
רוב מאזני העומסים משתמשים בגישה של הקצאת תנועה לפי סבב או לפי זרימה. למאזני עומסים שמשתמשים בגישה הזו יכול להיות קשה להסתגל כשיש עלייה חדה בביקוש לתנועה מעבר ליכולת ההצגה הזמינה. במדריך הזה נסביר איך Cloud Load Balancing מבצע אופטימיזציה של הקיבולת הגלובלית של האפליקציה, וכך משפר את חוויית המשתמש ומפחית את העלויות בהשוואה לרוב ההטמעות של איזון עומסים.
המאמר הזה הוא חלק מסדרת מאמרים בנושא שיטות מומלצות לשימוש במוצרי Cloud Load Balancing. המדריך הזה מלווה במאמר אופטימיזציה של קיבולת באפליקציות באמצעות איזון עומסים גלובלי, שבו מוסבר בפירוט רב יותר על המנגנונים הבסיסיים של הצפת איזון עומסים גלובלי. למידע נוסף על השהיה, אפשר לעיין במאמר אופטימיזציה של השהיה באפליקציות באמצעות Cloud Load Balancing.
במדריך הזה אנחנו מניחים שיש לכם ניסיון מסוים ב-Compute Engine. מומלץ גם להכיר את היסודות של מאזן עומסים חיצוני של אפליקציות.
מטרות
במדריך הזה תלמדו איך להגדיר שרת אינטרנט פשוט שמריץ אפליקציה עתירת CPU שמחשבת קבוצות מנדלברוט. מתחילים במדידת קיבולת הרשת באמצעות כלים לבדיקת עומסים (siege ו-httperf). לאחר מכן משנים את קנה המידה של הרשת למספר מכונות וירטואליות באזור אחד ומודדים את זמן התגובה בעומס. לבסוף, מרחיבים את הרשת למספר אזורים באמצעות איזון עומסים גלובלי, ואז מודדים את זמן התגובה של השרת בעומס ומשווים אותו לזמן התגובה של איזון עומסים באזור יחיד. ביצוע רצף הבדיקות הזה מאפשר לכם לראות את ההשפעות החיוביות של ניהול העומסים בין אזורים ב-Cloud Load Balancing.
מהירות התקשורת ברשת של ארכיטקטורת שרתים טיפוסית בת שלוש שכבות מוגבלת בדרך כלל על ידי מהירות שרת האפליקציות או קיבולת מסד הנתונים, ולא על ידי עומס המעבד בשרת האינטרנט. אחרי שתעברו על ההדרכה, תוכלו להשתמש באותם כלים לבדיקת עומסים ובהגדרות הקיבולת כדי לבצע אופטימיזציה של התנהגות איזון העומסים באפליקציה אמיתית.
תצטרכו:
siegeכך משתמשים בכלי לבדיקת עומסיםsiegeוhttperfכך משתמשים בכלי לבדיקת עומסיםhttperf.- קובעים את קיבולת ההצגה של מופע יחיד של מכונה וירטואלית.
- מודדים את ההשפעות של עומס יתר באמצעות איזון עומסים באזור יחיד.
- מדידת ההשפעות של גלישה לאזור אחר באמצעות איזון עומסים גלובלי.
עלויות
במדריך הזה נעשה שימוש ברכיבים של Google Cloud, והשימוש בהם כרוך בתשלום, כולל:
- Compute Engine
- איזון עומסים וכללי העברה
אפשר להשתמש במחשבון עלויות כדי ליצור הערכת עלויות בהתאם לשימוש החזוי.
לפני שמתחילים
-
בדף לבחירת הפרויקט במסוף Google Cloud , בוחרים פרויקט ב- Google Cloud או יוצרים אותו.
תפקידים שנדרשים כדי לבחור או ליצור פרויקט
- Select a project: כדי לבחור פרויקט לא צריך תפקיד IAM ספציפי – אפשר לבחור כל פרויקט שקיבלתם בו תפקיד.
-
יצירת פרויקט: כדי ליצור פרויקט, צריך את התפקיד Project Creator (יצירת פרויקטים) (
roles/resourcemanager.projectCreator), שכולל את ההרשאהresourcemanager.projects.create. איך מקצים תפקידים
-
מפעילים את Compute Engine API.
תפקידים שנדרשים להפעלת ממשקי API
כדי להפעיל ממשקי API, צריך את תפקיד ה-IAM 'אדמין של Service Usage' (
roles/serviceusage.serviceUsageAdmin), שכולל את ההרשאהserviceusage.services.enable. איך מקצים תפקידים
הגדרת הסביבה
בקטע הזה תגדירו את הגדרות הפרויקט, רשת ה-VPC וכללי חומת האש הבסיסיים שנדרשים כדי להשלים את המדריך.
הפעלת מופע Cloud Shell
פותחים את Cloud Shell מGoogle Cloud המסוף. אלא אם צוין אחרת, את שאר ההוראות במדריך הזה מבצעים מתוך Cloud Shell.
הגדרת הגדרות הפרויקט
כדי להקל על הפעלת פקודות gcloud, אפשר להגדיר מאפיינים כך שלא תצטרכו לספק אפשרויות למאפיינים האלה בכל פקודה.
