
בדף הזה מוסבר איך להשתמש בלוח הבקרה 'תובנות לגבי שאילתות' כדי לזהות ולנתח בעיות בביצועים של Spanner.
סקירה כללית של תובנות לגבי שאילתות
התובנות לגבי שאילתות עוזרות לכם לזהות בעיות בביצועים של שאילתות ושל הצהרות DML (INSERT, UPDATE ו-DELETE) במסד נתונים של Spanner ולאבחן אותן. הוא תומך בניטור אינטואיטיבי ומספק מידע אבחוני שעוזר לכם לזהות את שורש הבעיה בביצועים, ולא רק לזהות את הבעיה עצמה.
תובנות לגבי שאילתות עוזרות לכם לשפר את הביצועים של שאילתות Spanner. לשם כך, אתם יכולים לבצע את השלבים הבאים:
- קובעים אם שאילתות לא יעילות גורמות לניצול גבוה של CPU.
- זיהוי שאילתה או תג שעלולים לגרום לבעיות.
- מנתחים את התג של השאילתה או הבקשה כדי לזהות בעיות.
התובנות לגבי שאילתות זמינות בהגדרות של אזור יחיד ושל כמה אזורים.
תמחור
התכונה 'תובנות לגבי שאילתות' לא כרוכה בעלות נוספת.
שמירת נתונים
הנתונים ב'תובנות לגבי שאילתות' נשמרים למשך 30 ימים לכל היותר.
בתרשים Total CPU Utilization (per Query or Request tag), Spanner מאחזר נתונים מהטבלאות SPANNER_SYS.QUERY_STATS_TOP_*. הנתונים בטבלאות האלה נשמרים למשך 30 ימים לכל היותר. מידע נוסף על שמירת נתונים
התפקידים הנדרשים
אתם צריכים תפקידים והרשאות שונים ב-IAM בהתאם לסוג המשתמש שלכם: משתמש IAM או משתמש עם בקרת גישה ברמת גרנולריות גבוהה.
משתמש בניהול זהויות והרשאות גישה (IAM)
כדי לקבל את ההרשאות שדרושות בשביל להציג את הדף Query insights, צריך לבקש מהאדמין להקצות לכם את תפקידי ה-IAM הבאים במופע:
- Cloud Spanner Viewer (
roles/spanner.viewer) - Cloud Spanner Database Reader (
roles/spanner.databaseReader)
כדי לצפות בדף 'תובנות לגבי שאילתות', נדרשות ההרשאות הבאות בתפקיד Cloud Spanner Database Reader(
roles/spanner.databaseReader):
spanner.databases.beginReadOnlyTransactionspanner.databases.selectspanner.sessions.create
משתמש עם בקרת גישה פרטנית
אם אתם משתמשים בבקרת גישה פרטנית, ודאו שאתם:
- יש לכם את Cloud Spanner Viewer(
roles/spanner.viewer) - יש להם הרשאות בקרת גישה פרטניות, והם קיבלו את
spanner_sys_readerתפקיד המערכת או אחד מתפקידי החברים שלו. - בדף הסקירה הכללית של מסד הנתונים, בוחרים באפשרות
spanner_sys_readerאו בתפקיד של חבר/ה בתור התפקיד הנוכחי במערכת.
מידע נוסף זמין במאמרים מידע על בקרת גישה ברמת פירוט גבוהה ותפקידים במערכת של בקרת גישה ברמת פירוט גבוהה.
מרכז הבקרה Query insights
בלוח הבקרה 'תובנות לגבי שאילתות' מוצג עומס השאילתות על סמך מסד הנתונים וטווח הזמן שבחרתם. עומס השאילתות הוא מדד של השימוש הכולל ב-CPU עבור כל השאילתות במופע בטווח הזמן שנבחר. במרכז הבקרה יש סדרה של מסננים שעוזרים לכם לראות את עומס השאילתות.
כדי לראות את מרכז הבקרה 'תובנות לגבי שאילתות' של מסד נתונים:
- בחלונית הניווט הימנית, בוחרים באפשרות תובנות לגבי שאילתות. מרכז הבקרה Query insights ייפתח.
- בוחרים מסד נתונים מהרשימה מסדי נתונים. בלוח הבקרה מוצג מידע על עומס השאילתות במסד הנתונים.
אלה האזורים בלוח הבקרה:
- רשימת מסדי נתונים: סינון עומס השאילתות במסד נתונים ספציפי או בכל מסדי הנתונים.
- מסנן טווח זמן: מסנן את עומס השאילתות לפי טווחי זמן, כמו שעות, ימים או טווח מותאם אישית.
