
Panoramica
Questa pagina fornisce concetti sui piani di esecuzione delle query e su come vengono utilizzati da Spanner per eseguire query in un ambiente distribuito. Per scoprire come recuperare un piano di esecuzione per una query specifica utilizzando la consoleGoogle Cloud , consulta Scopri in che modo Spanner esegue le query. Puoi anche visualizzare piani di query storici campionati e confrontare le prestazioni di una query nel tempo per determinate query. Per saperne di più, consulta Piani di query campionati.
Spanner utilizza istruzioni SQL dichiarative per eseguire query sui suoi database. Le istruzioni SQL definiscono cosa vuole l'utente senza specificare come ottenere i risultati. Un piano di esecuzione query è l'insieme di passaggi per ottenere i risultati. Per una determinata istruzione SQL, esistono diversi modi per ottenere i risultati. L'ottimizzatore delle query di Spanner valuta diversi piani di esecuzione e sceglie quello che ritiene più efficiente. Spanner utilizza quindi il piano di esecuzione per recuperare i risultati. I piani di esecuzione supportano i database con dialetto GoogleSQL e PostgreSQL.
A livello concettuale, un piano di esecuzione è un albero di operatori relazionali. Ogni operatore legge le righe dai relativi input e produce righe di output. Il risultato dell'operatore alla radice dell'esecuzione viene restituito come risultato della query SQL.
Ad esempio, questa query:
SELECT s.SongName FROM Songs AS s;
genera un piano di esecuzione della query che può essere visualizzato come:
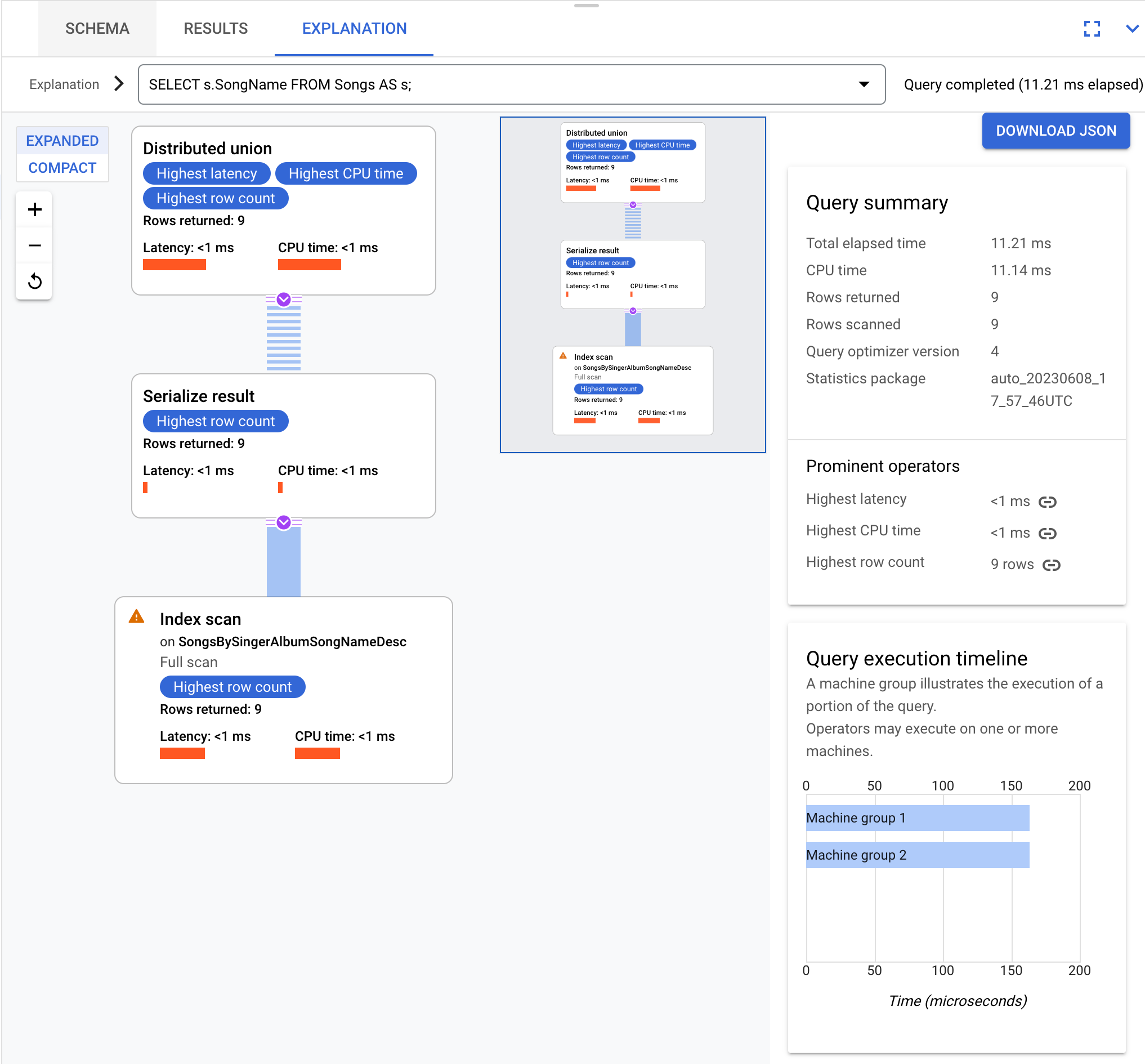
Le query e i piani di esecuzione in questa pagina si basano sul seguente schema del database:
CREATE TABLE Singers (
SingerId INT64 NOT NULL,
FirstName STRING(1024),
LastName STRING(1024),
SingerInfo BYTES(MAX),
BirthDate DATE
) PRIMARY KEY(SingerId);
CREATE INDEX SingersByFirstLastName ON Singers(FirstName, LastName);
CREATE TABLE Albums (
SingerId INT64 NOT NULL,
AlbumId INT64 NOT NULL,
AlbumTitle STRING(MAX),
MarketingBudget INT64
) PRIMARY KEY(SingerId, AlbumId),
INTERLEAVE IN PARENT Singers ON DELETE CASCADE;
CREATE INDEX AlbumsByAlbumTitle ON Albums(AlbumTitle);
CREATE INDEX AlbumsByAlbumTitle2 ON Albums(AlbumTitle) STORING (MarketingBudget);
CREATE TABLE Songs (
SingerId INT64 NOT NULL,
AlbumId INT64 NOT NULL,
