
Sensitive Data Protection עוזר לכם למצוא, להבין ולנהל את המידע האישי הרגיש שקיים בתשתית שלכם. אחרי שסורקים את התוכן כדי למצוא מידע אישי רגיש באמצעות Sensitive Data Protection, יש כמה אפשרויות לפעולה עם תובנות מניתוח הנתונים. במאמר הזה נסביר איך להשתמש ביכולות של תכונות אחרות של Google Cloud Google Cloud, כמו BigQuery, Cloud SQL ו-Data Studio, כדי:
- אחסון תוצאות הסריקה של Sensitive Data Protection ישירות ב-BigQuery.
- יצירת דוחות על המיקום של מידע אישי רגיש בתשתית שלכם.
- הפעלת ניתוח SQL מפורט כדי להבין איפה מאוחסן מידע אישי רגיש ואיזה סוג מידע הוא.
- אוטומציה של התראות או פעולות שמופעלות על סמך קבוצה אחת או שילוב של ממצאים.
בנוסף, בנושא הזה יש דוגמה מלאה לשימוש ב-Sensitive Data Protection יחד עם תכונות אחרות של Google Cloud כדי לבצע את כל הפעולות האלה.
סריקה של קטגוריית אחסון
קודם כל, מריצים סריקה של הנתונים. בהמשך מופיע מידע בסיסי על סריקת מאגרי אחסון באמצעות Sensitive Data Protection. הוראות מלאות לסריקת מאגרי אחסון, כולל שימוש בספריות לקוח, מופיעות במאמר בדיקת אחסון ומסדי נתונים לזיהוי נתונים רגישים.
כדי להריץ פעולת סריקה במאגרGoogle Cloud , צריך ליצור אובייקט JSON שכולל את אובייקטי ההגדרות הבאים:
InspectJobConfig: הגדרת משימת הסריקה של Sensitive Data Protection, שכוללת:-
StorageConfig: מאגר האחסון שרוצים לסרוק. InspectConfig: הסבר על אופן הסריקה ומה לחפש. אפשר גם להשתמש בתבנית בדיקה כדי להגדיר את הבדיקה.-
Action: משימות לביצוע בסיום העבודה. זה יכול לכלול שמירת ממצאים בטבלה ב-BigQuery או פרסום הודעה ב-Pub/Sub.
-
בדוגמה הזו, סורקים קטגוריה של Cloud Storage שמות של אנשים, מספרי טלפון, מספרי תעודת זהות בארה"ב וכתובות אימייל. לאחר מכן שולחים את הממצאים לטבלה ב-BigQuery שמוקדשת לאחסון הפלט של Sensitive Data Protection. אפשר לשמור את ה-JSON הבא בקובץ או לשלוח אותו ישירות לשיטה create של המשאב DlpJob Sensitive Data Protection.
קלט JSON:
POST https://dlp.googleapis.com/v2/projects/[PROJECT_ID]/dlpJobs
{
"inspectJob":{
"inspectConfig":{
"infoTypes":[
{
"name":"PERSON_NAME"
},
{
"name":"PHONE_NUMBER"
},
{
"name":"US_SOCIAL_SECURITY_NUMBER"
},
{
"name":"EMAIL_ADDRESS"
}
],
"includeQuote":true
},
"storageConfig":{
"cloudStorageOptions":{
"fileSet":{
"url":"gs://[BUCKET_NAME]/**"
}
}
},
"actions":[
{
"saveFindings":{
"outputConfig":{
"table":{
"projectId":"[PROJECT_ID]",
"datasetId":"[DATASET_ID]",
"tableId":"[TABLE_ID]"
}
}
}
}
]
}
}
אם מציינים שני כוכביות (**) אחרי כתובת הקטגוריה של Cloud Storage (gs://[BUCKET_NAME]/**), נותנים להגדרת הסריקה הוראה לסרוק באופן רקורסיבי. הצבת כוכבית אחת (*) תורה לעבודה לסרוק רק את רמת הספרייה שצוינה ולא לעומק רב יותר.
הפלט יישמר בטבלה שצוינה במערך הנתונים ובפרויקט שצוינו. משימות עוקבות שמציינות את מזהה הטבלה הנתון מוסיפות ממצאים לאותה טבלה. אפשר גם להשמיט מפתח "tableId" אם רוצים להנחות את Sensitive Data Protection ליצור טבלה חדשה בכל פעם שהסריקה מופעלת.
