
בדף הזה מתוארות אפשרויות לזמינות גבוהה ב-Google Distributed Cloud (תוכנה בלבד) ל-VMware.
פונקציונליות עיקרית
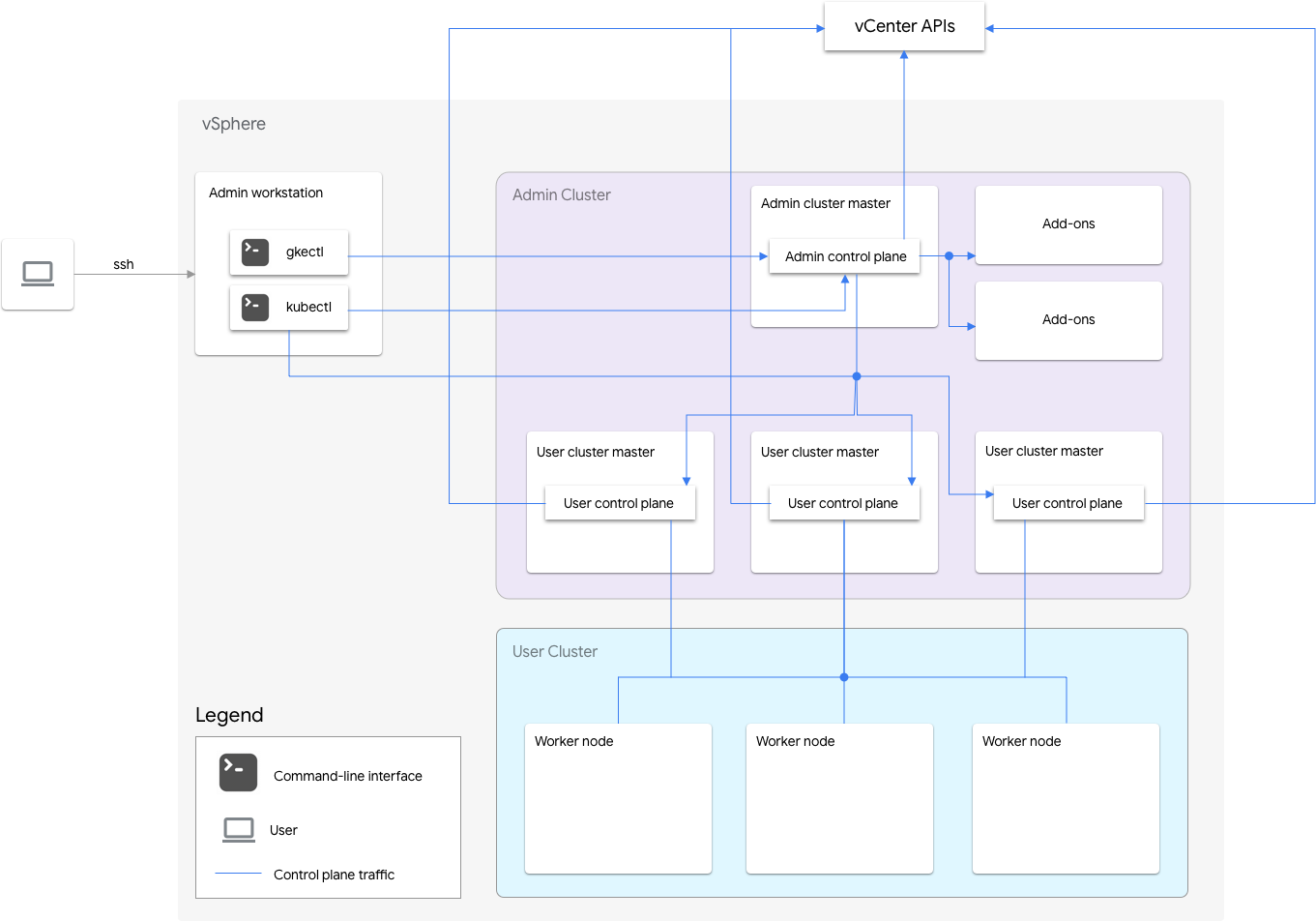
התקנה של Google Distributed Cloud for VMware שכוללת רק תוכנה כוללת אשכול אדמין ואשכול משתמש אחד או יותר.
אשכול האדמין מנהל את מחזור החיים של אשכולות המשתמשים, כולל יצירה, עדכונים, שדרוגים ומחיקה של אשכולות משתמשים. באשכול האדמין, ה-admin master מנהל את צמתי העובדים של האדמין, שכוללים user masters (צמתים שמריצים את מישור הבקרה של אשכולות המשתמשים המנוהלים) וצמתי תוספים (צמתים שמריצים את רכיבי התוספים שתומכים בפונקציונליות של אשכול האדמין).
לכל אשכול משתמשים יש לאשכול האדמין צומת אחד ללא זמינות גבוהה או שלושה צמתים עם זמינות גבוהה שמריצים את מישור הבקרה. מישור הבקרה כולל את שרת Kubernetes API, את מתזמן Kubernetes, את מנהל הבקרה של Kubernetes וכמה בקרי קריטיים עבור אשכול המשתמשים.