מגדירים את פרויקט ברירת המחדל באמצעות מזהה הפרויקט במקום
[PROJECT_ID]:gcloud config set project [PROJECT_ID]
מגדירים את ברירת המחדל לתחום (zone) של Compute Engine, באמצעות התחום המועדף שלכם ל-
[ZONE], ואז מגדירים את זה כמשתנה סביבה לשימוש מאוחר יותר:gcloud config set compute/zone [ZONE] export ZONE=[ZONE]
יצירה והגדרה של רשת ה-VPC
יוצרים רשת VPC לצורך בדיקה:
gcloud compute networks create lb-testing --subnet-mode auto
מגדירים כלל חומת אש שמאפשר תנועה פנימית:
gcloud compute firewall-rules create lb-testing-internal \ --network lb-testing --allow all --source-ranges 10.128.0.0/11מגדירים כלל חומת אש שמאפשר לתעבורת SSH לתקשר עם רשת VPC:
gcloud compute firewall-rules create lb-testing-ssh \ --network lb-testing --allow tcp:22 --source-ranges 0.0.0.0/0
קביעת קיבולת ההצגה של מכונה וירטואלית יחידה
כדי לבדוק את מאפייני הביצועים של סוג מכונה וירטואלית, מבצעים את הפעולות הבאות:
מגדירים מכונה וירטואלית שמשרתת את עומס העבודה לדוגמה (המופע של שרת האינטרנט).
יוצרים מכונה וירטואלית שנייה באותו אזור (המכונה הווירטואלית לבדיקת העומס).
במכונה הווירטואלית השנייה, תמדדו את הביצועים באמצעות כלים פשוטים לבדיקת עומסים ולמדידת ביצועים. תשתמשו במדידות האלה בהמשך המדריך כדי להגדיר את קיבולת איזון העומסים הנכונה לקבוצת המופעים.
במופע הראשון של המכונה הווירטואלית נעשה שימוש בסקריפט Python כדי ליצור משימה שדורשת הרבה משאבי CPU. הסקריפט מחשב ומציג תמונה של קבוצת מנדלברוט בכל בקשה לנתיב הבסיס (/). התוצאה לא נשמרת במטמון. במהלך המדריך, תקבלו את סקריפט Python ממאגר GitHub שמשמש לפתרון הזה.
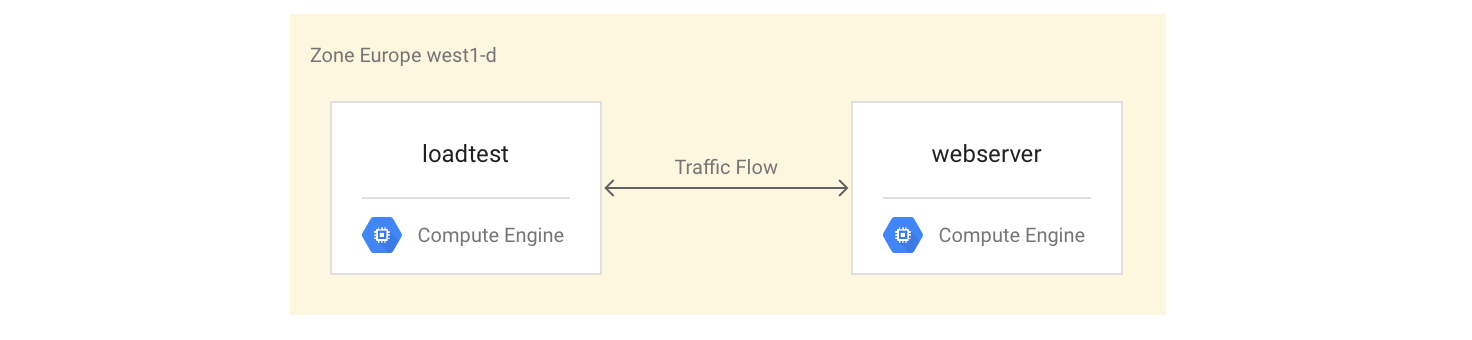
הגדרת המכונות הווירטואליות
מגדירים את המכונה הווירטואלית
webserverכמכונה וירטואלית עם 4 ליבות על ידי התקנה והפעלה של שרת Mandelbrot:gcloud compute instances create webserver --machine-type n1-highcpu-4 \ --network=lb-testing --image-family=debian-12 \ --image-project=debian-cloud --tags=http-server \ --metadata startup-script='#! /bin/bash apt-get -y update apt-get install -y git python-numpy python-matplotlib git clone \ https://github.com/GoogleCloudPlatform/lb-app-capacity-tutorial-python.git cd lb-app-capacity-tutorial-python python webserver.py'יוצרים כלל חומת אש שמאפשר גישה חיצונית ל
webserverמכונה מהמחשב שלכם:gcloud compute firewall-rules create lb-testing-http \ --network lb-testing --allow tcp:80 --source-ranges 0.0.0.0/0 \ --target-tags http-serverמקבלים את כתובת ה-IP של מופע
webserver:gcloud compute instances describe webserver \ --format "value(networkInterfaces[0].accessConfigs[0].natIP)"בדפדפן אינטרנט, עוברים לכתובת ה-IP שהוחזרה בפקודה הקודמת. מוצגת קבוצת מנדלברוט מחושבת:
יוצרים את המכונה לבדיקת העומס:
gcloud compute instances create loadtest --machine-type n1-standard-1 \ --network=lb-testing --image-family=debian-12 \ --image-project=debian-cloud
בדיקת המכונות הווירטואליות
השלב הבא הוא להריץ בקשות כדי לאמוד את מאפייני הביצועים של מכונת ה-VM לבדיקת עומסים.
