
In diesem Dokument wird beschrieben, wie Sie einen LangGraph ReAct-Agenten oder einen mit dem Agent Development Kit (ADK)-Framework erstellten generativen KI-Agenten so konfigurieren, dass multimodale Prompts und Antworten an Ihr Google Cloud -Projekt gesendet werden. Außerdem wird beschrieben, wie Sie gespeicherte multimodale Medien ansehen, analysieren und bewerten können:
Auf der Seite Trace Explorer können Sie sich einzelne Prompts oder Antworten oder eine ganze Unterhaltung ansehen. Sie können die Medien gerendert oder im Rohformat ansehen. Weitere Informationen
BigQuery-Dienste zum Analysieren der multimodalen Daten verwenden Sie können beispielsweise eine Funktion wie
AI.GENERATEverwenden, um eine Unterhaltung zusammenzufassen. Weitere Informationen finden Sie unter Prompt-Antwort-Daten mit BigQuery analysieren.Verwenden Sie das Vertex AI SDK, um eine Unterhaltung zu bewerten. Sie können beispielsweise Google Colaboratory verwenden, um eine Stimmungsanalyse durchzuführen. Weitere Informationen finden Sie unter Auswertungen für Prompt-Antwort-Daten mit Colaboratory ausführen.
Arten von Media, die Sie erfassen können
Sie können die folgenden Arten von Media erfassen:
- Audio.
- Dokumente.
- Google Bilder.
- Nur-Text und Markdown-formatierter Text.
- Video.
Prompts und Antworten können Inline-Inhalte und Links enthalten. Links können entweder zu öffentlichen Ressourcen oder zu Cloud Storage-Buckets führen.
Wo werden Prompts und Antworten gespeichert?
Wenn Ihre Agent-Anwendung Prompts erstellt oder empfängt, wird durch das von Ihrer Anwendung verwendete SDK die OpenTelemetry-Instrumentierung aufgerufen. Bei dieser Instrumentierung werden die Prompts und Antworten sowie die multimodalen Daten, die sie möglicherweise enthalten, gemäß Version 1.37.0 der OpenTelemetry-Konventionen für die Semantik von GenAI formatiert. Höhere Versionen werden ebenfalls unterstützt.
Als Nächstes führt die OpenTelemetry-Instrumentierung folgende Schritte aus:
Es werden Objekt-IDs für Prompts und Antwortdaten erstellt und diese Daten werden in Ihren Cloud Storage-Bucket geschrieben. Die Einträge in Ihrem Cloud Storage-Bucket werden im JSON Lines-Format gespeichert.
Es sendet Log- und Trace-Daten an Ihr Google Cloud Projekt, wo die Logging- und Trace-Dienste die Daten aufnehmen und speichern. Die semantischen OpenTelemetry-Konventionen bestimmen viele der Attribute und Felder, die Ihren Logeinträgen oder Ihren Trace-Spans zugeordnet sind.
Wenn die OpenTelemetry-Instrumentierung Cloud Storage-Bucket-Objekte erstellt, wird auch ein Logeintrag geschrieben, der Verweise auf diese Objekte enthält. Das folgende Beispiel zeigt einen Ausschnitt eines Logeintrags, der Objektverweise enthält:
{ ... "labels": { "gen_ai.system": "vertex_ai", "event.name": "gen_ai.client.inference.operation.details", "gen_ai.output.messages_ref": "gs://my-bucket/eso9aP7NA_GX2PgPkrOi-Qg_output.jsonl", "gen_ai.system_instructions_ref": "gs://my-bucket/eso9aP7NA_GX2PgPkrOi-Qg_system_instructions.jsonl", "gen_ai.input.messages_ref": "gs://my-bucket/eso9aP7NA_GX2PgPkrOi-Qg_input.jsonl" }, "logName": "projects/my-project/logs/gen_ai.client.inference.operation.details", "trace": "projects/my-project/traces/963761020fc7713e4590cad89ad03229", "spanId": "1234512345123451", ... }Beachten Sie im Beispiel für einen Logeintrag Folgendes:
- Das Label
"event.name": "gen_ai.client.inference.operation.details"gibt an, dass der Logeintrag Verweise auf Cloud Storage-Objekte enthält. - Die Labels, deren Schlüssel
gen_aienthalten, verweisen jeweils auf ein Objekt in einem Cloud Storage-Bucket. - Alle Logeinträge, die Objektverweise enthalten, werden in dasselbe Log geschrieben, das den Namen
projects/my-project/logs/gen_ai.client.inference.operation.detailshat.
Informationen dazu, wie Sie Logeinträge mit Objektverweisen anzeigen lassen, finden Sie in diesem Dokument im Abschnitt Alle Logeinträge mit Verweisen auf Prompts und Antworten finden.
- Das Label
Multimodale Prompts und Antworten erfassen
Das von Ihrer Anwendung verwendete SDK ruft OpenTelemetry automatisch auf, um Prompts und Antworten zu speichern und Log- und Trace-Daten an Ihr Google Cloud -Projekt zu senden. Sie müssen Ihre Anwendung nicht ändern. Sie müssen jedoch IhrGoogle Cloud -Projekt und das verwendete SDK konfigurieren.
