
Dokumen ini menunjukkan cara mempercepat pemuatan bobot model AI besar dari Cloud Storage menggunakan Run:ai Model Streamer dengan server inferensi vLLM di Google Kubernetes Engine (GKE).
Solusi dalam dokumen ini mengasumsikan bahwa Anda telah memuat model dan bobot AI dalam format safetensors di bucket Cloud Storage.
Dengan menambahkan tanda --load-format=runai_streamer ke deployment vLLM, Anda dapat menggunakan Run:ai Model Streamer untuk meningkatkan efisiensi download model untuk workload AI di GKE.
Dokumen ini ditujukan untuk pengguna berikut:
- Engineer machine learning (ML) yang perlu memuat model AI besar dari penyimpanan objek ke node GPU/TPU secepat mungkin.
- Admin dan operator platform yang mengotomatiskan dan mengoptimalkan infrastruktur penayangan model di GKE.
- Arsitek cloud yang mengevaluasi alat pemuatan data khusus untuk workload AI/ML.
Untuk mempelajari lebih lanjut peran umum dan contoh tugas yang dirujuk dalam konten, lihat Peran dan tugas pengguna GKE umum. Google Cloud
Ringkasan
Solusi yang dijelaskan dalam dokumen ini menggunakan tiga komponen inti—Run:ai Model Streamer, vLLM, dan format file safetensors—untuk mempercepat proses pemuatan bobot model dari Cloud Storage ke node GPU.
Run:ai Model Streamer
Run:ai Model Streamer adalah SDK Python open source yang mempercepat pemuatan model AI besar ke GPU. API ini melakukan streaming bobot model langsung dari penyimpanan, seperti bucket Cloud Storage, ke memori GPU Anda. Streamer model sangat cocok untuk mengakses file safetensors yang berada di Cloud Storage.
safetensors
safetensors adalah format file untuk menyimpan tensor, struktur data inti dalam model AI, dengan cara yang meningkatkan keamanan dan kecepatan. safetensors dirancang sebagai alternatif untuk format pickle Python, dan memungkinkan waktu pemuatan yang cepat melalui pendekatan tanpa salinan. Pendekatan ini memungkinkan tensor dapat diakses langsung dari sumber tanpa perlu memuat seluruh file ke memori lokal terlebih dahulu.
vLLM
vLLM adalah library open source untuk inferensi dan penyajian LLM. Server ini adalah server inferensi berperforma tinggi yang dioptimalkan untuk memuat model AI besar dengan cepat. Dalam dokumen ini, vLLM adalah mesin inti yang menjalankan model AI Anda di GKE dan menangani permintaan inferensi yang masuk. Dukungan autentikasi bawaan Run:ai Model Streamer untuk Cloud Storage memerlukan vLLM versi 0.11.1 atau yang lebih baru.
Cara Run:ai Model Streamer mempercepat pemuatan model
Saat Anda memulai aplikasi AI berbasis LLM untuk inferensi, sering kali terjadi penundaan yang signifikan sebelum model siap digunakan. Penundaan ini, yang dikenal sebagai cold start, terjadi karena seluruh file model multi-gigabyte harus didownload dari lokasi penyimpanan, seperti bucket Cloud Storage, ke disk lokal komputer Anda. File kemudian dimuat ke dalam memori GPU Anda. Selama periode pemuatan ini, GPU yang mahal tidak digunakan, yang tidak efisien dan mahal.
Alih-alih proses download lalu muat, streamer model melakukan streaming model langsung dari Cloud Storage ke memori GPU. Streamer menggunakan backend berperforma tinggi untuk membaca beberapa bagian model, yang disebut tensor, secara paralel. Membaca tensor secara serentak jauh lebih cepat daripada memuat file secara berurutan.
Ringkasan arsitektur
Run:ai Model Streamer terintegrasi dengan vLLM di GKE untuk mempercepat pemuatan model dengan melakukan streaming bobot model langsung dari Cloud Storage ke memori GPU, sehingga melewati disk lokal.