TrackId INT64 NOT NULL,
SongName STRING(MAX),
Duration INT64,
SongGenre STRING(25)
) PRIMARY KEY(SingerId, AlbumId, TrackId),
INTERLEAVE IN PARENT Albums ON DELETE CASCADE;
CREATE INDEX SongsBySingerAlbumSongNameDesc ON Songs(SingerId, AlbumId, SongName DESC), INTERLEAVE IN Albums;
CREATE INDEX SongsBySongName ON Songs(SongName);
CREATE TABLE Concerts (
VenueId INT64 NOT NULL,
SingerId INT64 NOT NULL,
ConcertDate DATE NOT NULL,
BeginTime TIMESTAMP,
EndTime TIMESTAMP,
TicketPrices ARRAY<INT64>
) PRIMARY KEY(VenueId, SingerId, ConcertDate);
Puoi utilizzare le seguenti istruzioni DML (Data Manipulation Language) per aggiungere dati a queste tabelle:
INSERT INTO Singers (SingerId, FirstName, LastName, BirthDate)
VALUES (1, "Marc", "Richards", "1970-09-03"),
(2, "Catalina", "Smith", "1990-08-17"),
(3, "Alice", "Trentor", "1991-10-02"),
(4, "Lea", "Martin", "1991-11-09"),
(5, "David", "Lomond", "1977-01-29");
INSERT INTO Albums (SingerId, AlbumId, AlbumTitle)
VALUES (1, 1, "Total Junk"),
(1, 2, "Go, Go, Go"),
(2, 1, "Green"),
(2, 2, "Forever Hold Your Peace"),
(2, 3, "Terrified"),
(3, 1, "Nothing To Do With Me"),
(4, 1, "Play");
INSERT INTO Songs (SingerId, AlbumId, TrackId, SongName, Duration, SongGenre)
VALUES (2, 1, 1, "Let's Get Back Together", 182, "COUNTRY"),
(2, 1, 2, "Starting Again", 156, "ROCK"),
(2, 1, 3, "I Knew You Were Magic", 294, "BLUES"),
(2, 1, 4, "42", 185, "CLASSICAL"),
(2, 1, 5, "Blue", 238, "BLUES"),
(2, 1, 6, "Nothing Is The Same", 303, "BLUES"),
(2, 1, 7, "The Second Time", 255, "ROCK"),
(2, 3, 1, "Fight Story", 194, "ROCK"),
(3, 1, 1, "Not About The Guitar", 278, "BLUES");
Ottenere piani di esecuzione efficienti è difficile perché Spanner divide i dati in split. Le suddivisioni possono spostarsi indipendentemente l'una dall'altra e vengono assegnate a server diversi, che potrebbero trovarsi in posizioni fisiche diverse. Per valutare i piani di esecuzione sui dati distribuiti, Spanner utilizza l'esecuzione in base a:
- esecuzione locale dei piani secondari nei server che contengono i dati
- orchestrazione e aggregazione di più esecuzioni remote con eliminazione aggressiva della distribuzione
Spanner utilizza l'operatore primitivo distributed union,
insieme alle sue varianti distributed cross apply e
distributed outer apply, per attivare questo modello.