הזמינות של מישור הבקרה של אשכול המשתמשים היא קריטית לפעולות של עומסי עבודה, כמו יצירה, הגדלה והקטנה של עומסי עבודה וסיום שלהם. במילים אחרות, הפסקת פעולה של מישור הבקרה לא משפיעה על עומסי העבודה הפועלים, אבל עומסי העבודה הקיימים מאבדים את יכולות הניהול משרת Kubernetes API אם מישור הבקרה שלו לא קיים.
עומסי עבודה ושירותים בקונטיינרים נפרסים בצמתי העובדים של אשכול המשתמשים. כל צומת עובד בודד לא צריך להיות קריטי לזמינות האפליקציה, כל עוד האפליקציה נפרסת עם תרמילים מיותרים שמתוזמנים בכמה צמתי עובד.
הפעלת זמינות גבוהה
vSphere ו-Google Distributed Cloud מספקים מספר תכונות שמשפרות את הזמינות הגבוהה (HA).
vSphere HA ו-vMotion
מומלץ להפעיל את שתי התכונות הבאות באשכול vCenter שמארח את אשכולות Google Distributed Cloud:
התכונות האלה משפרות את הזמינות ואת השחזור במקרה של כשל במארח ESXi.
vCenter HA משתמש בכמה מארחי ESXi שהוגדרו כאשכול כדי לספק שחזור מהיר מהפסקות זמניות בשירות וזמינות גבוהה (HA) חסכונית לאפליקציות שפועלות במכונות וירטואליות. מומלץ להקצות לאשכול vCenter עוד מארחים ולהפעיל את התכונה vSphere HA Host Monitoring עם Host Failure Response שמוגדר ל-Restart VMs. במקרה של כשל במארח ESXi, המכונות הווירטואליות יכולות להיות מופעלות מחדש באופן אוטומטי במארחים זמינים אחרים.
vMotion מאפשר מיגרציה פעילה של מכונות וירטואליות משרת ESXi אחד לשרת אחר ללא השבתה. במקרה של תחזוקת מארח מתוכננת, אפשר להשתמש בהעברה פעילה של vMotion כדי למנוע לחלוטין השבתה של האפליקציה ולהבטיח את המשכיות העסקית.
אשכול אדמין
Google Distributed Cloud תומך ביצירת אשכולות אדמין בזמינות גבוהה (HA). ל-HA admin cluster יש שלושה צמתים שמריצים רכיבי control-plane. מידע על הדרישות וההגבלות מופיע במאמר בנושא אשכול אדמין עם זמינות גבוהה.
שימו לב: חוסר זמינות של מישור הבקרה של אשכול האדמין לא משפיע על הפונקציונליות של אשכול המשתמש הקיים או על עומסי העבודה שפועלים באשכולות המשתמשים.
יש שני צמתי תוספים באשכול אדמין. אם אחד מהם מושבת, השני עדיין יכול להפעיל את פעולות אשכול האדמין. לצורך יתירות, Google Distributed Cloud מפזרת שירותים קריטיים של תוספים, כמו kube-dns, על שני צמתי התוספים.
אם מגדירים את antiAffinityGroups.enabled ל-true בקובץ ההגדרה של אשכול האדמין, Google Distributed Cloud יוצר באופן אוטומטי כללי vSphere DRS למניעת קרבה בין הצמתים של התוסף, וכך הם מפוזרים בין שני מארחים פיזיים לצורך זמינות גבוהה.
אשכול משתמשים
כדי להפעיל זמינות גבוהה (HA) באשכול משתמשים, צריך להגדיר את masterNode.replicas ל-3 בקובץ התצורה של אשכול המשתמשים. אם Controlplane V2 מופעל באשכול המשתמשים (מומלץ), שלושת הצמתים של מישור הבקרה פועלים באשכול המשתמשים.
באשכולות משתמשים מדור קודם של HA שלא מופעל בהם Controlplane V2, שלושת צמתי מישור הבקרה פועלים באשכול האדמין. בכל צומת של מישור הבקרה פועלת גם רפליקה של etcd. אשכול המשתמשים ממשיך לפעול כל עוד פועלת רמת בקרה אחת ויש קוורום של etcd. כדי להגיע לקוורום ב-etcd
צריך ששניים משלושת העותקים של etcd יפעלו.
אם מגדירים את antiAffinityGroups.enabled ל-true בקובץ התצורה של אשכול האדמין, Google Distributed Cloud יוצר באופן אוטומטי כללי אנטי-אפיניות של vSphere DRS לשלושת הצמתים שמריצים את מישור הבקרה של אשכול המשתמשים.
כתוצאה מכך, מכונות ה-VM האלה מתפרסות על פני שלושה מארחים פיזיים.
