
Questa pagina descrive come importare le informazioni del catalogo e mantenerle aggiornate.
Le procedure di importazione descritte in questa pagina si applicano sia ai consigli sia alla ricerca. Dopo aver importato i dati, entrambi i servizi possono utilizzarli, quindi non è necessario importare gli stessi dati due volte se utilizzi entrambi i servizi.
Puoi importare i dati di prodotto da BigQuery o specificare i dati incorporati nella richiesta. Ciascuna di queste procedure è un'importazione una tantum, ad eccezione del collegamento di Merchant Center. Pianifica importazioni regolari del catalogo (idealmente, una volta al giorno) per verificare che sia aggiornato.
Consulta Mantieni il catalogo aggiornato.
Puoi anche importare singoli articoli di prodotto. Per ulteriori informazioni, consulta Caricare un prodotto.
Prima di iniziare
Prima di iniziare a importare il catalogo, devi:
- Configurare il progetto.
- Creare un service account.
- Aggiungi il account di servizio al tuo ambiente locale.
Per ulteriori informazioni, consulta la sezione Prerequisiti di configurazione.
Considerazioni sull'importazione del catalogo
Questa sezione descrive i metodi che possono essere utilizzati per l'importazione batch dei dati del catalogo, quando potresti utilizzare ciascun metodo e alcune delle relative limitazioni.
| BigQuery | Descrizione | Importa i dati da una tabella BigQuery caricata in precedenza che utilizza lo schema di AI Commerce Search. Può essere eseguita utilizzando la console Google Cloud o curl. |
|---|---|---|
| Quando utilizzarlo |
Se hai cataloghi di prodotti con molti attributi. L'importazione
BigQuery utilizza lo schema di ricerca AI Commerce, che ha più attributi
del prodotto rispetto ad altre opzioni di importazione, inclusi gli attributi
personalizzati chiave/valore.
Se hai grandi volumi di dati. L'importazione BigQuery non ha un limite di dati. Se utilizzi già BigQuery. |
|
| Limitazioni | Richiede il passaggio aggiuntivo di creazione di una tabella BigQuery che corrisponda allo schema di AI Commerce Search. | |
| Cloud Storage | Descrizione |
Importa i dati in formato JSON dai file caricati in un bucket Cloud Storage. Ogni file deve avere dimensioni pari o inferiori a 2 GB e possono essere importati fino a 100 file alla volta. L'importazione può essere eseguita utilizzando la console Google Cloud
o curl. Utilizza il formato dei dati JSON Product, che consente
attributi personalizzati.
|
| Quando utilizzarlo | Se devi caricare una grande quantità di dati in un solo passaggio. | |
| Limitazioni | Non è ideale per i cataloghi con aggiornamenti frequenti di inventario e prezzi perché le modifiche non vengono applicate immediatamente. | |
| Importazione in linea | Descrizione |
Importa utilizzando una chiamata al metodo Product.import. Utilizza
l'oggetto ProductInlineSource, che ha meno attributi del catalogo
dei prodotti rispetto allo schema AI Commerce Search, ma supporta attributi
personalizzati.
|
| Quando utilizzarlo | Se hai dati di catalogo non relazionali e non strutturati o una frequenza elevata di aggiornamenti di quantità o prezzi. | |
| Limitazioni | È possibile importare non più di 100 elementi del catalogo alla volta. Tuttavia, è possibile eseguire molti passaggi di caricamento; non esiste alcun limite di elementi. |
Tutorial
Questa sezione esplora diversi metodi di importazione del catalogo con un video e tutorial di base.
Video tutorial
Guarda questo video per scoprire come importare un catalogo utilizzando l'API AI Commerce Search.
Tutorial sull'importazione del catalogo da BigQuery
Questo tutorial mostra come utilizzare una tabella BigQuery per importare grandi quantità di dati di catalogo senza limiti.
Per seguire le indicazioni dettagliate per questa attività direttamente nell'editor di Cloud Shell, fai clic su Procedura guidata:
Tutorial sull'importazione del catalogo da Cloud Storage
Questo tutorial mostra come importare un gran numero di articoli in un catalogo.
Per seguire le indicazioni dettagliate per questa attività direttamente nell'editor di Cloud Shell, fai clic su Procedura guidata:
Tutorial sull'importazione dei dati del catalogo in linea
Questo tutorial mostra come importare i prodotti in un catalogo in linea.
Per seguire le indicazioni dettagliate per questa attività direttamente nell'editor di Cloud Shell, fai clic su Procedura guidata:
Best practice per l'importazione del catalogo
Per generare risultati di alta qualità sono necessari dati di alta qualità. Se nei tuoi dati mancano campi o sono presenti valori segnaposto anziché valori effettivi, la qualità delle previsioni e dei risultati di ricerca ne risente.
Quando importi i dati del catalogo, assicurati di implementare le seguenti best practice:
Assicurati di distinguere con attenzione i prodotti principali dalle varianti dei prodotti. Prima di caricare i dati, consulta la sezione Livelli di prodotto.
Modifica la configurazione a livello di prodotto dopo aver dedicato uno sforzo significativo all'importazione dei dati. Gli articoli principali, non le varianti, vengono restituiti come risultati di ricerca o consigli.
Esempio: se il gruppo SKU principale è Maglietta a V,il modello di raccomandazione restituisce una maglietta a V e, magari, una maglietta a girocollo e una a barchetta. Tuttavia, se le varianti non vengono utilizzate e ogni SKU è primario, ogni combinazione di colore o taglia della maglietta a V viene restituita come articolo distinto nel riquadro dei consigli: maglietta a V marrone, taglia XL, maglietta a V marrone, taglia L,fino a maglietta a V bianca, taglia M, maglietta a V bianca, taglia S.
Le raccolte possono essere riconosciute insieme se gli ID variante sono inclusi insieme agli ID prodotto principali in
collectionMemberIds[]. In questo modo, una raccolta di prodotti, da cui un utente può aver acquistato uno o più prodotti del set, viene acquisita nell'evento utente, accreditando l'intero set all'acquisto. Ciò facilita la visualizzazione di altri prodotti della stessa raccolta per lo stesso utente in una query correlata futura.Esempio: un utente ha acquistato in precedenza una coperta, quindi vengono restituiti i prodotti corrispondenti in una collezione di lenzuola, come le federe.
Rispetta i limiti di importazione degli articoli di prodotto.
Per l'importazione collettiva da Cloud Storage, le dimensioni di ogni file devono essere pari o inferiori a 2 GB. Puoi includere fino a 100 file alla volta in un'unica richiesta di importazione in blocco.
Per l'importazione in linea, importa non più di 5000 elementi prodotto alla volta.
Assicurati che le informazioni richieste del catalogo siano incluse e corrette. Non utilizzare valori segnaposto.
Includi quante più informazioni facoltative del catalogo possibile.
Assicurati che tutti i tuoi eventi utilizzino una singola valuta, soprattutto se prevedi di utilizzare la consoleGoogle Cloud per ottenere le metriche sulle entrate. L'API AI Commerce Search non supporta l'utilizzo di più valute per catalogo.
Mantieni il catalogo aggiornato, idealmente ogni giorno. La pianificazione di importazioni periodiche del catalogo impedisce che la qualità del modello diminuisca nel tempo. Puoi pianificare importazioni automatiche e ricorrenti quando importi il catalogo utilizzando AI Commerce Search nella console Gemini Enterprise for Customer Experience. In alternativa, puoi utilizzare Google Cloud Scheduler per automatizzare le importazioni.
Non registrare eventi utente per gli articoli di prodotto che non sono ancora stati importati.
Dopo aver importato le informazioni del catalogo, esamina le informazioni su segnalazione e registrazione degli errori per il tuo progetto. Se trovi più di qualche errore, esaminali e correggi eventuali problemi di elaborazione che hanno causato gli errori.
La pipeline di importazione dati di AI Commerce Search comprende sia il catalogo prodotti sia i dati sugli eventi utente. Questo stream di dati fornisce le basi per un addestramento solido del modello e una valutazione continua tramite meccanismi di feedback. L'importazione dati accurati e completi non è solo un prerequisito, ma un processo continuo essenziale per mantenere l'adattabilità dei modelli sottostanti. A sua volta, questo influisce direttamente sulla qualità e sulla pertinenza dei risultati di ricerca, offrendo un significativo ritorno sull'investimento.
Tieni presente queste best practice per l'importazione dati quando progetti la tua soluzione di ricerca per il commercio.
Importazione collettiva, streaming in tempo reale o entrambi?
AI Commerce Search offre due metodi principali per l'importazione del catalogo:
Importazione collettiva
Flussi di dati in tempo reale
Questo duplice approccio soddisfa le diverse esigenze architetturali dei vari backend dei clienti. Non è necessario scegliere esclusivamente un metodo; è possibile utilizzare una modalità di importazione ibrida, che utilizza sia l'importazione collettiva sia gli aggiornamenti in streaming in base a requisiti specifici.
