
En este documento, se describe cómo usar el panel de Estadísticas de hotspots para detectar hotspots en tu base de datos de Spanner.
Descripción general de Estadísticas de hotspots
Los hotspots provocan latencia en tu base de datos de Spanner. El panel de Estadísticas de hotspots te ayuda a detectar las divisiones afectadas por los hotspots. Sigue estos pasos para determinar si los hotspots causan latencia y, si es así, cómo resolver el problema:
- Abre el panel.
- Determina si los hotspots necesitan tu intervención.
- Identifica las divisiones activas problemáticas.
Las estadísticas de hotspots están disponibles en configuraciones regionales, multirregionales y birregionales.
Precios
No hay costos adicionales para Estadísticas de hotspots.
Retención de datos
Las políticas de retención de datos para los gráficos de Estadísticas de hotspots y la tabla de divisiones de Top-N se basan en las tablas SPANNER_SYS.SPLIT_STATS_TOP_* subyacentes. Para conocer las políticas de retención específicas, consulta
Retención de datos de estadísticas de divisiones activas.
Roles obligatorios
Es posible que necesites diferentes roles y permisos de IAM, según si eres un usuario de IAM o un usuario de control de acceso detallado.
Usuario de Identity and Access Management (IAM)
Para obtener los permisos que necesitas para ver la página Estadísticas de hotspots, pídele a tu administrador que te otorgue los siguientes roles de IAM en la instancia:
-
Todos:
- Visualizador de Cloud Spanner (
roles/spanner.viewer) - Lector de base de datos de Cloud Spanner (
roles/spanner.databaseReader)
- Visualizador de Cloud Spanner (
Se requieren los siguientes permisos en el rol Lector de base de datos de Cloud Spanner (
roles/spanner.databaseReader) para ver la página Estadísticas de hotspots:
spanner.databases.beginReadOnlyTransactionspanner.databases.selectspanner.sessions.create
Usuario de control de acceso detallado
Si eres un usuario de control de acceso detallado, asegúrate de lo siguiente:
- Tener el Visualizador de Cloud Spanner
(
roles/spanner.viewer) - Tener privilegios de control de acceso detallado y que se te otorgue el rol del sistema
spanner_sys_readero uno de sus roles miembros - Seleccionar
spanner_sys_readero un rol miembro como tu rol del sistema actual en la página Descripción general de la base de datos
Para obtener más información, consulta Descripción general del control de acceso detallado y Roles del sistema de control de acceso detallado.
Abre el panel de Estadísticas de hotspots
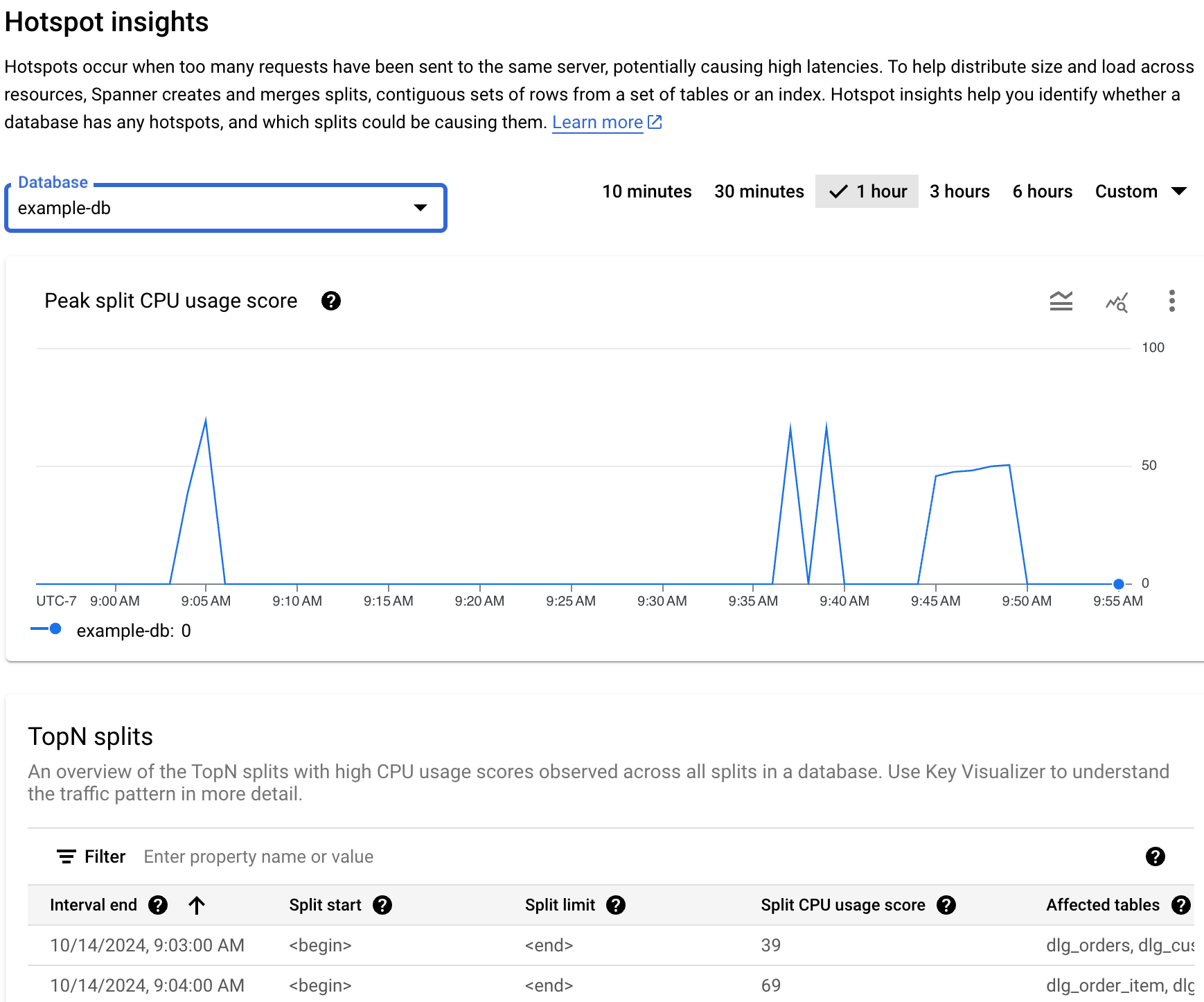
