
Si vous avez configuré le service de découverte des données sensibles pour envoyer tous les profils de données générés à BigQuery, vous pouvez interroger ces profils pour obtenir des insights sur vos données. Vous pouvez également utiliser des outils de visualisation tels que Data Studio pour créer des rapports personnalisés adaptés à vos besoins commerciaux. Vous pouvez également utiliser un rapport prédéfini fourni par Sensitive Data Protection, l'ajuster et le partager selon vos besoins.
Cette page fournit des exemples de requêtes SQL que vous pouvez utiliser pour en savoir plus sur vos profils de données. Il vous explique également comment visualiser les profils de données dans Data Studio.
Pour en savoir plus sur les profils de données, consultez Présentation de la découverte de données sensibles.
Avant de commencer
Cette page suppose que vous avez configuré le profilage au niveau de l'organisation, du dossier ou du projet. Dans la configuration de votre analyse de découverte, assurez-vous que l'action Enregistrer des copies des profils de données dans BigQuery est activée. Pour savoir comment créer une configuration d'analyse de découverte, consultez Créer une configuration d'analyse.
Table de sortie
Dans ce document, la table contenant les profils de données exportés est appelée table de sortie.
Assurez-vous d'avoir à portée de main l'ID du projet, l'ID de l'ensemble de données et l'ID de la table de sortie. Vous en aurez besoin pour suivre les procédures décrites sur cette page.
Vue latest
Lorsque Sensitive Data Protection exporte des profils de données vers votre table de sortie, il crée également la vue latest. Cette vue est une table virtuelle préfiltrée qui n'inclut que les derniers instantanés de vos profils de données. La vue latest a le même schéma que la table de sortie. Vous pouvez donc utiliser les deux de manière interchangeable dans vos requêtes SQL et vos rapports Data Studio. Les résultats peuvent être différents, car le tableau de sortie contient des instantanés plus anciens des profils de données.
La vue latest est stockée au même emplacement que la table de sortie. Son nom est au format suivant :
OUTPUT_TABLE_latest_VERSION
Remplacez les éléments suivants :
- OUTPUT_TABLE : ID de la table contenant les profils de données exportés.
- VERSION : numéro de version de la vue.
Par exemple, si le nom de votre table de sortie est table-profile, la vue latest porte un nom tel que table-profile_latest_v1.

Lorsque vous utilisez la vue latest dans des requêtes SQL, utilisez son nom complet, qui inclut l'ID du projet, l'ID de l'ensemble de données, l'ID de la table et le suffixe. Par exemple, myproject.mydataset.table-profile_latest_v1.
PROJECT_ID.DATASET_ID.OUTPUT_TABLE_latest_VERSION
Choisir entre la table de sortie et la vue latest
La vue latest n'inclut que les derniers instantanés de profil de données, tandis que la table de sortie contient tous les instantanés de profil de données, y compris ceux qui sont obsolètes. Par exemple, une requête sur la table de sortie peut renvoyer plusieurs profils de données de colonne pour la même colonne (un pour chaque fois que cette colonne a été profilée).
Lorsque vous choisissez entre l'utilisation de la table de sortie et de la vue latest dans vos requêtes SQL ou vos rapports Data Studio, tenez compte des points suivants :
La vue
latestest utile si vous avez des composants de données qui ont été re-profilés et que vous ne souhaitez voir que les profils les plus récents, et non leurs versions antérieures. En d'autres termes, vous souhaitez voir l'état actuel de vos données profilées.La table de sortie est utile si vous souhaitez obtenir une vue historique de vos données profilées. Par exemple, vous essayez de déterminer si votre organisation a déjà stocké un infoType spécifique ou vous souhaitez voir les modifications apportées à un profil de données particulier.
Exemples de requêtes SQL
Cette section fournit des exemples de requêtes que vous pouvez utiliser lorsque vous analysez des profils de données. Pour exécuter ces requêtes, consultez Exécuter des requêtes interactives.
