
Auf dieser Seite wird beschrieben, wie Sie mit dem Query Insights-Dashboard Leistungsprobleme in Spanner erkennen und analysieren.
Übersicht über Query Insights
Mit Query Insights können Sie Leistungsprobleme bei Abfragen und DML-Anweisungen (INSERT, UPDATE und DELETE) für eine Spanner-Datenbank erkennen und diagnostizieren. Es unterstützt ein intuitives Monitoring und liefert Diagnoseinformationen, die Ihnen helfen, über die Erkennung hinaus die Ursache von Leistungsproblemen zu identifizieren.
Mit Query Insights können Sie die Leistung von Spanner-Abfragen verbessern. Dabei werden Sie durch die folgenden Schritte geführt:
- Ermitteln, ob ineffiziente Abfragen eine hohe CPU-Auslastung verursachen.
- Potenziell problematische Abfrage oder potenziell problematisches Tag identifizieren
- Abfrage oder Anfrage-Tag analysieren, um Probleme zu ermitteln
Query Insights ist in Konfigurationen für eine und mehrere Regionen verfügbar.
Preise
Für Query Insights fallen keine zusätzlichen Kosten an.
Datenaufbewahrung
Daten in Query Insights werden maximal 30 Tage lang aufbewahrt.
Für das Diagramm Gesamte CPU-Auslastung (pro Abfrage oder Anfrage-Tag) ruft Spanner Daten aus den SPANNER_SYS.QUERY_STATS_TOP_*-Tabellen ab. Die Daten in diesen Tabellen werden maximal 30 Tage lang aufbewahrt. Weitere Informationen
Erforderliche Rollen
Je nachdem, ob Sie ein IAM-Nutzer oder ein Nutzer mit detaillierter Zugriffssteuerung sind, benötigen Sie unterschiedliche IAM-Rollen und -Berechtigungen.
Identity and Access Management (IAM)-Nutzer
Bitten Sie Ihren Administrator, Ihnen die folgenden IAM-Rollen für die Instanz zuzuweisen, um die Berechtigungen zu erhalten, die Sie zum Aufrufen der Seite „Query Insights“ benötigen:
- Cloud Spanner-Betrachter (
roles/spanner.viewer) - Cloud Spanner-Datenbank-Leser (
roles/spanner.databaseReader)
Die folgenden Berechtigungen in der Rolle Cloud Spanner Database Reader(
roles/spanner.databaseReader) sind erforderlich, um die Seite „Query Insights“ aufzurufen:
spanner.databases.beginReadOnlyTransactionspanner.databases.selectspanner.sessions.create
Nutzer mit detaillierter Zugriffssteuerung
Wenn Sie die detaillierte Zugriffssteuerung verwenden, prüfen Sie, ob Sie Folgendes getan haben:
- Sie haben die Rolle Cloud Spanner-Betrachter(
roles/spanner.viewer). - Sie haben detaillierte Berechtigungen für die Zugriffssteuerung und ihnen ist die Systemrolle
spanner_sys_readeroder eine ihrer Mitgliedsrollen zugewiesen. - Wählen Sie auf der Seite „Datenbankübersicht“ die Rolle
spanner_sys_readeroder eine Mitgliedsrolle als aktuelle Systemrolle aus.
Weitere Informationen finden Sie unter Detaillierte Zugriffssteuerung und Systemrollen für die detaillierte Zugriffssteuerung.
Das Query Insights-Dashboard
Im Query Insights-Dashboard wird die Abfragelast basierend auf der von Ihnen ausgewählten Datenbank und dem ausgewählten Zeitraum angezeigt. Die Abfragelast ist ein Maß für die gesamte CPU-Auslastung aller Abfragen in der Instanz im ausgewählten Zeitraum. Das Dashboard bietet eine Reihe von Filtern, mit denen Sie die Abfragelast anzeigen können.
So rufen Sie das Dashboard „Query Insights“ für eine Datenbank auf:
- Wählen Sie im linken Navigationsbereich Query Insights aus. Das Dashboard „Query Insights“ wird geöffnet.
