
Lo strumento di monitoraggio delle query di esplorazione e il riquadro Prestazioni di Esplora forniscono dati sul rendimento passo passo per una query di esplorazione. Questi dati possono aiutarti a identificare i punti di ingresso chiave per la risoluzione dei problemi e a risolvere i problemi di rendimento delle query, oltre a fornire consigli per i miglioramenti.
Esplora il tracker delle query
Il tracker delle query di Esplora mostra l'avanzamento di una query di Esplora nelle tre fasi della query durante l'esecuzione.
![]()
Se l'esecuzione di una query richiede molto tempo, il monitoraggio delle query può indicare quale fase della query causa il problema di prestazioni. Ciò è utile per identificare dove potrebbero verificarsi problemi di prestazioni e dove gli sforzi di ottimizzazione possono essere più efficaci.
Il monitoraggio delle query viene visualizzato quando è in esecuzione un'esplorazione, a condizione che sia aperto il riquadro Visualizzazione esplorazione o il riquadro Dati dell'esplorazione.
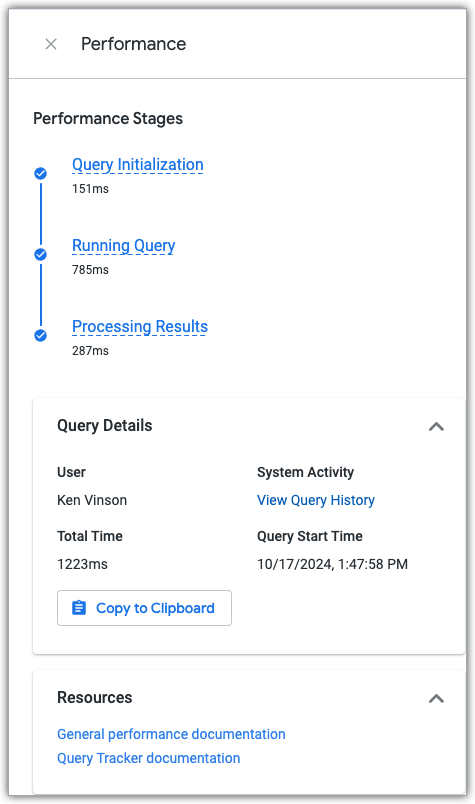
Esplorare il riquadro Rendimento
Per visualizzare il riquadro Rendimento di Esplora, fai clic sul link Visualizza dettagli sul rendimento, disponibile in qualsiasi query di Esplora eseguita.

Il riquadro Rendimento mostra il tempo trascorso dalla query in ciascuna delle tre fasi della query e include link alla documentazione sul rendimento e alla dashboard Attività di sistema Cronologia query, che mostra i dati sul rendimento attuali e storici per la query e l'esplorazione utilizzata per creare la query.
Fasi della query
Quando un'esplorazione di Looker esegue una query del database, la query viene eseguita in tre fasi:
- La fase di inizializzazione della query
- La fase di esecuzione della query
- La fase dei risultati di elaborazione
Fase di inizializzazione della query
Durante la fase di inizializzazione della query, Looker esegue tutte le attività necessarie prima che la query venga inviata al tuo database. La fase di inizializzazione della query include le seguenti attività:
- Compilazione del modello LookML
- Verifica in corso per stabilire se è necessario creare tabelle derivate permanenti (PDT)
- Generazione dell'SQL della query
- Acquisizione della connessione al database
La pagina della documentazione Informazioni sulle metriche sul rendimento delle query descrive come utilizzare l'esplorazione Metriche sul rendimento delle query in Attività di sistema per visualizzare le suddivisioni dettagliate di una query. La fase di inizializzazione della query del monitoraggio delle query include gli eventi descritti nelle fasi Worker asincrono, Inizializzazione e Gestione connessione dell'esplorazione Metriche sul rendimento delle query.
Fase di esecuzione della query
Nella fase Esecuzione della query, Looker contatta il tuo database, esegue la query e ne restituisce i risultati. I problemi di prestazioni durante questa fase potrebbero indicare un problema con il database esterno, ad esempio PDT che richiedono molto tempo per essere ricreate e potrebbero dover essere ottimizzate, oppure tabelle di database esterni che potrebbero dover essere ottimizzate. La fase Esecuzione query include le seguenti attività:
- Creazione di eventuali PDT nel database necessarie per la query di Esplora
- Esecuzione della query richiesta sul database
La pagina della documentazione Informazioni sulle metriche di rendimento delle query descrive come utilizzare l'esplorazione Metriche di rendimento delle query in Attività di sistema per visualizzare suddivisioni dettagliate di una query. La fase Query in esecuzione del monitoraggio delle query include gli eventi descritti nella fase Query principali dell'esplorazione Metriche sul rendimento delle query.
