
En esta página, se describe cómo puedes usar el panel de Estadísticas del sistema de Cloud SQL. El panel de Estadísticas del sistema muestra métricas para los recursos que usa tu instancia y te ayuda a detectar y analizar problemas de rendimiento del sistema.
Puedes usar la asistencia de Gemini in Databases para observar y solucionar problemas de tus recursos de Cloud SQL para PostgreSQL. Para obtener más información, consulta Observa y soluciona problemas con la asistencia de Gemini.Visualiza el panel de Estadísticas del sistema
Para ver el panel de Estadísticas del sistema, haz lo siguiente:
-
En la consola de Google Cloud , ve a la página Instancias de Cloud SQL.
- Haz clic en el nombre de una instancia.
Selecciona la pestaña Estadísticas del sistema en el panel de navegación de SQL a la izquierda.
Se abrirá el panel de Estadísticas del sistema.
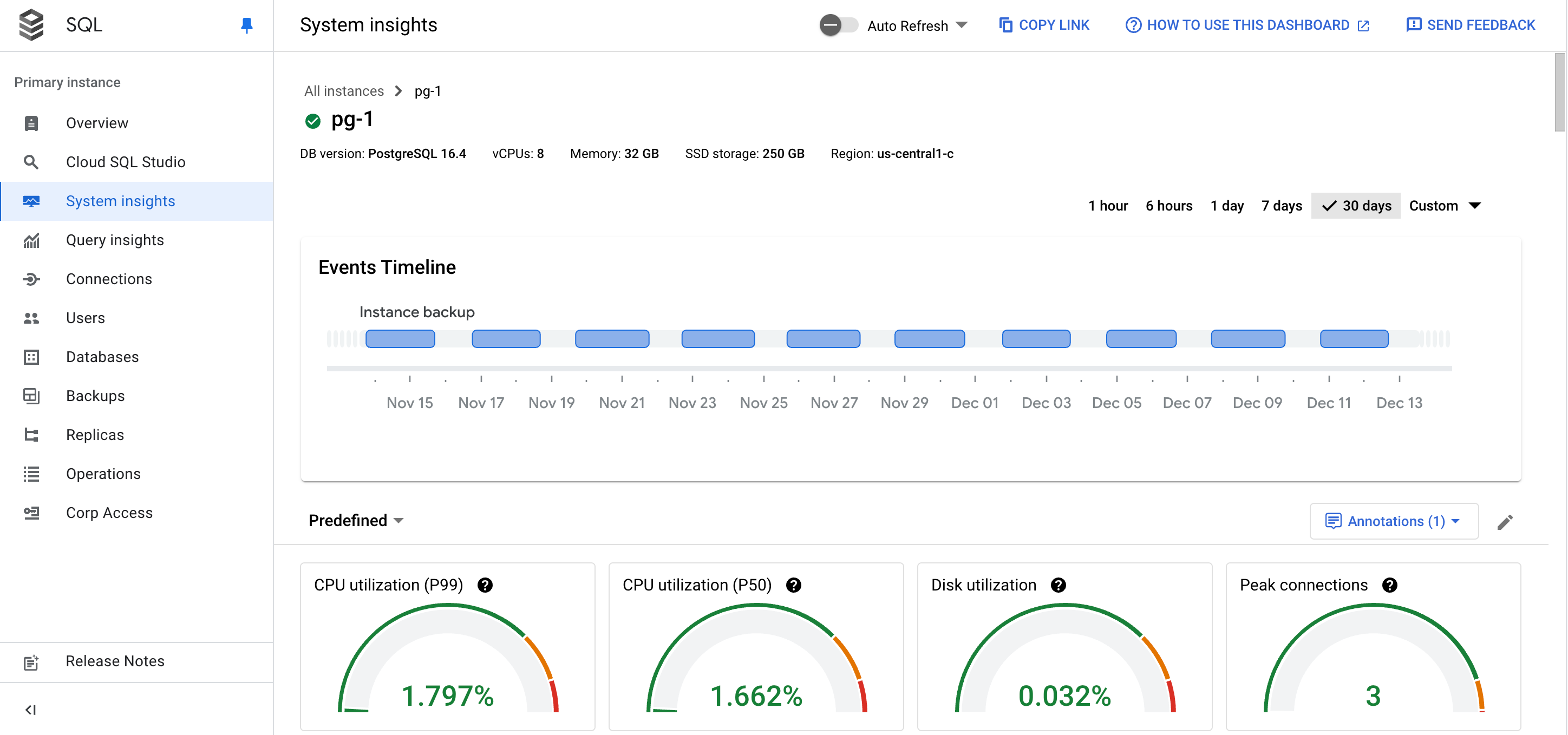
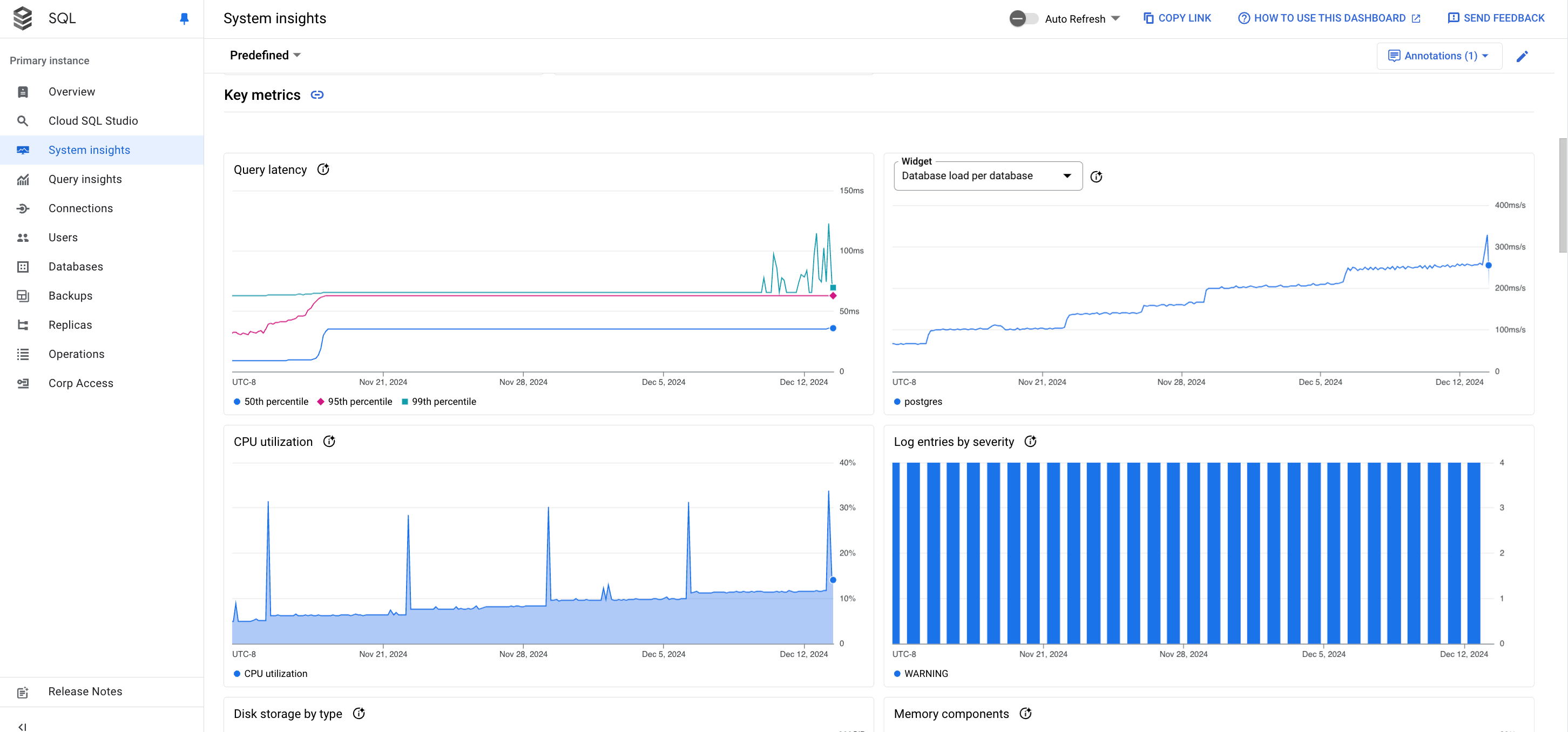
En el panel de Estadísticas del sistema, se muestra la siguiente información:
Detalles de la instancia
Cronograma de eventos: Muestra los eventos del sistema en orden cronológico. Esta información te ayuda a evaluar el impacto de los eventos del sistema en el estado y el rendimiento de la instancia.
