
Ringkasan
Halaman ini memberikan konsep tentang rencana eksekusi kueri dan cara Spanner menggunakannya untuk menjalankan kueri di lingkungan terdistribusi. Untuk mempelajari cara mengambil rencana eksekusi untuk kueri tertentu menggunakan Google Cloud konsol, lihat Memahami cara Spanner menjalankan kueri. Anda juga dapat melihat contoh rencana kueri historis dan membandingkan performa kueri dari waktu ke waktu untuk kueri tertentu. Untuk mempelajari lebih lanjut, lihat Contoh rencana kueri.
Spanner menggunakan pernyataan SQL deklaratif untuk membuat kueri database-nya. Pernyataan SQL menentukan apa yang diinginkan pengguna tanpa menentukan cara mendapatkan hasilnya. Rencana eksekusi kueri adalah kumpulan langkah untuk mendapatkan hasil. Untuk pernyataan SQL tertentu, mungkin ada beberapa cara untuk mendapatkan hasilnya. Pengoptimal kueri Spanner mengevaluasi berbagai rencana eksekusi dan memilih rencana yang dianggap paling efisien. Spanner kemudian menggunakan rencana eksekusi untuk mengambil hasilnya. Rencana eksekusi mendukung database dialek GoogleSQL dan database dialek PostgreSQL.
Secara konseptual, rencana eksekusi adalah hierarki operator relasional. Setiap operator membaca baris dari inputnya dan menghasilkan baris output. Hasil operator di root eksekusi ditampilkan sebagai hasil kueri SQL.
Sebagai contoh, kueri ini:
SELECT s.SongName FROM Songs AS s;
menghasilkan rencana eksekusi kueri yang dapat divisualisasikan sebagai:
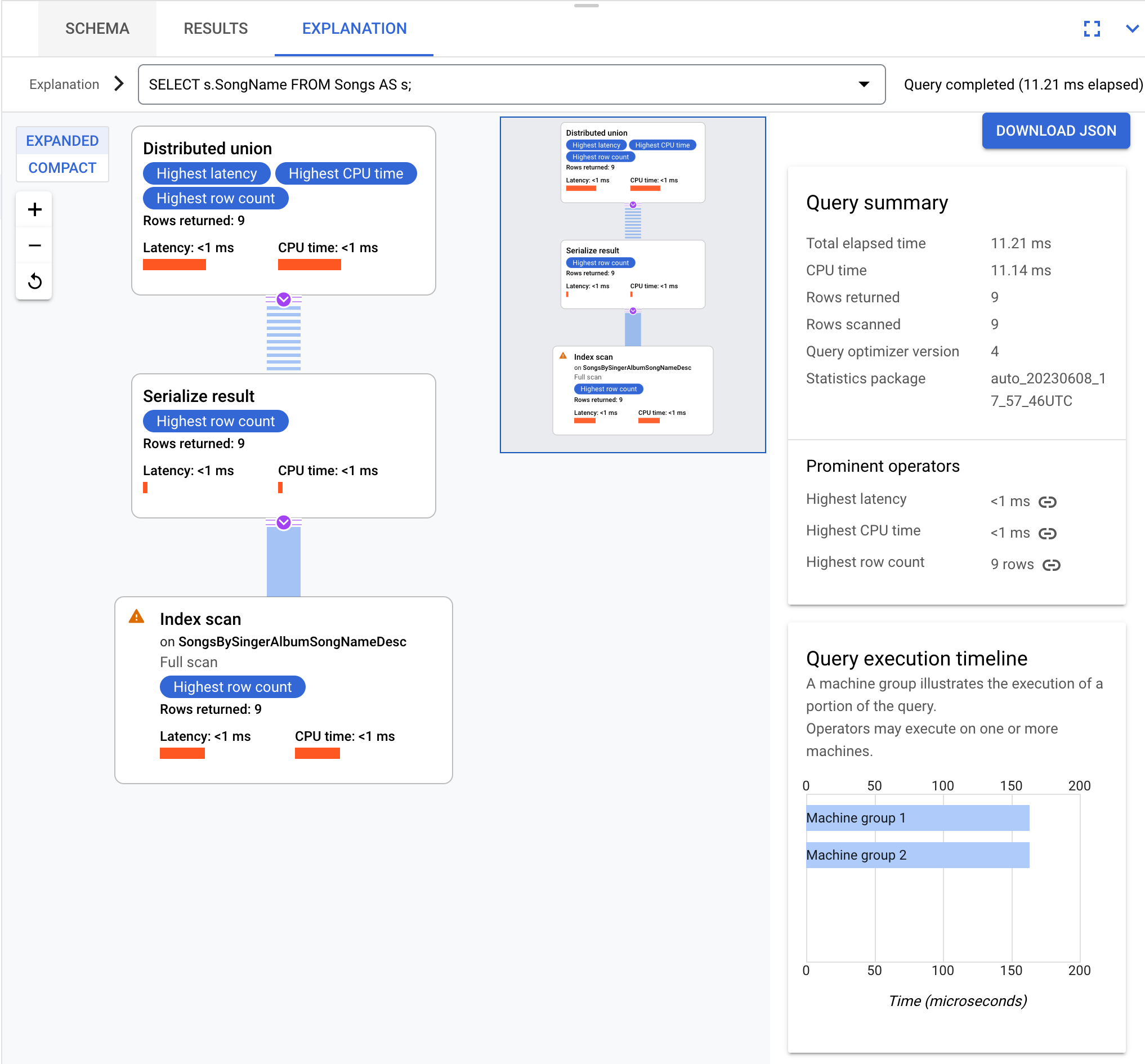
Kueri dan rencana eksekusi di halaman ini didasarkan pada skema database berikut:
CREATE TABLE Singers (
SingerId INT64 NOT NULL,
FirstName STRING(1024),
LastName STRING(1024),
SingerInfo BYTES(MAX),
BirthDate DATE
) PRIMARY KEY(SingerId);
CREATE INDEX SingersByFirstLastName ON Singers(FirstName, LastName);
CREATE TABLE Albums (
SingerId INT64 NOT NULL,
AlbumId INT64 NOT NULL,
AlbumTitle STRING(MAX),
MarketingBudget INT64
) PRIMARY KEY(SingerId, AlbumId),
INTERLEAVE IN PARENT Singers ON DELETE CASCADE;
CREATE INDEX AlbumsByAlbumTitle ON Albums(AlbumTitle);
