
בדף הזה מוסבר איך להוסיף ולערוך סוגי מידע בהגדרות הבדיקה באמצעות מסוף Google Cloud .
כשמשתמשים ב-Sensitive Data Protection כדי לבדוק או ליצור פרופיל של נתונים, משתמשים בהגדרת בדיקה כדי לציין את סוגי המידע (infoTypes) שרוצים לסרוק. הפעולות הבאות של Sensitive Data Protection במסוףGoogle Cloud מאפשרות להגדיר את ההגדרה של הבדיקה:
בפעולות האלה ב- Google Cloud console יש קטע InfoTypes, שבו אפשר לבחור סוגי מידע, לערוך את ההגדרות של סוגי מידע מובנים ולהוסיף סוגי מידע בהתאמה אישית. השלב שמכיל את הקטע InfoTypes משתנה בהתאם לפעולה שמבצעים. בטבלה הבאה מוצג השלב הרלוונטי בתהליך העבודה לכל פעולה.
| פעולה | שלב רלוונטי |
|---|---|
| יצירת תבנית בדיקה | הגדרת זיהוי |
| יצירת משימת בדיקה או הפעלת משימה | הגדרת זיהוי |
| יצירת הגדרות לסריקת גילוי | בחירת תבנית בדיקה |
בחירת סוגי מידע מובנים
- בקטע InfoTypes, לוחצים על Manage infoTypes.
כדי לצמצם את הבחירה של סוגי המידע, משתמשים במסננים בשדה Filter. בוחרים שם של נכס לסינון ומזינים ערך של נכס. לדוגמה, כדי לסנן את כל סוגי המידע שקשורים לאוסטרליה, מגדירים את שם המאפיין ל-Location. בקטע 'ערך המאפיין', בוחרים באפשרות אוסטרליה או מקלידים אותה.
אם אתם יודעים את השם של סוג המידע, אתם יכולים גם להקליד אותו ישירות בשדה מסנן.
כדי לראות את כל תגי הקטגוריות של סוג מידע, לוחצים על החלפת התצוגה של התוכן המלא של התא בשורה של סוג המידע הרלוונטי.
כדי להסתיר או לבטל את ההסתרה של עמודות, לוחצים על Column display options ובוחרים את שמות העמודות שרוצים להציג.
בוחרים את סוגי המידע שרוצים לכלול בהגדרת הבדיקה.
כדי להשתמש בסוגי מידע עם זמינות מוגבלת בהגדרה, בוחרים באפשרות Allow limited-availability infoTypes (התרת סוגי מידע עם זמינות מוגבלת). סוגי המידע האלה נתמכים רק באזורים ספציפיים. שימוש בהם במקומות אחרים עלול לגרום לשגיאות בסריקה.
לוחצים על סיום.
עריכת ההגדרות של סוג מידע מובנה
כשמגדירים את סוגי המידע שרוצים לכלול בהגדרת הבדיקה, אפשר גם לערוך את ההגדרות של סוג מידע אחד או יותר. אפשר לערוך את רמת הרגישות, ובמקרה של חלק מסוגי המידע, את הגרסה של סוג המידע.
- בוחרים את סוגי המידע המובנים שרוצים לכלול בהגדרת הבדיקה, כולל סוגי המידע שלא צריך לערוך. לא לוחצים על סיום.
לוחצים על עריכת סוגי המידע שנבחרו.
