
Se você configurou o serviço de descoberta de dados sensíveis para enviar todos os perfis de dados gerados com sucesso para o BigQuery, é possível consultar esses perfis para receber insights sobre seus dados. Você também pode usar ferramentas de visualização, como o Data Studio, para criar relatórios personalizados de acordo com suas necessidades. Como alternativa, você pode usar um relatório predefinido fornecido pela Proteção de dados sensíveis, ajustar e compartilhar conforme necessário.
Nesta página, você encontra exemplos de consultas SQL que podem ser usadas para saber mais sobre seus perfis de dados. Ele também mostra como visualizar perfis de dados no Data Studio.
Para mais informações sobre perfis de dados, consulte Visão geral da descoberta de dados sensíveis.
Antes de começar
Esta página pressupõe que você configurou a criação de perfis no nível da organização, da pasta ou do projeto. Na configuração da verificação de descoberta, verifique se a ação Salvar cópias do perfil dos dados no BigQuery está ativada. Para mais informações sobre como criar uma configuração de verificação de descoberta, consulte Criar uma configuração de verificação.
A tabela de saída
Neste documento, a tabela que contém os perfis de dados exportados é chamada de tabela de saída.
Verifique se você tem o ID do projeto, do conjunto de dados e da tabela de saída disponíveis. Você precisa deles para realizar os procedimentos nesta página.
Visualização latest
Quando a Proteção de Dados Sensíveis exporta perfis de dados para sua tabela de saída, ela também cria a latest visualização. Essa visualização é uma tabela virtual pré-filtrada que inclui apenas os snapshots mais recentes dos seus perfis de dados. A visualização latest tem o mesmo esquema da tabela de saída. Portanto, você pode usar as duas de forma intercambiável nas consultas SQL e nos relatórios do Data Studio. Os resultados podem ser diferentes porque a tabela de saída contém snapshots mais antigos dos perfis de dados.
A visualização latest é armazenada no mesmo local da tabela de saída. O nome tem o seguinte formato:
OUTPUT_TABLE_latest_VERSION
Substitua:
- OUTPUT_TABLE: o ID da tabela que contém os perfis de dados exportados.
- VERSION: o número da versão da visualização.
Por exemplo, se o nome da tabela de saída for table-profile, a visualização latest terá um nome como table-profile_latest_v1.

Ao usar a visualização latest em consultas SQL, use o nome completo dela, que inclui o ID do projeto, do conjunto de dados, da tabela e o sufixo. Por exemplo, myproject.mydataset.table-profile_latest_v1.
PROJECT_ID.DATASET_ID.OUTPUT_TABLE_latest_VERSION
Escolha entre a tabela de saída e a visualização latest
A visualização latest inclui apenas os snapshots de perfil dos dados mais recentes, enquanto a tabela de saída tem todos os snapshots de perfil dos dados, incluindo os desatualizados. Por exemplo, uma consulta na tabela de saída pode retornar vários perfis de dados de coluna para a mesma coluna, um para cada vez que ela foi analisada.
Ao escolher entre usar a tabela de saída e a visualização latest nas consultas SQL ou nos relatórios do Data Studio, considere o seguinte:
A visualização
latesté útil se você tiver recursos de dados que foram redefinidos e quiser ver apenas os perfis mais recentes, não as versões anteriores. Ou seja, você quer ver o estado atual dos dados analisados.A tabela de saída é útil se você quiser ter uma visão histórica dos dados de perfil. Por exemplo, você está tentando determinar se sua organização já armazenou um InfoType específico ou quer ver as mudanças que um perfil dos dados específico passou.
Amostras de consultas SQL
Nesta seção, você encontra exemplos de consultas que podem ser usadas ao analisar perfis de dados. Para executar essas consultas, consulte Como executar consultas interativas.
Nos exemplos a seguir, substitua TABLE_OR_VIEW por uma das seguintes opções:
- O nome da tabela de saída, que é a tabela que contém os perfis de dados exportados. Por exemplo,
myproject.mydataset.table-profile. - O nome da visualização
latestda tabela de saída. Por exemplo,myproject.mydataset.table-profile_latest_v1.