So erfassen und sehen Sie multimodale Prompts und Antworten aus einer Anwendung:
Projekt konfigurieren:
-
Prüfen Sie, ob für Ihr Google Cloud Projekt die Abrechnung aktiviert ist.
-
Aktivieren Sie die APIs Vertex AI, Cloud Storage, Telemetry, Cloud Logging und Cloud Trace.
Rollen, die zum Aktivieren von APIs erforderlich sind
Zum Aktivieren von APIs benötigen Sie die IAM-Rolle „Service Usage-Administrator“ (
roles/serviceusage.serviceUsageAdmin), die die Berechtigungserviceusage.services.enableenthält. Weitere Informationen zum Zuweisen von Rollen Prüfen Sie, ob Sie einen Cloud Storage-Bucket haben. Erstellen Sie bei Bedarf einen Cloud Storage-Bucket.
Wir empfehlen Folgendes:
Erstellen Sie den Cloud Storage-Bucket am selben Speicherort wie den Log-Bucket, in dem die Logdaten Ihrer Anwendung gespeichert sind. Diese Konfiguration macht BigQuery-Abfragen effizienter.
Prüfen Sie, ob die Speicherklasse Ihres Cloud Storage-Bucket externe Tabellen unterstützt. So können Sie Prompts und Antworten mit BigQuery abfragen. Wenn Sie nicht die Standardeinstellungen für einen neuen Cloud Storage-Bucket verwenden möchten, lesen Sie vor dem Erstellen des Buckets den Abschnitt Externe Cloud Storage-Tabellen erstellen.
Legen Sie die Aufbewahrungsdauer für Ihren Cloud Storage-Bucket so fest, dass sie der Aufbewahrungsdauer des Log-Buckets entspricht, in dem Ihre Logeinträge gespeichert werden. Die standardmäßige Aufbewahrungsdauer für Protokolldaten beträgt 30 Tage. Informationen zum Festlegen des Aufbewahrungszeitraums für Ihren Cloud Storage-Bucket finden Sie unter Bucket-Sperre.
Gewähren Sie dem Dienstkonto, das Ihre Anwendung verwendet, die Berechtigung
storage.objects.createfür Ihren Cloud Storage-Bucket. Mit dieser Berechtigung kann Ihre Anwendung Objekte in Ihren Cloud Storage-Bucket schreiben. In diesen Objekten werden die Prompts und Antworten gespeichert, die von Ihrer agentenbasierten Anwendung erstellt oder empfangen werden. Weitere Informationen finden Sie unter IAM-Richtlinien für Buckets festlegen und verwalten.
-
SDK konfigurieren:
Installieren und aktualisieren Sie die folgenden Abhängigkeiten:
ADK
google-adk>=1.16.0 opentelemetry-instrumentation-google-genai>=0.4b0 fsspec[gcs]==2025.10.0LangGraph
opentelemetry-instrumentation-vertexai>=2.2b0 opentelemetry-instrumentation-google-genai>=0.4b0 fsspec[gcs]==2025.10.0Nicht alle Versionen von
fsspecunterstützen die Erfassung von Prompts und Antworten. Die aufgeführte Version unterstützt diese Funktion. Sie können auch prüfen, ob Sie eine neuere Version verwenden können.Wenn Sie das ADK verwenden, aktualisieren Sie den Aufruf Ihrer Anwendung, um das Flag
otel_to_cloudzu aktivieren:Wenn Sie die CLI für das ADK verwenden, führen Sie den folgenden Befehl aus:
adk web --otel_to_cloud [other options]Andernfalls übergeben Sie das Flag beim Erstellen der FastAPI-App:
get_fast_api_app(..., otel_to_cloud=True)
Legen Sie die folgenden Umgebungsvariablen fest:
Weisen Sie OpenTelemetry an, Cloud Storage-Objekte als JSON Lines zu formatieren.
OTEL_INSTRUMENTATION_GENAI_UPLOAD_FORMAT='jsonl'Weisen Sie OpenTelemetry an, Prompt- und Antwortdaten hochzuladen, anstatt diese Inhalte in Trace-Spans einzubetten. Verweise auf die hochgeladenen Objekte sind in einem Logeintrag enthalten.
OTEL_INSTRUMENTATION_GENAI_COMPLETION_HOOK='upload'Weisen Sie OpenTelemetry an, die neuesten semantischen Konventionen für generative KI zu verwenden.
OTEL_SEMCONV_STABILITY_OPT_IN='gen_ai_latest_experimental'Optional: OpenTelemetry anweisen, keine Nachrichteninhalte als Attribute an Spans anzuhängen.
OTEL_INSTRUMENTATION_GENAI_CAPTURE_MESSAGE_CONTENT='NO_CONTENT'Sie müssen die vorherige Umgebungsvariable nicht festlegen. Wenn Sie das tun, empfehlen wir Ihnen, den Wert auf
NO_CONTENTfestzulegen. Informationen zu den zulässigen Werten finden Sie untergenai/types.py.Geben Sie den Pfad für Objekte an:
OTEL_INSTRUMENTATION_GENAI_UPLOAD_BASE_PATH='gs://STORAGE_BUCKET/PATH'Im vorherigen Ausdruck bezieht sich STORAGE_BUCKET auf den Namen des Cloud Storage-Bucket. PATH bezieht sich auf den Pfad, in dem Objekte gespeichert werden.
