
本頁說明如何使用查詢洞察資訊主頁,偵測及分析 Spanner 效能問題。
查詢洞察總覽
查詢洞察可協助您偵測及診斷 Spanner 資料庫的查詢和 DML (INSERT、UPDATE 和 DELETE) 陳述式效能問題。這項功能支援直覺化的監控工具,並提供診斷資訊,協助您在偵測到效能問題後,進一步找出根本原因。
查詢洞察會引導您完成下列步驟,協助您提升 Spanner 查詢效能:
查詢洞察功能適用於單一區域和多區域設定。
定價
查詢洞察功能不會產生額外費用。
資料保留
查詢洞察最多會保留 30 天的資料。
在「CPU 總使用率 (按『查詢』或『要求』標記顯示)」圖表中,Spanner 會從 SPANNER_SYS.QUERY_STATS_TOP_* 資料表擷取資料。這些資料表最多可保留 30 天。詳情請參閱「資料保留」一文。
必要的角色
視您是 IAM 使用者還是精細存取權控管使用者,您需要不同的 IAM 角色和權限。
身分與存取權管理 (IAM) 使用者
如要取得查看「查詢洞察」頁面所需的權限,請要求管理員在執行個體中授予您下列 IAM 角色:
- Cloud Spanner 檢視者 (
roles/spanner.viewer) - Cloud Spanner 資料庫讀取者 (
roles/spanner.databaseReader)
如要查看「查詢洞察」頁面,必須具備 Cloud Spanner 資料庫讀取者(
roles/spanner.databaseReader) 角色的下列權限:
spanner.databases.beginReadOnlyTransactionspanner.databases.selectspanner.sessions.create
精細的存取控管使用者
如果您是精細存取控管機制使用者,請確認下列事項:
- 具備 Cloud Spanner 檢視者(
