
Le suivi des requêtes d'exploration et le panneau Performances de l'exploration fournissent des données de performances détaillées pour une requête d'exploration. Ces données peuvent vous aider à identifier les points d'entrée clés pour résoudre les problèmes de performances liés aux requêtes et fournir des recommandations d'amélioration.
Suivi des requêtes d'exploration
Le suivi des requêtes d'exploration affiche la progression d'une requête d'exploration au cours des trois phases de la requête pendant son exécution.
![]()
Si une requête met beaucoup de temps à s'exécuter, le suivi des requêtes peut indiquer quelle phase de la requête est à l'origine du problème de performances. Cela permet d'identifier les points où des problèmes de performances peuvent survenir et où les efforts d'optimisation peuvent être les plus efficaces.
Le suivi des requêtes s'affiche lorsqu'une exploration est en cours d'exécution, à condition que le panneau Explore Visualisation ou le panneau Explore Données soit ouvert.
Panneau Performances de l'exploration
Pour afficher le panneau Performances de l'exploration, cliquez sur le lien Afficher les détails des performances, disponible sur toute requête d'exploration qui a été exécutée.

Le panneau Performances indique le temps passé par la requête dans chacune des trois phases de la requête et inclut des liens vers la documentation sur les performances et le tableau de bord Historique des requêtes de l'activité du système, qui affiche les données de performances actuelles et historiques pour la requête et l'exploration qui a été utilisée pour créer la requête.
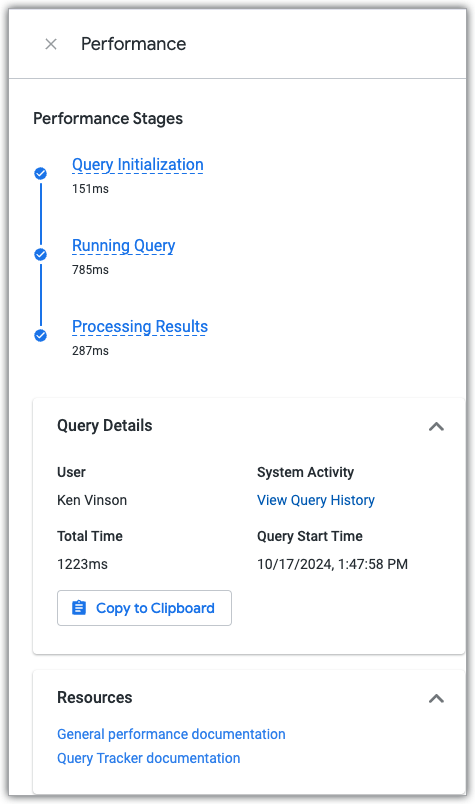
Phases de la requête
- La phase d'initialisation de la requête
- La phase d'exécution de la requête
- La phase de traitement des résultats
Phase d'initialisation de la requête
Pendant la phase d'initialisation de la requête, Looker effectue toutes les tâches requises avant l'envoi de la requête à votre base de données. La phase d'initialisation de la requête comprend les tâches suivantes :
- Compilation du modèle LookML
- Vérification de la nécessité de créer des tables dérivées persistantes (PDT)
- Génération du code SQL de la requête
- Acquisition de la connexion à la base de données
La page de documentation Comprendre les métriques de performances des requêtes explique comment utiliser l'exploration Métriques de performances des requêtes dans l'activité du système pour afficher des analyses détaillées d'une requête. La phase d'initialisation de la requête du suivi des requêtes inclut les événements décrits dans les phases Worker asynchrone, Initialisation et Gestion des connexions de l'exploration Métriques de performances des requêtes.
Phase d'exécution de la requête
La phase d'exécution de la requête correspond au moment où Looker contacte et interroge votre base de données, puis renvoie les résultats de la requête. Les problèmes de performances au cours de cette phase peuvent indiquer un problème avec la base de données externe, par exemple des PDT qui mettent beaucoup de temps à se reconstruire et qui peuvent nécessiter une optimisation, ou des tables de base de données externes qui peuvent nécessiter une optimisation. La phase d'exécution de la requête comprend les tâches suivantes :
- Création de toutes les PDT de la base de données requises pour la requête d'exploration
- Exécution de la requête demandée sur la base de données
La page de documentation Comprendre les métriques de performances des requêtes explique comment utiliser l'exploration Métriques de performances des requêtes dans l'activité du système pour afficher des analyses détaillées d'une requête. La phase d'exécution de la requête du suivi des requêtes inclut les événements décrits dans la phase Requêtes principales de l'exploration Métriques de performances des requêtes.