Tarjetas de resumen: Proporcionan una descripción general del estado y el rendimiento de la instancia mostrando los valores más recientes y agregados del uso de CPU, el uso del disco y las métricas de errores de registro.
Gráficos de métricas: Muestran información sobre el sistema operativo y las métricas de la base de datos que te ayudan a obtener estadísticas sobre varios problemas, como la capacidad de procesamiento, la latencia y el costo.
El panel ofrece las siguientes opciones de alto nivel:
- Para ver uno o dos gráficos por fila Haz clic en Personalizar vista para elegir cómo se muestran estos gráficos. También puedes usar esta opción para elegir las métricas que se mostrarán en el panel.
Para mantener el panel actualizado, habilita la opción
 Actualización automática. Cuando habilitas la Actualización automática, los datos del panel se actualizan cada minuto. Esta función no es compatible con los períodos personalizados.
Actualización automática. Cuando habilitas la Actualización automática, los datos del panel se actualizan cada minuto. Esta función no es compatible con los períodos personalizados.El selector de hora muestra
1 dayseleccionado de forma predeterminada. Para cambiar el período, selecciona uno de los otros períodos predefinidos o haz clic en Personalizado y define una hora de inicio y de finalización. Los datos están disponibles para los últimos 30 días.Para crear un vínculo absoluto al panel, haz clic en el botón Copiar vínculo. Puedes compartir este vínculo con otros usuarios de Cloud SQL que tengan los mismos permisos.
Para crear una alerta para un evento específico, haz clic en Notificación.
Para mostrar alertas específicas, haz clic en Anotaciones.
Tarjetas de resumen
En la siguiente tabla, se describen las tarjetas de resumen que se muestran en la parte superior del panel de Estadísticas del sistema. Estas tarjetas proporcionan una breve descripción general del estado y el rendimiento de la instancia durante el período elegido.
| Tarjeta de resumen | Descripción |
|---|---|
| Uso de CPU: P99 y P50 | Los valores de uso de CPU P99 y P50 durante el período seleccionado. |
| Conexiones máximas | La proporción entre las conexiones máximas totales y las del período seleccionado.
El recuento de conexiones máximas podría ser mayor que el recuento máximo en caso de que el recuento máximo haya cambiado hace poco, por ejemplo, debido al escalamiento de la instancia o a la configuración max_connections manual. |
| Uso de ID de transacción | El valor de uso del ID de transacción más reciente del período seleccionado. |
| Uso de disco | El valor de uso del disco más reciente. |
| Errores de registro | Es la cantidad de errores que registran los usuarios. |
Gráficos de métricas
Aparecerá una tarjeta del gráfico para una métrica de muestra de la siguiente manera.