Le importazioni collettive sono ideali quando si ha a che fare con aggiunte, eliminazioni o aggiornamenti su larga scala di migliaia di prodotti contemporaneamente. Al contrario, lo streaming in tempo reale è ideale quando sono necessari aggiornamenti continui per un volume relativamente ridotto di prodotti. La scelta tra questi metodi dipende dalla natura del catalogo prodotti, dalla frequenza degli aggiornamenti e dall'architettura complessiva dei sistemi di backend.
La funzionalità di importazione collettiva supporta tre origini dati distinte:
- BigQuery: BigQuery facilita la modifica rapida dei dati del catalogo, consente di specificare le date delle partizioni durante l'importazione e permette una trasformazione efficiente dei dati tramite query SQL.
- Google Cloud Storage: Cloud Storage richiede il rispetto di formati specifici, come JSON, e di limitazioni dei file. Gli utenti sono responsabili della gestione delle strutture dei bucket, della suddivisione dei file in blocchi e di altri aspetti della procedura di importazione. Inoltre, la modifica diretta del catalogo in Cloud Storage può essere macchinosa e, sebbene potenzialmente conveniente, manca della flessibilità di altri metodi.
- Dati in linea: per cataloghi estesi, le importazioni in linea potrebbero non essere l'opzione più scalabile a causa dei limiti di dimensioni. Riserva il loro utilizzo per aggiornamenti minori o test sperimentali.
Per gli scenari che prevedono un volume elevato di aggiornamenti del catalogo prodotti (migliaia di modifiche, aggiunte o eliminazioni di prodotti) in un breve periodo di tempo e a intervalli regolari, un approccio combinato di importazioni collettive e streaming in tempo reale può essere molto efficace. Organizza gli aggiornamenti in BigQuery o Cloud Storage ed esegui importazioni collettive incrementali a intervalli regolari, ad esempio ogni ora o due. Questo metodo gestisce in modo efficiente gli aggiornamenti su larga scala riducendo al minimo le interruzioni.
Per aggiornamenti più piccoli e meno frequenti o per quelli che richiedono un aggiornamento immediato nel catalogo, utilizza l'API di streaming in tempo reale. Nell'approccio ibrido, lo streaming in tempo reale può colmare le lacune tra le importazioni collettive, garantendo che il catalogo rimanga aggiornato. Questa strategia trova un equilibrio tra l'esecuzione di singole chiamate API REST (per l'applicazione di patch ai prodotti) e l'esecuzione di modifiche collettive, ottimizzando sia l'efficienza che la reattività nella gestione del catalogo di AI Commerce Search.
Strategie di ramificazione per la gestione del catalogo
Mantieni un catalogo unificato all'interno di un singolo ramo anziché avere cataloghi diversi in più rami. Questa pratica semplifica gli aggiornamenti del catalogo e riduce il rischio di incoerenze durante il cambio di ramo.
Le seguenti strategie di ramificazione comuni sono efficaci per la gestione del catalogo.
Aggiornamenti di una singola filiale
Imposta un ramo live come predefinito e aggiornalo continuamente man mano che vengono apportate modifiche al catalogo. Per gli aggiornamenti collettivi, utilizza la funzionalità di importazione nei periodi di traffico ridotto per ridurre al minimo le interruzioni. Utilizza le API di streaming per aggiornamenti incrementali più piccoli o raggruppali in blocchi più grandi per importazioni regolari.
Cambio di branch
Esistono due opzioni per gestire i diversi rami:
Utilizza i rami per lo staging e la verifica:
- Alcuni ingegneri di siti di e-commerce optano per un approccio di cambio di ramo, in cui il catalogo viene aggiornato all'interno di un ramo non live e poi reso il ramo predefinito (live) quando è pronto per la produzione. In questo modo è possibile preparare in anticipo il catalogo del giorno successivo. Gli aggiornamenti possono essere eseguiti utilizzando l'importazione collettiva o lo streaming nel ramo non live, garantendo una transizione senza interruzioni durante i periodi di scarso traffico.
- La scelta tra queste strategie dipende dai tuoi requisiti specifici, dalla frequenza degli aggiornamenti e dalla configurazione dell'infrastruttura. Tuttavia, indipendentemente dalla strategia scelta, mantenere un catalogo unificato all'interno di un singolo branch è fondamentale per un rendimento ottimale e risultati di ricerca coerenti in AI Commerce Search.
Utilizza i rami per i backup:
- Un singolo ramo live si concentra sull'inserimento e sull'elaborazione continui degli aggiornamenti dei prodotti per mantenere l'indice della Ricerca AI Commerce aggiornato quasi in tempo reale.
- Un altro ramo si concentra sulla creazione di uno snapshot giornaliero dei dati trasformati in AI Commerce Search, fungendo da solido meccanismo di fallback in caso di danneggiamento dei dati o problemi con il ramo 0.
- Un terzo ramo si concentra sulla creazione di uno snapshot settimanale della data trasformata. In questo modo, il cliente può avere un backup di un giorno e un backup di una settimana in rami diversi.
Eliminare definitivamente i branch del catalogo
Se importi nuovi dati del catalogo in un ramo esistente, è importante che il ramo del catalogo sia vuoto per garantire l'integrità dei dati importati nel ramo. Quando il ramo è vuoto, puoi importare nuovi dati del catalogo e collegare il ramo a un account commerciante.
Se pubblichi traffico di previsione in tempo reale o di ricerca e prevedi di eliminare il ramo predefinito, ti consigliamo di specificare prima un altro ramo come predefinito. Poiché il ramo predefinito restituirà risultati vuoti dopo essere stato eliminato, l'eliminazione di un ramo predefinito attivo può causare un'interruzione.
Per eliminare i dati da una filiale del catalogo:
Vai alla pagina Dati nella console AI Commerce Search in Gemini Enterprise for Customer Experience.
Vai alla pagina DatiSeleziona un branch catalogo dal campo Nome branch.
Nel menu con tre puntini accanto al campo Nome ramo, scegli Elimina ramo.
Viene visualizzato un messaggio che ti avvisa che stai per eliminare tutti i dati nel ramo, nonché tutti gli attributi creati per il ramo.
Inserisci la filiale e fai clic su Conferma per eliminare definitivamente i dati del catalogo dalla filiale.
Viene avviata un'operazione a lunga esecuzione per eliminare i dati dal ramo del catalogo. Al termine dell'operazione di eliminazione definitiva, lo stato dell'eliminazione definitiva viene visualizzato nell'elenco Catalogo prodotti nella finestra Stato attività.
Aggiornamenti dell'inventario in AI Commerce Search
Questa sezione descrive come ottimizzare il rendimento di AI Commerce Search eseguendo aggiornamenti regolari dell'inventario.
Flussi di dati in tempo reale
- Per i dati dinamici come le informazioni sull'inventario (prezzo, disponibilità) e i dettagli a livello di negozio, inclusi lo stato dell'evasione ordine e i prezzi specifici per negozio, lo streaming in tempo reale è l'unica opzione disponibile nella ricerca AI Commerce.
- Questa distinzione nasce dalla natura ad alta frequenza delle fluttuazioni dell'inventario rispetto ai dati del catalogo prodotti relativamente statici. La disponibilità dei prodotti può variare più volte al giorno, mentre le descrizioni o gli attributi rimangono relativamente costanti.
- La frequenza degli aggiornamenti a livello di negozio aumenta ulteriormente con il numero di punti vendita.
Aggiornamenti asincroni
- Per adattarsi a questo rapido ritmo di cambiamento, la ricerca AI Commerce utilizza aggiornamenti asincroni dell'inventario tramite API che restituiscono un ID job.
- Il processo di aggiornamento non viene considerato completato finché lo stato del job non viene sottoposto a polling e confermato, il che potrebbe introdurre un leggero ritardo che va da secondi a minuti.
Aggiornamenti fuori sequenza
- Una funzionalità importante di questo sistema è la possibilità di aggiornare le informazioni sull'inventario prima che il prodotto corrispondente venga inserito nel catalogo. In questo modo si risolve lo scenario comune in cui le pipeline di dati di inventario e prodotto operano in modo indipendente all'interno dei rivenditori, il che a volte porta le informazioni sull'inventario a essere disponibili prima dell'aggiornamento del catalogo dei prodotti. Quando aggiorni l'inventario, utilizza l'opzione
allowMissingper gestire gli aggiornamenti fuori ordine dell'inventario rispetto al prodotto. - Consentendo agli aggiornamenti dell'inventario di precedere l'importazione del catalogo, AI Commerce Search tiene conto di queste discrepanze della pipeline, garantendo che siano disponibili dati di inventario accurati anche per i prodotti appena introdotti.
- Tuttavia, le informazioni di inventario per un prodotto vengono conservate per 24 ore e verranno eliminate se non viene inserito un prodotto corrispondente entro questo periodo. Questo meccanismo garantisce la coerenza dei dati e impedisce che nel sistema rimangano informazioni di inventario obsolete.
Controlli preliminari del catalogo dei prodotti per test A/B affidabili in AI Commerce Search
Questa sezione illustra come eseguire i controlli preliminari sui dati del catalogo prodotti.
