
Come descritto in Piani di esecuzione delle query, il compilatore SQL trasforma un'istruzione SQL in un piano di esecuzione delle query, che viene utilizzato per ottenere i risultati della query. Questa pagina descrive le best practice per la creazione di istruzioni SQL in grado di aiutare Spanner a trovare piani di esecuzione efficienti.
Le istruzioni SQL di esempio mostrate in questa pagina utilizzano lo schema di esempio seguente:
GoogleSQL
CREATE TABLE Singers (
SingerId INT64 NOT NULL,
FirstName STRING(1024),
LastName STRING(1024),
SingerInfo BYTES(MAX),
BirthDate DATE
) PRIMARY KEY (SingerId);
CREATE TABLE Albums (
SingerId INT64 NOT NULL,
AlbumId INT64 NOT NULL,
AlbumTitle STRING(MAX),
ReleaseDate DATE
) PRIMARY KEY (SingerId, AlbumId),
INTERLEAVE IN PARENT Singers ON DELETE CASCADE;
Per il riferimento SQL completo, consulta Sintassi delle istruzioni, Funzioni e operatori e Struttura lessicale e sintassi.
PostgreSQL
CREATE TABLE Singers (
SingerId BIGINT PRIMARY KEY,
FirstName VARCHAR(1024),
LastName VARCHAR(1024),
SingerInfo BYTEA,
BirthDate TIMESTAMPTZ
);
CREATE TABLE Albums (
SingerId BIGINT NOT NULL,
AlbumId BIGINT NOT NULL,
AlbumTitle VARCHAR(1024),
ReleaseDate DATE,
PRIMARY KEY(SingerId, AlbumId),
FOREIGN KEY (SingerId) REFERENCES Singers(SingerId)
) INTERLEAVE IN PARENT Singers ON DELETE CASCADE;
Per saperne di più, consulta Il linguaggio PostgreSQL in Spanner.
Utilizzare parametri di ricerca
Spanner supporta parametri di ricerca per aumentare le prestazioni e contribuire a prevenire l'SQL injection quando le query vengono create utilizzando l'input utente'utente. Puoi utilizzare parametri di ricerca come sostituti di espressioni arbitrarie, ma non come sostituti di identificatori, nomi di colonne, nomi di tabelle o altre parti della query.
I parametri possono essere visualizzati ovunque sia previsto un valore letterale. Lo stesso nome del parametro può essere utilizzato più di una volta in una singola istruzione SQL.
In sintesi, parametri di ricerca supportano l'esecuzione delle query nei seguenti modi:
- Piani preottimizzati: le query che utilizzano parametri possono essere eseguite più rapidamente a ogni chiamata perché la parametrizzazione consente a Spanner di memorizzare più facilmente nella cache il piano di esecuzione.
- Composizione semplificata delle query: non devi utilizzare caratteri di escape per i valori stringa quando li fornisci nei parametri di ricerca. I parametri della query riducono anche il rischio di errori di sintassi.
- Sicurezza: i parametri di query rendono le query più sicure proteggendoti da vari attacchi di SQL injection. Questa protezione è particolarmente importante per le query che crei a partire dalinput utentet dell'utente.
Comprendere in che modo Spanner esegue le query
Spanner consente di eseguire query sui database utilizzando istruzioni SQL dichiarative che specificano i dati che vuoi recuperare. Se vuoi capire come Spanner ottiene i risultati, esamina il piano di esecuzione della query. Un piano di esecuzione della query mostra il costo di calcolo associato a ogni passaggio della query. Utilizzando questi costi, puoi eseguire il debug dei problemi di rendimento delle query e ottimizzare la query. Per saperne di più, consulta Piani di esecuzione delle query.
Puoi recuperare i piani di esecuzione delle query tramite la console Google Cloud o le librerie client.
Per ottenere un piano di esecuzione di una query specifica utilizzando la consoleGoogle Cloud , segui questi passaggi:
Apri la pagina delle istanze Spanner.
Seleziona i nomi dell'istanza Spanner e del database per cui vuoi eseguire query.
Fai clic su Spanner Studio nel pannello di navigazione a sinistra.
Digita la query nel campo di testo e fai clic su Esegui query.