- Wählen Sie eine Datenbank aus der Liste Datenbanken aus. Das Dashboard enthält Informationen zur Abfragelast für die Datenbank.
Zu den Bereichen des Dashboards gehören:
- Datenbankliste: Filtert die Abfragelast für eine bestimmte Datenbank oder für alle Datenbanken.
- Zeitraumfilter: Filtert die Abfragelast nach Zeiträumen, z. B. Stunden, Tagen oder einem benutzerdefinierten Bereich.
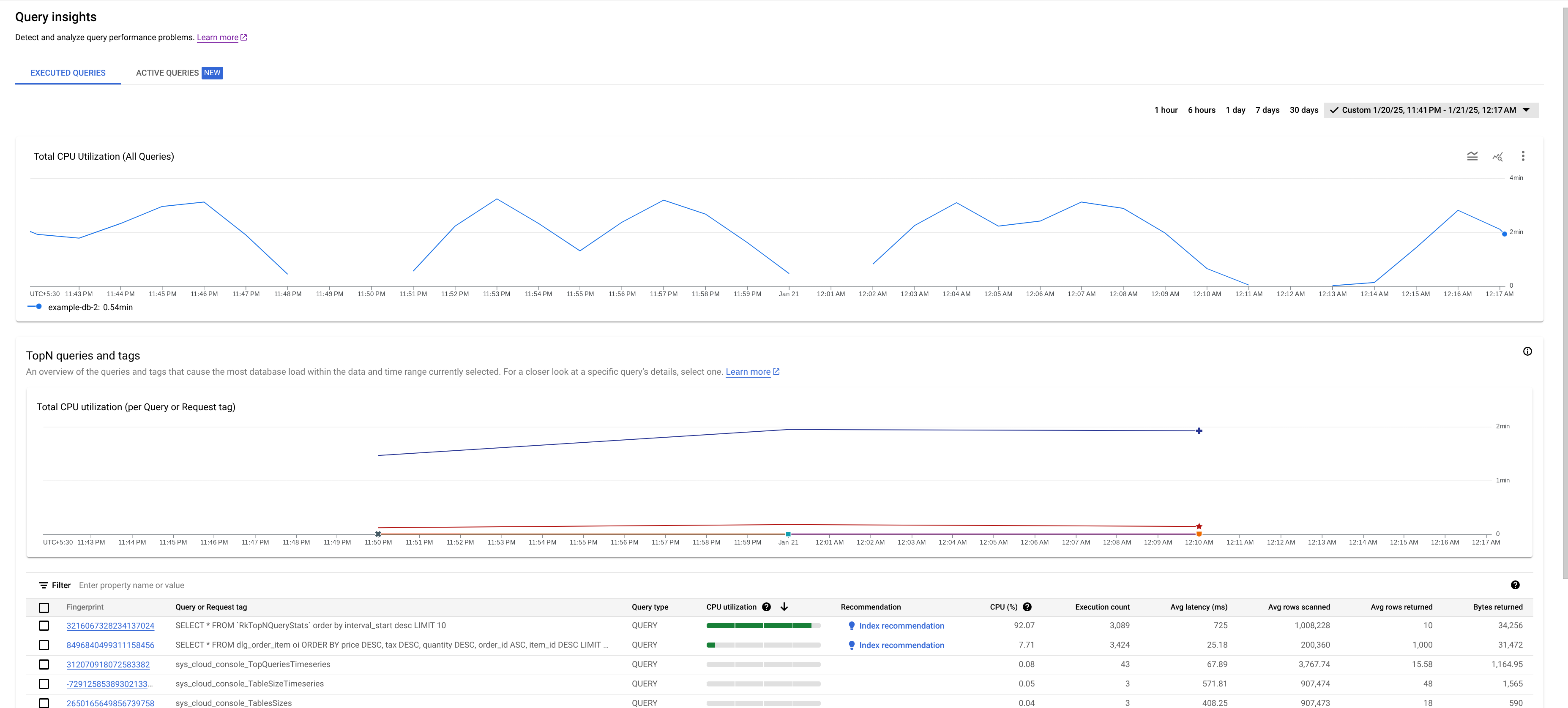
- Diagramm „Gesamte CPU-Auslastung (alle Abfragen)“: Zeigt die aggregierte durchschnittliche CPU-Nutzungsrate (in CPU-Sekunden pro Minute) aller Abfragen an.