משתמשים בפקודה
sshכדי להתחבר למכונת ה-VM לבדיקת העומס:gcloud compute ssh loadtest
במופע של בדיקת העומס, מתקינים את siege ואת httperf ככלים לבדיקת עומס:
sudo apt-get install -y siege httperf
הכלי
siegeמאפשר לדמות בקשות ממספר מסוים של משתמשים, ולשלוח בקשות המשך רק אחרי שהמשתמשים קיבלו תשובה. כך תוכלו לקבל תובנות לגבי הקיבולת וזמני התגובה הצפויים של אפליקציות בסביבה של העולם האמיתי.הכלי
httperfמאפשר לשלוח מספר מסוים של בקשות בשנייה, בלי קשר לשאלה אם מתקבלות תגובות או שגיאות. כך תוכלו לקבל תובנות לגבי האופן שבו אפליקציות מגיבות לעומס ספציפי.מדידת הזמן של בקשה פשוטה לשרת האינטרנט:
curl -w "%{time_total}\n" -o /dev/#objectives_2 -s webserverמקבלים תשובה כמו 0.395260. המשמעות היא שהשרת הגיב לבקשה אחרי 395 אלפיות השנייה (ms).
כדי להריץ 20 בקשות מ-4 משתמשים במקביל, משתמשים בפקודה הבאה:
siege -c 4 -r 20 webserver
הפלט אמור להיראות כך:
** SIEGE 4.0.2 ** Preparing 4 concurrent users for battle. The server is now under siege... Transactions: 80 hits Availability: 100.00 % Elapsed time: 14.45 secs Data transferred: 1.81 MB Response time: 0.52 secs Transaction rate: 5.05 trans/sec Throughput: 0.12 MB/sec Concurrency: 3.92 Successful transactions: 80 Failed transactions: 0 **Longest transaction: 0.70 Shortest transaction: 0.37 **
הפלט מוסבר במלואו במדריך של siege, אבל אפשר לראות בדוגמה הזו שזמני התגובה נעו בין 0.37 שניות ל-0.7 שניות. בממוצע, התקבלה תגובה ל-5.05 בקשות לשנייה. הנתונים האלה עוזרים להעריך את קיבולת ההצגה של המערכת.
מריצים את הפקודות הבאות כדי לאמת את הממצאים באמצעות הכלי
httperfלבדיקת עומסים:httperf --server webserver --num-conns 500 --rate 4
הפקודה הזו מריצה 500 בקשות בקצב של 4 בקשות לשנייה, שהוא נמוך מ-5.05 העסקאות לשנייה שהושלמו על ידי
siege.הפלט אמור להיראות כך:
httperf --client=0/1 --server=webserver --port=80 --uri=/ --rate=4 --send-buffer=4096 --recv-buffer=16384 --num-conns=500 --num-calls=1 httperf: warning: open file limit > FD_SETSIZE; limiting max. # of open files to FD_SETSIZE Maximum connect burst length: 1 Total: connections 500 requests 500 replies 500 test-duration 125.333 s Connection rate: 4.0 conn/s (251.4 ms/conn, <=2 concurrent connections) **Connection time [ms]: min 369.6 avg 384.5 max 487.8 median 377.5 stddev 18.0 Connection time [ms]: connect 0.3** Connection length [replies/conn]: 1.000 Request rate: 4.0 req/s (251.4 ms/req) Request size [B]: 62.0 Reply rate [replies/s]: min 3.8 avg 4.0 max 4.0 stddev 0.1 (5 samples) Reply time [ms]: response 383.8 