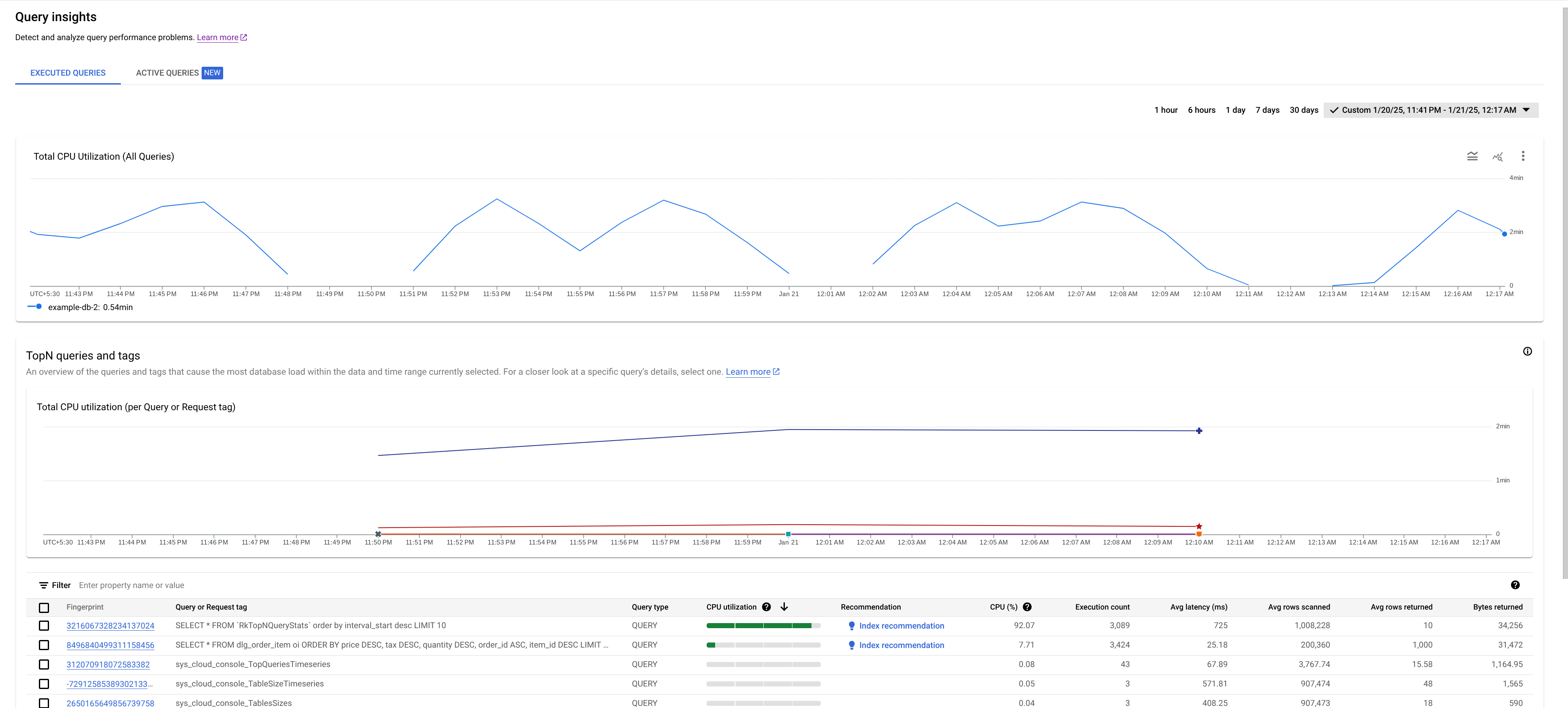
- תרשים של סה"כ ניצול המעבד (כל השאילתות): מוצג בו הממוצע המצטבר של שיעור השימוש במעבד (בשניות מעבד לדקה) של כל השאילתות.
- תרשים של סך ניצול המעבד (לכל תג שאילתה או בקשה): מוצג בו שיעור השימוש הממוצע במעבד (בשניות מעבד לדקה) לפי כל תג שאילתה או בקשה.
- טבלת התגים והשאילתות המובילות (TopN): מוצגת רשימה של השאילתות והתגים של הבקשות המובילות, ממוינים לפי ניצול המעבד. איך מזהים שאילתה או תג שעלולים לגרום לבעיות
ביצועים של לוח הבקרה
כדי לשפר את הביצועים של התובנות לגבי שאילתות, אפשר להשתמש בפרמטרים של שאילתות או לתייג את השאילתות. אם לא תגדירו פרמטרים או תתייגו את השאילתות, יכול להיות שיוחזרו יותר מדי תוצאות, ולכן יכול להיות שהטבלה TopN queries and tags לא תיטען כמו שצריך.
איך בודקים אם שאילתות לא יעילות גורמות לניצול גבוה של המעבד
המדד 'ניצול המעבד הכולל' הוא מדד של השיעור הממוצע של השימוש במעבד (בשניות מעבד לדקה) שהשאילתות שהופעלו במסד הנתונים שנבחר מבצעות לאורך זמן.

