
如果您已将敏感数据发现服务配置为将所有成功生成的数据剖析文件发送到 BigQuery,则可以查询这些数据剖析文件,以深入了解您的数据。您还可以使用数据洞察等可视化工具来构建根据您的业务需求量身定制的自定义报告。或者,您也可以使用 Sensitive Data Protection 提供的预制报告,根据需要对其进行调整并分享。
本页提供了一些 SQL 查询示例,可用于详细了解数据配置文件。本文还介绍了如何在数据洞察中直观呈现数据配置文件。
如需详细了解数据剖析文件,请参阅敏感数据发现概览。
准备工作
本页面假设您已在组织、文件夹或项目级配置了分析。在发现扫描配置中,确保已启用将数据分析副本保存到 BigQuery 操作。如需详细了解如何创建发现扫描配置,请参阅创建扫描配置。
输出表
在本文档中,包含导出数据剖析的表称为输出表。
确保您已准备好输出表的项目 ID、数据集 ID 和表 ID。您需要它们来执行本页面上的过程。
latest 视图
当 Sensitive Data Protection 将数据分析结果导出到输出表时,还会创建 latest 视图。此视图是一个预过滤的虚拟表,仅包含数据配置文件的最新快照。latest 视图与输出表具有相同的架构,因此您可以在 SQL 查询和数据洞察报告中交替使用这两个视图。结果可能会有所不同,因为输出表包含较旧的数据剖析快照。
latest 视图与输出表存储在同一位置。其名称的格式如下:
OUTPUT_TABLE_latest_VERSION
替换以下内容:
- OUTPUT_TABLE:包含导出的数据分析的表的 ID。
- VERSION:视图的版本号。
例如,如果输出表的名称为 table-profile,则 latest 视图的名称类似于 table-profile_latest_v1。

在 SQL 查询中使用 latest 视图时,请使用该视图的全名,其中包含项目 ID、数据集 ID、表 ID 和后缀,例如 myproject.mydataset.table-profile_latest_v1。
PROJECT_ID.DATASET_ID.OUTPUT_TABLE_latest_VERSION
选择输出表和 latest 视图
latest 视图仅包含最新的数据分析快照,而输出表包含所有数据分析快照,包括过时的快照。例如,对输出表的查询可以返回同一列的多个列数据分析,每次对该列进行分析时都会返回一个。
在 SQL 查询或数据洞察报告中选择使用输出表还是 latest 视图时,请考虑以下因素:
如果您有已重新分析的数据资产,并且只想查看最新的分析结果,而不希望查看之前的版本,那么
latest视图会非常有用。也就是说,您希望查看分析数据的当前状态。如果您想查看分析数据的历史记录,输出表会非常有用。例如,您想确定组织是否曾经存储过特定的 infoType,或者想查看特定数据分析经历的更改。
示例 SQL 查询
本部分提供了在分析数据配置文件时可以使用的示例查询。如需运行这些查询,请参阅运行交互式查询。
在以下示例中,将 TABLE_OR_VIEW 替换为以下任一内容:
- 输出表的名称,即包含导出的数据剖析的表,例如
myproject.mydataset.table-profile。 - 输出表的
latest视图的名称,例如myproject.mydataset.table-profile_latest_v1。
无论采用哪种方式,您都必须添加项目 ID 和数据集 ID。
如需了解详情,请参阅此页面上的在输出表和 latest 视图之间进行选择。
如需排查遇到的任何错误,请参阅错误消息。
列出所有自由文本得分较高且有其他 infoType 匹配证据的列
SELECT
column_profile.table_full_resource,
column_profile.COLUMN,
other_matches.info_type.name,
column_profile.profile_last_generated
FROM
`TABLE_OR_VIEW`
LEFT JOIN UNNEST(column_profile.other_matches) AS other_matches
WHERE
column_profile.free_text_score = 1
AND ( column_profile.column_info_type.info_type.name>""
OR ARRAY_LENGTH(column_profile.other_matches)>0 )