transfer 0.4 Reply size [B]: header 117.0 content 24051.0 footer 0.0 (total 24168.0) Reply status: 1xx=0 2xx=100 3xx=0 4xx=0 5xx=0 CPU time [s]: user 4.94 system 20.19 (user 19.6% system 80.3% total 99.9%) Net I/O: 94.1 KB/s (0.8*10^6 bps) Errors: total 0 client-timo 0 socket-timo 0 connrefused 0 connreset 0 Errors: fd-unavail 0 addrunavail 0 ftab-full 0 other 0
הפלט מוסבר בקובץ httperf README. שימו לב לשורה שמתחילה ב-
Connection time [ms], שבה מוצגות התוצאות הבאות: משך החיבורים היה בין 369.6 ל-487.8 אלפיות השנייה בסך הכול, ולא נוצרו שגיאות.חוזרים על הבדיקה 3 פעמים, ומגדירים את האפשרות
rateל-5, ל-7 ול-10 בקשות לשנייה.בקטעי הקוד הבאים מוצגות פקודות
httperfוהפלט שלהן (מוצגים רק השורות הרלוונטיות עם פרטי זמן החיבור).פקודה ל-5 בקשות לשנייה:
httperf --server webserver --num-conns 500 --rate 5 2>&1| grep 'Errors\|ion time'
תוצאות עבור 5 בקשות לשנייה:
Connection time [ms]: min 371.2 avg 381.1 max 447.7 median 378.5 stddev 7.2 Connection time [ms]: connect 0.2 Errors: total 0 client-timo 0 socket-timo 0 connrefused 0 connreset 0 Errors: fd-unavail 0 addrunavail 0 ftab-full 0 other 0
פקודה ל-7 בקשות לשנייה:
httperf --server webserver --num-conns 500 --rate 7 2>&1| grep 'Errors\|ion time'
תוצאות עבור 7 בקשות לשנייה:
Connection time [ms]: min 373.4 avg 11075.5 max 60100.6 median 8481.5 stddev 10284.2 Connection time [ms]: connect 654.9 Errors: total 4 client-timo 0 socket-timo 0 connrefused 0 connreset 4 Errors: fd-unavail 0 addrunavail 0 ftab-full 0 other 0
פקודה ל-10 בקשות לשנייה:
httperf --server webserver --num-conns 500 --rate 10 2>&1| grep 'Errors\|ion time'
תוצאות עבור 10 בקשות לשנייה:
Connection time [ms]: min 374.3 avg 18335.6 max 65533.9 median 10052.5 stddev 16654.5 Connection time [ms]: connect 181.3 Errors: total 32 client-timo 0 socket-timo 0 connrefused 0 connreset 32 Errors: fd-unavail 0 addrunavail 0 ftab-full 0 other 0
יוצאים מהמופע של
webserver:exit
מהמדידות האלה אפשר להסיק שהקיבולת של המערכת היא בערך 5 בקשות לשנייה (RPS). ב-5 בקשות לשנייה, מכונת ה-VM מגיבה עם זמן אחזור שדומה ל-4 חיבורים. ב-7 וב-10 חיבורים לשנייה, זמן התגובה הממוצע עולה באופן משמעותי ליותר מ-10 שניות, עם שגיאות חיבור מרובות. במילים אחרות, כל דבר מעל 5 בקשות בשנייה גורם להאטה משמעותית.
במערכת מורכבת יותר, קיבולת השרת נקבעת באופן דומה, אבל היא תלויה מאוד בקיבולת של כל הרכיבים שלה. אפשר להשתמש בכלים siege ו-httperf יחד עם ניטור העומס על המעבד ועל קלט/פלט של כל הרכיבים (לדוגמה, שרת הקצה הקדמי, שרת האפליקציות ושרת מסד הנתונים) כדי לזהות צווארי בקבוק. כך תוכלו להפעיל את ההתאמה האופטימלית של כל רכיב.