- Diagramm „Gesamte CPU-Auslastung (pro Abfrage- oder Anfrage-Tag)“: Hier wird die durchschnittliche CPU-Auslastung (in CPU-Sekunden pro Minute) für jede Abfrage oder jedes Anfrage-Tag dargestellt.
- Tabelle „Top-N-Abfragen und -Tags“: Hier wird die Liste der Top-Abfragen und ‑Anfrage-Tags nach CPU-Auslastung sortiert angezeigt. Weitere Informationen finden Sie unter Potenziell problematische Abfrage oder potenziell problematisches Tag identifizieren.
Dashboard-Leistung
Verwenden Sie Abfrageparameter oder taggen Sie Ihre Abfragen, um die Leistung von Query Insights zu optimieren. Wenn Sie Ihre Abfragen nicht parametrisieren oder taggen, werden möglicherweise zu viele Ergebnisse zurückgegeben. Das kann dazu führen, dass die Tabelle „TopN-Abfragen und ‑Tags“ nicht richtig geladen wird.
Prüfen, ob ineffiziente Abfragen für eine hohe CPU-Auslastung verantwortlich sind
Die gesamte CPU-Auslastung ist ein Maß für die durchschnittliche CPU-Nutzungsrate (in CPU-Sekunden pro Minute), die von den ausgeführten Abfragen in der ausgewählten Datenbank im Zeitverlauf ausgeführt wird.

Sehen Sie sich das Diagramm an, um diese Fragen zu beantworten:
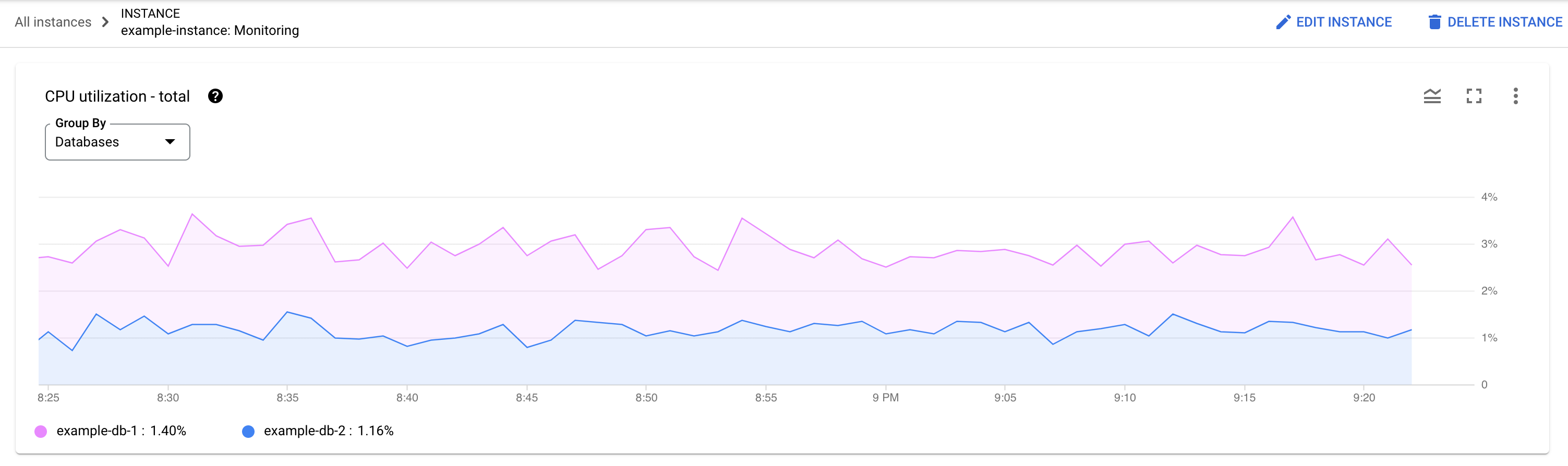
Welche Datenbank hat die Auslastung? Wählen Sie in der Liste „Datenbanken“ verschiedene Datenbanken aus, um die Datenbanken mit den höchsten Lasten zu finden. Um herauszufinden, welche Datenbank die höchste Last hat, können Sie auch das Diagramm CPU-Auslastung – insgesamt für Datenbanken in der Google Cloud -Konsole ansehen.