CREATE INDEX AlbumsByAlbumTitle2 ON Albums(AlbumTitle) STORING (MarketingBudget);
CREATE TABLE Songs (
SingerId INT64 NOT NULL,
AlbumId INT64 NOT NULL,
TrackId INT64 NOT NULL,
SongName STRING(MAX),
Duration INT64,
SongGenre STRING(25)
) PRIMARY KEY(SingerId, AlbumId, TrackId),
INTERLEAVE IN PARENT Albums ON DELETE CASCADE;
CREATE INDEX SongsBySingerAlbumSongNameDesc ON Songs(SingerId, AlbumId, SongName DESC), INTERLEAVE IN Albums;
CREATE INDEX SongsBySongName ON Songs(SongName);
CREATE TABLE Concerts (
VenueId INT64 NOT NULL,
SingerId INT64 NOT NULL,
ConcertDate DATE NOT NULL,
BeginTime TIMESTAMP,
EndTime TIMESTAMP,
TicketPrices ARRAY<INT64>
) PRIMARY KEY(VenueId, SingerId, ConcertDate);
Anda dapat menggunakan pernyataan Bahasa Manipulasi Data (DML) berikut untuk menambahkan data ke tabel ini:
INSERT INTO Singers (SingerId, FirstName, LastName, BirthDate)
VALUES (1, "Marc", "Richards", "1970-09-03"),
(2, "Catalina", "Smith", "1990-08-17"),
(3, "Alice", "Trentor", "1991-10-02"),
(4, "Lea", "Martin", "1991-11-09"),
(5, "David", "Lomond", "1977-01-29");
INSERT INTO Albums (SingerId, AlbumId, AlbumTitle)
VALUES (1, 1, "Total Junk"),
(1, 2, "Go, Go, Go"),
(2, 1, "Green"),
(2, 2, "Forever Hold Your Peace"),
(2, 3, "Terrified"),
(3, 1, "Nothing To Do With Me"),
(4, 1, "Play");
INSERT INTO Songs (SingerId, AlbumId, TrackId, SongName, Duration, SongGenre)
VALUES (2, 1, 1, "Let's Get Back Together", 182, "COUNTRY"),
(2, 1, 2, "Starting Again", 156, "ROCK"),
(2, 1, 3, "I Knew You Were Magic", 294, "BLUES"),
(2, 1, 4, "42", 185, "CLASSICAL"),
(2, 1, 5, "Blue", 238, "BLUES"),
(2, 1, 6, "Nothing Is The Same", 303, "BLUES"),
(2, 1, 7, "The Second Time", 255, "ROCK"),
(2, 3, 1, "Fight Story", 194, "ROCK"),
(3, 1, 1, "Not About The Guitar", 278, "BLUES");
Mendapatkan rencana eksekusi yang efisien adalah hal yang sulit karena Spanner membagi data menjadi pemisahan. Pemisahan dapat bergerak secara independen satu sama lain dan ditetapkan ke server yang berbeda, yang mungkin berada di lokasi fisik yang berbeda. Untuk mengevaluasi rencana eksekusi atas data terdistribusi, Spanner menggunakan eksekusi berdasarkan:
- eksekusi lokal sub-paket di server yang berisi data
- orkestrasi dan agregasi beberapa eksekusi jarak jauh dengan pemangkasan distribusi agresif
Spanner menggunakan operator primitif distributed union,
beserta variannya distributed cross apply dan
distributed outer apply, untuk mengaktifkan model ini.
Metrik performa utama
Visualisator rencana kueri Spanner Studio menampilkan metrik ringkasan untuk eksekusi kueri. Metrik ringkasan mewakili agregat metrik dari semua operator individual yang dieksekusi selama kueri. Tabel berikut menjelaskan metrik performa utama:
| Metrik | Deskripsi |
|---|---|
| Total waktu berlalu | Total waktu aktual yang diperlukan untuk menjalankan kueri. |
| Waktu CPU | Total waktu CPU yang dihabiskan di semua server yang terlibat dalam menjalankan kueri. Karena beberapa bagian eksekusi kueri dapat diproses secara paralel, waktu CPU dapat lebih besar daripada total waktu yang berlalu. |
Contoh rencana kueri
Contoh rencana kueri Spanner memungkinkan Anda melihat contoh rencana kueri historis dan membandingkan performa kueri dari waktu ke waktu. Tidak semua kueri memiliki contoh rencana kueri yang tersedia. Hanya kueri yang menggunakan CPU lebih tinggi yang mungkin diambil sampelnya. Periode retensi data untuk contoh rencana kueri Spanner adalah 30 hari. Anda dapat menemukan contoh rencana kueri di halaman Query insights di konsol Google Cloud . Untuk mengetahui petunjuknya, lihat Melihat contoh rencana kueri.
Anatomi contoh rencana kueri sama dengan rencana eksekusi kueri reguler. Untuk mengetahui informasi selengkapnya tentang cara memahami rencana visual dan menggunakannya untuk men-debug kueri, lihat Panduan visualisator rencana kueri.
Kasus penggunaan umum untuk contoh rencana kueri:
Beberapa kasus penggunaan umum untuk contoh rencana kueri mencakup:
- Mengamati perubahan rencana kueri karena perubahan skema (misalnya, menambahkan atau menghapus indeks).
- Mengamati perubahan rencana kueri karena update versi pengoptimal.