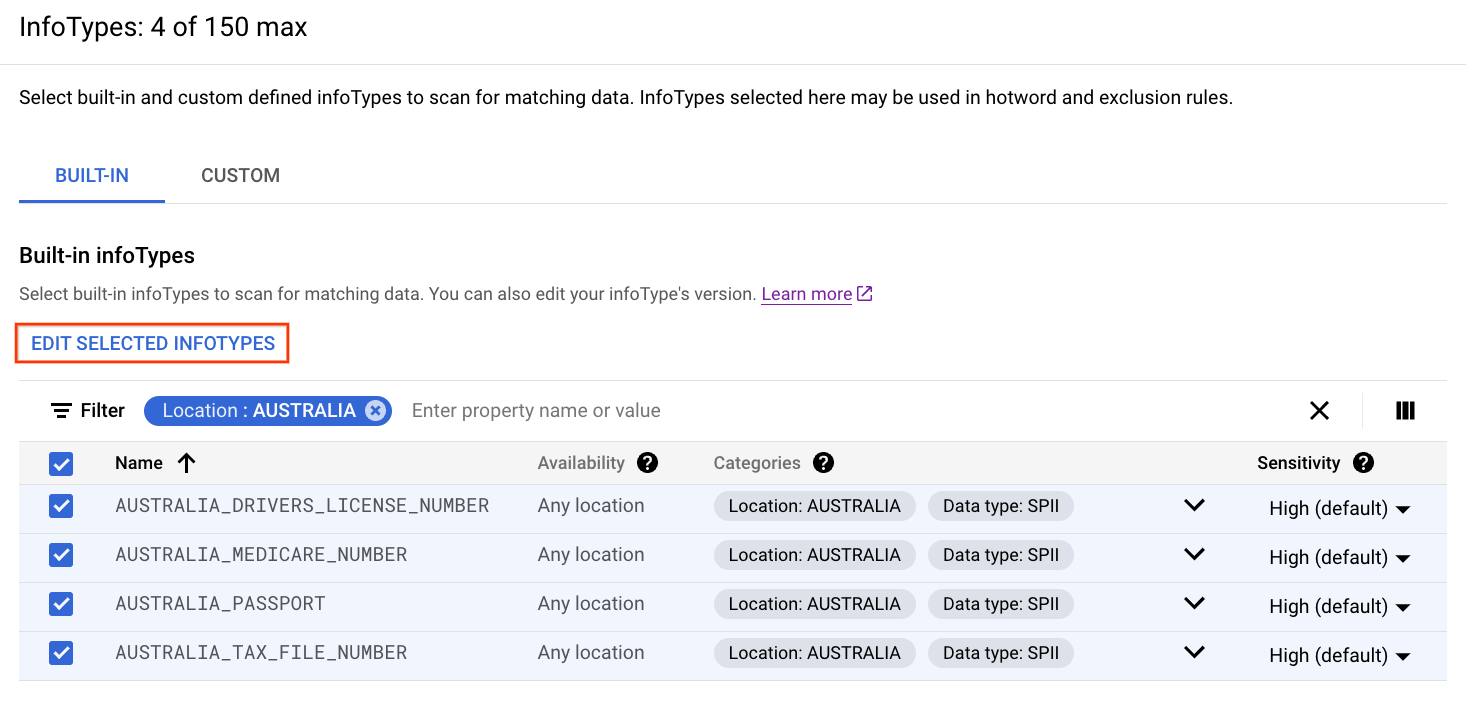
לכל infoType שרוצים לערוך, משתמשים בתפריטים הנפתחים כדי לבחור רמת רגישות או גרסת גלאי.
לוחצים על אישור.
לוחצים על סיום.
הוספת סוגי מידע מותאמים אישית
בקטע הזה מוסבר איך להוסיף infoType מותאם אישית על סמך קבוצת נתונים בסיסית. הנתונים הבסיסיים יכולים להיות כל אחד מהסוגים הבאים:
- רשימה של מילים או ביטויים שאתם מספקים בשורה בהגדרת הבדיקה.
- רשימה של מילים או ביטויים שמאוחסנים בקובץ טקסט ב-Cloud Storage.
רשימה גדולה של מילים או ביטויים שמאוחסנת בקובץ טקסט גדול ב-Cloud Storage או בעמודה ב-BigQuery.
כדי להשתמש בסוג הזה, קודם צריך ליצור סוג מידע מאוחסן שמפנה למילון הגדול המותאם אישית, ורק אז לבצע את המשימה הזו.
ביטוי רגולרי שאתם מספקים בשורה בהגדרת הבדיקה.
האפשרות להשתמש מחדש בסוג המידע המותאם אישית החדש תלויה בפעולה שביצעתם כשיצרתם את סוג המידע המותאם אישית:
אם יוצרים סוג מידע מותאם אישית בזמן יצירת משימת בדיקה או טריגר למשימה, סוג המידע המותאם אישית זמין רק למשימה או לטריגר למשימה הספציפיים.
אם יוצרים סוג מידע מותאם אישית במהלך יצירת תבנית בדיקה, סוג המידע המותאם אישית יהיה זמין לכל פעולה שמשתמשת בתבנית הבדיקה.
אם יוצרים infoType מותאם אישית במהלך הגדרת פרופילים, Sensitive Data Protection יוצר תבנית בדיקה חדשה מהגדרת הבדיקה. סוג המידע המותאם אישית זמין לכל פעולה שמשתמשת בתבנית הבדיקה החדשה.
מידע נוסף על סוגי מידע מותאמים אישית זמין במאמר גלאים של סוגי מידע מותאמים אישית.
כדי להוסיף גלאי מותאם אישית של סוג מידע:
- בקטע InfoTypes, לוחצים על Manage infoTypes.
- בכרטיסייה בהתאמה אישית, לוחצים על הוספת סוג מידע מותאם אישית.
בקטע Type, בוחרים את סוג גלאי ה-infoType המותאם אישית שרוצים ליצור:
מילים או ביטויים: התאמה למילה או לביטוי אחד או יותר שמוזנים בשדה. אפשר להזין עד 128KB של נתונים, ששווים לאלפי רשומות.
