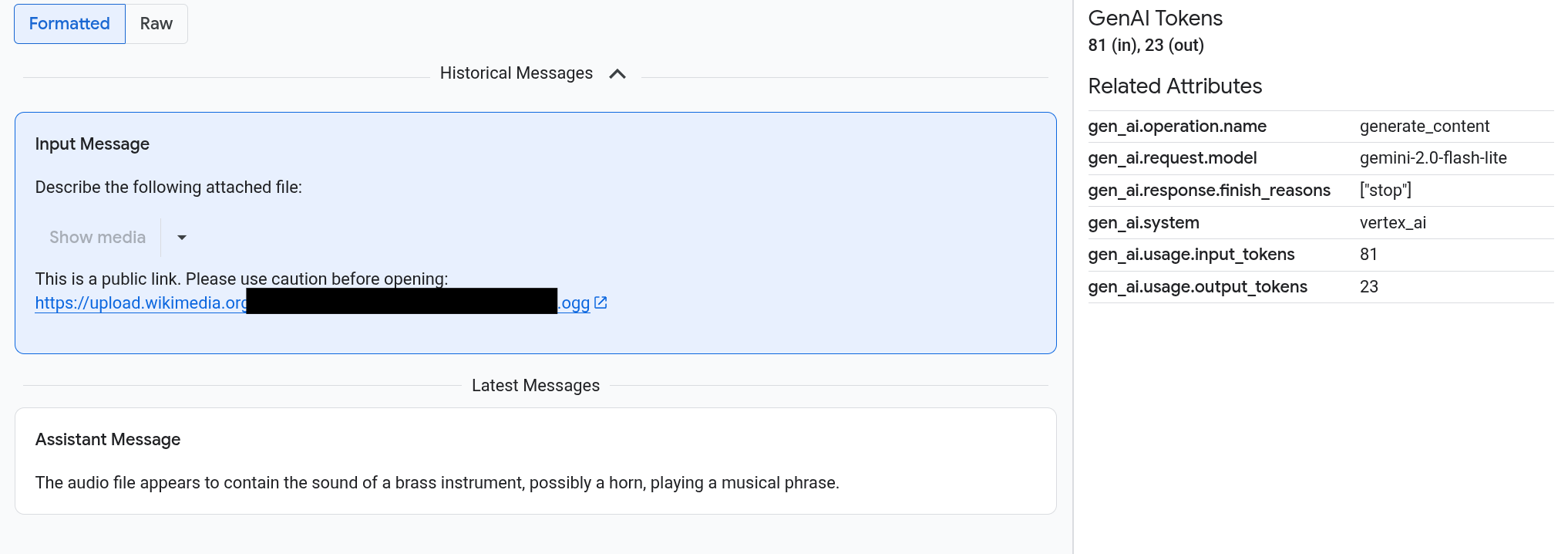
Antes de empezar
Para obtener los permisos que necesitas para ver tus peticiones y respuestas multimodales, pide a tu administrador que te conceda los siguientes roles de gestión de identidades y accesos en el proyecto:
-
Usuario de Cloud Trace (
roles/cloudtrace.user) -
Visualizador de registros (
roles/logging.viewer) -
Lector de objetos de Storage (
roles/storage.objectViewer)
Para obtener más información sobre cómo conceder roles, consulta el artículo Gestionar acceso a proyectos, carpetas y organizaciones.
También puedes conseguir los permisos necesarios a través de roles personalizados u otros roles predefinidos.
Buscar intervalos que contengan peticiones y respuestas multimodales
Para encontrar los tramos que contienen peticiones y respuestas multimodales, haz lo siguiente:
-
En la Google Cloud consola, ve a la página Explorador de trazas:
También puedes encontrar esta página mediante la barra de búsqueda.
En el panel Filtro de intervalo, ve a la sección Nombre del intervalo y selecciona
generate_content.También puedes añadir el filtro
gen_ai.operation.name: generate_content.Selecciona un intervalo de la lista de intervalos.
Se abrirá la página Detalles del intervalo. En esta página se muestra el intervalo en el contexto del rastreo. Si el nombre de un intervalo tiene un botón con la etiqueta Entradas/Salidas,
 , significa que hay eventos de IA generativa disponibles. En la siguiente sección, Explorar tus peticiones y respuestas multimodales, se explica cómo se presentan los datos y las opciones de visualización.
