
בדף הזה מתואר שירות מיון המידע האישי הרגיש. השירות הזה עוקב אחרי הנתונים שלכם באופן רציף, מסווג אותם ומראה לכם איפה נמצאים נתונים רגישים ונתונים בסיכון גבוה. גילוי וסיווג של מידע רגיש הם מרכיב חשוב באסטרטגיה חזקה של אבטחת נתונים בענן וניהול סיכונים.
שירות הגילוי של Sensitive Data Protection (שנקרא לפעמים data profiler) עוקב באופן רציף אחרי משאבי הנתונים בארגון, בתיקייה או בפרויקט. הוא מסווג את הנתונים לפי infoTypes (infoTypes) ומעריך את רמת הרגישות והסיכון של הנתונים. השירות הזה יוצר פרופילים של נתונים, שמספקים תובנות ומדדים לגבי הנתונים שלכם. אתם יכולים לשלוח פרופילים של נתונים לGoogle Cloud שירותים אחרים, כמו Security Command Center ו-Knowledge Catalog, כדי ליהנות מהתובנות שהפרופילים מספקים.
איך זה עובד
תהליך מיון המידע האישי הרגיש כולל את השלבים הכלליים הבאים:
כדי להפעיל את גילוי המידע האישי הרגיש, צריך ליצור הגדרת סריקה לגילוי (שנקראת גם הגדרת פרופיל נתונים) בהיקף של ארגון, תיקייה או פרויקט. בהגדרת הסריקה, אפשר להגדיר מסננים כדי לציין קבוצות משנה של נתונים שרוצים ליצור להם פרופיל או לדלג עליהם. אפשר גם להגדיר את לוח הזמנים של יצירת הפרופיל.
בהגדרת הסריקה, מגדירים גם את תבנית הבדיקה שבה רוצים להשתמש. בתבנית הבדיקה מציינים את סוגי המידע האישי הרגיש (שנקראים גם infoTypes) ש-Sensitive Data Protection צריך לסרוק.
אפשר גם להפעיל פעולות שרוצים ש-Sensitive Data Protection יבצע אחרי כל סריקה. לדוגמה, אתם יכולים להגדיר פעולה שתשלח התראה ב-Pub/Sub בכל פעם שרמת הרגישות של פרופיל נתונים משתנה.
במסגרת ההגדרה, Sensitive Data Protection סורק את כל מקורות הנתונים הנתמכים כדי למצוא מידע רגיש והקשר שמוגדרים כ-infoTypes בהגדרה. Sensitive Data Protection מנתח את הנתונים שלכם על סמך הגדרת הסריקה ותבנית הבדיקה.
Sensitive Data Protection יוצר פרופילי נתונים שמספקים מדדים ותובנות לגבי הנתונים שלכם. ב-Sensitive Data Protection, התהליך הזה נקרא יצירת פרופיל נתונים. סוגי הפרופילים שנוצרים תלויים בסוג הנתונים שנסרקו על ידי Sensitive Data Protection.
אם יוצרים פרופיל של נתונים שמאוחסנים ב-BigQuery או ב-Cloud SQL, Sensitive Data Protection יוצר את הפריטים הבאים:
- פרופיל נתוני טבלה אחד לכל טבלה.
- פרופיל נתונים של עמודה לכל עמודה בטבלה.
- פרופיל נתוני פרויקט אחד לכל פרויקט שנסרק. בפרופיל הזה מוצגים נתונים מצטברים של תובנות ומדדים מכל פרופילי הנתונים בפרויקט.
אם יוצרים פרופיל של נתונים שמאוחסנים ב-Cloud Storage או בשירות אחסון בעננים אחרים, Sensitive Data Protection יוצר את הפריטים הבאים:
- פרופיל אחד של נתוני חנות קבצים לכל קטגוריה.
- פרופיל נתונים אחד לכל פרויקט שנסרק. בפרופיל הזה מוצגים תובנות ומדדים מכל פרופילי הנתונים בפרויקט.
השירות Sensitive Data Protection מבצע את כל הפעולות שהפעלתם בהגדרות של סריקת הגילוי.
כל עוד ההגדרה של סריקת הגילוי פעילה, Sensitive Data Protection יוצרת באופן אוטומטי פרופיל של הנתונים שאתם מוסיפים או משנים.
התכונה Sensitive Data Protection יוצרת מחדש פרופילי נתונים בתדירות שמתוארת במאמר תדירות היצירה של פרופילים של נתונים. אתם יכולים להתאים אישית את תדירות יצירת הפרופילים בהגדרת הסריקה על ידי יצירת לוח זמנים. כדי לאלץ את שירות החיפוש ליצור מחדש את הפרופיל של הנתונים, אפשר לעיין במאמר בנושא איך לאלץ פעולה של יצירת פרופיל מחדש.

פרופילי נתונים
כל פרופיל נתונים הוא קבוצה של תובנות ומטא-נתונים ששירות הגילוי אוסף מסריקה של משאב נתמך. התובנות כוללות את infoTypes החזויים ואת רמות הסיכון והרגישות של הנתונים. אפשר להשתמש בתובנות האלה כדי לקבל החלטות מושכלות לגבי האופן שבו אתם מגנים על הנתונים, משתפים אותם ומשתמשים בהם.
פרופילי הנתונים נוצרים ברמות פירוט שונות. לדוגמה, כשמבצעים פרופיל של נתוני BigQuery, הפרופילים נוצרים ברמות הפרויקט, הטבלה והעמודה.
בתמונה הבאה מוצגת רשימה של פרופילי נתונים ברמת העמודה. כדי להגדיל את התמונה, לוחצים עליה.

רשימה של התובנות והמטא-נתונים שנכללים בכל פרופיל נתונים זמינה במאמר בנושא הפניה למדדים.
