
このページでは、Query Insights ダッシュボードを使用して Spanner のパフォーマンスの問題を検出して分析する方法について説明します。
Query Insights の概要
Query Insights は、Spanner データベースに対するクエリと DML(INSERT、UPDATE、DELETE)ステートメントのパフォーマンスに関する問題の検出と診断に役立ちます。直感的なモニタリングをサポートし、パフォーマンスの問題を検出するだけでなく、根本原因の特定に役立つ診断情報を提供します。
Query Insights では、次のことを行い、Spanner クエリのパフォーマンスを改善します。
Query Insights は、シングルリージョン構成とマルチリージョン構成で利用できます。
料金
Query Insights に追加料金はかかりません。
データの保持
Query Insights では、データは最大 30 日間保持されます。合計 CPU 使用率(クエリまたはリクエストタグごと)グラフの場合、Spanner は SPANNER_SYS.QUERY_STATS_TOP_* テーブルからデータを取得します。これらのテーブルの保持期間は最長で 30 日です。詳細については、データの保持をご覧ください。
必要なロール
IAM ユーザーか、きめ細かいアクセス制御のユーザーかによって、必要な IAM のロールと権限が異なります。
Identity and Access Management(IAM)ユーザー
Query Insights ページを表示するために必要な権限を取得するには、インスタンスに対する次の IAM ロールを付与するよう管理者に依頼してください。
- Cloud Spanner 閲覧者(
roles/spanner.viewer) - Cloud Spanner データベース読み取り(
roles/spanner.databaseReader)
[Query Insights] ページを表示するには、Cloud Spanner データベース読み取り(
roles/spanner.databaseReader)ロールの次の権限が必要です。
spanner.databases.beginReadOnlyTransactionspanner.databases.selectspanner.sessions.create
きめ細かいアクセス制御ユーザー
きめ細かいアクセス制御ユーザーの場合は、次の条件を満たしている必要があります。
- Cloud Spanner 閲覧者(
roles/spanner.viewer)のロールがある。 - きめ細かいアクセス制御の権限があり、
spanner_sys_readerシステムロールまたはそのメンバーのロールのいずれかが付与されている。 - データベースの [概要] ページで、現在のシステムロールとして
spanner_sys_readerまたはメンバーロールを選択している。
詳細については、きめ細かいアクセス制御についてときめ細かいアクセス制御システムのロールをご覧ください。
Query Insights ダッシュボード
Query Insights ダッシュボードには、選択したデータベースと時間範囲に基づいてクエリの負荷が表示されます。クエリの負荷は、選択した期間内のインスタンスのすべてのクエリの合計 CPU 使用率の測定値です。ダッシュボードには、クエリの負荷を確認するための一連のフィルタが用意されています。
データベースの Query Insights ダッシュボードを表示するには、次の操作を行います。
- 左側のナビゲーション パネルで [Query Insights] を選択します。Query Insights ダッシュボードが開きます。
- [データベース] リストからデータベースを選択します。ダッシュボードに、データベースのクエリ負荷情報が表示されます。
ダッシュボードには、次の領域があります。
- データベースのリスト: 特定のデータベースまたはすべてのデータベースのクエリの負荷をフィルタします。