, significa que hay eventos de IA generativa disponibles. En la siguiente sección, Explorar tus peticiones y respuestas multimodales, se explica cómo se presentan los datos y las opciones de visualización.
Consultar tus peticiones y respuestas multimodales
La pestaña Entradas/Salidas contiene dos secciones.
En una sección se muestran las peticiones y las respuestas, y en la otra se muestra OpenTelemetry: Attributes (OpenTelemetry: atributos). Esta pestaña solo aparece cuando los intervalos enviados a Trace siguen las convenciones semánticas de IA generativa de OpenTelemetry, versión 1.37.0 o posterior, lo que da lugar a mensajes cuyos nombres empiezan por gen_ai.
En la pestaña Entradas/Salidas se muestran tus mensajes en un formato similar al de un chat. Puede controlar qué mensajes aparecen y su formato mediante las opciones de la pestaña:
- Para ver toda la conversación, amplía el panel Mensajes históricos.
- Para ver solo las peticiones y las respuestas del periodo seleccionado, usa el panel Últimos mensajes.
Para ver imágenes, vídeos u otro contenido multimedia, selecciona Formateado.
El sistema no siempre muestra contenido multimedia. Para protegerte, si una petición o una respuesta incluye un enlace a una imagen, un documento o un vídeo públicos, debes confirmar que quieres que se muestre el contenido multimedia. Del mismo modo, si una petición o una respuesta incluye contenido multimedia almacenado en tu segmento de Cloud Storage y el contenido multimedia es muy grande, debes confirmar que quieres que se muestre.
Algunos elementos multimedia, como imágenes y vídeos, aparecen con un menú adjunto. Puedes usar este menú para realizar acciones como descargar una imagen en una unidad local. Las opciones del menú dependen del tipo de contenido multimedia.
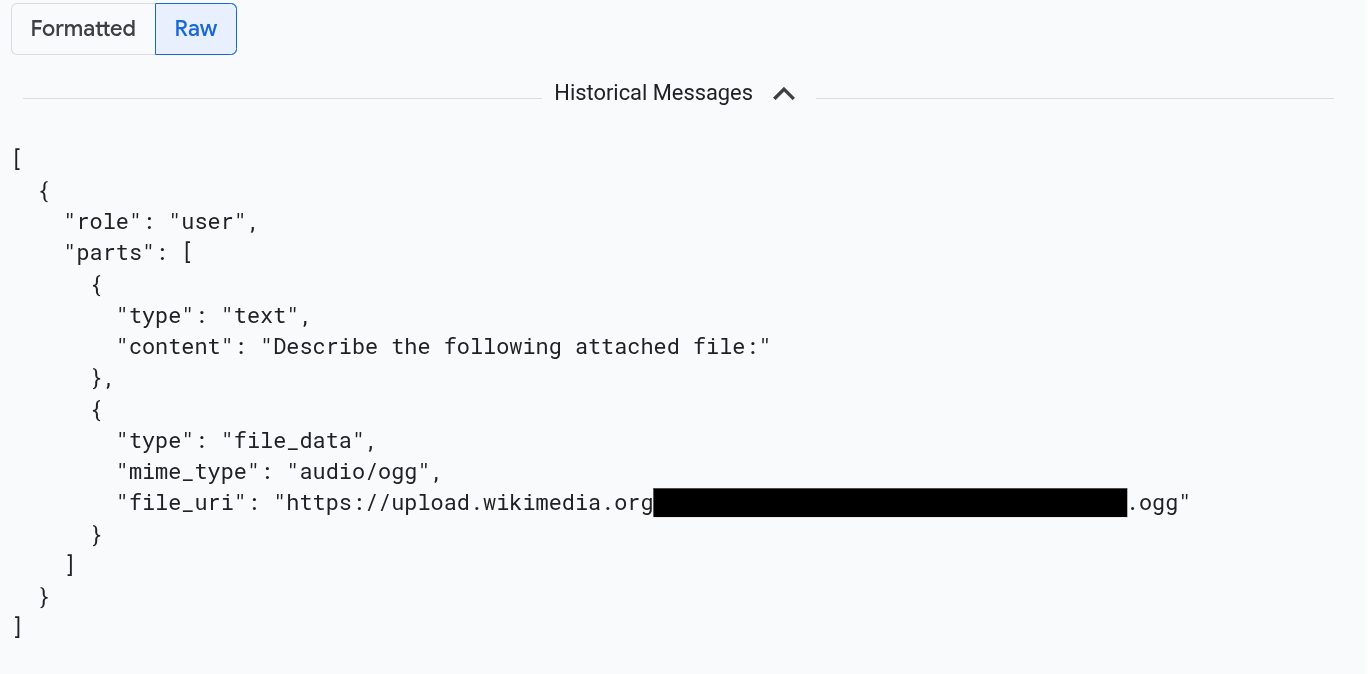
Para ver los mensajes con formato JSON, selecciona Sin formato. Con esta selección, no se renderizarán los elementos multimedia, como las imágenes.
