
Esta página apresenta estratégias recomendadas para identificar e corrigir riscos de dados na sua organização.
A proteção dos dados começa com a compreensão de quais dados você está processando, onde os dados sensíveis estão localizados e como eles são protegidos e usados. Quando você tem uma visão abrangente dos seus dados e da postura de segurança deles, pode tomar as medidas adequadas para protegê-los e monitorar continuamente a conformidade e o risco.
Nesta página, presumimos que você esteja familiarizado com os serviços de descoberta e inspeção e as diferenças entre eles.
Ativar a descoberta de dados sensíveis
Para determinar onde os dados sensíveis existem na sua empresa, configure a descoberta no nível da organização, da pasta ou do projeto. Esse serviço gera perfis de dados que contêm métricas e insights sobre seus dados, incluindo os níveis de sensibilidade e risco de dados.
Como um serviço, a descoberta atua como uma fonte de verdade sobre seus recursos de dados e pode gerar automaticamente métricas para relatórios de auditoria. Além disso, a descoberta pode se conectar a outros Google Cloud serviços, como o Security Command Center, o Google Security Operations e o Knowledge Catalog, para enriquecer as operações de segurança e o gerenciamento de dados.
O serviço de descoberta é executado continuamente e detecta novos dados à medida que sua organização opera e cresce. Por exemplo, se alguém na sua organização criar um novo projeto e enviar uma grande quantidade de dados novos, o serviço de descoberta poderá descobrir, classificar e gerar relatórios sobre os novos dados automaticamente.
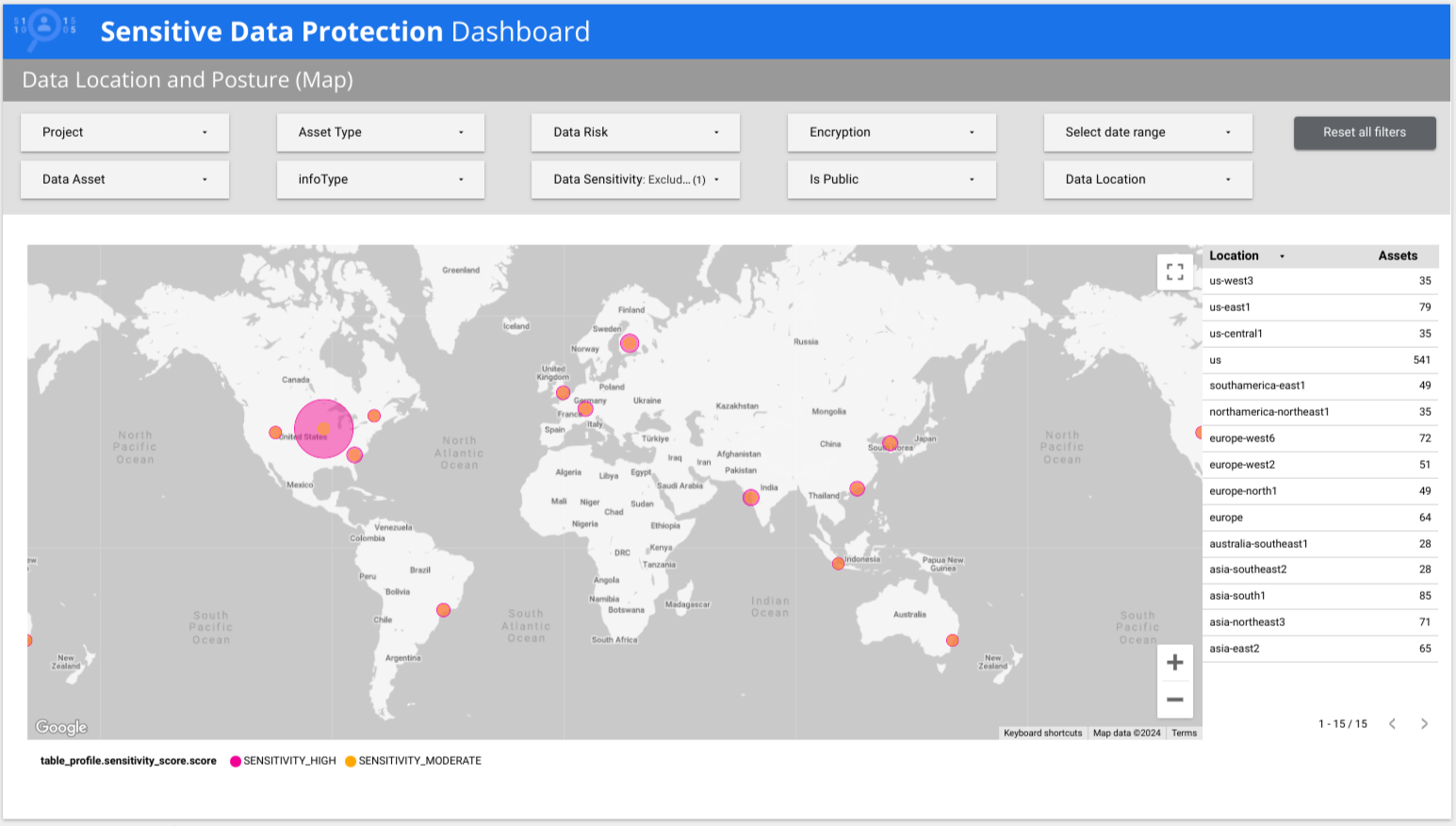
A Proteção de Dados Sensíveis oferece um relatório pré-criado de várias páginas do Data Studio que oferece uma visão geral dos seus dados, incluindo detalhamentos por risco, infoType e local. No exemplo a seguir, o relatório mostra que dados de baixa e alta sensibilidade estão presentes em vários países ao redor do mundo.
Entre em ação com base nos resultados da descoberta
Depois de ter uma visão geral da postura segurança de dados, você pode corrigir os problemas encontrados. Em geral, as descobertas se enquadram em um dos seguintes cenários:
- Cenário 1: dados sensíveis foram encontrados em uma carga de trabalho em que são esperados e estão devidamente protegidos.