כדאי לעיין בתרשים כדי לקבל תשובות לשאלות הבאות:
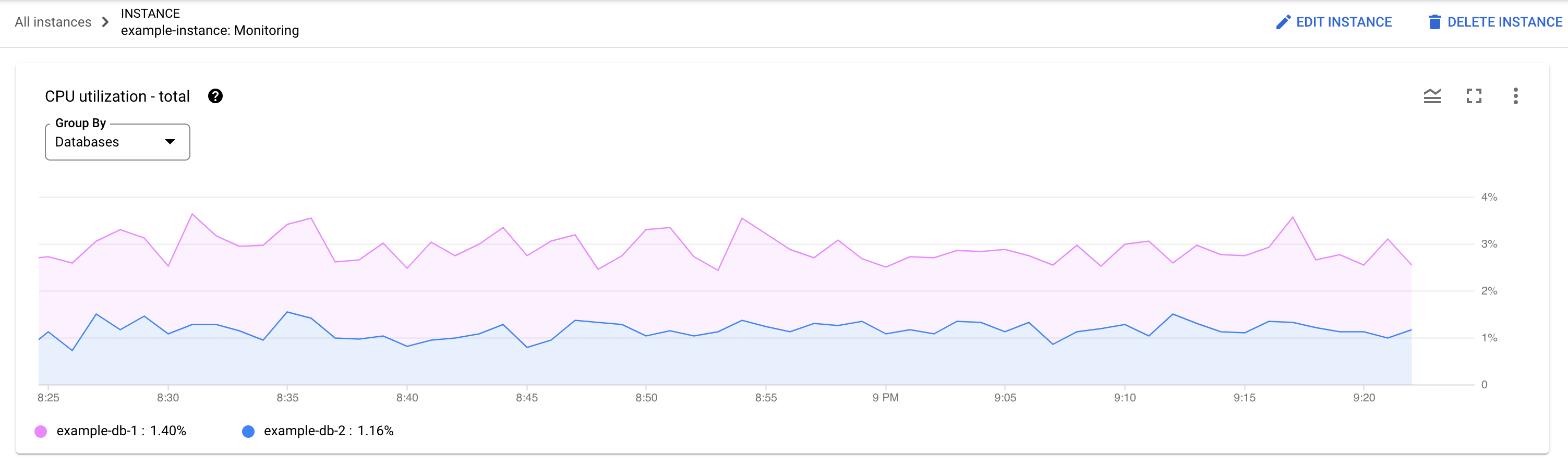
באיזה מסד נתונים העומס גבוה? בוחרים מסדי נתונים שונים מהרשימה Databases כדי למצוא את מסדי הנתונים עם העומסים הכי גבוהים. כדי לגלות באיזה מסד נתונים העומס הכי גבוה, אפשר גם לעיין בתרשים CPU utilization - total של מסדי נתונים במסוףGoogle Cloud .
האם ניצול המעבד (CPU) גבוה? האם יש קפיצות בתרשים או שהערכים גבוהים לאורך זמן? אם לא רואים ניצול גבוה של CPU, הבעיה לא קשורה לשאילתות.
כמה זמן נמשך השימוש הגבוה ב-CPU? האם הייתה עלייה חדה לאחרונה או שהערך היה גבוה באופן עקבי במשך זמן מה? אפשר להשתמש בבורר הטווח כדי לבחור תקופות זמן שונות ולבדוק כמה זמן הבעיה נמשכה. מגדילים את התצוגה כדי לראות חלון זמן שבו נצפו עליות חדות בעומס השאילתות. מגדילים את התצוגה כדי לראות עד שבוע אחד בציר הזמן.
אם רואים עלייה חדה או עלייה הדרגתית בגרף שמתאימה לשימוש הכולל במעבד של המופע, סביר להניח שהסיבה לכך היא שאילתה יקרה אחת או יותר. לאחר מכן, תוכלו להתעמק בתהליך איתור הבאגים על ידי זיהוי תג שאילתה או בקשה שעלול להיות בעייתי.
זיהוי תג של שאילתה או בקשה שעלולות להיות בעייתיות
כדי לזהות תג שאילתה או תג בקשה שעלולים לגרום לבעיות, בודקים את הקטע TopN queries:
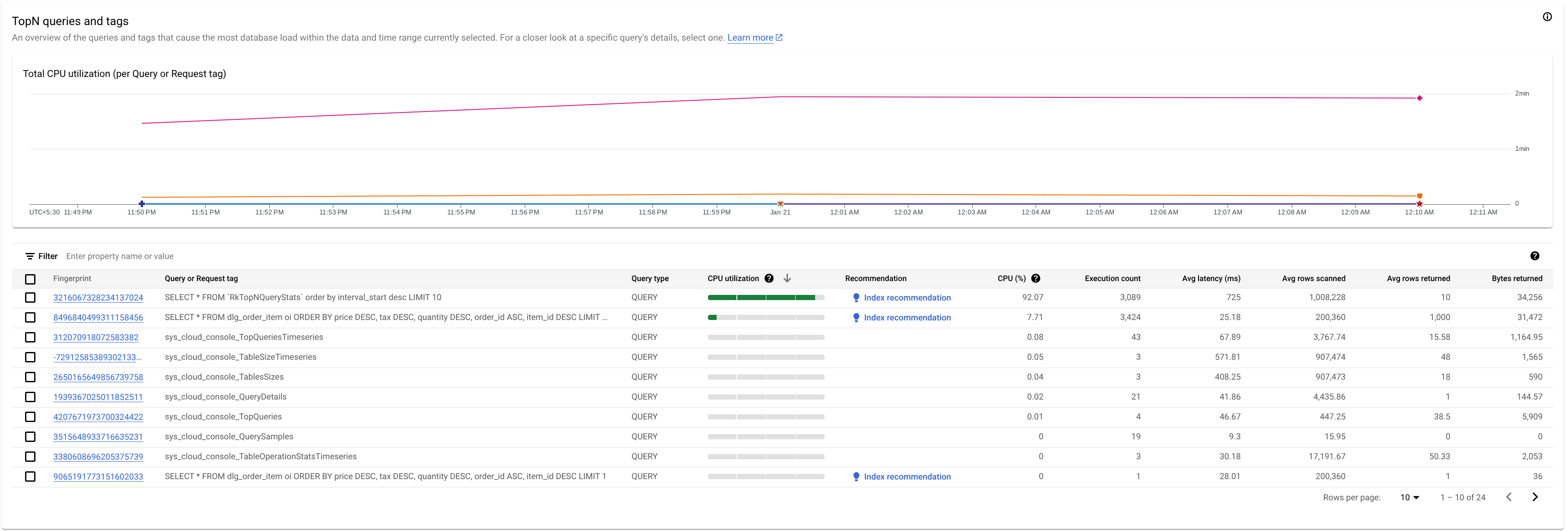
כאן אפשר לראות שהשאילתה עם טביעת האצבע 3216067328234137024 כוללת ניצול גבוה של המעבד (CPU) ויכולה להיות בעייתית.