Garantire la parità degli aggiornamenti del catalogo
- In preparazione a un test A/B all'interno di AI Commerce Search, è fondamentale mantenere una stretta parità tra il catalogo legacy (controllo) e il catalogo AI Commerce Search (test). Eventuali squilibri tra i due possono influire negativamente sul test A/B, portando a osservazioni distorte e risultati potenzialmente non validi. Ad esempio, le incoerenze nella disponibilità del prodotto, nei prezzi o anche piccole discrepanze degli attributi possono introdurre bias involontari nei dati di test.
- Per mitigare questo rischio, è imperativo progettare una procedura di aggiornamento parallela per i cataloghi di controllo e di test, evitando aggiornamenti sequenziali ogni volta che è possibile. L'obiettivo è massimizzare il periodo di tempo durante il quale entrambi i cataloghi sono sincronizzati. Gli aggiornamenti seriali, invece, possono introdurre ritardi in una corsia o nell'altra. Questi ritardi possono causare discrepanze temporanee nel catalogo, in cui un prodotto potrebbe essere disponibile in un catalogo ma non nell'altro. In alternativa, un prodotto appena aggiunto viene visualizzato in un catalogo prima che nell'altro. Queste disparità possono influenzare in modo significativo il comportamento, i clic e gli acquisti degli utenti, portando in definitiva a un confronto ingiusto e a risultati del test A/B imprecisi.
- Dando la priorità agli aggiornamenti paralleli e puntando a una parità coerente del catalogo, i retailer possono garantire condizioni di parità per i test A/B all'interno di AI Commerce Search. Questo approccio consente un'analisi imparziale ed equa dei risultati del test, portando a approfondimenti più affidabili e a un processo decisionale più consapevole.
Raggiungere la parità dei dati del catalogo
- La profondità e l'accuratezza della comprensione dei prodotti di un modello di ricerca e-commerce dipendono dalla ricchezza e dalla qualità delle informazioni del catalogo dei prodotti sottostante. Più completi sono i dati di prodotto all'interno del catalogo, più il modello è in grado di comprendere e classificare i prodotti in modo efficace.
- Pertanto, in preparazione al test A/B, è fondamentale assicurarsi che i dati di prodotto caricati sia nel catalogo legacy (controllo) sia nel catalogo AI Commerce Search (test) siano identici. Eventuali discrepanze nelle informazioni sui prodotti tra questi due ambienti possono distorcere in modo significativo i risultati del test A/B.
- Ad esempio, se il motore di ricerca legacy beneficia di un catalogo più ricco o più ampio rispetto ad AI Commerce Search, ciò crea un vantaggio sleale. Le informazioni mancanti nel catalogo di AI Commerce Search potrebbero essere fondamentali per la comprensione e la classificazione dei prodotti, con conseguente potenziale imprecisione dei risultati di ricerca e confronti fuorvianti del rendimento. Il rilevamento di queste disparità può essere difficile con strumenti esterni e spesso richiede un'ispezione manuale meticolosa di entrambi i cataloghi.
- Se si assicurano diligentemente che entrambi i cataloghi contengano gli stessi dati di prodotto con lo stesso livello di dettaglio, i rivenditori possono creare condizioni di parità per i test A/B nella ricerca AI Commerce. Questo approccio favorisce un confronto equo e imparziale dei due motori di ricerca, facilitando una valutazione accurata delle rispettive prestazioni e funzionalità.
Pianificazione del ripristino di emergenza
Un piano di ripristino di emergenza ben preparato garantisce che le funzionalità di ricerca di commercio rimangano operative e reattive, riducendo al minimo l'impatto sull'esperienza cliente e sulla generazione di entrate. Questo piano dovrebbe consentire il rapido ripristino del catalogo per risolvere il potenziale errore delle pipeline di importazione del catalogo e degli eventi utente, indipendentemente dalla causa sottostante.
L'utilizzo di BigQuery per lo staging dei dati offre un vantaggio distinto nel ripristino di emergenza. Se i dati attuali del catalogo o i dati sugli eventi utente all'interno di AI Commerce Search non sono significativamente diversi dall'istantanea più recente archiviata in BigQuery, la chiamata all'API di importazione può avviare un ripristino rapido. Questo approccio riduce al minimo i tempi di inattività e garantisce che la funzionalità di ricerca rimanga operativa.
Al contrario, se BigQuery non è integrato nella pipeline di dati, devono essere in atto meccanismi alternativi per ricaricare rapidamente il catalogo da uno stato buono noto. Questi meccanismi potrebbero includere sistemi di backup, replica dei dati o altre strategie di failover.
Se incorpori queste considerazioni sul ripristino di emergenza nell'architettura di AI Commerce Search, puoi rafforzare la robustezza del sistema e mantenere la continuità aziendale anche in caso di interruzioni impreviste.
Pianificare l'alta affidabilità
Quando carichi il catalogo dei prodotti in AI Commerce Search, è importante considerare il modo in cui i diversi servizi gestiscono la regionalità per progettare una pipeline di importazione dati resiliente. Google Cloud
Per creare una pipeline di importazione in grado di eseguire il ripristino di emergenza utilizzando Dataflow, esegui il deployment dei job in più regioni utilizzando uno dei seguenti design:
- Attivo/attivo:le istanze Dataflow in più regioni elaborano attivamente i dati contemporaneamente.
- Attivo/passivo:un'istanza Dataflow in una regione è attiva, mentre le istanze in altre regioni rimangono in standby.
Ecco come implementare questi progetti con Pub/Sub e Dataflow:
- Servizi globali:alcuni servizi, come Pub/Sub, operano a livello globale. Google Cloud gestisce la loro disponibilità in base agli accordi sul livello del servizio (SLA) specifici.
- Servizi regionali:altri servizi, come Dataflow, che potresti utilizzare per trasformare e importare i dati in AI Commerce Search, sono regionali. Sei responsabile della configurazione di questi componenti per l'alta affidabilità e ripristino di emergenza.
Ad esempio, quando utilizzi BigQuery per archiviare i dati, puoi configurarlo in modo che sia multiregionale, in modo che la ridondanza e la disponibilità dei dati vengano gestite automaticamente da Google Cloud. Allo stesso modo, quando utilizzi Cloud Storage, puoi configurarlo in modo che sia multiregionale.
Progettazione attivo/attivo
La progettazione active/active utilizza gli attributi dei messaggi Pub/Sub e i filtri di sottoscrizione per garantire che ogni messaggio venga elaborato esattamente una volta da un job Dataflow attivo in una regione specifica.
Aggiungi attributi del messaggio: quando pubblichi messaggi nell'argomento Pub/Sub, ad esempio aggiornamenti dei prodotti, includi un attributo che indichi la regione di destinazione. Ad esempio:
region:us-central1region:us-east1
Configura i filtri delle sottoscrizioni: per ogni pipeline Dataflow regionale, configura la relativa sottoscrizione Pub/Sub in modo da estrarre solo i messaggi corrispondenti alla regione utilizzando i filtri dei messaggi. Ad esempio, l'abbonamento per il job Dataflow
us-central1avrebbe un filtro comeattributes.region = "us-central1".Failover: se una regione non è più disponibile, aggiorna il sistema di pubblicazione upstream in modo da taggare tutti i nuovi messaggi con un attributo per una regione integra. In questo modo, l'elaborazione dei messaggi viene reindirizzata all'istanza Dataflow nella regione di failover.
Per impostazione predefinita, è possibile configurare più componenti utilizzati nell'architettura in modo che siano multiregionali. Ad esempio, quando utilizzi BigQuery per archiviare i dati, puoi configurarlo in modo che sia multiregionale, in modo che la ridondanza e la disponibilità dei dati vengano gestite automaticamente da Cloud Storage. Allo stesso modo, quando utilizzi Cloud Storage, puoi configurarlo in modo che sia multiregionale.
Design attivo/passivo
Questo design prevede che in qualsiasi momento sia attiva una sola pipeline Dataflow regionale che recupera i messaggi da Pub/Sub.
Collega un abbonamento: assicurati che sia collegato e stia recuperando i messaggi solo l'abbonamento Pub/Sub per il job Dataflow della regione attiva. Le sottoscrizioni per i job Dataflow nelle regioni passive devono essere create, ma rimangono separate.
Failover: se la regione attiva subisce un errore, manualmente o a livello di programmazione:
- Scollega la sottoscrizione Pub/Sub associata al job Dataflow della regione non riuscita.
- Collega l'abbonamento Pub/Sub associato a un job Dataflow in una delle regioni passive (di standby).
In questo modo, il carico di elaborazione dei messaggi viene trasferito alla regione appena attivata.