Dans les exemples suivants, remplacez TABLE_OR_VIEW par l'une des options suivantes :
- Nom de la table de sortie, qui est la table contenant les profils de données exportés (par exemple,
myproject.mydataset.table-profile). - Nom de la vue
latestde la table de sortie (par exemple,myproject.mydataset.table-profile_latest_v1).
Dans les deux cas, vous devez inclure l'ID du projet et l'ID de l'ensemble de données.
Pour en savoir plus, consultez Choisir entre la table de sortie et la vue latest sur cette page.
Pour résoudre les erreurs que vous rencontrez, consultez la page Messages d'erreur.
Lister toutes les colonnes qui ont un score de texte libre élevé et des correspondances avec d'autres infoTypes
SELECT
column_profile.table_full_resource,
column_profile.COLUMN,
other_matches.info_type.name,
column_profile.profile_last_generated
FROM
`TABLE_OR_VIEW`
LEFT JOIN UNNEST(column_profile.other_matches) AS other_matches
WHERE
column_profile.free_text_score = 1
AND ( column_profile.column_info_type.info_type.name>""
OR ARRAY_LENGTH(column_profile.other_matches)>0 )
Pour savoir comment corriger ces résultats, consultez Stratégies recommandées pour atténuer les risques liés aux données.
Pour en savoir plus sur les métriques Score de texte libre et Autres infoTypes, consultez Profils de données de colonne.
Lister toutes les tables contenant une colonne de numéros de carte de crédit
SELECT
column_profile.table_full_resource,
column_profile.profile_last_generated
FROM
`TABLE_OR_VIEW`
WHERE
column_profile.column_info_type.info_type.name="CREDIT_CARD_NUMBER"
CREDIT_CARD_NUMBER est un infoType intégré qui représente un numéro de carte de crédit.
Pour savoir comment corriger ces résultats, consultez Stratégies recommandées pour atténuer les risques liés aux données.
Lister les profils de table contenant des colonnes de numéros de carte de crédit, de numéros de sécurité sociale américains et de noms de personnes
SELECT
table_full_resource,
COUNT(*) AS count_findings
FROM (
SELECT
DISTINCT column_profile.table_full_resource,
column_profile.column_info_type.info_type.name
FROM
`TABLE_OR_VIEW`
WHERE
column_profile.column_info_type.info_type.name IN ('PERSON_NAME',
'CREDIT_CARD_NUMBER',
'US_SOCIAL_SECURITY_NUMBER')
ORDER BY
column_profile.table_full_resource ) ot1
GROUP BY
table_full_resource
#increase this number to match the total distinct infoTypes that must be present
HAVING
count_findings>=3
Cette requête utilise les infoTypes intégrés suivants :
CREDIT_CARD_NUMBER: représente un numéro de carte de créditPERSON_NAME: représente le nom complet d'une personneUS_SOCIAL_SECURITY_NUMBERreprésente un numéro de sécurité sociale américain.
Pour savoir comment corriger ces résultats, consultez Stratégies recommandées pour atténuer les risques liés aux données.
Lister les buckets dont le score de sensibilité est SENSITIVITY_HIGH
SELECT file_store_profile.file_store_path, file_store_profile.resource_visibility, file_store_profile.sensitivity_score
FROM `TABLE_OR_VIEW`
WHERE file_store_profile.sensitivity_score.score ='SENSITIVITY_HIGH'
;
Pour en savoir plus, consultez Profils de données du File Store.
Lister tous les chemins de bucket, clusters et extensions de fichier analysés où le score de sensibilité est SENSITIVITY_HIGH
SELECT file_store_profile.file_store_path, summaries.file_cluster_type.cluster, STRING_AGG(scanned_file_extensions.file_extension) AS scanned_extensions, file_store_profile.profile_last_generated.timestamp
FROM `TABLE_OR_VIEW`
LEFT JOIN UNNEST(file_store_profile.file_cluster_summaries) as summaries
LEFT JOIN UNNEST(summaries.file_store_info_type_summaries) as info_types
LEFT JOIN UNNEST(summaries.file_extensions_scanned) as scanned_file_extensions
WHERE file_store_profile.data_source_type.data_source = 'google/storage/bucket'
AND summaries.sensitivity_score.score ='SENSITIVITY_HIGH'
GROUP BY 1, 2, 4
;
Pour en savoir plus, consultez Profils de données du File Store.
