
Ce document explique comment utiliser le tableau de bord Insights sur les hotspots pour détecter les hotspots dans votre base de données Spanner.
Présentation des insights sur les hotspots
Les hotspots entraînent une latence dans votre base de données Spanner. Le tableau de bord Insights sur les hotspots vous aide à détecter les divisions affectées par les hotspots. Procédez comme suit pour déterminer si les hotspots sont à l'origine de la latence et, le cas échéant, comment résoudre le problème :
- Ouvrez le tableau de bord.
- Déterminez si les hotspots nécessitent votre intervention.
- Identifiez les divisions actives problématiques.
Les insights sur les hotspots sont disponibles dans les configurations régionales, birégionales et multirégionales.
Tarifs
L'utilisation des insights sur les hotspots n'entraîne aucun coût supplémentaire.
Conservation des données
Les règles de conservation des données pour les graphiques Insights sur les hotspots et le tableau des N principales divisions sont basées sur les tables SPANNER_SYS.SPLIT_STATS_TOP_* sous-jacentes. Pour
connaître les règles de conservation spécifiques, consultez
Conservation des données statistiques sur les divisions actives.
Rôles requis
Vous aurez peut-être besoin de différents rôles et autorisations IAM, selon que vous êtes un utilisateur IAM ou un utilisateur du contrôle des accès ultraprécis.
Utilisateur Identity and Access Management (IAM)
Pour obtenir les autorisations nécessaires pour afficher la page Insights sur les hotspots , demandez à votre administrateur de vous accorder les rôles IAM suivants sur l'instance :
-
Tous :
- Lecteur Cloud Spanner (
roles/spanner.viewer) - Lecteur de bases de données Cloud Spanner (
roles/spanner.databaseReader)
- Lecteur Cloud Spanner (
Les autorisations suivantes du rôle Lecteur de bases de données Cloud Spanner (
roles/spanner.databaseReader) sont requises pour afficher la page Insights sur les hotspots :
spanner.databases.beginReadOnlyTransactionspanner.databases.selectspanner.sessions.create
Utilisateur du contrôle des accès ultraprécis
Si vous utilisez le contrôle des accès ultraprécis, assurez-vous que :
- vous disposez du rôle Lecteur Cloud Spanner
(
roles/spanner.viewer) - vous disposez de privilèges de contrôle des accès ultraprécis et que le rôle système