Em ambos os casos, é necessário incluir o ID do projeto e do conjunto de dados.
Para mais informações, consulte
Escolher entre a tabela de saída e a visualização latest nesta
página.
Para resolver qualquer erro, consulte Mensagens de erro.
Listar todas as colunas com uma alta pontuação de texto livre e evidências de outras correspondências de infoType
SELECT
column_profile.table_full_resource,
column_profile.COLUMN,
other_matches.info_type.name,
column_profile.profile_last_generated
FROM
`TABLE_OR_VIEW`
LEFT JOIN UNNEST(column_profile.other_matches) AS other_matches
WHERE
column_profile.free_text_score = 1
AND ( column_profile.column_info_type.info_type.name>""
OR ARRAY_LENGTH(column_profile.other_matches)>0 )
Para saber como corrigir essas descobertas, consulte Estratégias recomendadas para reduzir o risco de dados.
Para mais informações sobre as métricas Pontuação de texto livre e Outros infoTypes, consulte Perfis de dados de coluna.
Liste todas as tabelas que contêm uma coluna de números de cartão de crédito
SELECT
column_profile.table_full_resource,
column_profile.profile_last_generated
FROM
`TABLE_OR_VIEW`
WHERE
column_profile.column_info_type.info_type.name="CREDIT_CARD_NUMBER"
CREDIT_CARD_NUMBER é um infoType integrado
que representa um número de cartão de crédito.
Para saber como corrigir essas descobertas, consulte Estratégias recomendadas para reduzir o risco de dados.
Listar perfis de tabela que contêm colunas de números de cartão de crédito, CPF ou CNPJ e nomes de pessoas
SELECT
table_full_resource,
COUNT(*) AS count_findings
FROM (
SELECT
DISTINCT column_profile.table_full_resource,
column_profile.column_info_type.info_type.name
FROM
`TABLE_OR_VIEW`
WHERE
column_profile.column_info_type.info_type.name IN ('PERSON_NAME',
'CREDIT_CARD_NUMBER',
'US_SOCIAL_SECURITY_NUMBER')
ORDER BY
column_profile.table_full_resource ) ot1
GROUP BY
table_full_resource
#increase this number to match the total distinct infoTypes that must be present
HAVING
count_findings>=3
Essa consulta usa os seguintes infoTypes integrados:
CREDIT_CARD_NUMBER: representa um número de cartão de crédito.PERSON_NAME: representa o nome completo de uma pessoa.US_SOCIAL_SECURITY_NUMBERrepresenta um número de CPF dos EUA
Para saber como corrigir essas descobertas, consulte Estratégias recomendadas para reduzir o risco de dados.
Listar buckets em que a pontuação de sensibilidade é SENSITIVITY_HIGH
SELECT file_store_profile.file_store_path, file_store_profile.resource_visibility, file_store_profile.sensitivity_score
FROM `TABLE_OR_VIEW`
WHERE file_store_profile.sensitivity_score.score ='SENSITIVITY_HIGH'
;
Para mais informações, consulte Perfis de dados do armazenamento de arquivos.
Liste todos os caminhos de bucket, clusters e extensões de arquivo verificados em que a pontuação de sensibilidade é SENSITIVITY_HIGH
SELECT file_store_profile.file_store_path, summaries.file_cluster_type.cluster, STRING_AGG(scanned_file_extensions.file_extension) AS scanned_extensions, file_store_profile.profile_last_generated.timestamp
FROM `TABLE_OR_VIEW`
LEFT JOIN UNNEST(file_store_profile.file_cluster_summaries) as summaries
LEFT JOIN UNNEST(summaries.file_store_info_type_summaries) as info_types
LEFT JOIN UNNEST(summaries.file_extensions_scanned) as scanned_file_extensions
WHERE file_store_profile.data_source_type.data_source = 'google/storage/bucket'
AND summaries.sensitivity_score.score ='SENSITIVITY_HIGH'
GROUP BY 1, 2, 4
;
Para mais informações, consulte Perfis de dados do armazenamento de arquivos.
