
In diesem Dokument wird beschrieben, wie Sie mit dem Dashboard „Hotspot-Statistiken“ Hotspots in Ihrer Cloud Spanner-Datenbank erkennen.
Übersicht über Hotspot-Statistiken
Hotspots verursachen Latenz in Ihrer Cloud Spanner-Datenbank. Mit dem Dashboard „Hotspot-Statistiken“ können Sie die Splits erkennen, die von Hotspots betroffen sind. Führen Sie die folgenden Schritte aus, um zu ermitteln, ob Hotspots Latenz verursachen und wie Sie das Problem beheben können:
- Öffnen Sie das Dashboard.
- Ermitteln Sie, ob Hotspots Ihr Eingreifen erfordern.
- Identifizieren Sie problematische Hot-Splits.
Hotspot-Statistiken sind in Konfigurationen mit einer, mehreren und zwei Regionen verfügbar.
Preise
Für Hotspot-Statistiken fallen keine zusätzlichen Kosten an.
Datenaufbewahrung
Die Richtlinien zur Datenaufbewahrung für die Diagramme „Hotspot-Statistiken“ und die Tabelle „TopN-Splits“ basieren auf den zugrunde liegenden SPANNER_SYS.SPLIT_STATS_TOP_*-Tabellen. Spezifische Richtlinien zur Datenaufbewahrung finden Sie unter
Datenaufbewahrung für Statistiken zu Hot-Splits.
Erforderliche Rollen
Je nachdem, ob Sie ein IAM-Nutzer oder ein Nutzer mit detaillierter Zugriffssteuerung sind, benötigen Sie möglicherweise unterschiedliche IAM-Rollen und ‑Berechtigungen.
IAM-Nutzer
Bitten Sie Ihren Administrator, Ihnen die folgenden IAM-Rollen für die Instanz zu gewähren, um die Berechtigungen zu erhalten, die Sie zum Aufrufen der Hotspot-Statistiken Seite benötigen:
-
Alle:
- Cloud Spanner-Betrachter (
roles/spanner.viewer) - Cloud Spanner-Datenbank-Leser (
roles/spanner.databaseReader)
- Cloud Spanner-Betrachter (
Die folgenden Berechtigungen in der Rolle „Cloud Spanner-Datenbank-Leser“ (
roles/spanner.databaseReader) sind erforderlich, um die Seite „Hotspot-Statistiken“ aufzurufen:
spanner.databases.beginReadOnlyTransactionspanner.databases.selectspanner.sessions.create
Nutzer mit detaillierter Zugriffssteuerung
Wenn Sie ein Nutzer mit detaillierter Zugriffssteuerung sind, müssen Sie Folgendes tun:
- Sie müssen die Rolle „Cloud Spanner-Betrachter“
(
roles/spanner.viewer) haben. - Sie müssen Berechtigungen für die detaillierte Zugriffssteuerung haben und die Systemrolle
spanner_sys_readeroder eine ihrer Mitgliedsrollen muss Ihnen zugewiesen sein. - Wählen Sie auf der Seite Übersicht der Datenbank die Rolle
spanner_sys_readeroder eine Mitgliedsrolle als aktuelle Systemrolle aus.
Weitere Informationen finden Sie unter Übersicht über die detaillierte Zugriffssteuerung und Systemrollen für die detaillierte Zugriffssteuerung.