- Mengamati perubahan rencana kueri karena statistik pengoptimal baru,
yang dikumpulkan setiap tiga hari secara otomatis atau dilakukan secara manual menggunakan
perintah
ANALYZE.
Jika performa kueri menunjukkan perbedaan yang signifikan dari waktu ke waktu atau jika Anda ingin meningkatkan performa kueri, lihat Praktik terbaik SQL untuk membuat pernyataan kueri yang dioptimalkan yang membantu Spanner menemukan rencana eksekusi yang efisien.
Proses Kueri
Kueri SQL di Spanner pertama-tama dikompilasi menjadi rencana eksekusi, lalu dikirim ke server root awal untuk dieksekusi. Server root dipilih untuk meminimalkan jumlah hop untuk mencapai data yang dikueri. Server root kemudian:
- memulai eksekusi sub-paket jarak jauh (jika diperlukan)
- menunggu hasil dari eksekusi jarak jauh
- menangani langkah eksekusi lokal yang tersisa seperti mengagregasi hasil
- menampilkan hasil untuk kueri
Server jarak jauh yang menerima sub-paket bertindak sebagai server "root" untuk sub-paket mereka, mengikuti model yang sama dengan server root teratas. Hasilnya adalah hierarki eksekusi jarak jauh. Secara konseptual, eksekusi kueri mengalir dari atas ke bawah, dan hasil kueri ditampilkan dari bawah ke atas.Diagram berikut menunjukkan pola ini:

Contoh berikut mengilustrasikan pola ini secara lebih mendetail.
Kueri agregasi
Kueri agregasi mengimplementasikan kueri GROUP BY.
Misalnya, menggunakan kueri ini:
SELECT s.SingerId, COUNT(*) AS SongCount
FROM Songs AS s
WHERE s.SingerId < 100