Diagram berikut menampilkan arsitektur ini:
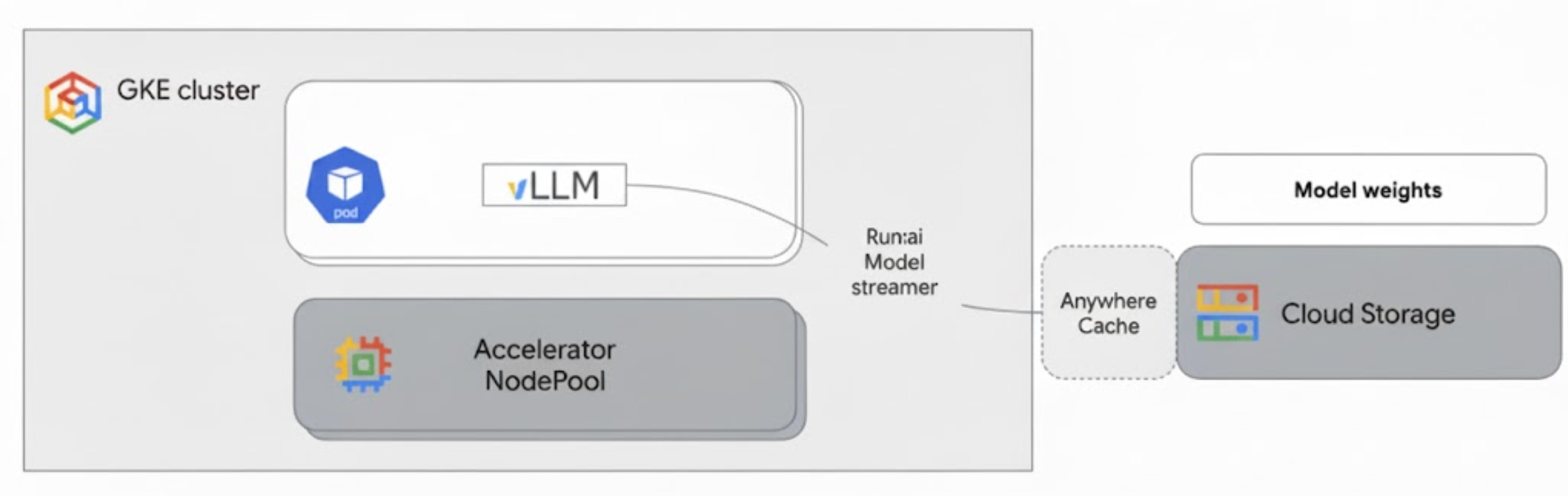
Arsitektur ini mencakup komponen dan alur kerja berikut:
- Bucket Cloud Storage: menyimpan bobot model AI dalam format
safetensors. - Pod GKE dengan GPU: menjalankan server inferensi vLLM.
- Server inferensi vLLM: dikonfigurasi dengan tanda
--load-format=runai_streamer, yang mengaktifkan fungsi streamer model. - Run:ai Model Streamer: saat vLLM dimulai, streamer model membaca bobot model dari jalur
gs://yang ditentukan di bucket Cloud Storage. Daripada mendownload file ke disk, file ini melakukan streaming data tensor langsung ke memori GPU Pod GKE, tempat file tersebut langsung tersedia untuk inferensi vLLM. - Cloud Storage Anywhere Cache (Opsional): Jika diaktifkan, Anywhere Cache akan meng-cache data bucket di zona yang sama dengan node GKE, sehingga lebih mempercepat akses data untuk streamer.
Manfaat
- Waktu cold start yang lebih singkat: streamer model secara signifikan mengurangi waktu yang diperlukan model untuk dimulai. Memuat bobot model hingga enam kali lebih cepat dibandingkan metode konvensional. Untuk mengetahui informasi selengkapnya, lihat Benchmark Run:ai Model Streamer
- Peningkatan pemanfaatan GPU: dengan meminimalkan penundaan pemuatan model, GPU dapat mendedikasikan lebih banyak waktu untuk tugas inferensi yang sebenarnya, sehingga meningkatkan efisiensi dan kapasitas pemrosesan secara keseluruhan.
- Alur kerja yang disederhanakan: solusi yang dijelaskan dalam dokumen ini terintegrasi dengan GKE, sehingga server inferensi seperti vLLM atau SGLang dapat langsung mengakses model di bucket Cloud Storage.
Sebelum memulai
Pastikan untuk menyelesaikan prasyarat berikut.
Pilih atau buat project dan aktifkan API
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
Verify that billing is enabled for your Google Cloud project.
Enable the Kubernetes Engine, Cloud Storage, Compute Engine, IAM APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM
role (roles/serviceusage.serviceUsageAdmin), which
contains the serviceusage.services.enable permission. Learn how to grant
roles.
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
Verify that billing is enabled for your Google Cloud project.
Enable the Kubernetes Engine, Cloud Storage, Compute Engine, IAM APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM
role (roles/serviceusage.serviceUsageAdmin), which
contains the serviceusage.services.enable permission. Learn how to grant
roles.
Menyiapkan Cloud Shell
Dokumen ini menggunakan perintah Google Cloud CLI dan kubectl untuk membuat dan mengelola resource yang diperlukan untuk solusi ini. Anda dapat menjalankan perintah ini di Cloud Shell dengan mengklik Activate Cloud Shell di bagian atas konsol Google Cloud .
