
이 페이지에서는 GKE 추론 빠른 시작 (GIQ)을 사용하여 Google Kubernetes Engine (GKE)에서 AI/ML 추론 워크로드의 배포를 간소화하는 방법을 설명합니다. 추론 빠른 시작은 추론 비즈니스 요구사항을 지정하고 모델, 모델 서버, 가속기 (GPU, TPU), 확장, 저장소에 관한 권장사항 및 Google의 벤치마크에 따라 최적화된 Kubernetes 구성을 가져올 수 있는 유틸리티입니다. 이렇게 하면 구성을 수동으로 조정하고 테스트하는 데 시간이 오래 걸리는 프로세스를 피할 수 있습니다.
이 페이지는 AI/ML 추론을 위해 GKE를 효율적으로 관리하고 최적화하는 방법을 알아보려는 머신러닝(ML) 엔지니어, 플랫폼 관리자 및 운영자, 데이터 및 AI 전문가를 대상으로 합니다. Google Cloud 콘텐츠에서 참조하는 일반적인 역할 및 예시 태스크에 대해 자세히 알아보려면 일반 GKE 사용자 역할 및 태스크를 참조하세요.
모델 서빙 개념 및 용어와 GKE 생성형 AI 기능이 모델 서빙 성능을 향상하고 지원하는 방법에 대해 자세히 알아보려면 GKE의 모델 추론 정보를 참조하세요.
이 페이지를 읽기 전에 Kubernetes, GKE, 모델 서빙을 숙지해야 합니다.
추론 빠른 시작 사용
Inference Quickstart를 사용하면 추론 워크로드의 성능과 비용 효율성을 분석하고 리소스 할당 및 모델 배포 전략에 관한 데이터 기반 결정을 내릴 수 있습니다.
추론 빠른 시작을 사용하는 대략적인 단계는 다음과 같습니다.
성능 및 비용 분석:
gcloud container ai profiles list명령어를 사용하여 사용 가능한 구성을 살펴보고 성능 및 비용 요구사항에 따라 필터링합니다. 특정 구성의 전체 벤치마킹 데이터를 보려면gcloud container ai profiles benchmarks list명령어를 사용합니다. 이 명령어를 사용하면 특정 성능 요구사항에 가장 비용 효율적인 하드웨어를 식별할 수 있습니다.또한 사용 사례, 입력/출력 크기, 서빙 스택과 같은 워크로드 특성을 기반으로 추론 빠른 시작 추천을 필터링할 수 있습니다. 서빙 스택은 모델을 호스팅하고, 추론을 처리하고, 사용자 요청을 라우팅하여 예측을 제공하는 데 사용되는 전체 기술 세트입니다. 예를 들어
llm-d서빙 스택은 vLLM을 기본 모델 서버로 사용하여 핵심 추론 엔진 위에 오케스트레이션 및 라우팅 레이어를 추가합니다.매니페스트 배포: 분석 후 최적화된 Kubernetes 매니페스트를 생성하여 배포할 수 있습니다. 필요에 따라 스토리지 및 자동 확장을 위한 최적화를 사용 설정할 수 있습니다. Google Cloud 콘솔에서 또는
kubectl apply명령어를 사용하여 배포할 수 있습니다. 배포하기 전에 Google Cloud 프로젝트에서 선택한 GPU 또는 TPU에 충분한 가속기 할당량이 있는지 확인해야 합니다.(선택사항) 자체 벤치마크 실행: 추론 빠른 시작에서 제공하는 구성 및 성능 데이터는
inference-perf도구로 생성된 벤치마크를 기반으로 합니다. 워크로드의 성능은 이 기준과 다를 수 있으므로inference-perf도구를 사용하여 사용 사례를 가장 잘 나타내는 데이터 세트로 모델의 성능을 측정하는 것이 좋습니다.
이점
추론 빠른 시작은 최적화된 구성을 제공하여 시간과 리소스를 절약하는 데 도움이 됩니다. 이러한 최적화는 다음과 같은 방법으로 성능을 개선하고 인프라 비용을 절감합니다.
- 가속기(GPU 및 TPU), 모델 서버, 확장 구성 설정에 관한 맞춤설정된 세부 권장사항을 확인할 수 있습니다. GKE는 최신 수정사항, 이미지, 성능 벤치마크를 사용하여 Inference Quickstart를 정기적으로 업데이트합니다.
- Google Cloud 콘솔 UI 또는 명령줄 인터페이스를 사용하여 워크로드의 지연 시간 및 처리량 요구사항을 지정하고 Kubernetes 배포 매니페스트로 맞춤설정된 자세한 권장사항을 확인할 수 있습니다.
작동 방식
추론 빠른 시작은 모델, 모델 서버, 가속기 토폴로지 조합의 단일 복제본 성능에 관한 Google의 포괄적인 내부 벤치마크를 기반으로 맞춤 권장사항을 제공합니다. 이러한 벤치마크는 큐 크기 및 KV 캐시 측정항목을 포함하여 지연 시간과 처리량을 그래프로 표시하여 각 조합의 성능 곡선을 매핑합니다.
맞춤 권장사항이 생성되는 방식
가속기의 포화도를 높여 출력 토큰당 정규화된 시간 (NTPOT)과 첫 번째 토큰까지의 시간 (TTFT)을 밀리초 단위로, 처리량을 초당 출력 토큰 단위로 측정합니다. 이러한 성능 측정항목에 대해 자세히 알아보려면 GKE의 모델 추론 정보를 참고하세요.