Weisen Sie OpenTelemetry für LangGraph ReAct-Agents an, Logdaten automatisch zu erfassen:
OTEL_PYTHON_LOGGING_AUTO_INSTRUMENTATION_ENABLED='true'Möglicherweise müssen Sie weitere Umgebungsvariablen festlegen. Wenn Sie beispielsweise in der Gemini Enterprise Agent Platform bereitstellen, sollten Sie auch die folgende Umgebungsvariable festlegen.
GOOGLE_CLOUD_AGENT_ENGINE_ENABLE_TELEMETRY='true'
Multimodale Prompts und Antworten ansehen
Um die Prompts und Antworten für einen Bereich zu ermitteln, führt Cloud Trace Abfragen aus, um Logdaten und Daten zu lesen, die in einem Cloud Storage-Bucket gespeichert sind. Ob Daten zurückgegeben werden, hängt von Ihren IAM-Rollen (Identity and Access Management) für die abgefragten Ressourcen ab. In einigen Fällen wird möglicherweise eine Fehlermeldung angezeigt. Wenn Sie beispielsweise keine Berechtigung zum Lesen von Daten aus einem Cloud Storage-Bucket haben, führt der Versuch, auf diese Daten zuzugreifen, zu einem Fehler vom Typ „Zugriff verweigert“.
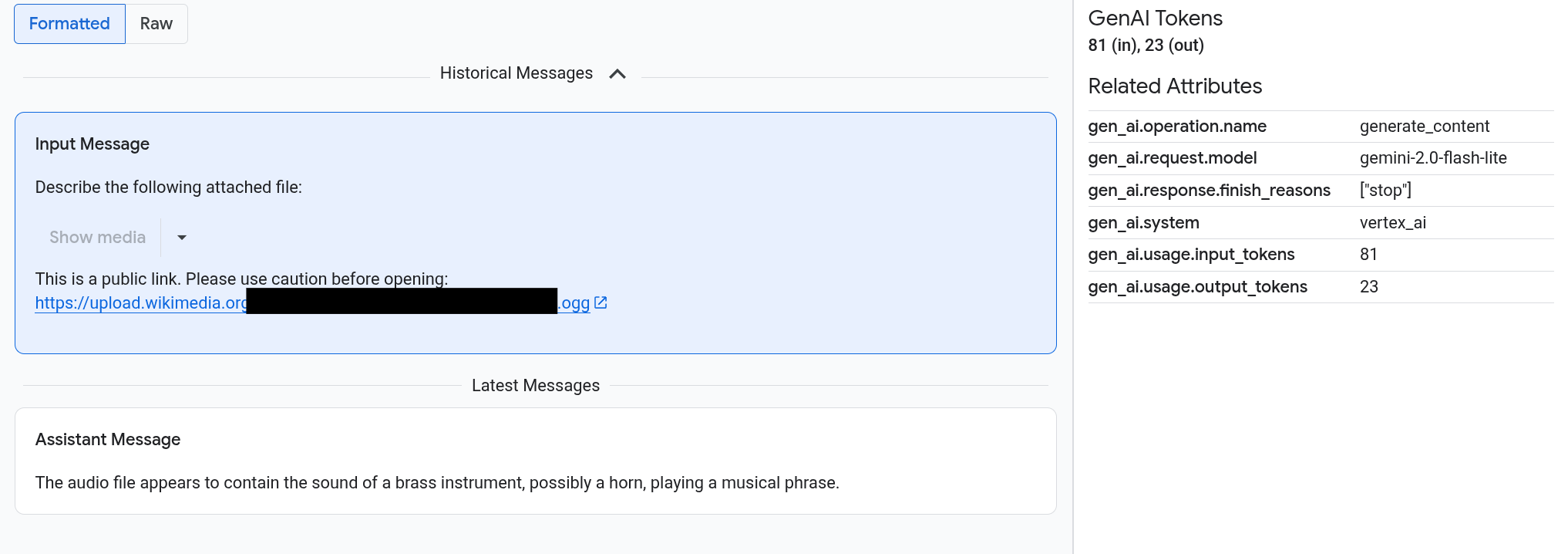
Prompts und Antworten werden in einem chatähnlichen Format angezeigt. Sie können auswählen, ob Medien wie Bilder automatisch gerendert oder im Quellformat angezeigt werden sollen. Sie können sich den gesamten Unterhaltungsverlauf oder nur die Prompts und Antworten ansehen, die einem Zeitraum zugeordnet sind.
Das folgende Beispiel zeigt, wie Prompts und Antworten dargestellt werden und wie OpenTelemetry: Attributes zusammengefasst werden:
Hinweis
Bitten Sie Ihren Administrator, Ihnen die folgenden IAM-Rollen für das Projekt zuzuweisen, um die Berechtigungen zu erhalten, die Sie zum Aufrufen multimodaler Prompts und Antworten benötigen:
- Cloud Trace-Nutzer (
roles/cloudtrace.user) - Logs Viewer (
roles/logging.viewer) - Storage-Objekt-Betrachter (
roles/storage.objectViewer)
Weitere Informationen zum Zuweisen von Rollen finden Sie unter Zugriff auf Projekte, Ordner und Organisationen verwalten.