בטבלה TopN queries מוצגת סקירה כללית של השאילתות שמשתמשות בכמות הכי גדולה של CPU במהלך חלון הזמן שנבחר, ממוינות מהגבוה לנמוך. מספר השאילתות מסוג TopN מוגבל ל-100.
כדי ליצור את הגרפים, אנחנו מאחזרים את הנתונים מטבלת הנתונים הסטטיסטיים של שאילתות TopN, שכוללת שלוש רמות פירוט שונות: דקה אחת, 10 דקות ושעה אחת. הערך של כל נקודת נתונים בתרשימים מייצג את הערך הממוצע לאורך מרווח של דקה אחת.
מומלץ להוסיף תגים לשאילתות SQL. תיוג שאילתות עוזר לכם למצוא בעיות במבנים ברמה גבוהה יותר, כמו לוגיקה עסקית או מיקרו-שירות.

הטבלה מציגה את המאפיינים הבאים:
- טביעת אצבע: גיבוב של תג הבקשה, או אם התג לא קיים, גיבוב של טקסט השאילתה.
תג שאילתה או בקשה: אם לשאילתה משויך תג, התג שיוצג הוא תג הבקשה. הנתונים הסטטיסטיים של כמה שאילתות עם אותה מחרוזת תגים מקובצים בשורה אחת, והערך
REQUEST_TAGתואם למחרוזת התגים. מידע נוסף על שימוש בתגי בקשהאם לשאילתה אין תג משויך, מוצגת שאילתת ה-SQL, שקוצרה לכ-64KB. ב-DML של קבוצות, משטחים את הצהרות ה-SQL לשורה אחת ומשרשרים אותן באמצעות נקודה ופסיק כמפריד. המערכת מסירה כפילויות מטקסטים זהים של SQL ברצף לפני שהיא חותכת אותם.
סוג שאילתה: מציין אם השאילתה היא
PARTITIONED_QUERYאוQUERY.PARTITIONED_QUERYהיא שאילתה עםpartitionTokenשהתקבלה מ-PartitionQuery API. כל השאילתות האחרות והצהרות DML מסומנות בסוג השאילתהQUERY.CPU Utilization: צריכת משאבי המעבד על ידי שאילתה, כאחוז מסך משאבי המעבד שמשמשים את כל השאילתות שפועלות במסדי הנתונים במרווח הזמן הזה. מוצג כפס אופקי בטווח של 0 עד 100.
המלצה: מערכת Spanner מנתחת את השאילתות כדי לקבוע אם אפשר לשפר את האינדקסים. אם כן, המערכת ממליצה על אינדקסים חדשים או ששונו שיכולים לשפר את ביצועי השאילתות. מידע נוסף זמין במאמר בנושא שימוש בכלי לייעוץ לגבי אינדקסים ב-Spanner.
CPU (%): צריכת משאבי המעבד על ידי שאילתה, כאחוז מתוך כל משאבי המעבד שמשמשים את כל השאילתות שמופעלות במסדי הנתונים במרווח הזמן הזה.
מספר ההרצות: השיעור הממוצע של הרצות השאילתות, בהרצות לדקה, שנמדד ב-Spanner במהלך המרווח.
זמן האחזור הממוצע (ms): משך הזמן הממוצע, במיקרו-שניות, של כל שאילתה שמופעלת במסד הנתונים. החישוב הממוצע הזה לא כולל את זמן הקידוד והשידור של קבוצת התוצאות, וגם לא את התקורה.
Avg rows scanned: המספר הממוצע של השורות שנסרקו על ידי השאילתה, לא כולל ערכים שנמחקו.
מספר ממוצע של שורות שהוחזרו: המספר הממוצע של השורות שהוחזרו על ידי השאילתה.
בייטים שהוחזרו: מספר בייטים של נתונים שהשאילתה החזירה, לא כולל תקורה של קידוד העברה.
