
Se hai configurato il servizio di rilevamento di dati sensibili in modo che invii tutti i profili di dati generati correttamente a BigQuery, puoi eseguire query su questi profili di dati per ottenere informazioni dettagliate su i tuoi dati. Puoi anche utilizzare strumenti di visualizzazione come Data Studio per creare report personalizzati in base alle esigenze della tua attività. In alternativa, puoi utilizzare un report predefinito fornito da Sensitive Data Protection, modificarlo e condividerlo in base alle esigenze.
Questa pagina fornisce esempi di query SQL che puoi utilizzare per scoprire di più sui tuoi profili di dati. Mostra anche come visualizzare i profili di dati in Data Studio.
Per ulteriori informazioni sui profili di dati, consulta Panoramica del rilevamento di dati sensibili.
Prima di iniziare
Questa pagina presuppone che tu abbia configurato la profilazione a livello di organizzazione, cartella o progetto. Nella configurazione della scansione di rilevamento, assicurati che l'azione Salva le copie dei profili di dati in BigQuery sia abilitata. Per ulteriori informazioni su come creare una configurazione della scansione di rilevamento, consulta Creare una configurazione della scansione.
La tabella di output
In questo documento, la tabella contenente i profili di dati esportati è chiamata tabella di output.
Assicurati di avere a portata di mano l'ID progetto, l'ID set di dati e l'ID tabella della tabella di output. Sono necessari per eseguire le procedure descritte in questa pagina.
La visualizzazione latest
Quando Sensitive Data Protection esporta i profili di dati nella tabella di output, crea anche la
latest visualizzazione. Questa visualizzazione è una tabella virtuale prefiltrata che include solo gli snapshot più recenti dei profili di dati. La visualizzazione latest ha lo stesso schema della tabella di output, quindi puoi utilizzare le due in modo intercambiabile nelle query SQL e nei report di Data Studio. I risultati possono variare perché la tabella di output contiene snapshot precedenti dei profili di dati.
La visualizzazione latest viene archiviata nella stessa posizione della tabella di output. Il nome ha il seguente formato:
OUTPUT_TABLE_latest_VERSION
Sostituisci quanto segue:
- OUTPUT_TABLE: l'ID della tabella contenente i profili di dati esportati.
- VERSION: il numero di versione della visualizzazione.
Ad esempio, se il nome della tabella di output è table-profile, la visualizzazione latest
ha un nome simile a table-profile_latest_v1.

Quando utilizzi la visualizzazione latest nelle query SQL, utilizza il nome completo della visualizzazione, che
include l'ID progetto, l'ID set di dati, l'ID tabella e il suffisso, ad esempio,
myproject.mydataset.table-profile_latest_v1.
PROJECT_ID.DATASET_ID.OUTPUT_TABLE_latest_VERSION
Scegliere tra la tabella di output e la visualizzazione latest
La visualizzazione latest include solo gli snapshot più recenti dei profili di dati, mentre la tabella di output contiene tutti gli snapshot dei profili di dati, inclusi quelli obsoleti. Ad esempio, una query sulla tabella di output può restituire più
profili di dati delle colonne
per la stessa colonna, uno per ogni volta che la colonna è stata profilata.
Quando scegli tra l'utilizzo della tabella di output e della visualizzazione latest nelle query SQL o nei report di Data Studio, tieni presente quanto segue:
La visualizzazione
latestè utile se hai asset di dati di cui è stata eseguita una nuova profilazione e vuoi visualizzare solo i profili più recenti, non le versioni precedenti. In altre parole, vuoi visualizzare lo stato attuale dei dati profilati.La tabella di output è utile se vuoi ottenere una visualizzazione storica dei dati profilati. Ad esempio, stai cercando di determinare se la tua organizzazione ha mai archiviato un determinato infoType o vuoi visualizzare le modifiche apportate a un determinato profilo di dati.
Esempi di query SQL
Questa sezione fornisce esempi di query che puoi utilizzare durante l'analisi dei profili di dati. Per eseguire queste query, consulta Eseguire query interattive.
Negli esempi seguenti, sostituisci TABLE_OR_VIEW con una delle seguenti opzioni:
- Il nome della tabella di output, ovvero la tabella contenente i profili di dati esportati, ad esempio
myproject.mydataset.table-profile. - Il nome della
latestvisualizzazione della tabella di output, ad esempiomyproject.mydataset.table-profile_latest_v1.