Principali metriche di rendimento
Il visualizzatore del piano di query di Spanner Studio mostra le metriche di riepilogo per l'esecuzione della query. Le metriche di riepilogo rappresentano l'aggregazione delle metriche di tutti gli operatori individuali eseguiti durante la query. La tabella seguente descrive le metriche chiave sul rendimento:
| Metrica | Descrizione |
|---|---|
| Tempo totale trascorso | Il tempo totale impiegato per eseguire la query. |
| Tempo di CPU | La quantità totale di tempo di CPU dedicata a tutti i server coinvolti nell'esecuzione della query. Poiché alcune parti dell'esecuzione della query possono procedere in parallelo, il tempo di CPU può essere maggiore del tempo totale trascorso. |
Piani di query campionati
I piani di query campionati di Spanner ti consentono di visualizzare campioni di piani di query storici e confrontare il rendimento di una query nel tempo. Non tutte le query hanno piani di query campionati disponibili. Potrebbero essere campionate solo le query che consumano più CPU. La conservazione dei dati per i campioni di piani di query Spanner è di 30 giorni. Puoi trovare esempi di piani di query nella pagina Approfondimenti sulle query della console Google Cloud . Per le istruzioni, vedi Visualizzare i piani di query campionati.
La struttura di un piano di query campionato è la stessa di un normale piano di esecuzione delle query. Per saperne di più su come comprendere i piani visivi e utilizzarli per eseguire il debug delle query, consulta Panoramica del visualizzatore del piano query.
Casi d'uso comuni per i piani di query campionati:
Alcuni casi d'uso comuni per i piani di query campionati includono:
- Osserva le modifiche al piano di query dovute a modifiche allo schema (ad esempio, aggiunta o rimozione di un indice).
- Osserva le modifiche al piano di query dovute a un aggiornamento della versione dell'ottimizzatore.
- Osserva le modifiche al piano di query dovute alle nuove statistiche dell'ottimizzatore,
che vengono raccolte automaticamente ogni tre giorni o eseguite manualmente utilizzando
il comando
ANALYZE.
Se il rendimento di una query mostra una differenza significativa nel tempo o se vuoi migliorare il rendimento di una query, consulta Best practice per SQL per creare istruzioni di query ottimizzate che aiutino Spanner a trovare piani di esecuzione efficienti.
Durata di una query
Una query SQL in Spanner viene prima compilata in un piano di esecuzione, poi viene inviata a un server radice iniziale per l'esecuzione. Il server radice viene scelto in modo da ridurre al minimo il numero di hop per raggiungere i dati su cui viene eseguita la query. Il server radice quindi:
- avvia l'esecuzione remota dei piani secondari (se necessario)
- attende i risultati delle esecuzioni remote
- gestisce i passaggi di esecuzione locali rimanenti, ad esempio l'aggregazione dei risultati
- restituisce i risultati della query
I server remoti che ricevono un piano secondario fungono da server "root" per il piano secondario, seguendo lo stesso modello del server root di primo livello. Il risultato è un albero di esecuzioni remote. Concettualmente, l'esecuzione della query scorre dall'alto verso il basso e i risultati della query vengono restituiti dal basso verso l'alto.Il seguente diagramma mostra questo pattern:

Gli esempi riportati di seguito illustrano questo pattern in modo più dettagliato.
Query di aggregazione
Una query aggregata implementa GROUP BY query.