다음 지연 시간 프로필 예시는 처리량이 정체되는 변곡점(녹색), 지연 시간이 악화되는 변곡점 이후 지점(빨간색), 지연 시간 목표에서 최적의 처리량을 위한 이상적인 영역(파란색)을 보여줍니다. Inference Quickstart는 이 이상적인 영역에 대한 성능 데이터와 구성을 제공합니다.
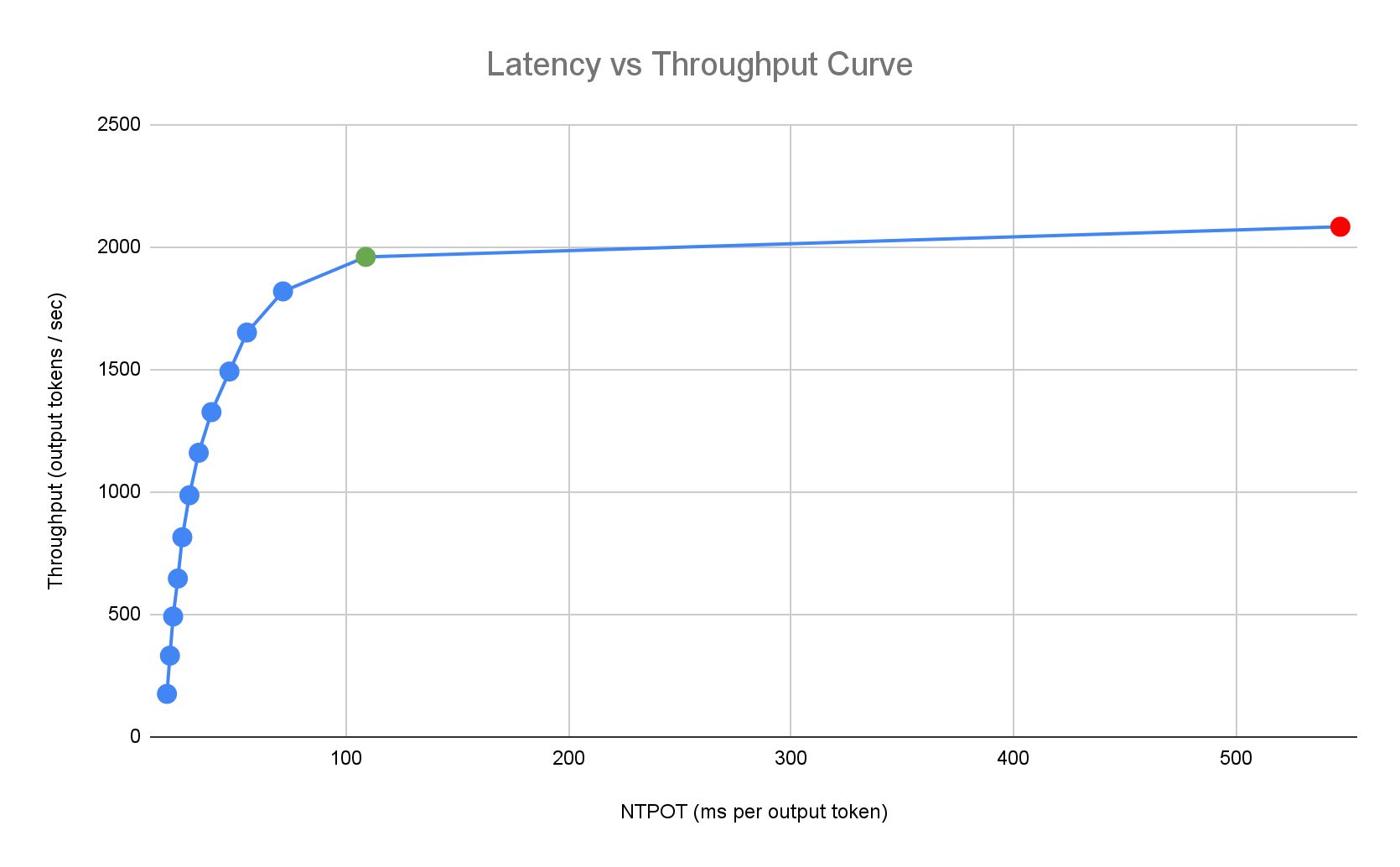
추론 애플리케이션의 지연 시간 요구사항에 따라 추론 빠른 시작은 적합한 조합을 식별하고 지연 시간-처리량 곡선에서 최적의 작동 지점을 결정합니다. 이 지점에서 확장 지연 시간을 고려하는 버퍼와 함께 수평형 포드 자동 확장 처리(HPA) 기준점이 설정됩니다. 전반적인 기준점은 필요한 초기 복제본 수도 알려 주지만 HPA는 워크로드를 기반으로 이 수를 동적으로 조정합니다.
예상 비용
가속기 VM의 토큰당 비용을 추정하기 위해 추론 빠른 시작에서는 구성 가능한 출력 대비 입력 비용 비율을 사용합니다. 예를 들어 이 비율이 4로 설정되면 각 출력 토큰의 비용이 입력 토큰의 4배라고 가정합니다. 다음 방정식은 토큰당 비용 측정항목을 계산하는 데 사용됩니다.
\[ \$/\text{output token} = \frac{\text{GPU \$/s}}{(\frac{1}{\text{output-to-input-cost-ratio}} \cdot \text{input tokens/s} + \text{output tokens/s})} \]
각 항목의 의미는 다음과 같습니다.
\[ \$/\text{input token} = \frac{\text{\$/output token}}{\text{output-to-input-cost-ratio}} \]
벤치마킹
제공된 구성 및 성능 데이터는 다음 입력 및 출력 분포로 트래픽을 전송하기 위해 inference-perf 도구에서 생성된 벤치마크를 기반으로 합니다.
| 입력 토큰 | 출력 토큰 | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 최소 | 중앙값 | 평균 | P90 | P99 | 최대 | 최소 | 중앙값 | 평균 | P90 | P99 | 최대 |
| 4 | 108 | 226 | 635 | 887 | 1024 | 1 | 132 | 195 | 488 | 778 | 1024 |
시작하기 전에
시작하기 전에 다음 태스크를 수행했는지 확인합니다.