roles/spanner.viewer) 角色 - 擁有精細的存取控管權限,並獲派
spanner_sys_reader系統角色或其中一個成員角色。 - 在資料庫總覽頁面中,選取
spanner_sys_reader或成員角色做為目前的系統角色。
詳情請參閱「關於精細存取控管」和「精細存取控管系統角色」。
查詢洞察資訊主頁
查詢洞察資訊主頁會根據您選取的資料庫和時間範圍,顯示查詢負載。查詢負載可測量所選時間範圍內,執行個體中所有查詢的總 CPU 使用率。資訊主頁提供一系列篩選器,可協助您查看查詢負載。
如要查看資料庫的「查詢洞察」資訊主頁,請按照下列步驟操作:
- 選取左側導覽面板中的「查詢洞察」,查詢洞察資訊主頁隨即開啟。
- 從「資料庫」清單中選取資料庫。資訊主頁會顯示資料庫的查詢負載資訊。
資訊主頁包含以下區域:
- 資料庫清單:篩選特定資料庫或所有資料庫的查詢負載。
- 時間範圍篩選器:依時間範圍 (例如小時、天或自訂範圍) 篩選查詢負載。
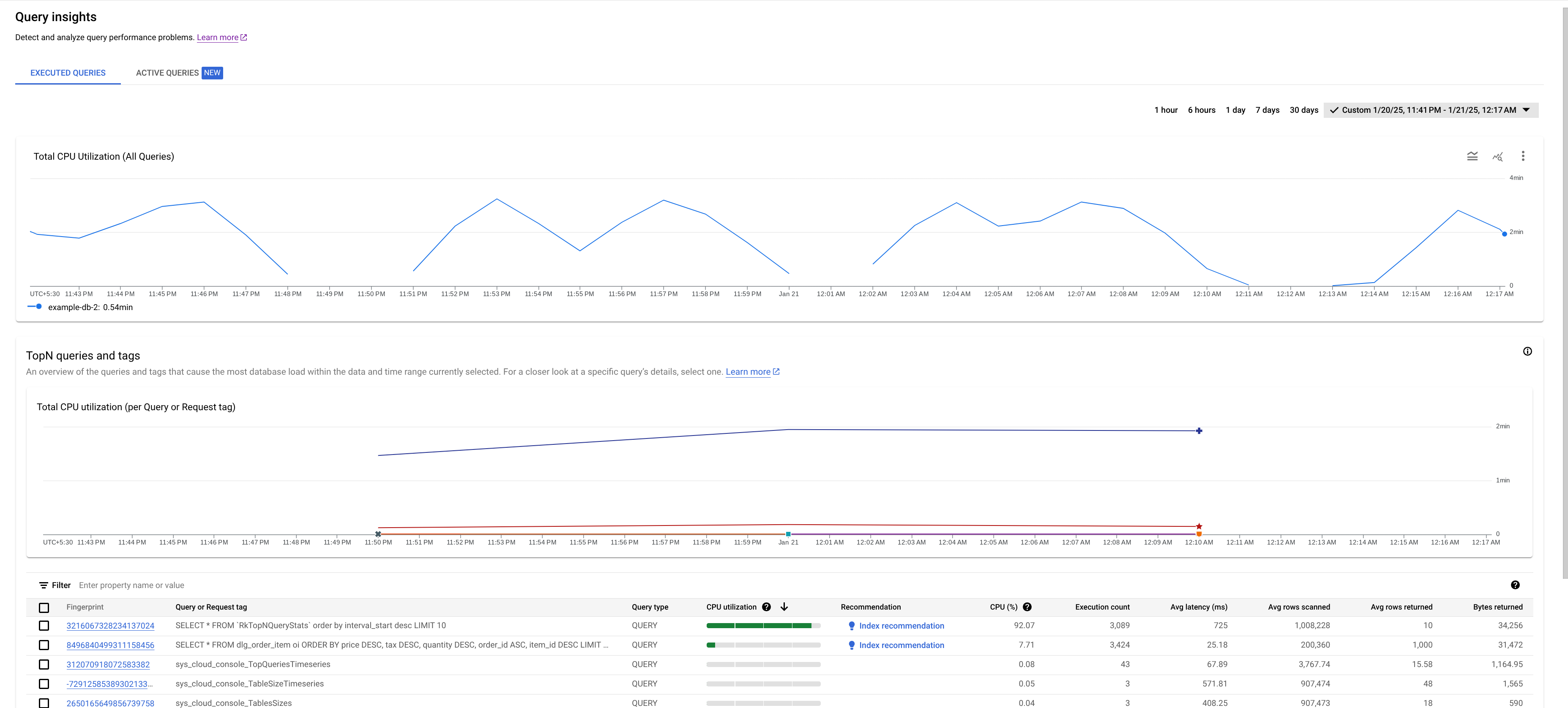
- CPU 總使用率 (所有查詢) 圖表:顯示所有查詢的 CPU 使用率平均值 (以每分鐘的 CPU 秒數為單位)。
- CPU 總使用率 (按「查詢」或「要求」標記顯示) 圖表:顯示每個查詢或要求標記的平均 CPU 使用率 (以每分鐘 CPU 秒數為單位)。
- TopN 查詢和標記表格:顯示依 CPU 使用率排序的熱門查詢和要求標記清單。請參閱「找出可能導致問題的查詢或代碼」。
資訊主頁效能
使用查詢參數或為查詢加上標記,提升查詢深入分析的效能。如果您未將查詢參數化或加上標記,系統可能會傳回過多結果,導致 TopN 查詢和標記表格無法正常載入。
確認高 CPU 使用率是否是由效率不彰的查詢所致
