
בדף הזה מתוארים שני שירותים של Sensitive Data Protection שמאפשרים להבין את הנתונים שלכם ומסייעים לכם ליצור תהליכי עבודה למשילות מידע: שירות הגילוי ושירות הבדיקה.
מיון מידע אישי רגיש
שירות הגילוי עוקב אחרי הנתונים בארגון. השירות הזה פועל באופן רציף ומגלה, מסווג ויוצר פרופילים של נתונים באופן אוטומטי. התכונה 'גילוי נתונים' יכולה לעזור לכם להבין את המיקום והאופי של הנתונים שאתם מאחסנים, כולל משאבי נתונים שאולי לא ידועים לכם. נתונים לא ידועים (לפעמים נקראים נתוני צל) בדרך כלל לא עוברים את אותה רמה של משילות מידע וניהול סיכונים כמו נתונים ידועים.
אפשר להגדיר את האיתור בהיקפים שונים. אתם יכולים להגדיר לוחות זמנים שונים ליצירת פרופילים עבור קבוצות משנה שונות של הנתונים. אפשר גם להחריג קבוצות משנה של נתונים שלא צריך ליצור להם פרופיל.
פלט של סריקת גילוי: פרופילי נתונים
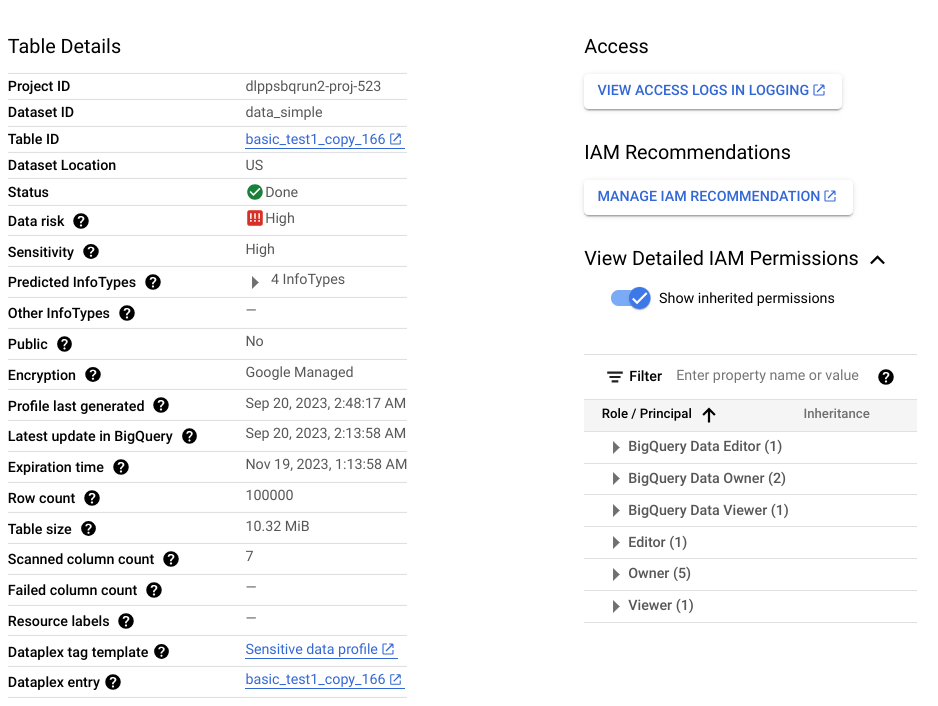
הפלט של סריקת גילוי הוא קבוצה של פרופילי נתונים לכל משאב נתונים בהיקף. לדוגמה, סריקת גילוי של נתונים ב-BigQuery או ב-Cloud SQL יוצרת פרופילי נתונים ברמת הפרויקט, הטבלה והעמודה.
פרופיל נתונים מכיל מדדים ותובנות לגבי המשאב שנוצר לו פרופיל. הוא כולל את סיווגי הנתונים (או סוגי המידע), רמות הרגישות, רמות הסיכון של הנתונים, גודל הנתונים, צורת הנתונים ורכיבים אחרים שמתארים את אופי הנתונים ומצב אבטחת הנתונים (עד כמה הנתונים מאובטחים). אתם יכולים להשתמש בפרופילי נתונים כדי לקבל החלטות מושכלות לגבי אופן ההגנה על הנתונים שלכם – למשל, על ידי הגדרת מדיניות גישה לטבלה.