- Google Kubernetes Engine API를 사용 설정합니다. Google Kubernetes Engine API 사용 설정
- 이 태스크에 Google Cloud CLI를 사용하려면 gcloud CLI를 설치한 후 초기화합니다. 이전에 gcloud CLI를 설치했으면
gcloud components update명령어를 실행하여 최신 버전을 가져옵니다. 이전 gcloud CLI 버전에서는 이 문서의 명령어를 실행하지 못할 수 있습니다.
Google Cloud 콘솔의 프로젝트 선택기 페이지에서 Google Cloud 프로젝트를 선택하거나 만듭니다.
프로젝트에 충분한 액셀러레이터 용량이 있는지 확인합니다.
- GPU를 사용하는 경우 할당량 페이지를 확인합니다.
- TPU를 사용하는 경우: TPU 및 기타 GKE 리소스의 할당량 확인을 참조하세요.
GKE AI/ML 사용자 인터페이스 사용 준비
Google Cloud 콘솔을 사용하는 경우 프로젝트에 아직 Autopilot 클러스터가 생성되지 않았다면 Autopilot 클러스터를 생성해야 합니다. Autopilot 클러스터 만들기의 안내를 따릅니다.
명령줄 인터페이스 사용 준비
gcloud CLI를 사용하여 추론 빠른 시작을 실행하는 경우 다음 추가 명령어 또한 실행해야 합니다.
gkerecommender.googleapis.comAPI를 사용 설정합니다.gcloud services enable gkerecommender.googleapis.comAPI 호출에 사용할 결제 할당량 프로젝트를 설정합니다.
gcloud config set billing/quota_project PROJECT_IDgcloud CLI 버전이 536.0.1 이상인지 확인합니다. 그렇지 않은 경우 다음을 실행합니다.
gcloud components update
제한사항
추론 빠른 시작을 사용하기 전에 다음 제한사항에 유의하세요.
- Google Cloud 콘솔 모델 배포는 Autopilot 클러스터에 대한 배포만 지원합니다.
- Inference Quickstart는 특정 모델 서버에서 지원하는 모든 모델의 프로필을 제공하지 않습니다.
- Hugging Face에서 대규모 모델(90GiB 이상)용으로 생성된 매니페스트를 사용할 때
HF_HOME환경 변수를 설정하지 않으면 기본값보다 큰 부팅 디스크가 있는 클러스터를 사용하거나 매니페스트를 수정하여HF_HOME을/dev/shm/hf_cache로 설정해야 합니다. 이렇게 하면 노드의 부팅 디스크 대신 캐시에 RAM이 사용됩니다. 자세한 내용은 문제 해결 섹션을 참조하세요. - Cloud Storage에서 모델을 로드하려면 GKE용 워크로드 아이덴티티 제휴가 필요합니다. Cloud Storage FUSE CSI 드라이버는 모든 TPU 워크로드에도 필요하며
v0.11.1이전의 특정 모델 서버 버전의 대체로도 필요합니다. GKE용 워크로드 아이덴티티 제휴 및 Cloud Storage FUSE CSI 드라이버는 기본적으로 Autopilot 클러스터에서 사용 설정됩니다. 자세한 내용은 GKE용 Cloud Storage FUSE CSI 드라이버 설정을 참고하세요.
모델 추론에 최적화된 구성 분석 및 보기
이 섹션에서는 Google Cloud CLI를 사용하여 구성 권장사항을 탐색하고 분석하는 방법을 설명합니다.
gcloud container ai profiles 명령어를 사용하여 최적화된 프로필 (모델, 모델 서버, 모델 서버 버전, 액셀러레이터의 조합)을 탐색하고 분석합니다.
모델
모델을 살펴보고 선택하려면 models 옵션을 사용하세요.
gcloud container ai profiles models list
프로필
list 명령어를 사용하여 생성된 프로필을 살펴보고 실적 및 비용 요구사항에 따라 필터링합니다. 예를 들면 다음과 같습니다.
gcloud container ai profiles list \
--model=openai/gpt-oss-20b \
--pricing-model=on-demand \
--target-ttft-milliseconds=300
출력에는 변곡점에서 처리량, 지연 시간, 백만 토큰당 비용과 같은 성능 측정항목이 지원되는 프로필이 표시됩니다. 다음과 비슷하게 표시됩니다.
Instance Type Accelerator Cost/M Input Tokens Cost/M Output Tokens Output Tokens/s NTPOT(ms) TTFT(ms) Model Server Model Server Version Model
a3-highgpu-1g nvidia-h100-80gb 0.009 0.035 13335 67 297 vllm gptoss openai/gpt-oss-20b
이 값은 이 가속기 유형을 사용하는 지정된 프로필에서 처리량 증가가 중지되고 지연 시간이 급격히 증가하기 시작하는 지점(즉, 변곡점 또는 포화점)에서 관찰된 성능을 나타냅니다. 이러한 성능 측정항목에 대해 자세히 알아보려면 GKE의 모델 추론 정보를 참고하세요.
설정할 수 있는 플래그의 전체 목록은 list 명령어 문서를 참고하세요.
모든 가격 정보는 USD 통화로만 제공되며 A3 머신을 사용하는 구성을 제외하고 기본적으로 us-east5 리전으로 설정됩니다. A3 머신을 사용하는 구성은 기본적으로 us-central1 리전으로 설정됩니다.