Voici quelques mesures à prendre si vous rencontrez des problèmes de performances au cours de cette phase :
- Créez des explorations à l'aide de
many_to_onejointures chaque fois que cela est possible. Joindre des vues du niveau le plus précis au niveau de détail le plus élevé (many_to_one) offre généralement les meilleures performances de requête. - Maximisez la mise en cache pour vous synchroniser avec vos règles ETL dans la mesure du possible afin de réduire le trafic des requêtes de base de données. Par défaut, Looker met en cache les requêtes pendant une heure. Vous pouvez contrôler la règle de mise en cache et synchroniser les actualisations des données Looker avec votre processus ETL en appliquant des groupes de données
dans les explorations à l'aide du paramètre
persist_with. La maximisation de la mise en cache permet à Looker de s'intégrer plus étroitement au pipeline de données backend afin que l'utilisation du cache puisse être maximisée, sans risque d'analyser des données obsolètes. Des règles de mise en cache nommées peuvent être appliquées à un modèle entier ou à des explorations individuelles et à des tables dérivées persistantes (PDT). - Utilisez la fonctionnalité de reconnaissance d'agrégats de Looker pour créer des tables de cumul ou de synthèse que Looker peut utiliser pour les requêtes chaque fois que cela est possible, en particulier pour les requêtes courantes de grandes bases de données. Vous pouvez également utiliser la reconnaissance d'agrégats pour améliorer considérablement les performances de l'ensemble des tableaux de bord. Pour en savoir plus, consultez le tutoriel Reconnaissance d'agrégats.
- Utilisez des PDT pour des requêtes plus rapides. Convertissez les explorations comportant de nombreuses jointures complexes ou peu performantes, ou des dimensions avec des sous-requêtes ou des sous-sélections, en PDT afin que les vues soient pré-jointes et prêtes avant l'exécution.
- Si votre dialecte de base de données prend en charge les PDT incrémentales, configurez les PDT incrémentales pour réduire le temps que Looker consacre à la reconstruction des tables PDT.
- Évitez de joindre des vues dans des explorations sur des clés primaires concaténées définies dans Looker. Au lieu de cela, joignez les champs de base qui composent la clé primaire concaténée à partir de la vue. Vous pouvez également recréer la vue en tant que PDT avec la clé primaire concaténée prédéfinie dans la définition SQL de la table, plutôt que dans le code LookML d'une vue.
- Utilisez l'outil Expliquer dans l'exécuteur SQL pour l'analyse comparative.
EXPLAINfournit une vue d'ensemble du plan d'exécution des requêtes de votre base de données pour une requête SQL donnée, ce qui vous permet de détecter les composants de requête qui peuvent être optimisés. Pour en savoir plus, consultez le post de la communauté Comment optimiser le code SQL avecEXPLAIN. - Déclarez des index. Vous pouvez consulter les index de chaque table directement dans Looker à partir de l'exécuteur SQL en cliquant sur l'icône en forme de roue dentée dans une table, puis en sélectionnant Afficher les index.
Les colonnes les plus courantes qui peuvent bénéficier d'index sont les dates importantes et les clés étrangères. L'ajout d'index à ces colonnes améliorera les performances de presque toutes les requêtes. Cela s'applique également aux PDT. Les paramètres LookML, tels que
indexes,sort keysetdistribution, peuvent être appliqués de manière appropriée.
Phase de traitement des résultats
Pendant la phase de traitement des résultats, Looker traite et affiche les résultats de la requête. La phase de traitement des résultats comprend les tâches suivantes :
- Diffusion en streaming des résultats de la requête dans le cache
- Résolution des calculs de table
- Mise en forme des résultats du langage de modèle Liquid
- Fusion des requêtes
- Calcul des totaux et des sous-totaux
La page de documentation Comprendre les métriques de performances des requêtes explique comment utiliser l'exploration Métriques de performances des requêtes dans l'activité du système pour afficher des analyses détaillées d'une requête. La phase de traitement des résultats du suivi des requêtes inclut les événements décrits dans la phase Post-requête de l'exploration Métriques de performances des requêtes.
Voici quelques mesures à prendre si vous rencontrez des problèmes de performances au cours de cette phase :
- Utilisez avec parcimonie des fonctionnalités telles que la fusion des résultats, les champs personnalisés, et les calculs de table. Ces fonctionnalités sont destinées à être utilisées comme preuves de concept pour vous aider à concevoir votre modèle. Il est recommandé de coder en dur tous les calculs et fonctions fréquemment utilisés dans LookML, ce qui générera du code SQL à traiter dans votre base de données. Un nombre excessif de calculs peut concurrencer la mémoire Java sur l'instance Looker, ce qui ralentit la réponse de l'instance Looker.
- Limitez le nombre de vues que vous incluez dans un modèle lorsqu'un grand nombre de fichiers de vue sont présents. L'inclusion de toutes les vues dans un seul modèle peut ralentir les performances. Lorsqu'un grand nombre de vues sont présentes dans un projet, n'incluez que les fichiers de vue nécessaires dans chaque modèle. Envisagez d'utiliser des conventions de nommage stratégiques pour les noms de fichiers de vue afin de permettre l'inclusion de groupes de vues dans un modèle. Un exemple est présenté dans la documentation du paramètre
includes. - Évitez de renvoyer un grand nombre de points de données par défaut dans les tuiles et les Looks du tableau de bord. Les requêtes qui renvoient des milliers de points de données consomment plus de mémoire. Assurez-vous que les données sont limitées dans la mesure du possible en appliquant des
filtres frontend aux tableaux de bord, aux Looks et aux explorations, ainsi qu'au niveau LookML avec les paramètres
required filters,conditionally_filteretsql_always_where. - Téléchargez ou distribuez les requêtes à l'aide de l'option Tous les résultats avec parcimonie, car certaines requêtes peuvent être très volumineuses et surcharger le serveur Looker lorsqu'elles sont traitées.