Ist die CPU-Auslastung hoch? Ist eine Spitze oder ein Anstieg im Zeitverlauf zu sehen? Wenn keine hohe CPU-Auslastung angezeigt wird, liegt das Problem nicht bei Ihren Abfragen.
Wie lange war die CPU-Auslastung hoch? Ist sie erst vor Kurzem gestiegen oder war sie schon länger hoch? Verwenden Sie die Bereichsauswahl, um verschiedene Zeiträume auszuwählen, um herauszufinden, wie lange das Problem besteht. Vergrößern Sie die Ansicht, um ein Zeitfenster zu sehen, in dem Spitzen bei der Abfragelast beobachtet werden. Zoomen Sie heraus, um bis zu einer Woche der Zeitachse anzuzeigen.
Wenn Sie im Diagramm einen Anstieg oder eine Erhöhung sehen, die der gesamten CPU-Nutzung der Instanz entspricht, liegt das höchstwahrscheinlich an einer oder mehreren ressourcenintensiven Abfragen. Als Nächstes können Sie sich das Debugging genauer ansehen, indem Sie ein potenziell problematisches Abfrage- oder Anfrage-Tag identifizieren.
Potenziell problematisches Abfrage- oder Anfrage-Tag identifizieren
Sehen Sie sich den Bereich „TopN-Abfragen“ an, um eine potenziell problematische Abfrage oder ein potenziell problematisches Anfragetag zu identifizieren:
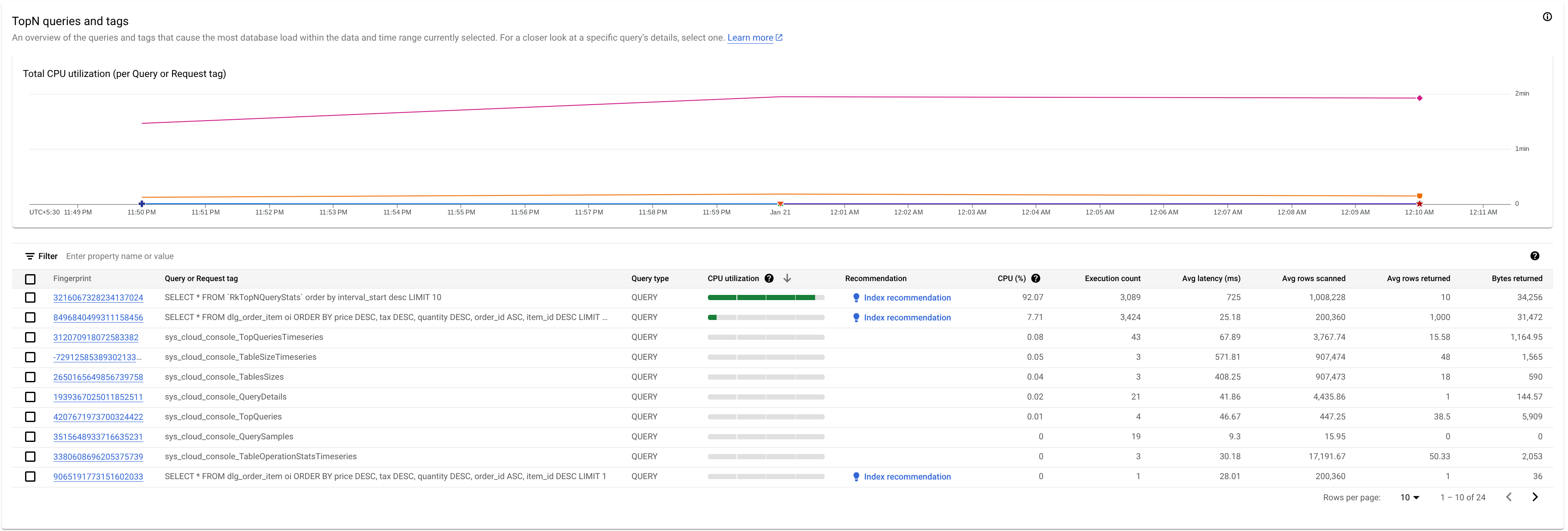
Hier sehen wir, dass die Abfrage mit dem Fingerabdruck 3216067328234137024 eine hohe CPU-Auslastung hat und problematisch sein kann.