GROUP BY s.SingerId;
Berikut hasilnya:
+----------+-----------+
| SingerId | SongCount |
+----------+-----------+
| 3 | 1 |
| 2 | 8 |
+----------+-----------+
Secara konseptual, ini adalah rencana eksekusi:
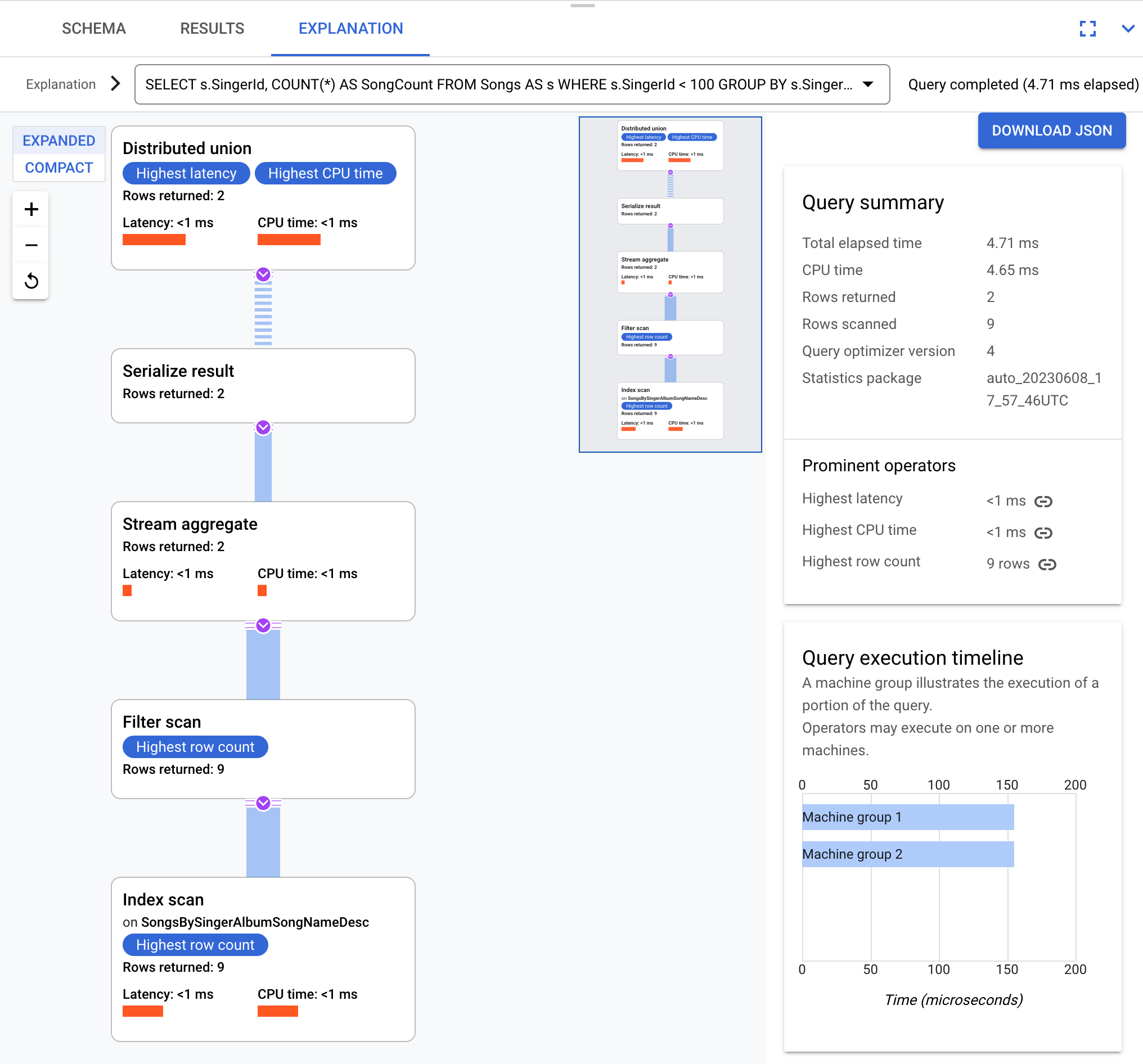
Spanner mengirimkan rencana eksekusi ke server root yang mengoordinasikan eksekusi kueri dan melakukan distribusi jarak jauh sub-paket.
Rencana eksekusi ini dimulai dengan _gabungan terdistribusi_, yang mendistribusikan
sub-paket ke server jarak jauh yang pemisahannya memenuhi SingerId < 100. Setelah pemindaian pada pemisahan individual selesai, operator agregat streaming akan mengagregasi baris untuk mendapatkan jumlah setiap SingerId. Operator hasil serialisasi kemudian menserialisasi hasilnya. Terakhir, gabungan terdistribusi menggabungkan semua hasil dan menampilkan hasil kueri.
Anda dapat mempelajari agregat lebih lanjut di operator agregat.
Kueri gabungan yang ditempatkan bersama
Tabel yang disisipkan disimpan secara fisik dengan baris tabel terkait yang ditempatkan bersama. Gabungan yang ditempatkan bersama adalah gabungan antara tabel yang disisipkan. Penggabungan yang ditempatkan bersama dapat menawarkan keunggulan performa dibandingkan penggabungan yang memerlukan indeks atau penggabungan kembali.
Misalnya, menggunakan kueri ini:
SELECT al.AlbumTitle, so.SongName
FROM Albums AS al, Songs AS so
WHERE al.SingerId = so.SingerId AND al.AlbumId = so.AlbumId;
(Kueri ini mengasumsikan bahwa Songs disisipkan di Albums.)