מידע נוסף על היררכיית המשאבים זמין במאמר היררכיית המשאבים. Google Cloud
סוגים של מיון מידע אישי רגיש
בקטע הזה מוסבר על סוגי פעולות הגילוי שאפשר לבצע ועל משאבי הנתונים הנתמכים.
גילוי נתונים ב-BigQuery וב-BigLake
כשמבצעים פרופיל של נתונים ב-BigQuery, נוצרים פרופילי נתונים ברמת הפרויקט, הטבלה והעמודה. אחרי שיוצרים פרופיל של טבלה ב-BigQuery, אפשר לחקור את הממצאים לעומק על ידי ביצוע בדיקה מעמיקה.
Sensitive Data Protection יוצר פרופילים של טבלאות שנתמכות על ידי BigQuery Storage Read API, כולל הטבלאות הבאות:
- טבלאות רגילות ב-BigQuery
- תמונות מצב של טבלאות
- טבלאות BigLake שמאוחסנות ב-Cloud Storage
אין תמיכה בתכונות הבאות:
- טבלאות של BigQuery Omni.
- טבלאות שבהן גודל הנתונים הסדרתי של שורות נפרדות חורג מגודל הנתונים הסדרתי המקסימלי שנתמך על ידי BigQuery Storage Read API – 128 MB.
- טבלאות חיצוניות שאינן BigLake, כמו Google Sheets.
למידע על יצירת פרופיל של נתונים ב-BigQuery, אפשר לעיין במאמרים הבאים:
מידע נוסף על BigQuery זמין במאמרי העזרה של BigQuery.
גילוי ב-Cloud SQL
כשמבצעים פרופיל של נתונים ב-Cloud SQL, נוצרים פרופילי נתונים ברמת הפרויקט, הטבלה והעמודה. כדי להתחיל את תהליך הגילוי, צריך לספק את פרטי החיבור לכל מופע של Cloud SQL שרוצים ליצור לו פרופיל.
למידע על יצירת פרופיל של נתוני Cloud SQL, אפשר לעיין במאמרים הבאים:
מידע נוסף על Cloud SQL זמין במסמכי התיעוד של Cloud SQL.
גילוי נתונים ב-Cloud Storage
כשמבצעים פרופיל לנתונים ב-Cloud Storage, פרופילי הנתונים נוצרים ברמת הקטגוריה. הכלי Sensitive Data Protection מקבץ את הקבצים שזוהו לאשכולות של קבצים ומספק סיכום לכל אשכול.
למידע על יצירת פרופילים של נתונים ב-Cloud Storage, אפשר לעיין במאמרים הבאים:
- יצירת פרופיל של נתוני Cloud Storage בפרויקט אחד
- יצירת פרופיל של נתונים ב-Cloud Storage בארגון או בתיקייה
מידע נוסף על Cloud Storage זמין במאמרי העזרה של Cloud Storage.
Discovery for Vertex AI
כשיוצרים פרופיל של משאב Vertex AI, Sensitive Data Protection יוצר פרופיל נתונים של מאגר קבצים או פרופיל נתונים של טבלה, בהתאם למקום שבו נשמרים נתוני האימון: Cloud Storage או BigQuery.
למידע נוסף, קראו את המאמרים הבאים:
- מיון מידע אישי רגיש ב-Vertex AI
- יצירת פרופיל של נתוני Vertex AI בפרויקט אחד
- יצירת פרופיל של נתוני Vertex AI בארגון או בתיקייה
מידע נוסף על Vertex AI זמין במאמרי העזרה של Vertex AI.
גילוי בספקי ענן אחרים
כשיוצרים פרופיל של נתונים ב-S3, פרופילי הנתונים נוצרים ברמת הקטגוריה. כשיוצרים פרופיל של נתונים ב-Azure Blob Storage, פרופילי הנתונים נוצרים ברמת הקונטיינר.
בשני המקרים, Sensitive Data Protection מקבצת את הקבצים שזוהו לאשכולות של קבצים ומספקת סיכום לכל אשכול.
למידע נוסף, קראו את המאמרים הבאים:
משתני סביבה של Cloud Run
שירות הגילוי יכול לזהות את הנוכחות של סודות במשתני הסביבה של פונקציות Cloud Run ושל עדכוני שירות Cloud Run, ולשלוח את הממצאים אל Security Command Center. לא נוצרים פרופילי נתונים.
מידע נוסף זמין במאמר דיווח על סודות במשתני סביבה ל-Security Command Center.
הרשאות שנדרשות כדי להגדיר פרופילי נתונים ולצפות בהם
בקטעים הבאים מפורטים תפקידי המשתמשים הנדרשים, לפי המטרה שלהם. בהתאם לאופן שבו הארגון שלכם מוגדר, יכול להיות שתחליטו שאנשים שונים יבצעו משימות שונות. לדוגמה, יכול להיות שאדם אחר יגדיר את פרופילי הנתונים מאשר האדם שמנטר אותם באופן קבוע.
תפקידים שנדרשים לעבודה עם פרופילי נתונים ברמת הארגון או התיקייה
התפקידים האלה מאפשרים לכם להגדיר פרופילי נתונים ולהציג אותם ברמת הארגון או התיקייה.
חשוב לוודא שהתפקידים האלה מוקצים לאנשים המתאימים ברמת הארגון. לחלופין, האדמין שלכם יכול ליצור תפקידים בהתאמה אישית עם ההרשאות הרלוונטיות בלבד. Google Cloud
| מטרה | תפקיד מוגדר מראש | הרשאות רלוונטיות |
|---|---|---|
| יצירת הגדרות לסריקת גילוי וצפייה בפרופילים של נתונים | אדמין DLP (roles/dlp.admin)
|
|
| יוצרים פרויקט שישמש כקונטיינר של סוכן השירות1 | Project Creator (roles/resourcemanager.projectCreator) |
|
| הענקת גישה לגילוי2 | אחת מהאפשרויות הבאות:
|
|
| הצגת פרופילי נתונים (לקריאה בלבד) | קורא פרופילים של נתונים ב-DLP (roles/dlp.dataProfilesReader) |
|
קורא DLP (roles/dlp.reader) |
|
1 אם אין לכם את התפקיד Project Creator (יוצר פרויקטים) (roles/resourcemanager.projectCreator), אתם עדיין יכולים ליצור הגדרת סריקה, אבל קונטיינר סוכן השירות שבו אתם משתמשים חייב להיות פרויקט קיים.