- 時間範囲フィルタ: 時間、日、カスタム範囲など、時間範囲でクエリの負荷をフィルタします。
- 合計 CPU 使用率(すべてのクエリ)グラフ: すべてのクエリを集計した負荷が表示されます。
- 合計 CPU 使用率(クエリまたはリクエストタグごと)グラフ: 各クエリまたはリクエストタグごとの CPU 使用率を表示します。
- 上位 N 個のクエリとタグのテーブル: CPU 使用率で並べ替えられた上位のクエリとリクエストタグのリストが表示されます。問題がある可能性のあるクエリまたはタグを特定するをご覧ください。

ダッシュボードのパフォーマンス
クエリ パラメータを使用するか、クエリにタグを付けると、Query Insights のパフォーマンスを最適化できます。クエリをパラメータ化またはタグ付けしないと、多すぎる結果が返されるため、上位 N 個のクエリとタグのテーブルが正しく読み込まれない可能性があります。
非効率的なクエリが高 CPU 使用率の原因かどうかを確認する
合計 CPU 使用率は、選択したデータベースで実行されたクエリが時間の経過に伴って行う作業量(CPU 秒)です。

グラフを確認して次のことを検討します。
どのデータベースで負荷が発生していますか?データベースのリストから別のデータベースを選択し、負荷が最も高いデータベースを見つけます。負荷が最も高いデータベースを確認するには、Google Cloud コンソールで、データベースの [CPU 使用率 - 合計] グラフを確認します。

CPU 使用率は高いですか?グラフは時間の経過とともに増少していますか?高 CPU 使用率を確認できない場合、クエリに問題はありません。
CPU 使用率が高い期間はどのくらいですか?最近急増しているのか、長期間にわたって常に高い状態になっていますか?範囲セレクタを使用して、さまざまな期間を選択し、問題が発生した期間を探します。ズームインすると、クエリの負荷の急増が観測された時間枠が拡大表示されます。ズームアウトすると、最大 1 週間のタイムラインが表示されます。
インスタンス全体の CPU 使用率に対応するグラフで急上昇や上昇が見られる場合は、1 つ以上の高コストクエリが原因である可能性があります。次に、問題がある可能性のあるクエリまたはリクエストタグを特定して、トラブルシューティングの詳しい流れを確認します。
問題がある可能性のあるクエリまたはタグを特定する
問題がある可能性のあるクエリやリクエストタグを特定するには、上位 N 個のクエリのセクションを確認します。

ここでは、フィンガープリント 3216067328234137024 のクエリの CPU 使用率が高く、問題が発生している可能性があることがわかります。
上位 N 個のクエリのテーブルには、選択した期間中に最も多く CPU を使用したクエリの概要が降順で表示されます。上位 N 個のクエリの数は 100 に制限されています。
グラフ用に上位 N 個のクエリ統計情報のテーブルからデータを取得します。このテーブルには 1 分、10 分、1 時間の 3 つの粒度があります。グラフの各データポイントの値は、1 分間隔の平均値を表します。
SQL クエリにはタグを追加することをおすすめします。クエリをタグ付けすることで、ビジネス ロジックやマイクロサービスなど、より高レベルなコンストラクトでの問題を見つけることができます。

テーブルには以下のプロパティが表示されます。
- フィンガープリント: リクエストタグのハッシュ。タグがない場合は、クエリテキストのハッシュ。
クエリまたはリクエストタグ: クエリにタグが関連付けられている場合は、リクエストタグが表示されます。同じタグ文字列を持つ複数のクエリの統計情報は、そのタグ文字列に一致する
REQUEST_TAG値がある 1 行にグループ化されます。リクエストタグの使用方法については、リクエストタグとトランザクション タグによるトラブルシューティングをご覧ください。クエリに関連付けられたタグがない場合、約 64 KB に切り詰められた SQL クエリが表示されます。バッチ DML の場合、SQL ステートメントは区切り文字のセミコロンを使用して 1 行に連結されます。連続する同一の SQL テキストは、切り詰める前に重複が除去されます。