In entrambi i casi, devi includere l'ID progetto e l'ID set di dati.
Per ulteriori informazioni, consulta la sezione
Scegliere tra la tabella di output e la latest visualizzazione in questa
pagina.
Per risolvere eventuali errori, consulta Messaggi di errore.
Elencare tutte le colonne con un punteggio di testo libero elevato e prove di altre corrispondenze di infoType
SELECT
column_profile.table_full_resource,
column_profile.COLUMN,
other_matches.info_type.name,
column_profile.profile_last_generated
FROM
`TABLE_OR_VIEW`
LEFT JOIN UNNEST(column_profile.other_matches) AS other_matches
WHERE
column_profile.free_text_score = 1
AND ( column_profile.column_info_type.info_type.name>""
OR ARRAY_LENGTH(column_profile.other_matches)>0 )
Per informazioni su come correggere questi risultati, consulta Strategie consigliate per mitigare il rischio dei dati.
Per ulteriori informazioni sulle metriche Punteggio di testo libero e Altri infoType , consulta Profili di dati delle colonne.
Elencare tutte le tabelle contenenti una colonna di numeri di carte di credito
SELECT
column_profile.table_full_resource,
column_profile.profile_last_generated
FROM
`TABLE_OR_VIEW`
WHERE
column_profile.column_info_type.info_type.name="CREDIT_CARD_NUMBER"
CREDIT_CARD_NUMBER è un infoType integrato
che rappresenta un numero carta.
Per informazioni su come correggere questi risultati, consulta Strategie consigliate per mitigare il rischio dei dati.
Elencare i profili delle tabelle contenenti colonne di numeri di carte di credito, numeri di previdenza sociale statunitensi e nomi di persone
SELECT
table_full_resource,
COUNT(*) AS count_findings
FROM (
SELECT
DISTINCT column_profile.table_full_resource,
column_profile.column_info_type.info_type.name
FROM
`TABLE_OR_VIEW`
WHERE
column_profile.column_info_type.info_type.name IN ('PERSON_NAME',
'CREDIT_CARD_NUMBER',
'US_SOCIAL_SECURITY_NUMBER')
ORDER BY
column_profile.table_full_resource ) ot1
GROUP BY
table_full_resource
#increase this number to match the total distinct infoTypes that must be present
HAVING
count_findings>=3
Questa query utilizza i seguenti infoType integrati:
CREDIT_CARD_NUMBER: rappresenta un numero di cartaPERSON_NAME: rappresenta il nome completo di una personaUS_SOCIAL_SECURITY_NUMBERrappresenta un numero di previdenza sociale statunitense
Per informazioni su come correggere questi risultati, consulta Strategie consigliate per mitigare il rischio dei dati.
Elencare i bucket in cui il punteggio di sensibilità è SENSITIVITY_HIGH
SELECT file_store_profile.file_store_path, file_store_profile.resource_visibility, file_store_profile.sensitivity_score
FROM `TABLE_OR_VIEW`
WHERE file_store_profile.sensitivity_score.score ='SENSITIVITY_HIGH'
;
Per ulteriori informazioni, consulta Profili di dati del datastore file.
Elencare tutti i percorsi dei bucket, i cluster e le estensioni dei file scansionati in cui il punteggio di sensibilità è SENSITIVITY_HIGH
SELECT file_store_profile.file_store_path, summaries.file_cluster_type.cluster, STRING_AGG(scanned_file_extensions.file_extension) AS scanned_extensions, file_store_profile.profile_last_generated.timestamp
FROM `TABLE_OR_VIEW`
LEFT JOIN UNNEST(file_store_profile.file_cluster_summaries) as summaries
LEFT JOIN UNNEST(summaries.file_store_info_type_summaries) as info_types
LEFT JOIN UNNEST(summaries.file_extensions_scanned) as scanned_file_extensions
WHERE file_store_profile.data_source_type.data_source = 'google/storage/bucket'
AND summaries.sensitivity_score.score ='SENSITIVITY_HIGH'
GROUP BY 1, 2, 4
;
Per ulteriori informazioni, consulta Profili di dati del datastore file.