Ad esempio, utilizzando questa query:
SELECT s.SingerId, COUNT(*) AS SongCount
FROM Songs AS s
WHERE s.SingerId < 100
GROUP BY s.SingerId;
Ecco i risultati:
+----------+-----------+
| SingerId | SongCount |
+----------+-----------+
| 3 | 1 |
| 2 | 8 |
+----------+-----------+
A livello concettuale, questo è il piano di esecuzione:
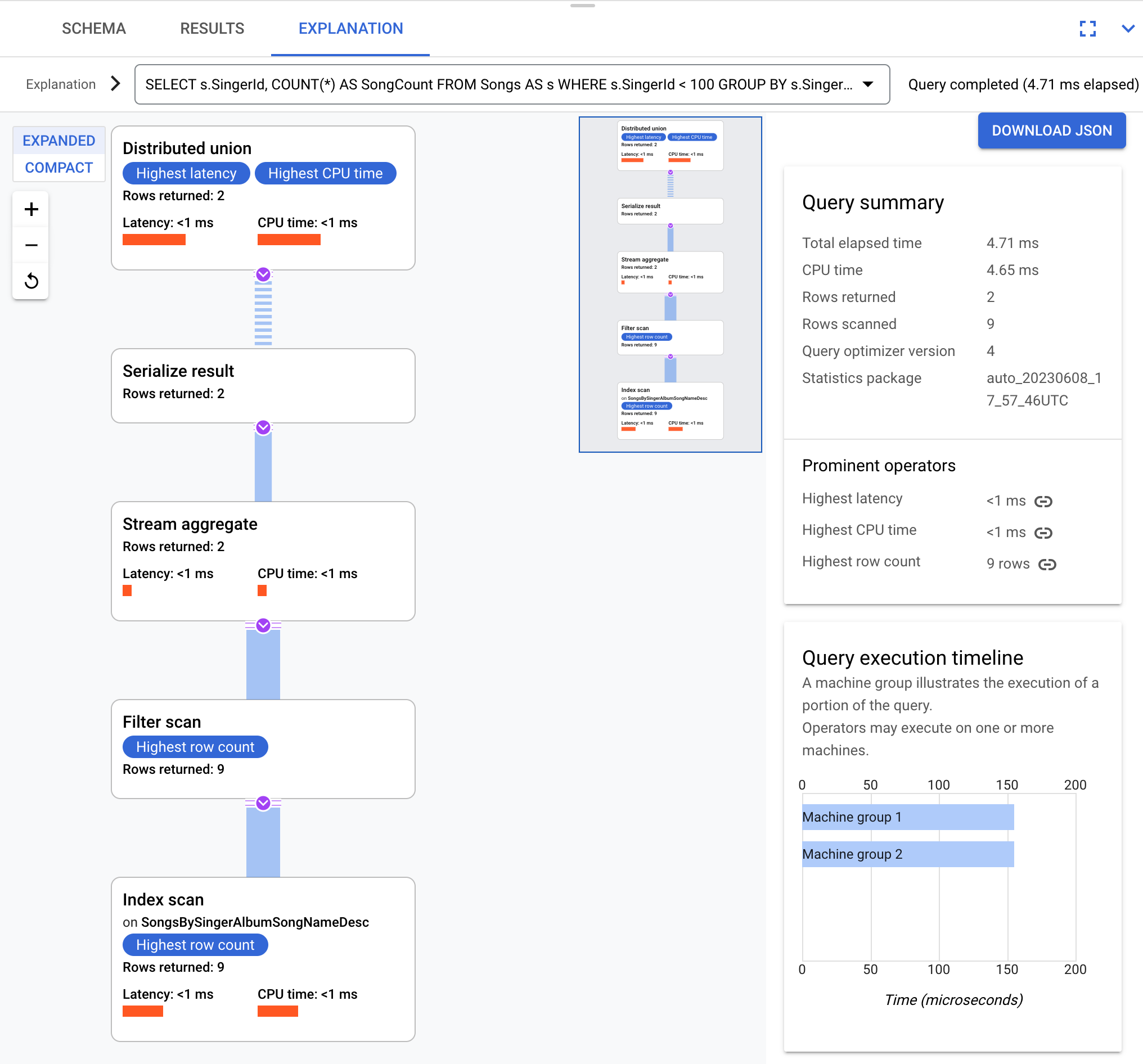
Spanner invia il piano di esecuzione a un server radice che coordina l'esecuzione della query ed esegue la distribuzione remota dei sottopiani.