2 אם אין לכם את התפקיד Organization Administrator (roles/resourcemanager.organizationAdmin) או Security Admin (roles/iam.securityAdmin), עדיין תוכלו ליצור הגדרת סריקה. אחרי שיוצרים את הגדרת הסריקה, מישהו בארגון עם אחד מהתפקידים האלה צריך להעניק לסוכן השירות גישה לגילוי.
תפקידים שנדרשים לעבודה עם פרופילי נתונים ברמת הפרויקט
התפקידים האלה מאפשרים לכם להגדיר פרופילים של נתונים ולצפות בהם ברמת הפרויקט.
חשוב לוודא שהתפקידים האלה מוקצים לאנשים המתאימים ברמת הפרויקט. לחלופין, האדמין שלכם יכול ליצור תפקידים בהתאמה אישית עם ההרשאות הרלוונטיות בלבד. Google Cloud
| מטרה | תפקיד מוגדר מראש | הרשאות רלוונטיות |
|---|---|---|
| הגדרה של פרופילי נתונים וצפייה בהם | אדמין DLP (roles/dlp.admin)
|
|
| הצגת פרופילי נתונים (לקריאה בלבד) | קורא פרופילים של נתונים ב-DLP (roles/dlp.dataProfilesReader) |
|
קורא DLP (roles/dlp.reader) |
|
הגדרת סריקה למיון מידע אישי רגיש
הגדרת סריקת גילוי (לפעמים נקראת הגדרת גילוי או הגדרת סריקה) מציינת איך Sensitive Data Protection צריכה ליצור פרופיל של הנתונים שלכם. ההגדרות האלה כוללות:
- ההיקף (ארגון, תיקייה או פרויקט) של פעולת הגילוי
- סוג המשאב ליצירת פרופיל
- תבניות של בדיקות לשימוש
- תדירות הסריקה
- קבוצות משנה ספציפיות של נתונים שצריך לכלול או להחריג מהגילוי
- פעולות שרוצים שהשירות Sensitive Data Protection יבצע אחרי הגילוי – לדוגמה, אילו Google Cloud שירותים לפרסם את הפרופילים
- סוכן שירות לשימוש בפעולות גילוי
מידע על יצירת הגדרה של סריקת גילוי ברמת הארגון או ברמת הפרויקט מופיע בדפים הבאים:
| סוג ה-Discovery | יצירת הגדרת סריקה ברמת הארגון | יצירת הגדרת סריקה ברמת הפרויקט1 |
|---|---|---|
| גילוי נתונים ב-BigQuery | יצירת פרופיל של נתוני BigQuery בארגון או בתיקייה | יצירת פרופיל של נתוני BigQuery בפרויקט יחיד |
| גילוי נתונים ב-Cloud SQL | יצירת פרופיל של נתוני Cloud SQL בארגון או בתיקייה | יצירת פרופיל של נתוני Cloud SQL בפרויקט יחיד |
| גילוי נתונים ב-Cloud Storage | יצירת פרופיל של נתונים ב-Cloud Storage בארגון או בתיקייה | יצירת פרופיל של נתונים ב-Cloud Storage בפרויקט יחיד |
| גילוי נתונים ב-Vertex AI | יצירת פרופיל של נתוני Vertex AI בארגון או בתיקייה | יצירת פרופיל של נתוני Vertex AI בפרויקט יחיד |
| גילוי נתונים ב-Amazon S3 | גילוי נתונים ב-Amazon S3 | לא רלוונטי |
| גילוי נתונים ב-Azure Blob Storage | גילוי נתונים ב-Azure Blob Storage | לא רלוונטי |
| גילוי סודות (לא נוצרו פרופילים) | הגדרה של גילוי סודות ברמת הארגון | הגדרה של גילוי סודות ברמת הפרויקט |
1 לא מתאים ללקוחות שיש להם מינוי לגילוי ברמת הארגון, כמו מינוי שניתן דרך Security Command Center
היקפי ההגדרה של הסריקה
אפשר ליצור הגדרת סריקה ברמות הבאות:
- ארגון
- תיקייה
- פרויקט
- משאב נתונים יחיד
ברמת הארגון והתיקייה, אם לשתי הגדרות סריקה פעילות או יותר יש את אותו פרויקט בהיקף שלהן, Sensitive Data Protection קובע איזו הגדרת סריקה יכולה ליצור פרופילים עבור הפרויקט הזה. מידע נוסף זמין בקטע שינוי הגדרות הסריקה שבדף הזה.
הגדרת סריקה ברמת הפרויקט תמיד יכולה ליצור פרופיל של פרויקט היעד, והיא לא מתחרה בהגדרות אחרות ברמת תיקיית האב או הארגון.
הגדרה של סריקת משאב יחיד נועדה לעזור לכם לבדוק את פרופיל הנתונים של משאב נתונים יחיד.
מיקום הגדרות הסריקה
בפעם הראשונה שיוצרים הגדרת סריקה, מציינים איפה רוצים ש-Sensitive Data Protection ישמור אותה. כל ההגדרות הבאות של הסריקות שתיצרו יישמרו באותו אזור.