In the Google Cloud console, activate Cloud Shell.
Atau, Anda dapat menginstal dan melakukan inisialisasi gcloud CLI di lingkungan shell lokal untuk menjalankan perintah. Jika Anda ingin menggunakan terminal shell lokal, jalankan perintah gcloud auth login untuk melakukan autentikasi dengan Google Cloud.
Memberikan peran IAM
Pastikan Google Cloud akun Anda memiliki peran IAM berikut di project Anda sehingga Anda dapat membuat cluster GKE dan mengelola Cloud Storage:
roles/container.adminroles/storage.admin
Untuk memberikan peran ini, jalankan perintah berikut:
gcloud projects add-iam-policy-binding PROJECT_ID \
--member="user:$(gcloud config get-value account)" \
--role="roles/container.admin"
gcloud projects add-iam-policy-binding PROJECT_ID \
--member="user:$(gcloud config get-value account)" \
--role="roles/storage.admin"
Ganti PROJECT_ID dengan project ID Anda.
Menyiapkan lingkungan Anda
Bagian ini akan memandu Anda menyiapkan cluster GKE dan mengonfigurasi izin untuk mengakses model Anda di Cloud Storage.
Membuat cluster GKE dengan GPU
Run:ai Model Streamer dapat digunakan dengan cluster GKE Autopilot dan Standard. Pilih mode cluster yang paling sesuai dengan kebutuhan Anda.
Tetapkan variabel untuk project dan nama cluster Anda:
export PROJECT_ID=PROJECT_ID export CLUSTER_NAME=CLUSTER_NAMEGanti kode berikut:
PROJECT_ID: Google Cloud Project ID Anda. Anda dapat menemukan project ID dengan menjalankan perintahgcloud config get-value project.CLUSTER_NAME: Nama cluster Anda. Contoh,run-ai-test.
Buat cluster Autopilot atau Standar:
Autopilot
Ikuti langkah-langkah berikut untuk membuat cluster GKE Autopilot:
Tetapkan region untuk cluster Anda:
export REGION=REGIONGanti
REGIONdengan region tempat Anda ingin membuat cluster. Untuk performa optimal, gunakan region yang sama dengan bucket Cloud Storage Anda.Membuat cluster:
gcloud container clusters create-auto $CLUSTER_NAME \ --project=$PROJECT_ID \ --location=$REGION
Cluster Autopilot secara otomatis menyediakan node berdasarkan persyaratan beban kerja. Saat Anda men-deploy server vLLM pada langkah selanjutnya, Autopilot akan menyediakan node GPU jika diperlukan. Untuk mengetahui informasi selengkapnya, lihat Tentang pembuatan otomatis node pool.
Standar
Ikuti langkah-langkah berikut untuk membuat cluster Standar GKE:
Tetapkan zona untuk cluster Anda:
export ZONE=ZONEGanti
ZONEdengan zona tempat Anda ingin membuat cluster. Untuk performa optimal, gunakan zona di region yang sama dengan bucket Cloud Storage Anda.Membuat cluster:
gcloud container clusters create $CLUSTER_NAME \ --project=$PROJECT_ID \ --zone=$ZONE \ --workload-pool=$PROJECT_ID.svc.id.goog \ --num-nodes=1Buat node pool dengan satu mesin G2 (GPU NVIDIA L4):
gcloud container node-pools create g2-gpu-pool \ --cluster=$CLUSTER_NAME \ --zone=$ZONE \ --machine-type=g2-standard-16 \ --num-nodes=1 \ --accelerator=type=nvidia-l4
Mengonfigurasi Workload Identity Federation for GKE
Konfigurasi Workload Identity Federation for GKE untuk mengizinkan workload GKE Anda mengakses model di bucket Cloud Storage Anda dengan aman.
Tetapkan variabel untuk akun layanan dan namespace Kubernetes Anda:
export KSA_NAME=KSA_NAME export NAMESPACE=NAMESPACEGanti kode berikut:
NAMESPACE: namespace tempat Anda ingin menjalankan workload. Pastikan untuk menggunakan namespace yang sama untuk membuat semua resource dalam dokumen ini.KSA_NAME: nama akun layanan Kubernetes yang dapat digunakan Pod Anda untuk mengautentikasi ke API Google Cloud .