벤치마크
특정 프로필의 모든 벤치마킹 데이터를 가져오려면 benchmarks list 명령어를 사용합니다.
예를 들면 다음과 같습니다.
gcloud container ai profiles benchmarks list \
--model=deepseek-ai/DeepSeek-R1-Distill-Qwen-7B \
--model-server=vllm
출력에는 다양한 요청 비율로 실행된 벤치마크의 성능 측정항목 목록이 포함됩니다.
이 명령어는 출력을 CSV 형식으로 표시합니다. 출력을 파일로 저장하려면 출력 리디렉션을 사용하세요. 예를 들면 gcloud container ai profiles benchmarks list > profiles.csv입니다.
설정할 수 있는 플래그의 전체 목록은 benchmarks list 명령어 문서를 참고하세요.
모델, 모델 서버, 모델 서버 버전, 가속기를 선택한 후 배포 매니페스트를 만들면 됩니다.
사용 사례별 추천 보기
Inference Quickstart는 일반적인 AI/ML 워크로드를 나타내는 다양한 사용 사례에 대한 추천을 제공합니다. 이러한 사용 사례는 실제 고객 워크로드를 기반으로 하는 다양한 입력 및 출력 토큰 길이로 특징지어지며, 이는 기본 추론 제공 스택의 성능에 영향을 미칠 수 있습니다.
다음 표에는 사용 가능한 사용 사례와 그 특징이 요약되어 있습니다.
| 사용 사례 | 입력 토큰 | 출력 토큰 | 비율 | 설명 |
|---|---|---|---|---|
| 고급 고객 지원 | 8,192 | 256 | 32:1 | 포괄적이고 종합적인 답변으로 복잡한 고객 문제를 해결하여 지원 운영을 확장하고 사용자 만족도를 개선하세요. |
| 코드 완성 | 512 | 32 | 16:1 | 코드를 자동으로 제안하고 완성하여 소프트웨어 개발 속도를 높입니다. |
| 텍스트 요약 | 1,024 | 128 | 8:1 | 긴 문서, 기사 또는 대화를 간결한 요약으로 압축합니다. |
| 챗봇 (ShareGPT) | 128 | 128 | 1:1 | 질문에 답변하고, 작업을 실행하고, 안내를 제공하는 즉각적인 대화형 지원을 제공합니다. |
| 텍스트 생성 | 512 | 2,048 | 1:4 | 이메일 및 보고서 초안 작성부터 창의적인 스토리 생성까지 새로운 텍스트 콘텐츠 생성을 자동화하세요. |
| Deep Research | 256 | 4,096 | 1:16 | 방대한 양의 데이터를 분석하고 종합하여 특정 정보를 찾고, 패턴을 식별하고, 인사이트를 발견하여 자세한 조사와 연구를 지원합니다. |
추론 빠른 시작에서 지원하는 사용 사례의 전체 목록을 확인하려면 gcloud container ai profiles use-cases list 명령어를 사용하세요.
사용 사례별로 추천을 필터링하려면 --use-case 플래그를 사용하세요. 매니페스트를 만들 때 이 플래그를 지정하지 않으면 기본값은 Chatbot입니다.
예를 들면 다음과 같습니다.
gcloud container ai profiles list \
--use-case="Text Summarization"
권장 구성 배포
이 섹션에서는 Google Cloud 콘솔 또는 명령줄을 사용하여 구성 권장사항을 생성하고 배포하는 방법을 설명합니다.
콘솔
- Google Cloud 콘솔에서 GKE AI/ML 페이지로 이동합니다.
- 모델 배포를 클릭합니다.
배포할 모델을 선택합니다. Inference Quickstart에서 지원하는 모델은 최적화됨 태그와 함께 표시됩니다.
- 파운데이션 모델을 선택하면 모델 페이지가 열립니다. 배포를 클릭합니다. 구성은 실제 배포 전에 계속 수정할 수 있습니다.
- 프로젝트에 Autopilot 클러스터가 없으면 Autopilot 클러스터를 만들라는 메시지가 표시됩니다. Autopilot 클러스터 만들기의 안내를 따릅니다. 클러스터를 만든 후 Google Cloud 콘솔의 GKE AI/ML 페이지로 돌아가 모델을 선택합니다.
- Gemma 또는 Llama와 같은 게이트 모델을 배포하려면 먼저 Hugging Face 토큰을 만들고 Kubernetes 보안 비밀로 추가해야 합니다. 그렇게 하지 않으면 배포가 생성되지 않는
"Does not have minimum availability"오류가 발생할 수 있습니다. 자세한 안내는 이 문서 페이지의 gcloud 탭을 참고하세요.
모델 배포 페이지에는 선택한 모델과 권장 모델 서버 및 가속기가 자동으로 입력됩니다. 최대 지연 시간 및 모델 소스와 같은 설정도 구성할 수 있습니다.
(선택사항) 권장 구성으로 매니페스트를 보려면 YAML 보기를 클릭합니다.
권장 구성으로 매니페스트를 배포하려면 배포를 클릭합니다. 배포 작업이 완료되는 데 몇 분 정도 걸릴 수 있습니다.
배포를 보려면 Kubernetes Engine > 워크로드 페이지로 이동합니다.
gcloud
모델 레지스트리에서 모델 로드 준비: 추론 빠른 시작은 Hugging Face 또는 Cloud Storage에서 모델 로드를 지원합니다.
Hugging Face
아직 없는 경우 Hugging Face 액세스 토큰과 해당 Kubernetes 보안 비밀을 생성합니다.
