
이 문서에서는 Google Kubernetes Engine(GKE)에서 vLLM 추론 서버와 함께 Run:ai Model Streamer를 사용하여 Cloud Storage에서 대규모 AI 모델 가중치 로드를 가속화하는 방법을 보여줍니다.
이 문서의 솔루션에서는 AI 모델과 가중치가 safetensors 형식으로 이미 Cloud Storage 버킷에 로드되어 있다고 가정합니다.
vLLM 배포에 --load-format=runai_streamer 플래그를 추가하면 Run:ai Model Streamer를 사용하여 GKE의 AI 워크로드에 대한 모델 다운로드 효율성을 개선할 수 있습니다.
이 문서는 다음 사용자를 대상으로 합니다.
- 객체 스토리지에서 GPU/TPU 노드로 대규모 AI 모델을 최대한 빨리 로드해야 하는 머신러닝 (ML) 엔지니어
- GKE에서 모델 서빙 인프라를 자동화하고 최적화하는 플랫폼 관리자 및 운영자
- AI/ML 워크로드용 특수 데이터 로드 도구를 평가하는 클라우드 설계자
Google Cloud 콘텐츠에서 언급된 일반적인 역할 및 예시 태스크에 대해 자세히 알아보려면 일반 GKE 사용자 역할 및 태스크를 참조하세요.
개요
이 문서에 설명된 솔루션은 세 가지 핵심 구성요소인 Run:ai Model Streamer, vLLM, safetensors 파일 형식을 사용하여 Cloud Storage에서 GPU 또는 TPU 노드로 모델 가중치를 로드하는 프로세스를 가속화합니다.
Run:ai Model Streamer
Run:ai Model Streamer는 대규모 AI 모델을 액셀러레이터에 로드하는 속도를 높이는 오픈소스 Python SDK입니다. Cloud Storage 버킷과 같은 스토리지에서 GPU 또는 TPU 메모리로 모델 가중치를 직접 스트리밍합니다. 이 모델 스트리머는 Cloud Storage에 있는 safetensors 파일에 액세스하는 데 특히 적합합니다.
safetensors
safetensors는 AI 모델의 핵심 데이터 구조인 텐서를 보안과 속도를 모두 향상하는 방식으로 저장하는 파일 형식입니다. safetensors는 Python 피클 형식의 대안으로 설계되었으며 제로 카피 접근 방식을 통해 빠른 로드 시간을 지원합니다. 이 접근 방식을 사용하면 먼저 전체 파일을 로컬 메모리에 로드하지 않고도 소스에서 텐서에 직접 액세스할 수 있습니다.
vLLM
vLLM은 LLM 추론 및 서빙을 위한 오픈소스 라이브러리입니다. 대규모 AI 모델을 빠르게 로드하도록 최적화된 고성능 추론 서버입니다. 이 문서에서 vLLM은 GKE에서 AI 모델을 실행하고 수신되는 추론 요청을 처리하는 핵심 엔진입니다. Cloud Storage에 대한 Run:ai Model Streamer의 기본 제공 인증 지원에는 GPU의 경우 vLLM 버전 0.11.1 이상, TPU의 경우 0.18.0 이상이 필요합니다.
Run:ai Model Streamer가 모델 로드를 가속화하는 방법
추론을 위해 LLM 기반 AI 애플리케이션을 시작하는 경우 모델을 사용할 수 있기 전에 상당한 지연이 발생할 때가 많습니다. 콜드 스타트라고 하는 이 지연이 발생하는 이유는 수 기가바이트에 달하는 전체 모델 파일을 Cloud Storage 버킷과 같은 스토리지 위치에서 머신의 로컬 디스크로 다운로드해야 하기 때문입니다. 이후 파일이 액셀러레이터의 메모리에 로드됩니다. 이 로드 기간 동안 비싼 가속기가 유휴 상태로 유지되므로 비효율적이고 비용이 많이 듭니다.
다운로드 후 로드하는 프로세스 대신 모델 스트리머는 Cloud Storage에서 GPU 또는 TPU 메모리로 모델을 직접 스트리밍합니다. 스트리머는 고성능 백엔드를 사용하여 텐서라고 하는 모델의 여러 부분을 동시에 읽습니다. 텐서를 동시에 읽는 것이 파일을 순차적으로 로드하는 것보다 훨씬 빠릅니다.
아키텍처 개요
Run:ai Model Streamer는 GKE의 vLLM과 통합되어 Cloud Storage에서 가속기 메모리로 직접 모델 가중치를 스트리밍하여 로컬 디스크를 우회함으로써 모델 로드를 가속화합니다.