Sie können die erforderlichen Berechtigungen auch über benutzerdefinierte Rollen oder andere vordefinierte Rollen erhalten.
Spannen mit multimodalen Prompts und Antworten finden
So finden Sie die Spannen, die multimodale Prompts und Antworten enthalten:
-
Rufen Sie in der Google Cloud Console die Seite
 Trace Explorer auf:
Trace Explorer auf:
Sie können diese Seite auch über die Suchleiste finden.
Gehen Sie im Bereich Span-Filter zum Abschnitt Span-Name und wählen Sie
generate_contentaus.Alternativ können Sie den Filter
gen_ai.operation.name: generate_contenthinzufügen.Wählen Sie einen Zeitraum aus der Liste aus.
Die Detailseite für den Span wird geöffnet. Auf dieser Seite wird der Span im Kontext des Traces angezeigt. Wenn für einen Bereichsnamen eine Schaltfläche mit dem Label Ein-/Ausgaben
 vorhanden ist, sind Ereignisse für generative KI verfügbar. Im nächsten Abschnitt Multimodale Prompts und Antworten ansehen wird erläutert, wie die Daten präsentiert werden und welche Visualisierungsoptionen es gibt.
vorhanden ist, sind Ereignisse für generative KI verfügbar. Im nächsten Abschnitt Multimodale Prompts und Antworten ansehen wird erläutert, wie die Daten präsentiert werden und welche Visualisierungsoptionen es gibt.
Multimodale Prompts und Antworten ausprobieren
Der Tab Ein-/Ausgaben enthält zwei Bereiche.
In einem Abschnitt werden die Prompts und Antworten angezeigt, im anderen OpenTelemetry: Attributes (OpenTelemetry: Attribute). Dieser Tab wird nur angezeigt, wenn Spans, die an Trace gesendet werden, den semantischen OpenTelemetry-Konventionen für generative KI (Version 1.37.0 oder höher) entsprechen. Dies führt zu Nachrichten, deren Namen mit gen_ai beginnen.
Auf dem Tab Ein-/Ausgaben werden Nachrichten in einem chatähnlichen Format angezeigt. Mit den Optionen auf dem Tab können Sie festlegen, welche Meldungen angezeigt werden und in welchem Format:
- Wenn Sie die gesamte Unterhaltung sehen möchten, maximieren Sie den Bereich Verlauf.
- Wenn Sie nur die Prompts und Antworten im ausgewählten Zeitraum sehen möchten, verwenden Sie den Bereich Letzte Nachrichten.
Wenn Sie Bilder, Videos oder andere Medien ansehen möchten, wählen Sie Formatiert aus.
Das System zeigt nicht immer Medien an. Zu Ihrem Schutz müssen Sie bestätigen, dass Sie die Medien sehen möchten, wenn in einem Prompt oder einer Antwort ein Link zu einem öffentlichen Bild, Dokument oder Video enthalten ist. Wenn ein Prompt oder eine Antwort Medien enthält, die in Ihrem Cloud Storage-Bucket gespeichert sind, und die Medien sehr groß sind, müssen Sie bestätigen, dass Sie die Medien anzeigen lassen möchten.
Einige Medien wie Bilder und Videos werden mit einem angehängten Menü angezeigt. Über dieses Menü können Sie Aktionen wie das Herunterladen eines Bildes auf ein lokales Laufwerk ausführen. Die Menüoptionen hängen vom Medientyp ab.
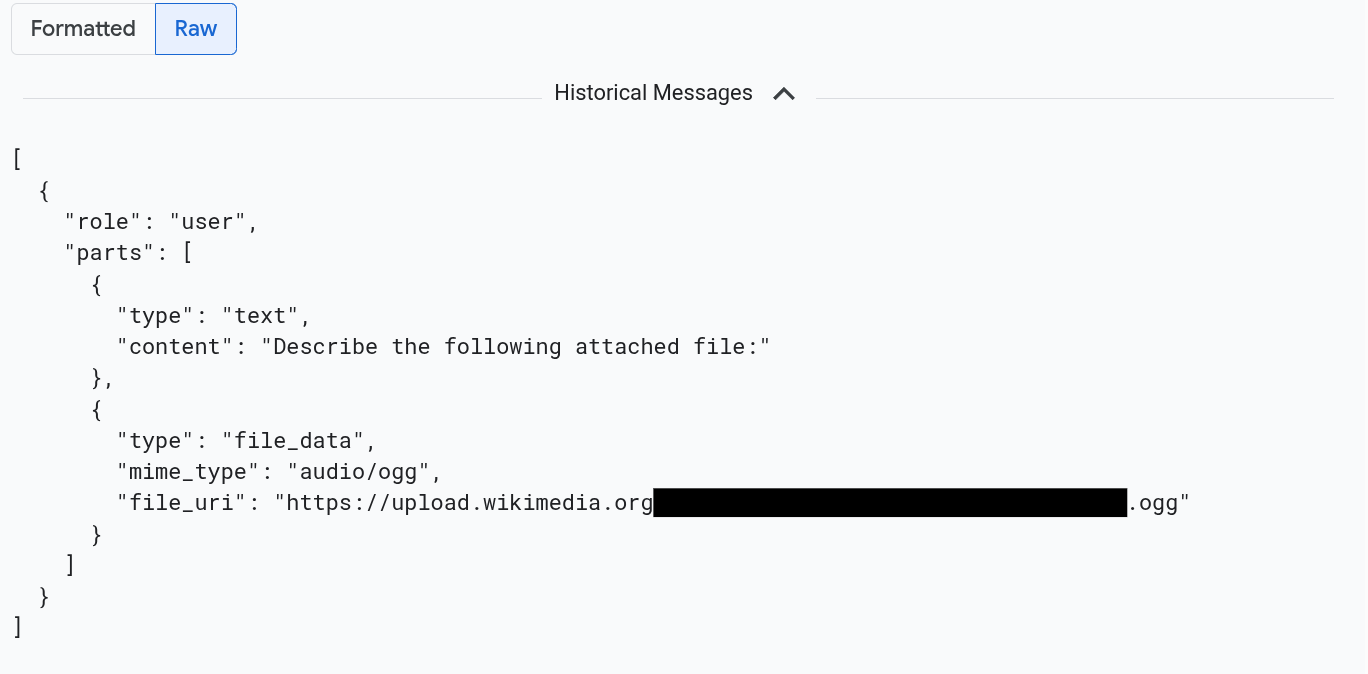