CPU 總使用率是衡量所選資料庫中執行的查詢作業,過去每分鐘的平均 CPU 使用率 (以 CPU 使用秒數為單位)。

查看圖表,瞭解下列問題的答案:
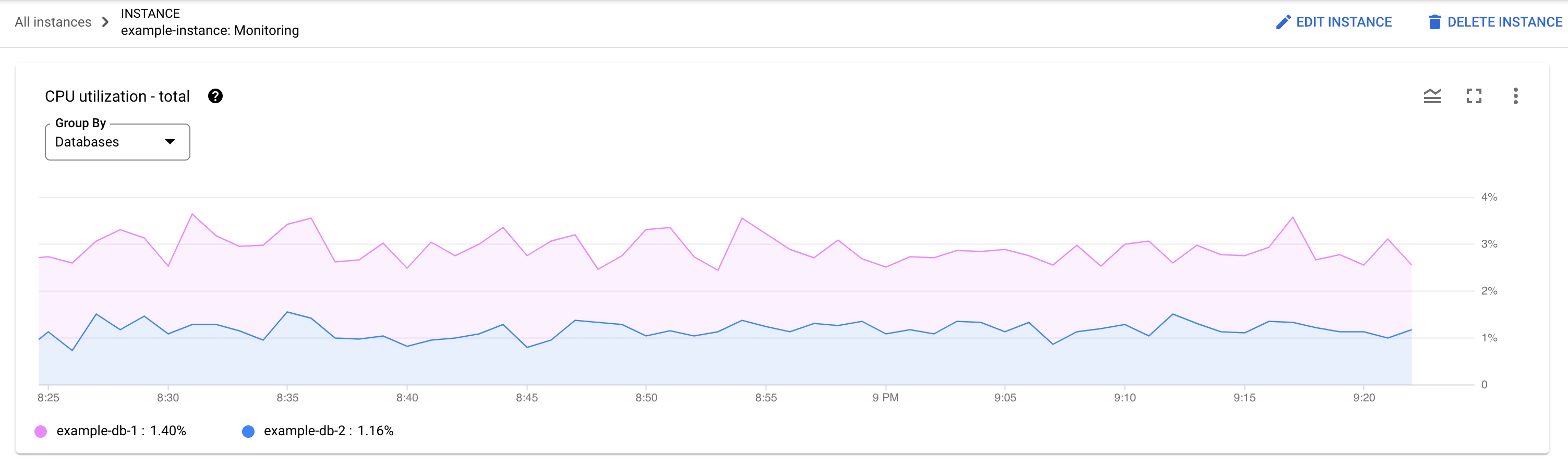
哪個資料庫負載過重?從「資料庫」清單中選取不同資料庫,找出負載最高的資料庫。如要找出負載最高的資料庫,您也可以查看Google Cloud 控制台中資料庫的「CPU 使用率 - 總計」圖表。
CPU 使用率是否偏高?圖表是否顯示一段時間內出現尖峰或高點?如果 CPU 使用率不高,問題就不是出在查詢。
CPU 使用率偏高的情況持續多久了?是最近突然暴增,還是已經持續一段時間?使用範圍選取器選取不同時間範圍,瞭解問題持續時間。放大即可查看查詢負載尖峰時段。縮小時間軸,最多可查看一週的資料。
如果圖表顯示整體執行個體 CPU 使用率有尖峰或上升趨勢,很可能是因為一或多個耗用資源的查詢。接下來,您可以找出可能導致問題的查詢或要求代碼,進一步進行偵錯。
找出可能導致問題的查詢或要求標記
如要找出可能發生問題的查詢或要求標記,請觀察 TopN 查詢部分:
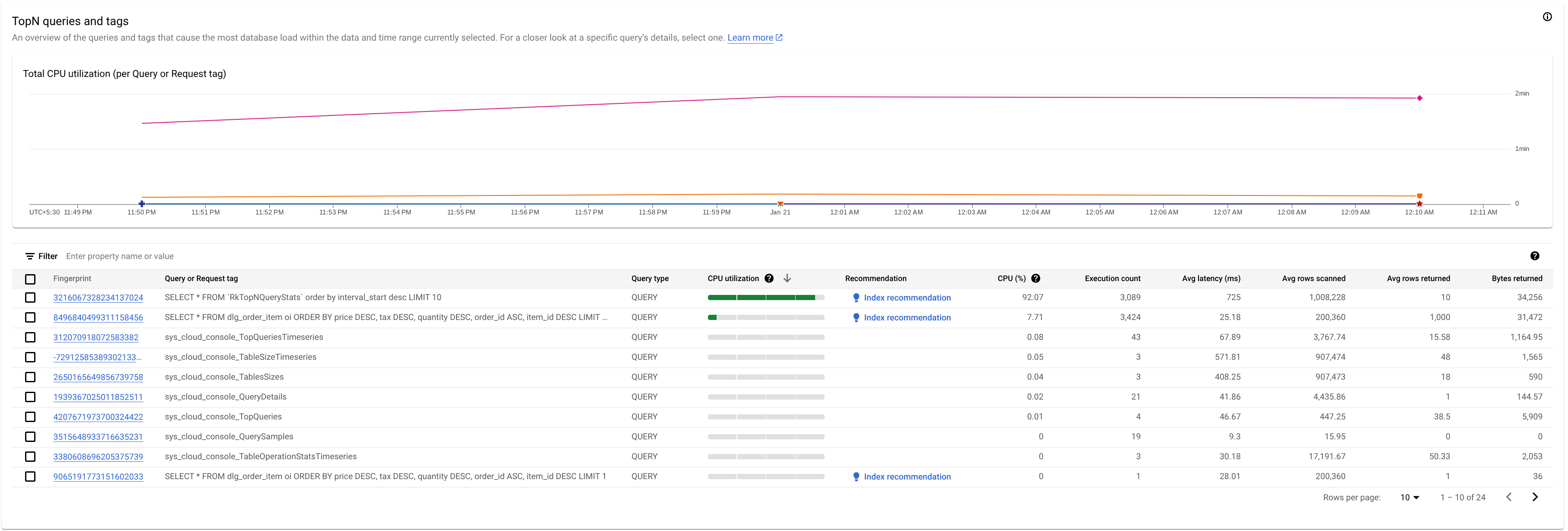
從這裡可以看出,指紋為 3216067328234137024 的查詢 CPU 使用率偏高,可能會有問題。
「前幾名查詢」表格會列出所選時間範圍內,CPU 使用率最高的查詢,並從高到低排序。TopN 查詢的數量上限為 100。
對於圖表,我們會從「前 N 個熱門查詢」統計資料表擷取資料,該資料表有三種不同的精細程度:1 分鐘、10 分鐘和 1 小時。圖表中每個資料點的值,代表一分鐘間隔內的平均值。
建議您在 SQL 查詢中加入標記。查詢標記有助於找出高階建構中的問題,例如商業邏輯或微服務。

表格會顯示下列屬性:
- 指紋:要求標記的雜湊,如果沒有標記,則為查詢文字的雜湊。