Resilienza e analisi forense
L'utilizzo di BigQuery nella progettazione dell'importazione dati può comportare la gestione della resilienza e la creazione di funzionalità per l'analisi forense e il debug. I prodotti e l'inventario inseriti direttamente con le API patch e addLocalInventory implicano che, quando i dati vengono inviati alla ricerca AI Commerce, non rimane alcuna traccia dell'aggiornamento di prodotti e inventario. L'utente potrebbe voler sapere perché un prodotto non viene visualizzato come previsto. Disporre di un'area di gestione temporanea creata con BigQuery con una cronologia completa dei dati facilita questo tipo di indagine e debug.
Architettura di riferimento
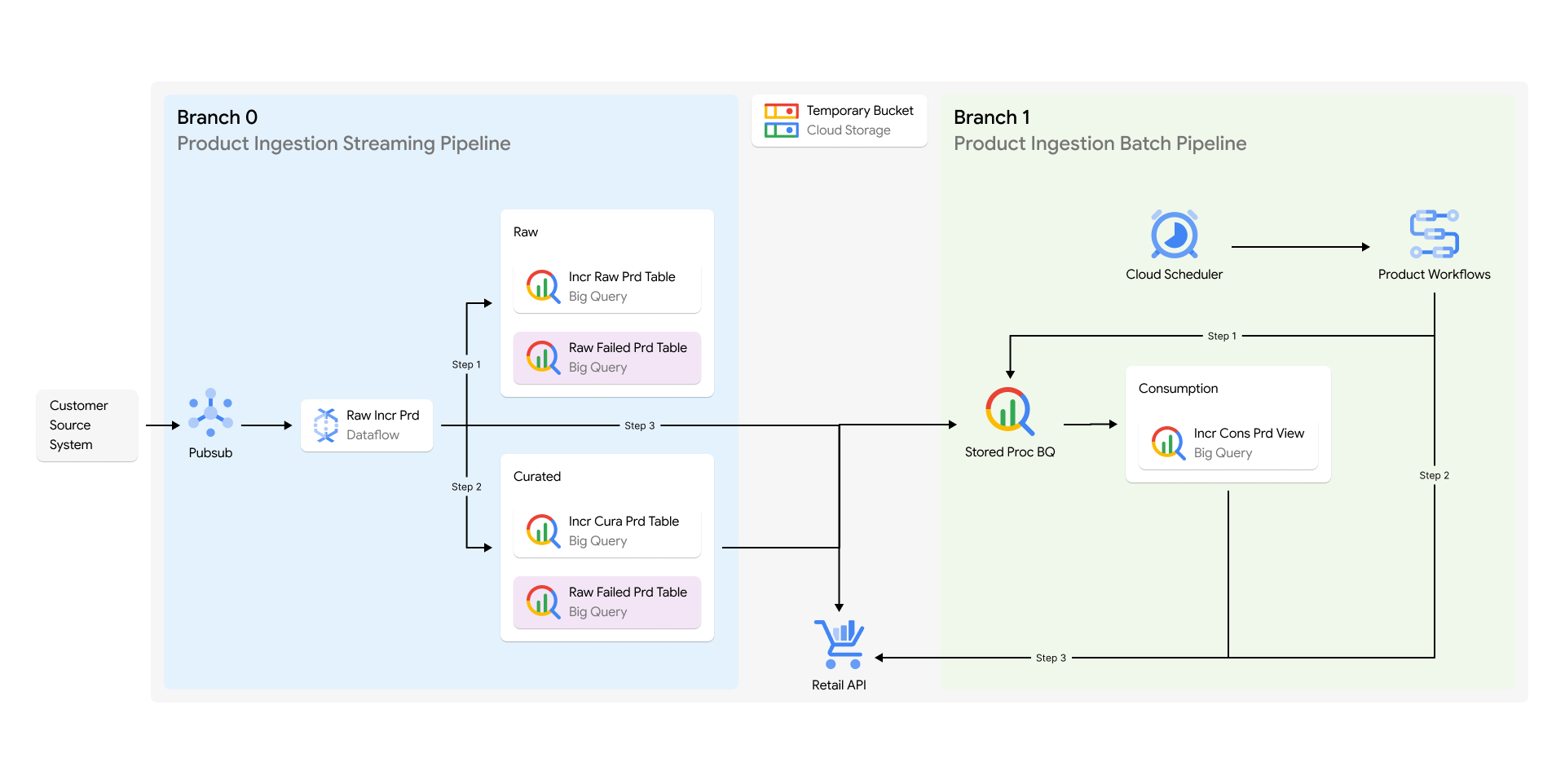
In questa architettura, l'importazione dati in genere prevede fasi non elaborate, curate e di consumo, tutte basate su BigQuery. Il sistema sposterebbe i dati tra le fasi utilizzando Dataflow e orchestrerebbe l'automazione di tutto ciò utilizzando i workflow cloud:
- Il sistema prende i dati non elaborati così come sono e li timestamp per mantenere la cronologia. Questi dati non sono stati modificati, quindi i clienti li considereranno una fonte attendibile.
- Il sistema trasforma i dati in una fase curata e li tagga nuovamente con l'ora. In questo modo i clienti sapranno quando è stata eseguita la trasformazione e se si è verificato un errore.
- Infine, il sistema creerebbe viste nella fase di consumo sui dati selezionati utilizzando l'ora in cui il sistema ha taggato i dati in precedenza. In questo modo, il cliente saprà esattamente quali dati trasformati devono essere infine importati nella ricerca AI Commerce.
I rami 0, 1 e 2 fungono da backup live, di un giorno e di una settimana. I dati inseriti direttamente nel ramo 0 vengono aggregati e indicizzati nel ramo 1 giornalmente e nel ramo 2 settimanalmente. In questo modo, qualsiasi danneggiamento dei dati può essere ripristinato, migliorando così la continuità aziendale e la resilienza del sistema.
Inoltre, è possibile eseguire analisi e debug poiché l'intera cronologia e la derivazione dei dati vengono mantenute nei set di dati BigQuery globali.
Pianificare i casi limite con l'importazione del catalogo
Una volta stabiliti i meccanismi principali per l'importazione del catalogo in AI Commerce Search, un approccio proattivo prevede la valutazione della loro resilienza a vari casi limite. Anche se alcuni di questi scenari potrebbero non essere immediatamente pertinenti ai tuoi requisiti aziendali specifici, tenerli in considerazione nella progettazione del backend può fornire una preziosa garanzia per il futuro.
Questo passaggio preparatorio prevede la revisione della capacità della pipeline di dati di gestire scenari imprevisti o casi limite, garantendo la sua robustezza e adattabilità alle esigenze in evoluzione. Anticipando i potenziali problemi e risolvendoli in modo proattivo, puoi ridurre le interruzioni future e mantenere il flusso continuo di dati di prodotto nel tuo sistema di ricerca AI Commerce.
A questo scopo, la logica di Dataflow deve essere creata in modo che:
Convalida ogni elemento dei dati non elaborati in modo che corrisponda a uno schema appropriato. Il contratto dei dati non elaborati deve essere determinato in anticipo e ogni elemento di dati deve essere sempre confrontato con il contratto. In caso di errore di convalida, l'elemento di dati non elaborati deve essere contrassegnato con un timestamp e reso persistente nelle tabelle non elaborate non riuscite di BigQuery con gli errori effettivi destinati all'analisi forense.
Alcuni esempi di questo errore potrebbero essere:
- Un determinato attributo che non fa parte del contratto appare improvvisamente nell'elemento di dati non elaborati.
- Un determinato attributo obbligatorio non è presente nell'elemento di dati non elaborati.
Convalida ogni elemento dei dati non elaborati per la trasformazione nel formato di AI Commerce Search. AI Commerce Search richiede alcuni campi obbligatori per l'importazione dei prodotti. Ogni elemento dei dati non elaborati deve ora essere ricontrollato per verificare se può essere trasformato correttamente nel formato dello schema di AI Commerce Search. In caso di errore di trasformazione, l'elemento di dati non elaborati deve essere contrassegnato con un timestamp e reso persistente nelle tabelle curate non riuscite di BigQuery con messaggi di errore effettivi che possono essere utili per l'analisi forense.
Alcuni esempi di questo errore potrebbero essere:
- Un determinato attributo, come il prezzo, non può essere formattato in un numero perché l'elemento di dati non elaborati è alfanumerico.
- Il nome del prodotto è completamente mancante.
Questo esempio mostra uno schema di tabella BigQuery di esempio per archiviare tutti gli errori per il debug:
Visualizza lo schema di esempio della tabella BigQuery
[ { "mode": "REQUIRED", "name": "ingestedTimestamp", "type": "TIMESTAMP" }, { "mode": "REQUIRED", "name": "payloadString", "type": "STRING" }, { "mode": "REQUIRED", "name": "payloadBytes", "type": "BYTES" }, { "fields": [ { "mode": "NULLABLE", "name": "key", "type": "STRING" }, { "mode": "NULLABLE", "name": "value", "type": "STRING" } ], "mode": "REPEATED", "name": "attributes", "type": "RECORD" }, { "mode": "NULLABLE", "name": "errorMessage", "type": "STRING" }, { "mode": "NULLABLE", "name": "stacktrace", "type": "STRING" } ]
Test di stress e scalabilità
Preparati a eventi e crescita con volumi elevati grazie a test di stress e scalabilità.