Dashboard „Hotspot-Statistiken“ öffnen
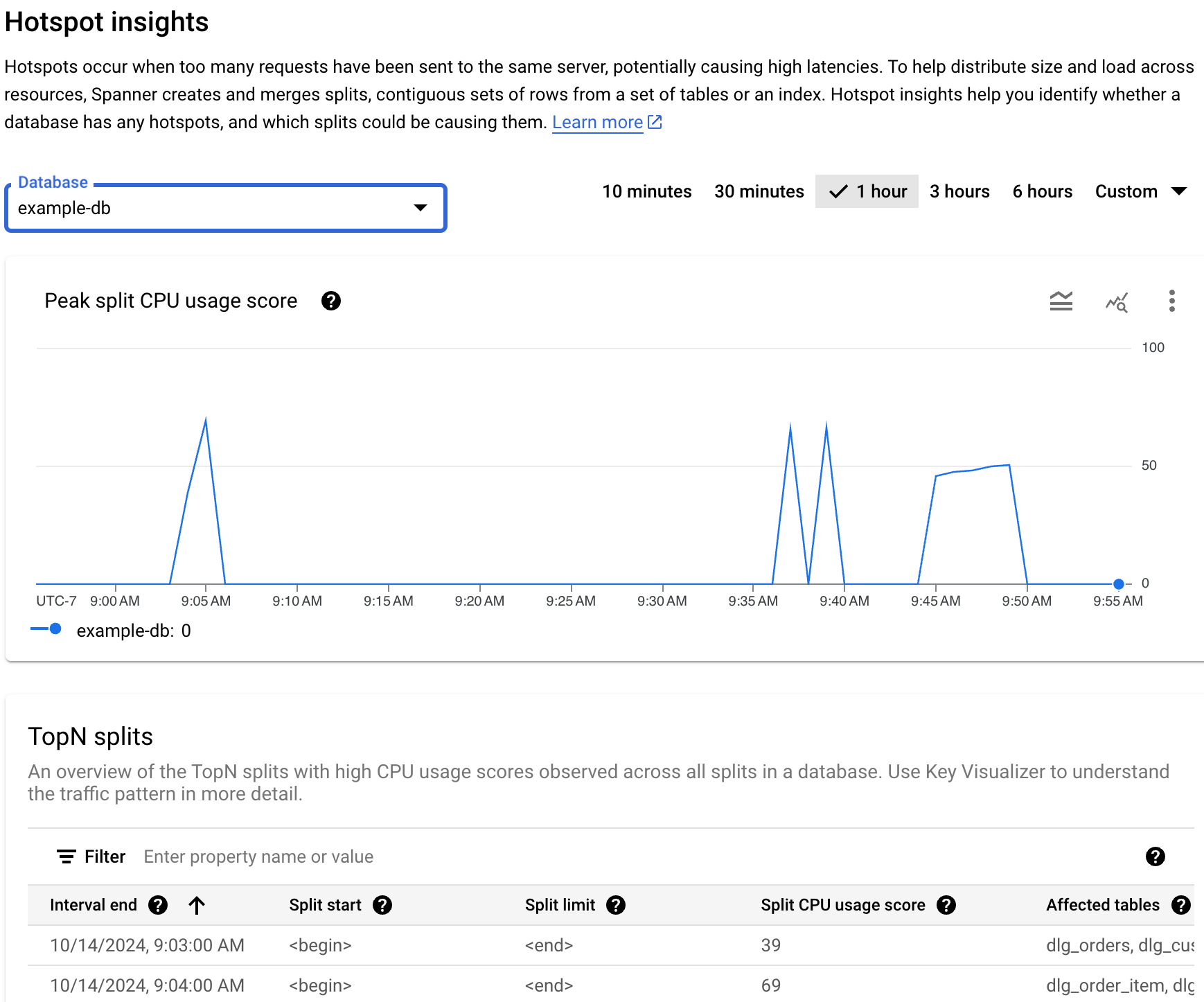
Das Dashboard Hotspot-Statistiken zeigt den prozentualen CPU-Nutzungswert des Spitzen-Splits. Dieser Messwert ist ein abstrakter Prozentsatz zwischen 0 und 100, der die Menge der CPU-Nutzung widerspiegelt, wenn auf Zeilen in einem Split zugegriffen wird.
So rufen Sie das Dashboard Hotspot-Statistiken für eine Datenbank auf:
Öffnen Sie in der Google Cloud Console die Seite Spanner.
Wählen Sie eine Instanz aus der Liste aus.
Klicken Sie im Navigationsmenü auf den Tab Hotspot-Statistiken.
Wählen Sie im Feld Datenbank eine Datenbank aus der Liste aus. Im Dashboard wird der CPU-Nutzungswert des Spitzen-Splits für die Datenbank angezeigt.
Das Dashboard enthält die folgenden Elemente:
- Diagramm CPU-Nutzungswert des Spitzen-Splits: Ein höherer CPU-Nutzungswert (z. B. nahe 100) weist darauf hin, dass der Split stark genutzt wird und sehr wahrscheinlich ein Heißlaufen auf dem Server verursacht, verglichen mit niedrigeren Werten.
- Datenbankfeld: Filtert die Informationen zu Hot-Splits für eine bestimmte Datenbank oder für alle Datenbanken.
- Zeitraumfilter: Filtert die CPU-Nutzung der Spitzen-Splits in Schritten von 1 Minute bis zu insgesamt 6 Stunden.