Liste todos os caminhos de bucket, clusters e extensões de arquivo verificados em que números de cartão de crédito foram detectados.
SELECT file_store_profile.file_store_path, summaries.file_cluster_type.cluster, STRING_AGG(scanned_file_extensions.file_extension) AS scanned_extensions
FROM `TABLE_OR_VIEW`
LEFT JOIN UNNEST(file_store_profile.file_cluster_summaries) as summaries
LEFT JOIN UNNEST(summaries.file_store_info_type_summaries) as info_types
LEFT JOIN UNNEST(summaries.file_extensions_scanned) as scanned_file_extensions
WHERE file_store_profile.data_source_type.data_source = 'google/storage/bucket'
AND info_types.info_type.name='CREDIT_CARD_NUMBER'
GROUP BY 1, 2
;
CREDIT_CARD_NUMBER é um infoType integrado
que representa um número de cartão de crédito.
Para mais informações, consulte Perfis de dados do armazenamento de arquivos.
Liste todos os caminhos de bucket, clusters e extensões de arquivo verificados em que um número de cartão de crédito, nome de pessoa ou número de CPF ou CNPJ dos EUA foi detectado.
SELECT file_store_profile.file_store_path, summaries.file_cluster_type.cluster, STRING_AGG(scanned_file_extensions.file_extension) AS scanned_extensions
FROM `TABLE_OR_VIEW`
LEFT JOIN UNNEST(file_store_profile.file_cluster_summaries) as summaries
LEFT JOIN UNNEST(summaries.file_store_info_type_summaries) as info_types
LEFT JOIN UNNEST(summaries.file_extensions_scanned) as scanned_file_extensions
WHERE file_store_profile.data_source_type.data_source = 'google/storage/bucket'
AND info_types.info_type.name IN ('CREDIT_CARD_NUMBER', 'PERSON_NAME', 'US_SOCIAL_SECURITY_NUMBER')
GROUP BY 1, 2
;
Essa consulta usa os seguintes infoTypes integrados:
CREDIT_CARD_NUMBER: representa um número de cartão de crédito.PERSON_NAME: representa o nome completo de uma pessoa.US_SOCIAL_SECURITY_NUMBERrepresenta um número de CPF dos EUA
Para mais informações, consulte Perfis de dados do armazenamento de arquivos.
Crie uma visualização que mostre exemplos de descobertas apenas dos perfis de dados mais recentes
Por padrão, a visualização latest da tabela de descobertas de amostra inclui as descobertas mais recentes detectadas para cada recurso de dados. Se um recurso de dados for
recriado e o novo perfil não tiver descobertas, a visualização de descobertas de amostra latest ainda vai reter as descobertas do perfil anterior.
Para ver exemplos de descobertas apenas do perfil mais recente de cada recurso de dados, de modo que os recursos sem descobertas no perfil recente não mostrem descobertas, crie uma visualização personalizada que una a tabela de exemplos de descobertas com a visualização latest da tabela de perfis de dados.
Exemplo de consulta para perfis de dados da tabela
CREATE OR REPLACE VIEW
`PROJECT_ID.DATASET_ID.VIEW_ID` AS
SELECT
findings_table.*
FROM
`FINDINGS_TABLE_PROJECT_ID.FINDINGS_TABLE_DATASET_ID.FINDINGS_TABLE_ID` AS findings_table
INNER JOIN
`PROFILES_TABLE_PROJECT_ID.PROFILES_TABLE_DATASET_ID.PROFILES_TABLE_ID_latest_v1` AS profiles_table
ON
findings_table.data_profile_resource_name = profiles_table.table_profile.name
AND findings_table.timestamp.timestamp = profiles_table.table_profile.profile_last_generated.timestamp
;
Exemplo de consulta para perfis de dados do repositório de arquivos
CREATE OR REPLACE VIEW
`PROJECT_ID.DATASET_ID.VIEW_ID` AS
SELECT
findings_table.*
FROM
`FINDINGS_TABLE_PROJECT_ID.FINDINGS_TABLE_DATASET_ID.FINDINGS_TABLE_ID` AS findings_table
INNER JOIN
`PROFILES_TABLE_PROJECT_ID.PROFILES_TABLE_DATASET_ID.PROFILES_TABLE_ID_latest_v1` AS profiles_table
ON
findings_table.data_profile_resource_name = profiles_table.file_store_profile.name
AND findings_table.timestamp.timestamp = profiles_table.file_store_profile.profile_last_generated.timestamp
;
Trabalhar com perfis de dados no Data Studio
Para visualizar seus perfis de dados no Data Studio, use um relatório predefinido ou crie o seu próprio.