Por ejemplo, en la siguiente imagen se muestra cómo aparece una conversación en formato sin formato:
Buscar todas las entradas de registro que hagan referencia a peticiones y respuestas
Para enumerar las entradas de registro que incluyen referencias de objetos a peticiones y respuestas multimodales, haz lo siguiente:
-
En la Google Cloud consola, ve a la página Explorador de registros:
Ve al Explorador de registros.
Si usas la barra de búsqueda para encontrar esta página, selecciona el resultado cuya sección sea Registro.
En el selector de proyectos, selecciona tu Google Cloud proyecto.
En la barra de herramientas, despliega Todos los nombres de registro, introduce
gen_aien el filtro y, a continuación, selecciona el registro llamado gen_ai.client.inference.operation.details.En los pasos anteriores se añade la siguiente consulta al Explorador de registros:
logName="projects/PROJECT_ID/logs/gen_ai.client.inference.operation.details"Si lo prefieres, puedes copiar la instrucción y pegarla en el panel Consulta del Explorador de registros, pero sustituye PROJECT_ID por el ID de tu proyecto antes de copiar la instrucción.
También puede filtrar los datos de registro por valor de etiqueta. Por ejemplo, si añade el siguiente filtro, solo aparecerán las entradas de registro que contengan la etiqueta especificada:
labels."event.name"="gen_ai.client.inference.operation.details"Para ver las peticiones y las respuestas a las que hace referencia una entrada de registro, haz clic en
 Ver detalles del seguimiento en la entrada de registro.
Ver detalles del seguimiento en la entrada de registro.Para saber cómo usar las opciones de la pestaña Entradas/Salidas, consulta la sección Explorar tus peticiones y respuestas multimodales de este documento.
Analizar datos de peticiones y respuestas con BigQuery
Puedes analizar las peticiones y las respuestas que almacena tu segmento de Cloud Storage con BigQuery. Antes de realizar este análisis, sigue estos pasos:
- Habilita las APIs necesarias y asegúrate de que se te han asignado los roles de IAM necesarios.
- Crea un conjunto de datos vinculado en tu segmento de registro.
- Concede a BigQuery permiso para leer datos de tu segmento de Cloud Storage.
- Crea una tabla externa.
Una vez que haya creado la tabla externa, combine los datos de su contenedor de registros con la tabla externa y realice el análisis con los datos combinados. En esta sección se muestra cómo unir tablas y extraer campos específicos. También se muestra cómo analizar la tabla combinada con funciones de BigQuery ML.
Antes de empezar
Los roles de gestión de identidades y accesos que se indican en esta sección son necesarios para realizar acciones como actualizar un segmento de registro y crear una tabla externa. Sin embargo, una vez completada la configuración, se necesitan menos permisos para ejecutar consultas.
-
Enable the BigQuery and BigQuery Connection APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
Para obtener los permisos que necesitas para configurar el sistema de forma que puedas ver tus peticiones y respuestas multimodales en BigQuery, pide a tu administrador que te conceda los siguientes roles de gestión de identidades y accesos en el proyecto:
-
Editor de configuración de registros (
roles/logging.configWriter) -
Administrador de almacenamiento (
roles/storage.admin) -
Administrador de conexiones de BigQuery (
roles/bigquery.connectionAdmin) -
Lector de datos de BigQuery (
roles/bigquery.dataViewer) -
Usuario de BigQuery Studio (
roles/bigquery.studioUser)
Para obtener más información sobre cómo conceder roles, consulta el artículo Gestionar acceso a proyectos, carpetas y organizaciones.
También puedes conseguir los permisos necesarios a través de roles personalizados u otros roles predefinidos.