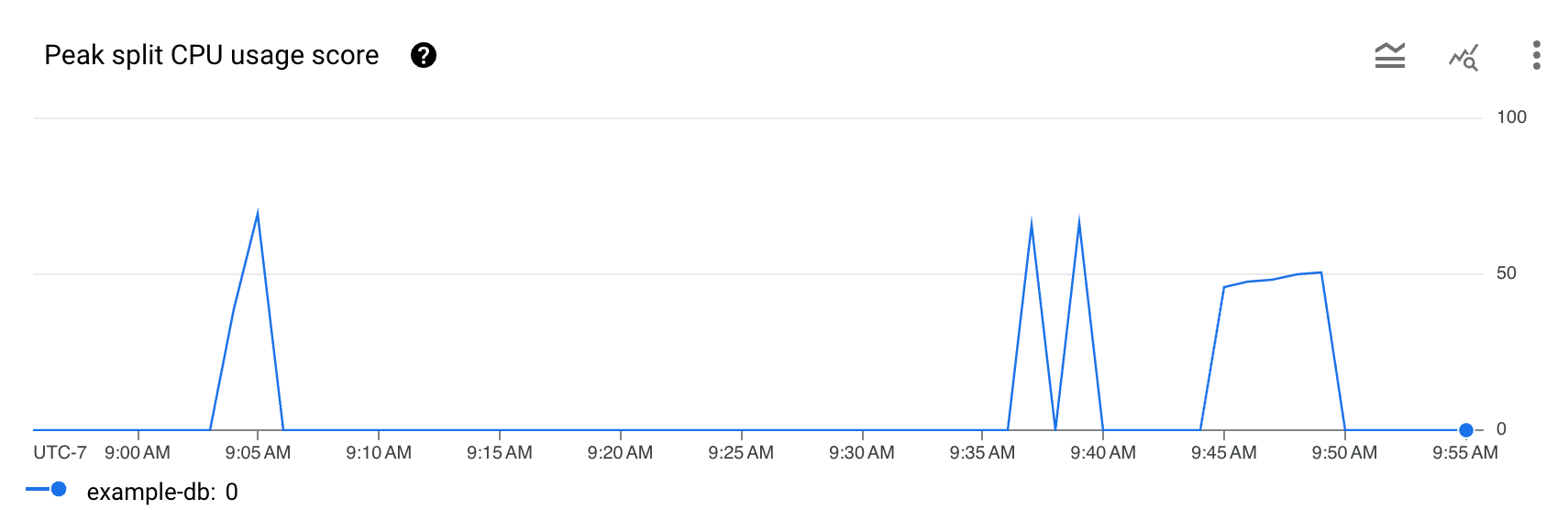
- Tabelle der TopN-Splits: Zeigt die Liste der Top-Splits sortiert nach CPU Nutzungswerten der Splits an.
Daten in der Tabelle der TopN-Splits verstehen:Die Tabelle TopN-Splits wird mit Daten aus den zugrunde liegenden SPANNER_SYS.SPLIT_STATS_TOP_*-Tabellen basierend auf dem von Ihnen ausgewählten Zeitraum gefüllt. Weitere
Informationen finden Sie unter
Datenaufbewahrung für Statistiken zu Hot-Splits.
Zeilen aus 10MINUTE oder HOUR-Tabellen interpretieren:
Zeilen aus SPANNER_SYS.SPLIT_STATS_TOP_10MINUTE oder SPANNER_SYS.SPLIT_STATS_TOP_HOUR
stellen aggregierte Daten über die jeweiligen Intervalle dar. Wie unter
Tabellenereignisaggregation,
beschrieben, ist der CPU_USAGE_SCORE in diesen Zeilen der maximale Wert, der in einem zug101}rundeliegenden 1-Minuten-Unterintervall beobachtet wurde, und UNSPLITTABLE_REASONS ist eine Vereinigung von
Gründen.
Ermitteln, ob Hotspots ein Eingreifen erfordern
Wenn Sie im Diagramm einen Anstieg oder eine Erhöhung sehen, die der Gesamtlatenz entspricht, und einen dauerhaft hohen CPU-Nutzungswert des Spitzen-Splits, müssen Sie möglicherweise weitere Untersuchungen durchführen.