Die Tabelle TopN-Abfragen bietet einen Überblick über die Abfragen, die im ausgewählten Zeitraum die meiste CPU-Zeit in Anspruch nehmen. Die Abfragen sind nach CPU-Zeit sortiert, von der höchsten zur niedrigsten. Die Anzahl der TopN-Abfragen ist auf 100 begrenzt.
Für die Diagramme rufen wir die Daten aus der Tabelle mit den Statistiken für Top-N-Abfragen ab, die drei verschiedene Granularitäten hat: 1 Minute, 10 Minuten und 1 Stunde. Der Wert für jeden Datenpunkt in den Diagrammen steht für den Durchschnittswert über ein Intervall von einer Minute.
Wir empfehlen, Tags zu SQL-Abfragen hinzuzufügen. Mit der Tag-Kennzeichnung von Abfragen können Sie Probleme auf übergeordneten Konstrukten finden, z. B. mit der Geschäftslogik oder einem Mikrodienst.

Die Tabelle enthält die folgenden Attribute:
- Fingerprint: Hash des Request-Tags oder, falls das Tag nicht vorhanden ist, ein Hash des Abfragetextes.
Abfrage- oder Anfrage-Tag: Wenn der Abfrage ein Tag zugeordnet ist, wird das Anfrage-Tag angezeigt. Statistiken für mehrere Abfragen, die denselben Tag-String haben, werden in einer einzelnen Zeile gruppiert, wobei der
REQUEST_TAG-Wert mit dem Tag-String übereinstimmt. Weitere Informationen zur Verwendung von Anfrage-Tags finden Sie unter Fehlerbehebung bei Anfrage- und Transaktions-Tags.Wenn der Abfrage kein Tag zugewiesen ist, wird die SQL-Abfrage angezeigt, die auf ca. 64 KB gekürzt wurde. Bei Batch-DML werden die SQL-Anweisungen in einer einzelnen Zeile zusammengefasst und mit einem Semikolon als Trennzeichen verkettet. Aufeinanderfolgende identische SQL-Texte werden vor dem Kürzen dedupliziert.
Abfragetyp: Gibt an, ob es sich bei einer Abfrage um eine
PARTITIONED_QUERYoderQUERYhandelt. EinePARTITIONED_QUERYist eine Abfrage mit einempartitionToken, der über die PartitionQuery API abgerufen wurde. Alle anderen Abfragen und DML-Anweisungen werden durch den AbfragetypQUERYgekennzeichnet.CPU-Auslastung: Der CPU-Ressourcenverbrauch einer Abfrage als Prozentsatz der gesamten CPU-Ressourcen, die von allen Abfragen verwendet werden, die im angegebenen Zeitraum in den Datenbanken ausgeführt werden. Die Werte werden in einem horizontalen Balken mit einem Bereich von 0 bis 100 dargestellt.
Empfehlung: Spanner analysiert Ihre Abfragen, um festzustellen, ob sie von verbesserten Indexen profitieren können. Falls ja, werden neue oder geänderte Indexe empfohlen, mit denen sich die Abfrageleistung verbessern lässt. Weitere Informationen finden Sie unter Indexberater für Spanner verwenden.
