
Le registre de schémas fournit des dépôts de schémas partagés par plusieurs applications. Auparavant, sans registre de schémas, les équipes pouvaient dépendre d'accords informels (comme des accords verbaux, des documents partagés non appliqués de manière programmatique ou des pages wiki) pour définir le format des messages et la manière de les sérialiser et de les désérialiser. Le registre de schémas garantit un encodage et un décodage cohérents des messages.
Ce document présente la fonctionnalité de registre de schémas pour Managed Service pour Apache Kafka, ses composants et le workflow de base.
Comprendre les schémas
Imaginez que vous développiez une application qui suit les commandes des clients. Vous pouvez utiliser un sujet Kafka appelé customer_orders pour transmettre des messages contenant des informations sur chaque commande. Un message de commande type peut inclure les champs d'informations suivants :
ID de commande
Nom du client
Nom du produit
Quantité
Prix
Pour vous assurer que ces messages sont structurés de manière cohérente, vous pouvez définir un schéma. Voici un exemple au format Apache Avro :
{
"type": "record",
"name": "Order",
"namespace": "com.example",
"fields": [
{"name": "orderId", "type": "string"},
{"name": "customerName", "type": "string"},
{"name": "productName", "type": "string"},
{"name": "quantity", "type": "int"},
{"name": "price", "type": "double"}
]
}
Voici le même exemple au format Protocol Buffer.
syntax = "proto3";
package com.example;
option java_multiple_files = true; // Optional: Recommended for Java users
option java_package = "com.example"; // Optional: Explicit Java package
message Order {
string orderId = 1;
string customerName = 2;
string productName = 3;
int32 quantity = 4; // Avro int maps to Protobuf int32
double price = 5;
}
Ce schéma est un plan pour un message. Il vous indique qu'un message order comporte cinq champs : un numéro de commande, un nom de client, un nom de produit, une quantité et un prix. Il spécifie également le type de données de chaque champ.
Si un client consommateur reçoit un message binaire encodé avec ce schéma, il doit savoir exactement comment l'interpréter. Pour ce faire, le producteur stocke le schéma order dans un registre de schémas et transmet un identifiant du schéma avec le message. Tant qu'un consommateur du message sait quel registre a été utilisé, il peut récupérer le même schéma et décoder le message.
Supposons que vous souhaitiez ajouter un champ, orderDate, à vos messages order. Vous devez créer une version du schéma order et l'enregistrer sous le même sujet. Cela vous permet de suivre l'évolution de votre schéma au fil du temps.
L'ajout d'un champ est une modification compatible avec les versions ultérieures. Cela signifie que les consommateurs qui utilisent des versions de schéma plus anciennes (sans orderDate) peuvent toujours lire et traiter les messages produits avec le nouveau schéma. Le nouveau champ est ignoré.
La rétrocompatibilité du registre de schéma signifie qu'une application consommateur configurée avec une nouvelle version de schéma peut lire les données produites avec un schéma précédent.
Dans cet exemple, le schéma order initial correspond à la version 1. Lorsque vous ajoutez le champ orderDate, vous créez la version 2 du schéma order. Les deux versions sont stockées sous le même sujet, ce qui vous permet de gérer les mises à jour de schéma sans interrompre les applications existantes qui peuvent encore s'appuyer sur la version 1.
Voici une vue de haut en bas d'un exemple de registre de schémas appelé schema_registry_test, organisé par contexte, sujet et version du schéma :
customer_supportcontextorderobjetVersion
V1(inclut orderId, customerName, productName, quantity, price)Version
V2(ajoute orderDate à la version V1)
Qu'est-ce qu'un schéma ?
Les messages Apache Kafka se composent de chaînes d'octets. Sans structure définie, les applications consommatrices doivent se coordonner directement avec les applications productrices pour comprendre comment interpréter ces octets.
Un schéma fournit une description formelle des données contenues dans un message. Il définit les champs et leurs types de données (chaîne, entier ou booléen, par exemple), ainsi que toutes les structures imbriquées.
Managed Service pour Apache Kafka est compatible avec les schémas aux formats suivants :
Protocol Buffers (Protobuf)
L'API du registre de schémas n'est pas compatible avec JSON.
La fonctionnalité de registre de schémas intégrée à Managed Service pour Apache Kafka vous permet de créer, de gérer et d'utiliser ces schémas avec vos clients Kafka. Le registre de schémas implémente l'API REST Confluent Schema Registry, qui est compatible avec les applications Apache Kafka existantes et les bibliothèques clientes courantes.
Organisation du registre de schémas
Le registre de schémas utilise une structure hiérarchique pour organiser les schémas.