Sehen Sie sich das Diagramm an und untersuchen Sie die folgenden Fragen:
In welcher Datenbank tritt die Latenzverschlechterung auf? Wählen Sie in der Liste Datenbanken verschiedene Datenbanken aus, um die Datenbanken mit der höchsten Latenz zu finden. Um herauszufinden, welche Datenbank die höchste Last hat, können Sie auch das Diagramm Latenzfür Datenbanken in der Google Cloud Console ansehen.
Ist die Latenz hoch? Ist die Latenz im Vergleich zur erwarteten Latenz für die Arbeitslast hoch? Ist eine Spitze oder ein Anstieg im Zeitverlauf zu sehen? Wenn keine hohe Latenz angezeigt wird, sind Hotspots kein Problem.
Beträgt der hohe CPU-Nutzungswert des Spitzen-Splits 100%? Ist eine Spitze oder ein Anstieg im Zeitverlauf zu sehen? Wenn Sie mindestens 10 Minuten lang keine dauerhaften CPU-Nutzungswerte des Spitzen-Splits von 100% sehen, sind Hotspots möglicherweise kein Problem. Wenn der CPU-Nutzungswert des Spitzen-Splits länger als 10 Minuten hoch ist, sollten Sie weitere Untersuchungen durchführen, um festzustellen, ob die Datenbank höhere als erwartete Latenzwerte aufweist.
Wenn Sie länger als 10 Minuten lang CPU-Nutzungswerte des Spitzen-Splits von 100% sehen, müssen Sie möglicherweise eingreifen. Als Nächstes können Sie mit der Fehlersuche fortfahren, indem Sie die Hot-Splits in Ihrer Datenbank identifizieren.
Problematische Hot-Splits identifizieren
Um einen potenziell problematischen Split mit Hotspots zu identifizieren, sehen Sie sich den TopN Splits Abschnitt in der Google Cloud Console an, wie unten dargestellt.
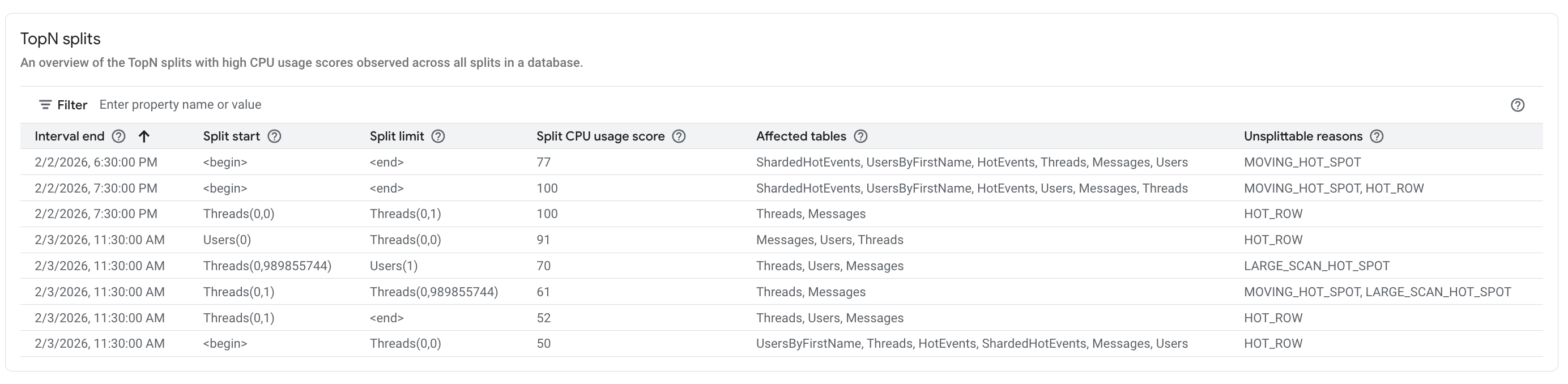
Die Tabelle TopN-Splits bietet eine Übersicht über die Splits, die im ausgewählten Zeitraum möglicherweise stark genutzt wurden, sortiert vom neuesten zum ältesten. Die Anzahl der TopN-Splits ist auf 100 begrenzt.
Für die Diagramme ruft Spanner Daten aus der Tabelle „TopN-Splits-Statistiken“ mit einer Granularität von einer Minute ab. Der Wert für jeden Datenpunkt in den Diagrammen stellt den Durchschnittswert über ein Intervall von einer Minute dar.
Die Tabelle enthält die folgenden Attribute:
- Ende des Intervalls: Datum und Uhrzeit, zu der die hohe CPU-Nutzung endet.