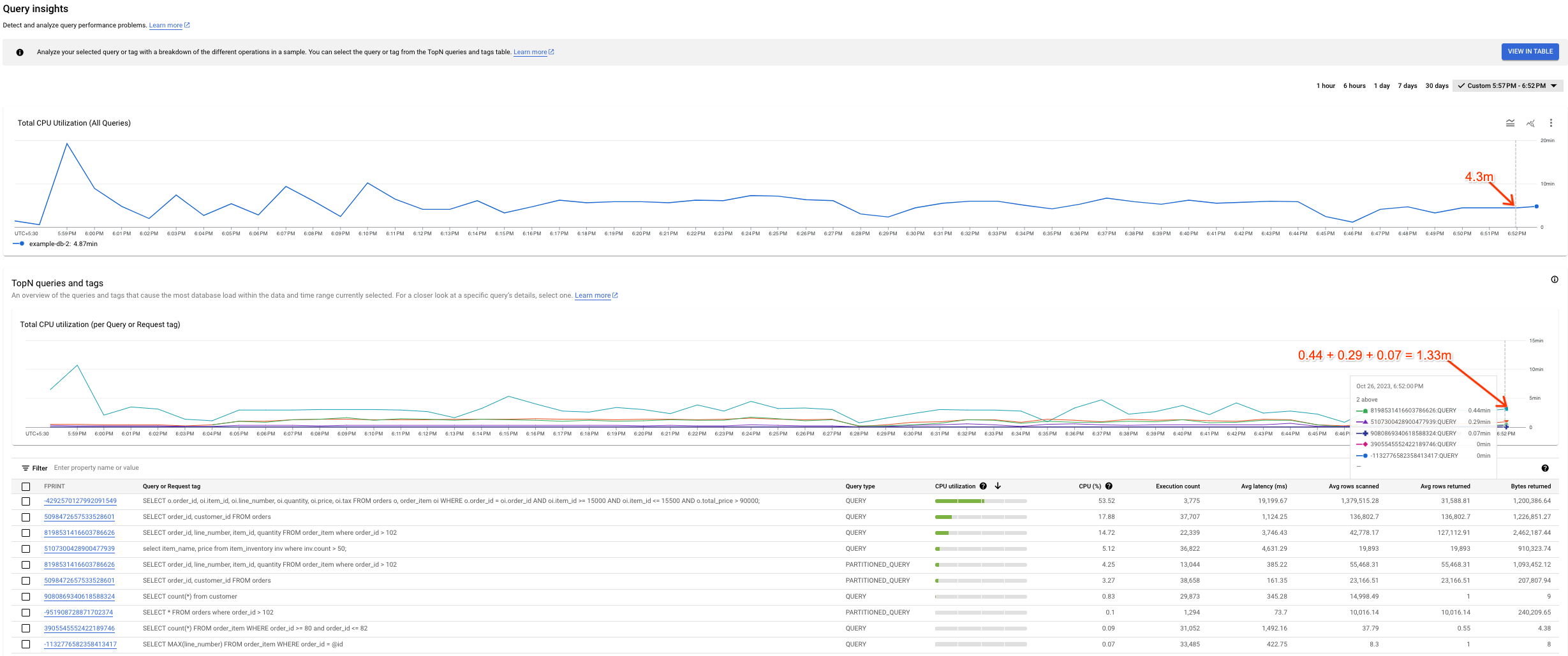
שונות אפשרית בין הגרפים
יכול להיות שתבחינו בהבדלים בין התרשים Total CPU Utilization (all queries) לבין התרשים Total CPU Utilization (per Query or Request tag). יש שתי סיבות אפשריות לכך:
מקורות נתונים שונים: הנתונים של Cloud Monitoring, שמוזנים לתרשים של ניצול המעבד הכולל (כל השאילתות), בדרך כלל מדויקים יותר כי הם נדחפים כל דקה ומשך השמירה שלהם הוא 45 ימים. לעומת זאת, יכול להיות שהנתונים בטבלת המערכת, שמשמשים ליצירת התרשים Total CPU Utilization (per Query or Request tag), מחושבים כממוצע על פני 10 דקות (או שעה). במקרה כזה, יכול להיות שנאבד נתונים ברמת פירוט גבוהה שמוצגים בתרשים Total CPU Utilization (all queries).
חלונות צבירה שונים: בשני הגרפים יש חלונות צבירה שונים. לדוגמה, כשבודקים אירוע מלפני יותר מ-6 שעות, מבצעים שאילתה בטבלה
SPANNER_SYS.QUERY_STATS_TOTAL_10MINUTE. במקרה כזה, אירוע שמתרחש בשעה 10:01 יצטבר במשך 10 דקות ויופיע בטבלת המערכת שמתאימה לחותמת הזמן 10:10.
בצילום המסך הבא אפשר לראות דוגמה לשונות כזו.
ניתוח של תג ספציפי של שאילתה או בקשה
כדי לקבוע אם תג שאילתה או תג בקשה הוא שורש הבעיה, לוחצים על תג השאילתה או תג הבקשה שנראה שיש לו את העומס הכי גבוה או שהוא לוקח יותר זמן מהאחרים. אפשר לבחור כמה שאילתות ותגי בקשה בו-זמנית.
אפשר להשאיר את סמן העכבר על הגרף של השאילתות בציר הזמן כדי לראות את ניצול המעבד שלהן (בשניות).