לדוגמה, אם יוצרים הגדרת סריקה לתיקייה א' ושומרים אותה באזור us-west1, כל הגדרת סריקה שתיצרו בהמשך לכל משאב אחר תיצור גם באזור הזה.
המטא-נתונים על הנתונים שיוגדרו בפרופיל מועתקים לאותו אזור שבו נמצאות הגדרות הסריקה, אבל הנתונים עצמם לא מועברים ולא מועתקים. מידע נוסף מופיע במאמר שיקולים לגבי מיקום הנתונים.
תבנית בדיקה
תבנית בדיקה מציינת אילו סוגי מידע (או infoTypes) מערכת Sensitive Data Protection מחפשת במהלך סריקת הנתונים. כאן אתם מספקים שילוב של סוגי מידע מובנים וסוגי מידע מותאמים אישית (אופציונלי).
אפשר גם לציין רמת הסתברות כדי לצמצם את מה ש-Sensitive Data Protection מחשיב כהתאמה. אתם יכולים להוסיף קבוצות של כללים כדי להחריג ממצאים לא רצויים או לכלול ממצאים נוספים.
כברירת מחדל, אם משנים תבנית בדיקה שמשמשת את הגדרת הסריקה, השינויים חלים רק על סריקות עתידיות. הפעולה שלכם לא גורמת לפעולת יצירת פרופיל מחדש של הנתונים.
אם רוצים ששינויים בתבנית הבדיקה יפעילו פעולות של יצירת פרופיל מחדש על הנתונים המושפעים, צריך להוסיף או לעדכן לוח זמנים בהגדרות הסריקה ולהפעיל את האפשרות ליצור פרופיל מחדש של הנתונים כשמשנים את תבנית הבדיקה. מידע נוסף זמין במאמר בנושא תדירות היצירה של פרופיל נתונים.
צריכה להיות לכם תבנית בדיקה בכל אזור שבו יש לכם נתונים שצריך ליצור להם פרופיל. אם רוצים להשתמש בתבנית אחת לכמה אזורים, אפשר להשתמש בתבנית שמאוחסנת באזור global. אם מדיניות הארגון מונעת מכם ליצור תבנית בדיקה באזור global, אתם צריכים להגדיר תבנית בדיקה ייעודית לכל אזור. מידע נוסף מופיע במאמר שיקולים לגבי מיקום הנתונים.
תבניות בדיקה הן רכיב ליבה בפלטפורמת Sensitive Data Protection. פרופילי נתונים משתמשים באותן תבניות בדיקה שבהן אתם יכולים להשתמש בכל שירותי Sensitive Data Protection. מידע נוסף על תבניות בדיקה זמין במאמר תבניות.
קונטיינר של סוכן שירות וסוכן שירות
כשיוצרים הגדרת סריקה לארגון או לתיקייה, צריך לספק מאגר של סוכני שירות ב-Sensitive Data Protection. מאגר של סוכני שירות הוא Google Cloud פרויקט שבו שירות Sensitive Data Protection עוקב אחרי חיובים שקשורים לפעולות פרופיל ברמת הארגון והתיקייה.
מאגר סוכני השירות מכיל סוכן שירות, ששירות Sensitive Data Protection משתמש בו כדי ליצור פרופיל של נתונים בשמכם. אתם צריכים סוכן שירות כדי לבצע אימות ל-Sensitive Data Protection ולממשקי API אחרים. לסוכן השירות שלך צריכות להיות כל ההרשאות הנדרשות כדי לגשת לנתונים שלך ולבנות פרופיל שלהם. המזהה של סוכן השירות הוא בפורמט הבא:
service-PROJECT_NUMBER@dlp-api.iam.gserviceaccount.com
כאן, PROJECT_NUMBER הוא המזהה המספרי של מאגר סוכני השירות.
כשמגדירים את מאגר סוכני השירות, אפשר לבחור פרויקט קיים. אם הפרויקט שבחרתם מכיל סוכן שירות, Sensitive Data Protection מעניק לסוכן השירות הזה את הרשאות ה-IAM הנדרשות. אם לפרויקט אין סוכן שירות, הכלי Sensitive Data Protection יוצר סוכן שירות ומעניק לו באופן אוטומטי הרשאות ליצירת פרופיל נתונים.
לחלופין, אפשר לבחור ש-Sensitive Data Protection ייצור באופן אוטומטי את מאגר הסוכן של השירות ואת סוכן השירות. הכלי Sensitive Data Protection מעניק באופן אוטומטי הרשאות ליצירת פרופיל נתונים לסוכן השירות.
בשני המקרים, אם שירות Sensitive Data Protection לא מצליח להעניק לסוכן השירות גישה ליצירת פרופיל נתונים, מוצגת שגיאה כשמציגים את פרטי הגדרת הסריקה.
בהגדרות סריקה ברמת הפרויקט, לא צריך מאגר של סוכני שירות. הפרויקט שאתם יוצרים לו פרופיל משמש למטרה של קונטיינר סוכן השירות. כדי להריץ פעולות פרופיל, Sensitive Data Protection משתמש בסוכן השירות של הפרויקט.
גישה לפרופיל נתונים ברמת הארגון או התיקייה
כשמגדירים גילוי של נתונים רגישים ברמת הארגון או התיקייה, Sensitive Data Protection מנסה להעניק באופן אוטומטי לסוכן השירות שלכם גישה לפרופיל הנתונים. עם זאת, אם אין לכם הרשאות להעניק גישה לגילוי, לא ניתן לבצע את הפעולה הזו בשמכם באמצעות Sensitive Data Protection. משתמש עם ההרשאות האלה בארגון שלכם, כמו Google Cloud אדמין, צריך להעניק לסוכן השירות שלכם גישה ליצירת פרופיל נתונים.
תדירות יצירת פרופיל הנתונים
אחרי שיוצרים הגדרת סריקה לגילוי משאב מסוים, Sensitive Data Protection מבצעת סריקה ראשונית ויוצרת פרופיל של הנתונים בהיקף של הגדרת הסריקה.