查詢或要求標記:如果查詢有相關聯的標記,系統會顯示要求標記。如果多個查詢具有相同的標記字串,系統會將這些查詢的統計資料歸入單一資料列,且
REQUEST_TAG值會與標記字串相符。如要進一步瞭解如何使用要求標記,請參閱「解決要求標記和交易標記問題」。如果查詢沒有相關聯的標記,系統會顯示 SQL 查詢,只顯示約 64KB 的內容。如果是批次 DML,系統會將 SQL 陳述式扁平化為單一資料列,並使用半形分號分隔符號串連。系統會先移除連續相同的 SQL 文字,再截斷文字。
查詢類型:指出查詢是
PARTITIONED_QUERY或QUERY。PARTITIONED_QUERY是指透過 PartitionQuery API 取得partitionToken的查詢。所有其他查詢和 DML 陳述式都會以QUERY查詢類型表示。「CPU Utilization」(CPU 使用率):查詢消耗的 CPU 資源,以百分比表示,相較於該時間間隔內資料庫上執行的所有查詢所使用的 CPU 資源總數,並顯示在範圍為 0 到 100 的水平長條上。
建議:Spanner 會分析查詢,判斷是否能透過改善索引提升效能。如果查詢效能不佳,系統會建議建立或修改索引,詳情請參閱「使用 Spanner 索引建議工具」。
CPU (%):查詢作業耗用的 CPU 資源,以百分比表示,計算方式為查詢作業耗用的 CPU 資源除以該時間間隔內,資料庫中所有查詢作業耗用的 CPU 資源總量。
執行次數:Spanner 在間隔期間看到的平均查詢執行率 (每分鐘執行次數)。
平均延遲時間 (毫秒):資料庫內每個查詢執行的平均時間長度,以微秒為單位。這個平均值會排除結果集和額外負荷的編碼與傳輸時間。
平均掃描列數:查詢掃描的平均列數,不包含已刪除的值。
平均傳回列數:查詢傳回的平均列數。
