
O Cloud Run é uma plataforma de aplicativos totalmente gerenciada para executar seu código, função ou contêiner na infraestrutura altamente escalonável do Google.
É possível implantar um código escrito em qualquer linguagem de programação no Cloud Run se puder criar uma imagem de contêiner com base nele. Na verdade, a criação de imagens de contêiner é opcional. Se você usa Go, Node.js, Python, Java, .NET, Ruby ou um framework compatível, é possível usar a opção implantação baseada em origem que cria o contêiner para você aproveitando as práticas recomendadas para a linguagem que está sendo usada.
O Google criou o Cloud Run para funcionar bem com outros serviços no Google Cloud. Assim, você pode criar aplicativos completos.
Em resumo, o Cloud Run permite que os desenvolvedores passem mais tempo escrevendo o código e quase sem tempo operando, configurando e escalonando o serviço do Cloud Run. Você não precisa criar um cluster ou gerenciar a infraestrutura para ser produtivo com o Cloud Run.
Serviços, jobs e pools de workers: três maneiras de executar seu código
No Cloud Run, o código pode ser executado como um serviço, job ou pool de trabalhadores. Todos esses tipos de recursos executam instâncias de contêiner em sandbox no mesmo ambiente de execução e podem ser integrados aos serviços doGoogle Cloud .
A tabela a seguir oferece uma visão geral das opções fornecidas por cada tipo de recurso do Cloud Run.
| Recurso | Descrição |
|---|---|
| Serviço | Responde a solicitações HTTP enviadas a um endpoint único e estável, usando instâncias sem estado que são escalonadas automaticamente com base em várias métricas principais. Também responde a eventos e funções. |
| Job | Executa tarefas paralelizadas que são executadas manualmente ou de acordo com uma programação e são concluídas. |
| Pool de workers | Processa cargas de trabalho em segundo plano sempre ativas, como cargas de trabalho baseadas em pull, por exemplo, consumidores do Kafka, filas de pull do Pub/Sub ou consumidores do RabbitMQ. |
Serviços do Cloud Run
Um serviço do Cloud Run oferece a infraestrutura necessária para executar um endpoint HTTPS confiável. Sua responsabilidade é garantir que o código detecte uma porta TCP e identifique solicitações HTTP.
O diagrama a seguir mostra um serviço do Cloud Run executando várias instâncias de contêiner para processar solicitações e eventos da Web do cliente usando um endpoint HTTPS.

Um serviço padrão inclui os seguintes recursos:
- Endpoint HTTPS exclusivo para cada serviço
- Todos os serviços do Cloud Run têm um endpoint HTTPS em um subdomínio exclusivo do domínio
*.run.app. Também é possível configurar domínios personalizados. O Cloud Run gerencia o TLS para você e oferece suporte a WebSockets, HTTP/2 (de ponta a ponta) e gRPC (de ponta a ponta). - Escalonamento automático rápido com base em solicitações
- O Cloud Run escalona horizontalmente com rapidez para lidar com todas as solicitações recebidas ou com o aumento da utilização da CPU fora das solicitações se a configuração de faturamento estiver definida como faturamento baseado em instâncias. Um serviço pode ser escalonado horizontalmente de forma rápida para até mil instâncias ou até mais, se você solicitar um aumento de cota. Se a demanda diminuir, o Cloud Run removerá os contêineres inativos. Se você estiver preocupado com custos ou sobrecarregando os sistemas downstream, poderá limitar o número máximo de instâncias.
- Escalonamento manual opcional
- Por padrão, o Cloud Run é escalonado automaticamente para mais instâncias e processa mais tráfego. No entanto, é possível substituir esse comportamento usando o escalonamento manual para controlar o escalonamento.
- Gerenciamento de tráfego integrado
Para reduzir o risco de implantação de uma nova revisão, o Cloud Run oferece suporte à realização de um lançamento gradual, incluindo o encaminhamento do tráfego de entrada para a revisão mais recente, a reversão para uma revisão anterior e a divisão do tráfego para várias revisões ao mesmo tempo.
Por exemplo, você pode começar enviando 1% das solicitações para uma nova revisão e aumentar essa porcentagem enquanto monitora a telemetria.
- Serviços públicos e privados
Um serviço do Cloud Run pode ser acessado pela Internet ou ter o acesso restrito das seguintes maneiras:
- Especifique uma política de acesso usando o Cloud IAM.