Usar um relatório predefinido
A Proteção de Dados Sensíveis oferece um relatório pré-criado do Data Studio que destaca os insights avançados dos perfis de dados. O painel de proteção de dados sensíveis é um relatório de várias páginas que oferece uma visão geral rápida dos seus perfis de dados, incluindo detalhamentos por risco, infoType e local. Confira as outras guias para ver visualizações por região geográfica e risco de postura ou detalhar métricas específicas. Você pode usar esse relatório predefinido no estado em que se encontra ou personalizá-lo conforme necessário. Essa é a versão recomendada do relatório predefinido.
Para conferir o relatório predefinido com seus dados, insira os valores necessários no seguinte URL. Em seguida, copie o URL resultante para o navegador.
https://lookerstudio.google.com/c/u/0/reporting/create?c.reportId=c9826374-e016-4c96-a495-7281328375c6&ds.connector=BIG_QUERY&ds.projectId=PROJECT_ID&ds.datasetId=DATASET_ID&ds.tableId=TABLE_OR_VIEW&ds.type=TABLE&ds.useFreshSchema=false
Substitua:
- PROJECT_ID: o projeto que contém a tabela de saída.
- DATASET_ID: o conjunto de dados que contém a tabela de saída.
TABLE_OR_VIEW: uma das seguintes opções:
- O nome da tabela de saída, que é a tabela que contém os perfis de dados exportados, por exemplo,
myproject.mydataset.table-profile. - O nome da visualização
latestda tabela de saída. Por exemplo,myproject.mydataset.table-profile_latest_v1.
Para mais informações, consulte Escolher entre a tabela de saída e a visualização
latestnesta página.- O nome da tabela de saída, que é a tabela que contém os perfis de dados exportados, por exemplo,
Pode levar alguns minutos para o Data Studio carregar o relatório com seus dados. Se você encontrar erros ou se o relatório não carregar, consulte Resolver problemas com o relatório predefinido nesta página.
No exemplo a seguir, o painel mostra que dados de baixa e alta sensibilidade estão presentes em vários países ao redor do mundo.