クエリタイプ: クエリが
PARTITIONED_QUERYかQUERYかを表します。PARTITIONED_QUERYは、PartitionQuery API から取得したpartitionTokenを使用したクエリです。他のすべてのクエリと DML ステートメントはQUERYクエリタイプになります。CPU 使用率: 1 つのクエリで使用される CPU リソースの使用量が、その期間内にデータベースで実行されているすべてのクエリが使用した合計 CPU リソースに対する割合で示されます(水平バーに表示、値の範囲は 0~100)。
推奨事項: Spanner はクエリを分析して、インデックスの改善でクエリのパフォーマンスが向上するかどうかを判断します。インデックスが不足している場合は、クエリのパフォーマンスを改善する可能性のある新しいインデックスまたはインデックスの変更が推奨されます。詳細については、Spanner インデックス アドバイザーを使用するをご覧ください。
CPU(%): クエリによって使用された CPU リソースの使用量が、その期間内にデータベースで実行されているすべてのクエリが使用した合計 CPU リソースに対する割合で示されます。
実行数: 期間中に Spanner がクエリを検出した回数。
平均レイテンシ(ms): データベース内での各クエリ実行の平均時間(ミリ秒)。この平均からは、オーバーヘッドだけでなく、結果セットのエンコードおよび伝送時間も除外されます。
平均スキャン行数: クエリでスキャンされた平均行数(削除された値を除く)。
平均戻り行数: クエリが返した平均行数。
戻りバイト数: クエリが返したデータバイト数(送信エンコードのオーバーヘッドを除く)。
グラフ間の差異
[合計 CPU 使用率(すべてのクエリ)] グラフと [合計 CPU 使用率(クエリまたはリクエストタグごと)] グラフとの間で相違がある場合があります。そのようになるシナリオとしては次の 2 つが考えられます。
異なるデータソース: 通常は、合計 CPU 使用率(すべてのクエリ)のグラフに示される Cloud Monitoring データのほうが正確です。これは、毎分 push され、45 日の保持期間が設定されているためです。一方、合計 CPU 使用率(クエリまたはリクエストタグごと)のグラフに示されるシステム テーブルデータは、平均をとる時間が 10 分(または 1 時間)にわたることがあり、その場合、合計 CPU 使用率(すべてのクエリ)に見られる高い粒度のデータが失われます。
異なる集計ウィンドウ: 両方のグラフで異なる集計ウィンドウが設定されています。たとえば、6 時間以上経過したイベントを調べる場合は、
SPANNER_SYS.QUERY_STATS_TOTAL_10MINUTEテーブルをクエリします。この場合、10:01 に発生したイベントは 10 分間にわたって集約され、10:10 のタイムスタンプに対応するシステム テーブルに表示されます。
次のスクリーンショットでは、このような差異の例を示します。

特定のクエリやリクエストタグを分析する
クエリやリクエストタグが問題の根本原因であるかどうかを判断するには、負荷が最大のクエリやリクエストタグ、または他のタグよりも時間がかかっているタグをクリックします。クエリやリクエストタグは、一度に複数選択できます。
タイムラインに沿ってクエリのグラフにマウスポインタを合わせると、CPU 使用率(秒)を確認できます。
以下のことを確認して、問題を絞り込んでみてください。
- 高い負荷がどのくらい続いていますか?高いのは今だけですか?それとも、長い間、高いですか?期間を変更して、クエリのパフォーマンスが悪化しはじめた日時を見つけます。
- CPU 使用率が急増していますか?時間枠を変更して、クエリの過去の CPU 使用率を調べることができます。
- リソースを消費しているのは何ですか?他のクエリとどのように関係していますか?テーブルを調べて、他のクエリのデータと選択したクエリを比較します。大きな違いはありますか?