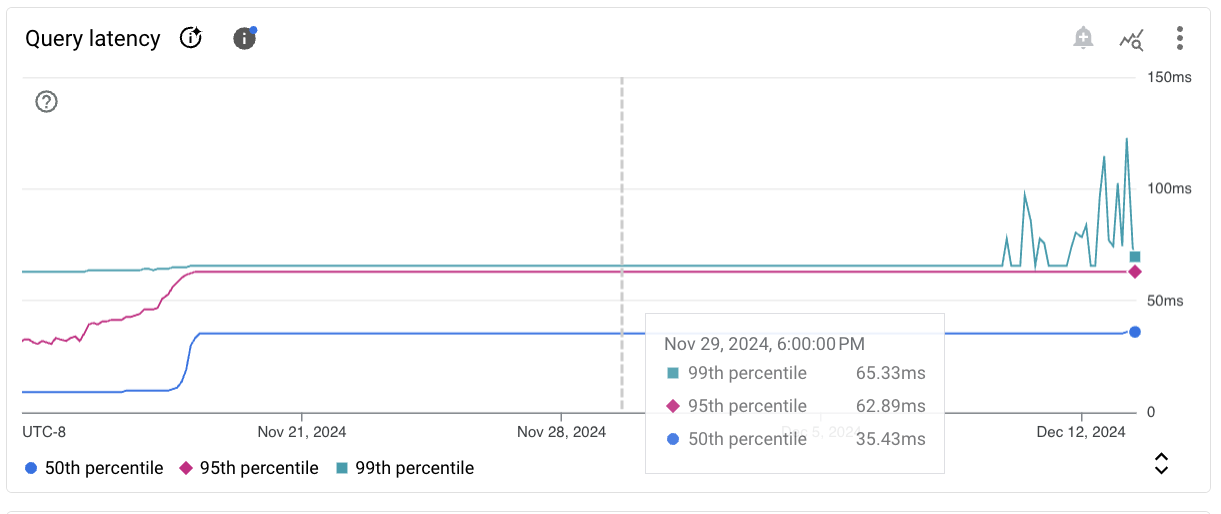
La barra de herramientas en cada tarjeta del gráfico proporciona el siguiente conjunto de opciones estándar:
Para ver los valores de las métricas de un momento específico en el período seleccionado, mueve el cursor sobre el gráfico.
Para acercar un gráfico, haz clic en él y arrastra horizontalmente a lo largo del eje X o verticalmente a lo largo del eje Y. Para revertir la operación de zoom, haz clic en Restablecer zoom. También puedes hacer clic en uno de los períodos predefinidos que se encuentran en la parte superior del panel. Las operaciones de zoom se aplican al mismo tiempo a todos los gráficos en un panel.
Para ver opciones adicionales, haz clic en more_vert Más opciones de gráfico. La mayoría de los gráficos ofrecen estas opciones:
Para ver un gráfico en el modo de pantalla completa, haz clic en Ver en pantalla completa. Para salir del modo de pantalla completa, haz clic en Cancelar.
Oculta o contrae la leyenda.
Descargar un archivo PNG o CSV del gráfico
Ver en el Explorador de métricas. Visualiza la métrica en el Explorador de métricas. Puedes ver otras métricas de Cloud SQL en el Explorador de métricas después de seleccionar el tipo de recurso Base de datos de Cloud SQL.
Para crear un panel personalizado, haz clic en edit Personalizar panel y asígnale un nombre. O bien, expande el menú Predefinido y selecciona un panel personalizado existente.
Para ver los datos de un gráfico de métricas en detalle, haz clic en query_stats Explorar datos. Aquí, puedes filtrar métricas específicas y elegir cómo se muestra el gráfico:

Para guardar esta vista personalizada como un gráfico de métricas, haz clic en Guardar en el panel.
Métricas predeterminadas
En la siguiente tabla, se describen las métricas de Cloud SQL que aparecen de forma predeterminada en el panel de estadísticas del sistema de Cloud SQL.
Las strings de tipo de métrica siguen este prefijo: cloudsql.googleapis.com/database/.
Para conocer la disponibilidad más reciente de las siguientes métricas en la etapa de lanzamiento, consulta las métricas deGoogle Cloud .