spanner_sys_readerou l'un de ses rôles membres vous a été attribué ; - Sélectionnez
spanner_sys_readerou un rôle de membre comme rôle système actuel sur la page Vue d'ensemble de la base de données.
Pour en savoir plus, consultez Présentation du contrôle des accès ultraprécis et Rôles système pour le contrôle des accès ultraprécis.
Ouvrir le tableau de bord Insights sur les hotspots
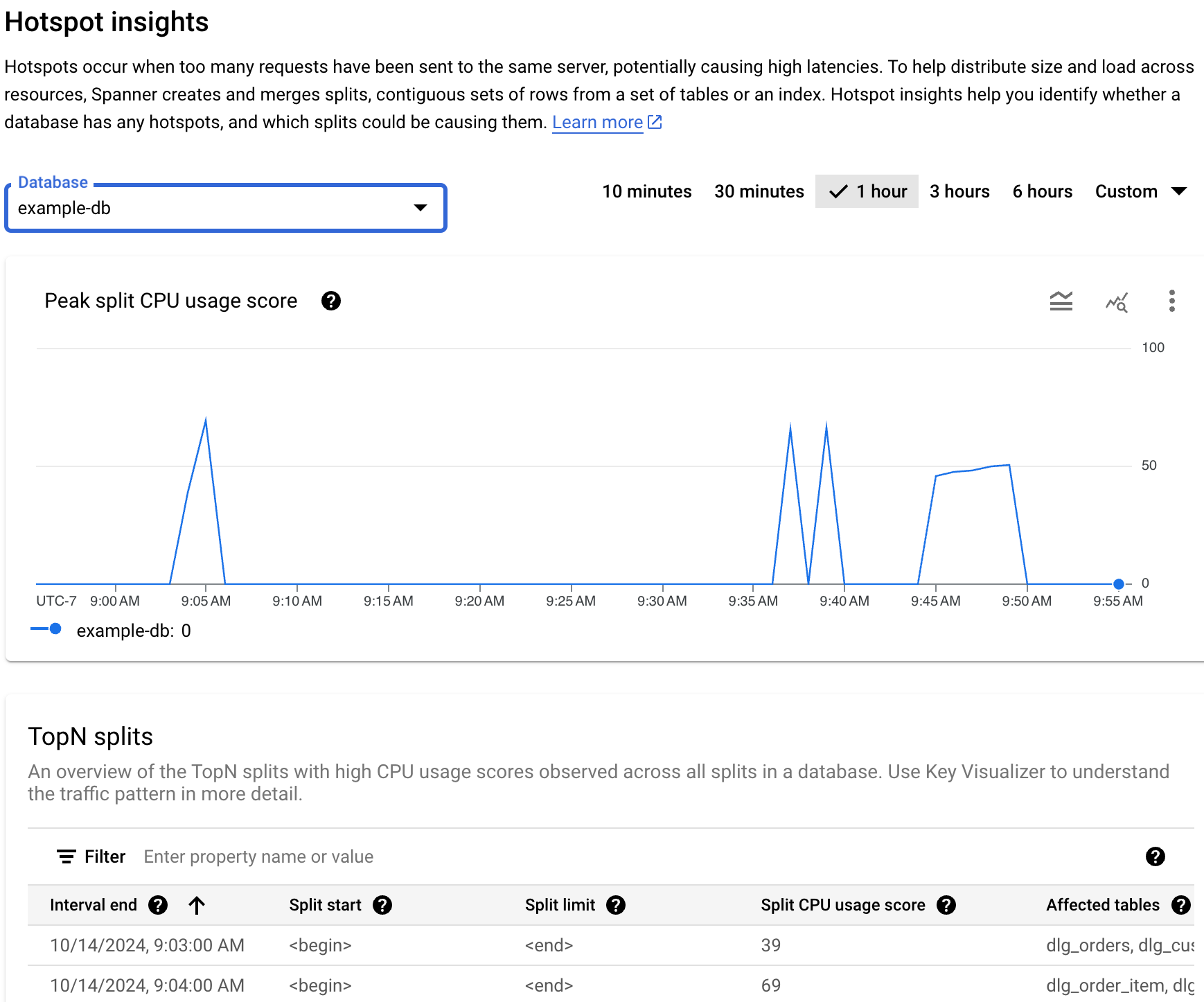
Le tableau de bord Insights sur les hotspots affiche le pourcentage maximal d'utilisation du CPU pour la division. Cette métrique est un pourcentage abstrait compris entre 0 et 100 qui reflète la quantité de CPU utilisée lorsque des lignes d'une division sont consultées.
Pour afficher le tableau de bord Insights sur les hotspots d'une base de données, procédez comme suit :
Dans la Google Cloud console, ouvrez la page Spanner.
Sélectionnez une instance dans la liste.
Dans le menu de navigation, cliquez sur l'onglet Insights sur les hotspots.
Dans le champ Base de données, sélectionnez une base de données dans la liste. Le tableau de bord affiche le score maximal d'utilisation du CPU pour la division de la base de données.
Le tableau de bord comprend les éléments suivants :
- Graphique Score maximal d'utilisation du CPU pour la division : un score d'utilisation du CPU plus élevé (par exemple, proche de 100) indique que la division est active et qu'elle est très susceptible de provoquer un hotspotting sur le serveur par rapport à des scores plus faibles.
- Champ "Base de données" : filtre les informations sur les divisions actives pour une base de données spécifique ou pour toutes les bases de données.
- Filtre "Période" : filtre l'utilisation maximale du CPU pour les divisions par incréments d'une minute jusqu'à un total de six heures.
- Tableau des N principales divisions : affiche la liste des principales divisions triées par score d'utilisation du CPU.
Comprendre les données du tableau des N principales divisions : le tableau N principales divisions remplit les données des tables SPANNER_SYS.SPLIT_STATS_TOP_* sous-jacentes en fonction de la période que vous sélectionnez. Pour
en savoir plus, consultez
Conservation des données statistiques sur les divisions actives.