傳回的位元組數:查詢傳回的資料位元組數,不包含傳輸編碼額外負荷。
圖表之間可能存在差異
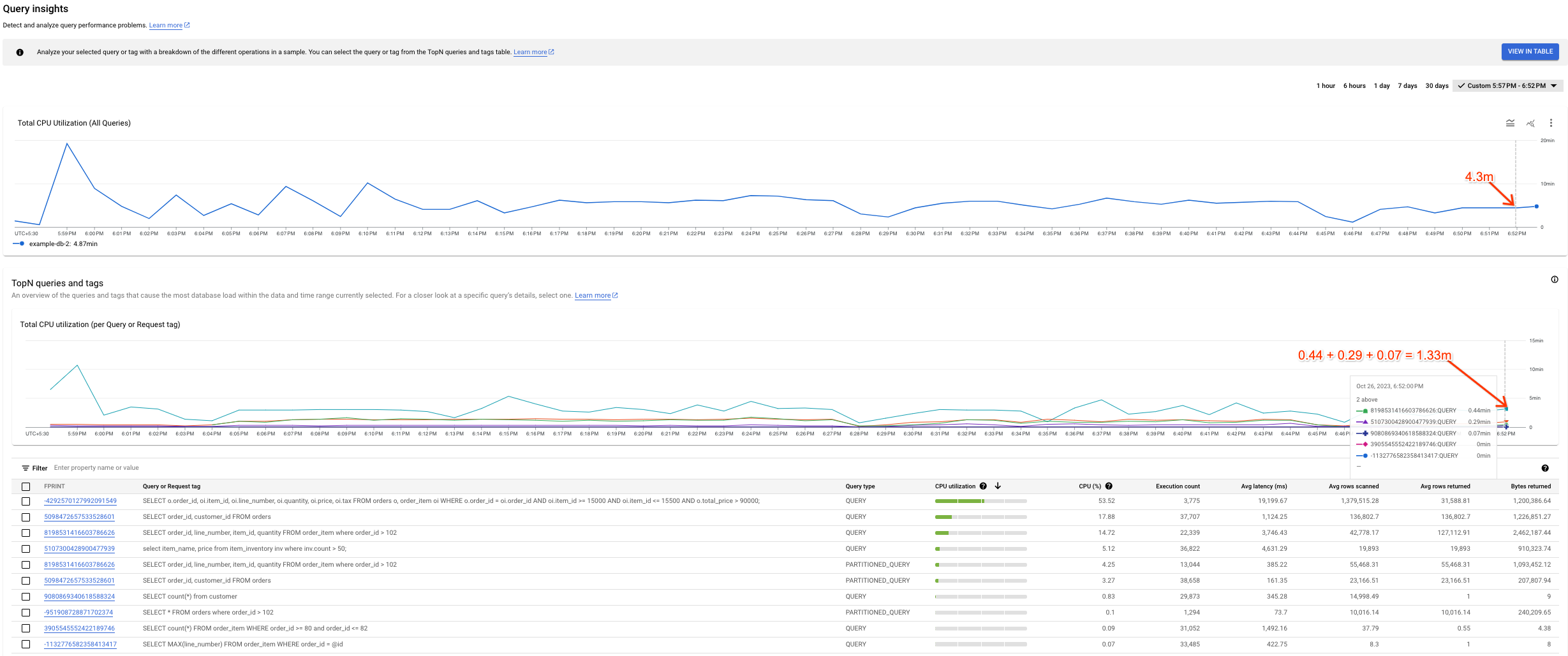
您可能會發現「CPU 總使用率 (所有查詢)」圖表與「CPU 總使用率 (按『查詢』或『要求』標記顯示)」圖表之間有些差異。有兩種情況可能導致這種情況:
資料來源不同:Cloud Monitoring 資料會提供「CPU 總使用率 (所有查詢)」圖表,通常會更準確,因為這類資料每分鐘都會推送,且保留期限為 45 天。另一方面,系統資料表資料 (用於提供「CPU 總使用率 (按『查詢』或『要求』標記顯示)」圖表) 可能會以 10 分鐘 (或 1 小時) 為間隔計算平均值,因此我們可能會遺失「CPU 總使用率 (所有查詢)」圖表中的高精細度資料。
不同的匯總時間範圍:兩張圖表的匯總時間範圍不同。舉例來說,如果檢查的事件發生時間超過 6 小時,我們會查詢
SPANNER_SYS.QUERY_STATS_TOTAL_10MINUTE表格。在這種情況下,10:01 發生事件的資料會匯總 10 分鐘,並出現在 10:10 時間戳記對應的系統資料表中。
下圖顯示這類差異的範例。
分析特定查詢或要求標記
如要判斷查詢或要求標記是否為問題的根本原因,請點選負載量最高或耗時最長的查詢或要求標記。您可以一次選取多個查詢和要求標記。
您可以將滑鼠游標懸停在時間軸上的查詢圖表,瞭解查詢的 CPU 使用率 (以秒為單位)。
請查看下列項目,嘗試縮小問題範圍:
- 負荷過高多久了?目前只有高嗎?還是長期偏高?變更時間範圍,找出查詢開始表現不佳的日期和時間。
- CPU 使用率是否突然飆升?您可以變更時間範圍,研究查詢的 CPU 使用率記錄。
- 資源用量是多少?這項查詢與其他查詢有何關聯? 查看表格,比較其他查詢與所選查詢的資料。兩者有什麼重大差異嗎?