Elencare tutti i percorsi dei bucket, i cluster e le estensioni dei file scansionati in cui sono stati rilevati numeri di carte di credito
SELECT file_store_profile.file_store_path, summaries.file_cluster_type.cluster, STRING_AGG(scanned_file_extensions.file_extension) AS scanned_extensions
FROM `TABLE_OR_VIEW`
LEFT JOIN UNNEST(file_store_profile.file_cluster_summaries) as summaries
LEFT JOIN UNNEST(summaries.file_store_info_type_summaries) as info_types
LEFT JOIN UNNEST(summaries.file_extensions_scanned) as scanned_file_extensions
WHERE file_store_profile.data_source_type.data_source = 'google/storage/bucket'
AND info_types.info_type.name='CREDIT_CARD_NUMBER'
GROUP BY 1, 2
;
CREDIT_CARD_NUMBER è un infoType integrato
che rappresenta un numero carta.
Per ulteriori informazioni, consulta Profili di dati del datastore file.
Elencare tutti i percorsi dei bucket, i cluster e le estensioni dei file scansionati in cui sono stati rilevati un numero carta, un nome di persona o un numero di previdenza sociale statunitense
SELECT file_store_profile.file_store_path, summaries.file_cluster_type.cluster, STRING_AGG(scanned_file_extensions.file_extension) AS scanned_extensions
FROM `TABLE_OR_VIEW`
LEFT JOIN UNNEST(file_store_profile.file_cluster_summaries) as summaries
LEFT JOIN UNNEST(summaries.file_store_info_type_summaries) as info_types
LEFT JOIN UNNEST(summaries.file_extensions_scanned) as scanned_file_extensions
WHERE file_store_profile.data_source_type.data_source = 'google/storage/bucket'
AND info_types.info_type.name IN ('CREDIT_CARD_NUMBER', 'PERSON_NAME', 'US_SOCIAL_SECURITY_NUMBER')
GROUP BY 1, 2
;
Questa query utilizza i seguenti infoType integrati:
CREDIT_CARD_NUMBER: rappresenta un numero di cartaPERSON_NAME: rappresenta il nome completo di una personaUS_SOCIAL_SECURITY_NUMBERrappresenta un numero di previdenza sociale statunitense
Per ulteriori informazioni, consulta Profili di dati del datastore file.
Utilizzare i profili di dati in Data Studio
Per visualizzare i profili di dati in Data Studio, puoi utilizzare un report predefinito o puoi crearne uno tuo.