如需了解如何修正这些发现结果,请参阅缓解数据风险的建议策略。
如需详细了解自由文本得分和其他 infoType 指标,请参阅列数据剖析文件。
列出包含信用卡号列的所有表
SELECT
column_profile.table_full_resource,
column_profile.profile_last_generated
FROM
`TABLE_OR_VIEW`
WHERE
column_profile.column_info_type.info_type.name="CREDIT_CARD_NUMBER"
CREDIT_CARD_NUMBER 是一种表示信用卡号的内置 infoType。
如需了解如何修正这些发现结果,请参阅缓解数据风险的建议策略。
列出包含信用卡号、美国社会保障号和人名的表配置文件
SELECT
table_full_resource,
COUNT(*) AS count_findings
FROM (
SELECT
DISTINCT column_profile.table_full_resource,
column_profile.column_info_type.info_type.name
FROM
`TABLE_OR_VIEW`
WHERE
column_profile.column_info_type.info_type.name IN ('PERSON_NAME',
'CREDIT_CARD_NUMBER',
'US_SOCIAL_SECURITY_NUMBER')
ORDER BY
column_profile.table_full_resource ) ot1
GROUP BY
table_full_resource
#increase this number to match the total distinct infoTypes that must be present
HAVING
count_findings>=3
此查询使用以下内置 infoType:
CREDIT_CARD_NUMBER:表示信用卡号PERSON_NAME:表示人员的全名US_SOCIAL_SECURITY_NUMBER表示美国社会保障号
如需了解如何修正这些发现结果,请参阅缓解数据风险的建议策略。
列出敏感度得分为 SENSITIVITY_HIGH 的存储分区
SELECT file_store_profile.file_store_path, file_store_profile.resource_visibility, file_store_profile.sensitivity_score
FROM `TABLE_OR_VIEW`
WHERE file_store_profile.sensitivity_score.score ='SENSITIVITY_HIGH'
;
如需了解详情,请参阅文件存储区数据配置文件。
列出所有扫描到的敏感度得分不低于 SENSITIVITY_HIGH 的存储桶路径、集群和文件扩展名
SELECT file_store_profile.file_store_path, summaries.file_cluster_type.cluster, STRING_AGG(scanned_file_extensions.file_extension) AS scanned_extensions, file_store_profile.profile_last_generated.timestamp
FROM `TABLE_OR_VIEW`
LEFT JOIN UNNEST(file_store_profile.file_cluster_summaries) as summaries
LEFT JOIN UNNEST(summaries.file_store_info_type_summaries) as info_types
LEFT JOIN UNNEST(summaries.file_extensions_scanned) as scanned_file_extensions
WHERE file_store_profile.data_source_type.data_source = 'google/storage/bucket'
AND summaries.sensitivity_score.score ='SENSITIVITY_HIGH'
GROUP BY 1, 2, 4
;
如需了解详情,请参阅文件存储区数据配置文件。