Questo piano di esecuzione inizia con un'unione distribuita, che distribuisce
i piani secondari ai server remoti le cui suddivisioni soddisfano SingerId < 100. Al termine della scansione
delle singole suddivisioni, l'operatore stream aggregate aggrega le righe
per ottenere i conteggi per ogni SingerId. L'operatore serialize result serializza il risultato. Infine, l'unione distribuita combina tutti i risultati
e restituisce i risultati della query.
Per saperne di più sugli aggregati, consulta la sezione Operatore di aggregazione.
Query di unione collocate
Le tabelle interleaved vengono archiviate fisicamente con le righe delle tabelle correlate collocate insieme. Un join colocalizzato è un join tra tabelle interleaved. I join collocati possono offrire vantaggi in termini di prestazioni rispetto ai join che richiedono indici o back join.
Ad esempio, utilizzando questa query:
SELECT al.AlbumTitle, so.SongName
FROM Albums AS al, Songs AS so
WHERE al.SingerId = so.SingerId AND al.AlbumId = so.AlbumId;
(Questa query presuppone che Songs sia interleaved in Albums.)
Ecco i risultati:
+-----------------------+--------------------------+
| AlbumTitle | SongName |
+-----------------------+--------------------------+
| Nothing To Do With Me | Not About The Guitar |
| Green | The Second Time |
| Green | Starting Again |
| Green | Nothing Is The Same |
| Green | Let's Get Back Together |
| Green | I Knew You Were Magic |
| Green | Blue |
| Green | 42 |
| Terrified | Fight Story |
+-----------------------+--------------------------+
Questo è il piano di esecuzione:
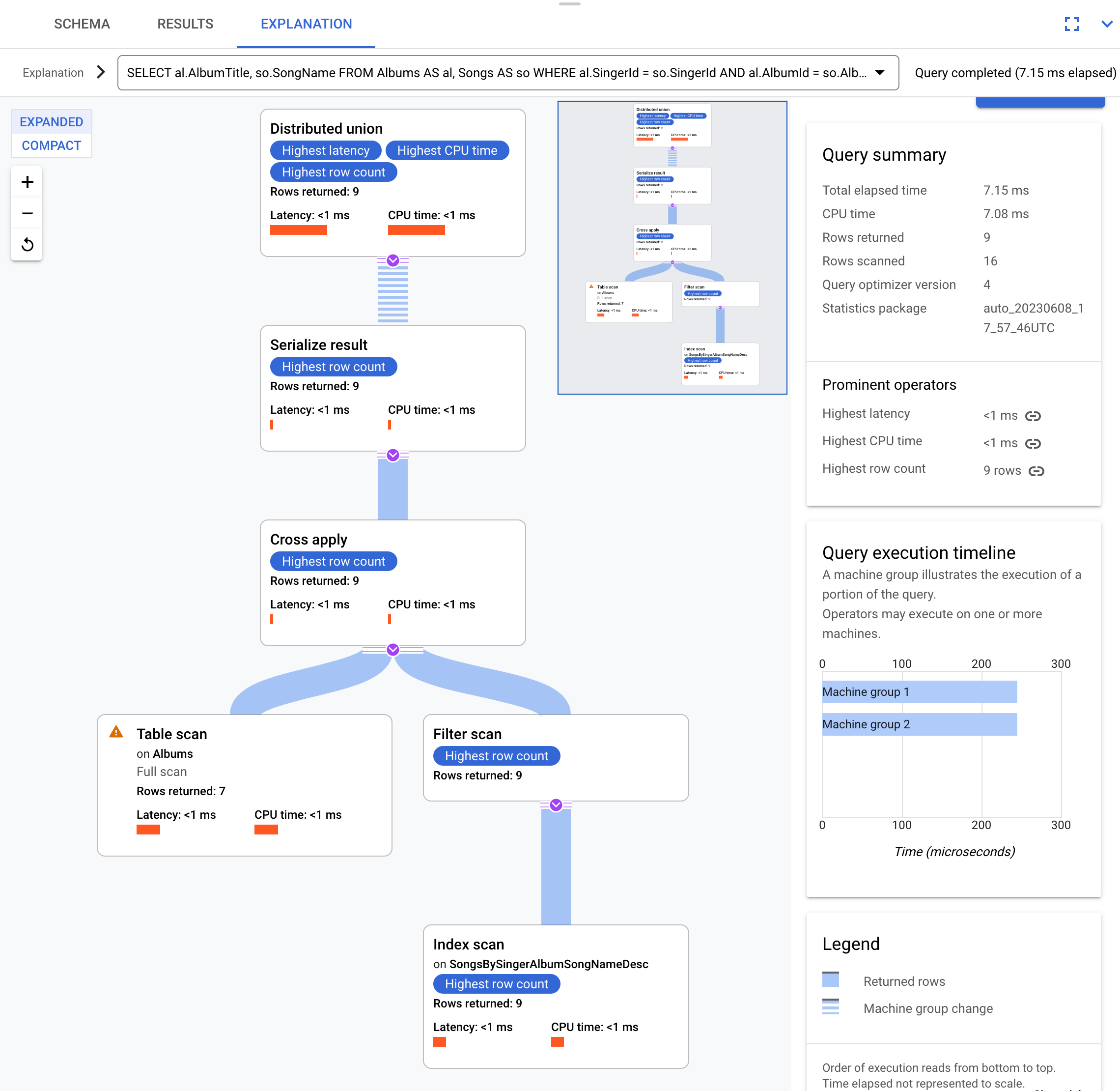