-
Editor de configuración de registros (
Crear un conjunto de datos vinculado en tu segmento de registro
Para determinar si el contenedor de registros que almacena tus datos de registro se ha actualizado para Analíticas de registros, ejecuta el siguiente comando:
gcloud logging buckets describe LOG_BUCKET_ID --location=LOCATIONSustituye los siguientes valores antes de ejecutar el comando:
- LOG_BUCKET_ID: ID del segmento de registro.
- LOCATION: la ubicación del segmento de registro.
Cuando se actualiza un contenedor de registros para usar Analíticas de registros, los resultados del comando
describeincluyen la siguiente instrucción:analyticsEnabled: trueSi tu contenedor de registro no se ha actualizado, ejecuta el siguiente comando:
gcloud logging buckets update LOG_BUCKET_ID --location=LOCATION --enable-analytics --asyncLa actualización puede tardar varios minutos en completarse. Cuando el comando
describeindique quelifecycleStateesACTIVE, la actualización se habrá completado.Para crear un conjunto de datos vinculado en tu contenedor de registros, ejecuta el siguiente comando:
gcloud logging links create LINKED_DATASET_NAME --bucket=LOG_BUCKET_ID --location=LOCATIONSustituye los siguientes valores antes de ejecutar el comando:
- LOG_BUCKET_ID: ID del segmento de registro.
- LOCATION: la ubicación del segmento de registro.
- LINKED_DATASET_NAME: nombre del conjunto de datos vinculado que se va a crear.
El conjunto de datos vinculado permite que BigQuery lea los datos de registro almacenados en tu bucket de registro. Para obtener más información, consulta Consultar un conjunto de datos de BigQuery vinculado.
Para confirmar que el enlace existe, ejecuta el siguiente comando:
gcloud logging links list --bucket=LOG_BUCKET_ID --location=LOCATIONSi la solicitud se realiza correctamente, la respuesta al comando anterior incluye la siguiente línea:
LINK_ID: LINKED_DATASET_NAME
Dar permiso a BigQuery para leer datos de tu segmento de Cloud Storage
Para crear una conexión de BigQuery, ejecuta el siguiente comando:
bq mk --connection --location=CONNECTION_LOCATION --project_id=PROJECT_ID \ --connection_type=CLOUD_RESOURCE CONNECTION_IDSustituye los siguientes valores antes de ejecutar el comando:
- PROJECT_ID: identificador del proyecto.
- CONNECTION_ID: ID de la conexión que se va a crear.
- CONNECTION_LOCATION: la ubicación de la conexión.
Cuando el comando se completa correctamente, muestra un mensaje similar al siguiente:
Connection 151560119848.CONNECTION_LOCATION.CONNECTION_ID successfully createdVerifica la conexión.
bq show --connection PROJECT_ID.CONNECTION_LOCATION.CONNECTION_IDLa respuesta a este comando muestra el ID de conexión y una cuenta de servicio:
{"serviceAccountId": "bqcx-151560119848-s1pd@gcp-sa-bigquery-condel.iam.gserviceaccount.com"}Concede a la cuenta de servicio de la conexión de BigQuery un rol de gestión de identidades y accesos que le permita leer los datos almacenados en tu segmento de Cloud Storage:
gcloud storage buckets add-iam-policy-binding gs://STORAGE_BUCKET \ --member=serviceAccount:SERVICE_ACCT_EMAIL \ --role=roles/storage.objectViewerSustituye los siguientes valores antes de ejecutar el comando:
- STORAGE_BUCKET: el nombre de tu segmento de Cloud Storage.
- SERVICE_ACCT_EMAIL: la dirección de correo de tu cuenta de servicio.
Crear una tabla externa de BigLake
Para usar BigQuery y consultar datos que no almacena, crea una tabla externa. Como un segmento de Cloud Storage almacena las peticiones y las respuestas, crea una tabla externa de BigLake.
-
En la Google Cloud consola, ve a la página BigQuery:
También puedes encontrar esta página mediante la barra de búsqueda.