Eventi con traffico elevato
Eventi con traffico elevato come le festività rappresentano una sfida significativa per le pipeline di importazione dati. L'aumento degli aggiornamenti dell'inventario, inclusi i livelli di stock e i prezzi, e le potenziali modifiche agli attributi dei prodotti richiedono un'infrastruttura solida. È importante valutare se il sistema di importazione è in grado di gestire questo carico maggiore. I test di carico simulati, che replicano i pattern di picco del traffico, identificano i colli di bottiglia e garantiscono un funzionamento regolare durante questi periodi critici.
Offerte lampo
Le offerte lampo presentano una sfida unica a causa della loro breve durata e delle rapide fluttuazioni dell'inventario. Garantire la sincronizzazione dell'inventario in tempo reale è fondamentale per evitare discrepanze tra i risultati di ricerca e la disponibilità effettiva. In caso contrario, i clienti potrebbero avere esperienze negative, ad esempio prodotti popolari che risultano disponibili quando in realtà sono esauriti o viceversa. Inoltre, le variazioni di prezzo durante le vendite flash possono influire in modo significativo sul ranking dei prodotti, evidenziando la necessità di aggiornamenti dei prezzi accurati e tempestivi nell'indice di ricerca.
Espansione del catalogo
La crescita aziendale o l'espansione della linea di prodotti può comportare un aumento drastico, ad esempio di 5 o 10 volte, del numero di prodotti all'interno del catalogo. La tua architettura di importazione deve essere scalabile per adattarsi a questa crescita senza problemi. Ciò può richiedere di rivedere l'intera pipeline ETL (estrazione, trasformazione e caricamento), in particolare se vengono introdotte nuove origini dati o formati di informazioni sui prodotti.
Affrontando in modo proattivo questi potenziali scenari, puoi assicurarti che la pipeline di importazione della ricerca AI Commerce rimanga solida, scalabile e reattiva, anche in caso di picchi improvvisi di traffico, vendite lampo o crescita significativa del catalogo. Questo approccio proattivo salvaguarda l'accuratezza e l'affidabilità dei risultati di ricerca, contribuendo a un'esperienza utente positiva e al successo dell'attività.
Il rendimento della pipeline di importazione dati deve essere valutato e deve essere formata una baseline per le seguenti metriche:
- Quanto tempo è necessario per pubblicare e importare l'intero catalogo e i dati di inventario? Ciò potrebbe essere necessario su base ad hoc durante il BFCM, quando i prezzi possono variare in modo significativo per l'intero catalogo.
- Quanto tempo occorre per visualizzare l'aggiornamento di un singolo prodotto?
- Qual è la frequenza massima di aggiornamenti di prodotti e inventario che il sistema può elaborare?
Colli di bottiglia
- Valuta e scopri se le pipeline sono in grado di fare lo scale up e lo scale down correttamente.
- Determina se il limite massimo per il numero di istanze è troppo alto o troppo basso.
- Determina se il sistema è soggetto a limitazioni di frequenza da parte di AI Commerce Search controllando il codice HTTP 429.
- Verifica se è necessario aumentare determinate quote API per ridurre i limiti di frequenza.
Struttura dei dati di prodotto per l'importazione del catalogo
Questa sezione descrive come preparare i dati di prodotto per l'importazione del catalogo.
Prodotti principali
I prodotti principali fungono da contenitori per raggruppare le varianti dei prodotti e da voci nella griglia di ricerca. Devono essere specificati solo gli attributi comuni condivisi tra le varianti dei prodotti principali. tra cui:
- ID prodotto principale
- ID prodotto (identico all'ID prodotto principale)
- Titolo
- Descrizione
Per saperne di più, consulta la sezione Informazioni sugli attributi di prodotto.
Varianti di prodotto
Le varianti dei prodotti ereditano gli attributi comuni dal prodotto principale, ma possono anche specificare valori unici.
Gli attributi obbligatori includono:
- Tutti gli attributi specificati per i prodotti principali (titolo, descrizione). Il prezzo, il titolo e la descrizione possono essere diversi dal prodotto principale.
- Attributi specifici delle varianti (colore, taglia e altre varianti di prodotto pertinenti).
Per saperne di più, consulta la sezione Informazioni sugli attributi di prodotto.
Recupero degli attributi
Il processo di recupero prende in considerazione tutti gli attributi disponibili per la ricerca sia per i prodotti principali sia per le varianti dei prodotti.
Punteggio di pertinenza
Il punteggio di pertinenza si basa esclusivamente sui campi del titolo e della descrizione. Per garantire una differenziazione adeguata, modifica leggermente la variante rispetto ai titoli dei prodotti principali (ad esempio, Nome prodotto + Colore).
Corrispondenza delle varianti nei risultati di ricerca
La corrispondenza delle varianti (ad esempio, abito blu) filtra i risultati in base ad attributi delle varianti predefiniti come colore e taglia. I risultati di ricerca restituiscono fino a cinque varianti corrispondenti per ogni prodotto principale.
Sincronizzare Merchant Center con AI Commerce Search
Merchant Center è uno strumento che puoi utilizzare per rendere disponibili i dati di prodotto del tuo negozio per gli annunci Shopping e altri servizi Google.
Per una sincronizzazione continua tra Merchant Center e AI Commerce Search, puoi collegare il tuo account Merchant Center ad AI Commerce Search.
Quando configuri una sincronizzazione di Merchant Center per AI Commerce Search, devi disporre del ruolo IAM Amministratore assegnato in Merchant Center. Anche se un ruolo di accesso standard ti consente di leggere i feed Merchant Center, quando provi a sincronizzare Merchant Center con AI Commerce Search, viene visualizzato un messaggio di errore. Pertanto, prima di poter sincronizzare correttamente Merchant Center con AI Commerce Search, esegui l'upgrade del tuo ruolo.
Collega il tuo account Merchant Center
Anche se AI Commerce Search è collegata all'account Merchant Center, le modifiche ai dati di prodotto nell'account Merchant Center vengono aggiornate automaticamente in pochi minuti in AI Commerce Search. Se vuoi impedire la sincronizzazione delle modifiche di Merchant Center con AI Commerce Search, puoi scollegare il tuo account Merchant Center.
Scollegare l'account Merchant Center non comporta l'eliminazione dei prodotti in AI Commerce Search. Per eliminare i prodotti importati, consulta la sezione Eliminare le informazioni sui prodotti.
Per sincronizzare il tuo account Merchant Center, completa i seguenti passaggi.
Sincronizzare l'account Merchant Center
console Cloud
-
Vai alla pagina Dati nella console AI Commerce Search in Gemini Enterprise for Customer Experience.
Vai alla pagina Dati - Fai clic su Importa per aprire il riquadro Importa dati.
- Scegli Catalogo prodotti.
- Seleziona Sincronizzazione Merchant Center come origine dati.
- Seleziona il tuo account Merchant Center. Se non vedi il tuo account, controlla Accesso utente.
- (Facoltativo) Seleziona Filtro feed Merchant Center per importare solo le offerte dai feed selezionati.
Se non specificato, vengono importate le offerte di tutti i feed (inclusi i feed futuri). - (Facoltativo) Per importare solo le offerte destinate a determinati paesi o lingue, espandi Mostra opzioni avanzate e seleziona i paesi di vendita e le lingue di Merchant Center da filtrare.
- Seleziona il ramo in cui caricherai il catalogo.
- Fai clic su Importa.
curl
Verifica che l'account di servizio nel tuo ambiente locale abbia accesso sia all'account Merchant Center sia alla ricerca AI Commerce. Per verificare quali account hanno accesso al tuo account Merchant Center, consulta Accesso degli utenti per Merchant Center.
Utilizza il metodo
MerchantCenterAccountLink.createper stabilire il collegamento.curl -X POST \ -H "Authorization: Bearer $(gcloud auth application-default print-access-token)" \ -H "Content-Type: application/json; charset=utf-8" \ --data '{ "merchantCenterAccountId": MERCHANT_CENTER_ID, "branchId": "BRANCH_ID", "feedFilters": [ {"dataSourceId": DATA_SOURCE_ID_1} {"dataSourceId": DATA_SOURCE_ID_2} ], "languageCode": "LANGUAGE_CODE", "feedLabel": "FEED_LABEL", }' \ "https://retail.googleapis.com/v2alpha/projects/PROJECT_ID/locations/global/catalogs/default_catalog/merchantCenterAccountLinks"
- MERCHANT_CENTER_ID: l'ID dell'account Merchant Center.
- BRANCH_ID: l'ID del ramo con cui stabilire il collegamento. Accetta i valori "0", "1" o "2".
- LANGUAGE_CODE: (FACOLTATIVO) Il codice lingua di due lettere dei prodotti che vuoi importare. Come visualizzato in
Merchant Center nella colonna
Languagedel prodotto. Se non viene impostato, vengono importate tutte le lingue. - FEED_LABEL: (FACOLTATIVO) l'etichetta del feed dei prodotti che vuoi importare. Puoi visualizzare l'etichetta del feed in Merchant Center nella colonna Etichetta del feed del prodotto. Se non è impostato, vengono importate tutte le etichette dei feed.