다음 다이어그램은 이 아키텍처를 보여줍니다.
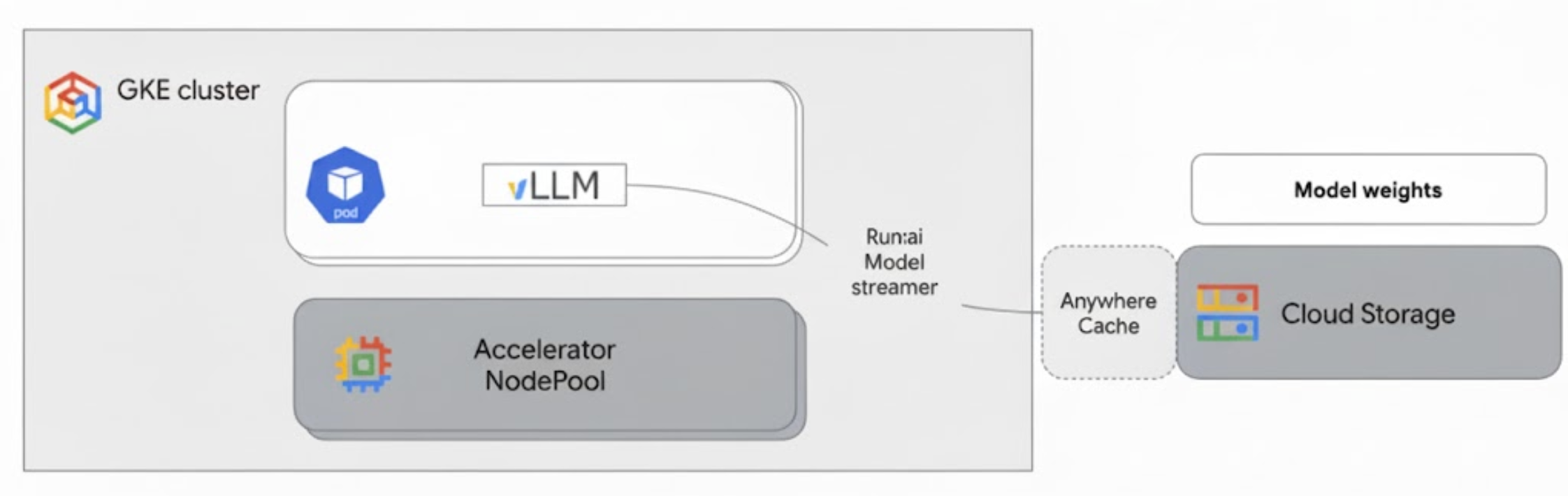
이 아키텍처에는 다음 구성요소와 워크플로가 포함됩니다.
- Cloud Storage 버킷: AI 모델 가중치를
safetensors형식으로 저장합니다. - GPU 또는 TPU가 포함된 GKE 포드: vLLM 추론 서버를 실행합니다.
- vLLM 추론 서버: 모델 스트리머 기능을 사용 설정하는
--load-format=runai_streamer플래그로 구성됩니다. - Run:ai Model Streamer: vLLM이 시작되면 모델 스트리머가 Cloud Storage 버킷의 지정된
gs://경로에서 모델 가중치를 읽습니다. 디스크에 파일을 다운로드하는 대신 텐서 데이터를 GKE 포드의 액셀러레이터 메모리로 직접 스트리밍하여 vLLM이 추론에 즉시 사용할 수 있도록 합니다. - Cloud Storage Rapid Cache (선택사항): 사용 설정된 경우 Rapid Cache는 GKE 노드와 동일한 영역에 버킷 데이터를 캐시하여 스트리머의 데이터 액세스를 더욱 가속화합니다.
이점
- 콜드 스타트 시간 단축: 모델 스트리머는 모델 시작에 소요되는 시간을 크게 줄여줍니다. 기존 방식에 비해 모델 가중치를 최대 6배 더 빠르게 로드합니다. 자세한 내용은 Run:ai Model Streamer 벤치마크를 참조하세요.
- 가속기 사용률 향상: 모델 로드 지연을 최소화하여 GPU 및 TPU와 같은 가속기가 실제 추론 작업에 더 많은 시간을 할애할 수 있으므로 전반적인 효율성과 처리 용량이 향상됩니다.