Interpréter les lignes des tables 10MINUTE ou HOUR :
les lignes provenant de SPANNER_SYS.SPLIT_STATS_TOP_10MINUTE ou SPANNER_SYS.SPLIT_STATS_TOP_HOUR
représentent des données agrégées sur leurs intervalles respectifs. Comme décrit dans
Agrégation des événements de table,
le CPU_USAGE_SCORE de ces lignes est le score maximal observé dans un
sous-intervalle sous-jacent d'une minute, et UNSPLITTABLE_REASONS est une union de
motifs.
Déterminer si les hotspots nécessitent une intervention
Si vous constatez un pic ou une augmentation dans le graphique qui correspond à la latence globale et à un score maximal d'utilisation du processeur pour la division élevé et persistant, vous devrez peut-être approfondir vos recherches.
Examinez le graphique pour explorer les questions suivantes :
Quelle base de données subit la dégradation de la latence ? Sélectionnez différentes bases de données dans la liste Bases de données pour trouver celles avec la latence la plus élevée. Pour savoir quelle base de données présente la charge la plus élevée, vous pouvez également consulter le graphiqueLatence des bases de données dans la Google Cloud console.
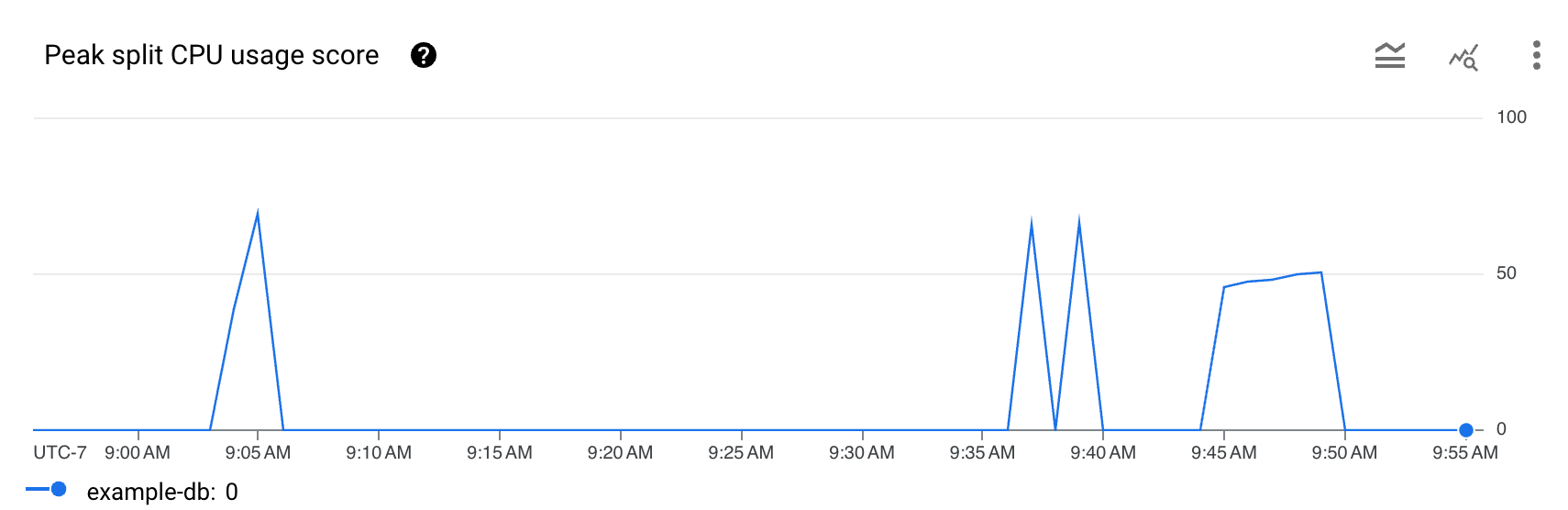
La latence est-elle élevée ? La latence est-elle élevée par rapport à la latence attendue pour la charge de travail ? Le graphique a-t-il connu un pic ou augmenté au fil du temps ? Si vous ne constatez pas de latence élevée, les hotspots ne posent pas de problème.
Le score maximal d'utilisation du CPU pour la division est-il de 100%? Le graphique a-t-il connu un pic ou augmenté au fil du temps ? Si vous ne constatez pas de pourcentage maximal d'utilisation du CPU pour la division de 100% pendant au moins 10 minutes, les hotspots ne posent peut-être pas de problème. Si le pourcentage maximal d'utilisation du CPU pour la division est élevé pendant plus de 10 minutes, vous pouvez approfondir vos recherches pour voir si la base de données présente des niveaux de latence plus élevés que prévu.