- FEED_FILTERS: (FACOLTATIVO) Elenco dei feed principali da cui verranno importati i prodotti. Se non selezioni i feed, vengono condivisi tutti i feed dell'account Merchant Center. Gli ID
sono disponibili nella risorsa feed di dati dell'API Content o visitando
Merchant Center, selezionando un feed e
recuperando l'ID feed dal parametro afmDataSourceId nell'URL del sito. Ad esempio,
mc/products/sources/detail?a=MERCHANT_CENTER_ID&afmDataSourceId=DATA_SOURCE_ID.
Per visualizzare il tuo account Merchant Center collegato, vai alla pagina Dati della console AI Commerce Search in Gemini Enterprise for Customer Experience e fai clic sul pulsante Merchant Center in alto a destra nella pagina. Si aprirà il riquadro Account Merchant Center collegati. Da questo riquadro puoi anche aggiungere altri account Merchant Center.
Consulta Visualizzare informazioni aggregate sul catalogo per istruzioni su come visualizzare i prodotti importati.
Elenca i link agli account Merchant Center
console Cloud
Vai alla pagina Dati nella console AI Commerce Search in Gemini Enterprise for Customer Experience.
Vai alla pagina DatiFai clic sul pulsante Merchant Center in alto a destra della pagina per aprire un elenco dei tuoi account Merchant Center collegati.
curl
Utilizza il metodo MerchantCenterAccountLink.list
per elencare la risorsa dei link.
curl -X GET \ -H "Authorization: Bearer $(gcloud auth application-default print-access-token)" \ -H "Content-Type: application/json; charset=utf-8" \ "https://retail.googleapis.com/v2alpha/projects/PROJECT_NUMBER/locations/global/catalogs/default_catalog/merchantCenterAccountLinks"
Scollegare l'account Merchant Center
Se scolleghi il tuo account Merchant Center, questo non potrà più sincronizzare i dati del catalogo con AI Commerce Search. Questa procedura non elimina i prodotti in AI Commerce Search che sono già stati caricati.
console Cloud
Vai alla pagina Dati nella console AI Commerce Search in Gemini Enterprise for Customer Experience.
Vai alla pagina DatiFai clic sul pulsante Merchant Center in alto a destra della pagina per aprire un elenco dei tuoi account Merchant Center collegati.
Fai clic su Scollega accanto all'account Merchant Center che stai scollegando e conferma la tua scelta nella finestra di dialogo visualizzata.
curl
Utilizza il metodo MerchantCenterAccountLink.delete per rimuovere la risorsa MerchantCenterAccountLink.
curl -X DELETE \ -H "Authorization: Bearer $(gcloud auth application-default print-access-token)" \ -H "Content-Type: application/json; charset=utf-8" \ "https://retail.googleapis.com/v2alpha/projects/PROJECT_NUMBER/locations/global/catalogs/default_catalog/merchantCenterAccountLinks/BRANCH_ID_MERCHANT_CENTER_ID"
Limitazioni al collegamento a Merchant Center
Un account Merchant Center può essere collegato a un numero qualsiasi di rami del catalogo, ma un singolo ramo del catalogo può essere collegato a un solo account Merchant Center.
Un account Merchant Center non può essere un account multi-cliente (AMC). Tuttavia, puoi collegare singoli account secondari.
Il primo import dopo il collegamento dell'account Merchant Center può richiedere ore. La quantità di tempo dipende dal numero di offerte nell'account Merchant Center.
Qualsiasi modifica dei prodotti tramite i metodi API è disattivata per i rami collegati a un account Merchant Center. Eventuali modifiche ai dati del catalogo prodotti in questi rami devono essere apportate utilizzando Merchant Center. Queste modifiche vengono poi sincronizzate automaticamente con AI Commerce Search.
Il tipo di prodotto raccolta non è supportato per le filiali che utilizzano il collegamento a Merchant Center.
Per garantire l'accuratezza dei dati, il tuo account Merchant Center può essere collegato solo a rami vuoti del catalogo. Per eliminare i prodotti da una filiale del catalogo, vedi Eliminare le informazioni sui prodotti.
Importa dati del catalogo da BigQuery
Per importare i dati del catalogo nel formato corretto da BigQuery, utilizza lo schema di AI Commerce Search per creare una tabella BigQuery con il formato corretto e caricare la tabella vuota con i dati del catalogo. Poi, carica i dati in AI Commerce Search.
Per ulteriore assistenza con le tabelle BigQuery, consulta Introduzione alle tabelle. Per assistenza con le query BigQuery, consulta Panoramica sull'esecuzione di query sui dati di BigQuery.
Per seguire le indicazioni dettagliate per questa attività direttamente nell'editor di Cloud Shell, fai clic su Procedura guidata:
Per importare il tuo catalogo:
Se il set di dati BigQuery si trova in un altro progetto, configura le autorizzazioni richieste in modo che AI Commerce Search possa accedere al set di dati BigQuery. Scopri di più.
Importa i dati del catalogo in AI Commerce Search.
console Cloud
-
Vai alla pagina Dati nella console AI Commerce Search in Gemini Enterprise for Customer Experience.
Vai alla pagina Dati - Fai clic su Importa per aprire il riquadro Importa dati.
- Scegli Catalogo prodotti.
- Seleziona BigQuery come origine dati.
- Seleziona il ramo in cui caricherai il catalogo.
- Scegli Schema cataloghi dei prodotti di Retail. Questo è lo schema del prodotto per AI Commerce Search.
- Inserisci la tabella BigQuery in cui si trovano i dati.
- (Facoltativo) In Mostra opzioni avanzate, inserisci la posizione di un bucket Cloud Storage nel tuo progetto come posizione temporanea per i tuoi dati.
Se non specificata, viene utilizzata una località predefinita. Se specificati, BigQuery e il bucket Cloud Storage devono trovarsi nella stessa regione. - Se la ricerca non è attivata e utilizzi
lo schema Merchant Center, seleziona il livello prodotto.
Devi selezionare il livello prodotto se è la prima volta che importi il catalogo o se lo reimporti dopo averlo eliminato. Scopri di più sui livelli dei prodotti. Modificare i livelli di prodotto dopo aver importato i dati richiede uno sforzo significativo.
Importante:non puoi attivare la ricerca per i progetti con un catalogo di prodotti importato come varianti. - Fai clic su Importa.
curl
Se è la prima volta che carichi il catalogo o lo reimporti dopo averlo eliminato, imposta i livelli di prodotto utilizzando il metodo
Catalog.patch. Questa operazione richiede il ruolo di amministratore Retail.ingestionProductType: supporta i valoriprimary(predefinito) evariant.merchantCenterProductIdField: supporta i valoriofferIdeitemGroupId. Se non utilizzi Merchant Center, non devi impostare questo campo.
curl -X PATCH \ -H "Authorization: Bearer $(gcloud auth application-default print-access-token)" \ -H "Content-Type: application/json; charset=utf-8" \ --data '{ "productLevelConfig": { "ingestionProductType": "PRODUCT_TYPE", "merchantCenterProductIdField": "PRODUCT_ID_FIELD" } }' \ "https://retail.googleapis.com/v2/projects/PROJECT_ID/locations/global/catalogs/default_catalog"
Crea un file di dati per i parametri di input per l'importazione.
Utilizza l'oggetto BigQuerySource per indirizzare il tuo set di dati BigQuery.
- DATASET_ID: l'ID del set di dati BigQuery.
- TABLE_ID: l'ID della tabella BigQuery che contiene i tuoi dati.
- PROJECT_ID: l'ID progetto in cui si trova l'origine BigQuery. Se non specificato, l'ID progetto viene ereditato dalla richiesta principale.
- STAGING_DIRECTORY: (Facoltativo) Una directory Cloud Storage utilizzata come posizione temporanea per i dati prima che vengano importati in BigQuery. Lascia vuoto questo campo per creare automaticamente una directory temporanea (opzione consigliata).
- ERROR_DIRECTORY: (Facoltativo) Una directory Cloud Storage per le informazioni sugli errori relativi all'importazione. Lascia vuoto questo campo per creare automaticamente una directory temporanea (consigliato).
dataSchema: per la proprietàdataSchema, utilizza il valoreproduct(predefinito). Utilizzerai lo schema AI Commerce Search.
Ti consigliamo di non specificare directory di gestione temporanea o di errore, in modo che venga creato automaticamente un bucket Cloud Storage con nuove directory di gestione temporanea e di errore. Queste directory vengono create nella stessa regione del set di dati BigQuery e sono univoche per ogni importazione (il che impedisce a più job di importazione di eseguire lo staging dei dati nella stessa directory e potenzialmente di reimportare gli stessi dati). Dopo tre giorni, il bucket e le directory vengono eliminati automaticamente per ridurre i costi di archiviazione.