| Nombre y tipo de métrica | Descripción |
|---|---|
Conexiones nuevas por segundopostgresql/new_connection_count
|
La cantidad de conexiones nuevas que creas en tu instancia de Cloud SQL para PostgreSQL por segundo. Cloud SQL calcula y muestra esta métrica por base de datos. Esta métrica está disponible para la versión 14 y posteriores de PostgreSQL. |
Tipos de eventos de espera
postgresql/backends_in_wait
|
La cantidad de conexiones para cada tipo de evento de espera en una instancia de Cloud SQL para PostgreSQL. |
Eventos de esperapostgresql/backends_in_wait
|
La cantidad de eventos de espera en una instancia de Cloud SQL para PostgreSQL. En el panel, se muestra esta métrica como nombre del evento de espera:tipo de evento de espera. |
Cantidad de transaccionespostgresql/transaction_count
|
La cantidad de transacciones en los estados |
Componentes de la memoriamemory/components
|
Los componentes de memoria disponibles para la base de datos. El valor de cada componente de la memoria se calcula como el porcentaje de la memoria total disponible para la base de datos. |
Retraso máximo de bytes de réplicaspostgresql/external_sync/max_replica_byte_lag
|
El retraso máximo de la replicación (en bytes) entre todas las bases de datos de la réplica del servidor externo (ES). |
Latencia de las consultaspostgresql/insights/aggregate/latencies |
Distribución de latencia de consultas agregada según P99, P95 y P50 por usuario y base de datos. Solo disponible para instancias con Estadísticas de consultas habilitadas. |
Carga de la base de datos por dirección de cliente, usuario o base de datospostgresql/insights/aggregate/execution_time |
El tiempo acumulado de ejecución de consultas por dirección del cliente, usuario o base de datos. Es la suma del tiempo de CPU, el tiempo de espera de E/S, el tiempo de espera de bloqueo, el cambio de contexto de procesos y la programación de todos los procesos involucrados en la ejecución de consultas. Solo disponible para instancias con Estadísticas de consultas habilitadas. |
Uso de CPUcpu/utilization |
El uso de CPU actual representado como un porcentaje de la CPU reservada que está en uso. |
Almacenamiento en disco por tipodisk/bytes_used_by_data_type |
El desglose del uso del disco de la instancia por tipos de datos, incluidos Esta métrica te ayuda a comprender los costos de almacenamiento. Para obtener más información sobre los cargos por el uso de almacenamiento, consulta los Precios de almacenamiento y herramientas de redes. La recuperación de un momento determinado (PITR) usa el archivo de registro de escritura por adelantado (WAL). Estos registros se actualizan periódicamente y usan espacio de almacenamiento. Los registros de escritura por adelantado se borran de forma automática con su copia de seguridad automática asociada, lo que suele ocurrir después de 7 días. Si el tamaño de tus registros de escritura por adelantado genera un problema en tu instancia, puedes aumentar el tamaño del almacenamiento, pero el aumento del espacio que ocupa el registro de escritura por adelantado en el disco puede ser temporal. Para evitar problemas de almacenamiento inesperados, Google recomienda habilitar los aumentos de almacenamiento automáticos cuando usas PITR. Para borrar los registros y recuperar almacenamiento, puedes inhabilitar la recuperación de un momento determinado. Sin embargo, ten en cuenta que disminuir el almacenamiento en uso no reduce el tamaño del almacenamiento aprovisionado para la instancia. Dentro de la métrica de uso del almacenamiento, se incluyen datos temporales. Los datos temporales se quitan como parte del mantenimiento y pueden aumentar más allá de los límites de capacidad definidos por el usuario con el fin de evitar un evento de disco completo. No se le cobra por esto al usuario. Una base de datos nueva usa alrededor de 100 MB para las tablas y los archivos del sistema. |
Almacenamiento en disco por tipodisk/bytes_used_by_data_type |