Liste tous les chemins de bucket, clusters et extensions de fichier analysés où des numéros de carte de paiement ont été détectés
SELECT file_store_profile.file_store_path, summaries.file_cluster_type.cluster, STRING_AGG(scanned_file_extensions.file_extension) AS scanned_extensions
FROM `TABLE_OR_VIEW`
LEFT JOIN UNNEST(file_store_profile.file_cluster_summaries) as summaries
LEFT JOIN UNNEST(summaries.file_store_info_type_summaries) as info_types
LEFT JOIN UNNEST(summaries.file_extensions_scanned) as scanned_file_extensions
WHERE file_store_profile.data_source_type.data_source = 'google/storage/bucket'
AND info_types.info_type.name='CREDIT_CARD_NUMBER'
GROUP BY 1, 2
;
CREDIT_CARD_NUMBER est un infoType intégré qui représente un numéro de carte de crédit.
Pour en savoir plus, consultez Profils de données du File Store.
Liste de tous les chemins d'accès aux buckets, des clusters et des extensions de fichier analysés dans lesquels un numéro de carte de crédit, un nom de personne ou un numéro de sécurité sociale américain a été détecté
SELECT file_store_profile.file_store_path, summaries.file_cluster_type.cluster, STRING_AGG(scanned_file_extensions.file_extension) AS scanned_extensions
FROM `TABLE_OR_VIEW`
LEFT JOIN UNNEST(file_store_profile.file_cluster_summaries) as summaries
LEFT JOIN UNNEST(summaries.file_store_info_type_summaries) as info_types
LEFT JOIN UNNEST(summaries.file_extensions_scanned) as scanned_file_extensions
WHERE file_store_profile.data_source_type.data_source = 'google/storage/bucket'
AND info_types.info_type.name IN ('CREDIT_CARD_NUMBER', 'PERSON_NAME', 'US_SOCIAL_SECURITY_NUMBER')
GROUP BY 1, 2
;
Cette requête utilise les infoTypes intégrés suivants :
CREDIT_CARD_NUMBER: représente un numéro de carte de créditPERSON_NAME: représente le nom complet d'une personneUS_SOCIAL_SECURITY_NUMBERreprésente un numéro de sécurité sociale américain.
Pour en savoir plus, consultez Profils de données du File Store.
Créer une vue qui affiche des exemples de résultats à partir des profils de données les plus récents uniquement
Par défaut, la vue latest du tableau des exemples de résultats inclut les exemples de résultats les plus récents détectés pour chaque élément de données. Si un profil de ressource de données est recréé et que le nouveau profil ne contient aucun résultat, la vue latest "Exemples de résultats" conserve les résultats de l'ancien profil.
Pour n'afficher que des exemples de résultats du profil le plus récent de chaque asset de données (afin que les assets sans résultats dans leur profil récent n'en affichent aucun), créez une vue personnalisée qui joint la table des exemples de résultats à la vue latest de la table des profils de données.
Exemple de requête pour les profils de données de table
CREATE OR REPLACE VIEW
`PROJECT_ID.DATASET_ID.VIEW_ID` AS
SELECT
findings_table.*
FROM
`FINDINGS_TABLE_PROJECT_ID.FINDINGS_TABLE_DATASET_ID.FINDINGS_TABLE_ID` AS findings_table
INNER JOIN
`PROFILES_TABLE_PROJECT_ID.PROFILES_TABLE_DATASET_ID.PROFILES_TABLE_ID_latest_v1` AS profiles_table
ON
findings_table.data_profile_resource_name = profiles_table.table_profile.name
AND findings_table.timestamp.timestamp = profiles_table.table_profile.profile_last_generated.timestamp
;
Exemple de requête pour les profils de données du magasin de fichiers
CREATE OR REPLACE VIEW
`PROJECT_ID.DATASET_ID.VIEW_ID` AS
SELECT
findings_table.*
FROM
`FINDINGS_TABLE_PROJECT_ID.FINDINGS_TABLE_DATASET_ID.FINDINGS_TABLE_ID` AS findings_table
INNER JOIN
`PROFILES_TABLE_PROJECT_ID.PROFILES_TABLE_DATASET_ID.PROFILES_TABLE_ID_latest_v1` AS profiles_table
ON
findings_table.data_profile_resource_name = profiles_table.file_store_profile.name
AND findings_table.timestamp.timestamp = profiles_table.file_store_profile.profile_last_generated.timestamp
;
Utiliser des profils de données dans Data Studio
Pour visualiser vos profils de données dans Data Studio, vous pouvez utiliser un rapport prédéfini ou créer le vôtre.