כדי לצמצם את הבעיה, כדאי לבדוק את הדברים הבאים:
- כמה זמן העומס גבוה? האם המחיר גבוה רק עכשיו? או שהיא גבוהה כבר הרבה זמן? משנים את טווחי הזמן כדי למצוא את התאריך והשעה שבהם הביצועים של השאילתה התחילו להיות גרועים.
- היו עליות פתאומיות בניצול המעבד? אפשר לשנות את חלון הזמן כדי לבדוק את היסטוריית השימוש במעבד בשאילתה.
- מהי צריכת המשאבים? איך זה קשור לשאילתות אחרות? מעיינים בטבלה ומשווים את הנתונים של שאילתות אחרות לשאילתה שנבחרה. האם יש הבדל משמעותי?
כדי לוודא שהשאילתה שנבחרה תורמת לניצול הגבוה של ה-CPU, אפשר להתעמק בפרטים של צורת השאילתה הספציפית (או תג הבקשה) ולנתח אותה עוד בדף פרטי השאילתה.
הצגת הדף 'פרטי השאילתה'
כדי לראות את הפרטים של צורת שאילתה או תג בקשה ספציפיים בפורמט גרפי, לוחצים על טביעת האצבע שמשויכת לשאילתה או לתג הבקשה. ייפתח הדף 'פרטי השאילתה'.
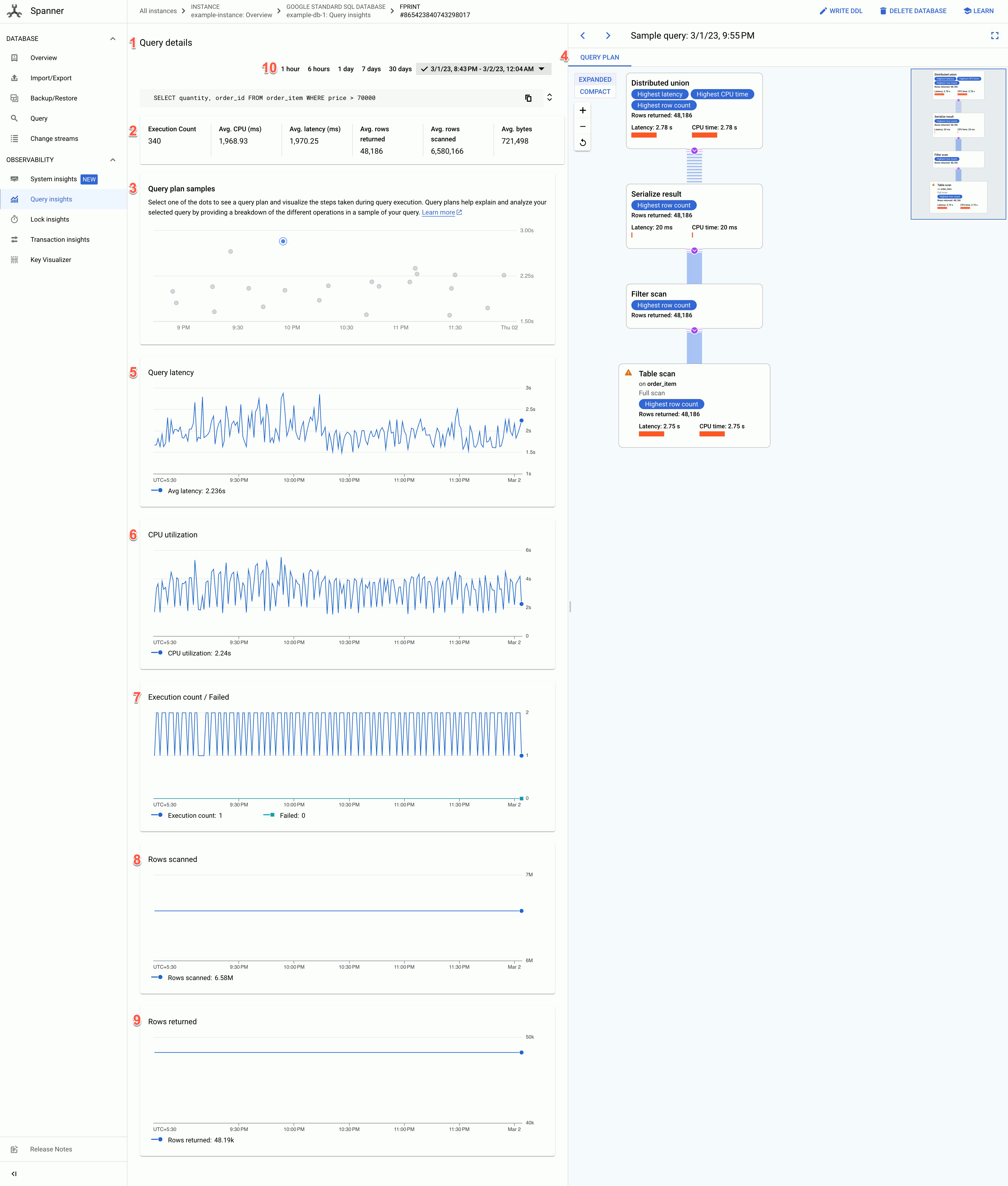
בדף פרטי השאילתה מוצג המידע הבא:
- הטקסט של פרטי השאילתה: טקסט של שאילתת SQL, שנחתך בערך ב-64KB. הנתונים הסטטיסטיים של כמה שאילתות עם אותו מחרוזת תגים מקובצים בשורה אחת עם התג REQUEST_TAG שתואם למחרוזת התגים הזו. בשדה הזה מוצג רק הטקסט של אחת מהשאילתות האלה. ב-DML של קבוצות, קבוצת משפטי ה-SQL משוטחת לשורה אחת, ומחוברת באמצעות נקודה-פסיק כמפריד. מערכת ה-SQL מבצעת דה-דופליקציה של טקסטים זהים רצופים לפני החיתוך.