- Split-Start: Der Startschlüssel des Zeilenbereichs im Split. Wenn der Split-Start <begin> ist, gibt er den Beginn des Schlüsselbereichs der Datenbank an.
- Split-Limit: Der Limitschlüssel des Zeilenbereichs im Split. Wenn der Limitschlüssel <end> ist, gibt er das Ende des Schlüsselbereichs der Datenbank an.
- CPU-Nutzungswert des Splits: Ein abstrakter Wert zwischen 0 und 100, der den Anteil der CPU-Nutzung durch Zugriffe auf die Zeilen innerhalb des Splits auf einem einzelnen Server angibt. Anhand des CPU-Nutzungswerts können Sie ermitteln, ob ein Heißlaufen zu verzeichnen ist.
- Betroffene Tabellen: Die Tabellen, deren Zeilen möglicherweise im Split enthalten sind.
- Gründe für die Unteilbarkeit: Ein Array von Gründen, warum Spanner
einen Hot-Split nicht weiter unterteilen kann. Das Vorhandensein von Werten hier weist darauf hin, dass das lastbasierte Splitting den Hotspot aus den aufgeführten Gründen nicht entschärfen kann. Weitere Informationen finden Sie unter
UNSPLITTABLE_REASONSTypen.
Gründe für die Unteilbarkeit analysieren
In der Tabelle TopN-Splits können Sie genauer untersuchen, welche spezifischen Splits zu bestimmten Zeiten von diesen Gründen betroffen sind. Diese Informationen finden Sie in der Spalte Gründe für die Unteilbarkeit.
Beispielhafter Diagnoseworkflow
Hier ist ein typischer Workflow für die Fehlersuche bei Hotspots mit dem Dashboard:
- Leistungsproblem beobachten:Sie bemerken eine erhöhte Latenz oder Fehler in Ihrer Anwendung.
- Hotspot-Statistiken öffnen: Rufen Sie in derConsole das Dashboard „Hotspot-Statistiken“ für die entsprechende Cloud Spanner-Datenbank Google Cloud auf. Wählen Sie den Zeitraum aus, der dem Problem entspricht.
- Diagramm untersuchen:
- Prüfen Sie im Diagramm CPU-Nutzungswert des Spitzen-Splits auf dauerhaft hohe Werte, z. B. > 50%, insbesondere Werte nahe 100 %, die mindestens 10 Minuten lang anhalten.
- Betroffene Splits identifizieren und Ergebnisse korrelieren:Wenn die CPU-Nutzung hoch ist, rufen Sie die Tabelle TopN-Splits auf. Filtern oder sortieren Sie, um die Splits mit dem höchsten CPU-Nutzungswert des Splits während des Zeitraums des Problems zu finden. Untersuchen Sie die Spalte
UNSPLITTABLE_REASONSfür diese Top-Splits:- Hoher CPU-Nutzungswert des Splits und Gründe für die Unteilbarkeit:Dies ist ein starkes Signal dafür, dass das Leistungsproblem mit Hotspots zusammenhängt, die Spanner nicht automatisch beheben kann. Der Grundtyp, z. B.
HOT_ROWoderMOVING_HOT_SPOT, liefert einen wichtigen Hinweis. - Hoher CPU-Nutzungswert des Splits und keine Gründe für die Unteilbarkeit:Der Hotspot ist möglicherweise neu und Spanner ist möglicherweise noch mit dem Splitting beschäftigt. Alternativ kann das Problem auf Änderungen der Arbeitslast reagieren, sodass keine Maßnahmen von Ihnen erforderlich sind.
- Hoher CPU-Nutzungswert des Splits und Gründe für die Unteilbarkeit:Dies ist ein starkes Signal dafür, dass das Leistungsproblem mit Hotspots zusammenhängt, die Spanner nicht automatisch beheben kann. Der Grundtyp, z. B.
- Gründe verstehen:Notieren Sie sich die spezifischen Codes im Array
UNSPLITTABLE_REASONS. - Entschärfen: Informationen zu den identifizierten Gründen finden Sie unter
UNSPLITTABLE_REASONSTypen Dort finden Sie detaillierte Erläuterungen und empfohlene Entschärfungsstrategien, die in der Regel Änderungen am Schemadesign oder Anpassungen der Arbeitslast umfassen.
Nächste Schritte
- Informationen zu Statistiken zu Split-Hotspots