Utiliser un rapport prédéfini
Sensitive Data Protection fournit un rapport Data Studio prédéfini qui met en évidence les insights détaillés des profils de données. Le tableau de bord "Protection des données sensibles" est un rapport de plusieurs pages qui vous offre une vue d'ensemble rapide de vos profils de données, y compris des répartitions par risque, par infoType et par emplacement. Explorez les autres onglets pour afficher les vues par région géographique et par risque de posture, ou pour afficher le détail de métriques spécifiques. Vous pouvez utiliser ce rapport prédéfini tel quel ou le personnaliser selon vos besoins. Il s'agit de la version recommandée du rapport prédéfini.
Pour afficher le rapport prédéfini avec vos données, saisissez les valeurs requises dans l'URL suivante. Copiez ensuite l'URL obtenue dans votre navigateur.
https://lookerstudio.google.com/c/u/0/reporting/create?c.reportId=c9826374-e016-4c96-a495-7281328375c6&ds.connector=BIG_QUERY&ds.projectId=PROJECT_ID&ds.datasetId=DATASET_ID&ds.tableId=TABLE_OR_VIEW&ds.type=TABLE&ds.useFreshSchema=false
Remplacez les éléments suivants :
- PROJECT_ID : projet contenant la table de sortie.
- DATASET_ID : ensemble de données contenant la table de sortie.
TABLE_OR_VIEW : l'une des options suivantes :
- Nom de la table de sortie, qui est la table contenant les profils de données exportés (par exemple,
myproject.mydataset.table-profile). - Nom de la vue
latestde la table de sortie (par exemple,myproject.mydataset.table-profile_latest_v1).
Pour en savoir plus, consultez la section Choisir entre la table de sortie et la vue
latestsur cette page.- Nom de la table de sortie, qui est la table contenant les profils de données exportés (par exemple,