אחרי הסריקה הראשונית, Sensitive Data Protection ממשיך לעקוב אחרי המשאב שנוצר לו פרופיל. הנתונים שנוספים למשאב עוברים פרופיל באופן אוטומטי זמן קצר אחרי ההוספה.
תדירות ברירת המחדל של יצירת פרופיל חדש
תדירות יצירת הפרופיל מחדש שמוגדרת כברירת מחדל משתנה בהתאם לסוג הגילוי של הגדרת הסריקה:
- פרופיל ב-BigQuery: לכל טבלה, מחכים 30 ימים ואז יוצרים מחדש את הפרופיל של הטבלה אם יש שינויים בסכימה, בשורות הטבלה או בתבנית הבדיקה.
- יצירת פרופיל ב-Cloud SQL: לכל טבלה, מחכים 30 ימים ואז יוצרים מחדש את הפרופיל של הטבלה אם יש שינויים בסכימה או בתבנית הבדיקה.
- פרופילים ב-Vertex AI: לכל משאב, מחכים 30 ימים ואז יוצרים פרופיל מחדש של המשאב אם יש שינויים בתבנית הבדיקה.
יצירת פרופיל של מאגר קבצים: לכל מאגר קבצים ב- Google Cloud או בעננים אחרים, צריך להמתין 30 יום ואז ליצור מחדש את הפרופיל של מאגר הקבצים אם יש שינויים בתבנית הבדיקה.
ב-Sensitive Data Protection, המונח file store מתייחס לקטגוריה או למאגר של אחסון קבצים.
התאמה אישית של תדירות יצירת הפרופיל מחדש
בהגדרות הסריקה, אתם יכולים להתאים אישית את התדירות של יצירת הפרופילים מחדש על ידי יצירת לוח זמנים אחד או יותר לקבוצות משנה שונות של הנתונים.
אלה התדירויות הזמינות ליצירת פרופיל חדש:
- לא ליצור פרופיל מחדש: לא ליצור פרופיל מחדש אחרי יצירת הפרופילים הראשוניים.
- יצירת פרופיל חדש מדי יום: צריך לחכות 24 שעות לפני יצירת פרופיל חדש.
- יצירת פרופיל מחדש מדי שבוע: צריך להמתין 7 ימים לפני יצירת פרופיל מחדש.
- יצירת פרופיל חדש מדי חודש: צריך להמתין 30 ימים לפני יצירת פרופיל חדש.
יצירת פרופיל מחדש לפי לוח זמנים
בהגדרת הסריקה, אפשר לציין אם צריך ליצור מחדש פרופיל של קבוצת משנה של נתונים באופן קבוע, בלי קשר לשאלה אם הנתונים עברו שינויים. התדירות שאתם מגדירים מציינת כמה זמן צריך לעבור בין פעולות הפרופיל. לדוגמה, אם מגדירים את התדירות לשבועית, Sensitive Data Protection יסווג משאב נתונים שבעה ימים אחרי הסיווג האחרון שלו.
יצירת פרופיל מחדש בעדכון
בהגדרת הסריקה, אפשר לציין אירועים שיכולים להפעיל פעולות של יצירת פרופיל מחדש. דוגמאות לאירועים כאלה הן עדכונים של תבניות בדיקה.
כשבוחרים את האירועים האלה, לוח הזמנים שהגדרתם מציין את הזמן הכי ארוך שבו Sensitive Data Protection מחכה להצטברות של עדכונים לפני שהיא יוצרת פרופיל מחדש של הנתונים. אם לא מתרחשים שינויים רלוונטיים בתקופה שצוינה – כמו שינויים בסכימה או שינויים בתבנית הבדיקה – לא מתבצע פרופיל מחדש של הנתונים. כשמתרחש השינוי הרלוונטי הבא, המערכת יוצרת פרופיל חדש של הנתונים המושפעים בהזדמנות הבאה, שנקבעת על ידי גורמים שונים (כמו קיבולת המכונה הזמינה או יחידות המינוי שנרכשו). אחרי כן, מערכת Sensitive Data Protection מתחילה להמתין שוב להצטברות של עדכונים בהתאם ללוח הזמנים שהגדרתם.
לדוגמה, נניח שהגדרת הסריקה מוגדרת ליצירת פרופיל חדש מדי חודש בשינוי סכימה. פרופילי הנתונים נוצרו לראשונה ביום 0. לא מתבצעים שינויים בסכימה עד היום ה-30, ולכן לא מתבצע פרופיל מחדש של הנתונים. ביום 35, מתרחש השינוי הראשון בסכימה. מערכת Sensitive Data Protection יוצרת מחדש את הפרופיל של הנתונים המעודכנים בהזדמנות הבאה. לאחר מכן המערכת ממתינה עוד 30 ימים כדי לצבור עדכונים בסכימה לפני שהיא יוצרת פרופיל מחדש של נתונים מעודכנים.
התהליך של שינוי הפרופיל יכול להימשך עד 24 שעות. אם העיכוב נמשך יותר מ-24 שעות ואתם משתמשים במצב תמחור לפי מינוי, כדאי לבדוק אם יש לכם קיבולת שנותרה לחודש.
דוגמאות לתרחישים אפשר למצוא במאמר דוגמאות לתמחור של פרופיל נתונים.
כדי לאלץ את שירות החיפוש ליצור מחדש את הפרופיל של הנתונים, אפשר לעיין במאמר בנושא איך לאלץ פעולה של יצירת פרופיל מחדש.