El desglose del uso del disco de la instancia por tipos de datos, incluidos Esta métrica te ayuda a comprender los costos de almacenamiento. Para obtener más información sobre los cargos por el uso de almacenamiento, consulta los Precios de almacenamiento y herramientas de redes. La recuperación de un momento determinado usa el archivo de registro de escritura por adelantado (WAL). En el caso de las instancias nuevas de Cloud SQL que tengan habilitada la recuperación de un momento determinado o de las instancias existentes que habiliten la recuperación de un momento determinado después de que esté disponible esta función para almacenar registros WAL en Cloud Storage, los registros ya no se almacenarán en el disco, sino que se almacenarán enCloud Storage en la misma región que las instancias. Para ver si los registros de una instancia se almacenan en Cloud Storage, verifica la métrica bytes_used_by_data_type de la instancia. Si el valor para el tipo de datos Todas las demás instancias existentes que tengan habilitada la recuperación de un momento determinado seguirán teniendo sus registros almacenados en el disco. El cambio al almacenamiento de registros en Cloud Storage estará disponible más adelante. Los registros de escritura por adelantado que se usan con la recuperación de un momento determinado se borran de forma automática con su copia de seguridad automática asociada, lo que suele ocurrir después de que se cumple el valor establecido para transactionLogRetentionDays. Esta es la cantidad de días de registros de transacciones que Cloud SQL conserva para la recuperación de un momento determinado, del 1 al 7. En las instancias con registros de escritura por adelantado almacenados en Cloud Storage, los registros se almacenan en la misma región que la instancia principal. Este almacenamiento de registros (hasta siete días, la duración máxima para la recuperación de un momento determinado) no genera costos adicionales por instancia. Si la instancia tiene habilitada la recuperación de un momento determinado y si el tamaño de los registros de escritura por adelantado en el disco está causando un problema en la instancia, inhabilita la recuperación de un momento determinado y vuelve a habilitarla para garantizar que los registros nuevos se almacenen en Cloud Storage en la misma región que la instancia. Esto borra los registros de escritura anticipada existentes, por lo que no puedes realizar un restablecimiento de un momento determinado antes del momento en el que vuelves a habilitar la recuperación de un momento determinado. Sin embargo, aunque los registros existentes se borran, el tamaño del disco sigue siendo el mismo. A fin de evitar problemas de almacenamiento inesperados, te recomendamos habilitar el aumento del almacenamiento automático para todas las instancias cuando se use la recuperación de un momento determinado. Esta recomendación aplica solo si la instancia tiene habilitada la recuperación de un momento determinado y los registros se almacenan en el disco. Para borrar los registros y recuperar almacenamiento, puedes inhabilitar la recuperación de un momento determinado. Sin embargo, ten en cuenta que disminuir los registros de escritura por adelantado usados no reduce el tamaño del disco aprovisionado para la instancia. Dentro de la métrica de uso del almacenamiento, se incluyen datos temporales. Los datos temporales se quitan como parte del mantenimiento y pueden aumentar más allá de los límites de capacidad definidos por el usuario con el fin de evitar un evento de disco completo. No se le cobra por esto al usuario. Una base de datos nueva usa alrededor de 100 MB para las tablas y los archivos del sistema. |
Operaciones de lectura y escritura de discodisk/read_ops_count, disk/write_ops_count |
La métrica de cantidad de lecturas indica la cantidad de operaciones de lectura entregadas por el disco que no provienen de la caché. Puedes usar esta métrica a fin de saber si tu instancia tiene el tamaño adecuado para tu entorno. De ser necesario, puedes cambiarte a un tipo de máquina más grande para entregar más solicitudes de la caché y reducir la latencia. La métrica Cantidad de escrituras es el número de operaciones de escritura en el disco. La actividad de escritura se genera incluso si tu aplicación no está activa, ya que las instancias de Cloud SQL, excepto las réplicas, escriben en una tabla del sistema aproximadamente cada segundo. |
Conexiones por estadopostgresql/num_backends_by_state |
La cantidad de conexiones agrupadas por estos estados: Para obtener información sobre estos estados, consulta la fila |
Conexiones por base de datospostgresql/num_backends |
La cantidad de conexiones que retiene la instancia de base de datos. |
Bytes de entrada/salidanetwork/received_bytes_count, network/sent_bytes_count |