Le chargement du rapport avec vos données dans Data Studio peut prendre quelques minutes. Si vous rencontrez des erreurs ou si le rapport ne se charge pas, consultez Résoudre les problèmes liés au rapport prédéfini sur cette page.
Dans l'exemple suivant, le tableau de bord montre que des données à sensibilité faible et élevée sont présentes dans plusieurs pays du monde.
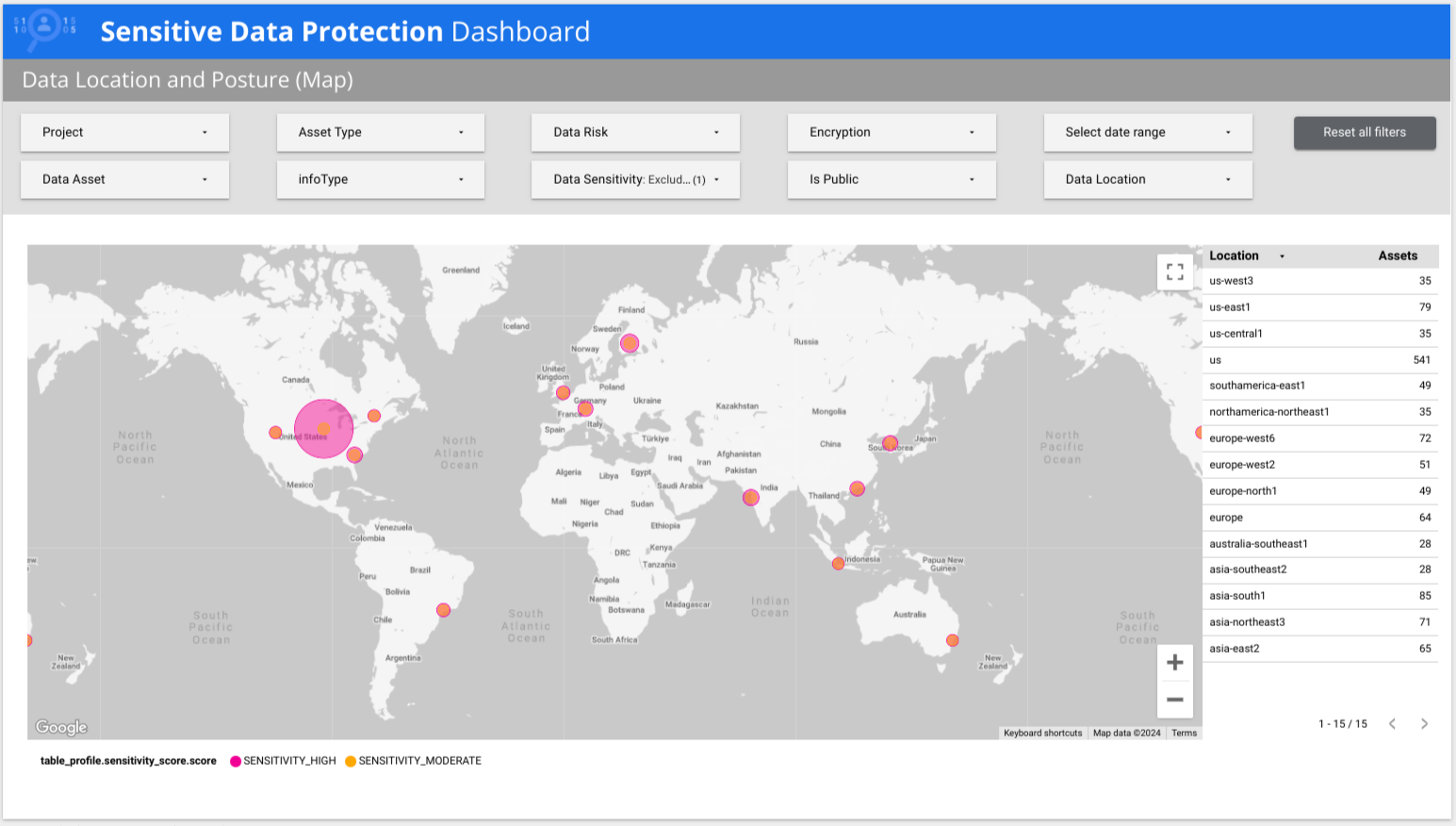
Version antérieure du rapport prédéfini
La première version du rapport prédéfini est toujours disponible à l'adresse suivante :
https://lookerstudio.google.com/c/u/0/reporting/create?c.reportId=907a2b73-ffe4-40b2-b9a1-c2aa0bbd69fd&ds.connector=BIG_QUERY&ds.projectId=PROJECT_ID&ds.datasetId=DATASET_ID&ds.tableId=TABLE_OR_VIEW&ds.type=TABLE&ds.useFreshSchema=false
Créer un rapport
Data Studio vous permet de créer des rapports interactifs. Dans cette section, vous allez créer dans Data Studio un rapport sous forme de tableau simple, basé sur les profils de données exportés vers votre table de sortie dans BigQuery.
Assurez-vous d'avoir à portée de main l'ID du projet, l'ID de l'ensemble de données et l'ID de la table de sortie ou de la vue latest. Vous en aurez besoin pour effectuer cette procédure.
Cet exemple vous montre comment créer un rapport contenant un tableau qui affiche chaque infoType signalé dans vos profils de données et sa fréquence correspondante.
En général, l'accès à BigQuery via Data Studio entraîne des frais d'utilisation BigQuery. Pour en savoir plus, consultez la page Visualiser des données BigQuery à l'aide de Data Studio.
Pour créer un rapport :
- Ouvrez Data Studio et connectez-vous.
- Cliquez sur Rapport vide.
- Dans l'onglet Se connecter aux données, cliquez sur la fiche BigQuery.