- הערכים של השדות הבאים:
- מספר ההרצות: שיעור ההרצות הממוצע של השאילתות, בהרצות לדקה, שנמדד ב-Spanner במהלך המרווח.
- Avg. CPU (ms): ממוצע צריכת משאבי המעבד (CPU) באלפיות השנייה, לפי שאילתה של משאבי המעבד של המופע במרווח זמן.
- Avg. Latency (ms): משך הזמן הממוצע, באלפיות השנייה, של כל שאילתה שמופעלת במסד הנתונים. החישוב הממוצע הזה לא כולל את הזמן של קידוד, שידור ותקורה של קבוצת התוצאות.
- מספר ממוצע של שורות שהוחזרו: המספר הממוצע של השורות שהוחזרו על ידי השאילתה.
- Avg. rows scanned: המספר הממוצע של השורות שהשאילתה סרקה, לא כולל ערכים שנמחקו.
- Avg. bytes: מספר בייטים של נתונים שהשאילתה החזירה, לא כולל תקורה של קידוד שידור.
- גרף של דוגמאות לתוכניות שאילתות: כל נקודה בגרף מייצגת תוכנית שאילתה שנדגמה בזמן מסוים, ואת זמן האחזור הספציפי של השאילתה. לוחצים על אחת הנקודות בתרשים כדי לראות את תוכנית השאילתות ואת השלבים שבוצעו במהלך הפעלת השאילתה. הערה: תוכניות שאילתה לא נתמכות בשאילתות עם partitionTokens שהתקבלו מ-PartitionQuery API ובשאילתות Partitioned DML.
כלי להמחשת תוכנית שאילתה: הצגת תוכנית השאילתה שנבחרה לדוגמה. ב-Spanner יש את אפשרויות הפריסה הבאות:
- תצוגת עץ: בתצוגת העץ, תוכנית השאילתה מוצגת כתרשים שבו כל צומת או כרטיס מייצג איטרטור שצורכת שורות מהקלט שלה ומפיקה שורות עבור ההורה שלה. אפשר ללחוץ על כל איטרטור כדי להרחיב את המידע.
תצוגה עוקבת: בתצוגה העוקבת מוצג תרשים של תוכנית השאילתה בטבלה היררכית, שבה כל שורה מייצגת אופרטור. אפשר ללחוץ על כל שורה כדי להרחיב את המידע.
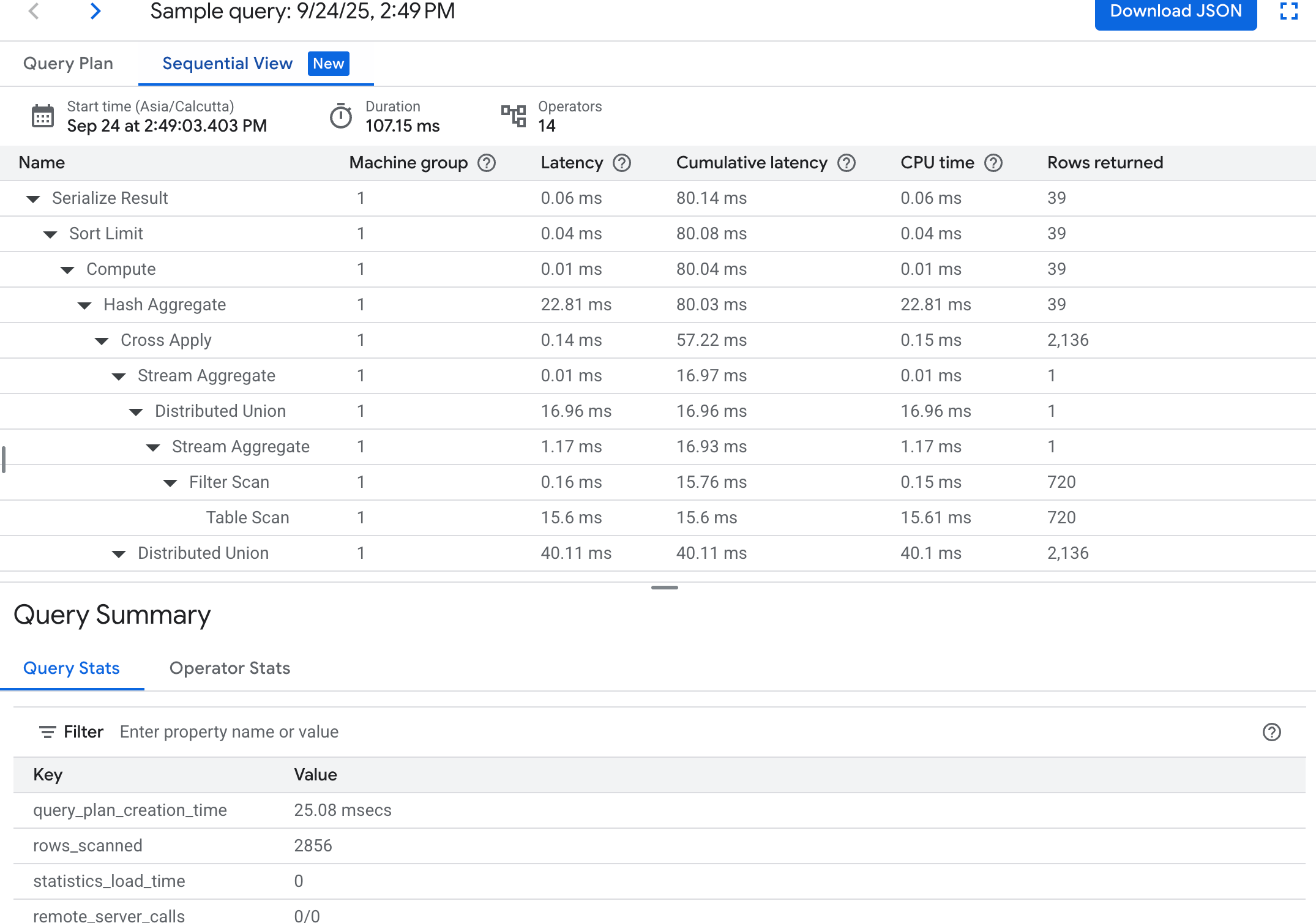
הטבלה כוללת את העמודות הבאות:
- שם: השם של האופרטור.
- קבוצת מכונות: קבוצת המכונות שבה הופעל האופרטור.
- זמן האחזור: משך הזמן שחלף במהלך הביצוע של הפעולה הנוכחית. יכול להיות שהערך הזה יהיה גדול יותר מזמן ה-CPU (לדוגמה, אם האופרטור המתין לשיחות מרוחקות או להשהיה במערכת הקבצים).