列出检测到信用卡号的所有扫描过的存储桶路径、集群和文件扩展名
SELECT file_store_profile.file_store_path, summaries.file_cluster_type.cluster, STRING_AGG(scanned_file_extensions.file_extension) AS scanned_extensions
FROM `TABLE_OR_VIEW`
LEFT JOIN UNNEST(file_store_profile.file_cluster_summaries) as summaries
LEFT JOIN UNNEST(summaries.file_store_info_type_summaries) as info_types
LEFT JOIN UNNEST(summaries.file_extensions_scanned) as scanned_file_extensions
WHERE file_store_profile.data_source_type.data_source = 'google/storage/bucket'
AND info_types.info_type.name='CREDIT_CARD_NUMBER'
GROUP BY 1, 2
;
CREDIT_CARD_NUMBER 是一种表示信用卡号的内置 infoType。
如需了解详情,请参阅文件存储区数据配置文件。
列出检测到信用卡号、人名或美国社会保障号的所有扫描到的存储桶路径、集群和文件扩展名
SELECT file_store_profile.file_store_path, summaries.file_cluster_type.cluster, STRING_AGG(scanned_file_extensions.file_extension) AS scanned_extensions
FROM `TABLE_OR_VIEW`
LEFT JOIN UNNEST(file_store_profile.file_cluster_summaries) as summaries
LEFT JOIN UNNEST(summaries.file_store_info_type_summaries) as info_types
LEFT JOIN UNNEST(summaries.file_extensions_scanned) as scanned_file_extensions
WHERE file_store_profile.data_source_type.data_source = 'google/storage/bucket'
AND info_types.info_type.name IN ('CREDIT_CARD_NUMBER', 'PERSON_NAME', 'US_SOCIAL_SECURITY_NUMBER')
GROUP BY 1, 2
;
此查询使用以下内置 infoType:
CREDIT_CARD_NUMBER:表示信用卡号PERSON_NAME:表示人员的全名US_SOCIAL_SECURITY_NUMBER表示美国社会保障号
如需了解详情,请参阅文件存储区数据配置文件。
在数据洞察中使用数据剖析文件
如需在数据洞察中直观呈现数据概况,您可以使用预制报告,也可以自行创建报告。
使用预制报告
Sensitive Data Protection 提供了一份预先制作的数据洞察报告,其中重点介绍了数据分析结果的丰富洞见。Sensitive Data Protection 信息中心是一份多页报告,可让您快速了解数据剖析文件的概况,包括按风险、按 infoType 和按位置细分的数据。探索其他标签页,查看按地理区域和姿势风险划分的视图,或展开细目查看具体指标。您可以直接使用此预建报告,也可以根据需要对其进行自定义。这是预建报告的推荐版本。
如需查看包含您的数据的预建报告,请在以下网址中输入所需的值。然后,将生成的网址复制到浏览器中。
https://lookerstudio.google.com/c/u/0/reporting/create?c.reportId=c9826374-e016-4c96-a495-7281328375c6&ds.connector=BIG_QUERY&ds.projectId=PROJECT_ID&ds.datasetId=DATASET_ID&ds.tableId=TABLE_OR_VIEW&ds.type=TABLE&ds.useFreshSchema=false