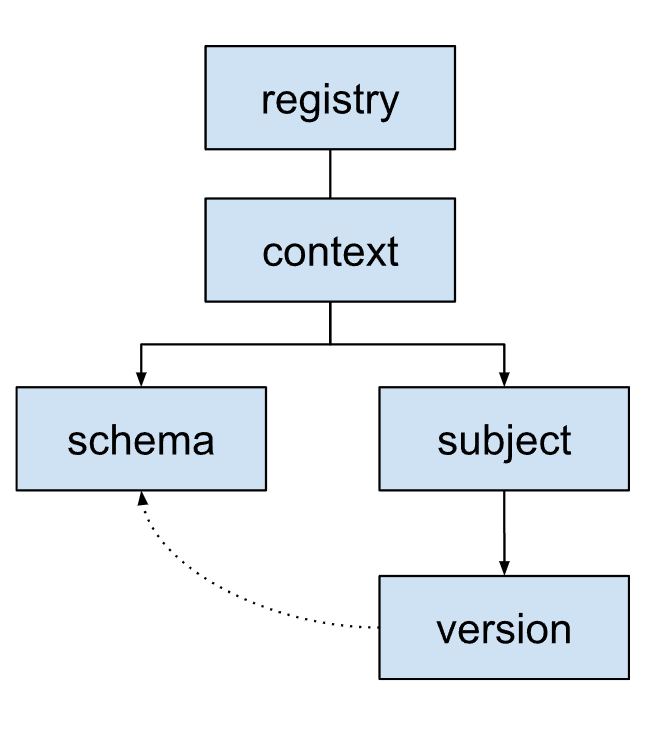
Schéma : structure et types de données d'un message. Chaque schéma est identifié par un ID de schéma. Cet ID est utilisé par les applications pour récupérer le schéma.
Sujet : conteneur logique pour différentes versions d'un schéma. Les sujets gèrent l'évolution des schémas au fil du temps à l'aide de règles de compatibilité. Chaque sujet correspond généralement à un sujet ou à un objet d'enregistrement Kafka.
Version : lorsque la logique métier nécessite des modifications de la structure d'un message, créez et enregistrez une nouvelle version du schéma sous le sujet concerné.
Chaque version fait référence à un schéma spécifique. Les versions de différents sujets peuvent faire référence au même schéma si le schéma sous-jacent est le même.
Contexte : regroupement ou espace de noms de haut niveau pour les sujets. Les contextes permettent à différentes équipes ou applications d'utiliser le même nom de sujet sans conflit au sein du même registre de schéma.
Un registre de schémas peut comporter plusieurs contextes. Il contient toujours un contexte par défaut identifié comme
., qui est l'endroit où les schémas et les sujets sont placés lorsqu'aucun autre identifiant de contexte n'est spécifié.Un contexte peut contenir plusieurs sujets.
Registre : conteneur de premier niveau pour l'ensemble de l'écosystème de schémas. Il stocke et gère tous les schémas, sujets, versions et contextes.
Workflow du registre de schémas
Pour suivre le workflow décrit dans cette section, vous pouvez essayer le guide de démarrage rapide Produire des messages Avro avec le registre de schémas.
Les sérialiseurs et désérialiseurs de vos clients Kafka interagissent avec le registre de schéma pour s'assurer que les messages sont conformes à un schéma défini. Voici un workflow type pour un registre de schémas dans Managed Service pour Apache Kafka :
Initialisez votre application de production avec un schéma spécifique indiqué comme classe générée par Avro, et configurez-la pour qu'elle utilise une bibliothèque de sérialisation et un registre de schéma particuliers.
Configurez un client consommateur pour qu'il utilise une bibliothèque de désérialisation correspondante et le même registre de schémas.
Lors de l'exécution, le client transmet l'objet de message à la méthode
producer.send, et la bibliothèque cliente Kafka utilise le sérialiseur configuré pour convertir cet enregistrement en octets encodés au format Avro.Le sérialiseur détermine un nom de sujet pour le schéma en fonction d'une stratégie de nom de sujet configurée dans la bibliothèque cliente. Il utilise ensuite ce nom de sujet dans une requête envoyée au registre de schémas pour récupérer l'ID du schéma. Pour en savoir plus, consultez Stratégies de dénomination des sujets.
Si le schéma n'existe pas dans le registre sous ce nom de sujet, le client peut être configuré pour enregistrer le schéma, auquel cas il reçoit l'ID nouvellement attribué.
Évitez cette configuration dans les environnements de production.
Le producteur envoie le message sérialisé avec l'ID de schéma au sujet approprié d'un courtier Kafka.
Le broker Kafka stocke la représentation du tableau d'octets de votre message dans un sujet.
L'application consommateur reçoit le message.
Le désérialiseur récupère le schéma avec cet ID à partir du registre de schéma.
Le désérialiseur analyse le message pour l'application consommateur.
Limites
Le registre de schémas ne prend pas en charge les fonctionnalités suivantes :
Formats de schéma :
- Format de schéma JSON.
Modes de schéma :
- Mode schéma
READONLY_OVERRIDE.
- Mode schéma
Valeurs de configuration du schéma :
- Valeurs de configuration
NormalizeetAlias.
- Valeurs de configuration
Méthodes d'API :
- La méthode
ModifySchemaTags(/subjects/{subject}/versions/{version}/tags). - La méthode
GetLatestWithMetadata(/subjects/{subject}/metadata). - La méthode
ListSchemas(/schemas). - La méthode
DeleteSchemaMode. - Pour la méthode
GetVersion: les paramètresformat,deletedetfindTags. - Pour la méthode
CreateVersion: les paramètresmetadata,ruleSet,schemaTagsToAddetschemaTagsToRemove. - Pour la méthode
UpdateSchemaMode: le paramètreforce. - Pour la méthode
GetSchemaMode: le paramètredefaultToGlobal. - Pour la méthode
GetSchema: les paramètresWorkspaceMaxIdetfindTags. - Pour la méthode
ListVersions: le paramètredeletedOnly. - Pour la méthode
ListSubjects: le paramètredeletedOnly.
- La méthode