- 간소화된 워크플로: 이 문서에 설명된 솔루션은 GKE와 통합되어 vLLM 또는 SGLang과 같은 추론 서버가 Cloud Storage 버킷의 모델에 직접 액세스할 수 있습니다.
시작하기 전에
다음 기본 요건을 완료해야 합니다.
프로젝트를 선택하거나 만들고 API를 사용 설정합니다.
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
Verify that billing is enabled for your Google Cloud project.
Enable the Kubernetes Engine, Cloud Storage, Compute Engine, IAM APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM
role (roles/serviceusage.serviceUsageAdmin), which
contains the serviceusage.services.enable permission. Learn how to grant
roles.
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
Verify that billing is enabled for your Google Cloud project.
Enable the Kubernetes Engine, Cloud Storage, Compute Engine, IAM APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM
role (roles/serviceusage.serviceUsageAdmin), which
contains the serviceusage.services.enable permission. Learn how to grant
roles.
Cloud Shell 설정
이 문서에서는 Google Cloud CLI 및 kubectl 명령어를 사용하여 이 솔루션에 필요한 리소스를 만들고 관리합니다. Google Cloud 콘솔 상단에서 Cloud Shell 활성화를 클릭하여 Cloud Shell에서 이러한 명령어를 실행할 수 있습니다.
Google Cloud 콘솔에서 Cloud Shell을 활성화합니다.
또는 로컬 셸 환경에 gcloud CLI를 설치하고 초기화하여 명령어를 실행할 수 있습니다. 로컬 셸 터미널을 사용하려면 gcloud auth login 명령어를 실행하여 Google Cloud에 인증합니다.
IAM 역할 부여
GKE 클러스터를 만들고 Cloud Storage를 관리할 수 있도록 프로젝트에 대한 다음 IAM 역할이 Google Cloud 계정에 있는지 확인합니다.
roles/container.adminroles/storage.admin
이러한 역할을 부여하려면 다음 명령어를 실행합니다.
gcloud projects add-iam-policy-binding PROJECT_ID \
--member="user:$(gcloud config get-value account)" \
--role="roles/container.admin"
gcloud projects add-iam-policy-binding PROJECT_ID \
--member="user:$(gcloud config get-value account)" \
--role="roles/storage.admin"
PROJECT_ID를 프로젝트 ID로 바꿉니다.
개발 환경 준비
이 섹션에서는 GKE 클러스터를 설정하고 Cloud Storage의 모델에 액세스할 수 있는 권한을 구성하는 방법을 안내합니다.
GKE 클러스터 만들기
Run:ai Model Streamer는 GKE Autopilot 및 Standard 클러스터 모두와 함께 사용할 수 있습니다. 요구사항에 가장 적합한 클러스터 모드를 선택합니다.
프로젝트 및 클러스터 이름의 변수를 설정합니다.
export PROJECT_ID=PROJECT_ID export CLUSTER_NAME=CLUSTER_NAME다음을 바꿉니다.
PROJECT_ID: Google Cloud 프로젝트 ID입니다.gcloud config get-value project명령어를 실행하여 프로젝트 ID를 찾을 수 있습니다.CLUSTER_NAME: 클러스터 이름입니다. 예를 들면run-ai-test입니다.
Autopilot 또는 Standard 클러스터를 만듭니다.
Autopilot
GKE Autopilot 클러스터를 만들려면 다음 단계를 따르세요.
클러스터의 리전을 설정합니다.
export REGION=REGIONREGION을 클러스터를 만들려는 리전으로 바꿉니다. 최적의 성능을 위해 Cloud Storage 버킷과 동일한 리전을 사용하세요.클러스터를 만듭니다.
gcloud container clusters create-auto $CLUSTER_NAME \ --project=$PROJECT_ID \ --location=$REGION
Autopilot 클러스터는 워크로드 요구사항에 따라 노드를 자동으로 프로비저닝합니다. 나중에 vLLM 서버를 배포하면 Autopilot에서 필요한 경우 GPU 또는 TPU 노드를 프로비저닝합니다. 자세한 내용은 노드 풀 자동 생성 정보를 참조하세요.
표준
GKE Standard 클러스터를 만들려면 다음 단계를 따르세요.