Questo piano di esecuzione inizia con un'unione distribuita, che
distribuisce i sottopiani ai server remoti che hanno suddivisioni della tabella Albums.
Poiché Songs è una tabella interleaved di Albums, ogni server remoto è in grado
di eseguire l'intero piano secondario su ogni server remoto senza richiedere un join a
un server diverso.
I sottopiani contengono un'applicazione incrociata. Ogni cross apply esegue una scansione
della tabella sulla tabella Albums per recuperare SingerId, AlbumId e
AlbumTitle. Il cross apply mappa quindi l'output della scansione della tabella all'output
di una scansione dell'indice sull'indice SongsBySingerAlbumSongNameDesc, soggetto a un
filtro di SingerId nell'indice corrispondente a SingerId dell'output
della scansione della tabella. Ogni cross apply invia i risultati a un operatore serialize result che serializza i dati AlbumTitle e SongName e restituisce i risultati alle unioni distribuite locali. L'operazione Union distribuita aggrega
i risultati delle operazioni Union distribuite locali e li restituisce come risultato della query.
Query di indice e di unione inversa
L'esempio precedente utilizzava un'unione di due tabelle, una intercalata nell'altra. I piani di esecuzione sono più complessi e meno efficienti quando due tabelle o una tabella e un indice non sono interleaved.
Prendi in considerazione un indice creato con il seguente comando:
CREATE INDEX SongsBySongName ON Songs(SongName)
Utilizza questo indice in questa query:
SELECT s.SongName, s.Duration
FROM Songs@{force_index=SongsBySongName} AS s
WHERE STARTS_WITH(s.SongName, "B");
Ecco i risultati:
+----------+----------+
| SongName | Duration |
+----------+----------+
| Blue | 238 |
+----------+----------+
Questo è il piano di esecuzione:
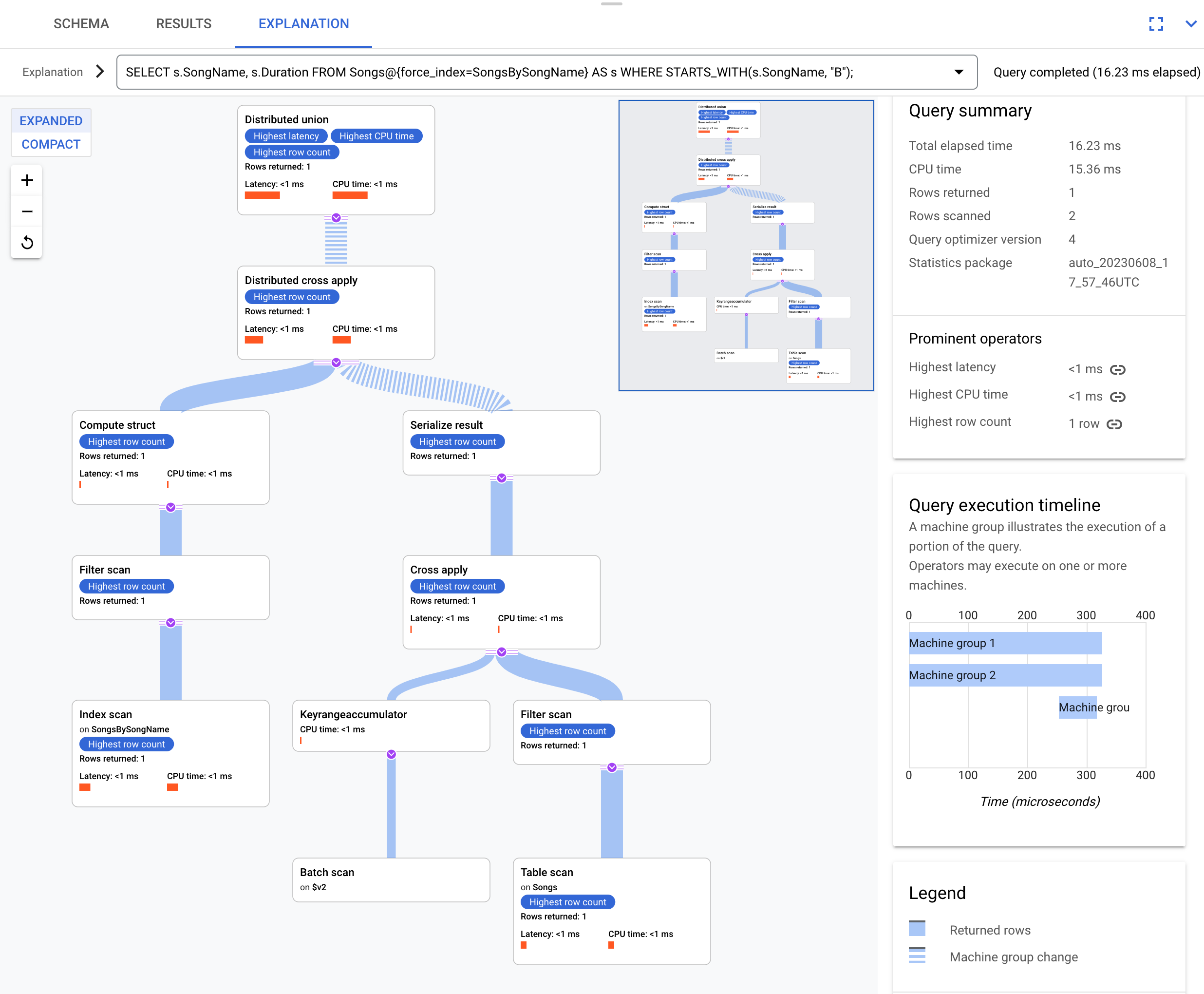
Il piano di esecuzione risultante è complesso perché l'indice SongsBySongName
non contiene la colonna Duration. Per ottenere il valore Duration,
Spanner deve eseguire un back join dei risultati indicizzati alla tabella
Songs. Si tratta di un'unione, ma non è colocalizzata perché la tabella Songs e
l'indice globale SongsBySongName non sono intercalati. Il piano di esecuzione risultante
è più complesso dell'esempio di join colocalizzato perché
Spanner esegue ottimizzazioni per velocizzare l'esecuzione se i dati
non sono colocalizzati.
L'operatore principale è un Distributed Cross Apply. Il lato di input di questo operatore sono batch di righe dell'indice SongsBySongName che soddisfano il predicato STARTS_WITH(s.SongName, "B"). L'operazione Cross Apply distribuita
mappa quindi questi batch ai server remoti le cui suddivisioni contengono i dati Duration. I server remoti utilizzano una scansione della tabella per recuperare la colonna Duration.
La scansione della tabella utilizza il filtro Condition:($Songs_key_TrackId' =
$batched_Songs_key_TrackId), che unisce TrackId della tabella Songs a
TrackId delle righe raggruppate dall'indice SongsBySongName.
I risultati vengono aggregati nella risposta finale della query. A sua volta, il lato di input
dell'applicazione incrociata distribuita contiene una coppia di unioni distribuite/unioni distribuite locali
per valutare le righe dell'indice che soddisfano il predicato STARTS_WITH.