如要確認所選查詢是否導致 CPU 使用率偏高,可以深入瞭解特定查詢形狀 (或要求標記) 的詳細資料,並在「查詢詳細資料」頁面進一步分析。
查看「查詢詳細資料」頁面
如要以圖形形式查看特定查詢形狀或要求標記的詳細資料,請按一下與查詢或要求標記相關聯的指紋。「查詢詳細資料」頁面隨即開啟。
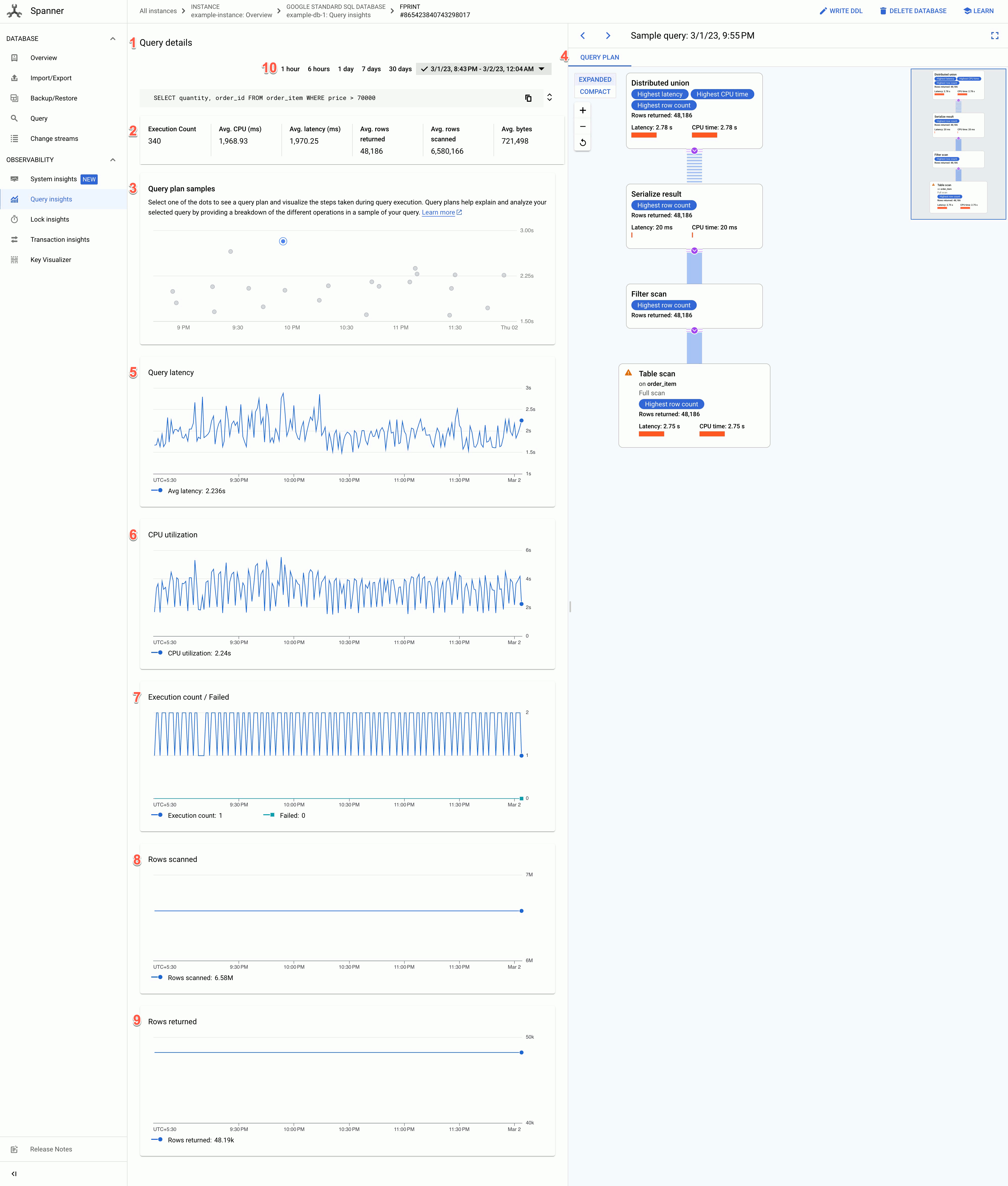
「查詢詳細資料」頁面會顯示下列資訊:
- 查詢詳細資料文字:SQL 查詢文字,只顯示約 64KB 的內容。 如果多個查詢項目具有相同的標記字串,系統會將這些查詢項目的統計資料分組,並在單一資料列中顯示,且 REQUEST_TAG 會與該標記字串相符。這個欄位只會顯示其中一個查詢的文字。如果是批次 DML,系統會將一組 SQL 陳述式壓平為單一資料列,並使用半形分號分隔符號串連。系統會先對連續相同的 SQL 文字進行重複資料刪除,再截斷文字。
- 下列欄位的值:
- 執行次數:Spanner 在間隔期間看到的查詢執行平均速率,以每分鐘執行次數為單位。
- 平均 CPU (毫秒):在時間間隔內,執行個體 CPU 資源的查詢所耗用的平均 CPU 資源 (以毫秒為單位)。
- 平均延遲時間 (毫秒):資料庫內每個查詢執行的平均時間長度,以毫秒為單位。這個平均值會排除結果集和額外負荷的編碼與傳輸時間。
- 平均傳回列數:查詢傳回的平均列數。
- 平均掃描列數:查詢掃描的平均列數,不包含已刪除的值。