ביצועים בקמפיינים לחיפוש וגילוי אפליקצי
משך הזמן שנדרש ליצירת פרופיל של הנתונים משתנה בהתאם לכמה גורמים, כולל, בין היתר:
- מספר משאבי הנתונים שנכללים בפרופיל
- הגדלים של משאבי הנתונים
- בטבלאות, מספר העמודות
- בטבלאות, סוגי הנתונים בעמודות
לכן, הביצועים של'הגנה על נתונים רגישים' בבדיקה או במשימת פרופיל מהעבר לא מעידים על הביצועים שלה במשימות פרופיל עתידיות.
שמירת נתוני הפרופילים
Sensitive Data Protection שומר את הגרסה האחרונה של פרופיל נתונים ללא הגבלת זמן. כש-Sensitive Data Protection יוצר פרופילים מחדש של משאב נתונים, המערכת מחליפה את הפרופילים הקיימים של משאב הנתונים בפרופילים חדשים.
מחיקת פרופיל נתונים מחייבת את המערכת ליצור פרופיל חדש של נתוני המקור, אלא אם אתם מוציאים אותו מהגדרות הגילוי.
במאמר תמחור של גילוי נתונים מוסבר איך Sensitive Data Protection מחייב על נתוני פרופילים.
אם רוצים לנתח את פרופילי הנתונים, לצרף אותם למקורות נתונים אחרים או לשמור תיעוד של השינויים שחלים עליהם, כדאי לשמור את פרופילי הנתונים ב-BigQuery כשמגדירים גילוי של נתונים רגישים. אתם בוחרים את מערך הנתונים ב-BigQuery שבו יישמרו הפרופילים, ושולטים במדיניות התפוגה של הטבלה במערך הנתונים הזה.
שינוי הגדרות הסריקה
אפשר ליצור רק הגדרת סריקה אחת לכל שילוב של היקף וסוג גילוי. לדוגמה, אפשר ליצור רק הגדרת סריקה אחת ברמת הארגון ליצירת פרופיל של נתונים ב-BigQuery, והגדרת סריקה אחת ברמת הארגון לגילוי סודות. באופן דומה, אפשר ליצור רק הגדרת סריקה אחת ברמת הפרויקט ליצירת פרופיל נתונים ב-BigQuery והגדרת סריקה אחת ברמת הפרויקט לגילוי סודות.
אם לשתי הגדרות סריקה פעילות או יותר יש את אותו פרויקט ואותו סוג גילוי בהיקף שלהן, הכללים הבאים חלים:
- מבין ההגדרות של סריקות ברמת הארגון וברמת התיקייה, ההגדרה שהכי קרובה לפרויקט תוכל להריץ גילוי עבור הפרויקט הזה. הכלל הזה חל גם אם קיימת הגדרת סריקה ברמת הפרויקט עם אותו סוג גילוי.
- Sensitive Data Protection מתייחס להגדרות סריקה ברמת הפרויקט בנפרד מההגדרות ברמת הארגון וברמת התיקייה. הגדרת סריקה שיוצרים ברמת הפרויקט לא יכולה לבטל הגדרה שיוצרים עבור תיקיית אב או ארגון.
לדוגמה, נניח שיש שלוש הגדרות סריקה פעילות. נניח שכל הגדרות הסריקה האלה הן לפרופיל נתונים ב-BigQuery.
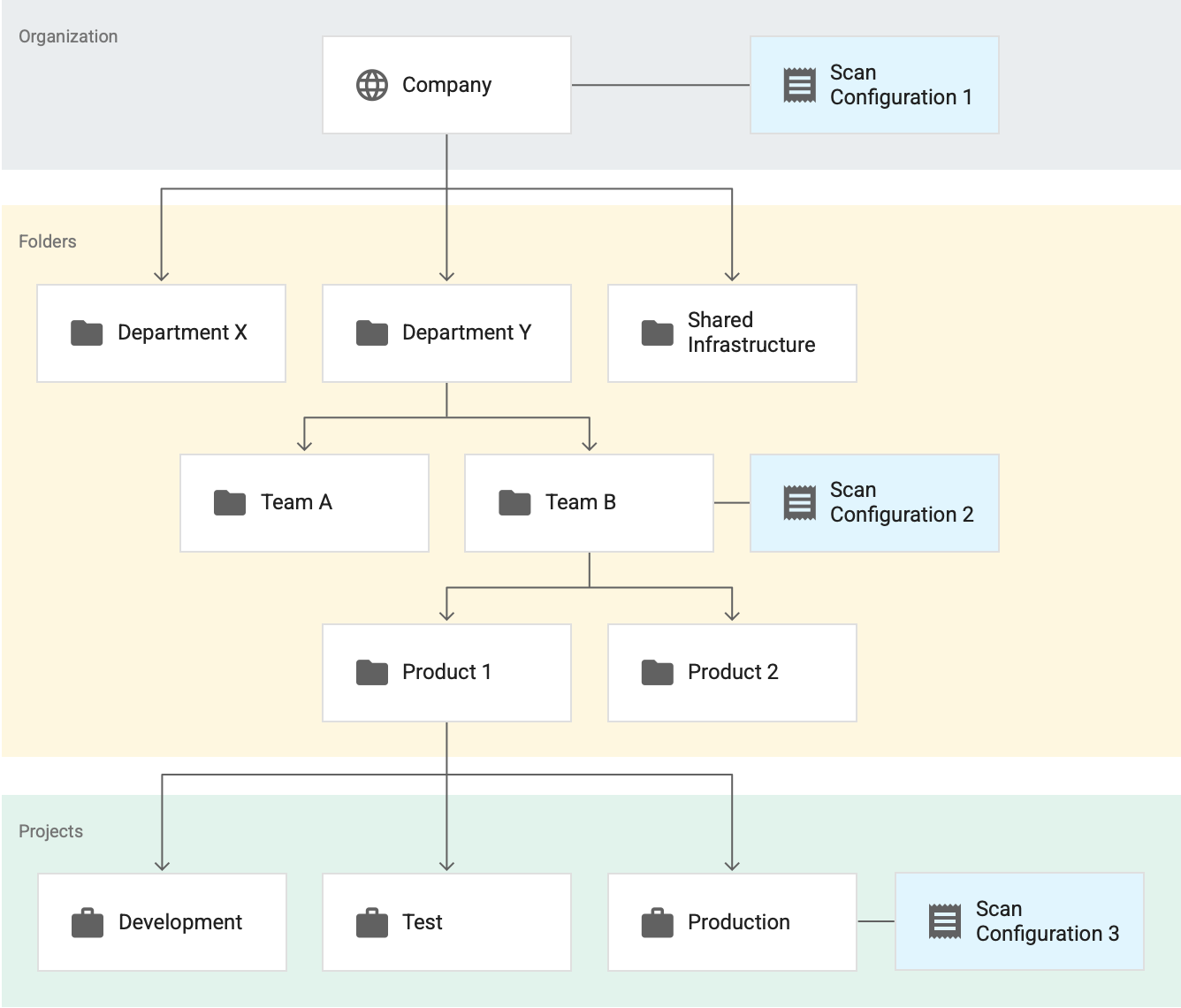
בדוגמה הזו, הגדרת סריקה 1 חלה על הארגון כולו, הגדרת סריקה 2 חלה על התיקייה Team B, והגדרת סריקה 3 חלה על הפרויקט Production. בדוגמה הזו:
- פרופילים של Sensitive Data Protection סורקים את כל הטבלאות בפרויקטים שלא נמצאים בתיקייה Team B בהתאם להגדרת הסריקה 1.