- Cenário 2: dados sensíveis foram encontrados em uma carga de trabalho em que não eram esperados ou em que não há controles adequados.
- Cenário 3: dados sensíveis foram encontrados, mas precisam de mais investigação.
Cenário 1: dados sensíveis foram encontrados e estão devidamente protegidos
Embora esse cenário não exija uma ação específica, inclua os perfis de dados nos relatórios de auditoria e nos fluxos de trabalho de análise de segurança e continue monitorando as mudanças que podem colocar seus dados em risco.
Recomendamos fazer o seguinte:
Publique os perfis de dados em ferramentas para monitorar sua postura de segurança e investigar ameaças cibernéticas. Os perfis de dados podem ajudar a determinar a gravidade de uma ameaça ou vulnerabilidade de segurança que possa colocar seus dados sensíveis em risco. É possível exportar perfis de dados automaticamente para:
Publique os perfis dos dados no Knowledge Catalog ou em um sistema de inventário para acompanhar as métricas de perfil dos dados, além de outros metadados comerciais adequados. Para informações sobre como exportar perfis de dados automaticamente para o Knowledge Catalog, consulte Adicionar aspectos do Knowledge Catalog com base em insights de perfis de dados.
Cenário 2: dados sensíveis foram encontrados e não estão devidamente protegidos
Se a descoberta encontrar dados sensíveis em um recurso que não está devidamente protegido por controles de acesso, considere as recomendações descritas nesta seção.
Depois de estabelecer os controles e a postura de segurança de dados corretos, monitore as mudanças que podem colocar seus dados em risco. Consulte as recomendações no cenário 1.
Recomendações gerais
Considere fazer o seguinte:
Faça uma cópia desidentificada dos seus dados para mascarar ou tokenizar as colunas sensíveis para que seus analistas e engenheiros de dados ainda possam trabalhar com seus dados sem revelar identificadores sensíveis brutos, como informações de identificação pessoal (PII).
Para dados do Cloud Storage, é possível usar um recurso integrado na Proteção de Dados Sensíveis para fazer cópias desidentificadas.
Se você não precisar dos dados, considere excluí-los.
Recomendações para proteger dados do BigQuery
- Ajuste as permissões no nível da tabela usando o IAM.