Fai clic su Spiegazione
. La console Google Cloud mostra un piano di esecuzione visivo per la tua query.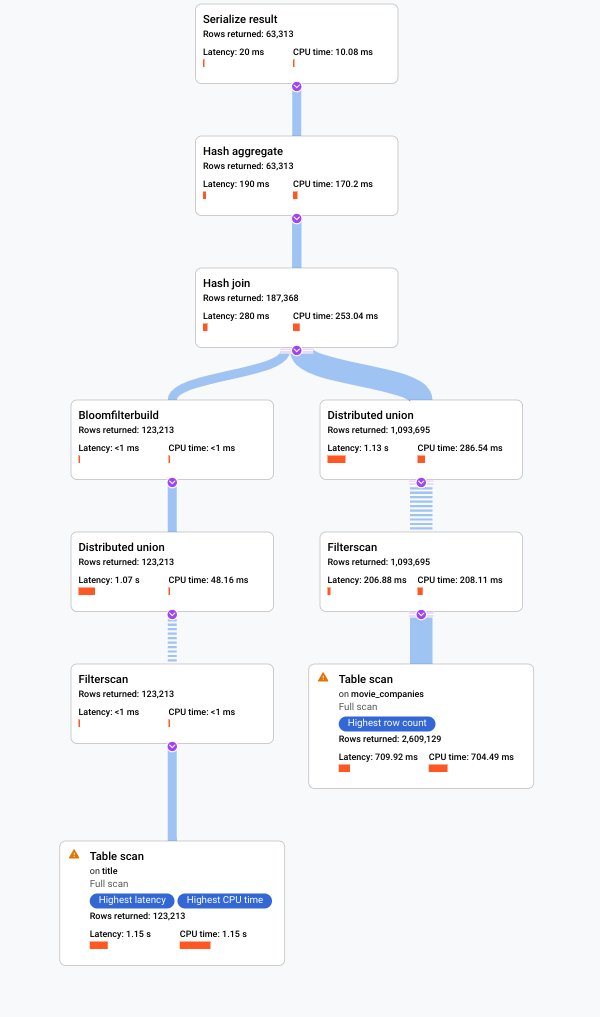
Per saperne di più su come comprendere i piani visivi e utilizzarli per eseguire il debug delle query, consulta Regolazione di una query utilizzando il visualizzatore del piano query.
Puoi anche visualizzare esempi di piani di query storici e confrontare il rendimento di una query nel tempo per determinate query. Per saperne di più, consulta Piani di query campionati.
Utilizzare gli indici secondari
Come altri database relazionali, Spanner offre indici secondari, che puoi utilizzare per recuperare i dati utilizzando un'istruzione SQL o l'interfaccia di lettura di Spanner. Il modo più comune per recuperare i dati da un indice è utilizzare Spanner Studio. L'utilizzo di un indice secondario in una query SQL ti consente di specificare come vuoi che Spanner ottenga i risultati. La specifica di un indice secondario può velocizzare l'esecuzione delle query.
Ad esempio, supponiamo di voler recuperare gli ID di tutti i cantanti con un cognome specifico. Un modo per scrivere una query SQL di questo tipo è:
SELECT s.SingerId
FROM Singers AS s
WHERE s.LastName = 'Smith';
Questa query restituirebbe i risultati che ti aspetti, ma potrebbe
richiedere molto tempo. La tempistica dipende dal numero di righe nella
tabella Singers e da quante soddisfano il predicato WHERE s.LastName = 'Smith'.
Se non esiste un indice secondario che contenga la colonna LastName da cui leggere,
il piano di query leggerà l'intera tabella Singers per trovare le righe che corrispondono al
predicato. La lettura dell'intera tabella è chiamata scansione completa della tabella. Una scansione completa della tabella è un modo costoso per ottenere i risultati quando la tabella contiene solo una piccola percentuale di Singers con quel cognome.
Puoi migliorare il rendimento di questa query definendo un indice secondario nella colonna del cognome:
CREATE INDEX SingersByLastName ON Singers (LastName);
Poiché l'indice secondario SingersByLastName contiene la colonna della tabella indicizzata LastName e la colonna della chiave primaria SingerId, Spanner può recuperare tutti i dati dalla tabella dell'indice molto più piccola anziché scansionare l'intera tabella Singers.
In questo scenario, Spanner utilizza automaticamente l'indice secondario
SingersByLastName durante l'esecuzione della query (a condizione che siano trascorsi tre giorni
dalla creazione del database; vedi Una nota sui nuovi database).