El tráfico de red en términos de la cantidad de bytes de entrada (bytes recibidos) y de salida (bytes enviados) hacia y desde la instancia, respectivamente. |
Desglose de tiempo de IO por tipopostgresql/insights/aggregate/io_time |
Desglose del tiempo de espera de E/S para las instrucciones de SQL por tipo de operaciones de lectura y escritura. Solo disponible para instancias con Estadísticas de consultas habilitadas. |
Recuento de interbloqueos por base de datospostgresql/deadlock_count |
La cantidad de interbloqueos por base de datos. |
Recuento de bloques leídospostgresql/blocks_read_count |
La cantidad de bloques leídos por segundo desde el disco y desde la caché del búfer. |
Filas procesadas por operaciónpostgresql/tuples_processed_count |
Cantidad de filas procesadas por operación por segundo. |
Filas de la base de datos por estadopostgresql/tuple_size |
La cantidad de filas para cada estado de la base de datos. Cloud SQL informa esta métrica si la cantidad de bases de datos en la instancia es inferior a 50. |
Transacción más antigua por antigüedadpostgresql/vacuum/oldest_transaction_age |
La antigüedad de la transacción más antigua que bloquea la operación de vacío. |
Archivado de WALreplication/log_archive_success_count, replication/log_archive_failure_count |
Cantidad de archivos de registro de escritura por adelantado que se archivaron de forma correcta o incorrecta por minuto. |
Uso de ID de transacciónpostgresql/transaction_id_utilization |
El porcentaje de ID de transacción que se usaron en la instancia. |
Recuento de conexiones por nombre de aplicaciónpostgresql/num_backends_by_application |
La cantidad de conexiones a la instancia de Cloud SQL agrupadas por aplicaciones. |
Filas recuperadas, filas mostradas y filas escritas
|
Si la diferencia entre las filas mostradas y las filas recuperadas es tan grande que sus valores no aparecen en la misma escala, el valor de las filas recuperadas se muestra como 0 porque no tiene importancia en comparación con el valor de las filas mostradas. |
Tamaño de datos temporalespostgresql/temp_bytes_written_count |
La cantidad total de datos (en bytes) que se usan para ejecutar consultas y realizar algoritmos, como unir y ordernar. |
Archivos temporalespostgresql/temp_files_written_count |
La cantidad de archivos temporales que se usan para ejecutar consultas y realizar algoritmos, como unir y ordenar. |
Además, la métrica de Cloud Logging, Entradas de registro por gravedad (logging.googleapis.com/log_entry_count), muestra la cantidad total de entradas de registro de error y de advertencia.
Estos se extraen de postgres.log, que es el registro de la base de datos, y de pgaudit.log, que contiene información de acceso a los datos.
Para obtener más información, consulta Métricas de Cloud SQL.
Cronograma de eventos
En el panel, se proporcionan los detalles de los siguientes eventos:
| Nombre del evento | Descripción | Tipo de operación |
|---|---|---|
Instance restart |
Reinicia la instancia de Cloud SQL. | RESTART |
Instance failover |
Inicia una conmutación por error manual de una instancia principal con alta disponibilidad (HA) a una instancia en espera, que se convierte en la instancia principal. | FAILOVER |
Instance maintenance |
Indica que la instancia está actualmente en mantenimiento. El mantenimiento suele hacer que la instancia no esté disponible durante 1 a 3 minutos. | MAINTENANCE |
Instance backup |
Realiza una copia de seguridad de instancias. | BACKUP_VOLUME |
Instance update |
Actualiza la configuración de una instancia de Cloud SQL. | UPDATE |
Promote replica |
Promueve una instancia de réplica de Cloud SQL. | PROMOTE_REPLICA |
Start replica |
Inicia la replicación en una instancia de réplica de lectura de Cloud SQL. | START_REPLICA |
Stop replica |
Detiene la replicación en una instancia de réplica de lectura de Cloud SQL. | STOP_REPLICA |
Recreate replica |
Vuelve a crear los recursos para una instancia de réplica de Cloud SQL. | RECREATE_REPLICA |
Create replica |
Crea una instancia de réplica de Cloud SQL. | CREATE_REPLICA |
Data import |
Importa datos a una instancia de Cloud SQL. | IMPORT |
Instance export |
Exporta datos de una instancia de Cloud SQL a un bucket de Cloud Storage. | EXPORT |
Restore backup |
Restablece una copia de seguridad de una instancia de Cloud SQL. Esta operación podría hacer que se reinicie la instancia. | RESTORE_VOLUME |