Prendi in considerazione una query leggermente diversa che non selezioni la colonna s.Duration:
SELECT s.SongName
FROM Songs@{force_index=SongsBySongName} AS s
WHERE STARTS_WITH(s.SongName, "B");
Questa query è in grado di sfruttare appieno l'indice, come mostrato in questo piano di esecuzione:
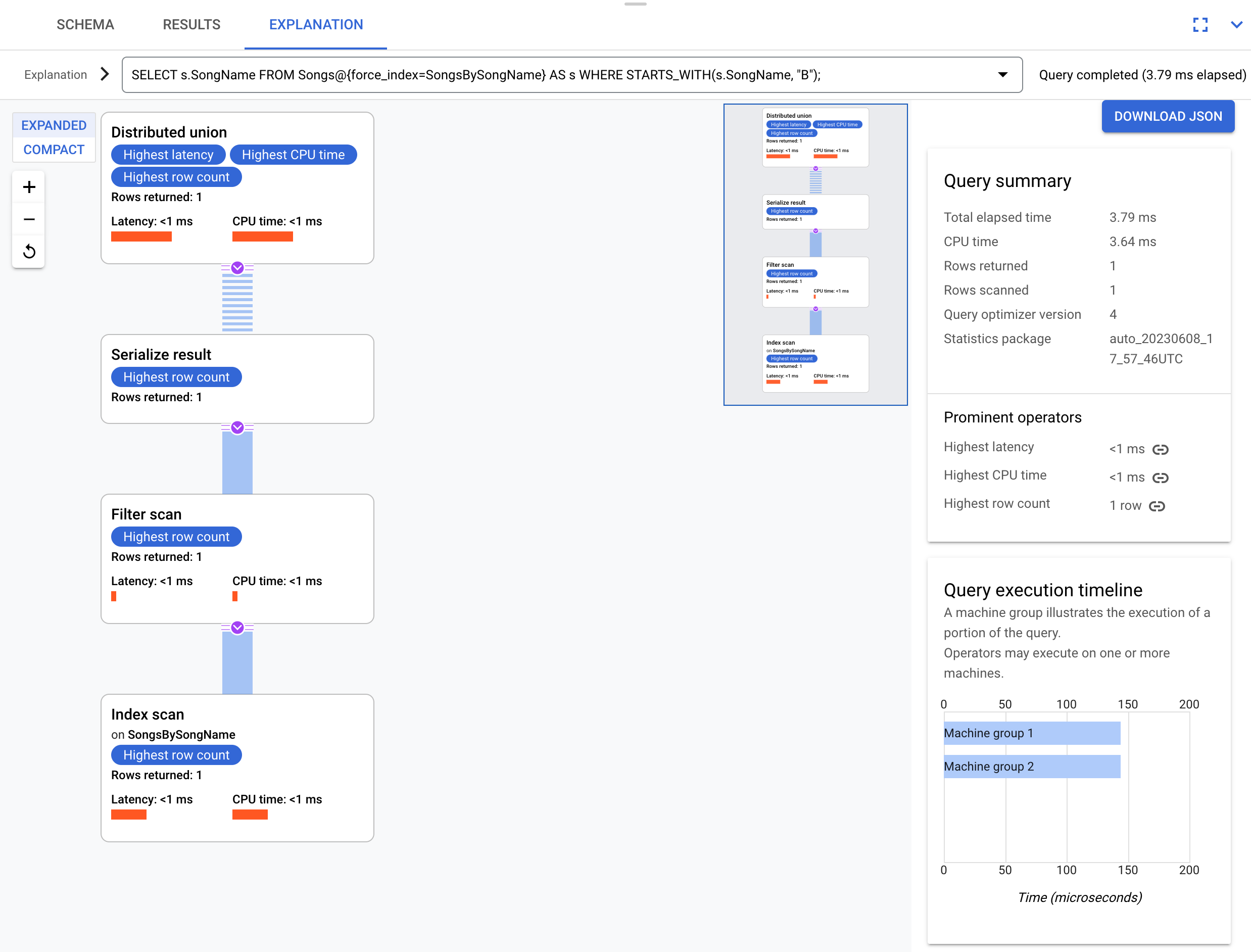
Il piano di esecuzione non richiede un back join perché tutte le colonne richieste dalla query sono presenti nell'indice.
Passaggi successivi
Scopri di più sugli operatori di esecuzione delle query
Scopri di più sullo strumento di ottimizzazione delle query di Spanner
Scopri come gestire lo strumento di ottimizzazione delle query