Si vous constatez des pourcentages maximaux d'utilisation du CPU pour la division de 100% pendant plus de 10 minutes, les hotspots peuvent nécessiter votre intervention. Vous pouvez ensuite poursuivre le débogage en identifiant les divisions actives dans votre base de données.
Identifier les divisions actives problématiques
Pour identifier une division potentiellement problématique comportant des hotspots, consultez la section N principales divisions de la Google Cloud console, comme illustré ci-dessous.
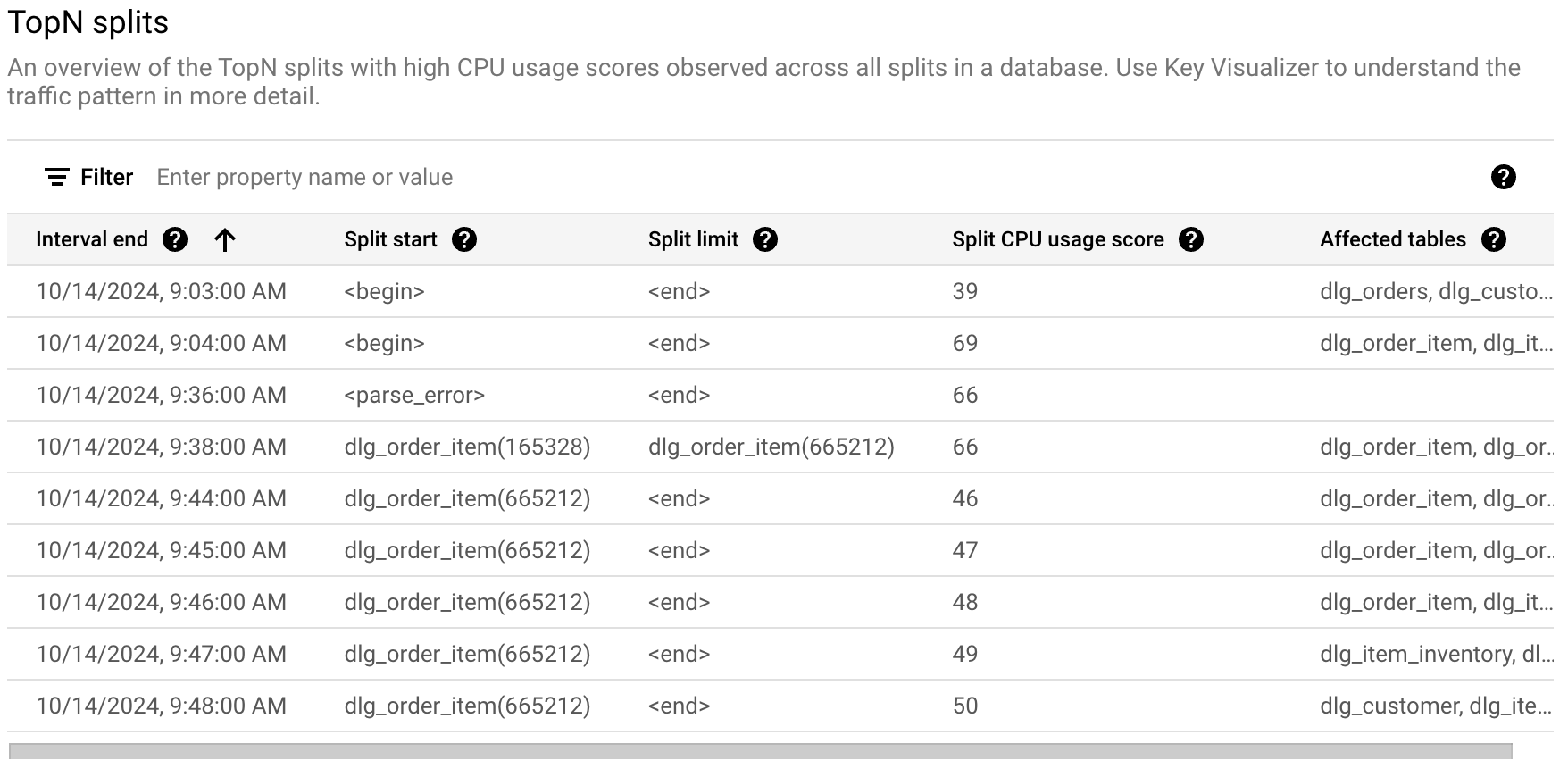
Le tableau N principales divisions fournit une vue d'ensemble des divisions qui peuvent être actives pendant la période choisie, triées de la plus récente à la plus ancienne. Le nombre de N principales divisions est limité à 100.