- Use as configurações de entrada para restringir o acesso à rede. Isso é útil se você quiser permitir apenas o tráfego interno da VPC e dos serviços internos.
- Permitir apenas usuários autenticados com o Identity-Aware Proxy (IAP).
É possível disponibilizar recursos armazenáveis em cache a partir de um local do perímetro próximo aos clientes usando uma rede de fornecimento de conteúdo (CDN), como o Firebase Hosting e o Cloud CDN, para disponibilizar um serviço do Cloud Run.
Escalonar para zero e instâncias mínimas
Por padrão, se o faturamento estiver definido como faturamento baseado em instâncias, o Cloud Run adicionará e removerá instâncias automaticamente para processar todas as solicitações recebidas ou lidar com o aumento da utilização da CPU fora das solicitações.
Se não houver solicitações de entrada para seu serviço, até mesmo a última instância restante será removida. Esse comportamento é normalmente chamado de escala para zero. Se não houver instâncias ativas quando uma solicitação chegar, o Cloud Run vai criar uma nova instância. Isso aumenta o tempo de resposta para essas primeiras solicitações, dependendo da velocidade com que seu contêiner fica pronto para lidar com as solicitações.
Para mudar esse comportamento, use um dos seguintes métodos:
- Configure o Cloud Run para manter uma quantidade mínima de instâncias ativas para que o serviço não seja escalonado para zero instâncias.
- Use o escalonamento manual para ter mais controle sobre o escalonamento.
Preços de pagamento por uso para serviços
A redução da escala para zero é atraente por motivos econômicos, porque você é cobrado pela CPU e memória alocadas para uma instância com uma granularidade de 100 ms. Se você não configurar instâncias mínimas, não haverá cobrança se o serviço não for usado. Há um nível sem custo financeiro generoso. Consulte Preços para mais informações.
Há duas configurações de faturamento que podem ser ativadas:
- Baseada em solicitações
- Se uma instância não estiver processando solicitações, você não vai receber cobranças. Você paga uma taxa por solicitação.
- Com base em instâncias
- A cobrança é feita durante todo o ciclo de vida de uma instância. Não há taxa por solicitação.
Há um nível sem custo financeiro generoso. Consulte preços para mais informações e Configurações de faturamento para saber como ativar o faturamento do serviço para solicitações ou instâncias.
Um sistema de arquivos de contêiner descartável
As instâncias no Cloud Run são descartáveis. Cada contêiner tem uma sobreposição de sistema de arquivos gravável na memória, que não é mantida se o contêiner é desligado. O Cloud Run determina quando parar de enviar solicitações a uma instância e desativá-la, por exemplo, ao reduzir o escalonamento vertical.
Para receber um aviso quando o Cloud Run estiver prestes a encerrar uma instância, seu aplicativo pode interceptar o sinal SIGTERM. Isso permite que o código limpe buffers locais e mantenha os dados locais em um armazenamento de dados externo.
Para manter os arquivos de forma permanente, integre ao Cloud Storage ou ative um sistema de arquivos de rede (NFS).
Quando usar os serviços do Cloud Run
Os serviços do Cloud Run são ótimos para o código que processa solicitações, eventos ou funções. Como exemplos de casos de uso, temos:
- Sites e aplicativos da Web
- Crie seu app da Web usando sua pilha favorita, acesse seu banco de dados SQL e renderize páginas HTML dinâmicas.
- APIs e microsserviços
- É possível criar uma API REST, uma API GraphQL ou microsserviços particulares que se comunicam por HTTP ou gRPC.
- Processamento de dados de streaming
- Os serviços do Cloud Run podem receber mensagens de Assinaturas de push do Pub/Sub e eventos do Eventarc.
- Cargas de trabalho assíncronas
- As funções do Cloud Run podem responder a eventos assíncronos, como uma mensagem em um tópico do Pub/Sub, uma alteração em um bucket do Cloud Storage ou um evento Firebase.
- Inferência de IA
- Os serviços do Cloud Run com ou sem GPU configurada podem hospedar cargas de trabalho de IA, como modelos de inferência e treinamento de modelo.