בנוסף, Google Distributed Cloud יוצר כללי אנטי-אפיניות של vSphere DRS עבור צמתי העובדים באשכול המשתמשים, וכתוצאה מכך הצמתים האלה מפוזרים בין לפחות שלושה מארחים פיזיים. כמה כללי DRS anti-affinity משמשים לכל מאגר צמתים של אשכול משתמשים, בהתאם למספר הצמתים. כך מוודאים שהצמתים של העובדים יוכלו למצוא מארחים להפעלה, גם אם מספר המארחים קטן ממספר מכונות ה-VM במאגר הצמתים של אשכול המשתמשים. מומלץ לכלול עוד מארחים פיזיים באשכול vCenter. צריך גם להגדיר את DRS כך שהוא יהיה אוטומטי לחלוטין, כדי שבמקרה שמארח מסוים לא יהיה זמין, DRS יוכל להפעיל מחדש מכונות וירטואליות באופן אוטומטי במארחים זמינים אחרים, בלי להפר את כללי האנטי-אפיניות של המכונות הווירטואליות.
ב-Google Distributed Cloud יש תווית צומת מיוחדת, onprem.gke.io/failure-domain-name, שהערך שלה מוגדר לשם המארח הבסיסי של ESXi. אפליקציות של משתמשים שרוצים זמינות גבוהה יכולות להגדיר כללי podAntiAffinity עם התווית הזו כtopologyKey כדי לוודא שפודים של האפליקציה שלהם מפוזרים על פני מכונות וירטואליות שונות וגם על פני מארחים פיזיים.
אפשר גם להגדיר כמה מאגרי צמתים עבור אשכול משתמשים עם מאגרי נתונים שונים ותוויות צמתים מיוחדות. באופן דומה, אפשר להגדיר podAntiAffinityכללים עם התווית המיוחדת של הצומת כtopologyKey כדי להשיג זמינות גבוהה יותר במקרה של כשלים במאגר הנתונים.
כדי להשיג זמינות גבוהה לעומסי עבודה של משתמשים, צריך לוודא שלאשכול המשתמשים יש מספר מספיק של רפליקות בקטע nodePools.replicas, כדי להבטיח את המספר הרצוי של צמתי עובדים באשכול המשתמשים במצב פעיל.
אתם יכולים להשתמש במאגרי נתונים נפרדים לאשכולות של אדמינים ולאשכולות של משתמשים כדי לבודד את הכשלים שלהם.
מאזן עומסים
יש שני סוגים של מאזני עומסים שאפשר להשתמש בהם כדי להשיג זמינות גבוהה.
מאזן עומסים משולב של MetalLB
כדי להשיג זמינות גבוהה (HA) באמצעות מאזן העומסים MetalLB שכלול בחבילה, צריך יותר מצומת אחד עם enableLoadBalancer: true.
MetalLB מפזר את השירותים בין הצמתים של איזון העומסים, אבל לכל שירות יש רק צומת מוביל אחד שמטפל בכל התנועה של השירות הזה.
במהלך שדרוג האשכול, יש זמן השבתה מסוים כשצמתי איזון העומסים משודרגים. משך ההפרעה למעבר לגיבוי (failover) של MetalLB גדל ככל שמספר הצמתים של איזון העומסים גדל. אם יש פחות מ-5 צמתים, ההפרעה היא בתוך 10 שניות.
איזון עומסים ידני
באיזון עומסים ידני, אתם מגדירים את Google Distributed Cloud כך שישתמש במאזן עומסים לפי בחירתכם, כמו F5 BIG-IP או Citrix. אתם מגדירים זמינות גבוהה במאזן העומסים, ולא ב-Google Distributed Cloud.
שימוש בכמה אשכולות לצורך תוכנית התאוששות מאסון (DR)
פריסת אפליקציות בכמה אשכולות בכמה שרתי vCenter יכולה לספק זמינות גלובלית גבוהה יותר ולהגביל את רדיוס ההשפעה במהלך הפסקות שירות.
במקרה כזה, המערכת משתמשת באשכול הקיים במרכז הנתונים המשני לצורך התאוששות מאסון, במקום להגדיר אשכול חדש. בהמשך מופיע סיכום כללי של השלבים לביצוע הפעולה הזו:
יוצרים עוד אשכול אדמין ואשכול משתמשים במרכז הנתונים המשני. בארכיטקטורה מרובת האשכולות הזו, אנחנו דורשים שלמשתמשים יהיו שני אשכולות אדמין בכל מרכז נתונים, וכל אשכול אדמין מפעיל אשכול משתמשים.
למשתמש המשני יש מספר מינימלי של צמתי עובד (שלושה), והוא נמצא במצב המתנה פעיל (תמיד פועל).
אפשר לשכפל פריסות של אפליקציות בשני vCenter באמצעות סנכרון תצורות, או להשתמש בגישה המועדפת של שרשרת toolchain קיימת של DevOps (CI/CD, Spinnaker) לאפליקציות.
במקרה של אסון, אפשר לשנות את הגודל של אשכול המשתמשים למספר הצמתים.
בנוסף, נדרש מעבר DNS כדי לנתב את התעבורה בין האשכולות למרכז הנתונים המשני.