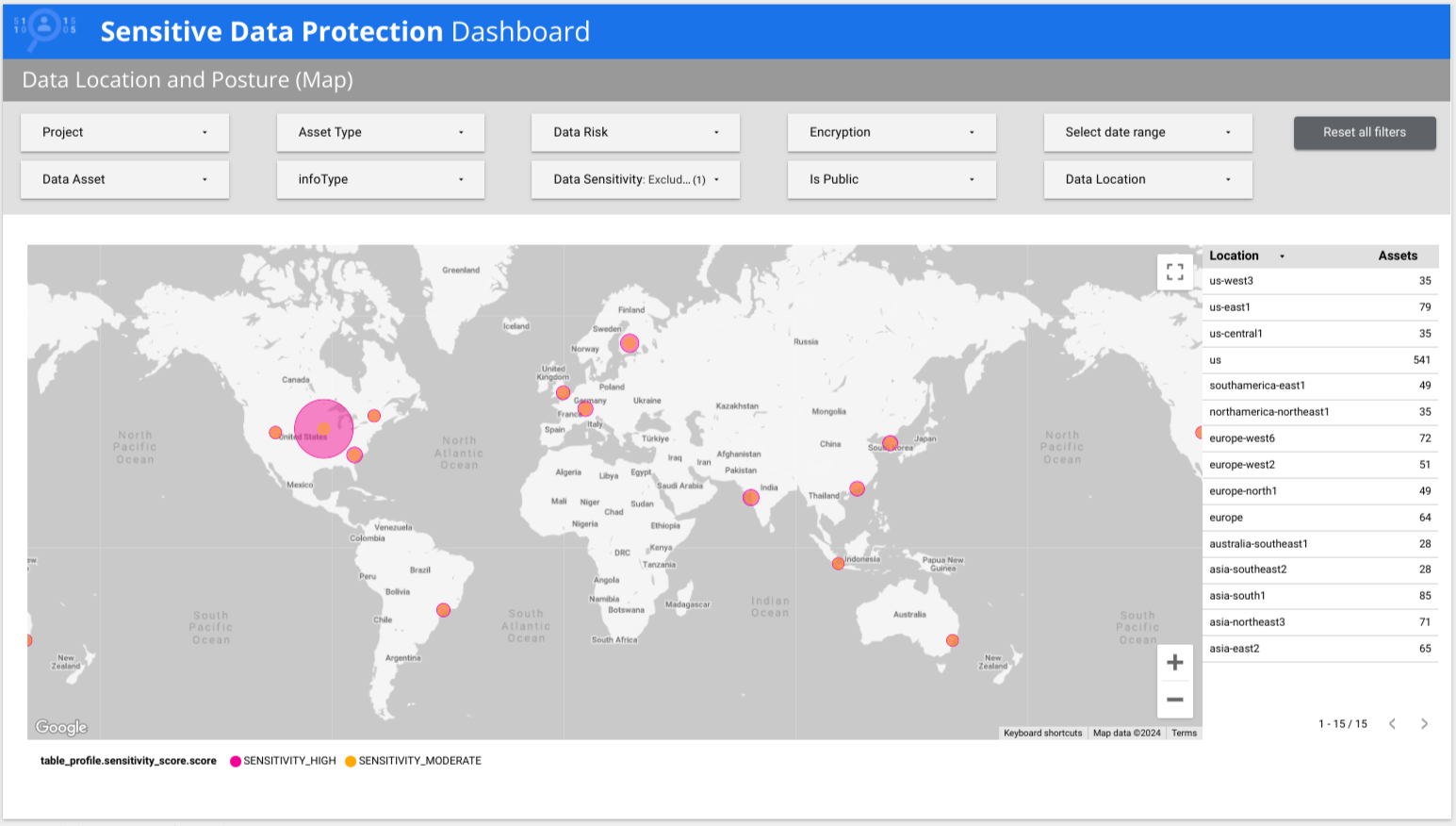
Versão anterior do relatório predefinido
A primeira versão do relatório predefinido ainda está disponível no seguinte endereço:
https://lookerstudio.google.com/c/u/0/reporting/create?c.reportId=907a2b73-ffe4-40b2-b9a1-c2aa0bbd69fd&ds.connector=BIG_QUERY&ds.projectId=PROJECT_ID&ds.datasetId=DATASET_ID&ds.tableId=TABLE_OR_VIEW&ds.type=TABLE&ds.useFreshSchema=false
Crie um relatório
Com o Data Studio, é possível criar relatórios interativos. Nesta seção, você cria um relatório de tabela simples no Data Studio com base nos perfis de dados exportados para a tabela de saída no BigQuery.
Verifique se você tem o ID do projeto, do conjunto de dados e da tabela de saída ou a visualização latest disponível. Você precisa delas para realizar esse
procedimento.