אחרי ששולחים את ה-JSON הזה בבקשה ל-method projects.dlpJobs.create דרך כתובת ה-URL שצוינה, מקבלים את התגובה הבאה:
פלט JSON:
{
"name":"projects/[PROJECT_ID]/dlpJobs/[JOB_ID]",
"type":"INSPECT_JOB",
"state":"PENDING",
"inspectDetails":{
"requestedOptions":{
"snapshotInspectTemplate":{
},
"jobConfig":{
"storageConfig":{
"cloudStorageOptions":{
"fileSet":{
"url":"gs://[BUCKET_NAME]/**"
}
}
},
"inspectConfig":{
"infoTypes":[
{
"name":"PERSON_NAME"
},
{
"name":"PHONE_NUMBER"
},
{
"name":"US_SOCIAL_SECURITY_NUMBER"
},
{
"name":"EMAIL_ADDRESS"
}
],
"minLikelihood":"POSSIBLE",
"limits":{
},
"includeQuote":true
},
"actions":[
{
"saveFindings":{
"outputConfig":{
"table":{
"projectId":"[PROJECT_ID]",
"datasetId":"[DATASET_ID]",
"tableId":"[TABLE_ID]"
}
}
}
}
]
}
}
},
"createTime":"2018-11-19T21:09:07.926Z"
}
אחרי שהמשימה מסתיימת, הממצאים שלה נשמרים בטבלה ב-BigQuery שצוינה.
כדי לקבל את הסטטוס של המשימה, קוראים לשיטה projects.dlpJobs.get או שולחים בקשת GET לכתובת ה-URL הבאה, ומחליפים את [PROJECT_ID] במזהה הפרויקט ואת [JOB_ID] במזהה המשימה שמופיע בתגובה של Cloud Data Loss Prevention API לבקשה ליצירת המשימה (לפני מזהה המשימה יופיע i-):
GET https://dlp.googleapis.com/v2/projects/[PROJECT_ID]/dlpJobs/[JOB_ID]
עבור העבודה שיצרתם, הבקשה הזו מחזירה את ה-JSON הבא. שימו לב
שסיכום של תוצאות הסריקה מוחזר אחרי פרטי הבדיקה. אם הסריקה עדיין לא הסתיימה, המפתח "state" יציין "RUNNING".
פלט JSON:
{
"name":"projects/[PROJECT_ID]/dlpJobs/[JOB_ID]",
"type":"INSPECT_JOB",
"state":"DONE",
"inspectDetails":{
"requestedOptions":{
"snapshotInspectTemplate":{
},
"jobConfig":{
"storageConfig":{
"cloudStorageOptions":{
"fileSet":{
"url":"gs://[BUCKET_NAME]/**"
}
}
},
"inspectConfig":{
"infoTypes":[
{
"name":"PERSON_NAME"
},
{
"name":"PHONE_NUMBER"
},
{
"name":"US_SOCIAL_SECURITY_NUMBER"
},
{
"name":"EMAIL_ADDRESS"
}
],
"minLikelihood":"POSSIBLE",
"limits":{
},
"includeQuote":true
},
"actions":[
{
"saveFindings":{
"outputConfig":{
"table":{
"projectId":"[PROJECT_ID]",
"datasetId":"[DATASET_ID]",
"tableId":"[TABLE_ID]"
}
}
}
}
]
}
},
"result":{
"processedBytes":"536734051",
"totalEstimatedBytes":"536734051",
"infoTypeStats":[
{
"infoType":{
"name":"PERSON_NAME"
},
"count":"269679"
},
{
"infoType":{
"name":"EMAIL_ADDRESS"
},
"count":"256"
},
{
"infoType":{
"name":"PHONE_NUMBER"
},
"count":"7"
}
]
}
},
"createTime":"2018-11-19T21:09:07.926Z",
"startTime":"2018-11-19T21:10:20.660Z",
"endTime":"2018-11-19T22:07:39.725Z"
}
הפעלת ניתוח נתונים ב-BigQuery
אחרי שיצרתם טבלה ב-BigQuery עם התוצאות של הסריקה של Sensitive Data Protection, השלב הבא הוא להריץ ניתוח נתונים על הטבלה.
בצד ימין של מסוף Google Cloud Big Data, לוחצים על BigQuery. פותחים את הפרויקט ואת מערך הנתונים, ומאתרים את הטבלה החדשה שנוצרה.