- חביון מצטבר: משך הזמן שחלף במהלך הביצוע של עץ המשנה כולו שמתחיל בפעולה הזו. הזמן הזה לא כולל את הזמן שנדרש ליצירת התוכנית והוצאות תקורה אחרות, ולכן יכול להיות שהחביון המצטבר יהיה קצר יותר ממשך הזמן הכולל של השאילתה.
- זמן מעבד: סכום הזמן הכולל שהמעבד השקיע בהרצת השאילתה. לא כולל זמן אחזור ברשת. חלקים מסוימים בהרצת השאילתה עשויים להתבצע במקביל, ולכן יכול להיות שזמן השימוש במעבד יהיה ארוך יותר מהזמן הכולל שחלף. לדוגמה, אם שאילתה מבצעת עשר פעולות מקבילות במילי-שנייה אחת (ms), הזמן שחלף הוא מילי-שנייה אחת, אבל זמן השימוש במעבד הוא 10 מילי-שניות.
- השורות שהוחזרו: מספר השורות שהוחזרו על ידי האופרטור.
תרשים של זמן האחזור של השאילתה: מציג את הערך של זמן האחזור של שאילתה שנבחרה לאורך תקופה. מוצג גם זמן האחזור הממוצע.
תרשים של ניצול המעבד: מציג את ניצול המעבד לפי שאילתה, באחוזים, לאורך תקופת זמן. מוצג גם ממוצע השימוש במעבד.
תרשים של מספר ההפעלות/הכישלונות: בתרשים מוצג השיעור הממוצע של הפעלות שאילתות (בהפעלות לדקה) לאורך תקופה, והשיעור הממוצע של הפעלות שאילתות שנכשלו (בהפעלות שנכשלו לדקה).
תרשים של שורות שנסרקו: מספר השורות שהשאילתה סרקה לאורך תקופת זמן.
תרשים השורות שהוחזרו: מציג את מספר השורות שהשאילתה החזירה לאורך תקופת זמן.
מסנן טווח זמן: מסנן את פרטי השאילתה לפי טווחי זמן, כמו שעה, יום או טווח מותאם אישית.
כדי ליצור את הגרפים, אנחנו מאחזרים את הנתונים מטבלת הנתונים הסטטיסטיים של שאילתות TopN, שכוללת שלוש רמות פירוט שונות: דקה אחת, 10 דקות ושעה אחת. הערך של כל נקודת נתונים בתרשימים מייצג את הערך הממוצע לאורך מרווח של דקה אחת.
חיפוש כל ההרצות של שאילתה ביומן הביקורת
כדי לחפש את כל ההפעלות של טביעת אצבע מסוימת של שאילתה ביומני הביקורת של Cloud, שולחים שאילתה ליומן הביקורת ומחפשים את כל הערכים של query_fingerprint שתואמים לשדה Fingerprint בטבלת נתוני השאילתות של TopN. מידע נוסף מופיע במאמר סקירה כללית על שאילתות וצפייה ביומנים. משתמשים בשיטה הזו כדי לזהות את המשתמש שהפעיל את השאילתה.