Un nome bucket creato automaticamente include l'ID progetto, la regione del bucket e il nome dello schema dei dati, separati da trattini bassi (ad esempio,
4321_us_catalog_retail). Le directory create automaticamente sono chiamatestagingoerrors, a cui viene aggiunto un numero (ad esempio,staging2345oerrors5678).Se specifichi le directory, il bucket Cloud Storage deve trovarsi nella stessa regione del set di dati BigQuery, altrimenti l'importazione non andrà a buon fine. Fornisci le directory di gestione temporanea e degli errori nel formato
gs://<bucket>/<folder>/; devono essere diverse.{ "inputConfig":{ "bigQuerySource": { "projectId":"PROJECT_ID", "datasetId":"DATASET_ID", "tableId":"TABLE_ID", "dataSchema":"product"} } }
Importa le informazioni del catalogo inviando una richiesta
POSTal metodo RESTProducts:import, fornendo il nome del file di dati (in questo caso, mostrato comeinput.json).curl -X POST \ -H "Authorization: Bearer $(gcloud auth application-default print-access-token)" \ -H "Content-Type: application/json; charset=utf-8" -d @./input.json \ "https://retail.googleapis.com/v2/projects/PROJECT_NUMBER/locations/global/catalogs/default_catalog/branches/0/products:import"
Puoi controllare lo stato in modo programmatico utilizzando l'API. Dovresti ricevere un oggetto di risposta simile al seguente:
{ "name": "projects/PROJECT_ID/locations/global/catalogs/default_catalog/operations/import-products-123456", "done": false }
Il campo nome è l'ID dell'oggetto operazione. Per richiedere lo stato di questo oggetto, sostituisci il campo del nome con il valore restituito dal metodo
import, finché il campodonenon restituiscetrue:curl -H "Authorization: Bearer $(gcloud auth application-default print-access-token)" \ "https://retail.googleapis.com/v2/projects/PROJECT_ID/locations/global/catalogs/default_catalog/operations/import-products-123456"
Al termine dell'operazione, l'oggetto restituito ha un valore
donepari atruee include un oggetto Stato simile al seguente esempio:{ "name": "projects/PROJECT_ID/locations/global/catalogs/default_catalog/operations/import-products-123456", "metadata": { "@type": "type.googleapis.com/google.cloud.retail.v2.ImportMetadata", "createTime": "2020-01-01T03:33:33.000001Z", "updateTime": "2020-01-01T03:34:33.000001Z", "successCount": "2", "failureCount": "1" }, "done": true, "response": { "@type": "type.googleapis.com/google.cloud.retail.v2.ImportProductsResponse", }, "errorsConfig": { "gcsPrefix": "gs://error-bucket/error-directory" } }
Puoi esaminare i file nella directory degli errori in Cloud Storage per verificare se si sono verificati errori durante l'importazione.
-
Vai alla pagina Dati nella console AI Commerce Search in Gemini Enterprise for Customer Experience.
Configurare l'accesso al set di dati BigQuery
Per configurare l'accesso quando il set di dati BigQuery si trova in un progetto diverso dal servizio AI Commerce Search, completa i seguenti passaggi.
Apri la pagina IAM nella console Google Cloud .
Seleziona il progetto AI Commerce Search.
Trova il account di servizio con il nome Retail Service Agent.
Se non hai mai avviato un'operazione di importazione, questo account di servizio potrebbe non essere elencato. Se non vedi questo account di servizio, torna all'attività di importazione e avvia l'importazione. Se l'operazione non va a buon fine a causa di errori di autorizzazione, torna qui e completa questa attività.
Copia l'identificatore del account di servizio, che ha l'aspetto di un indirizzo email (ad esempio,
service-525@gcp-sa-retail.iam.gserviceaccount.com).Passa al tuo progetto BigQuery (nella stessa pagina IAM e amministrazione) e fai clic su person_add Concedi l'accesso.
Per Nuove entità, inserisci l'identificatore dell'account di servizio AI Commerce Search e seleziona il ruolo BigQuery > Utente BigQuery.
Fai clic su Aggiungi un altro ruolo e seleziona BigQuery > Editor dati BigQuery.
Se non vuoi fornire il ruolo Editor dati all'intero progetto, puoi aggiungerlo direttamente al set di dati. Scopri di più.
Fai clic su Salva.
Schema del prodotto
Quando importi un catalogo da BigQuery, utilizza lo schema del prodotto AI Commerce Search riportato di seguito per creare una tabella BigQuery con il formato corretto e caricarla con i dati del catalogo. Poi, importa il catalogo.
Importa i dati di catalogo da Cloud Storage
Per importare i dati del catalogo in formato JSON, crea uno o più file JSON che contengono i dati del catalogo da importare e caricali in Cloud Storage. Da qui, puoi importarlo in AI Commerce Search.
Per un esempio di formato dell'articolo di prodotto JSON, consulta Formato dei dati JSON dell'articolo di prodotto.
Per assistenza con il caricamento di file in Cloud Storage, consulta Caricare oggetti.
Assicurati che il account di servizio di AI Commerce Search disponga dell'autorizzazione di lettura e scrittura per il bucket.
Il account di servizio AI Commerce Search è elencato nella pagina IAM della console Google Cloud con il nome Agente di servizio Retail. Utilizza l'identificatore delaccount di serviziot, che ha l'aspetto di un indirizzo email (ad esempio,
service-525@gcp-sa-retail.iam.gserviceaccount.com), quando aggiungi l'account alle autorizzazioni del bucket.Importa i dati del catalogo.
console Cloud
-
Vai alla pagina Dati nella console AI Commerce Search in Gemini Enterprise for Customer Experience.
Vai alla pagina Dati - Fai clic su Importa per aprire il riquadro Importa dati.
- Scegli Catalogo prodotti come origine dati.
- Seleziona il ramo in cui caricherai il catalogo.
- Scegli Schema cataloghi dei prodotti di Retail come schema.
- Inserisci la posizione Cloud Storage dei tuoi dati.
- Se la ricerca non è attivata, seleziona i livelli di prodotto.
Devi selezionare i livelli di prodotto se è la prima volta che importi il catalogo o se lo importi di nuovo dopo averlo eliminato. Scopri di più sui livelli dei prodotti. Modificare i livelli di prodotto dopo aver importato i dati richiede uno sforzo significativo.
Importante:non puoi attivare la ricerca per i progetti con un catalogo di prodotti importato come varianti. - Fai clic su Importa.
curl
Se è la prima volta che carichi il catalogo o lo reimporti dopo averlo eliminato, imposta i livelli di prodotto utilizzando il metodo
Catalog.patch. Scopri di più sui livelli dei prodotti.ingestionProductType: supporta i valoriprimary(predefinito) evariant.merchantCenterProductIdField: supporta i valoriofferIdeitemGroupId. Se non utilizzi Merchant Center, non devi impostare questo campo.
curl -X PATCH \ -H "Authorization: Bearer $(gcloud auth application-default print-access-token)" \ -H "Content-Type: application/json; charset=utf-8" \ --data '{ "productLevelConfig": { "ingestionProductType": "PRODUCT_TYPE", "merchantCenterProductIdField": "PRODUCT_ID_FIELD" } }' \ "https://retail.googleapis.com/v2/projects/PROJECT_ID/locations/global/catalogs/default_catalog"
Crea un file di dati per i parametri di input per l'importazione. Utilizza l'oggetto
GcsSourceper puntare al tuo bucket Cloud Storage.Puoi fornire più file o solo uno; questo esempio utilizza due file.
- INPUT_FILE: uno o più file in Cloud Storage contenenti i dati del catalogo.
- ERROR_DIRECTORY: una directory Cloud Storage per le informazioni sugli errori relativi all'importazione.
I campi del file di input devono essere nel formato
gs://<bucket>/<path-to-file>/. La directory degli errori deve essere nel formatogs://<bucket>/<folder>/. Se la directory degli errori non esiste, viene creata. Il bucket deve esistere già.{ "inputConfig":{ "gcsSource": { "inputUris": ["INPUT_FILE_1", "INPUT_FILE_2"] } }, "errorsConfig":{"gcsPrefix":"ERROR_DIRECTORY"} }
Importa le informazioni del catalogo inviando una richiesta
POSTal metodo RESTProducts:import, fornendo il nome del file di dati (in questo caso, mostrato comeinput.json).curl -X POST \ -H "Authorization: Bearer $(gcloud auth application-default print-access-token)" \ -H "Content-Type: application/json; charset=utf-8" -d @./input.json \ "https://retail.googleapis.com/v2/projects/PROJECT_NUMBER/locations/global/catalogs/default_catalog/branches/0/products:import"
Il modo più semplice per controllare lo stato dell'operazione di importazione è utilizzare la console Google Cloud . Per saperne di più, consulta Visualizzare lo stato di un'operazione di integrazione specifica.