מדידת ההשפעות של עומס יתר באמצעות מאזן עומסים באזור יחיד
בקטע הזה נבחן את ההשפעות של עומס יתר על מאזני עומסים באזור יחיד, כמו מאזני עומסים טיפוסיים שמשמשים בפריסה מקומית, או Google Cloud מאזן עומסי רשת חיצוני להעברת סיגנל ללא שינוי. אפשר לראות את ההשפעה הזו גם במאזן עומסים מסוג HTTP(S) כשמשתמשים בו לפריסה אזורית (ולא גלובלית).
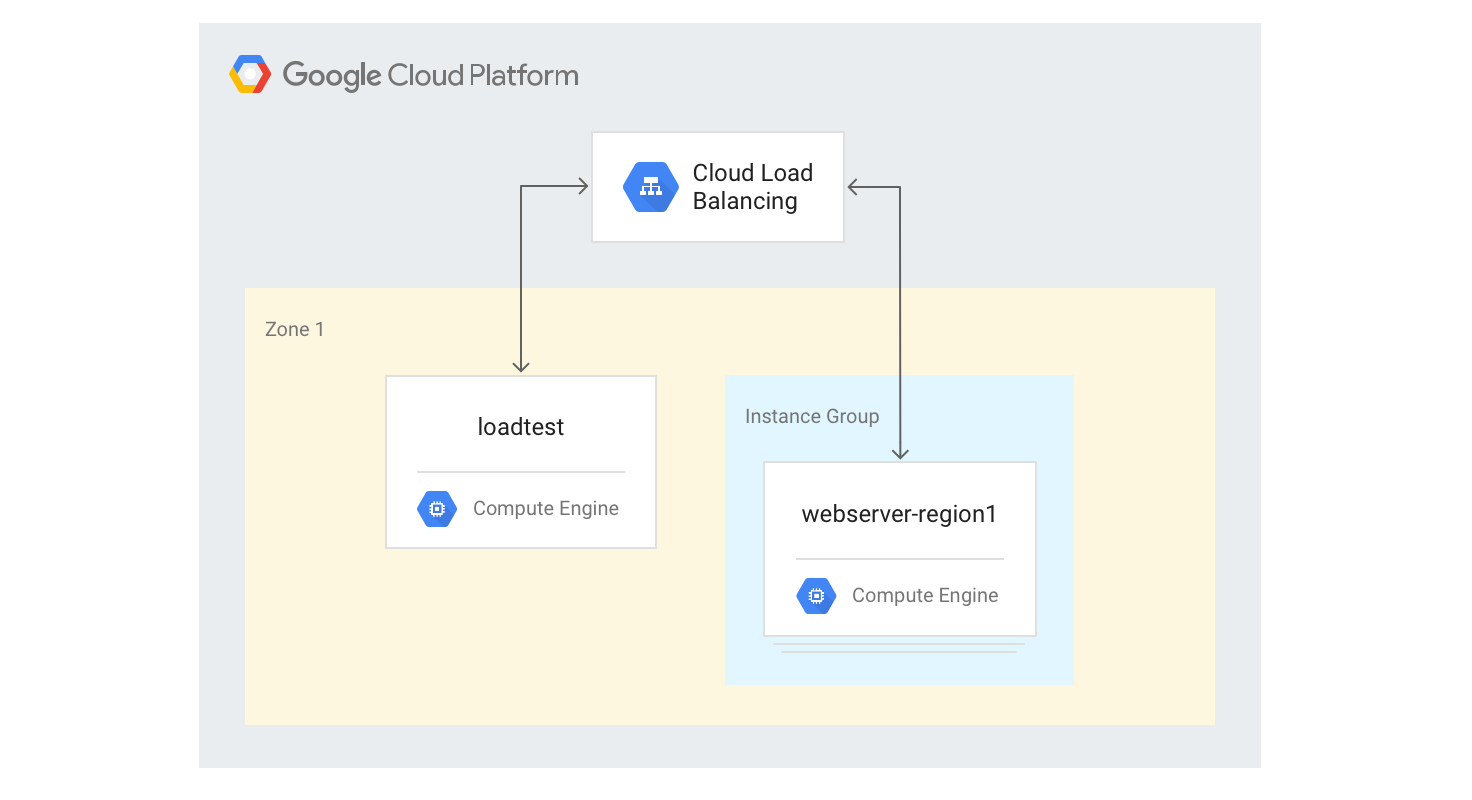
יצירת מאזן עומסים אזורי מסוג HTTP(S)
בשלבים הבאים מוסבר איך ליצור מאזן עומסים HTTP(S) באזור יחיד עם גודל קבוע של 3 מכונות וירטואליות.
יוצרים תבנית של הגדרות מכונה למכונות וירטואליות של שרת האינטרנט באמצעות סקריפט ליצירת מנדלברוט ב-Python שבו השתמשתם קודם. מריצים את הפקודות הבאות ב-Cloud Shell:
gcloud compute instance-templates create webservers \ --machine-type n1-highcpu-4 \ --image-family=debian-12 --image-project=debian-cloud \ --tags=http-server \ --network=lb-testing \ --metadata startup-script='#! /bin/bash apt-get -y update apt-get install -y git python-numpy python-matplotlib git clone \ https://github.com/GoogleCloudPlatform/lb-app-capacity-tutorial-python.git cd lb-app-capacity-tutorial-python python webserver.py'יוצרים קבוצת מופעי מכונה מנוהלים עם 3 מכונות על סמך התבנית מהשלב הקודם:
gcloud compute instance-groups managed create webserver-region1 \ --size=3 --template=webserversיוצרים את בדיקת התקינות, שירות לקצה העורפי, מפת URL, שרת ה-proxy ביעד וכלל ההעברה הגלובלי שנדרשים כדי ליצור איזון עומסים של HTTP:
gcloud compute health-checks create http basic-check \ --request-path="/health-check" --check-interval=60s gcloud compute backend-services create web-service \ --health-checks basic-check --global gcloud compute backend-services add-backend web-service \ --global --instance-group=webserver-region1 \ --instance-group-zone $ZONE gcloud compute url-maps create web-map --default-service web-service gcloud compute target-http-proxies create web-proxy --url-map web-map gcloud compute forwarding-rules create web-rule --global \ --target-http-proxy web-proxy --ports 80משיגים את כתובת ה-IP של כלל ההעברה:
gcloud compute forwarding-rules describe --global web-rule --format "value(IPAddress)"
הפלט הוא כתובת ה-IP הציבורית של מאזן העומסים שיצרתם.
בדפדפן, עוברים לכתובת ה-IP שהוחזרה מהפקודה הקודמת. אחרי כמה דקות, תופיע שוב אותה תמונה של מנדלברוט שראיתם קודם. אבל הפעם התמונה מוגשת מאחד ממופעי ה-VM בקבוצה החדשה שנוצרה.