選択したクエリが、高 CPU 使用率であることを確認するには、特定のクエリの形(またはリクエストタグ)の詳細をドリルダウンし、[クエリの詳細] ページで詳しく分析します。
クエリの詳細ページを表示する
特定のクエリの形やリクエストタグの詳細をグラフィカルな形式で表示するには、クエリやリクエストタグに関連付けられたフィンガープリントをクリックします。[クエリの詳細] ページが開きます。
![[クエリの詳細] ページ](https://docs.cloud.google.com/static/spanner/docs/images/query-details-v2.png?hl=ja)
[クエリの詳細] ページには、次の情報が表示されます。
- クエリ詳細テキスト: SQL クエリテキスト。約 64 KB に切り詰められます。同じタグ文字列を持つ複数のクエリの統計情報は、タグ文字列に一致する REQUEST_TAG がある 1 行にグループ化されます。このフィールドには、そうしたクエリのいずれかのテキストのみが表示されます。バッチ DML の場合、SQL ステートメントは、区切り文字のセミコロンを使用して 1 行に連結されます。連続する同一の SQL テキストは、切り詰める前に重複が除去されます。
- 次のフィールドの値:
- 実行数: 期間中に Spanner がクエリを検出した回数。
- 平均 CPU(ms): 一定の時間間隔で、インスタンスの CPU リソースのクエリによる平均 CPU リソース消費量(ミリ秒)。
- 平均レイテンシ(ms): データベース内での各クエリ実行の平均時間(ミリ秒)。この平均からは、結果セットとオーバーヘッドのエンコードと送信時間が除外されます。
- 平均戻り行数: クエリが返した平均行数。
- 平均スキャン行数: クエリでスキャンされた平均行数(削除された値を除く)。
- 平均バイト数: クエリで返されたデータバイト数(送信エンコードのオーバーヘッドを除く)。
- クエリプランのサンプルグラフ: グラフ上の各ドットは、特定の時間にサンプリングされたクエリプランとその特定のクエリ レイテンシを表します。グラフ内のドットのいずれかをクリックするとクエリプランが表示され、クエリの実行中に実行されたステップが可視化されます。注: クエリプランは、PartitionQuery API およびパーティション化 DML クエリから取得した partitionTokens を使用するクエリではサポートされません。
クエリプラン ビジュアライザー: 選択したサンプリングされたクエリプランを表示します。 Spanner には、次のレイアウト オプションが用意されています。
- ツリービュー: ツリービューは、クエリプランをグラフとして可視化します。各ノードまたはカードは、入力から行を取り込み、親に行を生成するイテレータを表します。各イテレータをクリックすると、詳細情報が表示されます。