替换以下内容:
- PROJECT_ID:包含输出表的项目。
- DATASET_ID:包含输出表的数据集。
TABLE_OR_VIEW:以下任一值:
- 输出表的名称,即包含导出的数据剖析的表,例如
myproject.mydataset.table-profile。 - 输出表的
latest视图的名称,例如myproject.mydataset.table-profile_latest_v1。
如需了解详情,请参阅本页面上的选择输出表和
latest视图。- 输出表的名称,即包含导出的数据剖析的表,例如
数据洞察可能需要几分钟时间才能加载包含您数据的报告。如果您遇到错误或报告无法加载,请参阅本页中的排查预建报告的错误。
在以下示例中,信息中心显示,低敏感度和高敏感度数据分布在全球多个国家/地区。
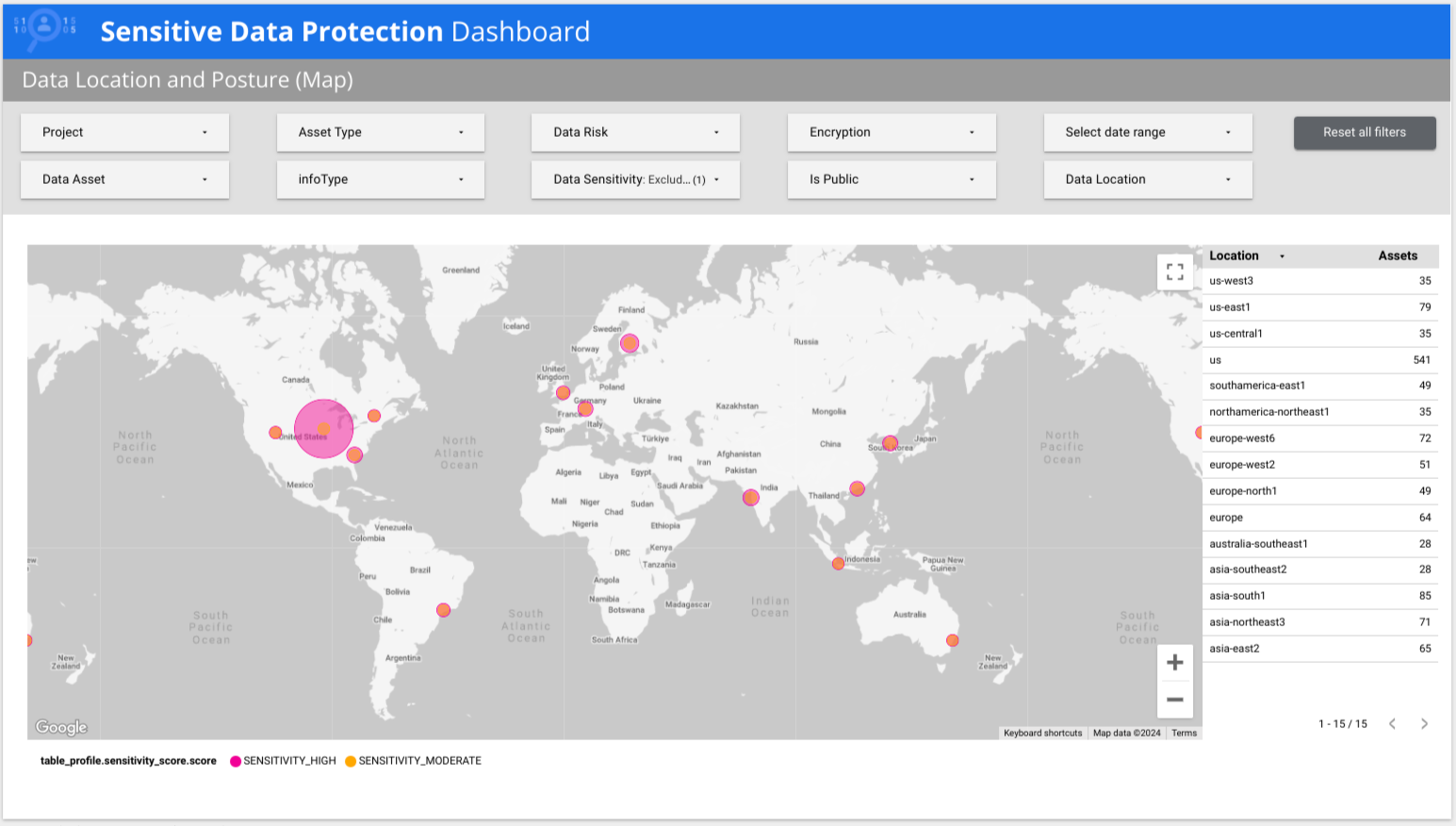
预制报告的早期版本
预建报告的第一个版本仍可在以下地址查看:
https://lookerstudio.google.com/c/u/0/reporting/create?c.reportId=907a2b73-ffe4-40b2-b9a1-c2aa0bbd69fd&ds.connector=BIG_QUERY&ds.projectId=PROJECT_ID&ds.datasetId=DATASET_ID&ds.tableId=TABLE_OR_VIEW&ds.type=TABLE&ds.useFreshSchema=false
创建报告
利用数据洞察,您可以创建交互式报告。在本部分中,您将在数据洞察中创建一个简单的表格报告,它基于导出到 BigQuery 输出表中的数据配置文件。
确保您已准备好输出表或 latest 视图的项目 ID、数据集 ID 和表 ID。您需要这些权限才能执行此程序。
此示例展示了如何创建包含一个表格的报告,该表格显示了数据配置文件中报告的每个 infoType 及其对应的频次。
一般来说,通过数据洞察访问 BigQuery 时会产生 BigQuery 使用费。如需了解详情,请参阅使用数据洞察直观呈现 BigQuery 数据。
如需创建报告,请执行以下操作:
- 打开数据洞察并登录。
- 点击空白报告。
- 在连接到数据标签页上,点击 BigQuery 卡。
- 如果出现提示,请授权数据洞察访问您的 BigQuery 项目。
连接到 BigQuery 数据:
- 在项目部分,选择包含输出表的项目。您可以在近期的项目、我的项目和共享的项目标签页中搜索项目。
- 在数据集部分,选择包含输出表的数据集。
对于表,请选择输出表或输出表的
latest视图。如需了解详情,请参阅本页上的在输出表和
latest视图之间进行选择。点击 Add(添加)。
在随即显示的对话框中,点击添加到报告。
如需添加一个表格,其中显示了报告的每种 infoType 及其对应的频次(记录数),请按以下步骤操作:
- 点击添加图表。
- 选择表格样式。
点击要放置图表的区域。
图表以表格格式显示。
根据需要调整表格大小。
只要选中表格,其属性就会显示在图表窗格中。
在图表窗格的设置标签页中,移除所有预先选择的维度和指标。
对于维度,请添加
column_profile.column_info_type.info_type.name或file_store_profile.file_cluster_summaries.file_store_info_type_summaries.info_type.name。这些示例提供了列级和文件集群级的数据。您也可以尝试其他维度。例如,您可以使用表级和存储桶级维度。
对于指标,添加记录数。
生成的表格如下所示:

详细了解数据洞察中的表格。
排查预建报告中的错误
如果您在加载预建报告时看到任何错误、缺少控件或缺少图表,请确保预建报告使用的是最新字段:
如果预建报告已连接到输出表,请确认该表已附加到有效的发现扫描配置。如需查看扫描配置的设置,请参阅查看扫描配置。
如果预建报告已关联到
latest视图,请确认该视图是否仍然存在于 BigQuery 中。如果存在,请尝试更改视图。或者,复制该视图,然后将预建报告与该副本相关联。如需详细了解latest视图,请参阅本页面上的latest视图。
如果您在尝试上述步骤后仍遇到错误,请与 Cloud Customer Care联系。
后续步骤
了解您可以采取哪些措施来修复数据分析的发现结果。