El panel de Estadísticas de hotspots muestra el porcentaje máximo de uso de CPU de división. Esta métrica es un porcentaje abstracto de 0 a 100 que refleja la cantidad de CPU que se usa cuando se accede a las filas dentro de una división.
Para ver el panel de Estadísticas de hotspots de una base de datos, haz lo siguiente:
En la Google Cloud consola de, abre la página Spanner.
Elige una instancia de la lista.
En el menú de navegación, haz clic en la pestaña Estadísticas de hotspots.
En el campo base de datos, selecciona una base de datos de la lista. El panel muestra la puntuación máxima de uso de CPU de división para la base de datos.
El panel incluye los siguientes elementos:
- Gráfico de puntuación máxima de uso de CPU de división: Una puntuación de uso de CPU más alta (como cerca de 100) indica que la división es activa y es muy probable que cause un hotspot en el servidor en comparación con las puntuaciones más bajas.
- Campo de base de datos: Filtra la información de las divisiones activas en una base de datos específica o en todas las bases de datos.
- Filtro de intervalo de tiempo: Filtra el uso de CPU de las divisiones máximas en incrementos de 1 minuto hasta un total de 6 horas.
- Tabla de divisiones de Top-N: Muestra la lista de las principales divisiones ordenadas por puntuaciones de uso de CPU de división.
Información sobre los datos en la tabla de divisiones de Top-N: La tabla de divisiones de Top-N propaga datos de las tablas SPANNER_SYS.SPLIT_STATS_TOP_* subyacentes según el intervalo de tiempo que selecciones. Para
obtener más información, consulta
Retención de datos de estadísticas de divisiones activas.
Interpretación de filas de tablas 10MINUTE o HOUR:
Las filas provenientes de SPANNER_SYS.SPLIT_STATS_TOP_10MINUTE o SPANNER_SYS.SPLIT_STATS_TOP_HOUR
representan datos agregados en sus intervalos respectivos. Como se describe en
Agregación de eventos de tabla,
el CPU_USAGE_SCORE en estas filas es la puntuación máxima que se ve en cualquier
subintervalo subyacente de 1 minuto, y UNSPLITTABLE_REASONS es una unión de
motivos.
Determina si los hotspots necesitan intervención
Si ves un aumento repentino o una elevación en el gráfico que corresponde a la latencia general y una puntuación máxima de uso de CPU de división alta y persistente, es posible que debas investigar más.
Revisa el gráfico para explorar estas preguntas:
¿Qué base de datos experimenta la degradación de la latencia? Selecciona bases de datos diferentes en la lista Bases de datos para encontrar las bases de datos con la latencia más alta. Para saber qué base de datos tiene la carga más alta, también puedes revisar el gráfico deLatencia para bases de datos en la Google Cloud consola.