Hugging Face 토큰이 포함된 Kubernetes 보안 비밀을 만들려면 다음 명령어를 실행합니다.
kubectl create secret generic hf-secret \ --from-literal=hf_api_token=HUGGING_FACE_TOKEN \ --namespace=NAMESPACE다음 값을 바꿉니다.
- HUGGING_FACE_TOKEN: 앞에서 생성한 Hugging Face 토큰입니다.
- NAMESPACE: 모델 서버를 배포할 Kubernetes 네임스페이스입니다.
일부 모델에서는 동의 라이선스 계약에 동의하고 서명해야 할 수도 있습니다.
Cloud Storage
조정된 Cloud Storage FUSE 설정으로 Cloud Storage에서 지원되는 모델을 로드할 수 있습니다. 이렇게 하려면 먼저 Hugging Face에서 Cloud Storage 버킷으로 모델을 로드해야 합니다.
이 Kubernetes 작업을 배포하여 모델을 전송하고
MODEL_ID을 추론 빠른 시작 지원 모델로 변경할 수 있습니다.매니페스트 생성: 매니페스트를 생성할 때 사용할 수 있는 옵션은 다음과 같습니다.
- 기본 구성: 단일 복제본 추론 서버를 배포하기 위한 표준 Kubernetes 배포, 서비스, PodMonitoring 매니페스트를 생성합니다.
- (선택사항) 스토리지 최적화 구성: Cloud Storage 로드에 최적화된 매니페스트를 생성합니다. 이 구성은 지원되는 vLLM 버전의 성능을 개선하기 위해 Run:ai Model Streamer에 우선순위를 부여하는 동시에 이전 버전에는 조정된 Cloud Storage FUSE 설정을 사용합니다.
--model-bucket-uri플래그를 사용하여 이 구성을 사용 설정합니다. 이러한 최적화를 통해 LLM Pod 시작 시간을 7배 이상 개선할 수 있습니다. (선택사항) 자동 확장 최적화 구성: 트래픽에 따라 모델 서버 복제본 수를 자동으로 조정하는 수평형 포드 자동 확장 처리 (HPA)가 포함된 매니페스트를 생성합니다.
--target-ntpot-milliseconds와 같은 플래그로 지연 시간 타겟을 지정하여 이 구성을 사용 설정합니다.
기본 구성
터미널에서
manifests옵션을 사용하여 배포, 서비스, PodMonitoring 매니페스트를 생성합니다.gcloud container ai profiles manifests create필수
--model,--model-server,--accelerator-type파라미터를 사용하여 매니페스트를 맞춤설정합니다.원하는 경우 다음 파라미터를 설정할 수 있습니다.
--target-ntpot-milliseconds: 이 파라미터를 설정하여 HPA 기준점을 지정합니다. 이 파라미터를 사용하면 50번째 백분위수에서 측정되는 출력 토큰당 정규화된 시간 (NTPOT) P50 지연 시간을 지정된 값 미만으로 유지하도록 확장 기준점을 정의할 수 있습니다. 액셀러레이터의 최소 지연 시간보다 큰 값을 선택합니다. 액셀러레이터의 최대 지연 시간보다 높은 NTPOT 값을 지정하면 HPA가 최대 처리량으로 구성됩니다. 예를 들면 다음과 같습니다.gcloud container ai profiles manifests create \ --model=google/gemma-2-27b-it \ --model-server=vllm \ --model-server-version=v0.7.2 \ --accelerator-type=nvidia-l4 \ --target-ntpot-milliseconds=200--target-ttft-milliseconds: 타겟 첫 번째 토큰까지의 시간(TTFT)(밀리초)입니다. 이 값이 설정되면 매니페스트에 지정된 기준점 미만으로 p50 TTFT를 유지하는 수평형 포드 자동 확장 처리 (HPA) 리소스가 포함됩니다.--output-path: 지정된 경우 출력이 터미널에 인쇄되지 않고 제공된 경로에 저장되므로 배포하기 전에 출력을 수정할 수 있습니다. 예를 들어 매니페스트를 YAML 파일에 저장하려면--output=manifest옵션과 함께 사용할 수 있습니다. 예를 들면 다음과 같습니다.gcloud container ai profiles manifests create \ --model deepseek-ai/DeepSeek-R1-Distill-Qwen-7B \ --model-server vllm \ --accelerator-type=nvidia-tesla-a100 \ --output=manifest \ --output-path /tmp/manifests.yaml--target-itl-milliseconds: 타겟 토큰 간 지연 시간(ITL)(밀리초)입니다. 이 값이 설정되면 매니페스트에 지정된 기준점 아래로 p50 ITL을 유지하는 수평형 포드 자동 확장 처리 (HPA) 리소스가 포함됩니다.--use-case: 매니페스트가 이 사용 사례에 맞게 최적화됩니다. 지정하지 않으면 이 플래그의 기본값은Chatbot입니다. 자세한 내용은 사용 사례별 권장사항 보기를 참고하세요.
설정할 수 있는 플래그의 전체 목록은
manifests create명령어 문서를 참고하세요.스토리지 최적화
Cloud Storage에서 모델을 로드하여 Pod 시작 시간을 개선할 수 있습니다. Inference Quickstart는 구성에 가장 적합한 성능의 스토리지 백엔드를 자동으로 선택합니다.
- Run:ai Model Streamer: GPU의 vLLM 버전 0.11.1 이상과 TPU의 0.14.0 이상에서 자동으로 사용되는 스트리밍 솔루션입니다.
- Cloud Storage FUSE CSI 드라이버: vLLM 버전 0.11.1 이전 버전 및 기타 모델 서버에 사용되는 표준 스토리지 최적화입니다.