En el editor de consultas, introduce la siguiente instrucción:
CREATE OR REPLACE EXTERNAL TABLE `PROJECT_ID.EXT_TABLE_DATASET_NAME.EXT_TABLE_NAME` ( -- Schema matching the JSON structure in a Cloud Storage bucket. parts ARRAY< STRUCT< type STRING, content STRING, -- multimodal attachments mime_type STRING, uri STRING, data BYTES, -- tool calls id STRING, name STRING, arguments JSON, response JSON > >, role STRING, `index` INT64, ) WITH CONNECTION `PROJECT_ID.CONNECTION_LOCATION.CONNECTION_ID` OPTIONS ( format = 'NEWLINE_DELIMITED_JSON', uris = ['gs://STORAGE_BUCKET/PATH/*'], ignore_unknown_values = TRUE );Sustituye los siguientes valores antes de ejecutar el comando:
- PROJECT_ID: identificador del proyecto.
- EXT_TABLE_DATASET_NAME: nombre del conjunto de datos que se va a crear.
- EXT_TABLE_NAME: nombre de la tabla externa de BigLake que se va a crear.
- CONNECTION_LOCATION: la ubicación de tu CONNECTION_ID.
- CONNECTION_ID: ID de la conexión.
- STORAGE_BUCKET: nombre del segmento de Cloud Storage.
- PATH: la ruta a las peticiones y respuestas. La variable de entorno
OTEL_INSTRUMENTATION_GENAI_UPLOAD_BASE_PATHespecifica la ruta.
Haz clic en Ejecutar.
Para obtener más información sobre las tablas externas, consulta lo siguiente:
Combinar una tabla externa con los datos de registro
En esta sección se muestra cómo puedes analizar tus peticiones multimodales en BigQuery. La solución se basa en combinar tu tabla externa de BigLake con tus datos de registro, lo que te permite recuperar objetos de tu segmento de Cloud Storage. En el ejemplo se une el URI de los mensajes de entrada, gen_ai.input.messages. También puedes unirte en el URI de los mensajes de salida, gen_ai.output.messages, o en las instrucciones del sistema, gen_ai.system_instructions.
Para unir tu tabla de BigLake externa con tus datos de registro, haz lo siguiente:
-
En la Google Cloud consola, ve a la página BigQuery:
También puedes encontrar esta página mediante la barra de búsqueda.
En el editor de consultas, introduce la siguiente consulta, que combina tus datos de registro y tu tabla externa en la ruta a las entradas del segmento de Cloud Storage:
-- Query the linked dataset for completion logs. FROM-- Join completion log entries with the external table. |> JOIN `PROJECT_ID.EXT_TABLE_DATASET_NAME.EXT_TABLE_NAME` ON messages_ref_uri = _FILE_NAME |> RENAME `index` AS message_idx -- Flatten. |> CROSS JOIN UNNEST(parts) AS part WITH OFFSET AS part_idx -- Print fields. |> SELECT insert_id, labels, timestamp, trace, span_id, role, part.content, part.uri, part.mime_type, TO_HEX(MD5(part.data)) AS data_md5_hex, part.id AS tool_id, part.name AS tool_name, part.arguments AS tool_args, part.response AS tool_response, message_idx, part_idx, |> ORDER BY timestamp, message_idx, part_idx; |> LIMIT 10;PROJECT_ID.LINKED_DATASET_NAME._AllLogs|> WHERE log_name = 'projects/PROJECT_ID/logs/gen_ai.client.inference.operation.details' AND timestamp > TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 1 DAY) |> SELECT insert_id, timestamp, labels, trace, span_id, STRING(labels['gen_ai.input.messages_ref']) AS messages_ref_uriSustituye los siguientes valores antes de ejecutar la consulta:
- PROJECT_ID: identificador del proyecto.
- LINKED_DATASET_NAME: el nombre del conjunto de datos vinculado.
- EXT_TABLE_DATASET_NAME: Nombre del conjunto de datos de la tabla externa de BigLake.
- EXT_TABLE_NAME: el nombre de la tabla externa de BigLake.
Opcional: La consulta anterior filtra por el nombre del registro y la marca de tiempo. Si también quieres filtrar por un ID de seguimiento específico, añade la siguiente instrucción a la cláusula
WHERE:AND trace = 'projects/PROJECT_ID/traces/TRACE_ID'En la expresión anterior, sustituye TRACE_ID por la cadena hexadecimal de 16 bytes que contiene un ID de rastreo.
Usar funciones de BigQuery ML
Puedes usar funciones de BigQuery ML, como AI.GENERATE, en las peticiones y respuestas almacenadas en tu segmento de Cloud Storage.