- 平均位元組數:查詢傳回的資料位元組數,不包含傳輸編碼額外負荷。
- 查詢計畫範例圖表:圖表上的每個點代表特定時間的查詢計畫範例,以及該查詢的特定延遲時間。按一下圖表中的任一點,即可查看查詢計畫,並以視覺化的方式瞭解查詢執行期間採取的步驟。注意:查詢計畫不支援使用從 PartitionQuery API 取得的 partitionTokens 進行的查詢,以及分區 DML 查詢。
查詢計畫視覺化工具:顯示所選的查詢計畫樣本。 Spanner 提供下列版面配置選項:
- 樹狀檢視:樹狀檢視會將查詢計畫顯示為圖表,其中每個節點或資訊卡代表一個疊代器,會從輸入內容取用資料列,並產生資料列給父項。您可以點選每個疊代器,查看擴展資訊。
依序檢視:依序檢視會以階層式表格呈現查詢計畫,每個資料列代表一個運算子。按一下各個資料列,即可展開查看詳細資訊。
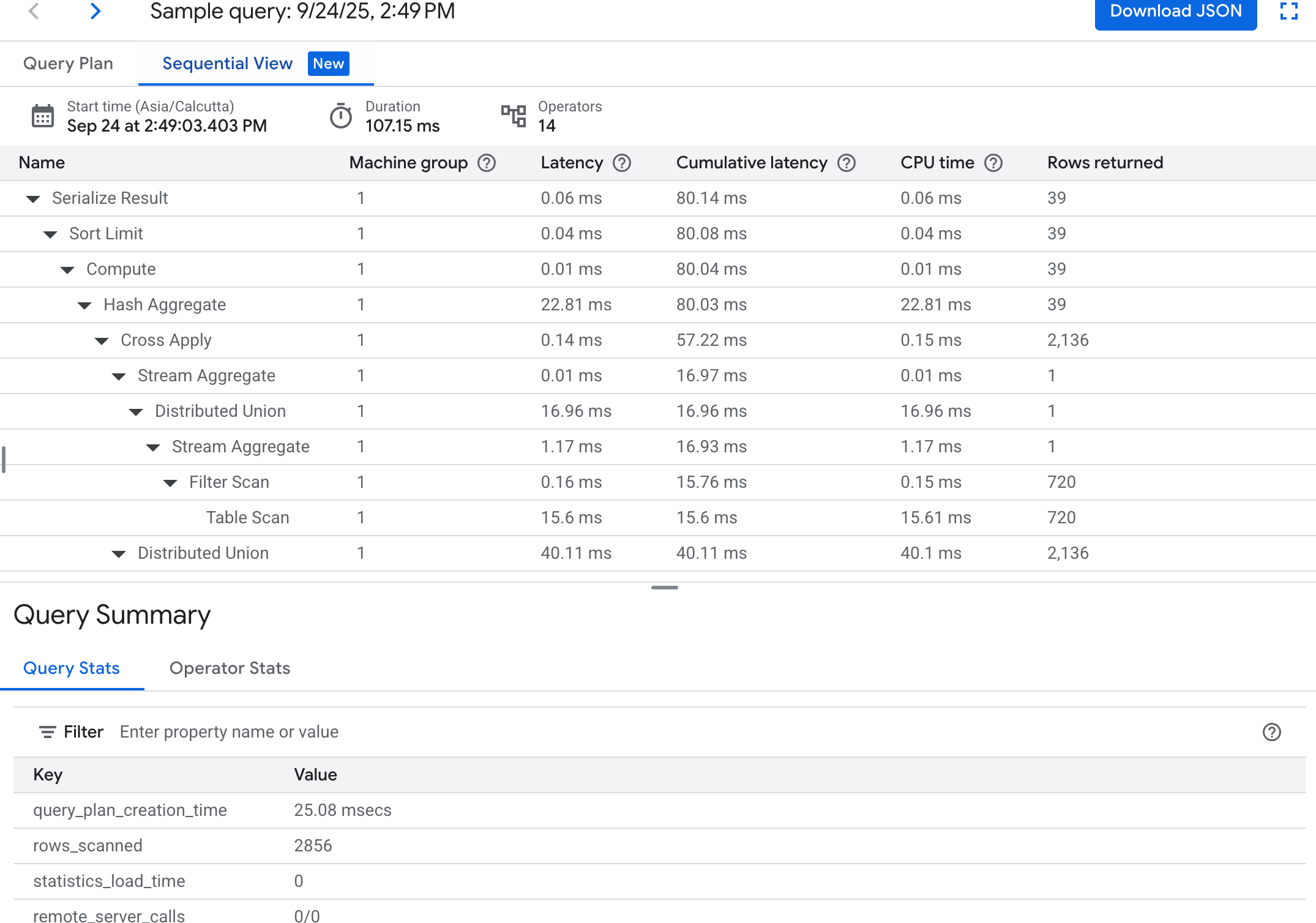
資料表會顯示下列資料欄:
- 名稱:運算子名稱。
- 機器群組:這個運算子執行的機器群組。
- 延遲:執行目前作業時經過的時間長度。這可能會超過 CPU 作業時間 (例如,運算子因遠端呼叫或檔案系統延遲而等待時,就可能會超過)。
- 累計延遲時間:以這個運算子為根層級的整個子樹狀結構,執行作業耗費的時間總和。這不包括方案建立時間和其他營運負載,因此累計延遲時間可能短於查詢總時長。