Wenn Sie die Nachrichten im JSON-Format sehen möchten, wählen Sie Roh aus. Bei dieser Auswahl werden keine Medien wie Bilder gerendert.
Das folgende Bild zeigt beispielsweise, wie eine Unterhaltung im Rohformat aussieht:
Alle Logeinträge finden, die sich auf Prompts und Antworten beziehen
So listen Sie die Logeinträge auf, die Objektverweise auf multimodale Prompts und Antworten enthalten:
-
Rufen Sie in der Google Cloud Console das und die Seite Log-Explorer auf:
Wenn Sie diese Seite über die Suchleiste suchen, wählen Sie das Ergebnis mit der Zwischenüberschrift Logging aus.
Wählen Sie in der Projektauswahl Ihr Google Cloud -Projekt aus.
Maximieren Sie in der Symbolleiste Alle Lognamen, geben Sie
gen_aiin den Filter ein und wählen Sie dann das Log mit dem Namen gen_ai.client.inference.operation.details aus.Durch die vorherigen Schritte wird dem Log-Explorer die folgende Abfrage hinzugefügt:
logName="projects/PROJECT_ID/logs/gen_ai.client.inference.operation.details"Sie können die Anweisung auch kopieren und in den Bereich Abfrage des Log-Explorers einfügen. Ersetzen Sie jedoch PROJECT_ID durch Ihre Projekt-ID, bevor Sie die Anweisung kopieren.
Sie können Logdaten auch nach Labelwert filtern. Wenn Sie beispielsweise den folgenden Filter hinzufügen, werden nur Logeinträge angezeigt, die das angegebene Label enthalten:
labels."event.name"="gen_ai.client.inference.operation.details"Wenn Sie die Prompts und Antworten aufrufen möchten, auf die in einem Logeintrag verwiesen wird, klicken Sie im Logeintrag auf
Trace-Details ansehen.Informationen zur Verwendung der Optionen auf dem Tab Ein-/Ausgaben finden Sie im Abschnitt Multimodale Prompts und Antworten untersuchen in diesem Dokument.
Prompt-Antwort-Daten mit BigQuery analysieren
Sie können die Prompts und Antworten, die in Ihrem Cloud Storage-Bucket gespeichert sind, mit BigQuery analysieren. Führen Sie vor dieser Analyse die folgenden Schritte aus:
- Aktivieren Sie die erforderlichen APIs und prüfen Sie, ob Sie die erforderlichen IAM-Rollen haben.
- Erstellen Sie ein verknüpftes Dataset für Ihren Log-Bucket.
- Erteilen Sie BigQuery die Berechtigung, Daten aus Ihrem Cloud Storage-Bucket zu lesen.
- Erstellen Sie eine externe Tabelle.
Nachdem Sie die externe Tabelle erstellt haben, führen Sie die Daten in Ihrem Log-Bucket mit der externen Tabelle zusammen und analysieren die zusammengeführten Daten. In diesem Abschnitt wird veranschaulicht, wie Sie Ihre Tabellen zusammenführen und bestimmte Felder extrahieren. Außerdem wird gezeigt, wie die verknüpfte Tabelle mit BigQuery ML-Funktionen analysiert wird.
Hinweis
Die in diesem Abschnitt aufgeführten IAM-Rollen sind erforderlich, um Aktionen wie das Aktualisieren eines Log-Buckets und das Erstellen einer externen Tabelle auszuführen. Nach Abschluss der Konfiguration sind jedoch weniger Berechtigungen zum Ausführen von Abfragen erforderlich.
-
Aktivieren Sie die BigQuery API und die BigQuery Connection API.