CPU (%): Der CPU-Ressourcenverbrauch einer Abfrage als Prozentsatz der gesamten CPU-Ressourcen, die von allen Abfragen verwendet werden, die in diesem Zeitraum in den Datenbanken ausgeführt werden.
Anzahl der Ausführungen: Die durchschnittliche Rate der Abfrageausführungen in Ausführungen pro Minute, die Spanner während des Intervalls registriert hat.
Durchschnittliche Latenz (ms): Durchschnittliche Zeit in Mikrosekunden für jede Abfrageausführung in der Datenbank. Dieser Durchschnitt schließt die Codierungs- und Übertragungszeit für die Ergebnismenge sowie den Aufwand aus.
Durchschnittlich gescannte Zeilen: Durchschnittliche Anzahl der Zeilen, die von der Abfrage gescannt wurden, ausgenommen gelöschte Werte.
Durchschnittliche zurückgegebene Zeilen: Durchschnittliche Anzahl der Zeilen, die die Abfrage zurückgegeben hat.
Zurückgegebene Byte: Anzahl der von der Abfrage zurückgegebenen Datenbyte, ohne den Aufwand der Übertragungskodierung.
Mögliche Abweichungen zwischen den Grafiken
Möglicherweise stellen Sie einige Abweichungen zwischen dem Diagramm Gesamte CPU-Auslastung (alle Abfragen) und dem Diagramm Gesamte CPU-Auslastung (pro Abfrage oder Anfrage-Tag) fest. Es gibt zwei mögliche Ursachen für dieses Szenario:
Verschiedene Datenquellen: Die Cloud Monitoring-Daten, die dem Diagramm „CPU-Gesamtauslastung (alle Anfragen)“ zugrunde liegen, sind in der Regel genauer, da sie jede Minute übertragen werden und eine Aufbewahrungsdauer von 45 Tagen haben. Andererseits werden die Daten der Systemtabelle, die dem Diagramm „Gesamte CPU-Auslastung (pro Abfrage oder Anfrage-Tag)“ zugrunde liegen, möglicherweise über 10 Minuten (oder 1 Stunde) gemittelt. In diesem Fall gehen möglicherweise Daten mit hoher Granularität verloren, die im Diagramm „Gesamte CPU-Auslastung (alle Abfragen)“ zu sehen sind.
Unterschiedliche Aggregationszeiträume: Beide Diagramme haben unterschiedliche Aggregationszeiträume. Wenn wir beispielsweise ein Ereignis untersuchen, das älter als 6 Stunden ist, fragen wir die Tabelle
SPANNER_SYS.QUERY_STATS_TOTAL_10MINUTEab. In diesem Fall würde ein Ereignis, das um 10:01 Uhr eintritt, über 10 Minuten hinweg aggregiert und in der Systemtabelle mit dem Zeitstempel 10:10 Uhr angezeigt.
Der folgende Screenshot zeigt ein Beispiel für eine solche Abweichung.

Bestimmte Abfrage oder bestimmtes Anfrage-Tag analysieren
Wenn Sie herausfinden möchten, ob eine Abfrage oder ein Anfrage-Tag die Ursache des Problems ist, klicken Sie auf die Abfrage oder das Anfrage-Tag, das vermeintlich die höchste Last hat oder mehr Zeit als die anderen benötigt. Sie können mehrere Abfragen und Tag-Anfragen gleichzeitig auswählen.
Wenn Sie den Mauszeiger auf das Diagramm für Abfragen im Zeitachsendiagramm bewegen, wird die CPU-Auslastung (in Sekunden) angezeigt.
Versuchen Sie, das Problem folgendermaßen einzugrenzen:
- Wie lange war die Last hoch? Ist sie nur jetzt hoch? Oder ist sie schon lange hoch? Ändern Sie die Zeiträume, um das Datum und die Uhrzeit zu ermitteln, zu der sich die Leistung der Abfrage verschlechterte.