シーケンシャル ビュー: シーケンシャル ビューは、各行がオペレーターを表す階層テーブルでクエリプランを可視化します。各行をクリックすると、詳細情報が表示されます。
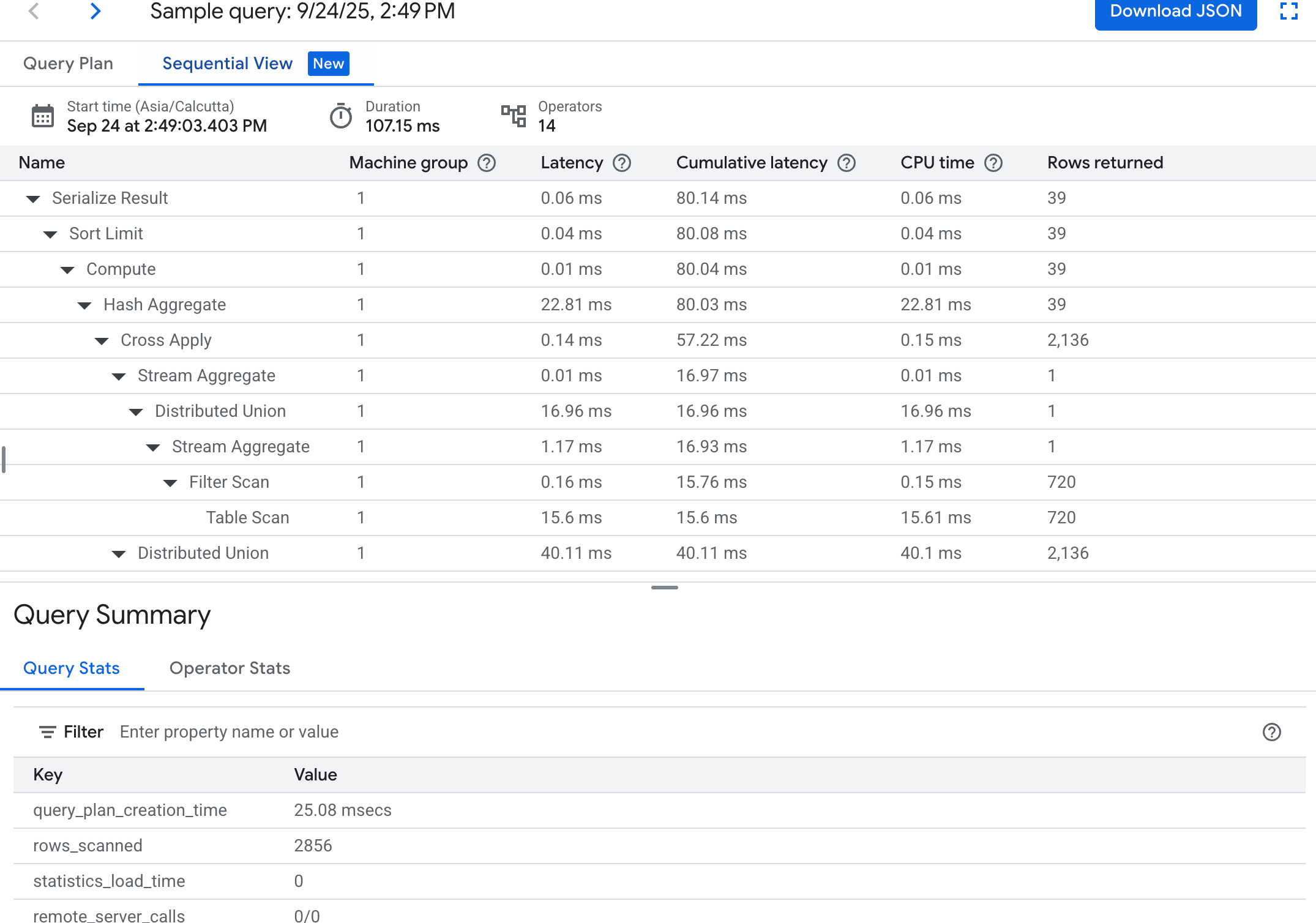
テーブルには次の列が表示されます。
- 名前: オペレーターの名前。
- マシングループ: このオペレーターが実行されたマシングループ。
- レイテンシ: 現在のオペレーションの実行中に経過した時間。この時間は、CPU 時間よりも長くなることがあります(たとえば、オペレーターがリモート呼び出しやファイルシステムの遅延により待機した場合など)。
- 累積レイテンシ: このオペレーターをルートとするサブツリー全体の実行中に経過した時間。これにはプラン作成時間やその他のオーバーヘッドは含まれていないため、累積レイテンシはクエリの合計時間よりも短くなることがあります。
- CPU 時間: クエリの実行に費やされた CPU 時間の合計。ネットワーク レイテンシは除外します。クエリ実行の一部は並列で進められることがあるため、CPU 時間は合計経過時間より長くなることがあります。たとえば、クエリで 1 ミリ秒(ms)間に 10 個の並列オペレーションが実行されると、経過時間は 1 ミリ秒ですが、CPU 時間は 10 ミリ秒になります。
- 返された行数: オペレーターによって返された行数。
クエリ レイテンシ グラフ: 一定期間のクエリのクエリ レイテンシの値が表示されます。また、平均レイテンシも表示されます。
CPU 使用率グラフ: 一定期間のクエリごとの CPU 使用率(%)が表示されます。また、平均 CPU 使用率も表示されます。
実行数 / 失敗グラフ: 一定期間のクエリの実行数とクエリ実行の失敗回数が表示されます。
スキャン行数: 一定期間にクエリがスキャンした行数が表示されます。
戻り行数: 一定期間にクエリが戻した行数が表示されます。
時間範囲フィルタ: 時間、日、カスタム範囲など、時間範囲でクエリの詳細をフィルタします。
グラフ用に上位 N 個のクエリ統計情報のテーブルからデータを取得します。このテーブルには 1 分、10 分、1 時間の 3 つの粒度があります。グラフの各データポイントの値は、1 分間隔の平均値を表します。
監査ログでクエリのすべての実行を検索する
Cloud Audit Logs で特定のクエリ フィンガープリントのすべての実行を検索するには、監査ログをクエリし、上位 N 個のクエリ統計情報テーブルで Fingerprint フィールドに一致する query_fingerprint を検索します。詳細については、ログのクエリと表示の概要をご覧ください。この方法でクエリを開始したユーザーを特定します。