Rollen, die zum Aktivieren von APIs erforderlich sind
Zum Aktivieren von APIs benötigen Sie die IAM-Rolle „Service Usage-Administrator“ (
roles/serviceusage.serviceUsageAdmin), die die Berechtigungserviceusage.services.enableenthält. Weitere Informationen zum Zuweisen von Rollen -
Bitten Sie Ihren Administrator, Ihnen die folgenden IAM-Rollen für das Projekt zuzuweisen, um die Berechtigungen zu erhalten, die Sie zum Konfigurieren des Systems benötigen, damit Sie multimodale Prompts und Antworten in BigQuery ansehen können:
- Autor von Log-Konfigurationen (
roles/logging.configWriter) - Storage-Administrator (
roles/storage.admin) - BigQuery Connection Admin (
roles/bigquery.connectionAdmin) - BigQuery Data Viewer (
roles/bigquery.dataViewer) - BigQuery Studio User (
roles/bigquery.studioUser)
Weitere Informationen zum Zuweisen von Rollen finden Sie unter Zugriff auf Projekte, Ordner und Organisationen verwalten.
Sie können die erforderlichen Berechtigungen auch über benutzerdefinierte Rollen oder andere vordefinierte Rollen erhalten.
- Autor von Log-Konfigurationen (
Verknüpftes Dataset für Ihren Log-Bucket erstellen
Führen Sie den folgenden Befehl aus, um zu ermitteln, ob für den Log-Bucket, in dem Ihre Logdaten gespeichert sind, ein Upgrade für Observability Analytics durchgeführt wurde:
gcloud logging buckets describe LOG_BUCKET_ID --location=LOCATIONErsetzen Sie vor dem Ausführen des Befehls Folgendes:
- LOG_BUCKET_ID: Die ID des Log-Buckets.
- LOCATION: der Speicherort des Log-Buckets
Wenn ein Log-Bucket für Observability Analytics aktualisiert wird, enthalten die Ergebnisse des
describe-Befehls die folgende Anweisung:analyticsEnabled: trueWenn Ihr Log-Bucket nicht aktualisiert wurde, führen Sie den folgenden Befehl aus:
gcloud logging buckets update LOG_BUCKET_ID --location=LOCATION --enable-analytics --asyncDas Upgrade kann mehrere Minuten dauern. Wenn der Befehl
describefürlifecycleStateden StatusACTIVEmeldet, ist das Upgrade abgeschlossen.Führen Sie den folgenden Befehl aus, um ein verknüpftes Dataset für Ihren Log-Bucket zu erstellen:
gcloud logging links create LINKED_DATASET_NAME --bucket=LOG_BUCKET_ID --location=LOCATIONErsetzen Sie vor dem Ausführen des Befehls Folgendes:
- LOG_BUCKET_ID: Die ID des Log-Buckets.
- LOCATION: der Speicherort des Log-Buckets
- LINKED_DATASET_NAME: Name des zu erstellenden verknüpften Datasets.
Mit dem verknüpften Dataset kann BigQuery die Logdaten lesen, die in Ihrem Log-Bucket gespeichert sind. Weitere Informationen
Führen Sie den folgenden Befehl aus, um zu prüfen, ob der Link vorhanden ist:
gcloud logging links list --bucket=LOG_BUCKET_ID --location=LOCATIONBei Erfolg enthält die Antwort auf den vorherigen Befehl die folgende Zeile:
LINK_ID: LINKED_DATASET_NAME
BigQuery die Berechtigung zum Lesen aus Ihrem Cloud Storage-Bucket erteilen
Führen Sie den folgenden Befehl aus, um eine BigQuery-Verbindung zu erstellen:
bq mk --connection --location=CONNECTION_LOCATION --project_id=PROJECT_ID \ --connection_type=CLOUD_RESOURCE CONNECTION_IDErsetzen Sie vor dem Ausführen des Befehls Folgendes:
- PROJECT_ID: Die Kennung des Projekts.
- CONNECTION_ID: Die ID der Verbindung, die erstellt werden soll.
- CONNECTION_LOCATION: der Standort der Verbindung
Bei erfolgreicher Befehlsausführung wird eine Meldung angezeigt, die etwa so aussieht:
Connection 151560119848.CONNECTION_LOCATION.CONNECTION_ID successfully createdPrüfen Sie die Verbindung.
bq show --connection PROJECT_ID.CONNECTION_LOCATION.CONNECTION_IDDie Antwort auf diesen Befehl enthält die Verbindungs-ID und ein Dienstkonto:
{"serviceAccountId": "bqcx-151560119848-s1pd@gcp-sa-bigquery-condel.iam.gserviceaccount.com"}Weisen Sie dem Dienstkonto für die BigQuery-Verbindung eine IAM-Rolle zu, mit der es Daten lesen kann, die in Ihrem Cloud Storage-Bucket gespeichert sind:
gcloud storage buckets add-iam-policy-binding gs://STORAGE_BUCKET \ --member=serviceAccount:SERVICE_ACCT_EMAIL \ --role=roles/storage.objectViewerErsetzen Sie vor dem Ausführen des Befehls Folgendes:
- STORAGE_BUCKET: Der Name Ihres Cloud Storage-Buckets
- SERVICE_ACCT_EMAIL: Die E-Mail-Adresse Ihres Dienstkontos.