Cloud Storage에서 로드하려면 GKE 버전 1.29.6-gke.1254000, 1.30.2-gke.1394000 이상이 필요합니다.
이를 위해 다음 단계를 따르세요.
- Hugging Face 저장소에서 Cloud Storage 버킷으로 모델을 로드합니다.
매니페스트를 생성할 때
--model-bucket-uri플래그를 설정합니다. 이렇게 하면 Cloud Storage 버킷에서 로드하도록 모델이 구성됩니다. 모델은 지원되는 vLLM 버전의 경우 고성능 Run:ai Model Streamer를 자동으로 사용하고, 그 외의 경우 Cloud Storage FUSE CSI 드라이버로 대체됩니다. URI는 모델의config.json파일과 가중치가 포함된 경로를 가리켜야 합니다. 버킷 URI에 추가하여 버킷 내 디렉터리의 경로를 지정할 수 있습니다.예를 들면 다음과 같습니다.
gcloud container ai profiles manifests create \ --model=openai/gpt-oss-120b \ --model-server=vllm \ --model-server-version=v0.11.2 \ --accelerator-type=nvidia-h100-80gb \ --model-bucket-uri=gs://BUCKET_NAME \ --output-path=manifests.yamlBUCKET_NAME을 Cloud Storage 버킷의 이름으로 바꿉니다.매니페스트를 적용하기 전에 매니페스트의 주석에 있는
gcloud storage buckets add-iam-policy-binding명령어를 실행해야 합니다. 이 명령어는 GKE 서비스 계정에 GKE용 워크로드 아이덴티티 제휴를 사용하여 Cloud Storage 버킷에 액세스할 수 있는 권한을 부여하는 데 필요합니다.TPU에서 배포를 두 개 이상의 복제본으로 확장하려면 XLA 캐시 경로 (
VLLM_XLA_CACHE_PATH)에 대한 동시 쓰기 오류를 방지하기 위해 다음 옵션 중 하나를 선택해야 합니다.- 옵션 1 (권장): 먼저 배포를 복제본 1개로 확장합니다. 포드가 준비될 때까지 기다립니다. 그러면 포드가 XLA 캐시에 쓸 수 있습니다. 그런 다음 원하는 복제본 수로 확장합니다. 이후 복제본은 쓰기 충돌 없이 채워진 캐시에서 읽습니다.
- 옵션 2: 매니페스트에서
VLLM_XLA_CACHE_PATH환경 변수를 완전히 삭제합니다. 이 접근 방식은 더 간단하지만 모든 복제본의 캐싱을 사용 중지합니다.
TPU 가속기 유형에서 이 캐시 경로는 XLA 컴파일 캐시를 저장하는 데 사용되며, 이는 반복 배포를 위한 모델 준비를 가속화합니다.
성능 개선에 관한 자세한 내용은 GKE 성능을 위해 Cloud Storage FUSE CSI 드라이버 최적화를 참고하세요.
자동 확장 최적화
부하에 따라 모델 서버 복제본 수를 자동으로 조정하도록 수평형 포드 자동 확장 처리 (HPA)를 구성할 수 있습니다. 이를 통해 모델 서버가 필요에 따라 확장 또는 축소되어 다양한 부하를 효율적으로 처리할 수 있습니다. HPA 구성은 GPU 및 TPU 가이드의 자동 확장 권장사항을 따릅니다.
매니페스트를 생성할 때 HPA 구성을 포함하려면
--target-ntpot-milliseconds및--target-ttft-milliseconds플래그 중 하나 또는 둘 다를 사용합니다. 이러한 파라미터는 HPA가 NTPOT 또는 TTFT의 P50 지연 시간을 지정된 값 미만으로 유지하도록 확장 기준점을 정의합니다. 이러한 플래그 중 하나만 설정하면 해당 측정항목만 확장 시 고려됩니다.가속기의 최소 지연 시간보다 큰 값을 선택합니다. 액셀러레이터의 최대 지연 시간보다 큰 값을 지정하면 HPA가 최대 처리량으로 구성됩니다.
예를 들면 다음과 같습니다.
gcloud container ai profiles manifests create \ --model=google/gemma-2-27b-it \ --accelerator-type=nvidia-l4 \ --target-ntpot-milliseconds=250클러스터 만들기: GKE Autopilot 또는 Standard 클러스터에서 모델을 서빙할 수 있습니다. 완전 관리형 Kubernetes 환경을 위해서는 Autopilot 클러스터를 사용하는 것이 좋습니다. 워크로드에 가장 적합한 GKE 작업 모드를 선택하려면 GKE 작업 모드 선택을 참조하세요.
기존 클러스터가 없는 경우 다음 단계를 따르세요.
Autopilot
다음 안내에 따라 Autopilot 클러스터를 만드세요. 프로젝트에 필요한 할당량이 있는 경우 GKE는 배포 매니페스트에 따라 GPU 또는 TPU 용량이 있는 노드 프로비저닝을 처리합니다.
Standard
- 영역 또는 리전 클러스터를 만듭니다.
적절한 액셀러레이터로 노드 풀을 만듭니다. 선택한 가속기 유형에 따라 다음 단계를 따르세요.
- GPU: 먼저 Google Cloud 콘솔의 할당량 페이지에서 GPU 용량이 충분한지 확인합니다. 그런 다음 GPU 노드 풀 만들기의 안내를 따릅니다.
- TPU: 먼저 TPU 및 기타 GKE 리소스의 할당량 확인의 안내에 따라 TPU가 충분한지 확인합니다. 그런 다음 TPU 노드 풀 만들기로 진행합니다.