- Gab es Spitzen bei der CPU-Auslastung? Sie können das Zeitfenster ändern, um die bisherige CPU-Auslastung für die Abfrage zu untersuchen.
- Wie hoch ist der Ressourcenverbrauch? Wie hängt er mit anderen Anfragen zusammen? Sehen Sie sich die Tabelle an und vergleichen Sie die Daten anderer Anfragen mit der ausgewählten. Gibt es einen großen Unterschied?
Um zu bestätigen, dass die ausgewählte Abfrage zur hohen CPU-Auslastung beiträgt, können Sie die Details der spezifischen Abfrageform (oder des Anfragetags) aufrufen und auf der Seite „Abfragedetails“ weiter analysieren.
Detailseite der Abfrage aufrufen
Wenn Sie die Details einer bestimmten Abfrageform oder eines bestimmten Anfragetags in grafischer Form ansehen möchten, klicken Sie auf den Fingerabdruck, der mit der Abfrage oder dem Anfragetag verknüpft ist. Die Seite „Abfragedetails“ wird geöffnet.

Auf der Seite „Abfragedetails“ werden die folgenden Informationen angezeigt:
- Text mit Abfragedetails: SQL-Abfragetext, verkürzt auf ca. 64 KB. Statistiken für mehrere Abfragen, die denselben Tag-String haben, werden in einer einzelnen Zeile gruppiert, wobei REQUEST_TAG mit diesem Tag-String übereinstimmt. In diesem Feld wird nur der Text einer dieser Anfragen angezeigt. Bei Batch-DML wird die Gruppe von SQL-Anweisungen in einer einzelnen Zeile zusammengefasst und mit einem Semikolon getrennt. Aufeinanderfolgende identische SQL-Texte werden vor dem Kürzen dedupliziert.
- Die Werte der folgenden Felder:
- Anzahl der Ausführungen: Die durchschnittliche Rate der Abfrageausführungen in Ausführungen pro Minute, die Spanner während des Intervalls registriert hat.
- Durchschnittliche CPU (ms): Der durchschnittliche CPU-Ressourcenverbrauch in Millisekunden durch eine Abfrage der CPU-Ressourcen der Instanz in einem Zeitintervall.
- Durchschnittliche Latenz (ms): Durchschnittliche Zeit in Millisekunden für jede Abfrageausführung in der Datenbank. Dieser Durchschnitt schließt die Codierungs- und Übertragungszeit für die Ergebnismenge sowie den Aufwand aus.
- Durchschnittlich zurückgegebene Zeilen: Durchschnittliche Anzahl der Zeilen, die die Abfrage zurückgegeben hat.
- Durchschnittlich gescannte Zeilen: Durchschnittliche Anzahl der Zeilen, die von der Abfrage gescannt wurden, ausgenommen gelöschte Werte.
- Durchschnittliche Byte: Anzahl der von der Abfrage zurückgegebenen Datenbyte, ohne den Aufwand der Übertragungskodierung.
- Diagramm „Beispiele für Abfragepläne“: Jeder Punkt im Diagramm steht für einen Beispielabfrageplan zu einem bestimmten Zeitpunkt und die zugehörige Abfragelatenz. Klicken Sie auf einen der Punkte im Diagramm, um den Abfrageplan aufzurufen und die Schritte während der Abfrageausführung zu visualisieren. Hinweis: Abfragepläne werden für Abfragen mit partitionTokens, die über die PartitionQuery API abgerufen wurden, und für partitionierte DML-Abfragen nicht unterstützt.
Abfrageplan-Visualisierung: Hier wird der ausgewählte Abfrageplan für die Stichprobe angezeigt. Spanner bietet die folgenden Layoutoptionen:
- Baumansicht: In der Baumansicht wird der Abfrageplan als Diagramm dargestellt. Jeder Knoten oder jede Karte steht für einen Iterator, der Zeilen aus seinen Eingaben verwendet und Zeilen für das übergeordnete Element erzeugt. Wenn Sie auf die einzelnen Iteratoren klicken, werden weitere Informationen angezeigt.