נניח שיש עמודה ב-BigQuery בשם ccn, שכל שורה בה מכילה מספר כרטיס אשראי ייחודי ואין בה ערכים מסוג null. פרופיל הנתונים שנוצר ברמת העמודה יכלול את הפרטים הבאים:
| השם המוצג | ערך |
|---|---|
Field ID |
ccn |
Data risk |
High |
Sensitivity |
High |
Data type |
TYPE_STRING |
Policy tags |
No |
Free text score |
0 |
Estimated uniqueness |
High |
Estimated null proportion |
Very low |
Last profile generated |
DATE_TIME |
Predicted infoType |
CREDIT_CARD_NUMBER |
בנוסף, הפרופיל ברמת העמודה הוא חלק מפרופיל ברמת הטבלה, שכולל תובנות כמו מיקום הנתונים, סטטוס ההצפנה והאם הטבלה משותפת עם הציבור. במסוף Google Cloud , אפשר גם לראות את הרשומות של Cloud Logging עבור הטבלה, ואת ישויות ה-IAM עם תפקידים בטבלה.
רשימה מלאה של המדדים והתובנות שזמינים בפרופילי נתונים מופיעה במאמר הפניה למדדים.
מתי כדאי להשתמש באיתור
כשמתכננים את הגישה לניהול סיכוני הנתונים, מומלץ להתחיל עם גילוי. שירות הגילוי עוזר לכם לקבל תמונה רחבה של הנתונים שלכם ומאפשר לכם להגדיר התראות, דוחות ופתרון של בעיות.
בנוסף, שירות הגילוי יכול לעזור לכם לזהות את המשאבים שבהם יכולים להיות נתונים לא מובנים. יכול להיות שמשאבים כאלה מצדיקים בדיקה מקיפה. נתונים לא מובנים מצוינים על ידי ציון גבוה של טקסט חופשי בסולם של 0 עד 1.
בדיקה של מידע אישי רגיש
שירות הבדיקה מבצע סריקה מקיפה של משאב יחיד כדי לאתר כל מופע בודד של מידע אישי רגיש. בבדיקה נוצרת ממצא לכל מופע שזוהה.
משימות בדיקה מספקות מגוון רחב של אפשרויות הגדרה שיעזרו לכם לאתר את הנתונים שאתם רוצים לבדוק. לדוגמה, אתם יכולים להפעיל דגימה כדי להגביל את הנתונים שייבדקו למספר מסוים של שורות (לנתוני BigQuery) או לסוגים מסוימים של קבצים (לנתוני Cloud Storage). אפשר גם לטרגט טווח זמן ספציפי שבו הנתונים נוצרו או שונו.
בניגוד לגילוי, שבו המערכת עוקבת אחרי הנתונים שלכם באופן רציף, בדיקה היא פעולה שמתבצעת לפי דרישה. עם זאת, אתם יכולים לתזמן עבודות בדיקה חוזרות שנקראות טריגרים של עבודות.
פלט של סריקת בדיקה: ממצאים
כל ממצא כולל פרטים כמו המיקום של המופע שזוהה, סוג המידע הפוטנציאלי שלו ורמת הוודאות (שנקראת גם סבירות) שהממצא תואם לסוג המידע. בהתאם להגדרות, אפשר גם לקבל את המחרוזת בפועל שהממצא מתייחס אליה. המחרוזת הזו נקראת ציטוט ב-Sensitive Data Protection.
רשימה מלאה של הפרטים שכלולים בממצא של בדיקה זמינה במאמר Finding.
מתי כדאי להשתמש בכלי הבדיקה
הבדיקה שימושית כשצריך לבדוק נתונים לא מובְנים (כמו תגובות או ביקורות שמשתמשים כתבו) ולזהות כל מופע של פרטים אישיים מזהים (PII). אם סריקת הגילוי מזהה משאבים שמכילים נתונים לא מובנים, מומלץ להריץ סריקת בדיקה במשאבים האלה כדי לקבל פרטים על כל ממצא בנפרד.