Membuat namespace Kubernetes:
kubectl create namespace $NAMESPACEBuat akun layanan Kubernetes (KSA):
kubectl create serviceaccount $KSA_NAME \ --namespace=$NAMESPACEBerikan izin yang diperlukan untuk KSA Anda:
Tetapkan variabel lingkungan:
export BUCKET_NAME=BUCKET_NAME export PROJECT_ID=PROJECT_ID export PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID \ --format 'get(projectNumber)')Ganti kode berikut:
BUCKET_NAME: nama bucket Cloud Storage Anda yang berisi filesafetensors.PROJECT_ID: Google Cloud Project ID Anda.
PROJECT_NUMBER,PROJECT_ID,NAMESPACE, danKSA_NAMEakan digunakan untuk membuat ID utama Workload Identity Federation for GKE untuk project Anda pada langkah-langkah berikut.Berikan peran
roles/storage.bucketViewerkepada KSA Anda untuk melihat objek di bucket Cloud Storage Anda:gcloud storage buckets add-iam-policy-binding gs://$BUCKET_NAME \ --member="principal://iam.googleapis.com/projects/$PROJECT_NUMBER/locations/global/workloadIdentityPools/$PROJECT_ID.svc.id.goog/subject/ns/$NAMESPACE/sa/$KSA_NAME" \ --role="roles/storage.bucketViewer"Berikan peran
roles/storage.objectUserkepada KSA Anda untuk membaca, menulis, dan menghapus objek di bucket Cloud Storage Anda:gcloud storage buckets add-iam-policy-binding gs://$BUCKET_NAME \ --member="principal://iam.googleapis.com/projects/$PROJECT_NUMBER/locations/global/workloadIdentityPools/$PROJECT_ID.svc.id.goog/subject/ns/$NAMESPACE/sa/$KSA_NAME" \ --role="roles/storage.objectUser"
Anda kini telah menyiapkan cluster GKE dengan GPU dan mengonfigurasi Workload Identity Federation for GKE, sehingga memberikan izin yang diperlukan kepada Akun Layanan Kubernetes untuk mengakses model AI Anda di Cloud Storage. Setelah cluster dan izin disiapkan, Anda siap men-deploy server inferensi vLLM, yang akan menggunakan akun layanan ini untuk melakukan streaming bobot model dengan Run:ai Model Streamer.
Men-deploy vLLM dengan Run:ai Model Streamer
Deploy Pod yang menjalankan server yang kompatibel dengan vLLM OpenAI, dan dikonfigurasi dengan tanda --load-format=runai_streamer untuk menggunakan Run:ai Model Streamer. Versi vLLM harus 0.11.1 atau yang lebih baru.
Contoh manifes berikut menunjukkan konfigurasi vLLM dengan streamer model yang diaktifkan untuk model berukuran kecil, seperti gemma-2-9b-it, menggunakan satu GPU NVIDIA L4.
- Jika Anda menggunakan model besar yang memerlukan beberapa GPU, tingkatkan nilai
--tensor-parallel-sizeke jumlah GPU yang diperlukan. - Flag
--model-loader-extra-config={"distributed":true}memungkinkan pemuatan bobot model terdistribusi dan merupakan setelan yang direkomendasikan untuk meningkatkan performa pemuatan model dari penyimpanan objek.
Untuk mengetahui informasi selengkapnya, lihat Paralelisme tensor dan Parameter yang dapat disesuaikan.
Simpan manifes berikut sebagai
vllm-deployment.yaml. Manifes dirancang agar fleksibel di seluruh cluster Autopilot dan Standard.apiVersion: apps/v1 kind: Deployment metadata: name: vllm-streamer-deployment namespace: NAMESPACE spec: replicas: 1 selector: matchLabels: app: vllm-streamer template: metadata: labels: app: vllm-streamer spec: serviceAccountName: KSA_NAME containers: - name: vllm-container image: vllm/vllm-openai:v0.11.1 command: - python3 - -m - vllm.entrypoints.openai.api_server args: - --model=gs://BUCKET_NAME/PATH_TO_MODEL - --load-format=runai_streamer - --model-loader-extra-config={"distributed":true} - --host=0.0.0.0 - --port=8000 - --disable-log-requests - --tensor-parallel-size=1 ports: - containerPort: 8000 name: api # startupProbe allows for longer startup times for large models startupProbe: httpGet: path: /health port: 8000 failureThreshold: 60 # 60 * 10s = 10 minutes timeout periodSeconds: 10 initialDelaySeconds: 30 readinessProbe: httpGet: path: /health port: 8000 failureThreshold: 3 periodSeconds: 10 resources: limits: nvidia.com/gpu: "1" requests: nvidia.com/gpu: "1" volumeMounts: - mountPath: /dev/shm name: dshm nodeSelector: cloud.google.com/gke-accelerator: nvidia-l4 volumes: - emptyDir: medium: Memory name: dshmGanti kode berikut:
NAMESPACE: namespace Kubernetes Anda.KSA_NAME: nama akun layanan Kubernetes Anda.BUCKET_NAME: nama bucket Cloud Storage Anda.PATH_TO_MODEL: jalur ke direktori model Anda dalam bucket, misalnya,models/my-llama.