נכנסים למכונת
loadtest:gcloud compute ssh loadtest
בשורת הפקודה של מכונת
loadtest, בודקים את תגובת השרת עם מספרים שונים של בקשות לשנייה (RPS). חשוב לוודא שאתם משתמשים בערכי RPS לפחות בטווח שבין 5 ל-20.לדוגמה, הפקודה הבאה יוצרת 10 בקשות לשנייה. מחליפים את
[IP_address]בכתובת ה-IP של איזון העומסים משלב קודם בתהליך הזה.httperf --server [IP_address] --num-conns 500 --rate 10 2>&1| grep 'Errors\|ion time'
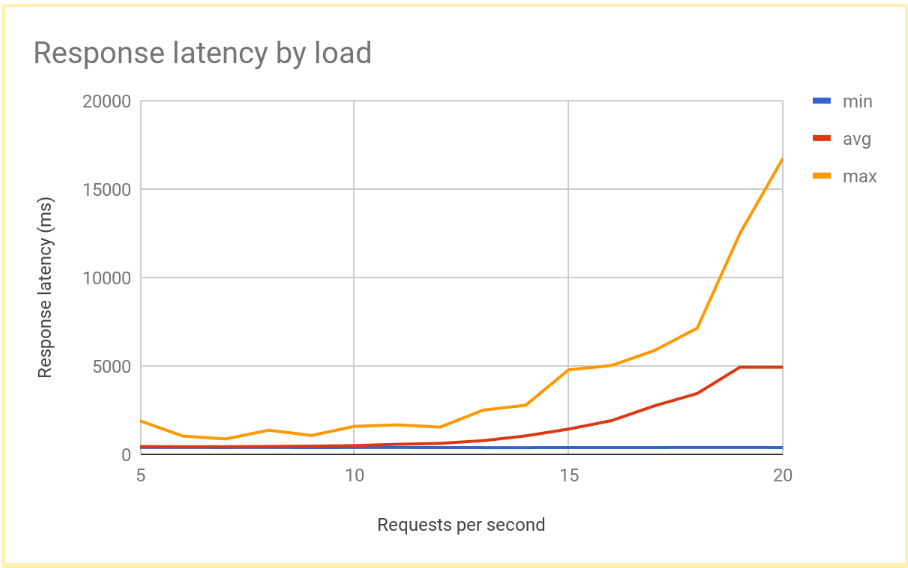
זמן האחזור של התגובה עולה באופן משמעותי ככל שמספר הבקשות לשנייה עולה מעל 12 או 13. הנה תרשים שמציג תוצאות אופייניות:
יוצאים מהחשבון במכונה הווירטואלית
loadtest:exit
הביצועים האלה אופייניים למערכת עם איזון עומסים אזורי. כשהעומס גדל מעבר לקיבולת ההצגה, זמן האחזור הממוצע וגם המקסימלי של הבקשות גדל באופן חד. ב-10 בקשות לשנייה, זמן האחזור הממוצע של הבקשות קרוב ל-500 אלפיות השנייה, אבל ב-20 בקשות לשנייה זמן האחזור הוא 5,000 אלפיות השנייה. זמן האחזור גדל פי עשרה וחוויית המשתמש מתדרדרת במהירות, מה שמוביל לנטישת משתמשים או לפסק זמן של האפליקציה, או לשניהם.
בקטע הבא, תוסיפו אזור שני לטופולוגיית איזון העומסים ותשוו את ההשפעה של מעבר הגיבוי האוטומטי בין אזורים על זמן האחזור של משתמשי הקצה.
מדידת השפעות של עודף תנועה באזור אחר
אם אתם משתמשים באפליקציה גלובלית עם מאזן עומסים של אפליקציות (ALB) חיצוני, ויש לכם שרתי קצה עורפיים שפרוסים בכמה אזורים, כשמתרחש עומס יתר על הקיבולת באזור אחד, תעבורת הנתונים מועברת אוטומטית לאזור אחר. כדי לוודא זאת, אפשר להוסיף לקובץ התצורה שיצרתם בקטע הקודם עוד קבוצת מכונות וירטואליות באזור אחר.
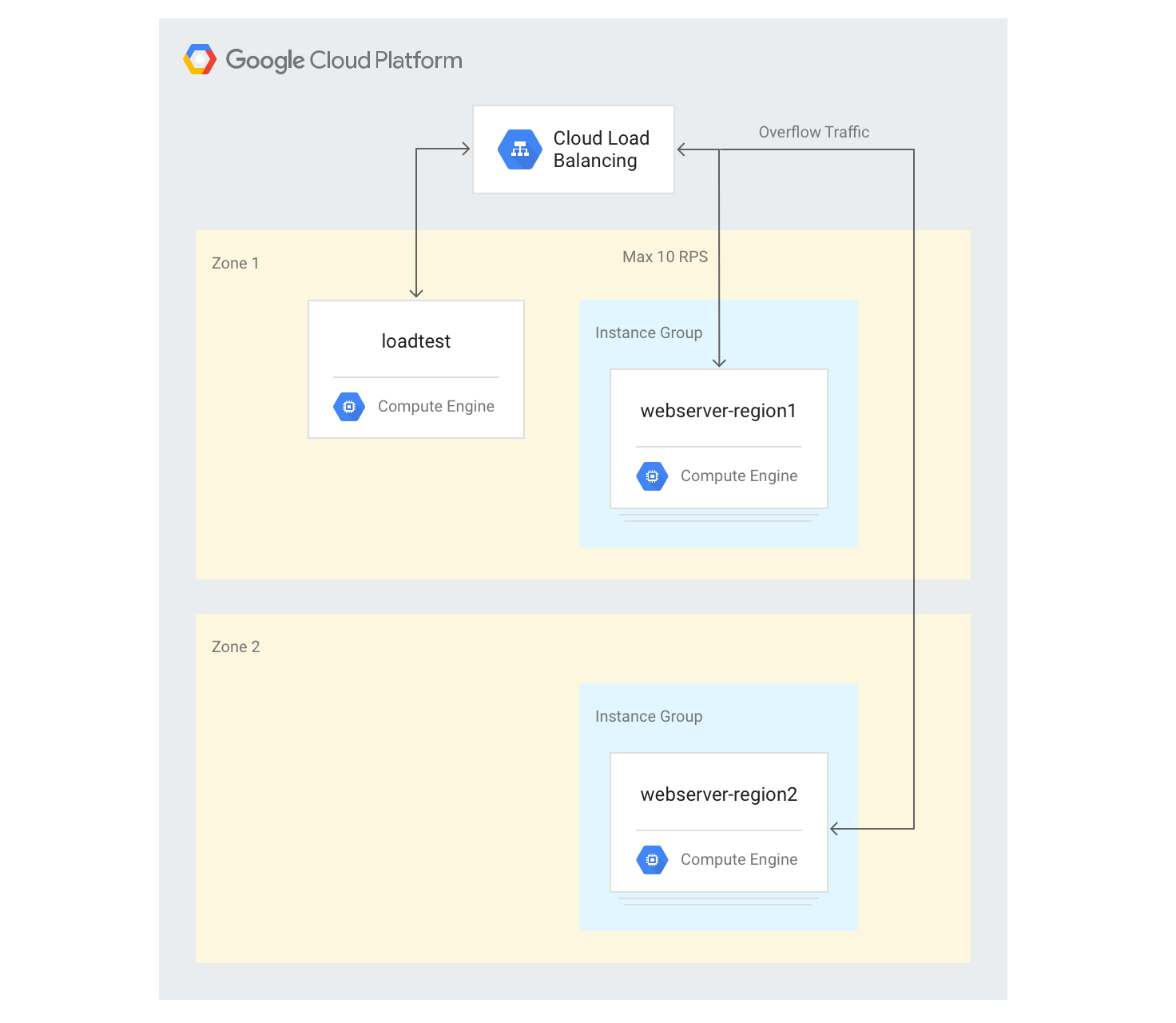
יצירת שרתים בכמה אזורים
בשלבים הבאים תוסיפו עוד קבוצה של שרתי קצה באזור אחר ותקצו קיבולת של 10 בקשות לשנייה לכל אזור. אחרי כן תוכלו לראות איך מאזן העומסים מגיב כשחורגים מהמגבלה הזו.
ב-Cloud Shell, בוחרים אזור שונה מאזור ברירת המחדל ומגדירים אותו כמשתנה סביבה:
export ZONE2=[zone]
יוצרים קבוצת מופעים חדשה באזור השני עם 3 מופעים של מכונות וירטואליות:
gcloud compute instance-groups managed create webserver-region2 \ --size=3 --template=webservers --zone $ZONE2מוסיפים את קבוצת המכונות לשירות הקיים לקצה העורפי עם קיבולת מקסימלית של 10 בקשות לשנייה:
gcloud compute backend-services add-backend web-service \ --global --instance-group=webserver-region2 \ --instance-group-zone $ZONE2 --max-rate 10משנים את
max-rateל-10 בקשות לשנייה בשביל שירות הקצה העורפי הקיים:gcloud compute backend-services update-backend web-service \ --global --instance-group=webserver-region1 \ --instance-group-zone $ZONE --max-rate 10אחרי שכל המופעים יופעלו, נכנסים למופע של מכונת ה-VM
loadtest:gcloud compute ssh loadtest
מריצים 500 בקשות בקצב של 10 בקשות לשנייה. מחליפים את
[IP_address]בכתובת ה-IP של מאזן העומסים:httperf --server [IP_address] --num-conns 500 --rate 10 2>&1| grep 'ion time'
התוצאות ייראו כך:
Connection time [ms]: min 405.9 avg 584.7 max 1390.4 median 531.5 stddev 181.3 Connection time [ms]: connect 1.1
התוצאות דומות לאלה שמתקבלות ממאזן העומסים האזורי.
כלי הבדיקה מפעיל מיד טעינה מלאה, ולא מגדיל את העומס בהדרגה כמו בהטמעה בעולם האמיתי. לכן, צריך לחזור על הבדיקה כמה פעמים כדי שמנגנון הגלישה יפעל. מריצים 500 בקשות 5 פעמים בקצב של 20 בקשות לשנייה. מחליפים את
[IP_address]בכתובת ה-IP של מאזן העומסים.for a in \`seq 1 5\`; do httperf --server [IP_address] \ --num-conns 500 --rate 20 2>&1| grep 'ion time' ; doneהתוצאות ייראו כך:
Connection time [ms]: min 426.7 avg 6396.8 max 13615.1 median 7351.5 stddev 3226.8 Connection time [ms]: connect 0.9 Connection time [ms]: min 417.2 avg 3782.9 max 7979.5 median 3623.5 stddev 2479.8 Connection time [ms]: connect 0.9 Connection time [ms]: min 411.6 avg 860.0 max 3971.2 median 705.5 stddev 492.9 Connection time [ms]: connect 0.7 Connection time [ms]: min 407.3 avg 700.8 max 1927.8 median 667.5 stddev 232.1 Connection time [ms]: connect 0.7 Connection time [ms]: min 410.8 avg 701.8 max 1612.3 median 669.5 stddev 209.0 Connection time [ms]: connect 0.8
אחרי שהמערכת מתייצבת, זמן התגובה הממוצע הוא 400 אלפיות השנייה ב-10 RPS, והוא עולה ל-700 אלפיות השנייה ב-20 RPS. זהו שיפור עצום לעומת העיכוב של 5,000 אלפיות השנייה שמאזן עומסים אזורי מציע, והתוצאה היא חוויית משתמש טובה בהרבה.