Tuttavia, è meglio indicare esplicitamente a Spanner di utilizzare l'indice
specificando una direttiva index nella clausola FROM:
GoogleSQL
SELECT s.SingerId
FROM Singers@{FORCE_INDEX=SingersByLastName} AS s
WHERE s.LastName = 'Smith';
PostgreSQL
SELECT s.SingerId
FROM Singers /*@ FORCE_INDEX=SingersByLastName */ AS s
WHERE s.LastName = 'Smith';
Se utilizzi schemi denominati,
utilizza la seguente sintassi per la clausola FROM:
GoogleSQL
FROM NAMED_SCHEMA_NAME.TABLE_NAME@{FORCE_INDEX="NAMED_SCHEMA_NAME.TABLE_INDEX_NAME"}
PostgreSQL
FROM NAMED_SCHEMA_NAME.TABLE_NAME /*@ FORCE_INDEX = TABLE_INDEX_NAME */
Supponiamo ora di voler recuperare anche il nome del cantante oltre all'ID. Anche se la colonna FirstName non è contenuta nell'indice, devi comunque specificare la direttiva index come prima:
GoogleSQL
SELECT s.SingerId, s.FirstName
FROM Singers@{FORCE_INDEX=SingersByLastName} AS s
WHERE s.LastName = 'Smith';
PostgreSQL
SELECT s.SingerId, s.FirstName
FROM Singers /*@ FORCE_INDEX=SingersByLastName */ AS s
WHERE s.LastName = 'Smith';
L'utilizzo dell'indice offre comunque un vantaggio in termini di prestazioni perché
Spanner non deve eseguire una scansione completa della tabella durante l'esecuzione del
piano di query. Seleziona invece il sottoinsieme di righe che soddisfano il predicato
dall'indice SingersByLastName, quindi esegue una ricerca dalla tabella di base
Singers per recuperare il nome solo per quel sottoinsieme di righe.
Se vuoi che Spanner non debba recuperare righe dalla tabella di base, puoi archiviare una copia della colonna FirstName nell'indice stesso:
GoogleSQL
CREATE INDEX SingersByLastName ON Singers (LastName) STORING (FirstName);
PostgreSQL
CREATE INDEX SingersByLastName ON Singers (LastName) INCLUDE (FirstName);
L'utilizzo di una clausola STORING (per il dialetto GoogleSQL) o di una clausola INCLUDE (per il dialetto PostgreSQL) come questa comporta un costo aggiuntivo per lo spazio di archiviazione, ma offre i seguenti vantaggi:
- Le query SQL che utilizzano l'indice e selezionano le colonne memorizzate nella clausola
STORINGoINCLUDEnon richiedono un'unione aggiuntiva alla tabella di base. - Le letture che utilizzano l'indice possono leggere le colonne memorizzate nella clausola
STORINGoINCLUDE.
Gli esempi precedenti illustrano come gli indici secondari possono velocizzare le query
quando le righe scelte dalla clausola WHERE di una query possono essere identificate rapidamente
utilizzando l'indice secondario.
Un altro scenario in cui gli indici secondari possono offrire vantaggi in termini di prestazioni è per determinate query che restituiscono risultati ordinati. Ad esempio, supponiamo che tu voglia recuperare tutti i titoli degli album e le relative date di pubblicazione in ordine crescente di data di pubblicazione e decrescente di titolo dell'album. Puoi scrivere una query SQL come segue:
SELECT a.AlbumTitle, a.ReleaseDate
FROM Albums AS a
ORDER BY a.ReleaseDate, a.AlbumTitle DESC;
Senza un indice secondario, questa query richiede un passaggio di ordinamento potenzialmente costoso nel piano di esecuzione. Potresti velocizzare l'esecuzione delle query definendo questo indice secondario:
CREATE INDEX AlbumsByReleaseDateTitleDesc on Albums (ReleaseDate, AlbumTitle DESC);
Quindi, riscrivi la query per utilizzare l'indice secondario:
GoogleSQL
SELECT a.AlbumTitle, a.ReleaseDate
FROM Albums@{FORCE_INDEX=AlbumsByReleaseDateTitleDesc} AS a
ORDER BY a.ReleaseDate, a.AlbumTitle DESC;
PostgreSQL
SELECT a.AlbumTitle, a.ReleaseDate
FROM Albums /*@ FORCE_INDEX=AlbumsByReleaseDateTitleDesc */ AS s
ORDER BY a.ReleaseDate, a.AlbumTitle DESC;
Questa query e la definizione dell'indice soddisfano entrambi i seguenti criteri:
- Per rimuovere il passaggio di ordinamento, assicurati che l'elenco delle colonne nella clausola
ORDER BYsia un prefisso dell'elenco delle chiavi di indice. - Per evitare di eseguire nuovamente il join dalla tabella di base per recuperare le colonne mancanti, assicurati che l'indice copra tutte le colonne della tabella utilizzate dalla query.
Sebbene gli indici secondari possano velocizzare le query comuni, l'aggiunta di indici secondari può aumentare la latenza delle operazioni di commit, perché ogni indice secondario in genere richiede il coinvolgimento di un nodo aggiuntivo in ogni commit. Per la maggior parte dei workload, pochi indici secondari sono sufficienti. Tuttavia, devi valutare se ti interessa di più la latenza di lettura o scrittura e quali operazioni sono più critiche per il tuo workload. Esegui il benchmark del carico di lavoro per assicurarti che funzioni come previsto.
Per il riferimento completo sugli indici secondari, consulta Indici secondari.