¿La latencia es alta? ¿La latencia es alta en comparación con la latencia esperada para la carga de trabajo? ¿El gráfico aumenta o se incrementa con el tiempo? Si no ves una latencia alta, entonces los hotspots no son un problema.
¿La puntuación máxima de uso de CPU de división alta está al 100%? ¿El gráfico aumenta o se incrementa con el tiempo? Si no ves porcentajes máximos de uso de CPU de división persistentes del 100% durante al menos 10 minutos, es posible que los hotspots no sean un problema. Si el porcentaje máximo de uso de CPU de división es alto durante más de 10 minutos, es posible que desees investigar más para ver si la base de datos tiene niveles de latencia más altos de lo esperado.
Si ves porcentajes máximos de uso de CPU de división del 100% durante más de 10 minutos, es posible que los hotspots necesiten tu intervención. A continuación, puedes continuar el recorrido de depuración identificando las divisiones activas en tu base de datos.
Identifica las divisiones activas problemáticas
Para identificar una división potencialmente problemática que tiene hotspots, consulta la sección TopN splits en la Google Cloud consola, como se muestra a continuación.
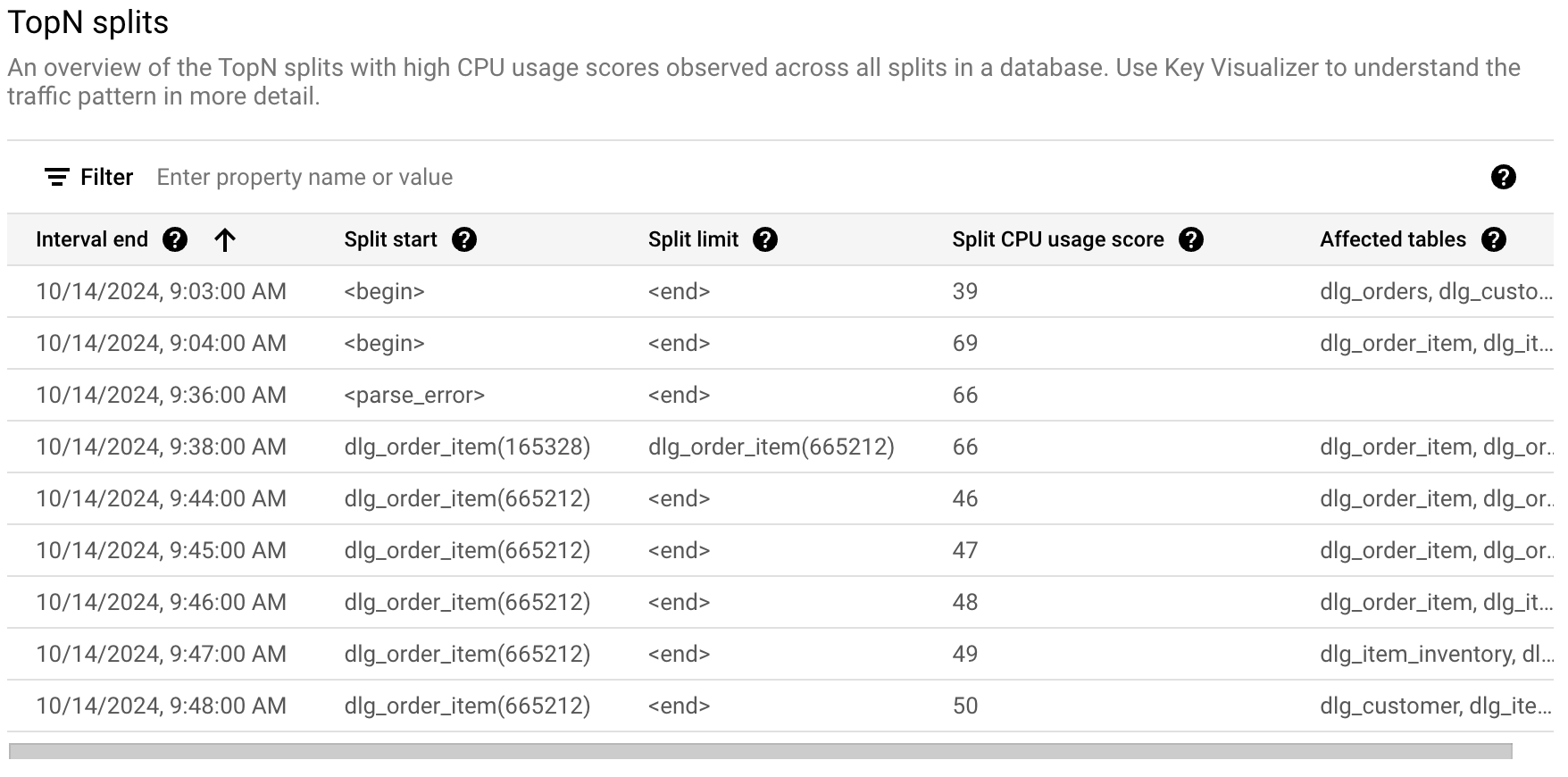
La tabla de divisiones de Top-N proporciona una descripción general de las divisiones que podrían estar activas durante el período elegido, ordenadas de más reciente a más antigua. La cantidad de divisiones de Top-N está limitada a 100.