I possibili passaggi da intraprendere se riscontri problemi di prestazioni durante questa fase includono:
- Crea esplorazioni utilizzando unioni
many_to_one, se possibile. L'unione di viste dal livello più granulare al livello di dettaglio più elevato (many_to_one) in genere offre le migliori prestazioni delle query. - Massimizza la memorizzazione nella cache per la sincronizzazione con le tue norme ETL, ove possibile, per ridurre il traffico delle query del database. Per impostazione predefinita, Looker memorizza nella cache le query per un'ora. Puoi controllare il criterio di memorizzazione nella cache e sincronizzare gli aggiornamenti dei dati di Looker con il processo ETL applicando i gruppi di dati
all'interno degli Explore utilizzando il parametro
persist_with. La massimizzazione della memorizzazione nella cache consente a Looker di integrarsi più strettamente con la pipeline di dati di backend, in modo che l'utilizzo della cache possa essere massimizzato senza il rischio di analizzare dati obsoleti. I criteri di memorizzazione nella cache denominati possono essere applicati a un intero modello o a singole esplorazioni e tabelle derivate persistenti (PDT). - Utilizza la funzionalità consapevolezza aggregata di Looker per creare tabelle di riepilogo o roll-up che Looker può utilizzare per le query, se possibile, soprattutto per le query comuni di database di grandi dimensioni. Puoi anche utilizzare il riconoscimento degli aggregati per migliorare drasticamente il rendimento di intere dashboard. Per ulteriori informazioni, consulta il tutorial sulla consapevolezza aggregata.
- Utilizza le Tabelle derivate persistenti (PDT) per query più rapide. Converti le esplorazioni con molti join complessi o non performanti oppure dimensioni con sottoquery o sottoselezioni in PDT in modo che le viste vengano unite in precedenza e siano pronte prima del runtime.
- Se il tuo dialetto del database supporta le PDT incrementali, configura le PDT incrementali per ridurre il tempo che Looker impiega per ricostruire le tabelle PDT.
- Evita di unire le visualizzazioni in Esplora in base a chiavi primarie concatenate definite in Looker. Esegui invece il join sui campi di base che compongono la chiave primaria concatenata della vista. In alternativa, ricrea la vista come PDT con la chiave primaria concatenata predefinita nella definizione SQL della tabella, anziché nel LookML di una vista.
- Utilizza lo strumento Spiega in SQL Runner per il benchmarking.
EXPLAINproduce una panoramica del piano di esecuzione delle query del tuo database per una determinata query SQL, consentendoti di rilevare i componenti della query che possono essere ottimizzati. Scopri di più nel post della community Come ottimizzare SQL conEXPLAIN. - Dichiara gli indici. Puoi esaminare gli indici di ogni tabella direttamente in Looker da SQL Runner facendo clic sull'icona a forma di ingranaggio in una tabella e poi selezionando Mostra indici.
Le colonne più comuni che possono trarre vantaggio dagli indici sono date importanti e chiavi esterne. L'aggiunta di indici a queste colonne aumenterà il rendimento di quasi tutte le query. Questo vale anche per le notifiche PDT. I parametri LookML, come
indexes,sort keysedistribution, possono essere applicati in modo appropriato.
Fase di elaborazione dei risultati
Durante la fase di elaborazione dei risultati, Looker elabora i risultati della query e ne esegue il rendering. La fase Risultati dell'elaborazione include le seguenti attività:
- Streaming dei risultati delle query nella cache
- Risoluzione dei calcoli tabulari
- Formattazione dei risultati del linguaggio di modelli Liquid
- Unire le query
- Calcolo di totali e subtotali
La pagina di documentazione Comprendere le metriche di rendimento delle query descrive come utilizzare l'esplorazione Metriche di rendimento delle query in Attività di sistema per visualizzare le suddivisioni dettagliate di una query. La fase Elaborazione risultati del monitoraggio delle query include gli eventi descritti nella fase post-query dell'esplorazione Metriche di rendimento delle query.
I possibili passaggi da intraprendere se riscontri problemi di prestazioni durante questa fase includono:
- Utilizza con parsimonia funzionalità come unione dei risultati, campi personalizzati e calcoli tabulari. Queste funzionalità sono pensate per essere utilizzate come prove concettuali per aiutarti a progettare il tuo modello. La best practice prevede di codificare in modo permanente tutti i calcoli e le funzioni utilizzati di frequente in LookML, che genererà SQL da elaborare nel database. I calcoli eccessivi possono competere per la memoria Java nell'istanza Looker, causando una risposta più lenta dell'istanza.
- Limita il numero di visualizzazioni che includi in un modello quando è presente un numero elevato di file di visualizzazione. L'inclusione di tutte le visualizzazioni in un unico modello può rallentare le prestazioni. Quando in un progetto è presente un numero elevato di visualizzazioni, valuta la possibilità di includere solo i file di visualizzazione necessari in ogni modello. Valuta la possibilità di utilizzare convenzioni di denominazione strategiche per i nomi dei file di vista per consentire l'inclusione di gruppi di viste all'interno di un modello. Un esempio è descritto nella documentazione del parametro
includes. - Evita di restituire un numero elevato di punti dati per impostazione predefinita nei riquadri delle dashboard e nelle esplorazioni. Le query che restituiscono migliaia di punti dati consumano più memoria. Assicurati che i dati siano limitati ove possibile applicando
filtri frontend a dashboard, esplorazioni e Look e a livello LookML con i parametri
required filters,conditionally_filteresql_always_where. - Scarica o distribuisci le query utilizzando l'opzione Tutti i risultati con parsimonia, poiché alcune query possono essere molto grandi e sovraccaricare il server Looker durante l'elaborazione.