Berikut hasilnya:
+-----------------------+--------------------------+
| AlbumTitle | SongName |
+-----------------------+--------------------------+
| Nothing To Do With Me | Not About The Guitar |
| Green | The Second Time |
| Green | Starting Again |
| Green | Nothing Is The Same |
| Green | Let's Get Back Together |
| Green | I Knew You Were Magic |
| Green | Blue |
| Green | 42 |
| Terrified | Fight Story |
+-----------------------+--------------------------+
Berikut rencana eksekusinya:
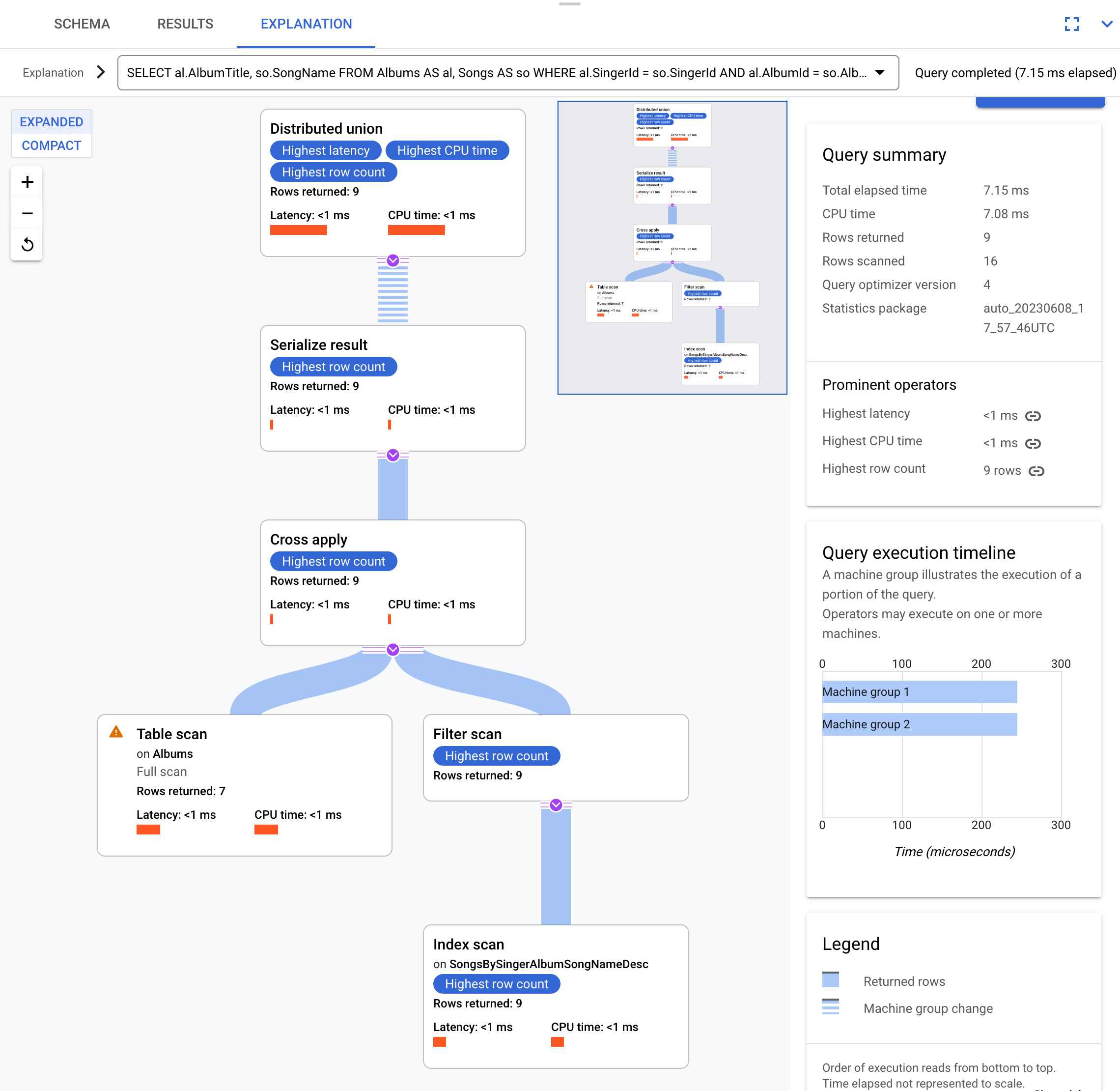
Rencana eksekusi ini dimulai dengan gabungan terdistribusi, yang
mendistribusikan sub-paket ke server jarak jauh yang memiliki pemisahan tabel Albums.