Sequenzielle Ansicht: In der sequenziellen Ansicht wird der Abfrageplan in einer hierarchischen Tabelle visualisiert, in der jede Zeile einen Operator darstellt. Wenn Sie auf eine Zeile klicken, werden weitere Informationen angezeigt.

Die Tabelle enthält die folgenden Spalten:
- Name: Der Name des Operators.
- Maschinengruppe: Die Maschinengruppe, in der dieser Operator ausgeführt wurde.
- Latenz: Die Zeit, die während der Ausführung des aktuellen Vorgangs verstrichen ist. Dies kann mehr als die CPU-Zeit sein, beispielsweise wenn der Operator auf Remote-Aufrufe gewartet hat oder eine Verzögerung im Dateisystem vorlag.
- Kumulative Latenz: Die Zeit, die während der Ausführung des gesamten Unterbaums verstrichen ist, dessen Stamm dieser Operator ist. Die Zeit für die Planerstellung und anderweitigen Aufwand sind nicht enthalten. Daher kann die kumulative Latenz kürzer als die Gesamtdauer der Abfrage sein.
- CPU-Zeit: Gesamte CPU-Zeit, die für die Ausführung der Abfrage aufgewendet wurde. exkl. Netzwerklatenz. Einige Teile der Abfrageausführung laufen möglicherweise parallel, sodass die CPU-Zeit länger als die gesamte verstrichene Zeit sein kann. Wenn eine Abfrage beispielsweise zehn parallele Vorgänge in 1 Millisekunde (ms) ausführt, beträgt die verstrichene Zeit 1 ms, die CPU-Zeit jedoch 10 ms.
- Zurückgegebene Zeilen: Die Anzahl der Zeilen, die vom Operator zurückgegeben wurden.
Diagramm zur Abfragelatenz: Hier wird der Wert der Abfragelatenz für eine ausgewählte Abfrage über einen bestimmten Zeitraum dargestellt. Außerdem wird die durchschnittliche Latenz angezeigt.
Diagramm zur CPU-Auslastung: Zeigt die CPU-Auslastung einer Anfrage in Prozent über einen Zeitraum hinweg. Außerdem wird die durchschnittliche CPU-Auslastung angezeigt.
Diagramm „Anzahl der Ausführungen/Fehler“: Zeigt die durchschnittliche Rate der Abfrageausführungen (in Ausführungen pro Minute) über einen Zeitraum hinweg und die durchschnittliche Rate der fehlgeschlagenen Abfrageausführungen (in fehlgeschlagenen Ausführungen pro Minute).
Diagramm „Gescannte Zeilen“: Hier sehen Sie die Anzahl der Zeilen, die für die Abfrage über einen bestimmten Zeitraum gescannt wurden.
Diagramm „Zurückgegebene Zeilen“: Hier sehen Sie die Anzahl der Zeilen, die von der Abfrage in einem bestimmten Zeitraum zurückgegeben wurden.
Zeitraumfilter: Filtert Abfragedetails nach Zeiträumen, z. B. Stunde, Tag oder einen benutzerdefinierten Bereich.
Für die Diagramme rufen wir die Daten aus der Tabelle mit den Statistiken für Top-N-Abfragen ab, die drei verschiedene Granularitäten hat: 1 Minute, 10 Minuten und 1 Stunde. Der Wert für jeden Datenpunkt in den Diagrammen steht für den Durchschnittswert über ein Intervall von einer Minute.
Nach allen Ausführungen einer Abfrage im Audit-Log suchen
Wenn Sie in Cloud-Audit-Logs nach allen Ausführungen eines bestimmten Abfrage-Fingerabdrucks suchen möchten, fragen Sie das Audit-Log ab und suchen Sie nach einem query_fingerprint, das dem Feld Fingerprint in der Tabelle „TopN query statistics“ (TopN-Abfragestatistiken) entspricht. Weitere Informationen finden Sie unter Logs abfragen und ansehen. Mit dieser Methode können Sie den Nutzer identifizieren, der die Anfrage initiiert hat.