Externe BigLake-Tabelle erstellen
Wenn Sie mit BigQuery Daten abfragen möchten, die nicht in BigQuery gespeichert sind, erstellen Sie eine externe Tabelle. Da in einem Cloud Storage-Bucket die Prompts und Antworten gespeichert werden, erstellen Sie eine externe BigLake-Tabelle.
-
Rufen Sie in der Google Cloud Console die Seite "BigQuery" auf.
Sie können diese Seite auch über die Suchleiste finden.
Geben Sie im Abfrageeditor die folgende Anweisung ein:
CREATE OR REPLACE EXTERNAL TABLE `PROJECT_ID.EXT_TABLE_DATASET_NAME.EXT_TABLE_NAME` ( -- Schema matching the JSON structure in a Cloud Storage bucket. parts ARRAY< STRUCT< type STRING, content STRING, -- multimodal attachments mime_type STRING, uri STRING, data BYTES, -- tool calls id STRING, name STRING, arguments JSON, response JSON > >, role STRING, `index` INT64, ) WITH CONNECTION `PROJECT_ID.CONNECTION_LOCATION.CONNECTION_ID` OPTIONS ( format = 'NEWLINE_DELIMITED_JSON', uris = ['gs://STORAGE_BUCKET/PATH/*'], ignore_unknown_values = TRUE );Ersetzen Sie vor dem Ausführen des Befehls Folgendes:
- PROJECT_ID: Die Kennung des Projekts.
- EXT_TABLE_DATASET_NAME: Der Name des zu erstellenden Datasets.
- EXT_TABLE_NAME: Der Name der externen BigLake-Tabelle, die erstellt werden soll.
- CONNECTION_LOCATION: Der Standort Ihres CONNECTION_ID.
- CONNECTION_ID: Die ID der Verbindung.
- STORAGE_BUCKET: Der Name des Cloud Storage-Bucket.
- PATH: Der Pfad zu den Prompts und Antworten. Die Umgebungsvariable
OTEL_INSTRUMENTATION_GENAI_UPLOAD_BASE_PATHgibt den Pfad an.
Klicken Sie auf Ausführen.
Weitere Informationen zu externen Tabellen finden Sie unter:
Externe Tabelle mit Ihren Logdaten zusammenführen
In diesem Abschnitt wird veranschaulicht, wie Sie multimodale Prompts in BigQuery analysieren können. Die Lösung basiert darauf, Ihre externe BigLake-Tabelle mit Ihren Logdaten zu verknüpfen. So können Sie Objekte aus Ihrem Cloud Storage-Bucket abrufen. Im Beispiel wird der URI für die Eingabenachrichten, gen_ai.input.messages, verwendet. Sie können auch den URI für die Ausgabenachrichten (gen_ai.output.messages) oder die Systemanweisungen (gen_ai.system_instructions) verwenden.
So verknüpfen Sie Ihre externe BigLake-Tabelle mit Ihren Logdaten:
-
Rufen Sie in der Google Cloud Console die Seite "BigQuery" auf.
Sie können diese Seite auch über die Suchleiste finden.
Geben Sie im Abfrageeditor die folgende Abfrage ein, mit der Ihre Logdaten und Ihre externe Tabelle über den Pfad zu den Cloud Storage-Bucket-Einträgen verknüpft werden:
-- Query the linked dataset for completion logs. FROM-- Join completion log entries with the external table. |> JOIN `PROJECT_ID.EXT_TABLE_DATASET_NAME.EXT_TABLE_NAME` ON messages_ref_uri = _FILE_NAME |> RENAME `index` AS message_idx -- Flatten. |> CROSS JOIN UNNEST(parts) AS part WITH OFFSET AS part_idx -- Print fields. |> SELECT insert_id, labels, timestamp, trace, span_id, role, part.content, part.uri, part.mime_type, TO_HEX(MD5(part.data)) AS data_md5_hex, part.id AS tool_id, part.name AS tool_name, part.arguments AS tool_args, part.response AS tool_response, message_idx, part_idx, |> ORDER BY timestamp, message_idx, part_idx; |> LIMIT 10;PROJECT_ID.LINKED_DATASET_NAME._AllLogs|> WHERE log_name = 'projects/PROJECT_ID/logs/gen_ai.client.inference.operation.details' AND timestamp > TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 1 DAY) |> SELECT insert_id, timestamp, labels, trace, span_id, STRING(labels['gen_ai.input.messages_ref']) AS messages_ref_uriErsetzen Sie vor dem Ausführen der Abfrage Folgendes:
- PROJECT_ID: Die Kennung des Projekts.
- LINKED_DATASET_NAME: Der Name des verknüpften Datasets.
- EXT_TABLE_DATASET_NAME: Der Name des Datasets für die externe BigLake-Tabelle.
- EXT_TABLE_NAME: Der Name der externen BigLake-Tabelle.
Optional: Die vorherige Abfrage wird nach Logname und Zeitstempel gefiltert. Wenn Sie auch nach einer bestimmten Trace-ID filtern möchten, fügen Sie der
WHERE-Klausel die folgende Anweisung hinzu:AND trace = 'projects/PROJECT_ID/traces/TRACE_ID'Ersetzen Sie im vorherigen Ausdruck TRACE_ID durch den 16‑Byte-Hexadezimalstring, der eine Trace-ID enthält.