- CPU 時間:執行查詢耗費的總 CPU 作業時間。不含網路延遲時間。查詢執行作業的某些部分可能會平行進行,因此 CPU 作業時間有可能超過總執行時間。舉例來說,如果查詢在 1 毫秒內執行 10 項平行作業,執行時間為 1 毫秒,不過 CPU 作業時間會是 10 毫秒。
- 傳回的資料列:運算子傳回的資料列數。
查詢延遲時間圖表:顯示所選查詢在一段時間內的查詢延遲時間值。還會顯示平均延遲時間。
CPU 使用率圖表:顯示查詢在一段時間範圍內的 CPU 使用率百分比。還會顯示平均 CPU 使用率。
執行次數/失敗次數圖表:顯示一段時間範圍內的平均查詢執行率 (每分鐘執行次數),以及平均查詢執行失敗率 (每分鐘失敗次數)。
掃描的資料列數圖表:顯示查詢在一段時間範圍內掃描的資料列數。
傳回的資料列數圖表:顯示查詢在一段時間範圍內傳回的資料列數。
時間範圍篩選器:依時間範圍 (例如小時、天或自訂範圍) 篩選查詢詳細資料。
對於圖表,我們會從「前 N 個熱門查詢」統計資料表擷取資料,該資料表有三種不同的精細程度:1 分鐘、10 分鐘和 1 小時。圖表中每個資料點的值,代表一分鐘間隔內的平均值。
在稽核記錄中搜尋查詢的所有執行作業
如要在 Cloud 稽核記錄中搜尋特定查詢指紋的所有執行作業,請查詢稽核記錄,並搜尋「TopN 查詢統計資料」表格中與 Fingerprint 欄位相符的任何 query_fingerprint。詳情請參閱「查詢和查看記錄檔總覽」。使用這個方法找出啟動查詢的使用者。