Defina controles de acesso refinados no nível da coluna usando tags de política do BigQuery para restringir o acesso às colunas sensíveis e de alto risco. Esse recurso permite proteger essas colunas, permitindo o acesso ao restante da tabela.
Também é possível usar tags de política para ativar o mascaramento automático de dados, que pode fornecer dados parcialmente ofuscados aos usuários .
Use o recurso de segurança no nível da linha do BigQuery para ocultar ou mostrar determinadas linhas de dados, dependendo de um usuário ou grupo estar ou não em uma lista de permissões.
Desidentifique os dados do BigQuery no momento da consulta com funções remotas (UDF).
Recomendações para proteger dados do Cloud Storage
Aplique controles de acesso usando listas de controle de acesso .
Faça cópias desidentificadas dos seus dados do Cloud Storage.
Cenário 3: dados sensíveis foram encontrados, mas precisam de mais investigação
Em alguns casos, você pode receber resultados que exigem mais investigação. Por exemplo, um perfil dos dados pode especificar que uma coluna tem uma pontuação de texto livre alta com evidências de dados sensíveis. Uma pontuação de texto livre alta indica que os dados não têm uma estrutura previsível e podem conter instâncias intermitentes de dados sensíveis. Essa pode ser uma coluna de observações em que determinadas linhas contêm PII, como nomes, detalhes de contato ou identificadores emitidos pelo governo. Nesse caso, recomendamos que você defina controles de acesso adicionais na tabela e execute outras correções descritas no cenário 2. Além disso, recomendamos executar uma inspeção mais profunda e direcionada para identificar a extensão do risco.
O serviço de inspeção permite executar uma verificação completa de um único recurso, como uma tabela do BigQuery individual ou um bucket do Cloud Storage. Para fontes de dados que não são compatíveis diretamente com o serviço de inspeção, é possível exportar os dados para um bucket do Cloud Storage ou uma tabela do BigQuery e executar um job de inspeção nesse recurso. Por exemplo, se você tiver dados que precisam ser inspecionados em um banco de dados do Cloud SQL, exporte esses dados para um arquivo CSV ou AVRO no Cloud Storage e execute um job de inspeção.
Um job de inspeção localiza instâncias individuais de dados sensíveis, como um número de cartão de crédito no meio de uma frase em uma célula da tabela. Esse nível de detalhe pode ajudar você a entender que tipo de dados está presente em colunas não estruturadas ou em objetos de dados, incluindo arquivos de texto, PDFs, imagens e outros formatos de documentos avançados. Em seguida, corrija as descobertas usando qualquer uma das recomendações descritas no cenário 2.
Além das etapas recomendadas no cenário 2, considere tomar medidas para impedir que informações sensíveis entrem no armazenamento de dados de back-end.
Os métodos content
da API Cloud Data Loss Prevention podem aceitar dados de qualquer carga de trabalho ou aplicativo
para inspeção e mascaramento de dados em movimento. Por exemplo, seu aplicativo pode fazer o seguinte:
- Aceitar um comentário fornecido pelo usuário.
- Executar
content.deidentifypara desidentificar dados sensíveis dessa string. - Salvar a string desidentificada no armazenamento de back-end em vez da string original.
Resumo das práticas recomendadas
A tabela a seguir resume as práticas recomendadas neste documento:
| Desafio | Ação |
|---|---|
| Você quer saber que tipo de dados sua organização está armazenando. | Execute a descoberta no nível da organização, da pasta ou do projeto. |
| Você encontrou dados sensíveis em um recurso que já está protegido. | Monitore continuamente esse recurso executando a descoberta e exportando perfis automaticamente para o Security Command Center, o Google SecOps e o Knowledge Catalog. |
| Você encontrou dados sensíveis em um recurso que não está protegido. | Oculte ou mostre dados com base em quem está visualizando; use o IAM, a segurança no nível da coluna ou a segurança no nível da linha. Também é possível usar as ferramentas de desidentificação da Proteção de Dados Sensíveis para transformar ou remover os elementos sensíveis. |
| Você encontrou dados sensíveis e precisa investigar mais para entender a extensão do risco de dados. | Execute um job de inspeção no recurso. Também é possível impedir proativamente que dados sensíveis entrem no armazenamento de back-end usando os métodos síncronos content da API DLP, que processam dados quase em tempo real. |