클러스터의 영역을 설정합니다.
export ZONE=ZONEZONE을 클러스터를 만들려는 영역으로 바꿉니다. 최적의 성능을 위해 Cloud Storage 버킷과 동일한 리전의 영역을 사용하세요.클러스터를 만듭니다.
gcloud container clusters create $CLUSTER_NAME \ --project=$PROJECT_ID \ --zone=$ZONE \ --workload-pool=$PROJECT_ID.svc.id.goog \ --num-nodes=1
노드 풀 만들기
Standard 클러스터를 만든 경우 GPU 또는 TPU가 포함된 노드 풀을 만들어야 합니다. Autopilot 클러스터는 워크로드 요구사항에 따라 노드를 자동으로 프로비저닝합니다. 사용할 액셀러레이터에 따라 노드 풀을 만듭니다.
* {GPU}
Create a node pool with one G2 machine (NVIDIA L4 GPU):
```sh
gcloud container node-pools create g2-gpu-pool \
--cluster=$CLUSTER_NAME \
--zone=$ZONE \
--machine-type=g2-standard-16 \
--num-nodes=1 \
--accelerator=type=nvidia-l4
```
* {TPU}
Create a node pool with TPU v7x nodes:
```sh
gcloud container node-pools create tpu7x-pool \
--cluster=$CLUSTER_NAME \
--zone=$ZONE \
--machine-type=tpu7x-standard-4t \
--num-nodes=1
```
GKE용 워크로드 아이덴티티 제휴 구성
GKE 워크로드가 Cloud Storage 버킷의 모델에 안전하게 액세스할 수 있도록 GKE용 워크로드 아이덴티티 제휴를 구성합니다.
Kubernetes 서비스 계정 및 네임스페이스의 변수를 설정합니다.
export KSA_NAME=KSA_NAME export NAMESPACE=NAMESPACE다음을 바꿉니다.
NAMESPACE: 워크로드가 실행될 네임스페이스입니다. 이 문서의 모든 리소스를 만들 때 동일한 네임스페이스를 사용해야 합니다.KSA_NAME: 포드가 Google Cloud API에 인증하는 데 사용할 수 있는 Kubernetes 서비스 계정의 이름입니다.
Kubernetes 네임스페이스를 만듭니다.
kubectl create namespace $NAMESPACEKubernetes 서비스 계정(KSA)을 만듭니다.
kubectl create serviceaccount $KSA_NAME \ --namespace=$NAMESPACEKSA에 필요한 권한을 부여합니다.
환경 변수를 설정합니다.
export BUCKET_NAME=BUCKET_NAME export PROJECT_ID=PROJECT_ID export PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID \ --format 'get(projectNumber)')다음을 바꿉니다.
BUCKET_NAME:safetensors파일이 포함된 Cloud Storage 버킷의 이름입니다.PROJECT_ID: Google Cloud 프로젝트 ID입니다.
PROJECT_NUMBER,PROJECT_ID,NAMESPACE,KSA_NAME은 다음 단계에서 프로젝트의 GKE용 워크로드 아이덴티티 제휴 주 구성원 식별자를 구성하는 데 사용됩니다.Cloud Storage 버킷의 객체를 볼 수 있도록 KSA에
roles/storage.bucketViewer역할을 부여합니다.gcloud storage buckets add-iam-policy-binding gs://$BUCKET_NAME \ --member="principal://iam.googleapis.com/projects/$PROJECT_NUMBER/locations/global/workloadIdentityPools/$PROJECT_ID.svc.id.goog/subject/ns/$NAMESPACE/sa/$KSA_NAME" \ --role="roles/storage.bucketViewer"Cloud Storage 버킷에서 객체를 읽고 쓰고 삭제할 수 있도록 KSA에
roles/storage.objectUser역할을 부여합니다.gcloud storage buckets add-iam-policy-binding gs://$BUCKET_NAME \ --member="principal://iam.googleapis.com/projects/$PROJECT_NUMBER/locations/global/workloadIdentityPools/$PROJECT_ID.svc.id.goog/subject/ns/$NAMESPACE/sa/$KSA_NAME" \ --role="roles/storage.objectUser"
GPU 또는 TPU가 있는 GKE 클러스터를 설정하고 GKE용 워크로드 아이덴티티 제휴를 구성하여 Kubernetes 서비스 계정에 Cloud Storage의 AI 모델에 액세스하는 데 필요한 권한을 부여했습니다. 클러스터와 권한이 준비되면 이 서비스 계정을 사용하여 Run:ai Model Streamer로 모델 가중치를 스트리밍하는 vLLM 추론 서버를 배포할 수 있습니다.
Run:ai Model Streamer로 vLLM 배포
vLLM OpenAI 호환 서버를 실행하고 Run:ai Model Streamer를 사용하도록 --load-format=runai_streamer 플래그로 구성된 포드를 배포합니다. vLLM 버전은 GPU의 경우 0.11.1 이상, TPU의 경우 0.18.0 이상이어야 합니다.