Terapkan manifes untuk membuat Deployment:
kubectl create -f vllm-deployment.yaml
Anda dapat membuat lebih banyak manifes vLLM menggunakan alat Panduan Memulai Inferensi GKE.
Memverifikasi Deployment
Periksa status Deployment:
kubectl get deployments -n NAMESPACEDapatkan nama Pod:
kubectl get pods -n NAMESPACE | grep vllm-streamerPerhatikan nama Pod yang diawali dengan
vllm-streamer-deployment.Untuk memeriksa apakah streamer model mendownload model dan bobot, lihat log Pod:
kubectl logs -f POD_NAME -n NAMESPACEGanti
POD_NAMEdengan nama Pod dari langkah sebelumnya. Log streaming yang berhasil akan terlihat seperti berikut:[RunAI Streamer] Overall time to stream 15.0 GiB of all files: 13.4s, 1.1 GiB/s
Opsional: Meningkatkan performa dengan Anywhere Cache
Cloud Storage Anywhere Cache dapat lebih mempercepat pemuatan model dengan meng-cache data lebih dekat ke node GKE Anda. Caching sangat bermanfaat saat menskalakan beberapa node di zona yang sama.
Anda mengaktifkan Cache di Mana Saja untuk bucket Cloud Storage tertentu di zona Google Cloud tertentu. Untuk meningkatkan performa, zona cache harus cocok dengan zona tempat Pod inferensi GKE Anda berjalan. Pendekatan Anda bergantung pada apakah Pod Anda berjalan di zona yang dapat diprediksi.
Untuk cluster zona GKE Standard, tempat Anda mengetahui zona tempat Pod akan berjalan, aktifkan Anywhere Cache untuk zona tertentu tersebut.
Untuk cluster GKE regional (Autopilot dan Standard), tempat Pod dapat dijadwalkan di beberapa zona, Anda memiliki opsi berikut:
- Aktifkan caching di semua zona: Aktifkan Cache di Mana Saja di setiap zona dalam region cluster. Hal ini memastikan cache tersedia di mana pun GKE menjadwalkan Pod Anda. Perhatikan bahwa Anda akan dikenai biaya untuk setiap zona tempat caching diaktifkan. Untuk mengetahui informasi selengkapnya, lihat harga Anywhere Cache.
- Menempatkan Pod ke zona tertentu: Gunakan aturan
nodeSelectorataunodeAffinitydalam manifes workload untuk membatasi Pod ke satu zona. Kemudian, Anda dapat mengaktifkan Anywhere Cache hanya di zona tersebut. Ini adalah pendekatan yang lebih hemat biaya jika workload Anda dapat ditoleransi untuk dibatasi ke satu zona.
Untuk mengaktifkan Anywhere Cache untuk zona tempat cluster GKE Anda berada, jalankan perintah berikut:
# Enable the cache
gcloud storage buckets anywhere-caches create gs://$BUCKET_NAME $ZONE
# Check the status of the cache
gcloud storage buckets anywhere-caches describe $BUCKET_NAME/$ZONE
Pembersihan
Agar tidak dikenai biaya pada akun Google Cloud Anda untuk resource yang digunakan dalam dokumen ini, hapus project yang berisi resource tersebut, atau simpan project dan hapus setiap resource.
Untuk menghapus setiap resource, ikuti langkah-langkah berikut:
Hapus cluster GKE. Tindakan ini akan menghapus semua node dan workload.
gcloud container clusters delete CLUSTER_NAME --location=ZONE_OR_REGIONGanti kode berikut:
CLUSTER_NAME: nama cluster Anda.ZONE_OR_REGION: zona atau region cluster Anda.
Nonaktifkan Anywhere Cache, jika Anda mengaktifkannya, untuk menghindari biaya berkelanjutan. Untuk mengetahui informasi selengkapnya, lihat Menonaktifkan cache.
Langkah berikutnya
- Pelajari cara Memuat Model Hugging Face ke Cloud Storage (eksperimental)
- Pelajari cara Menyajikan LLM di GKE menggunakan GPU.
- Pelajari lebih lanjut GPU yang tersedia di GKE.
- Baca Ringkasan GKE Storage.
- Pelajari Mengonfigurasi Workload Identity Federation.