- Si vous y êtes invité, autorisez Data Studio à accéder à vos projets BigQuery.
Connectez-vous à vos données BigQuery :
- Pour Projet, sélectionnez le projet contenant la table de sortie. Vous pouvez rechercher le projet dans les onglets Projets récents, Mes projets et Projets partagés.
- Pour Ensemble de données, sélectionnez l'ensemble de données contenant la table de sortie.
Pour Table, sélectionnez la table de sortie ou la vue
latestde la table de sortie.Pour en savoir plus, consultez Choisir entre la table de sortie et la vue
latestsur cette page.Cliquez sur Ajouter.
Dans la boîte de dialogue qui s'affiche, cliquez sur Ajouter au rapport.
Pour ajouter un tableau qui affiche chaque infoType signalé et sa fréquence correspondante (nombre d'enregistrements), procédez comme suit :
- Cliquez sur Ajouter un graphique.
- Sélectionnez un style de tableau.
Cliquez sur la zone où vous souhaitez positionner le graphique.
Le graphique s'affiche sous forme de tableau.
Redimensionnez le tableau si nécessaire.
Tant que le tableau est sélectionné, ses propriétés s'affichent dans le volet Graphique.
Dans le volet Graphique, dans l'onglet Configurer, supprimez les dimensions et métriques présélectionnées.
Pour Dimension, ajoutez
column_profile.column_info_type.info_type.nameoufile_store_profile.file_cluster_summaries.file_store_info_type_summaries.info_type.name.Ces exemples fournissent des données au niveau des colonnes et des clusters de fichiers. Vous pouvez également essayer d'autres dimensions. Par exemple, vous pouvez utiliser des dimensions au niveau des tables et des buckets.
Dans Métrique, ajoutez Nombre d'enregistrements.
Le tableau obtenu ressemble à ceci :
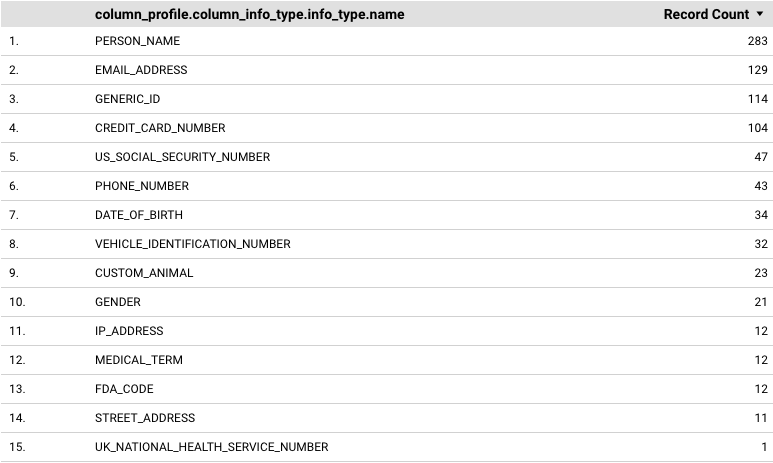
En savoir plus sur les tableaux dans Data Studio
Résoudre les problèmes liés au rapport prédéfini
Si vous constatez des erreurs, des commandes manquantes ou des graphiques manquants lors du chargement du rapport prédéfini, assurez-vous qu'il utilise les derniers champs :
Si votre rapport prédéfini est associé à la table de sortie, vérifiez que cette table est associée à une configuration d'analyse de découverte active. Pour afficher les paramètres de vos configurations d'analyse, consultez Afficher une configuration d'analyse.
Si votre rapport prédéfini est associé à la vue
latest, vérifiez que cette vue est toujours présente dans BigQuery. Si elle est présente, essayez de modifier la vue. Vous pouvez également copier la vue et associer le rapport prédéfini à cette copie. Pour en savoir plus sur la vuelatest, consultez la section Vuelatestsur cette page.
Si des erreurs persistent après avoir suivi ces étapes, contactez l'assistance client Cloud.
Étapes suivantes
Découvrez les actions que vous pouvez effectuer pour corriger les résultats des profils de données.