
La subconsulta de arreglos es similar a una subconsulta escalar, excepto que se le permite a la subconsulta poder consumir más de una fila de entrada. Spanner convierte las filas consumidas en un único array de salida escalar que contiene un elemento por cada fila de entrada consumida.
Esquema de la base de datos
Las consultas y los planes de ejecución en esta página se basan en el siguiente esquema de base de datos:
CREATE TABLE Singers (
SingerId INT64 NOT NULL,
FirstName STRING(1024),
LastName STRING(1024),
SingerInfo BYTES(MAX),
BirthDate DATE
) PRIMARY KEY(SingerId);
CREATE INDEX SingersByFirstLastName ON Singers(FirstName, LastName);
CREATE TABLE Albums (
SingerId INT64 NOT NULL,
AlbumId INT64 NOT NULL,
AlbumTitle STRING(MAX),
MarketingBudget INT64
) PRIMARY KEY(SingerId, AlbumId),
INTERLEAVE IN PARENT Singers ON DELETE CASCADE;
CREATE INDEX AlbumsByAlbumTitle ON Albums(AlbumTitle);
CREATE INDEX AlbumsByAlbumTitle2 ON Albums(AlbumTitle) STORING (MarketingBudget);
CREATE TABLE Songs (
SingerId INT64 NOT NULL,
AlbumId INT64 NOT NULL,
TrackId INT64 NOT NULL,
SongName STRING(MAX),
Duration INT64,
SongGenre STRING(25)
) PRIMARY KEY(SingerId, AlbumId, TrackId),
INTERLEAVE IN PARENT Albums ON DELETE CASCADE;
CREATE INDEX SongsBySingerAlbumSongNameDesc ON Songs(SingerId, AlbumId, SongName DESC), INTERLEAVE IN Albums;
CREATE INDEX SongsBySongName ON Songs(SongName);
CREATE TABLE Concerts (
VenueId INT64 NOT NULL,
SingerId INT64 NOT NULL,
ConcertDate DATE NOT NULL,
BeginTime TIMESTAMP,
EndTime TIMESTAMP,
TicketPrices ARRAY<INT64>
) PRIMARY KEY(VenueId, SingerId, ConcertDate);
Puedes usar las siguientes declaraciones del lenguaje de manipulación de datos (DML) para agregar datos a estas tablas:
INSERT INTO Singers (SingerId, FirstName, LastName, BirthDate)
VALUES (1, "Marc", "Richards", "1970-09-03"),
(2, "Catalina", "Smith", "1990-08-17"),
(3, "Alice", "Trentor", "1991-10-02"),
(4, "Lea", "Martin", "1991-11-09"),
(5, "David", "Lomond", "1977-01-29");
INSERT INTO Albums (SingerId, AlbumId, AlbumTitle)
VALUES (1, 1, "Total Junk"),
(1, 2, "Go, Go, Go"),
(2, 1, "Green"),
(2, 2, "Forever Hold Your Peace"),
(2, 3, "Terrified"),
(3, 1, "Nothing To Do With Me"),
(4, 1, "Play");
INSERT INTO Songs (SingerId, AlbumId, TrackId, SongName, Duration, SongGenre)