Puoi anche controllare lo stato in modo programmatico utilizzando l'API. Dovresti ricevere un oggetto di risposta simile al seguente:
{ "name": "projects/PROJECT_ID/locations/global/catalogs/default_catalog/operations/import-products-123456", "done": false }
Il campo nome è l'ID dell'oggetto operazione. Richiedi lo stato di questo oggetto, sostituendo il campo del nome con il valore restituito dal metodo di importazione, finché il campo
donenon restituisce il valoretrue:curl -H "Authorization: Bearer $(gcloud auth application-default print-access-token)" \ "https://retail.googleapis.com/v2/projects/PROJECT_ID/locations/global/catalogs/default_catalog/operations/[OPERATION_NAME]"
Al termine dell'operazione, l'oggetto restituito ha un valore
doneditruee include un oggetto Stato simile al seguente esempio:{ "name": "projects/PROJECT_ID/locations/global/catalogs/default_catalog/operations/import-products-123456", "metadata": { "@type": "type.googleapis.com/google.cloud.retail.v2.ImportMetadata", "createTime": "2020-01-01T03:33:33.000001Z", "updateTime": "2020-01-01T03:34:33.000001Z", "successCount": "2", "failureCount": "1" }, "done": true, "response": { "@type": "type.googleapis.com/google.cloud.retail.v2.ImportProductsResponse" }, "errorsConfig": { "gcsPrefix": "gs://error-bucket/error-directory" } }
Puoi ispezionare i file nella directory degli errori in Cloud Storage per vedere il tipo di errori che si sono verificati durante l'importazione.
-
Vai alla pagina Dati nella console AI Commerce Search in Gemini Enterprise for Customer Experience.
Importa i dati del catalogo in linea
curl
Importi le informazioni del catalogo inline effettuando una richiesta POST al metodo REST Products:import, utilizzando l'oggetto productInlineSource per specificare i dati del catalogo.
Fornisci un intero prodotto su una singola riga. Ogni prodotto deve essere su una riga separata.
Per un esempio di formato dell'articolo di prodotto JSON, consulta Formato dei dati JSON dell'articolo di prodotto.
Crea il file JSON per il tuo prodotto e chiamalo
./data.json:{ "inputConfig": { "productInlineSource": { "products": [ { PRODUCT_1 } { PRODUCT_2 } ] } } }Chiama il metodo POST:
curl -X POST \ -H "Authorization: Bearer $(gcloud auth application-default print-access-token)" \ -H "Content-Type: application/json; charset=utf-8" \ --data @./data.json \ "https://retail.googleapis.com/v2/projects/PROJECT_NUMBER/locations/global/catalogs/default_catalog/branches/0/products:import"
Java
Formato dei dati JSON degli articoli di prodotto
Le voci Product nel file JSON devono essere simili agli esempi riportati di seguito.
Fornisci un intero prodotto su una singola riga. Ogni prodotto deve essere su una riga separata.
Campi minimi obbligatori:
{
"id": "1234",
"categories": "Apparel & Accessories > Shoes",
"title": "ABC sneakers"
}
{
"id": "5839",
"categories": "casual attire > t-shirts",
"title": "Crew t-shirt"
}
Visualizza oggetto completo
{ "name": "projects/PROJECT_NUMBER/locations/global/catalogs/default_catalog/branches/0/products/1234", "id": "1234", "categories": "Apparel & Accessories > Shoes", "title": "ABC sneakers", "description": "Sneakers for the rest of us", "attributes": { "vendor": {"text": ["vendor123", "vendor456"]} }, "language_code": "en", "tags": [ "black-friday" ], "priceInfo": { "currencyCode": "USD", "price":100, "originalPrice":200, "cost": 50 }, "availableTime": "2020-01-01T03:33:33.000001Z", "availableQuantity": "1", "uri":"http://example.com", "images": [ {"uri": "http://example.com/img1", "height": 320, "width": 320 } ] } { "name": "projects/PROJECT_NUMBER/locations/global/catalogs/default_catalog/branches/0/products/4567", "id": "4567", "categories": "casual attire > t-shirts", "title": "Crew t-shirt", "description": "A casual shirt for a casual day", "attributes": { "vendor": {"text": ["vendor789", "vendor321"]} }, "language_code": "en", "tags": [ "black-friday" ], "priceInfo": { "currencyCode": "USD", "price":50, "originalPrice":60, "cost": 40 }, "availableTime": "2020-02-01T04:44:44.000001Z", "availableQuantity": "2", "uri":"http://example.com", "images": [ {"uri": "http://example.com/img2", "height": 320, "width": 320 } ] }
Dati storici del catalogo
AI Commerce Search supporta l'importazione e la gestione dei dati storici del catalogo. I dati storici del catalogo possono essere utili quando utilizzi gli eventi utente storici per l'addestramento del modello. Le informazioni sui prodotti passati possono essere utilizzate per arricchire i dati storici sugli eventi utente e migliorare l'accuratezza del modello.
I prodotti storici vengono archiviati come prodotti scaduti. Non vengono restituiti nelle risposte di ricerca, ma sono visibili alle chiamate API Update, List e Delete.
Importare i dati storici del catalogo
Quando il campo expireTime di un prodotto è impostato su un timestamp passato, questo prodotto viene considerato storico. Imposta la
disponibilità del prodotto
su OUT_OF_STOCK per evitare di influire
sui consigli.
Ti consigliamo di utilizzare i seguenti metodi per importare i dati storici del catalogo:
- Chiamata del metodo
Product.Create. - Importazione in linea di prodotti scaduti.
- Importazione di prodotti scaduti da BigQuery.
Chiama il metodo Product.Create
Utilizza il metodo Product.Create per creare una voce Product
con il campo expireTime impostato su un timestamp precedente.
Importare in linea i prodotti scaduti
I passaggi sono identici all'importazione in linea, tranne per il fatto che i prodotti
devono avere i campi expireTime impostati su un timestamp
passato.
Fornisci un intero prodotto su una singola riga. Ogni prodotto deve essere su una riga separata.
Un esempio di ./data.json utilizzato nella richiesta di importazione in linea:
Visualizza questo esempio utilizzato nella richiesta di importazione in linea
{
"inputConfig": {
"productInlineSource": {
"products": [
{
"id": "historical_product_001",
"categories": "Apparel & Accessories > Shoes",
"title": "ABC sneakers",
"expire_time": {
"second": "2021-10-02T15:01:23Z" // a past timestamp
}
},
{
"id": "historical product 002",
"categories": "casual attire > t-shirts",
"title": "Crew t-shirt",
"expire_time": {
"second": "2021-10-02T15:01:24Z" // a past timestamp
}
}
]
}
}
}
Importare prodotti scaduti da BigQuery o Cloud Storage
Utilizza le stesse procedure documentate per
importare i dati di catalogo da BigQuery o
importare i dati di catalogo da Cloud Storage. Tuttavia, assicurati di impostare
il campo expireTime su un timestamp passato.
Mantieni il catalogo aggiornato
Per ottenere risultati ottimali, il catalogo deve contenere informazioni aggiornate. Ti consigliamo di importare il catalogo quotidianamente per assicurarti che sia aggiornato. Puoi utilizzare Google Cloud Scheduler per pianificare le importazioni oppure scegliere un'opzione di pianificazione automatica quando importi i dati utilizzando la consoleGoogle Cloud .
Puoi aggiornare solo gli articoli di prodotto nuovi o modificati oppure importare l'intero catalogo. Se importi prodotti già presenti nel catalogo, questi non vengono aggiunti di nuovo. Qualsiasi elemento modificato viene aggiornato.
Per aggiornare un singolo elemento, vedi Aggiornare le informazioni sul prodotto.
Aggiornamento batch
Puoi utilizzare il metodo di importazione per l'aggiornamento batch del catalogo. Per farlo, segui la stessa procedura dell'importazione iniziale, descritta in Importare i dati del catalogo.
Monitorare l'integrità dell'importazione
Per monitorare l'importazione e l'integrità del catalogo:
Visualizza informazioni aggregate sul tuo catalogo e visualizza l'anteprima dei prodotti caricati nella scheda Catalogo di AI Commerce Search in Gemini Enterprise for Customer Experience nella pagina Dati.
Valuta se devi aggiornare i dati del catalogo per migliorare la qualità dei risultati di ricerca e sbloccare i livelli di rendimento della ricerca nella pagina Qualità dei dati.
Per saperne di più su come controllare la qualità dei dati di ricerca e visualizzare i livelli di rendimento della ricerca, consulta Sbloccare i livelli di rendimento della ricerca. Per un riepilogo delle metriche del catalogo disponibili in questa pagina, consulta Metriche di qualità del catalogo.
Per creare avvisi che ti informino se si verifica un problema con i caricamenti dei dati, segui le procedure descritte in Configurare gli avvisi di Cloud Monitoring.
Mantenere aggiornato il catalogo è importante per ottenere risultati di alta qualità. Utilizza gli avvisi per monitorare i tassi di errore di importazione e intraprendere azioni se necessario.
Passaggi successivi
- Inizia a registrare gli eventi utente.
- Visualizzare informazioni aggregate sul tuo catalogo.
- Configura gli avvisi di caricamento dei dati.