Karena Songs adalah tabel yang disisipkan dari Albums, setiap server jarak jauh dapat menjalankan seluruh sub-paket di setiap server jarak jauh tanpa memerlukan gabungan ke server lain.
Sub-paket berisi cross apply. Setiap cross apply melakukan tabel
pemindaian pada tabel Albums untuk mengambil SingerId, AlbumId, dan
AlbumTitle. Cross apply kemudian memetakan output dari pemindaian tabel ke output
dari pemindaian indeks pada indeks SongsBySingerAlbumSongNameDesc, yang tunduk pada
filter dari SingerId dalam indeks yang cocok dengan SingerId dari
output pemindaian tabel. Setiap cross apply mengirimkan hasilnya ke operator serialize result
yang menserialkan data AlbumTitle dan SongName serta mengembalikan
hasil ke gabungan terdistribusi lokal. Penggabungan terdistribusi mengagregasi hasil dari penggabungan terdistribusi lokal dan menampilkannya sebagai hasil kueri.
Kueri indeks dan gabungan kembali
Contoh di atas menggunakan gabungan pada dua tabel, satu disisipkan di tabel lainnya. Rencana eksekusi lebih kompleks dan kurang efisien jika dua tabel, atau tabel dan indeks, tidak disisipkan.
Pertimbangkan indeks yang dibuat dengan perintah berikut:
CREATE INDEX SongsBySongName ON Songs(SongName)
Gunakan indeks ini dalam kueri ini:
SELECT s.SongName, s.Duration
FROM Songs@{force_index=SongsBySongName} AS s
WHERE STARTS_WITH(s.SongName, "B");
Berikut hasilnya:
+----------+----------+
| SongName | Duration |
+----------+----------+
| Blue | 238 |
+----------+----------+
Berikut rencana eksekusinya:
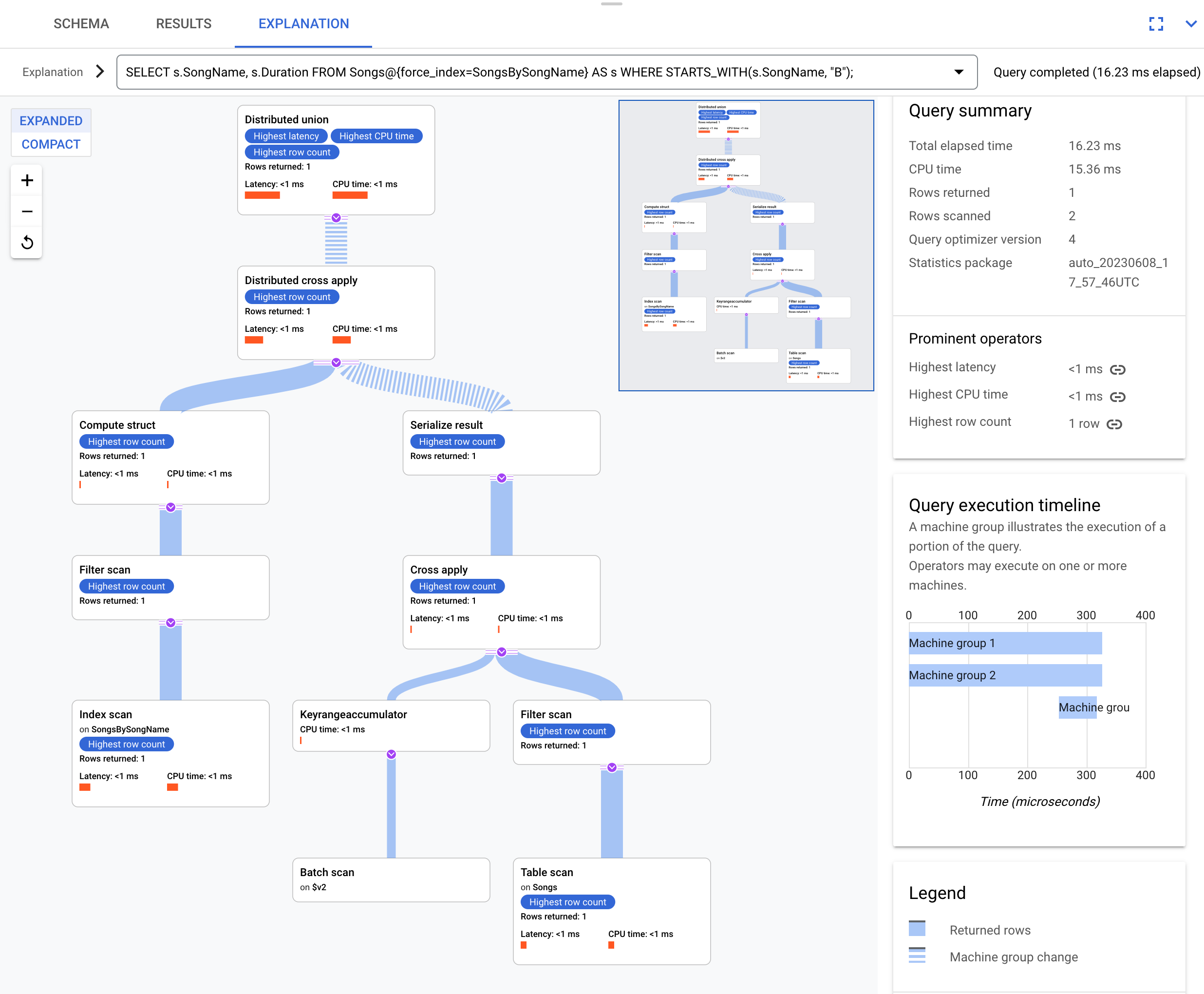