Jobs do Cloud Run
Se o código executar o trabalho e depois parar, por exemplo, usando um script, você poderá usar um job do Cloud Run para executá-lo. É possível executar um job na linha de comando usando a Google Cloud CLI, programando um job recorrenteou executando-o como parte de um fluxo de trabalho.
Jobs de matriz são uma maneira mais rápida de executar jobs
Um job pode iniciar uma única instância para executar o código. Essa é uma maneira comum de executar um script ou uma ferramenta.
No entanto, também é possível usar um job de matriz, iniciando várias instâncias idênticas e independentes em paralelo. Os jobs de matriz são uma maneira mais rápida de processar jobs que podem ser divididos em várias tarefas independentes.
O diagrama a seguir mostra como um job com sete tarefas leva mais tempo para ser executado sequencialmente do que o mesmo job quando quatro instâncias podem processar tarefas independentes em paralelo:

Por exemplo, se você estiver redimensionando e cortando mil imagens do Cloud Storage, processá-las consecutivamente será mais lento do que processá-las em paralelo com muitas instâncias, com o Cloud Run gerenciando o escalonamento automático.
Quando usar jobs do Cloud Run
Os jobs do Cloud Run são adequados para executar códigos que executam tarefas (um job) e são encerrados quando o trabalho é concluído. Por exemplo:
- Script ou ferramenta
- Executar um script para realizar migrações de banco de dados ou outras tarefas operacionais.
- Job de matriz
- Executar o processamento altamente paralelo de todos os arquivos em um bucket do Cloud Storage.
- Job agendado
- Crie e envie faturas em intervalos regulares ou salve os resultados de uma consulta no banco de dados como XML e faça upload do arquivo em intervalos de algumas horas.
- Cargas de trabalho de IA
- Os jobs do Cloud Run com ou sem GPU configurada podem hospedar cargas de trabalho de IA, como inferência em lote, modelos de ajuste fino e treinamento de modelo.
Pools de workers do Cloud Run
Os pools de workers são projetados para cargas de trabalho que não dependem do processamento de solicitações HTTP. Eles oferecem um pool flexível e escalonável de recursos de computação adaptados para processamento contínuo, não HTTP e em segundo plano baseado em pull. As seguintes características principais definem como os pools de workers operam:
Os pools de workers não são escalonados automaticamente. Escalone manualmente o número de instâncias que seu pool de workers do Cloud Run precisa para processar a carga de trabalho. Para iniciar e permanecer ativa, sua carga de trabalho precisa ter pelo menos uma instância. Se você definir o número mínimo de instâncias como
0, a instância de worker não será iniciada, mesmo que a implantação seja bem-sucedida.Para ajustar dinamicamente as instâncias com base na demanda em tempo real, crie seu próprio escalonador automático. Para um exemplo, consulte Escalonar automaticamente suas cargas de trabalho do consumidor do Kafka.
Os pools de trabalhadores gerenciam os lançamentos dividindo as instâncias entre as revisões, em vez de dividir o tráfego. Por exemplo, para um pool de workers com quatro instâncias, você pode alocar 25% (uma instância) para uma nova revisão e 75% (três instâncias) para uma revisão estável.
Os pools de workers são compatíveis com saída e entrada VPC diretas e não têm um endpoint ou URL com balanceamento de carga. Para mais informações sobre o suporte ao servidor de metadados (MDS) e como recuperar os endereços IP particulares da instância do pool de workers, consulte o Contrato de tempo de execução do contêiner.
O Cloud Run cobra apenas pela duração da execução das instâncias do pool de workers.
Quando usar pools de workers do Cloud Run
Os pools de workers não exigem endpoints HTTP públicos. Isso torna sua rede mais segura e simplifica o código do aplicativo. Além disso, não é necessário gerenciar portas para verificações de integridade. Os seguintes casos de uso se aplicam a pools de workers:
Cargas de trabalho baseadas em pull: implante uma carga de trabalho para extrair mensagens de uma fila e processá-las. Por exemplo, Kafka Consumer, Pub/Sub pull e RabbitMQ.