VALUES (2, 1, 1, "Let's Get Back Together", 182, "COUNTRY"),
(2, 1, 2, "Starting Again", 156, "ROCK"),
(2, 1, 3, "I Knew You Were Magic", 294, "BLUES"),
(2, 1, 4, "42", 185, "CLASSICAL"),
(2, 1, 5, "Blue", 238, "BLUES"),
(2, 1, 6, "Nothing Is The Same", 303, "BLUES"),
(2, 1, 7, "The Second Time", 255, "ROCK"),
(2, 3, 1, "Fight Story", 194, "ROCK"),
(3, 1, 1, "Not About The Guitar", 278, "BLUES");
En la siguiente consulta, se muestra el operador de subconsulta de array:
SELECT a.albumid,
array
(
select concertdate
FROM concerts
WHERE concerts.singerid = a.singerid)
FROM albums AS a;
La subconsulta es la siguiente:
SELECT concertdate
FROM concerts
WHERE concerts.singerid = a.singerid;
Spanner convierte los resultados de la subconsulta para cada AlbumId en un array de filas de ConcertDate en comparación con las de AlbumId. El plan de ejecución muestra una subconsulta de arreglo, etiquetada como Subconsulta de arreglo, sobre un operador de unión distribuida:
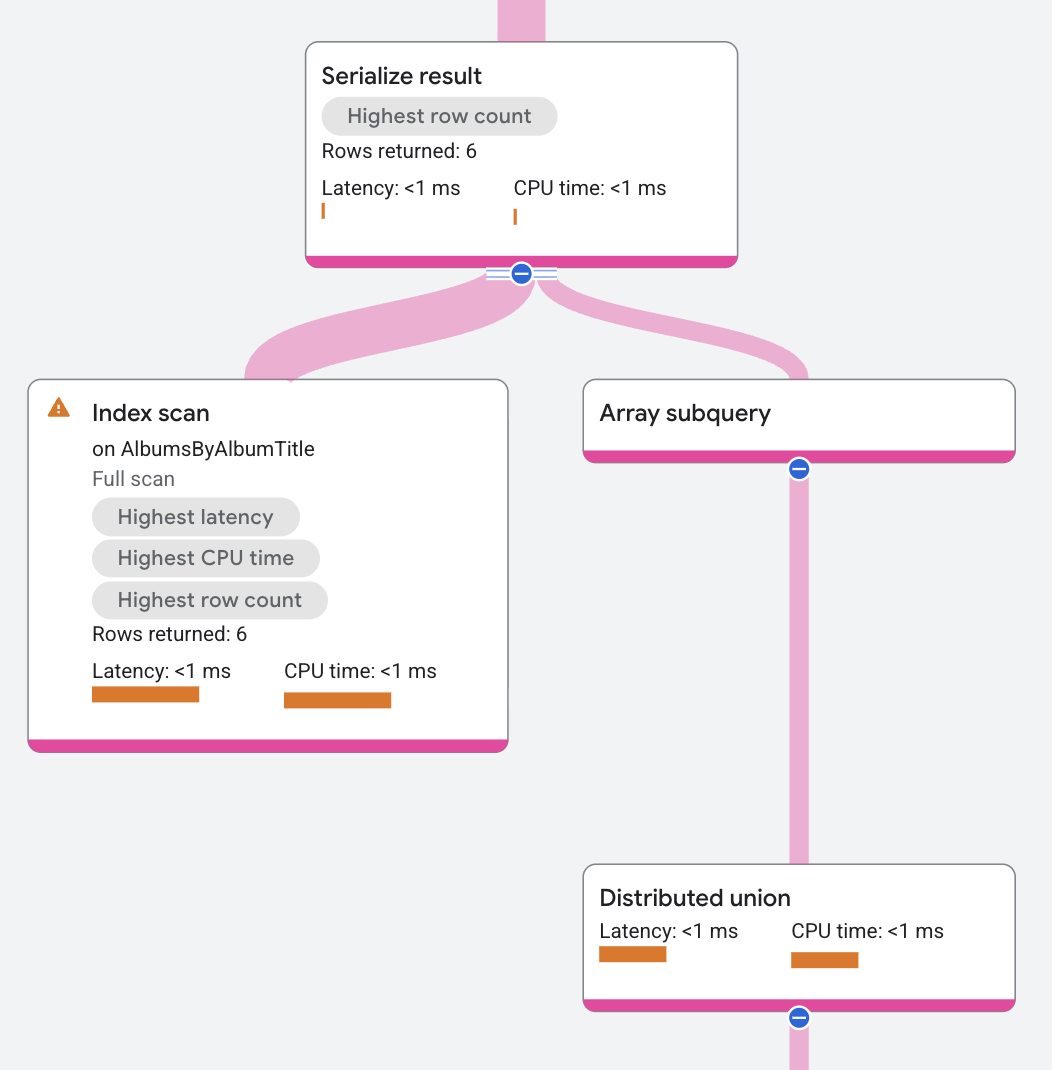
Propiedades y estadísticas de ejecución
Una propiedad de un operador describe un rasgo que se usa cuando se ejecuta el operador. Una estadística de ejecución es un valor recopilado durante la ejecución de la consulta para ayudarte a evaluar el rendimiento del operador.
Propiedades
| Nombre | Descripción |
|---|---|
| Método de ejecución | En la ejecución de filas, el operador procesa una fila a la vez. En la ejecución por lotes, el operador procesa un lote de filas a la vez. |
Estadísticas de ejecución
| Nombre | Descripción |
|---|---|
| Latencia | Tiempo transcurrido de todas las ejecuciones realizadas en el operador. |
| Latencia acumulativa | Es el tiempo total del operador actual y sus elementos subordinados. |
| Tiempo de CPU | Es la suma del tiempo de CPU dedicado a ejecutar el operador. |
| Tiempo de CPU acumulativo | Es el tiempo total de CPU dedicado a ejecutar el operador y sus elementos secundarios. |
| Tiempo de ejecución | Es la cantidad total de tiempo que se tardó en ejecutar la consulta y procesar los resultados. |
| Filas mostradas | Cantidad de filas que genera este operador |
| Cantidad de ejecuciones | Es la cantidad de veces que se ejecutó el operador. Algunas ejecuciones se pueden realizar en paralelo. |