Para los gráficos, Spanner recupera datos de la tabla de estadísticas de divisiones de Top-N, con una granularidad de un minuto. El valor de cada punto de datos en los gráficos representa el valor promedio durante un intervalo de un minuto.
En la tabla, se muestran las siguientes propiedades:
- Fin del intervalo: Es la fecha y hora en que finaliza el uso máximo de CPU.
- Inicio de la división: Es la clave inicial del rango de filas en la división. Si el inicio de la división es <begin>, indica el comienzo del rango de claves de la base de datos.
- Límite de división: Es la clave de límite del rango de filas en la división. Si la clave de límite es <end>, indica el final del rango de claves de la base de datos.
- Puntuación de uso de CPU dividida: Es una puntuación abstracta de 0 a 100 que refleja la cantidad de CPU que se usa en los accesos a las filas dentro de la división en un solo servidor. Usa la puntuación de uso de la CPU para evaluar si tienes hotspots.
- Tablas afectadas: Son las tablas cuyas filas podrían estar en la división.
- Motivos de no división: Es un array de motivos por los que Spanner
no puede dividir más una división activa. La presencia de valores aquí indica que la división basada en la carga no puede mitigar el hotspot por los motivos enumerados. Para obtener más información, consulta los tipos de
UNSPLITTABLE_REASONS.
Analiza los motivos de no división
La tabla de divisiones de Top-N te permite desglosar qué divisiones específicas se ven afectadas por estos motivos en momentos determinados, como se muestra en la columna Motivos de no división.
Ejemplo de flujo de trabajo de diagnóstico
Este es un flujo de trabajo típico para depurar hotspots con el panel:
- Observa el problema de rendimiento: Observa el aumento de la latencia o los errores en tu aplicación.
- Abre Estadísticas de hotspots: Navega al panel de Estadísticas de hotspots en la Google Cloud consola de para la base de datos de Spanner correspondiente. Selecciona el intervalo de tiempo correspondiente al problema.
- Examina el gráfico:
- Verifica el gráfico de puntuación máxima de uso de CPU de división para obtener valores altos y sostenidos, por ejemplo, >50%, en especial, si se acerca al 100% durante al menos 10 minutos.
- Identifica las divisiones afectadas y correlaciona los resultados: Si el uso de CPU es alto, ve a la tabla de divisiones de Top-N. Filtra u ordena para encontrar las divisiones con la puntuación de uso de CPU dividida más alta durante el tiempo de impacto. Examina la columna
UNSPLITTABLE_REASONSpara estas divisiones principales:- Puntuación de uso de CPU dividida alta y motivos de no división: Esta es una señal sólida de que el problema de rendimiento está relacionado con los hotspots que Spanner no puede resolver automáticamente. El tipo de motivo, como
HOT_ROWoMOVING_HOT_SPOT, proporciona una pista crucial. - Puntuación de uso de CPU dividida alta y sin motivos de no división: Es posible que el hotspot sea nuevo y que Spanner aún esté en proceso de división. Como alternativa, es posible que el problema responda a los cambios en la carga de trabajo, lo que no requiere ninguna acción de tu parte.
- Puntuación de uso de CPU dividida alta y motivos de no división: Esta es una señal sólida de que el problema de rendimiento está relacionado con los hotspots que Spanner no puede resolver automáticamente. El tipo de motivo, como
- Comprende los motivos: Ten en cuenta los códigos específicos en el array
UNSPLITTABLE_REASONS. - Mitiga: Según los motivos identificados, consulta los tipos de
UNSPLITTABLE_REASONSpara obtener explicaciones detalladas y estrategias de mitigación recomendadas, que suelen incluir cambios en el diseño del esquema o ajustes de la carga de trabajo.