Utilizzare un report predefinito
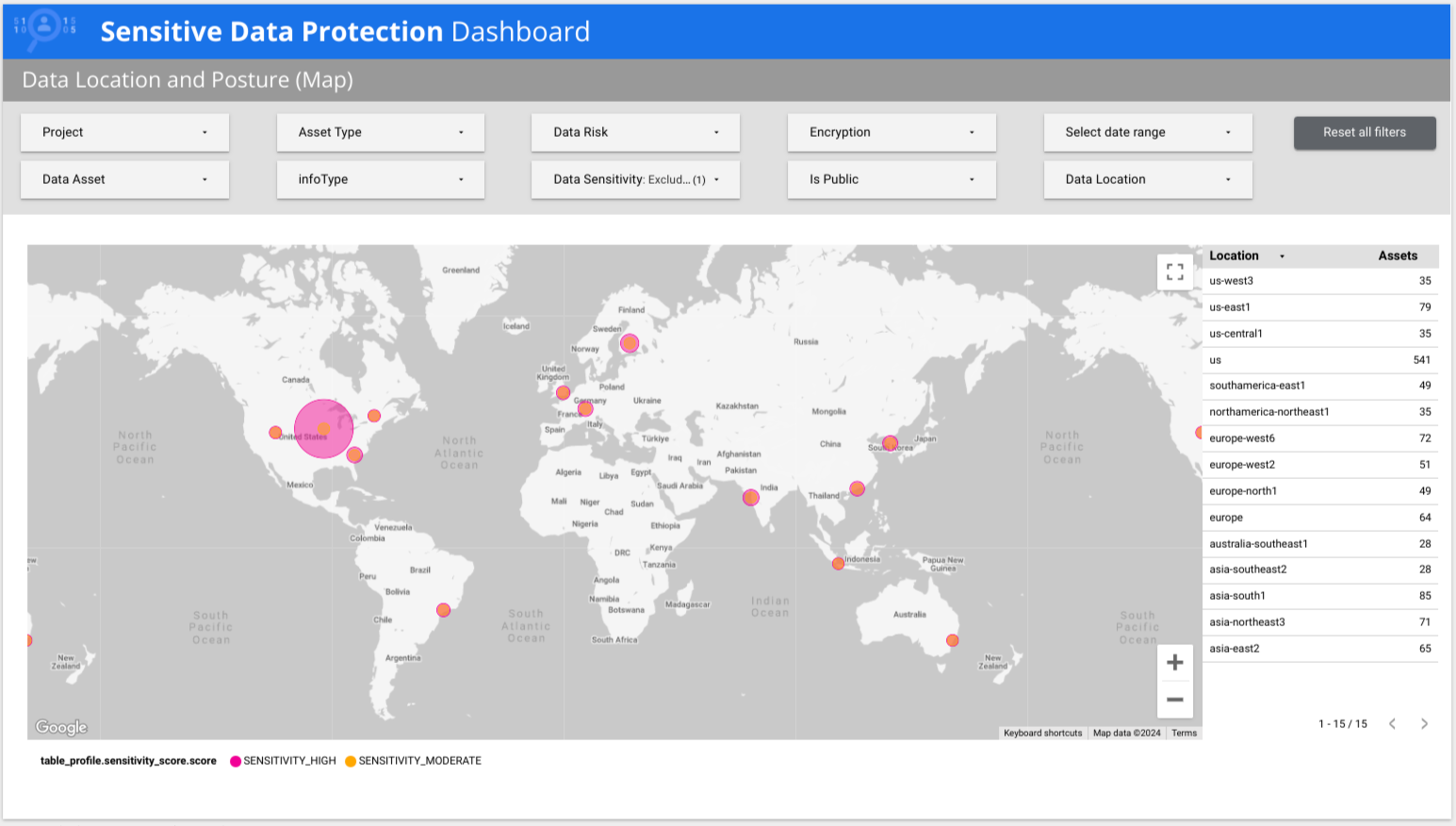
Sensitive Data Protection fornisce un report predefinito di Data Studio che mette in evidenza le informazioni dettagliate dei profili di dati. La dashboard di Sensitive Data Protection è un report di più pagine che offre una rapida visualizzazione di alto livello dei profili di dati, inclusi i dettagli per rischio, infoType e località. Esplora le altre schede per visualizzare le visualizzazioni per area geografica e rischio di postura o visualizzare in dettaglio metriche specifiche. Puoi utilizzare questo report predefinito così com'è o personalizzarlo in base alle esigenze. Questa è la versione consigliata del report predefinito.
Per visualizzare il report predefinito con i tuoi dati, inserisci i valori richiesti nel seguente URL. Poi, copia l'URL risultante nel browser.
https://lookerstudio.google.com/c/u/0/reporting/create?c.reportId=c9826374-e016-4c96-a495-7281328375c6&ds.connector=BIG_QUERY&ds.projectId=PROJECT_ID&ds.datasetId=DATASET_ID&ds.tableId=TABLE_OR_VIEW&ds.type=TABLE&ds.useFreshSchema=false
Sostituisci quanto segue:
- PROJECT_ID: il progetto contenente la tabella di output.
- DATASET_ID: il set di dati contenente la tabella di output.
TABLE_OR_VIEW: una delle seguenti opzioni:
- Il nome della tabella di output, ovvero la tabella contenente i profili di dati esportati,ad esempio
myproject.mydataset.table-profile. - Il nome della
latestvisualizzazione della tabella di output, ad esempiomyproject.mydataset.table-profile_latest_v1.
Per ulteriori informazioni, consulta la sezione Scegliere tra la tabella di output e la visualizzazione
latestview in questa pagina.- Il nome della tabella di output, ovvero la tabella contenente i profili di dati esportati,ad esempio
Il caricamento del report con i tuoi dati in Data Studio può richiedere alcuni minuti. Se riscontri errori o se il report non viene caricato, consulta Risolvere i problemi relativi al report predefinito in questa pagina.
Nell'esempio seguente, la dashboard mostra che i dati a bassa e alta sensibilità sono presenti in più paesi in tutto il mondo.