מתי לא כדאי להשתמש בבדיקה
בדיקת משאב לא תועיל אם מתקיימים שני התנאים הבאים: סריקת גילוי יכולה לעזור לכם להחליט אם נדרשת סריקת בדיקה.
- במשאב יש רק נתונים מובְנים. כלומר, אין עמודות של נתונים חופשיים, כמו תגובות או ביקורות של משתמשים.
- אתם כבר יודעים אילו סוגי מידע מאוחסנים במשאב הזה.
לדוגמה, נניח שפרופילי נתונים מסריקת גילוי מציינים שלטבלה מסוימת ב-BigQuery אין עמודות עם נתונים לא מובנים, אבל יש לה עמודה של מספרים ייחודיים של כרטיסי אשראי. במקרה כזה, בדיקה של מספרי כרטיסי אשראי בטבלה לא תועיל. בבדיקה יתקבלו ממצאים לכל פריט בעמודה. אם יש לכם מיליון שורות וכל שורה מכילה מספר כרטיס אשראי אחד, עבודת בדיקה תפיק מיליון ממצאים עבור CREDIT_CARD_NUMBER infoType. בדוגמה הזו, אין צורך בבדיקה כי הסריקה לגילוי כבר מציינת שהעמודה מכילה מספרים ייחודיים של כרטיסי אשראי.
מיקום הנתונים, העיבוד והאחסון שלהם
גם גילוי וגם בדיקה תומכים בדרישות של שמירת נתונים במדינה מסוימת:
- שירות הגילוי מעבד את הנתונים שלכם במקום שבו הם נמצאים, ומאחסן את פרופילי הנתונים שנוצרו באותו אזור או באותו מרחב רב-אזורי שבו נמצאים הנתונים שנוצרו מהם הפרופילים. מידע נוסף מופיע במאמר שיקולים לגבי מיקום הנתונים.
- כשבודקים נתונים ב Google Cloud מערכת אחסון, שירות הבדיקה מעבד את הנתונים באותו אזור שבו הנתונים נמצאים, ומאחסן את עבודת הבדיקה באותו אזור. כשבודקים נתונים באמצעות עבודה היברידית או באמצעות שיטה
content, שירות הבדיקה מאפשר לציין איפה הוא צריך לעבד את הנתונים. מידע נוסף מופיע במאמר איך הנתונים מאוחסנים.
סיכום השוואה: שירותי גילוי ובדיקה
| Discovery | בדיקה | |
|---|---|---|
| יתרונות |
|
|
| עלות |
עלות של 10TB היא בערך 300$לחודש במצב צריכה. |
העלות של סריקת 10TB היא בערך 10,000 דולר ארה"ב לכל סריקה. |
| מקורות נתונים נתמכים | BigLake BigQuery משתני סביבה של פונקציות Cloud Run משתני סביבה של עדכון שירות Cloud Run Cloud SQL Cloud Storage Vertex AI Amazon S3 Azure Blob Storage |
BigQuery Cloud Storage Datastore היברידי (כל מקור)1 |
| היקפים נתמכים |
|
טבלה אחת ב-BigQuery, קטגוריה אחת ב-Cloud Storage או סוג אחד ב-Datastore. |
| תבניות בדיקה מובנות | כן | כן |
| infoType מובנה ו-infoType מותאם אישית | כן | כן |
| פלט הסריקה | סקירה כללית (פרופילי נתונים) של כל הנתונים הנתמכים. | ממצאים קונקרטיים של מידע אישי רגיש במשאב שנבדק. |
| שמירת התוצאות ב-BigQuery | כן | כן |
| שליחה אל Knowledge Catalog כתגים (הוצא משימוש) | כן | כן |
| שליחה אל Knowledge Catalog כהיבטים | כן | לא |
| פרסום תוצאות ב-Security Command Center | כן | כן |
| פרסום הממצאים ב-Google Security Operations | כן לגילוי ברמת הארגון וברמת התיקייה | לא |
| פרסום ב-Pub/Sub | כן | כן |
| תמיכה במיקום הנתונים | כן | כן |
1 לביקורת היברידית יש מודל תמחור שונה. מידע נוסף זמין במאמר בנושא בדיקת נתונים מכל מקור .
המאמרים הבאים
- אסטרטגיות מומלצות לצמצום הסיכון לנתונים (המסמך הבא בסדרה)