Ottimizzare le scansioni
Alcune query Spanner potrebbero trarre vantaggio dall'utilizzo di un metodo di elaborazione orientato ai batch durante la scansione dei dati anziché del metodo di elaborazione orientato alle righe più comune. L'elaborazione delle scansioni in batch è un modo più efficiente per elaborare grandi volumi di dati contemporaneamente e consente alle query di ottenere un utilizzo della CPU e una latenza inferiori.
L'operazione di scansione Spanner inizia sempre l'esecuzione con il metodo orientato alle righe. Durante questo periodo, Spanner raccoglie diverse metriche di runtime. Spanner applica quindi un insieme di euristiche basate sul risultato di queste metriche per determinare il metodo di scansione ottimale. Se appropriato, Spanner passa a un metodo di elaborazione orientato ai batch per migliorare la velocità effettiva e il rendimento della scansione.
Casi d'uso comuni
Le query con le seguenti caratteristiche in genere traggono vantaggio dall'utilizzo dell'elaborazione orientata ai batch:
- Scansioni di grandi dimensioni su dati aggiornati di rado.
- Scansioni con predicati su colonne a larghezza fissa.
- Scansioni con un numero elevato di ricerche. Una ricerca utilizza un indice per recuperare i record.
Casi d'uso senza miglioramenti delle prestazioni
Non tutte le query traggono vantaggio dall'elaborazione orientata ai batch. I seguenti tipi di query funzionano meglio con l'elaborazione della scansione orientata alle righe:
- Query di ricerca puntuale: query che recuperano una sola riga.
- Query di scansione di piccole dimensioni: scansioni di tabelle che scansionano solo poche righe, a meno che non abbiano un numero elevato di ricerche.
- Query che utilizzano
LIMIT. - Query che leggono dati con un tasso di abbandono elevato: query in cui più del 10% circa dei dati letti viene aggiornato di frequente.
- Query con righe contenenti valori di grandi dimensioni: le righe con valori di grandi dimensioni sono quelle contenenti valori superiori a 32.000 byte (pre-compressione) in una singola colonna.
Controllare il metodo di scansione utilizzato da una query
Per verificare se la query utilizza l'elaborazione orientata ai batch, l'elaborazione orientata alle righe o se passa automaticamente da un metodo di scansione all'altro:
Vai alla pagina Istanze di Spanner nella consoleGoogle Cloud .
Fai clic sul nome dell'istanza con la query che vuoi esaminare.
Nella tabella Database, fai clic sul database con la query che vuoi esaminare.
Nel menu di navigazione, fai clic su Spanner Studio.
Apri una nuova scheda facendo clic su Nuova scheda dell'editor SQL o Nuova scheda.
Quando viene visualizzato l'editor di query, scrivi la query.
Fai clic su Esegui.
Spanner esegue la query e mostra i risultati.
Fai clic sulla scheda Spiegazione sotto l'editor di query.
Spanner mostra un visualizzatore del piano di esecuzione delle query. Ogni scheda del grafico rappresenta un iteratore.
Fai clic sulla scheda dell'iteratore Scansione tabella per aprire un riquadro informativo.
Il riquadro informativo mostra informazioni contestuali sulla scansione selezionata. Il metodo di scansione è mostrato in questa scheda. Automatico indica che Spanner determina il metodo di scansione. Altri valori possibili includono Batch per l'elaborazione orientata ai batch e Row per l'elaborazione orientata alle righe.
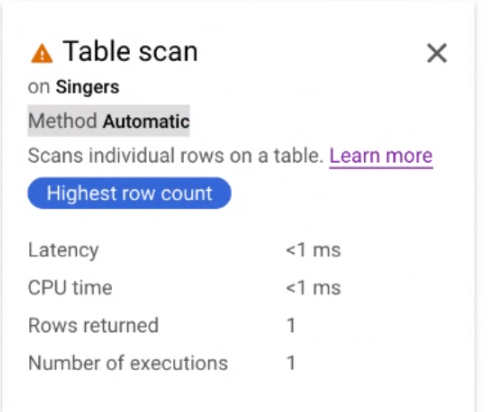
Imporre il metodo di scansione utilizzato da una query
Per ottimizzare le prestazioni delle query, Spanner sceglie il metodo di scansione ottimale per la query. Ti consigliamo di utilizzare questo metodo di scansione predefinito. Tuttavia, in alcuni scenari potresti voler applicare un tipo specifico di metodo di scansione.
Applica la scansione orientata ai batch
Puoi applicare la scansione orientata ai batch a livello di tabella e di istruzione.
Per applicare il metodo di scansione orientato ai batch a livello di tabella, utilizza un suggerimento per la tabella nella query:
GoogleSQL
SELECT ...
FROM (t1@{SCAN_METHOD=BATCH} JOIN t2 ON ...)
WHERE ...
PostgreSQL
SELECT ...
FROM (t1/*@ scan_method=batch */ JOIN t2 on ...)