다음 샘플 매니페스트는 gemma-2-9b-it와 같은 소형 모델에 모델 스트리머를 사용 설정하여 vLLM을 구성하는 방법을 보여줍니다.
--model-loader-extra-config={"distributed":true} 플래그는 모델 가중치의 분산 로드를 사용 설정하며 객체 스토리지에서 모델 로드 성능을 개선하기 위해 권장되는 설정입니다.
자세한 내용은 텐서 병렬 처리 및 조정 가능한 파라미터를 참고하세요.
사용하려는 액셀러레이터에 따라 샘플 매니페스트를 선택합니다.
GPU
다음 샘플 매니페스트는 단일 NVIDIA L4 GPU를 사용합니다. 여러 GPU가 필요한 대규모 모델을 사용하는 경우
--tensor-parallel-size값을 필요한 GPU 수로 늘립니다.다음 매니페스트를
vllm-deployment.yaml로 저장합니다. 이 매니페스트는 Autopilot 및 Standard 클러스터 모두에서 유연하게 사용할 수 있도록 설계되었습니다.apiVersion: apps/v1 kind: Deployment metadata: name: vllm-streamer-deployment namespace: NAMESPACE spec: replicas: 1 selector: matchLabels: app: vllm-streamer template: metadata: labels: app: vllm-streamer spec: serviceAccountName: KSA_NAME containers: - name: vllm-container image: vllm/vllm-openai:v0.11.1 command: - python3 - -m - vllm.entrypoints.openai.api_server args: - --model=gs://BUCKET_NAME/PATH_TO_MODEL - --load-format=runai_streamer - --model-loader-extra-config={"distributed":true} - --host=0.0.0.0 - --port=8000 - --disable-log-requests - --tensor-parallel-size=1 ports: - containerPort: 8000 name: api # startupProbe allows for longer startup times for large models startupProbe: httpGet: path: /health port: 8000 failureThreshold: 60 # 60 * 10s = 10 minutes timeout periodSeconds: 10 initialDelaySeconds: 30 readinessProbe: httpGet: path: /health port: 8000 failureThreshold: 3 periodSeconds: 10 resources: limits: nvidia.com/gpu: "1" requests: nvidia.com/gpu: "1" volumeMounts: - mountPath: /dev/shm name: dshm nodeSelector: cloud.google.com/gke-accelerator: nvidia-l4 volumes: - emptyDir: medium: Memory name: dshm다음을 바꿉니다.
NAMESPACE: Kubernetes 네임스페이스입니다.KSA_NAME: Kubernetes 서비스 계정 이름입니다.BUCKET_NAME: Cloud Storage 버킷 이름PATH_TO_MODEL: 버킷 내 모델 디렉터리의 경로(예:models/my-llama)
TPU
다음 샘플 매니페스트는 TPU v7x 노드를 사용합니다.
다음 매니페스트를
vllm-deployment.yaml로 저장합니다.apiVersion: apps/v1 kind: Deployment metadata: name: tpu-vllm namespace: NAMESPACE spec: replicas: 1 selector: matchLabels: app: tpu-vllm template: metadata: labels: app: tpu-vllm spec: serviceAccountName: KSA_NAME containers: - name: vllm-container image: vllm/vllm-tpu:v0.18.0 resources: limits: google.com/tpu: "4" command: ["sh", "-c"] args: - >- python3 -m vllm.entrypoints.openai.api_server --model=gs://BUCKET_NAME/PATH_TO_MODEL --load-format=runai_streamer --tensor-parallel-size=8 --port=8000 ports: - containerPort: 8000 env: - name: VLLM_XLA_CACHE_PATH value: "gs://BUCKET_NAME/PATH_TO_CACHE" nodeSelector: cloud.google.com/gke-tpu-accelerator: tpu7x cloud.google.com/gke-tpu-topology: 2x2x1다음을 바꿉니다.
NAMESPACE: Kubernetes 네임스페이스입니다.KSA_NAME: Kubernetes 서비스 계정 이름입니다.BUCKET_NAME: Cloud Storage 버킷 이름PATH_TO_MODEL: 버킷 내 모델 디렉터리의 경로(예:models/my-llama)PATH_TO_CACHE: 버킷 내 XLA 컴파일 캐시 디렉터리의 경로(예:models/xla-cache)
매니페스트를 적용하여 배포를 만듭니다.
kubectl create -f vllm-deployment.yaml
GKE Inference Quickstart 도구를 사용하여 vLLM 매니페스트를 더 많이 생성할 수 있습니다.