Por ejemplo, la siguiente consulta une las entradas del registro de finalización con la tabla externa, aplana y filtra el resultado de la unión. A continuación, la petición ejecuta AI.GENERATE para analizar si las entradas contienen una imagen y generar un resumen de cada entrada:
-- Query the linked dataset for completion logs.
FROM PROJECT_ID.LINKED_DATASET_NAME._AllLogs
|> WHERE
log_name = 'projects/PROJECT_ID/logs/gen_ai.client.inference.operation.details'
AND timestamp > TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 1 DAY)
|> SELECT
insert_id,
timestamp,
labels,
trace,
span_id,
STRING(labels['gen_ai.input.messages_ref']) AS messages_ref_uri
-- Join completion log entries with the external table.
|> JOIN `PROJECT_ID.EXT_TABLE_DATASET_NAME.EXT_TABLE_NAME`
ON messages_ref_uri = _FILE_NAME
|> RENAME `index` AS message_idx
-- Flatten.
|> CROSS JOIN UNNEST(parts) AS part WITH OFFSET AS part_idx
|> WHERE part.uri IS NOT NULL AND part.uri LIKE 'gs://%'
|> LIMIT 10
-- Use natural language to search for images, and then summarize the entry.
|> EXTEND
AI.GENERATE(
(
'Describe the attachment in one sentence and whether the image contains a diagram.',
OBJ.FETCH_METADATA(OBJ.MAKE_REF(part.uri, 'CONNECTION_LOCATION.CONNECTION_ID'))),
connection_id => 'CONNECTION_LOCATION.CONNECTION_ID',
endpoint => 'gemini-2.5-flash-lite',
output_schema => 'description STRING, is_match BOOLEAN') AS gemini_summary
|> SELECT insert_id, trace, span_id, timestamp, part_idx, part.uri, part.mime_type, gemini_summary
|> WHERE gemini_summary.is_match = TRUE
|> ORDER BY timestamp DESC
Sustituye los siguientes valores antes de ejecutar la consulta:
- PROJECT_ID: identificador del proyecto.
- LINKED_DATASET_NAME: el nombre del conjunto de datos vinculado.
- EXT_TABLE_DATASET_NAME: Nombre del conjunto de datos de la tabla externa de BigLake.
- EXT_TABLE_NAME: el nombre de la tabla externa de BigLake.
- CONNECTION_LOCATION: la ubicación de tu CONNECTION_ID.
- CONNECTION_ID: ID de la conexión.
Realizar evaluaciones en los datos de peticiones y respuestas con Colaboratory
Puedes evaluar tus peticiones y respuestas con el SDK de Vertex AI para Python.
Para ejecutar evaluaciones con un cuaderno de Google Colaboratory, haz lo siguiente:
Para ver un cuaderno de ejemplo, haz clic en
evaluating_observability_datasets.ipynb.Se abre GitHub y se muestran las instrucciones para usar el cuaderno.
Selecciona Abrir en Colab.
Se abrirá Colaboratory y se mostrará el archivo
evaluating_observability_datasets.ipynb.En la barra de herramientas, haz clic en Copiar en Drive.
Colaboratory crea un cuaderno de copia, lo guarda en tu unidad y, a continuación, abre la copia.
En tu copia, ve a la sección Set Google Cloud project information (Definir información del proyecto de Google Cloud) e introduce el Google Cloud ID del proyecto y una ubicación compatible con Vertex AI. Por ejemplo, puedes definir la ubicación como
"us-central1".Ve a la sección Cargar conjuntos de datos de IA generativa de Observabilidad de Google e introduce los valores de las siguientes fuentes:
- INPUT_SOURCE
- OUTPUT_SOURCE
- SYSTEM_SOURCE
Puede encontrar los valores de estos campos mediante las etiquetas
gen_aique están asociadas a sus entradas de registro. Por ejemplo, en el caso de INPUT_SOURCE, el valor es similar al siguiente:'gs://STORAGE_BUCKET/PATH/REFERENCE_inputs.jsonl'En la expresión anterior, los campos tienen los siguientes significados:
- STORAGE_BUCKET: nombre del segmento de Cloud Storage.
- PATH: la ruta a las peticiones y respuestas.
- REFERENCE: identificador de los datos de tu segmento de Cloud Storage.
Para obtener información sobre cómo encontrar valores de estas fuentes, consulta Buscar todas las entradas de registro que hagan referencia a peticiones y respuestas.
En la barra de herramientas, haz clic en Ejecutar todo.