WHERE ...
Per applicare il metodo di scansione orientato al batch a livello di istruzione, utilizza un suggerimento per l'istruzione nella query:
GoogleSQL
@{SCAN_METHOD=BATCH}
SELECT ...
FROM ...
WHERE ...
PostgreSQL
/*@ scan_method=batch */
SELECT ...
FROM ...
WHERE ...
Disattivare la scansione automatica e applicare la scansione orientata alle righe
Sebbene non sia consigliabile disattivare il metodo di scansione automatica impostato da Spanner, potresti decidere di disattivarlo e utilizzare il metodo di scansione orientato alle righe per la risoluzione dei problemi, ad esempio la diagnosi della latenza.
Per disattivare il metodo di scansione automatica e forzare l'elaborazione delle righe a livello di tabella, utilizza un suggerimento per la tabella nella query:
GoogleSQL
SELECT ...
FROM (t1@{SCAN_METHOD=ROW} JOIN t2 ON ...)
WHERE ...
PostgreSQL
SELECT ...
FROM (t1/*@ scan_method=row */ JOIN t2 on ...)
WHERE ...
Per disattivare il metodo di scansione automatica e forzare l'elaborazione delle righe a livello di istruzione, utilizza un suggerimento per l'istruzione nella query:
GoogleSQL
@{SCAN_METHOD=ROW}
SELECT ...
FROM ...
WHERE ...
PostgreSQL
/*@ scan_method=row */
SELECT ...
FROM ...
WHERE ...
Ottimizzare l'esecuzione delle query
Oltre a ottimizzare le scansioni, puoi anche ottimizzare l'esecuzione delle query applicando il metodo di esecuzione a livello di istruzione. Funziona solo per alcuni operatori ed è indipendente dal metodo di scansione, che viene utilizzato solo dall'operatore di scansione.
Per impostazione predefinita, la maggior parte degli operatori viene eseguita con il metodo orientato alle righe, che elabora i dati una riga alla volta. Gli operatori vettorializzati vengono eseguiti con il metodo orientato ai batch per migliorare la velocità effettiva e il rendimento dell'esecuzione. Questi operatori elaborano i dati un blocco alla volta. Quando un operatore deve elaborare molte righe, il metodo di esecuzione orientato ai batch è in genere più efficiente.
Metodo di esecuzione e metodo di scansione
Il metodo di esecuzione della query è indipendente dal metodo di scansione della query. Puoi impostare uno, entrambi o nessuno di questi metodi nel suggerimento per la query.
Il metodo di esecuzione delle query si riferisce al modo in cui gli operatori di query elaborano i risultati intermedi e al modo in cui gli operatori interagiscono tra loro, mentre il metodo di scansione si riferisce al modo in cui l'operatore di scansione interagisce con il livello di archiviazione di Spanner.
Forza il metodo di esecuzione utilizzato dalla query
Per ottimizzare le prestazioni delle query, Spanner sceglie il metodo di esecuzione ottimale per la query in base a varie euristiche. Ti consigliamo di utilizzare questo metodo di esecuzione predefinito. Tuttavia, potrebbero verificarsi scenari in cui potresti voler applicare un tipo specifico di metodo di esecuzione.
Puoi applicare il metodo di esecuzione a livello di istruzione. EXECUTION_METHOD è un suggerimento per la query, non un'istruzione. In definitiva, l'ottimizzatore delle query decide quale metodo utilizzare per ogni singolo operatore.
Per applicare il metodo di esecuzione orientato al batch a livello di istruzione, utilizza un suggerimento per l'istruzione nella query:
GoogleSQL
@{EXECUTION_METHOD=BATCH}
SELECT ...
FROM ...
WHERE ...
PostgreSQL
/*@ execution_method=batch */
SELECT ...
FROM ...
WHERE ...
Sebbene non sia consigliabile disabilitare il metodo di esecuzione automatica impostato da Spanner, potresti decidere di disabilitarlo e utilizzare il metodo di esecuzione orientato alle righe per la risoluzione dei problemi, ad esempio la diagnosi della latenza.
Per disattivare il metodo di esecuzione automatica e applicare il metodo di esecuzione orientato alle righe a livello di istruzione, utilizza un suggerimento per l'istruzione nella query:
GoogleSQL
@{EXECUTION_METHOD=ROW}
SELECT ...
FROM ...
WHERE ...
PostgreSQL
/*@ execution_method=row */
SELECT ...
FROM ...
WHERE ...
Controllare quale metodo di esecuzione è abilitato
Non tutti gli operatori Spanner supportano i metodi di esecuzione orientati ai batch e alle righe. Per ogni operatore, il visualizzatore del piano di esecuzione della query mostra il metodo di esecuzione nella scheda dell'iteratore. Se il metodo di esecuzione è orientato al batch, viene visualizzato Batch. Se è orientato alle righe, mostra Riga.