(선택사항이나 권장됨) 모니터링 가능성 기능 사용 설정: 생성된 매니페스트의 주석 섹션에는 추천 모니터링 가능성 기능을 사용 설정하기 위한 추가 명령어가 제공됩니다. 이러한 기능을 사용 설정하면 워크로드와 기본 인프라의 성능 및 상태를 모니터링하는 데 도움이 되는 더 많은 정보를 얻을 수 있습니다.
다음은 모니터링 가능성 기능을 사용 설정하는 명령어의 예시입니다.
gcloud container clusters update $CLUSTER_NAME \ --project=$PROJECT_ID \ --location=$LOCATION \ --enable-managed-prometheus \ --logging=SYSTEM,WORKLOAD \ --monitoring=SYSTEM,DEPLOYMENT,HPA,POD,DCGM \ --auto-monitoring-scope=ALL자세한 내용은 추론 워크로드 모니터링을 참조하세요.
(HPA만 해당) 측정항목 어댑터 배포: 배포 매니페스트에서 HPA 리소스가 생성된 경우 커스텀 측정항목 Stackdriver 어댑터와 같은 측정항목 어댑터가 필요합니다. 측정항목 어댑터를 사용하면 HPA가 kube 외부 측정항목 API를 사용하는 모델 서버 측정항목에 액세스할 수 있습니다. 어댑터를 배포하려면 GitHub의 어댑터 문서를 참조하세요.
매니페스트 배포:
kubectl apply명령어를 실행하고 매니페스트의 YAML 파일을 전달합니다. 예를 들면 다음과 같습니다.kubectl apply -f ./manifests.yaml
llm-d 서빙 스택에 권장 구성 배포
llm-d는 테스트되고 벤치마킹된 '잘 조명된 경로'를 제공하여 대규모 생성형 AI 모델을 높은 수준의 성능으로 제공할 수 있도록 지원하는 Kubernetes 네이티브 분산 추론 서빙 스택입니다. 자세한 내용은 llm-d 문서를 참고하세요.
추론 빠른 시작을 사용하여 llm-d 서빙 스택의 권장 구성을 생성하고 배포하려면 값이 llm-d으로 설정된 --serving-stack 플래그를 사용하세요. 예를 들면 다음과 같습니다.
gcloud container ai profiles manifests create \
--accelerator-type=nvidia-h100-80gb \
--model=openai/gpt-oss-120b \
--model-server=vllm \
--serving-stack=llm-d \
--use-case 'Multi Agent Large Document Summarization'
manifests create 출력에서 추가 클러스터 생성 및 종속 항목 설치 안내를 확인하여 llm-d 환경을 올바르게 설정합니다.
배포 엔드포인트 테스트
매니페스트를 배포하면 서비스가 http://SERVICE_NAME:8000에 노출됩니다. 여기서 SERVICE_NAME은 배포 이름입니다.
서비스 이름을 확인하려면 네임스페이스의 서비스를 나열하면 됩니다(예: default).
kubectl get services --namespace NAMESPACE
배포를 테스트하려면 kubectl port-forward 명령어를 사용하여 로컬 포트를 서비스 포트로 전달합니다. 별도의 터미널에서 다음 명령어를 실행합니다.
kubectl port-forward service/SERVICE_NAME 8000:8000
그런 다음 http://localhost:8000에 요청을 보낼 수 있습니다. 엔드포인트에 요청을 빌드하고 전송하는 방법의 예시는 vLLM 문서를 참고하세요.
매니페스트 버전 관리
추론 빠른 시작에서는 최근 GKE 클러스터 버전에서 검증된 최신 매니페스트를 제공합니다. 프로필에 대해 반환된 매니페스트는 시간이 지남에 따라 변경될 수 있으므로 배포 시 최적화된 구성을 받게 됩니다. 안정적인 매니페스트가 필요한 경우 별도로 저장하세요.
매니페스트에는 다음과 같은 형식의 주석과 recommender.ai.gke.io/version 주석이 포함됩니다.
# Generated on DATE using:
# GKE cluster CLUSTER_VERSION
# GPU_DRIVER_VERSION GPU driver for node version NODE_VERSION
# Model server MODEL_SERVER MODEL_SERVER_VERSION
이전 주석의 값은 다음과 같습니다.
- DATE: 매니페스트가 생성된 날짜입니다.
- CLUSTER_VERSION: 유효성 검사에 사용되는 GKE 클러스터 버전입니다.
- NODE_VERSION: 검증에 사용되는 GKE 노드 버전입니다.
- GPU_DRIVER_VERSION: (GPU만 해당) 검증에 사용되는 GPU 드라이버 버전입니다.
- MODEL_SERVER: 매니페스트에 사용된 모델 서버입니다.
- MODEL_SERVER_VERSION: 매니페스트에 사용된 모델 서버 버전입니다.
추론 워크로드 모니터링
배포된 추론 워크로드를 모니터링하려면 Google Cloud 콘솔의 측정항목 탐색기로 이동합니다.
자동 모니터링 사용 설정
GKE에는 광범위한 모니터링 가능성 기능의 일부인 자동 모니터링 기능이 포함되어 있습니다. 이 기능은 지원되는 모델 서버에서 실행되는 워크로드를 클러스터에서 스캔하고 이러한 워크로드 측정항목이 Cloud Monitoring에 표시되도록 하는 PodMonitoring 리소스를 배포합니다. 자동 모니터링을 사용 설정하고 구성하는 방법에 관한 자세한 내용은 워크로드의 자동 애플리케이션 모니터링 구성을 참조하세요.
이 기능을 사용 설정하면 GKE가 지원되는 워크로드의 모니터링 애플리케이션을 위한 사전 빌드된 대시보드를 설치합니다.