Versione precedente del report predefinito
La prima versione del report predefinito è ancora disponibile al seguente indirizzo:
https://lookerstudio.google.com/c/u/0/reporting/create?c.reportId=907a2b73-ffe4-40b2-b9a1-c2aa0bbd69fd&ds.connector=BIG_QUERY&ds.projectId=PROJECT_ID&ds.datasetId=DATASET_ID&ds.tableId=TABLE_OR_VIEW&ds.type=TABLE&ds.useFreshSchema=false
Creare un report
Data Studio consente di creare report interattivi. In questa sezione, creerai un semplice report tabellare in Data Studio basato sui profili di dati esportati nella tabella di output in BigQuery.
Assicurati di avere a portata di mano l'
ID progetto, l'ID set di dati e l'ID tabella della tabella di output o della visualizzazione
latest readily available. Sono necessari per eseguire questa procedura.
Questo esempio mostra come creare un report contenente una tabella che mostra ogni infoType segnalato nei profili di dati e la relativa frequenza.
In genere, l'accesso a BigQuery tramite Data Studio comporta costi di utilizzo di BigQuery. Per ulteriori informazioni, consulta Visualizzare i dati di BigQuery utilizzando Data Studio.
Per creare un report:
- Apri Data Studio e accedi.
- Fai clic su Report vuoto.
- Nella scheda Connetti ai dati, fai clic sulla scheda BigQuery.
- Se richiesto, autorizza Data Studio ad accedere ai tuoi progetti BigQuery.
Connettiti ai dati di BigQuery:
- In Progetto, seleziona il progetto contenente la tabella di output. Puoi cercare il progetto nelle schede Progetti recenti, I miei progetti, e Progetti condivisi.
- In Set di dati, seleziona il set di dati contenente la tabella di output.
In Tabella, seleziona la tabella di output o la
latestvisualizzazione della tabella di output.Per ulteriori informazioni, consulta la sezione Scegliere tra la tabella di output e la visualizzazione
latestview in questa pagina.Fai clic su Aggiungi.
Nella finestra di dialogo visualizzata, fai clic su Aggiungi al report.
Per aggiungere una tabella che mostri ogni infoType segnalato e la relativa frequenza (numero di record):
- Fai clic su Aggiungi un grafico.
- Seleziona uno stile di tabella.
Fai clic sull'area in cui vuoi posizionare il grafico.
Il grafico viene visualizzato in formato tabellare.
Ridimensiona la tabella in base alle esigenze.
Se la tabella è selezionata, le relative proprietà vengono visualizzate nel riquadro Grafico.
Nel riquadro Grafico, nella scheda Configurazione, rimuovi le dimensioni e le metriche preselezionate.
In Dimensione, aggiungi
column_profile.column_info_type.info_type.nameofile_store_profile.file_cluster_summaries.file_store_info_type_summaries.info_type.name.Questi esempi forniscono dati a livello di colonna e cluster di file. Puoi provare anche altre dimensioni. Ad esempio, puoi utilizzare le dimensioni a livello di tabella e di bucket.
In Metrica, aggiungi Numero di record.
La tabella risultante sarà simile alla seguente:

Scopri di più sulle tabelle in Data Studio.
Risolvere i problemi relativi al report predefinito
Se visualizzi errori, controlli mancanti o grafici mancanti durante il caricamento del report predefinito, assicurati che il report predefinito utilizzi i campi più recenti:
Se il report predefinito è collegato alla tabella di output, verifica che questa tabella sia collegata a una configurazione della scansione di rilevamento attiva. Per visualizzare le impostazioni delle configurazioni della scansione, consulta Visualizzare una configurazione della scansione.
Se il report predefinito è collegato alla visualizzazione
latest, verifica che questa visualizzazione sia ancora presente in BigQuery. Se è presente, prova ad apportare una modifica alla visualizzazione. In alternativa, crea una copia della visualizzazione e collega il report predefinito a questa copia. Per ulteriori informazioni sulla visualizzazionelatest, consulta La visualizzazionelatestin questa pagina.
Se continui a visualizzare errori dopo aver provato questi passaggi, contatta l'assistenza clienti Google Cloud.
Passaggi successivi
Scopri le azioni che puoi intraprendere per correggere i risultati dei profili di dati.