Se gli operatori nella query vengono eseguiti utilizzando metodi di esecuzione diversi, gli adattatori del metodo di esecuzione DataBlockToRowAdapter e RowToDataBlockAdapter vengono visualizzati tra gli operatori per mostrare la modifica del metodo di esecuzione.
Ottimizzare le ricerche di chiavi di intervallo
Un utilizzo comune di una query SQL è la lettura di più righe da Spanner in base a un elenco di chiavi note.
Le seguenti best practice ti aiutano a scrivere query efficienti quando recuperi dati in base a un intervallo di chiavi:
Se l'elenco delle chiavi è sparso e non adiacente, utilizza parametri di ricerca e
UNNESTper creare la query.Ad esempio, se l'elenco delle chiavi è
{1, 5, 1000}, scrivi la query nel seguente modo:GoogleSQL
SELECT * FROM Table AS t WHERE t.Key IN UNNEST (@KeyList)
PostgreSQL
SELECT * FROM Table AS t WHERE t.Key IN UNNEST ($1)
Note:
L'operatore UNNEST dell'array appiattisce un array di input in righe di elementi.
Il parametro della query, che è
@KeyListper GoogleSQL e$1per PostgreSQL, può velocizzare la query come descritto nella best practice precedente.
Se l'elenco di chiavi è adiacente e rientra in un intervallo, specifica i limiti inferiore e superiore dell'intervallo di chiavi nella clausola
WHERE.Ad esempio, se l'elenco delle chiavi è
{1,2,3,4,5}, crea la query come segue:GoogleSQL
SELECT * FROM Table AS t WHERE t.Key BETWEEN @min AND @max
PostgreSQL
SELECT * FROM Table AS t WHERE t.Key BETWEEN $1 AND $2
Questa query è più efficiente solo se le chiavi nell'intervallo di chiavi sono adiacenti. In altre parole, se l'elenco di chiavi è
{1, 5, 1000}, non specificare i limiti inferiore e superiore come nella query precedente, perché la query risultante esaminerebbe ogni valore compreso tra 1 e 1000.
Ottimizzare i join
Le operazioni di join possono essere costose perché possono aumentare notevolmente il numero di righe che la query deve analizzare, il che comporta query più lente. Oltre alle tecniche che utilizzi abitualmente in altri database relazionali per ottimizzare le query di join, ecco alcune best practice per un JOIN più efficiente quando utilizzi Spanner SQL:
Se possibile, unisci i dati nelle tabelle interleaved in base alla chiave primaria. Ad esempio:
SELECT s.FirstName, a.ReleaseDate FROM Singers AS s JOIN Albums AS a ON s.SingerId = a.SingerId;
È garantito che le righe della tabella interleaved
Albumssiano memorizzate fisicamente negli stessi split della riga padre inSingers, come descritto in Schema e modello di dati. Pertanto, i join possono essere completati localmente senza inviare molti dati attraverso la rete.Utilizza la direttiva join se vuoi forzare l'ordine del join. Ad esempio:
GoogleSQL
SELECT * FROM Singers AS s JOIN@{FORCE_JOIN_ORDER=TRUE} Albums AS a ON s.SingerId = a.Singerid WHERE s.LastName LIKE '%x%' AND a.AlbumTitle LIKE '%love%';
PostgreSQL
SELECT * FROM Singers AS s JOIN/*@ FORCE_JOIN_ORDER=TRUE */ Albums AS a ON s.SingerId = a.Singerid WHERE s.LastName LIKE '%x%' AND a.AlbumTitle LIKE '%love%';
La direttiva di join
FORCE_JOIN_ORDERindica a Spanner di utilizzare l'ordine di join specificato nella query (ovveroSingers JOIN Albums, nonAlbums JOIN Singers). I risultati restituiti sono gli stessi, indipendentemente dall'ordine scelto da Spanner. Tuttavia, potresti voler utilizzare questa direttiva di join se noti nel piano di query che Spanner ha modificato l'ordine di join e ha causato conseguenze indesiderate, come risultati intermedi più grandi, o ha perso opportunità di ricerca di righe.Utilizza una direttiva di join per scegliere un'implementazione di join. Quando utilizzi SQL per eseguire query su più tabelle, Spanner utilizza automaticamente un metodo di join che probabilmente renderà la query più efficiente. Tuttavia, Google ti consiglia di eseguire test con algoritmi di join diversi. La scelta dell'algoritmo di join corretto può migliorare la latenza, il consumo di memoria o entrambi. Questa query mostra la sintassi per l'utilizzo di un'istruzione JOIN con il suggerimento
JOIN_METHODper scegliere unHASH JOIN:GoogleSQL
SELECT * FROM Singers s JOIN@{JOIN_METHOD=HASH_JOIN} Albums AS a ON a.SingerId = a.SingerId
PostgreSQL
SELECT * FROM Singers s JOIN/*@ JOIN_METHOD=HASH_JOIN */ Albums AS a ON a.SingerId = a.SingerId
Se utilizzi un'istruzione
HASH JOINoAPPLY JOINe se hai una clausolaWHEREaltamente selettiva su un lato diJOIN, inserisci la tabella che produce il numero più piccolo di righe come prima tabella nella clausolaFROMdell'unione. Questa struttura è utile perché inHASH JOIN, Spanner sceglie sempre la tabella a sinistra come build e quella a destra come probe. Analogamente, perAPPLY JOIN, Spanner sceglie la tabella a sinistra come esterna e quella a destra come interna. Scopri di più su questi tipi di unione: unione hash e unione apply.Per le query critiche per il tuo workload, specifica il metodo di join e l'ordine di join più performanti nelle istruzioni SQL per prestazioni più coerenti.