BigQuery ML-Funktionen verwenden
Sie können BigQuery ML-Funktionen wie AI.GENERATE für die Prompts und Antworten verwenden, die in Ihrem Cloud Storage-Bucket gespeichert sind.
In der folgenden Abfrage werden beispielsweise die Einträge im Vervollständigungsprotokoll mit der externen Tabelle zusammengeführt. Das Ergebnis wird vereinfacht und gefiltert. Als Nächstes wird mit dem Prompt AI.GENERATE ausgeführt, um zu analysieren, ob Einträge ein Bild enthalten, und um eine Zusammenfassung der einzelnen Einträge zu erstellen:
-- Query the linked dataset for completion logs.
FROM PROJECT_ID.LINKED_DATASET_NAME._AllLogs
|> WHERE
log_name = 'projects/PROJECT_ID/logs/gen_ai.client.inference.operation.details'
AND timestamp > TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 1 DAY)
|> SELECT
insert_id,
timestamp,
labels,
trace,
span_id,
STRING(labels['gen_ai.input.messages_ref']) AS messages_ref_uri
-- Join completion log entries with the external table.
|> JOIN `PROJECT_ID.EXT_TABLE_DATASET_NAME.EXT_TABLE_NAME`
ON messages_ref_uri = _FILE_NAME
|> RENAME `index` AS message_idx
-- Flatten.
|> CROSS JOIN UNNEST(parts) AS part WITH OFFSET AS part_idx
|> WHERE part.uri IS NOT NULL AND part.uri LIKE 'gs://%'
|> LIMIT 10
-- Use natural language to search for images, and then summarize the entry.
|> EXTEND
AI.GENERATE(
(
'Describe the attachment in one sentence and whether the image contains a diagram.',
OBJ.FETCH_METADATA(OBJ.MAKE_REF(part.uri, 'CONNECTION_LOCATION.CONNECTION_ID'))),
connection_id => 'CONNECTION_LOCATION.CONNECTION_ID',
endpoint => 'gemini-2.5-flash-lite',
output_schema => 'description STRING, is_match BOOLEAN') AS gemini_summary
|> SELECT insert_id, trace, span_id, timestamp, part_idx, part.uri, part.mime_type, gemini_summary
|> WHERE gemini_summary.is_match = TRUE
|> ORDER BY timestamp DESC
Ersetzen Sie vor dem Ausführen der Abfrage Folgendes:
- PROJECT_ID: Die Kennung des Projekts.
- LINKED_DATASET_NAME: Der Name des verknüpften Datasets.
- EXT_TABLE_DATASET_NAME: Der Name des Datasets für die externe BigLake-Tabelle.
- EXT_TABLE_NAME: Der Name der externen BigLake-Tabelle.
- CONNECTION_LOCATION: Der Standort Ihres CONNECTION_ID.
- CONNECTION_ID: Die ID der Verbindung.
Bewertungen der Prompt-Antwort-Daten mit Colaboratory ausführen
Sie können Prompts und Antworten mit dem Vertex AI SDK für Python bewerten.
So führen Sie Auswertungen mit einem Google Colaboratory-Notebook aus:
Wenn Sie ein Beispiel-Notebook aufrufen möchten, klicken Sie auf
evaluating_observability_datasets.ipynb.GitHub wird geöffnet und zeigt eine Anleitung zur Verwendung des Notebooks an.
Wählen Sie In Colab öffnen aus.
Colaboratory wird geöffnet und die Datei
evaluating_observability_datasets.ipynbwird angezeigt.Klicken Sie in der Symbolleiste auf In Drive kopieren.
Colaboratory erstellt eine Kopie des Notebooks, speichert sie auf Ihrer Festplatte und öffnet sie dann.
Rufen Sie in Ihrer Kopie den Abschnitt Informationen zum Google Cloud-Projekt festlegen auf und geben Sie Ihre Google Cloud Projekt-ID und einen von Vertex AI unterstützten Standort ein. Sie können den Speicherort beispielsweise auf
"us-central1"festlegen.Rufen Sie den Abschnitt Gen AI-Datasets in Google Observability laden auf und geben Sie Werte für die folgenden Quellen ein:
- INPUT_SOURCE
- OUTPUT_SOURCE
- SYSTEM_SOURCE
Sie können die Werte für diese Felder mithilfe der
gen_ai-Labels finden, die Ihren Logeinträgen zugeordnet sind. Für INPUT_SOURCE sieht der Wert beispielsweise so aus:'gs://STORAGE_BUCKET/PATH/REFERENCE_inputs.jsonl'Im vorherigen Ausdruck haben die Felder die folgende Bedeutung:
- STORAGE_BUCKET: Der Name des Cloud Storage-Bucket.
- PATH: Der Pfad zu den Prompts und Antworten.
- REFERENCE: Die Kennung der Daten in Ihrem Cloud Storage-Bucket.
Informationen zum Ermitteln von Werten für diese Quellen finden Sie unter Alle Logeinträge mit Verweisen auf Prompts und Antworten finden.
Klicken Sie in der Symbolleiste auf Alle ausführen.