Google Cloud 콘솔의 GKE AI/ML 페이지에서 배포하는 경우 targetNtpot 구성을 사용하여 PodMonitoring 및 HPA 리소스가 자동으로 생성됩니다.
문제 해결
- 지연 시간을 너무 낮게 설정하면 추론 빠른 시작에서 추천을 생성하지 않을 수 있습니다. 이 문제를 해결하려면 선택한 가속기에서 관찰된 최소 지연 시간과 최대 지연 시간 사이의 지연 시간 목표를 선택합니다.
- 추론 빠른 시작은 GKE 구성요소와 독립적으로 존재하므로 서비스 사용에 클러스터 버전이 직접적으로 관련이 없습니다. 하지만 성능 차이를 방지하려면 최신 클러스터를 사용하는 것이 좋습니다.
- 할당량 프로젝트가 누락되었다는
gkerecommender.googleapis.com명령어에 대한PERMISSION_DENIED오류가 표시되면 수동으로 설정해야 합니다.gcloud config set billing/quota_project PROJECT_ID를 실행하여 이 문제를 해결합니다.
임시 스토리지가 부족하여 포드가 제거됨
Hugging Face에서 대규모 모델(90GiB 이상)을 배포할 때 다음과 유사한 오류 메시지와 함께 포드가 제거될 수 있습니다.
Fails because inference server consumes too much ephemeral storage, and gets evicted low resources: Warning Evicted 3m24s kubelet The node was low on resource: ephemeral-storage. Threshold quantity: 10120387530, available: 303108Ki. Container inference-server was using 92343412Ki, request is 0, has larger consumption of ephemeral-storage..,
이 오류는 모델이 노드의 부팅 디스크(임시 스토리지의 한 형태)에 캐시되기 때문에 발생합니다. 배포 매니페스트에서 HF_HOME 환경 변수를 노드의 RAM에 있는 디렉터리로 설정하지 않으면 부팅 디스크가 임시 스토리지에 사용됩니다.
- 기본적으로 GKE 노드에는 100GiB 부팅 디스크가 있습니다.
- GKE는 시스템 오버헤드를 위해 부팅 디스크의 10%를 예약하므로 워크로드에 90GiB가 남습니다.
- 모델 크기가 90GiB 이상이고 기본 크기의 부팅 디스크에서 실행되는 경우 kubelet이 임시 스토리지를 확보하기 위해 포드를 제거합니다.
이 문제를 해결하려면 다음 옵션 중 하나를 선택합니다.
- 모델 캐싱에 RAM 사용: 배포 매니페스트에서
HF_HOME환경 변수를/dev/shm/hf_cache로 설정합니다. 이렇게 하면 부팅 디스크 대신 노드의 RAM을 사용하여 모델을 캐시합니다. - 부팅 디스크 크기 늘리기:
- GKE Standard: 클러스터를 만들거나 노드 풀을 만들거나 노드 풀을 업데이트할 때 부팅 디스크 크기를 늘립니다.
- Autopilot: 더 큰 부팅 디스크를 요청하려면 커스텀 컴퓨팅 클래스를 만들고
machineType규칙에서bootDiskSize필드를 설정합니다.
Cloud Storage에서 모델을 로드할 때 포드가 비정상 종료 루프에 진입함
--model-bucket-uri 플래그로 생성된 매니페스트를 배포하면 배포가 멈추고 포드가 CrashLoopBackOff 상태가 될 수 있습니다.
inference-server 컨테이너의 로그를 확인하면 huggingface_hub.errors.HFValidationError과 같은 오해의 소지가 있는 오류가 표시될 수 있습니다. 예를 들면 다음과 같습니다.
huggingface_hub.errors.HFValidationError: Repo id must use alphanumeric chars or '-', '_', '.', '--' and '..' are forbidden, '-' and '.' cannot start or end the name, max length is 96: '/data'.
이 오류는 일반적으로 --model-bucket-uri 플래그에 제공된 Cloud Storage 경로가 잘못된 경우에 발생합니다. vLLM과 같은 추론 서버가 마운트된 경로에서 필요한 모델 파일 (예: config.json)을 찾을 수 없습니다.
로컬 파일을 찾지 못하면 서버는 경로가 Hugging Face Hub 저장소 ID라고 가정합니다. 경로가 유효한 저장소 ID가 아니므로 서버가 검증 오류로 인해 실패하고 비정상 종료 루프에 진입합니다.
이 문제를 해결하려면 --model-bucket-uri 플래그에 제공한 경로가 모델의 config.json 파일과 모든 관련 모델 가중치가 포함된 Cloud Storage 버킷의 정확한 디렉터리를 가리키는지 확인하세요.
다음 단계
- GKE의 AI/ML 조정 포털을 방문하여 GKE에서 AI/ML 워크로드를 실행하는 공식 가이드, 튜토리얼, 사용 사례를 살펴보세요.
- 모델 서빙 최적화에 관한 자세한 내용은 GPU를 사용한 대규모 언어 모델 추론 최적화 권장사항을 참조하세요. GKE에서 GPU를 사용한 LLM 서빙을 위한 권장사항을 다룹니다. 여기에는 양자화, 텐서 동시 로드, 메모리 관리가 포함됩니다.
- 자동 확장에 관한 권장사항에 대한 자세한 내용은 다음 가이드를 참조하세요.
- 스토리지 권장사항에 대한 자세한 내용은 GKE 성능을 위해 Cloud Storage FUSE CSI 드라이버 최적화를 참고하세요.
- GKE AI Labs에서 GKE를 활용하여 AI/ML 이니셔티브를 가속화하기 위한 실험용 샘플 살펴보기