בתרשים הבא מוצג זמן התגובה שנמדד לפי RPS באמצעות איזון עומסים גלובלי:
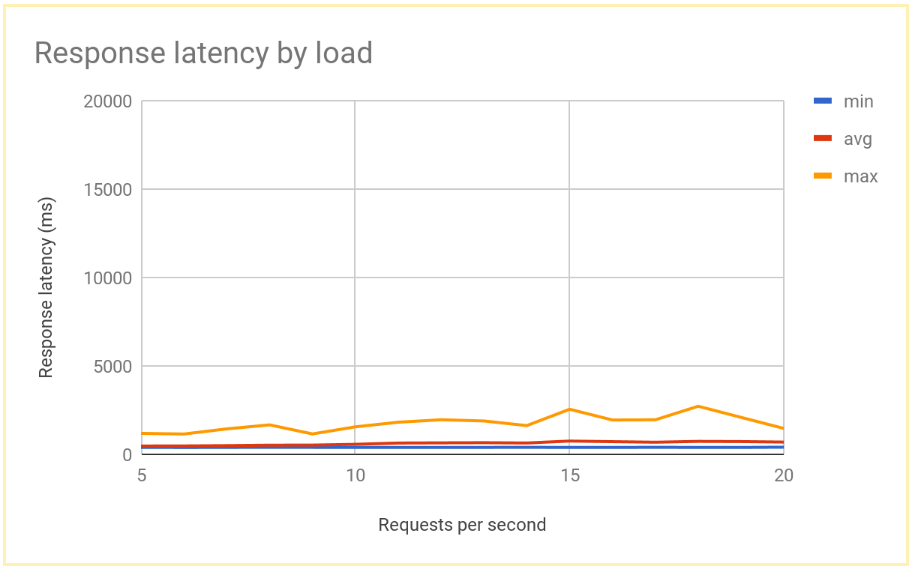
השוואה בין תוצאות של איזון עומסים אזורי וגלובלי
אחרי שקובעים את הקיבולת של צומת יחיד, אפשר להשוות בין זמן האחזור שנמדד אצל משתמשי קצה בפריסה שמבוססת על אזור לבין זמן האחזור בארכיטקטורה של איזון עומסים גלובלי. למרות שמספר הבקשות לאזור יחיד נמוך יותר מקיבולת ההגשה הכוללת באותו אזור, לשתי המערכות יש זמן אחזור דומה למשתמשי הקצה, כי המשתמשים תמיד מופנים לאזור הקרוב ביותר.
כשהעומס באזור מסוים עולה על קיבולת ההגשה באזור הזה, זמן האחזור של משתמש הקצה שונה באופן משמעותי בין הפתרונות:
פתרונות אזוריים לאיזון עומסים מוצפים כשהתעבורה גדלה מעבר לקיבולת, כי התעבורה יכולה לזרום רק למכונות וירטואליות בעורף שהוצפו. זה כולל מאזני עומסים מסורתיים מקומיים, מאזנים חיצוניים של עומסי רשת להעברת סיגנל ללא שינוי ב- Google Cloudומאזנים חיצוניים של עומסי אפליקציות בהגדרה של אזור יחיד (לדוגמה, שימוש במסלול רגיל ברשת). החביון הממוצע והמקסימלי של הבקשות גדל ביותר מפי 10, מה שמוביל לחוויית משתמש גרועה, ובתורה עלול להוביל לנטישה משמעותית של משתמשים.
מאזני עומסים גלובליים חיצוניים של אפליקציות עם בק-אנד באזורים שונים מאפשרים לתעבורה לעבור לאזור הקרוב ביותר שיש בו קיבולת זמינה להצגת תוכן. השינוי הזה מוביל לעלייה מדידה אבל נמוכה יחסית בזמן האחזור של משתמשי הקצה, ומספק חוויית משתמש טובה בהרבה. אם האפליקציה שלכם לא יכולה להתרחב במהירות מספקת באזור מסוים, מומלץ להשתמש במאזן עומסים חיצוני גלובלי של אפליקציות (ALB). גם במהלך כשל באזור מלא של שרתי אפליקציות של משתמשים, התעבורה מופנית מחדש במהירות לאזורים אחרים, ועוזרת להימנע מהשבתה מלאה של השירות.
הסרת המשאבים
מחיקת הפרויקט
הדרך הקלה ביותר לבטל את החיוב היא למחוק את הפרויקט שיצרתם בשביל המדריך הזה.
כדי למחוק את הפרויקט:
- במסוף Google Cloud , נכנסים לדף Manage resources.
- ברשימת הפרויקטים, בוחרים את הפרויקט שרוצים למחוק ולוחצים על Delete.
- כדי למחוק את הפרויקט, כותבים את מזהה הפרויקט בתיבת הדו-שיח ולוחצים על Shut down.
המאמרים הבאים
בדפים הבאים מופיע מידע נוסף על אפשרויות איזון העומסים של Google:
- אופטימיזציה של זמן האחזור של אפליקציות באמצעות Cloud Load Balancing
- Codelab בנושא רשתות – מבוא
- מאזן עומסי רשת חיצוני להעברת סיגנל ללא שינוי
- מאזן עומסים חיצוני של אפליקציות (ALB)
- מאזן עומסי רשת חיצוני לשרת proxy