Ottimizza le query con il pushdown del predicato del timestamp
Il push-down dei predicati di timestamp è una tecnica di ottimizzazione delle query utilizzata in Spanner per migliorare l'efficienza delle query che utilizzano timestamp e dati con criteri di archiviazione a livelli basati sull'età. Quando attivi questa ottimizzazione, le operazioni di filtro sulle colonne timestamp vengono eseguite il prima possibile nel piano di esecuzione della query. Ciò può ridurre notevolmente la quantità di dati elaborati e migliorare le prestazioni complessive delle query.
Con il push-down del predicato del timestamp, il motore del database analizza la query e identifica il filtro del timestamp. Poi "trasferisce" questo filtro al livello di archiviazione, in modo che solo i dati pertinenti in base ai criteri del timestamp vengano letti dall'SSD. In questo modo, la quantità di dati elaborati e trasferiti viene ridotta al minimo, con conseguente esecuzione più rapida delle query.
Per ottimizzare le query in modo che accedano solo ai dati archiviati sull'SSD, devono essere soddisfatte le seguenti condizioni:
- La query deve avere il pushdown del predicato del timestamp abilitato. Per saperne di più, consulta Suggerimenti per le istruzioni GoogleSQL e Suggerimenti per le istruzioni PostgreSQL.
La query deve utilizzare una limitazione basata sull'età uguale o inferiore all'età specificata nel criterio di spill dei dati (impostato con l'opzione
ssd_to_hdd_spill_timespannell'istruzione DDLCREATE LOCALITY GROUPoALTER LOCALITY GROUP). Per ulteriori informazioni, consulta le istruzioni GoogleSQLLOCALITY GROUPe le istruzioni PostgreSQLLOCALITY GROUP.La colonna filtrata nella query deve essere una colonna timestamp che contiene il timestamp del commit. Per informazioni dettagliate su come creare una colonna con timestamp di commit, consulta Timestamp di commit in GoogleSQL e Timestamp di commit in PostgreSQL. Queste colonne devono essere aggiornate insieme alla colonna del timestamp e risiedere all'interno dello stesso gruppo di località, che ha una policy di archiviazione a livelli basata sull'età.
Se, per una determinata riga, alcune delle colonne sottoposte a query risiedono su SSD e alcune risiedono su HDD (perché le colonne vengono aggiornate in momenti diversi e passano all'HDD in momenti diversi), le prestazioni della query potrebbero essere peggiori quando utilizzi l'hint. Questo perché la query deve compilare i dati dei diversi livelli di archiviazione. A seguito dell'utilizzo del suggerimento, Spanner invecchia i dati a livello di singola cella (livello di granularità riga e colonna) in base al timestamp di commit di ogni cella, rallentando la query. Per evitare questo problema, assicurati di aggiornare regolarmente tutte le colonne sottoposte a query utilizzando questa tecnica di ottimizzazione nella stessa transazione, in modo che tutte le colonne condividano lo stesso timestamp di commit e beneficino dell'ottimizzazione.
Per attivare il push-down del predicato timestamp a livello di istruzione, utilizza un suggerimento per l'istruzione nella query. Ad esempio:
GoogleSQL
@{allow_timestamp_predicate_pushdown=TRUE}
SELECT s.SingerInfo
FROM Singers s
WHERE s.ModificationTime > TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 12 HOUR);
PostgreSQL
/*@allow_timestamp_predicate_pushdown=TRUE*/
SELECT s.SingerInfo
FROM Singers s
WHERE s.ModificationTime > CURRENT_TIMESTAMP - INTERVAL '12 hours';
Evita letture di grandi dimensioni all'interno di transazioni di lettura/scrittura
Le transazioni di lettura/scrittura consentono una sequenza di zero o più letture o query SQL e possono includere un insieme di mutazioni prima di una chiamata a commit. Per mantenere la coerenza dei dati, Spanner acquisisce blocchi durante la lettura e la scrittura di righe nelle tabelle e negli indici. Per maggiori informazioni sul blocco, consulta Durata delle letture e delle scritture.