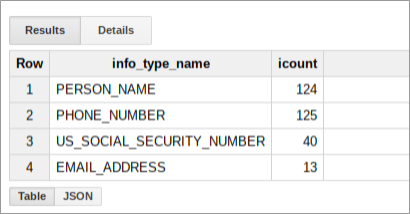
אתם יכולים להריץ שאילתות SQL בטבלה הזו כדי לקבל מידע נוסף על מה ששירות Sensitive Data Protection מצא בדלילת הנתונים שלכם. לדוגמה, מריצים את הפקודה הבאה כדי לספור את כל תוצאות הסריקה לפי infoType, אחרי שמחליפים את ערכי placeholder בערכים האמיתיים המתאימים:
SELECT
info_type.name,
COUNT(*) AS iCount
FROM
`[PROJECT_ID].[DATASET_ID].[TABLE_ID]`
GROUP BY
info_type.name
השאילתה הזו מחזירה סיכום של הממצאים לגבי הקטגוריה, שיכול להיראות כך:
יצירת דוח ב-Data Studio
בעזרת Data Studio אפשר ליצור דוחות בהתאמה אישית שמבוססים על טבלאות BigQuery. בקטע הזה, תיצרו דוח טבלה פשוט ב-Data Studio שמבוסס על ממצאים של Sensitive Data Protection שמאוחסנים ב-BigQuery.
- פותחים את Data Studio ומתחילים דוח חדש.
- לוחצים על יצירת מקור נתונים חדש.
- ברשימת המחברים, לוחצים על BigQuery. אם צריך, לוחצים על Authorize (אישור) כדי לאשר ל-Data Studio להתחבר לפרויקטים שלכם ב-BigQuery.
- עכשיו בוחרים את הטבלה שרוצים לחפש בה, ואז לוחצים על My Projects או על Shared Projects, בהתאם למיקום הפרויקט. מוצאים את הפרויקט, מערך הנתונים והטבלה ברשימות שבדף.
- לוחצים על Connect (חיבור) כדי להריץ את הדוח.
- לוחצים על הוספה לדוח.
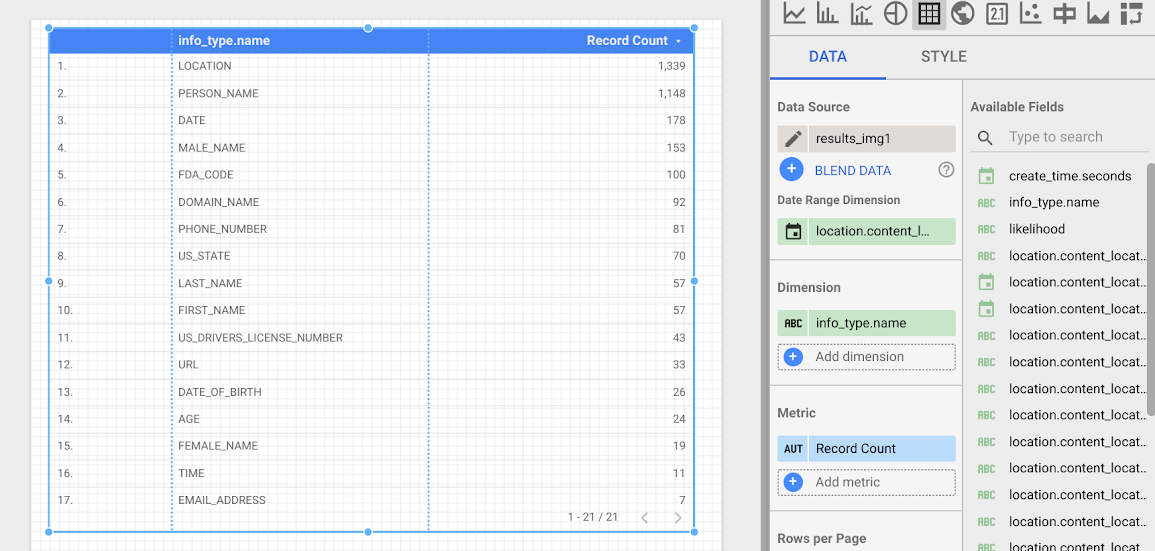
עכשיו תיצור טבלה שתציג את השכיחות של כל infoType. בוחרים בשדה info_type.name כמאפיין. הטבלה שמתקבלת תיראה כך:
השלבים הבאים
זו רק ההתחלה של מה שאפשר להציג באופן חזותי באמצעות Data Studio והפלט של Sensitive Data Protection. אפשר להוסיף עוד רכיבים של תרשימים ומסננים של פירוט כדי ליצור לוחות בקרה ודוחות. מידע נוסף על מה שזמין ב-Data Studio מופיע במאמר סקירה כללית על המוצר Data Studio.