배포 확인
배포 상태를 확인합니다.
kubectl get deployments -n NAMESPACEPod 이름을 가져옵니다.
kubectl get pods -n NAMESPACE | grep vllm-streamervllm-streamer-deployment로 시작하는 포드의 이름을 기록해 둡니다.모델 스트리머가 모델과 가중치를 다운로드하는지 확인하려면 포드 로그를 확인하세요.
kubectl logs -f POD_NAME -n NAMESPACEPOD_NAME을 이전 단계의 포드 이름으로 바꿉니다. 성공적인 스트리밍 로그는 다음과 비슷합니다.[RunAI Streamer] Overall time to stream 15.0 GiB of all files: 13.4s, 1.1 GiB/s
선택사항: Rapid Cache로 성능 개선
Cloud Storage Rapid Cache는 GKE 노드에 더 가까운 위치에 데이터를 캐시하여 모델 로딩을 더욱 가속화할 수 있습니다. 캐싱은 동일한 영역에서 여러 노드를 스케일 아웃할 때 특히 유용합니다.
특정 Google Cloud 영역의 특정 Cloud Storage 버킷에 대해 Rapid Cache를 사용 설정합니다. 성능을 개선하려면 캐시의 영역이 GKE 추론 포드가 실행되는 영역과 일치해야 합니다. 접근 방식은 포드가 예측 가능한 영역에서 실행되는지에 따라 달라집니다.
포드가 실행될 영역을 알고 있는 GKE Standard 영역 클러스터의 경우 해당 특정 영역에 대해 Rapid Cache를 사용 설정합니다.
여러 영역에 포드를 예약할 수 있는 리전 GKE 클러스터(Autopilot 및 Standard 모두)의 경우 다음과 같은 옵션이 있습니다.
- 모든 영역에서 캐싱 사용 설정: 클러스터 리전 내의 모든 영역에서 Rapid Cache를 사용 설정합니다. 이렇게 하면 GKE가 포드를 예약하는 위치와 관계없이 캐시를 사용할 수 있습니다. 캐싱이 사용 설정된 영역마다 비용이 발생한다는 점에 유의하세요. 자세한 내용은 Rapid Cache 가격 책정을 참고하세요.
- 특정 영역에 포드 배치: 워크로드 매니페스트에서
nodeSelector또는nodeAffinity규칙을 사용하여 포드를 단일 영역으로 제한합니다. 그런 다음 해당 영역에서만 Rapid Cache를 사용 설정할 수 있습니다. 워크로드가 단일 영역으로 제한되는 것을 허용하는 경우 이 방법이 더 비용 효율적입니다.
GKE 클러스터가 있는 영역에 대해 Rapid Cache를 사용 설정하려면 다음 명령어를 실행합니다.
# Enable the cache
gcloud storage buckets anywhere-caches create gs://$BUCKET_NAME $ZONE
# Check the status of the cache
gcloud storage buckets anywhere-caches describe $BUCKET_NAME/$ZONE
삭제
이 문서에서 사용된 리소스 비용이 Google Cloud 계정에 청구되지 않도록 하려면 리소스가 포함된 프로젝트를 삭제하거나 프로젝트는 유지하되 개별 리소스를 삭제하세요.
개별 리소스를 삭제하려면 다음 단계를 따르세요.
GKE 클러스터를 삭제합니다. 이 작업을 수행하면 모든 노드와 워크로드가 삭제됩니다.
gcloud container clusters delete CLUSTER_NAME --location=ZONE_OR_REGION다음을 바꿉니다.
CLUSTER_NAME: 클러스터 이름입니다.ZONE_OR_REGION: 클러스터의 영역 또는 리전입니다.
Rapid Cache를 사용 설정한 경우 지속적인 비용이 발생하지 않도록 이를 중지합니다. 자세한 내용은 캐시 중지를 참조하세요.
다음 단계
- Hugging Face 모델을 Cloud Storage에 로드하는 방법(실험용) 알아보기
- GKE에서 여러 GPU로 LLM을 서빙하는 방법을 알아보세요.
- GKE에서 사용 가능한 GPU 자세히 알아보기
- GKE에서 사용할 수 있는 TPU에 대해 자세히 알아보세요.
- GKE 스토리지 개요 읽기
- 워크로드 아이덴티티 제휴 구성 알아보기