O diagrama a seguir mostra casos de uso para implantação de pools de workers para cargas de trabalho baseadas em pull:
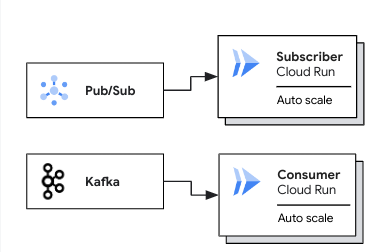
Em um caso de uso do Pub/Sub, um assinante do Cloud Run com escalonamento automático extrai mensagens de uma assinatura do Pub/Sub. Em um caso de uso do Kafka, um consumidor do Cloud Run com escalonamento automático extrai mensagens de um tópico do Kafka.
Cargas de trabalho genéricas sem solicitação: execute uma carga de trabalho baseada em contêineres que não foi projetada para processar solicitações de entrada.
Integrações doGoogle Cloud
O Cloud Run se integra ao ecossistema mais amplo do Google Cloud, o que permite criar aplicativos completos.
As integrações essenciais incluem:
- Armazenamento de dados
- O Cloud Run se integra ao Cloud SQL (MySQL gerenciado, PostgreSQL e SQL Server), Memorystore (gerenciado Redis e Memcached), Firestore, Cloud Spanner, Cloud Storage e muito mais. Consulte Armazenamento de dados para ver uma lista completa.
- Geração de registros e relatórios de erros
- O Cloud Logging ingere automaticamente os registros de contêiner. Se houver exceções nos registros, o Error Reporting os agrega e notifica você. As seguintes linguagens são compatíveis: Go, Java, Node.js, PHP, Python, Ruby e .NET.
- Identidade do serviço
- Cada revisão do Cloud Run está vinculada a uma conta de serviço, e as bibliotecas de cliente do Google Cloud usam essa conta de serviço de maneira transparente para autenticar com as APIs do Google Cloud .
- Entrega contínua
- Se você armazenar seu código-fonte no GitHub, poderá configurar o Cloud Run para implantar automaticamente novas confirmações.
- Rede privada
- As instâncias do Cloud Run podem acessar recursos na rede de nuvem privada virtual (VPC) por meio do conector de acesso à VPC sem servidor. É assim que seu serviço se conecta com as máquinas virtuais ou os produtos do Compute Engine baseados no Compute Engine, como o Google Kubernetes Engine ou o Memorystore.
- APIs doGoogle Cloud
- O código do serviço é autenticado de maneira transparente com as APIs do Google Cloud . Isso inclui as APIs de IA e machine learning, como a API Cloud Vision, API Speech-to-Text, API AutoML Natural Language, API Cloud Translation e muito mais.
- Tarefas em segundo plano
- É possível programar um código para ser executado posteriormente ou imediatamente após retornar uma solicitação da Web. O Cloud Run funciona bem com o Cloud Tasks para oferecer uma execução assíncrona escalonável e confiável.
Consulte Como se conectar a serviços do Google Cloud para conferir uma lista dos vários serviços do Google Cloud que funcionam bem com o Cloud Run.
O código está sendo executado em uma imagem de contêiner
Não é necessário ter familiaridade com contêineres para implantar seu código em um Cloud Run, mas ele sempre acaba sendo executado em instâncias de contêiner em sandbox.
Se você não estiver familiarizado com os contêineres, veja uma breve introdução conceitual.

Como o diagrama mostra, você usa o código-fonte, os recursos e as dependências da biblioteca para criar a imagem do contêiner, que é um pacote com tudo o que seu serviço precisa para ser executado. Isso inclui artefatos de build, recursos, pacotes do sistema e, opcionalmente, um ambiente de execução. Isso facilita a portabilidade de um aplicativo em contêiner. Ele funciona em qualquer lugar onde um contêiner possa ser executado. Exemplos de artefatos de build incluem binários compilados ou arquivos de script, e os exemplos de ambientes de execução são o ambiente de execução JavaScript em Node.js ou uma máquina virtual Java (JVM).
Profissionais avançados valorizam o fato de que o Cloud Run não impõe outros encargos à execução do código: é possível executar qualquer binário no Cloud Run.
Se você quiser mais conveniência ou delegar o contêiner de aplicativos ao Google, o Cloud Run se integra aos buildpacks de código aberto do Google Cloud para oferecer uma implantação baseada na origem.
A seguir
- Implantar um serviço do Cloud Run
- Criar e executar um job do Cloud Run
- Saiba como executar jobs no prazo
- Implantar um pool de workers
- Conheça o modelo de recursos
- Leia mais sobre o contrato de ambiente de execução do contêiner