- Sensitive Data Protection יוצר פרופילים לכל הטבלאות בפרויקטים בתיקייה Team B – כולל טבלאות בפרויקט Production – בהתאם להגדרת הסריקה 2.
- פרופילים של Sensitive Data Protection בודקים את כל הטבלאות בפרויקט Production בהתאם להגדרת סריקה 3.
בדוגמה הזו, Sensitive Data Protection יוצר שני סטים של פרופילים לפרויקט Production – סט אחד לכל אחת מהגדרות הסריקה הבאות:
- הגדרת סריקה 2
- הגדרת סריקה 3
עם זאת, גם אם יש שני סטים של פרופילים לאותו פרויקט, הם לא מוצגים יחד בלוח הבקרה. אתם יכולים לראות רק את הפרופילים שנוצרו במשאב – ארגון, תיקייה או פרויקט – ובאזור שאתם צופים בו.
מידע נוסף על היררכיית המשאבים של Google Cloudזמין במאמר היררכיית המשאבים.
תמונות מצב של פרופיל הנתונים
כל פרופיל נתונים כולל תמונת מצב של הגדרת הסריקה ותבנית הבדיקה ששימשו ליצירת הפרופיל. אתם יכולים להשתמש בתמונת המצב הזו כדי לבדוק את ההגדרות שבהן השתמשתם כדי ליצור פרופיל נתונים מסוים.
שיקולים לגבי מיקום הנתונים
השיקולים לגבי מיקום הנתונים משתנים בהתאם לסוג הנתונים שסורקים:Google Cloud נתונים או נתונים מספקי ענן אחרים.
שיקולים לגבי מיקום הנתונים של Google Cloud
הקטע הזה רלוונטי רק לגילוי מידע אישי רגיש במשאבים. Google Cloudבקטע שיקולים לגבי מיקום נתונים של משאבים מספקי ענן אחרים שבדף הזה מפורטים שיקולים לגבי מיקום נתונים שקשורים למשאבים מספקי ענן אחרים.
השירות Sensitive Data Protection נועד לתמוך במיקום הנתונים. אם אתם מחויבים לעמוד בדרישות בנוגע למיקום הנתונים, כדאי לשים לב לנקודות הבאות:
תבניות אזוריות לבדיקה
הקטע הזה רלוונטי רק לגילוי מידע אישי רגיש במשאבים. Google Cloudבקטע שיקולים לגבי מיקום נתונים של משאבים מספקי ענן אחרים שבדף הזה מפורטים שיקולים לגבי מיקום נתונים שקשורים למשאבים מספקי ענן אחרים.
השירות Sensitive Data Protection מעבד את הנתונים באותו אזור שבו הנתונים מאוחסנים. כלומר, הנתונים לא יוצאים מהאזור הנוכחי שלהם.
בנוסף, אפשר להשתמש בתבנית בדיקה רק כדי ליצור פרופיל של נתונים שנמצאים באותו אזור כמו התבנית. לדוגמה, אם מגדירים את האפשרות 'גילוי' לשימוש בתבנית בדיקה שמאוחסנת באזור us-west1, Sensitive Data Protection יכול ליצור פרופיל נתונים רק באזור הזה.
אפשר להגדיר תבנית בדיקה ייעודית לכל אזור שבו יש לכם נתונים.
אם מספקים תבנית בדיקה שמאוחסנת באזור global, Sensitive Data Protection משתמשת בתבנית הזו לנתונים באזורים שאין להם תבנית בדיקה ייעודית.
בטבלה הבאה מוצגים תרחישים לדוגמה:
| תרחיש | תמיכה |
|---|---|
סריקת נתונים באזור us באמצעות תבנית בדיקה מאזור us. |
נתמך |
סריקת נתונים באזור global באמצעות תבנית בדיקה
מהאזור us. |
לא נתמך |
סריקת נתונים באזור us באמצעות תבנית בדיקה מהאזור global. |
נתמך |
סריקת נתונים באזור us באמצעות תבנית בדיקה מהאזור us-east1. |
לא נתמך |
סריקת נתונים באזור us-east1 באמצעות תבנית בדיקה
מהאזור us. |
לא נתמך |
סריקת נתונים באזור us באמצעות תבנית בדיקה מהאזור asia. |
לא נתמך |
הגדרת פרופיל נתונים
הקטע הזה רלוונטי רק לגילוי מידע אישי רגיש במשאבים. Google Cloudבקטע שיקולים לגבי מיקום נתונים של משאבים מספקי ענן אחרים שבדף הזה מפורטים שיקולים לגבי מיקום נתונים שקשורים למשאבים מספקי ענן אחרים.