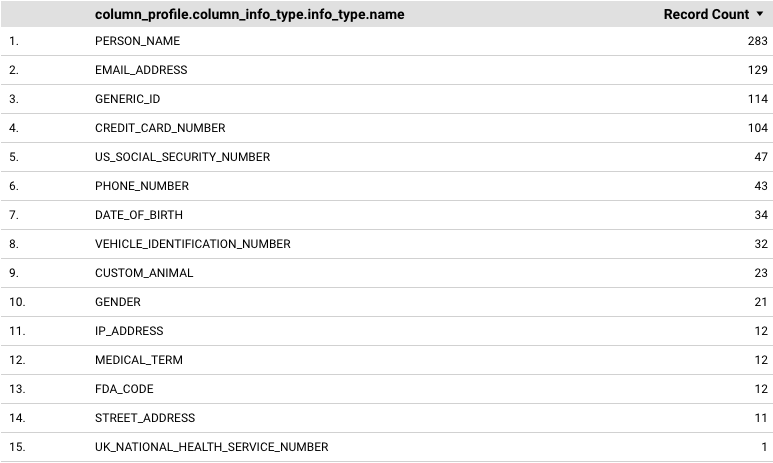
Este exemplo mostra como criar um relatório com uma tabela que mostra cada infoType informado nos seus perfis de dados e a frequência correspondente.
Em geral, são cobrados os custos de uso do BigQuery ao acessar o BigQuery pelo Data Studio. Saiba mais em Como visualizar dados do BigQuery com o Data Studio.
Para criar um relatório, faça o seguinte:
- Abra o Data Studio e faça login.
- Clique em Relatório em branco.
- Na guia Conectar aos dados, clique no cartão do BigQuery.
- Se necessário, autorize o Data Studio a acessar seus projetos do BigQuery.
Conecte-se aos seus dados do BigQuery:
- Em Projeto, selecione o projeto que contém a tabela de saída. Você pode pesquisar o projeto nas guias Projetos recentes, Meus projetos e Projetos compartilhados.
- Em Conjunto de dados, selecione o conjunto de dados que contém a tabela de saída.
Em Tabela, selecione a tabela de saída ou a visualização
latestdela.Para mais informações, consulte Escolher entre a tabela de saída e a visualização
latestnesta página.Clique em Adicionar.
Na caixa de diálogo exibida, clique em Adicionar ao relatório.
Para adicionar uma tabela que mostre cada infoType informado e a frequência correspondente (contagem de registros), siga estas etapas:
- Clique em Adicionar um gráfico.
- Selecione um estilo de tabela.
Clique na área onde você quer posicionar o gráfico.
O gráfico aparece em formato de tabela.
Redimensione a tabela conforme necessário.
Enquanto a tabela estiver selecionada, as propriedades dela vão aparecer no painel Gráfico.
No painel Gráfico, na guia Configuração, remova as dimensões e métricas pré-selecionadas.
Em Dimensão, adicione
column_profile.column_info_type.info_type.nameoufile_store_profile.file_cluster_summaries.file_store_info_type_summaries.info_type.name.Esses exemplos fornecem dados nos níveis de coluna e cluster de arquivos. Você também pode testar outras dimensões. Por exemplo, é possível usar dimensões no nível da tabela e do bucket.
Em Métrica, adicione Contagem de registros.
A tabela resultante será semelhante a esta:
Saiba mais sobre tabelas no Data Studio.
Resolver erros com o relatório predefinido
Se você encontrar erros, controles ou gráficos ausentes ao carregar o relatório predefinido, verifique se ele está usando os campos mais recentes:
Se o relatório predefinido estiver conectado à tabela de saída, confirme se ela está anexada a uma configuração de verificação de descoberta ativa. Para conferir as configurações das suas configurações de verificação, consulte Ver uma configuração de verificação.
Se o relatório predefinido estiver conectado à visualização
latest, confirme se ela ainda está presente no BigQuery. Se ele estiver presente, tente fazer uma mudança na visualização. Ou faça uma cópia da visualização e conecte o relatório predefinido a ela. Para mais informações sobre a visualizaçãolatest, consulte A visualizaçãolatestnesta página.
Se os erros persistirem depois de tentar essas etapas, entre em contato com o Cloud Customer Care.
A seguir
Saiba mais sobre as ações que você pode realizar para corrigir as descobertas do perfil dos dados.