A causa del modo in cui funziona il blocco in Spanner, l'esecuzione di una query SQL o di lettura che legge un numero elevato di righe (ad esempio SELECT * FROM
Singers) impedisce ad altre transazioni di scrivere nelle righe che hai letto finché la transazione non viene eseguita o interrotta.
Inoltre, poiché la transazione elabora un numero elevato di righe, è
probabile che richieda più tempo rispetto a una transazione che legge un intervallo di righe molto più piccolo
(ad esempio SELECT LastName FROM Singers WHERE SingerId = 7), il che aggrava ulteriormente il problema e riduce la velocità effettiva del sistema.
Pertanto, cerca di evitare letture di grandi dimensioni (ad esempio scansioni complete delle tabelle o operazioni di unione massicce) nelle transazioni, a meno che tu non voglia accettare una velocità effettiva di scrittura inferiore.
In alcuni casi, il seguente pattern può produrre risultati migliori:
- Esegui le letture di grandi dimensioni all'interno di una transazione di sola lettura. Le transazioni di sola lettura consentono un throughput aggregato più elevato perché non utilizzano blocchi.
- (Facoltativo) Esegui l'elaborazione necessaria sui dati appena letti.
- Avvia una transazione di lettura/scrittura.
- Verifica che i valori delle righe critiche non siano cambiati da quando hai eseguito
la transazione di sola lettura nel passaggio 1.
- Se le righe sono cambiate, esegui il rollback della transazione e ricomincia dal passaggio 1.
- Se tutto sembra a posto, esegui il commit delle mutazioni.
Un modo per assicurarti di evitare letture di grandi dimensioni nelle transazioni di lettura/scrittura è esaminare i piani di esecuzione generati dalle query.
Utilizza ORDER BY per garantire l'ordinamento dei risultati SQL
Se ti aspetti un determinato ordine per i risultati di una query SELECT,
includi esplicitamente la clausola ORDER BY. Ad esempio, se vuoi elencare tutti i cantanti in ordine di chiave primaria, utilizza questa query:
SELECT * FROM Singers
ORDER BY SingerId;
Spanner garantisce l'ordinamento dei risultati solo se la clausola ORDER BY
è presente nella query. In altre parole, considera questa query senza ORDER
BY:
SELECT * FROM Singers;
Spanner non garantisce che i risultati di questa query saranno
in ordine di chiave primaria. Inoltre, l'ordine dei risultati può cambiare in qualsiasi
momento e non è garantito che sia coerente da un'invocazione all'altra. Se una
query ha una clausola ORDER BY e Spanner utilizza un indice che
fornisce l'ordine richiesto, Spanner non ordina esplicitamente
i dati. Pertanto, non preoccuparti dell'impatto sul rendimento dell'inclusione di questa clausola. Puoi verificare se nell'esecuzione è inclusa un'operazione di ordinamento esplicito esaminando il piano di query.
Utilizza STARTS_WITH anziché LIKE
Poiché Spanner non valuta i pattern LIKE con parametri
fino al momento dell'esecuzione, deve leggere tutte le righe e valutarle
in base all'espressione LIKE per filtrare le righe che non corrispondono.
Quando un pattern LIKE ha la forma foo% (ad esempio, inizia con una stringa fissa e termina con un singolo carattere jolly percentuale) e la colonna è indicizzata, utilizza STARTS_WITH anziché LIKE. Questa opzione consente a Spanner di
ottimizzare in modo più efficace il piano di esecuzione delle query.
Non consigliato:
GoogleSQL
SELECT a.AlbumTitle FROM Albums a WHERE a.AlbumTitle LIKE @like_clause;
PostgreSQL
SELECT a.AlbumTitle FROM Albums a WHERE a.AlbumTitle LIKE $1;
Consigliato:
GoogleSQL
SELECT a.AlbumTitle FROM Albums a WHERE STARTS_WITH(a.AlbumTitle, @prefix);
PostgreSQL
SELECT a.AlbumTitle FROM Albums a WHERE STARTS_WITH(a.AlbumTitle, $2);
Utilizzare i timestamp di commit
Se la tua applicazione deve eseguire query sui dati scritti dopo un determinato orario, aggiungi
le colonne dei timestamp di commit alle tabelle pertinenti. I timestamp di commit consentono un'ottimizzazione di Spanner che può ridurre l'I/O delle query le cui clausole WHERE limitano i risultati alle righe scritte più di recente rispetto a un momento specifico.
Scopri di più su questa ottimizzazione con i database di dialetto GoogleSQL o con i database di dialetto PostgreSQL.