Rencana eksekusi yang dihasilkan rumit karena indeks SongsBySongName tidak berisi kolom Duration. Untuk mendapatkan nilai Duration, Spanner perlu menggabungkan kembali hasil yang diindeks ke tabel Songs. Ini adalah gabungan, tetapi tidak ditempatkan bersama karena tabel Songs dan
indeks global SongsBySongName tidak disisipkan. Rencana eksekusi yang dihasilkan lebih kompleks daripada contoh gabungan yang ditempatkan bersama karena Spanner melakukan pengoptimalan untuk mempercepat eksekusi jika data tidak ditempatkan bersama.
Operator teratas adalah cross apply terdistribusi. Sisi input operator ini adalah batch baris dari indeks SongsBySongName yang memenuhi
predikat STARTS_WITH(s.SongName, "B"). Cross apply terdistribusi kemudian memetakan batch ini ke server jarak jauh yang pemisahannya berisi data Duration. Server jarak jauh menggunakan pemindaian tabel untuk mengambil kolom Duration.
Pemindaian tabel menggunakan filter Condition:($Songs_key_TrackId' =
$batched_Songs_key_TrackId), yang menggabungkan TrackId dari tabel Songs ke
TrackId baris yang di-batch dari indeks SongsBySongName.
Hasilnya diagregasi ke dalam jawaban kueri akhir. Selanjutnya, sisi input cross apply terdistribusi berisi pasangan gabungan terdistribusi/gabungan terdistribusi lokal untuk mengevaluasi baris dari indeks yang memenuhi predikat STARTS_WITH.
Pertimbangkan kueri yang sedikit berbeda yang tidak memilih kolom s.Duration:
SELECT s.SongName
FROM Songs@{force_index=SongsBySongName} AS s
WHERE STARTS_WITH(s.SongName, "B");
Kueri ini dapat memanfaatkan indeks sepenuhnya seperti yang ditunjukkan dalam rencana eksekusi ini:

Rencana eksekusi tidak memerlukan gabungan kembali karena semua kolom yang diminta oleh kueri ada dalam indeks.
Langkah berikutnya
Pelajari Operator eksekusi kueri
Pelajari cara Mengelola pengoptimal kueri