Pour les graphiques, Spanner récupère les données du tableau des statistiques des N principales divisions, avec une granularité d'une minute. La valeur de chaque point de données des graphiques représente la valeur moyenne sur un intervalle d'une minute.
Le tableau affiche les propriétés suivantes :
- Fin de l'intervalle : date et heure de fin de l'utilisation maximale du CPU.
- Début de la division : clé de début de la plage de lignes dans la division. Si le début de la division est <begin>, cela indique le début de la plage de clés de la base de données.
- Limite de division : clé de limite de la plage de lignes dans la division. Si la clé de limite est <end>, cela indique la fin de la plage de clés de la base de données.
- Score d'utilisation du CPU pour la division : score abstrait compris entre 0 et 100 qui reflète la quantité de CPU utilisée par les accès aux lignes dans la division sur un seul serveur. Utilisez le score d'utilisation du CPU pour évaluer la présence de hotspotting.
- Tables concernées : tables dont les lignes peuvent se trouver dans la division.
- Motifs de non-fractionnement : tableau de motifs pour lesquels Spanner
ne peut pas fractionner davantage une division active. La présence de valeurs ici indique que le fractionnement basé sur la charge ne peut pas atténuer le hotspot pour les motifs listés. Pour en savoir plus, consultez
UNSPLITTABLE_REASONStypes.
Analyser les motifs de non-fractionnement
Le tableau N principales divisions vous permet d'examiner en détail les divisions spécifiques qui sont affectées par ces motifs à des moments précis, comme indiqué dans la colonne Motifs de non-fractionnement.
Exemple de workflow de diagnostic
Voici un workflow type pour déboguer les hotspots à l'aide du tableau de bord :
- Observer le problème de performances : remarquez une latence ou des erreurs accrues dans votre application.
- Ouvrir Insights sur les hotspots : accédez au tableau de bord Insights sur les hotspots dans la Google Cloud console pour la base de données Spanner concernée. Sélectionnez la période correspondant au problème.
- Examiner le graphique
- Vérifiez que le graphique Score maximal d'utilisation du CPU pour la division présente des valeurs élevées et soutenues, par exemple > 50%, en particulier si elles approchent 100% pendant au moins 10 minutes.
- Identifier les divisions concernées et corréler les résultats : si l'utilisation du CPU est élevée, accédez au tableau N principales divisions. Filtrez ou triez pour trouver les divisions avec le Score d'utilisation du CPU pour la division le plus élevé pendant la période d'impact. Examinez la colonne
UNSPLITTABLE_REASONSpour ces principales divisions :- Score d'utilisation du CPU pour la division élevé et motifs de non-fractionnement : il s'agit d'un signal fort indiquant que le problème de performances est lié à des hotspots que Spanner ne peut pas résoudre automatiquement. Le type de motif, tel que
HOT_ROWouMOVING_HOT_SPOT, fournit un indice essentiel. - Score d'utilisation du CPU pour la division élevé et aucun motif de non-fractionnement : le hotspot est peut-être nouveau et Spanner est peut-être encore en train de le fractionner. Le problème peut également répondre aux modifications de la charge de travail, ce qui ne nécessite aucune action de votre part.
- Score d'utilisation du CPU pour la division élevé et motifs de non-fractionnement : il s'agit d'un signal fort indiquant que le problème de performances est lié à des hotspots que Spanner ne peut pas résoudre automatiquement. Le type de motif, tel que
- Comprendre les motifs : notez les codes spécifiques dans le tableau
UNSPLITTABLE_REASONS. - Atténuer : en fonction des motifs identifiés, consultez
UNSPLITTABLE_REASONStypes pour obtenir des explications détaillées et des stratégies d’atténuation recommandées, qui impliquent généralement des modifications de la conception du schéma ou des ajustements de la charge de travail.