כשבוחרים בסוג הזה, מופיע השדה רשימה של מילים או ביטויים. מזינים את המילה או הביטוי שרוצים ש-Sensitive Data Protection יזהה. כדי להתאים לכמה מילים או ביטויים, לוחצים על
Enterאחרי כל ערך. מידע נוסף זמין במאמר בנושא יצירת גלאי מילון מותאם אישית רגיל.נתיב למילון: התאמות למילים או לביטויים שמאוחסנים בקובץ טקסט ב-Cloud Storage. כדאי להשתמש בסוג המידע המותאם אישית הזה אם רוצים לחפש מאות אלפי מילים או ביטויים. הגישה הזו שימושית גם אם הרשימה מכילה מונחים רגישים שאתם מעדיפים לא לאחסן בשורה בהגדרת הבדיקה.
כשבוחרים בסוג הזה, מופיע השדה Dictionary location. מזינים או מעיינים בנתיב של Cloud Storage שבו מאוחסן קובץ המילון. מידע נוסף זמין במאמר בנושא יצירת כלי רגיל לזיהוי מילונים בהתאמה אישית.
ביטוי רגולרי (regex): התאמה של תוכן על סמך ביטוי רגולרי.
כשבוחרים בסוג הזה, מופיע השדה Regex. מזינים תבנית של ביטוי רגולרי כדי להתאים מילים וביטויים. מידע נוסף זמין במאמר בנושא תחביר של ביטויים רגולריים נתמכים.
סוג מידע מאוחסן: התאמות למילים או לביטויים שמאוחסנים בקובץ טקסט גדול ב-Cloud Storage או בעמודה יחידה ב-BigQuery.
האפשרות הזו מוסיפה מזהה מותאם אישית של מילון גדול. כדאי להשתמש בסוג המידע המותאם אישית הזה אם יש לכם מיליוני מילים או ביטויים שאתם רוצים לחפש.
כדי להשתמש בסוג הזה, צריך קודם ליצור סוג מידע מאוחסן שמפנה למילון מותאם אישית גדול.
כשבוחרים בסוג הזה, מופיע השדה Stored infoType name (שם סוג המידע המאוחסן). מזינים את השם המלא של המשאב של סוג המידע המאוחסן.
ביטוי Metadata KeyValue: תואם לצמדי מפתח/ערך במטא-נתונים בקבצים.
כשבוחרים בסוג הזה, מופיעים השדות Key Pattern ו-Value Pattern. מזינים את דפוסי הביטוי הרגולרי להתאמה של המפתח והערך של המטא-נתונים לזיהוי. מידע נוסף זמין במאמר בנושא יצירת כלי מותאם אישית לזיהוי תוויות של מטא-נתונים.
בשדה InfoType, מזינים שם לסוג המידע המותאם אישית שרוצים ליצור.
אם אתם יוצרים סוג מידע מותאם אישית מסוג Stored infoType (סוג מידע מאוחסן), צריך להזין שם ששונה מהשם של סוג המידע המאוחסן הבסיסי.
בקטע סבירות, בוחרים את רמת הסבירות שרוצים להקצות כברירת מחדל לכל הממצאים שתואמים לסוג המידע המותאם אישית הזה. אפשר לכוונן עוד יותר את רמת הסבירות של ממצאים ספציפיים באמצעות כללי מילות הפעלה. אם לא מציינים ערך ברירת מחדל, רמת הסבירות שמוגדרת כברירת מחדל היא
VERY_LIKELY. מידע נוסף מופיע במאמר בנושא הסתברות להתאמה.בקטע רגישות, בוחרים את רמת הרגישות שרוצים להקצות לכל הממצאים שתואמים לסוג המידע המותאם אישית הזה. אם לא מציינים ערך, רמות הרגישות של הממצאים האלה מוגדרות כ-
HIGH.ציוני הרגישות משמשים בפרופילים של נתונים. כשמבצעים פרופיל לנתונים, Sensitive Data Protection משתמש בציוני הרגישות של ה-infoTypes כדי לחשב את רמת הרגישות.
לוחצים על סיום.
אופציונלי: כדי להוסיף עוד סוג מידע מותאם אישית, לוחצים שוב על הוספת סוג מידע מותאם אישית.
לוחצים על סיום.
המאמרים הבאים
- אפשר לעיין ברשימה של גלאי Infotype מובנים.
- מידע נוסף על גלאי סוגי מידע בהתאמה אישית
- איך יוצרים מזהה מילון מותאם אישית רגיל באמצעות DLP API
- איך יוצרים מזהה מילון מותאם אישית גדול באמצעות DLP API
- כך יוצרים גלאי ביטוי רגולרי בהתאמה אישית באמצעות DLP API.