כש-Sensitive Data Protection יוצר פרופילים של נתונים, הוא מצלם את הגדרות הסריקה ואת תבנית הבדיקה ושומר אותן בכל פרופיל של נתוני טבלה או פרופיל של נתוני מאגר קבצים.
אם תגדירו את הגילוי כך שישתמש בתבנית בדיקה מהאזור, Sensitive Data Protection יעתיק את התבנית הזו לכל אזור שיש בו נתונים ליצירת פרופיל.global באופן דומה, הוא מעתיק את הגדרות הסריקה לאזורים האלה.
לדוגמה: פרויקט א' מכיל את טבלה 1. טבלה 1 נמצאת באזור us-west1, הגדרת הסריקה נמצאת באזור us-west2 ותבנית הבדיקה נמצאת באזור global.
כש-Sensitive Data Protection סורק את פרויקט א', הוא יוצר פרופילי נתונים עבור טבלה 1 ושומר אותם באזור us-west1. פרופיל נתוני הטבלה של טבלה 1 מכיל עותקים של הגדרת הסריקה ותבנית הבדיקה שנעשה בהם שימוש בפעולת יצירת הפרופיל.
אם לא רוצים שהתבנית לבדיקה תועתק לאזורים אחרים, לא מגדירים את Sensitive Data Protection לסריקת נתונים באזורים האלה.
אחסון אזורי של פרופילי נתונים
הקטע הזה רלוונטי רק לגילוי מידע אישי רגיש במשאבים. Google Cloudבקטע שיקולים לגבי מיקום נתונים של משאבים מספקי ענן אחרים שבדף הזה מפורטים שיקולים לגבי מיקום נתונים שקשורים למשאבים מספקי ענן אחרים.
השירות Sensitive Data Protection מעבד את הנתונים שלכם באזור או במספר האזורים שבהם הם נמצאים, ומאחסן את פרופילי הנתונים שנוצרו באותו אזור או באותם אזורים.
כדי לראות פרופילים של נתונים במסוף Google Cloud , צריך קודם לבחור את האזור שבו הם נמצאים. אם יש לכם נתונים בכמה אזורים, תצטרכו להחליף אזורים כדי לראות כל קבוצה של פרופילים.
אזורים שלא נתמכים
הקטע הזה רלוונטי רק לגילוי מידע אישי רגיש במשאבים. Google Cloudבקטע שיקולים לגבי מיקום נתונים של משאבים מספקי ענן אחרים שבדף הזה מפורטים שיקולים לגבי מיקום נתונים שקשורים למשאבים מספקי ענן אחרים.
אם יש לכם נתונים באזור שלא נתמך על ידי Sensitive Data Protection, שירות הגילוי ידלג על מקורות הנתונים האלה ויציג שגיאה כשתציגו את פרופילי הנתונים.
במספר אזורים
ב-Sensitive Data Protection, מספר אזורים נחשב לאזור אחד ולא לאוסף של אזורים. לדוגמה, האזור us ומספר האזורים us-west1 נחשבים לשני אזורים נפרדים מבחינת מיקום הנתונים.
משאבים של תחום מוגדר
Sensitive Data Protection הוא שירות אזורי ורב-אזורי, והוא לא מבחין בין אזורים. במקרה של משאב של תחום מוגדר נתמך, כמו מופע Cloud SQL, הנתונים מעובדים באזור הנוכחי שלו, אבל לא בהכרח בתחום הנוכחי. לדוגמה, אם מופע של Cloud SQL מאוחסן באזור us-central1-a, Sensitive Data Protection מעבד ומאחסן את פרופילי הנתונים באזור us-central1.
מידע כללי על Google Cloud מיקומים זמין במאמר מיקום גיאוגרפי ואזורים.
שיקולים לגבי מיקום הנתונים כשמדובר בנתונים מספקי ענן אחרים
כשמתכננים ליצור פרופיל של נתונים מספקי ענן אחרים, כדאי לשים לב לנקודות הבאות:
- פרופילי הנתונים נשמרים לצד הגדרות סריקת הגילוי. לעומת זאת, כשיוצרים פרופיל של נתונים, הפרופילים מאוחסנים באותו אזור שבו מאוחסנים הנתונים שרוצים ליצור להם פרופיל. Google Cloud
- אם מאחסנים את תבנית הבדיקה באזור
global, מתבצעת קריאה של עותק בזיכרון של התבנית באזור שבו מאחסנים את הגדרת סריקת הגילוי. - הנתונים שלכם לא ישתנו. עותק של הנתונים בזיכרון נקרא באזור שבו מאוחסנת ההגדרה של סריקת הגילוי. עם זאת, Sensitive Data Protection לא מתחייב לגבי המיקום שבו הנתונים עוברים אחרי שהם מגיעים לאינטרנט הציבורי. הנתונים מוצפנים באמצעות SSL.
תאימות
מידע על האופן שבו Sensitive Data Protection מטפל בנתונים שלכם ועוזר לכם לעמוד בדרישות התאימות זמין במאמר בנושא אבטחת נתונים.
המאמרים הבאים
מומלץ לקרוא את הפוסט בבלוג בנושא זהות ואבטחה ניהול אוטומטי של סיכוני נתונים ב-BigQuery באמצעות הגנה על מידע אישי רגיש.
מידע על איך Sensitive Data Protection מחשב את הסיכון לנתונים ואת רמות הרגישות כשיוצרים פרופיל של הנתונים